医疗数仓业务数据采集与同步
业务数据采集与同步
- 业务采集组件配置
- 业务数据同步概述
- 数据同步策略选择
- 数据同步工具概述
- 1.1.4 全量表数据同步
- DataX配置文件生成
- 全量表数据同步脚本
- 增量表数据同步 MySQL - Maxwell - Kafka - Flume - HDFS
- Maxwell配置
- 增量表首日全量同步
业务采集组件配置

Maxwell将业务采集到的kafka,下游从kafka消费数据用于计算
链接: 配置Maxwell
业务数据同步概述
业务数据是数据仓库的重要数据来源,我们需要每日定时从业务数据库中抽取数据,传输到数据仓库中,之后再对数据进行分析统计。为保证统计结果的正确性,需要保证数据仓库中的数据与业务数据库是同步的,离线数仓的计算周期通常为天,所以数据同步周期也通常为天,即每天同步一次即可。数据的同步策略有全量同步和增量同步。
全量同步,就是每天都将业务数据库中的全部数据同步一份到数据仓库,这是保证两侧数据同步的最简单的方式。

增量同步,就是每天只将业务数据中的新增及变化数据同步到数据仓库。采用每日增量同步的表,通常需要在首日先进行一次全量同步。

数据同步策略选择
两种策略都能保证数据仓库和业务数据库的数据同步,那应该如何选择呢?下面对两种策略进行简要对比。

若业务表数据量比较大,且每天数据变化的比例比较低,这时应采用增量同步,否则可采用全量同步。

数据同步工具概述
数据同步工具种类繁多,大致可分为两类,
一类是以DataX、Sqoop为代表的基于Select查询的离线、批量同步工具,
另一类是以Maxwell、Canal、Flink-CDC为代表的基于数据库数据变更日志(例如MySQL的binlog,其会实时记录所有的insert、update以及delete操作)的实时流式同步工具。
全量同步通常使用DataX、Sqoop等基于查询的离线同步工具。而增量同步既可以使用DataX、Sqoop等工具,也可使用Maxwell、Canal、Flink-CDC等工具,下面对增量同步不同方案进行简要对比。

1.1.4 全量表数据同步
链接: 配置DataX
数据通道
全量表数据由DataX从MySQL业务数据库直接同步到HDFS,具体数据流向,如下图所示。

DataX配置文件
我们需要为每张全量表编写一个DataX的json配置文件,此处以 user为例,配置文件内容如下:
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["id","create_time","update_time","email","hashed_password","telephone","username"],"connection": [{"jdbcUrl": ["jdbc:mysql://hadoop102:3306/medical?useSSL=false&allowPublicKeyRetrieval=true&useUnicode=true&characterEncoding=utf-8"],"table": ["user"]}],"password": "000000","splitPk": "","username": "root"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "bigint"},{"name": "create_time","type": "string"},{"name": "update_time","type": "string"},{"name": "email","type": "string"},{"name": "hashed_password","type": "string"},{"name": "telephone","type": "string"},{"name": "username","type": "string"}],"compress": "gzip","defaultFS": "hdfs://hadoop102:8020","fieldDelimiter": "\t","fileName": "user","fileType": "text","path": "${targetdir}","writeMode": "truncate","nullFormat": ""}}}],"setting": {"speed": {"channel": 1}}}
}
由于目标路径包含一层日期,用于对不同天的数据加以区分,故path参数并未写死,需在提交任务时通过参数动态传入,参数名称为targetdir。
DataX配置文件生成
链接: DataX配置文件生成
将生成器上传到服务器的/opt/module/gen_datax_config目录
[atguigu@hadoop102 ~]$ mkdir /opt/module/gen_datax_config
[atguigu@hadoop102 ~]$ cd /opt/module/gen_datax_config
上传生成器

修改configuration.properties配置
mysql.username=root
mysql.password=000000
mysql.host=hadoop102
mysql.port=3306
mysql.database.import=medical
# mysql.database.export=
mysql.tables.import=dict,doctor,hospital,medicine,patient,user
# mysql.tables.export=
is.seperated.tables=0
hdfs.uri=hdfs://hadoop102:8020
import_out_dir=/opt/module/datax/job/medical/import
# export_out_dir=
执行
[atguigu@hadoop102 gen_datax_config]$ java -jar datax-config-generator-1.0-SNAPSHOT-jar-with-dependencies.jar
测试生成的DataX配置文件
以user为例,测试用脚本生成的配置文件是否可用。
1)创建目标路径
由于DataX同步任务要求目标路径提前存在,故需手动创建路径,当前user表的目标路径应为/origin_data/medical/user_full/2023-05-09。
[atguigu@hadoop102 bin]$ hadoop fs -mkdir -p /origin_data/medical/user_full/2023-05-09
2)执行DataX同步命令
[atguigu@hadoop102 bin]$ python /opt/module/datax/bin/datax.py -p"-Dtargetdir=/origin_data/medical/user_full/2023-05-09" /opt/module/datax/job/medical/import/medical.user.json
3)观察同步结果
观察HFDS目标路径是否出现数据。

全量表数据同步脚本
为方便使用以及后续的任务调度,此处编写一个全量表数据同步脚本。
1)在~/bin目录创建medical_mysql_to_hdfs_full.sh
[atguigu@hadoop102 bin]$ vim ~/bin/medical_mysql_to_hdfs_full.sh
#!/bin/bashDATAX_HOME=/opt/module/datax
DATAX_DATA=/opt/module/datax/job/medical#清理脏数据
handle_targetdir() {hadoop fs -rm -r $1 >/dev/null 2>&1hadoop fs -mkdir -p $1
}#数据同步
import_data() {local datax_config=$1local target_dir=$2handle_targetdir "$target_dir"echo "正在处理$1"python $DATAX_HOME/bin/datax.py -p"-Dtargetdir=$target_dir" $datax_config >/tmp/datax_run.log 2>&1if [ $? -ne 0 ]thenecho "处理失败, 日志如下:"cat /tmp/datax_run.log fi
}#接收表名变量
tab=$1
# 如果传入日期则do_date等于传入的日期,否则等于前一天日期
if [ -n "$2" ] ;thendo_date=$2
elsedo_date=$(date -d "-1 day" +%F)
ficase ${tab} in
dict|doctor|hospital|medicine|patient|user)import_data $DATAX_DATA/import/medical.${tab}.json /origin_data/medical/${tab}_full/$do_date;;
"all")for tmp in dict doctor hospital medicine patient userdoimport_data $DATAX_DATA/import/medical.${tmp}.json /origin_data/medical/${tmp}_full/$do_datedone;;
esac
2)为mysql_to_hdfs_full.sh增加执行权限
[atguigu@hadoop102 bin]$ chmod +x ~/bin/medical_mysql_to_hdfs_full.sh
3)测试同步脚本
[atguigu@hadoop102 bin]$ medical_mysql_to_hdfs_full.sh all 2023-05-09
4)检查同步结果
查看HDFS目表路径是否出现全量表数据,全量表共6张。
全量表同步逻辑比较简单,只需每日执行全量表数据同步脚本medical_mysql_to_hdfs_full.sh即可。
增量表数据同步 MySQL - Maxwell - Kafka - Flume - HDFS
数据通道

Flume配置
1)Flume配置概述
Flume需要将Kafka中各topic的数据传输到HDFS,因此选用KafkaSource以及HDFSSink。对于安全性要求高的数据(不允许丢失)选用FileChannel,允许部分丢失的数据如日志可以选用MemoryChannel以追求更高的效率。此处采集的是业务数据,不允许丢失,选用FileChannel,生产环境根据实际情况选择合适的组件。
KafkaSource订阅Kafka medical_ods主题的数据,HDFSSink将不同topic的数据写入不同路径,路径中应包含表名及日期,前者用于区分来源于不同业务表的数据,后者按天对数据进行划分。关键配置如下:

具体数据示例如下:

链接: 医疗数仓配置Flume
Maxwell配置
1)Maxwell时间戳问题

为了让Maxwell时间戳日期与模拟的业务日期保持一致,对Maxwell源码进行改动,增加了mock_date参数,在/opt/module/maxwell/config.properties文件中将该参数的值修改为业务日期即可。
2)补充mock.date参数
配置参数如下。
log_level=info#Maxwell数据发送目的地,可选配置有stdout|file|kafka|kinesis|pubsub|sqs|rabbitmq|redis
producer=kafka
# 目标Kafka集群地址
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
#目标Kafka topic,可静态配置,例如:maxwell,也可动态配置,例如:%{database}_%{table}
kafka_topic=topic_db# MySQL相关配置
host=hadoop102
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true# 指定数据按照主键分组进入Kafka不同分区,避免数据倾斜
producer_partition_by=primary_key# 修改数据时间戳的日期部分
mock_date=2023-05-093)重新启动Maxwell
[atguigu@hadoop102 bin]$ mxw.sh restart
4)重新生成模拟数据
[atguigu@hadoop102 bin]$ medical_mock.sh 1
5)观察HDFS目标路径日期是否与业务日期保持一致
增量表首日全量同步
通常情况下,增量表需要在首日进行一次全量同步,后续每日再进行增量同步,首日全量同步可以使用Maxwell的bootstrap功能,方便起见,下面编写一个增量表首日全量同步脚本。
1)在~/bin目录创建medical_mysql_to_kafka_inc_init.sh
[atguigu@hadoop102 bin]$ vim medical_mysql_to_kafka_inc_init.sh
脚本内容如下
#!/bin/bash# 该脚本的作用是初始化所有的增量表,只需执行一次MAXWELL_HOME=/opt/module/maxwellimport_data() {for tab in $@do $MAXWELL_HOME/bin/maxwell-bootstrap --database medical --table $tab --config $MAXWELL_HOME/config.propertiesdone
}case $1 in
consultation | payment | prescription | prescription_detail | user | patient | doctor)import_data $1;;
"all")import_data consultation payment prescription prescription_detail user patient doctor;;
esac
2)为medical_mysql_to_kafka_inc_init.sh增加执行权限
[atguigu@hadoop102 bin]$ chmod 777 ~/bin/medical_mysql_to_kafka_inc_init.sh
3)测试同步脚本
(1)清理历史数据
为方便查看结果,现将HDFS上之前同步的增量表数据删除。
[atguigu@hadoop102 ~]$ hadoop fs -ls /origin_data/medical | grep _inc | awk '{print KaTeX parse error: Expected 'EOF', got '}' at position 2: 8}̲' | xargs hadoo… medical_mysql_to_kafka_inc_init.sh all
4)检查同步结果
观察HDFS上是否重新出现增量表数据。
相关文章:
医疗数仓业务数据采集与同步
业务数据采集与同步 业务采集组件配置业务数据同步概述数据同步策略选择数据同步工具概述1.1.4 全量表数据同步DataX配置文件生成全量表数据同步脚本增量表数据同步 MySQL - Maxwell - Kafka - Flume - HDFSMaxwell配置增量表首日全量同步 业务采集组件配置 Maxwell将业务采集到…...

数字孪生智慧水利与水务所包含的应用场景有哪些?二者有何区别
水利和水务是两个密切相关但有所区别的概念,它们在水资源管理和保护方面各自承担着不同的职责和功能。 定义 智慧水务:智慧水务是指通过物联网、大数据、云计算、人工智能等新一代信息技术,对城市供水、排水、污水处理、水质监测等水务系统…...

Qt Creator项目构建配置说明
QT安装好之后,在安装目录的Tools\QtCreator\bin下找到qtcreator.exe文件并双击打开 点击文件-新建文件或项目 选择Qt Widgets Application 设置项目名称以及路径 make工具选择qmake(cmake还未尝试过) 设置主界面对应类的名称、父类&#…...

进程间通信的“五大武器”
😄作者简介: 小曾同学.com,一个致力于测试开发的博主⛽️,主要职责:测试开发、CI/CD 如果文章知识点有错误的地方,还请大家指正,让我们一起学习,一起进步。 😊 座右铭:不…...
备考实战之循环结构(for循环语句)(六))
全国青少年信息学奥林匹克竞赛(信奥赛)备考实战之循环结构(for循环语句)(六)
实战训练1—输出九九乘法表 问题描述: 在学校里学过九九乘法表,编程实现打印九九乘法表。 输入格式: 无输入 输出格式: 1*11 2*12 2*24 3*13 3*26 3*39 4*14 4*28 4*312 4*416 5*15 5*210 5*315 5*420 5*525 6*16 6*212 6*318 6*424 6*5…...

封装echarts成vue component
封装echarts成vue component EChartsLineComponent 文章目录 封装echarts成vue component EChartsLineComponent封装说明重写重点EChartsLineComponent的源码 使用说明调用EChartsLineComponent示例源码 封装说明 为了减少一些公共代码和方便使用echarts的line图形,…...

uniapp Stripe 支付
引入 Stripe npm install stripe/stripe-js import { loadStripe } from stripe/stripe-js; Stripe 提供两种不同类型组件 Payment Element 和 Card Element:如果你使用的是 Payment Element,它是一个更高级别的组件,能够自动处理多种支…...

Windows onnxruntime编译openvino
理论上来说,可以直接访问 ONNXRuntime Releases 下载 dll 文件,然后从官方文档中下载缺少的头文件以直接调用,但我没有尝试过。 1. 下载 OpenVINO 包 从官网下载 OpenVINO 的安装包并放置在 C:\Program Files (x86) 路径下,例如…...
vue3+TS+vite中Echarts的安装与使用
概述 技术栈:Vue3TsViteEcharts 简述:图文详解,教你如何在Vue项目中引入Echarts,封装Echarts组件,并实现常用Echats图列 文章目录 一,效果图 二,引入Echarts 2.1安装Echarts 2.2main.ts中引…...

期末算法分析程序填空题
目录 5-1 最小生成树(普里姆算法) 5-2 快速排序(分治法) 输入样例: 输出样例: 5-3 归并排序(递归法) 输入样例: 输出样例: 5-4 求解编辑距离问题(动态规划法)…...

搭建android开发环境 android studio
1、环境介绍 在进行安卓开发时,需要掌握java,需要安卓SDK,需要一款编辑器,还需要软件的测试环境(真机或虚拟机)。 早起开发安卓app,使用的是eclipse加安卓SDK,需要自行搭建。 目前开…...

R语言6种将字符转成数字的方法,写在新年来临之际
咱们临床研究中,拿到数据后首先要对数据进行清洗,把数据变成咱们想要的格式,才能进行下一步分析,其中数据中的字符转成数字是个重要的内容,因为字符中常含有特殊符号,不利于分析,转成数字后才能…...

RocketMQ学习笔记(持续更新中......)
目录 1. 单机搭建 2. 测试RocketMQ 3. 集群搭建 4. 集群启动 5. RocketMQ-DashBoard搭建 6. 不同类型消息发送 1.同步消息 2. 异步消息发送 3. 单向发送消息 7. 消费消息 1. 单机搭建 1. 先从rocketmq官网下载二进制包,ftp上传至linux服务器,…...
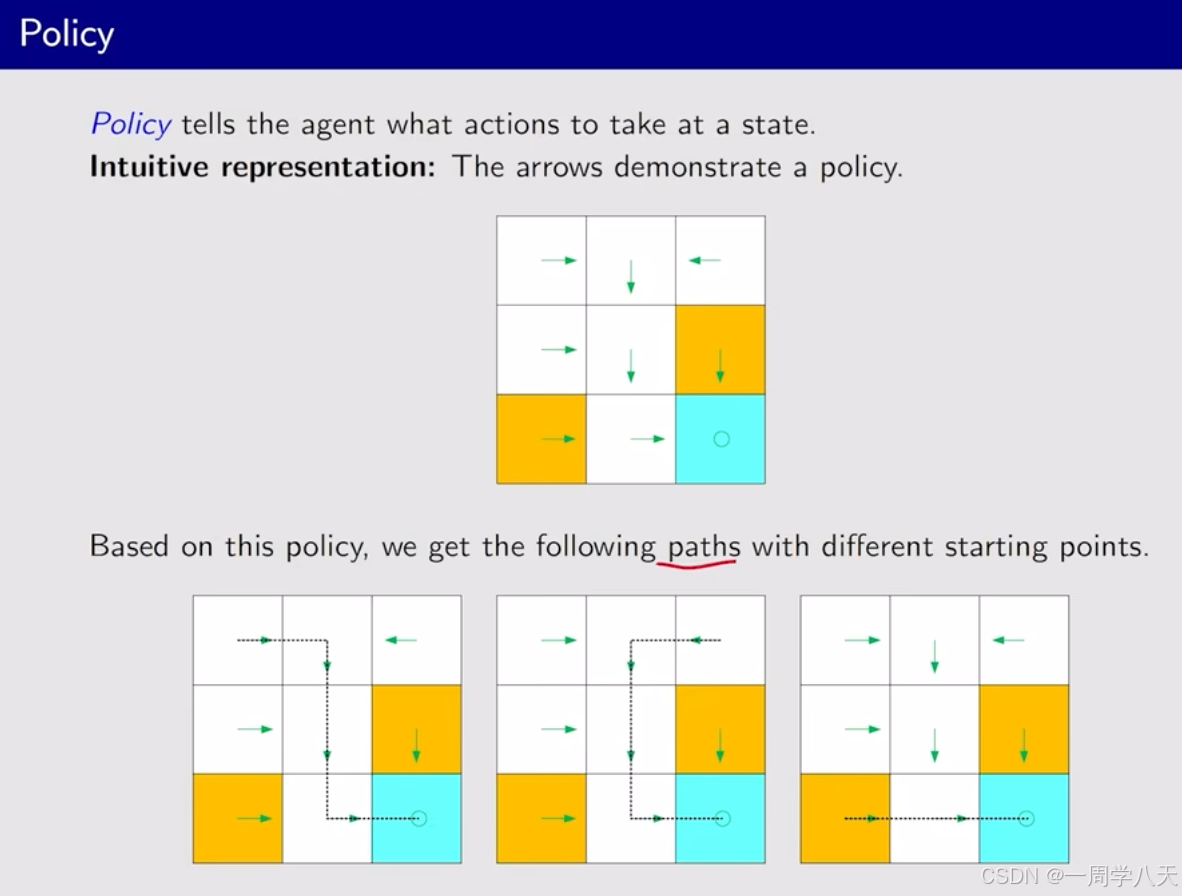
强化学习的基础概念
这节课会介绍一些基本的概念,并结合例子讲解。 在马尔科夫决策框架下介绍这些概念 本博客是基于西湖大学强化学习课程的视屏进行笔记的,这是链接: 课程链接 目录 强化学习的基本概念 state和state space Action和Action Space State transiti…...
)
excel怎么删除右边无限列(亲测有效)
excel怎么删除右边无限列(亲测有效) 网上很多只用第1步的,删除了根本没用,还是存在,但是隐藏后取消隐藏却是可以的。 找到右边要删除的列的第一个空白列,选中整个列按“ctrlshift>(向右的小箭头)”&am…...

STM32-笔记23-超声波传感器HC-SR04
一、简介 HC-SR04 工作参数: • 探测距离:2~600cm • 探测精度:0.1cm1% • 感应角度:<15 • 输出方式:GPIO • 工作电压:DC 3~5.5V • 工作电流:5.3mA • 工作温度:-40~85℃ 怎么…...

Linux | Ubuntu零基础安装学习cURL文件传输工具
目录 介绍 检查安装包 下载安装 手册 介绍 cURL是一个利用URL语法在命令行下工作的文件传输工具,首次发行于1997年12。cURL支持多种协议,包括FTP、FTPS、HTTP、HTTPS、TFTP、SFTP、Gopher、SCP、Telnet、DICT、FILE、LDAP、LDAPS、IMAP、POP3…...

什么是 GPT?Transformer 工作原理的动画展示
大家读完觉得有意义记得关注和点赞!!! 目录 1 图解 “Generative Pre-trained Transformer”(GPT) 1.1 Generative:生成式 1.1.1 可视化 1.1.2 生成式 vs. 判别式(译注) 1.2 Pr…...
)
SpringCloudAlibaba实战入门之路由网关Gateway过滤器(十三)
承接上篇,我们知道除了断言,还有一个重要的功能是过滤器,本节课我们就讲一下常见的网关过滤器及其一般使用。 一、Filter介绍 类似SpringMVC里面的的拦截器Interceptor,Servlet的过滤器。“pre”和“post”分别会在请求被执行前调用和被执行后调用,用来修改请求和响应信…...

电路仿真软件PSIM简介
在从事开关电源相关产品开发的工程师或者正在学习开关电源的学习者,常常会用到各种仿真软件进行电路的仿真,不仅可以快速验证电路参数,还能清楚知道各器件的工作状态。 现在的电路仿真软件很多,例如matlab、Multisim、Simplis&…...
 【新手友好】)
如何用Vibe coding一周做三个成果?(附完整prompt) 【新手友好】
最近AI圈刮起了一阵"Vibe coding"旋风,很多朋友私信问我:到底什么是Vibe coding?零基础真的能学会吗?一周真的能做出好几个可以用的成果吗?作为亲身体验了一把的人,我可以明确告诉大家࿱…...
别再死记硬背公式了!用大白话和动图拆解Transformer的注意力机制
用生活场景拆解Transformer:注意力机制就像一场高效会议 想象你正在主持一场跨国团队会议,成员们用不同语言讨论项目进展。作为主持人,你需要快速捕捉每个人的发言重点,判断谁的意见最关键,并协调不同观点之间的关系—…...

3分钟上手Windhawk:像安装App一样轻松定制Windows系统
3分钟上手Windhawk:像安装App一样轻松定制Windows系统 【免费下载链接】windhawk The customization marketplace for Windows programs: https://windhawk.net/ 项目地址: https://gitcode.com/gh_mirrors/wi/windhawk 你是否厌倦了Windows系统一成不变的界…...

CANN Ascend C数据转换临时空间API
GetTransDataMaxMinTmpSize 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: http…...

5分钟学会在PowerPoint中插入LaTeX公式:科研工作者的高效神器
5分钟学会在PowerPoint中插入LaTeX公式:科研工作者的高效神器 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 还在为PowerPoint里输入复杂的数学公式而头疼吗?作为科研人员、教师或…...

政企级无人机管理系统,如何用一套方案搞定多行业巡检?
一、为什么政企客户越来越倾向私有化无人机平台?在低空经济政策收紧、数据安全要求趋严的今天,很多单位在采购无人机管理系统时,已经不再满足于 “能用就行”。公有云平台无法部署在政务内网,数据出网存在合规风险;通用…...

RISC-V开发板测评实战:从申请到深度评测的完整指南
1. 项目概述:一次深度参与RISC-V生态的绝佳机会最近在电子发烧友论坛上看到了一个挺有意思的活动——“第二届RISC-V开发板测评大赛”,主办方是昊芯。对于咱们这些搞嵌入式、玩单片机、或者对开源硬件和RISC-V架构感兴趣的朋友来说,这绝对是一…...

如何在Windows 11上免费安装安卓子系统:3步快速搭建跨平台应用中心
如何在Windows 11上免费安装安卓子系统:3步快速搭建跨平台应用中心 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA 想在Windows电脑上无缝运行手…...

避坑指南:注册个体户时,经营范围怎么选才不影响以后开票和接项目?
技术创业者必读:个体户经营范围选择的战略与实操指南 在数字经济蓬勃发展的今天,越来越多的技术从业者选择以个体户形式开启创业之路。作为企业合法经营的"身份证",营业执照中经营范围的填写看似简单,实则暗藏玄机。一个…...
)
别再手动分片了!用SeaweedFS的Chunk机制搞定海量小文件存储(Docker实战)
别再手动分片了!用SeaweedFS的Chunk机制搞定海量小文件存储(Docker实战) 当你的图片上传服务每天新增百万级文件时,传统存储方案往往会突然"罢工"——目录遍历耗时从秒级飙升到分钟级,inode耗尽导致服务崩溃…...