什么是 GPT?Transformer 工作原理的动画展示
大家读完觉得有意义记得关注和点赞!!!
目录
1 图解 “Generative Pre-trained Transformer”(GPT)
1.1 Generative:生成式
1.1.1 可视化
1.1.2 生成式 vs. 判别式(译注)
1.2 Pre-trained:预训练
1.2.1 可视化
1.2.2 预训练 vs. 增量训练(微调)
1.3 Transformer:一类神经网络架构
1.4 小结
2 Transformer 起源与应用
2.1 Attention Is All You Need, Google, 2017,机器翻译
2.2 Generative Transformer
2.3 GPT-2/GPT-3 生成效果(文本续写)预览
2.4 ChatGPT 等交互式大模型
2.5 小结
3 Transformer 数据处理四部曲
3.1 Embedding:分词与向量表示
3.1.1 token 的向量表示
3.1.2 向量表示的直观解释
3.2 Attention:embedding 向量间的语义交流
3.2.1 语义交流
3.2.2 例子:”machine learning model” / “fashion model”
3.3 Feed-forward / MLP:向量之间无交流
3.3.1 针对所有向量做一次性变换
3.3.2 直观解释
3.3.3 重复 Attention + Feed-forward 模块,组成多层网络
3.4 Unembedding:概率
3.4.1 最后一层 feed-forward 输出中的最后一个向量
3.4.2 下一个单词的选择
3.5 小结
4 GPT -> ChatGPT:从文本补全到交互式聊天助手
4.1 系统提示词,伪装成聊天
4.2 如何训练一个企业级 GPT 助手(译注)
5 总结
1 图解 “Generative Pre-trained Transformer”(GPT)
GPT 是 Generative Pre-trained Transformer 的缩写,直译为“生成式预训练 transformer”, 我们先从字面上解释一下它们分别是什么意思。
1.1 Generative:生成式
“Generative”(生成式)意思很直白,就是给定一段输入(例如,最常见的文本输入), 模型就能续写(“编”)下去。
1.1.1 可视化
下面是个例子,给定 “The most effective way to learn computer science is” 作为输入, 模型就开始续写后面的内容了。

“Generative”:生成(续写)文本的能力。
1.1.2 生成式 vs. 判别式(译注)
文本续写这种生成式模型,区别于 BERT 那种判别式模型(用于分类、完形填空等等),
- BERT:预训练深度双向 Transformers 做语言理解(Google,2019)
1.2 Pre-trained:预训练
“Pre-trained”(预训练)指的是模型是用大量数据训练出来的。
1.2.1 可视化

“Pre-trained”:用大量数据进行训练。
图中的大量旋钮/仪表盘就是所谓的“模型参数”,训练过程就是在不断优化这些参数,后面会详细介绍。
1.2.2 预训练 vs. 增量训练(微调)
“预”这个字也暗示了模型还有在特定任务中进一步训练的可能 —— 也就是我们常说的“微调”(finetuning)。
如何对预训练模型进行微调: InstructGPT:基于人类反馈训练语言模型遵从指令的能力(OpenAI,2022)。 译注。
1.3 Transformer:一类神经网络架构
“GPT” 三个词中最重要的其实是最后一个词 Transformer。 Transformer 是一类神经网络/机器学习模型,作为近期 AI 领域的核心创新, 推动着这个领域近几年的极速发展。
Transformer 直译为“变换器”或“转换器”,通过数学运算不断对输入数据进行变换/转换。另外,变压器、变形金刚也是这个词。 译注。

Transformer:一类神经网络架构的统称。

Transformer 最后的输出层。后面还会详细介绍
1.4 小结
如今已经可以基于 Transformer 构建许多不同类型的模型,不限于文本,例如,
- 语音转文字
- 文字转语音
-
文生图(text-to-image):DALL·E、MidJourney 等在 2022 年风靡全球的工具,都是基于 Transformer。
文生图(text-to-image)简史:扩散模型(diffusion models)的崛起与发展(2022)

虽然无法让模型真正理解 "物种 π"是什么(本来就是瞎编的),但它竟然能生成出来,而且效果很惊艳。
本文希望通过“文字+动图”这种可视化又方便随时停下来思考的方式,解释 Transformer 的内部工作原理。
2 Transformer 起源与应用
2.1 Attention Is All You Need, Google, 2017,机器翻译
Transformer 是 Google 2017 年在 Attention Is All You Need paper 中提出的, 当时主要用于文本翻译:

2.2 Generative Transformer
之后,Transformer 的应用场景扩展到了多个领域,例如 ChatGPT 背后也是 Transformer, 这种 Transformer 接受一段文本(或图像/音频)作为输入,然后就能预测接下来的内容。 以预测下一个单词为例,如下图所示,下一个单词有多种可能,各自的概率也不一样:

但有了一个这样的预测下一个单词模型,就能通过如下步骤让它生成更长的文字,非常简单:
- 将初始文本输入模型;
- 模型预测出下一个可能的单词列表及其概率,然后通过某种算法(不一定挑概率最大的) 从中选一个作为下一个单词,这个过程称为采样(sampling);
- 将新单词追加到文本结尾,然后将整个文本再次输入模型;转 2;
以上 step 2 & 3 不断重复,得到的句子就越来越长。
2.3 GPT-2/GPT-3 生成效果(文本续写)预览
来看看生成的效果,这里拿 GPT-2 和 GPT-3 作为例子。
下面是在我的笔记本电脑上运行 GPT-2,不断预测与采样,逐渐补全为一个故事。 但结果比较差,生成的故事基本上没什么逻辑可言:

下面是换成 GPT-3(模型不再开源,所以是通过 API), GPT-3 和 GPT-2 基本架构一样,只是规模更大, 但效果突然变得非常好, 生成的故事不仅合乎逻辑,甚至还暗示 “物种 π” 居住在一个数学和计算王国:

2.4 ChatGPT 等交互式大模型
以上这个不断重复“预测+选取”来生成文本的过程,就是 ChatGPT 或其他类似大语言模型(LLM) 的底层工作原理 —— 逐单词(token)生成文本。
2.5 小结
以上是对 GPT 及其背后的 Transformer 的一个感性认识。接下来我们就深入到 Transformer 内部, 看看它是如何根据给定输入来预测(计算)出下一个单词的。
3 Transformer 数据处理四部曲
为理解 Transformer 的内部工作原理,本节从端到端(从最初的用户输入,到最终的模型输出)的角度看看数据是如何在 Transformer 中流动的。 从宏观来看,输入数据在 Transformer 中经历如下四个处理阶段:

Transformer 数据处理四部曲
下面分别来看。
3.1 Embedding:分词与向量表示
首先,输入内容会被拆分成许多小片段(这个过程称为 tokenization),这些小片段称为 token,
- 对于文本:token 通常是单词、词根、标点符号,或者其他常见的字符组合;
- 对于图片:token 可能是一小块像素区域;
- 对于音频:token 可能是一小段声音。
然后,将每个 token 用一个向量(一维数组)来表示。
3.1.1 token 的向量表示
这实际上是以某种方式在编码该 token;

Embedding:每个 token 对应一个 N*1 维度的数值格式表示的向量。
3.1.2 向量表示的直观解释
如果把这些向量看作是在高维空间中的坐标, 那么含义相似的单词在这个高维空间中是相邻的。

词义相近的四个单词 “leap/jump/skip/hop” 在向量空间中是相邻的
将输入进行 tokenization 并转成向量表示之后,输入就从一个句子就变成了一个向量序列。 接下来,这个向量序列会进行一个称为 attention 的运算。
3.2 Attention:embedding 向量间的语义交流
3.2.1 语义交流
attention 使得向量之间能够相互“交流”信息。这个交流是双向的,在这个过程中,每个向量都会更新自身的值。

这种信息“交流”是有上下文和语义理解能力的。
3.2.2 例子:”machine learning model” / “fashion model”
例如,“model” 这个词在 “machine learning model”(机器学习模型)和在 “fashion model”(时尚模特)中的意思就完全不一样, 因此虽然是同一个单词(token),但对应的 embedding 向量是不同的,

Attention 模块的作用就是确定上下文中哪些词之间有语义关系,以及如何准确地理解这些含义(更新相应的向量)。 这里说的“含义”(meaning),指的是编码在向量中的信息。
3.3 Feed-forward / MLP:向量之间无交流
Attention 模块让输入向量们彼此充分交换了信息(例如,单词 “model” 指的应该是“模特”还是“模型”), 然后,这些向量会进入第三个处理阶段:

第三阶段:多层感知机(multi-layer perceptron),也称为前馈层(feed-forward layer)。
3.3.1 针对所有向量做一次性变换
这个阶段,向量之间没有互相“交流”,而是并行地经历同一处理:

3.3.2 直观解释
后面会看,从直观上来说,这个步骤有点像对每个向量都提出一组同样的问题,然后根据得到的回答来更新对应的向量:

以上解释中省略了归一化等一些中间步骤,但已经可以看出: attention 和 feed-forward 本质上都是大量的矩阵乘法,

本文的一个目的就是让读者理解这些矩阵乘法的直观意义。
3.3.3 重复 Attention + Feed-forward 模块,组成多层网络
Transformer 基本上是不断复制 Attention 和 Feed-forward 这两个基本结构, 这两个模块的组合成为神经网络的一层。在每一层,

- 输入向量通过 attention 更新彼此;
- feed-forward 模块将这些更新之后的向量做统一变换,得到这一层的输出向量;
3.4 Unembedding:概率
3.4.1 最后一层 feed-forward 输出中的最后一个向量
如果一切顺利,最后一层 feed-forward 输出中的最后一个向量(the very last vector in the sequence), 就已经包含了句子的核心意义(essential meaning of the passage)。对这个向量进行 unembedding 操作(也是一次性矩阵运算), 得到的就是下一个单词的备选列表及其概率:

图:原始输入为 "To date, the cleverest thinker of all time was",让模型预测下一个 token。经过多层 attention + feed-forward 之后, 最后一层输出的最后一个向量已经学习到了输入句子表达的意思,(经过简单转换之后)就能作为下一个单词的概率。
3.4.2 下一个单词的选择
根据一定的规则选择一个 token,
- 注意这里不一定选概率最大的,根据工程经验,一直选概率最大的,生成的文本会比较呆板;
- 实际上由一个称为
temperature的参数控制;
3.5 小结
以上就是 Transformer 内部的工作原理。
前面已经提到,有了一个这样的预测下一个单词模型,就能通过如下步骤让它生成更长的文字,非常简单:
- 将初始文本输入模型;
- 模型预测出下一个可能的单词列表及其概率,然后通过某种算法(不一定挑概率最大的) 从中选一个作为下一个单词,这个过程称为采样(sampling);
- 将新单词追加到文本结尾,然后将整个文本再次输入模型;转 2;
4 GPT -> ChatGPT:从文本补全到交互式聊天助手
GPT-3 的早期演示就是这样的:给 GPT-3 一段起始文本,它就自动补全(续写)故事和文章。 这正式以上介绍的 Transformer 的基本也是核心功能。
ChatGPT 的核心是 GPT 系列(GPT 3/3.5/4),但它怎么实现聊天这种工作方式的呢?
4.1 系统提示词,伪装成聊天
其实很简单,将输入文本稍作整理,弄成聊天内容,然后把这样的文本再送到 GPT/Transformer, 它就会把这个当前是聊天内容,续写下去。最后只需要把它续写的内容再抽出来返回给用户, 对用户来说,就是在聊天。

这段文本设定用户是在与一个 AI 助手交互的场景,这就是所谓的系统提示词(system prompt)。
4.2 如何训练一个企业级 GPT 助手(译注)
OpenAI 官方对 GPT->ChatGPT 有过专门分享:如何训练一个企业级 GPT 助手(OpenAI,2023)
基础模型不是助手,它们不想回答问题,只想补全文档。 因此,如果让它们“写一首关于面包和奶酪的诗”,它们不仅不“听话”,反而会有样学样,列更多的任务出来,像下面左图这样,
这是因为它只是在忠实地补全文档。 但如果你能成功地提示它,例如,开头就说“这是一首关于面包和奶酪的诗”, 那它接下来就会真的补全一首这样的诗出来,如右图。
我们还可以通过 few-shot 来进一步“欺骗”它。把你想问的问题整理成一个“提问+回答”的文档格式, 前面给一点正常的论述,然后突然来个问题,它以为自己还是在补全文档,其实已经把问题回答了:
这就是把基础模型调教成一个 AI 助手的过程。

5 总结
本文整理翻译了原视频的前半部分,通过可视化方式解释 GPT/Transformer 的内部工作原理。 原视频后面的部分是关于 general deep learning, machine learning 等等的基础,想继续学习的,强烈推荐。
相关文章:

什么是 GPT?Transformer 工作原理的动画展示
大家读完觉得有意义记得关注和点赞!!! 目录 1 图解 “Generative Pre-trained Transformer”(GPT) 1.1 Generative:生成式 1.1.1 可视化 1.1.2 生成式 vs. 判别式(译注) 1.2 Pr…...
)
SpringCloudAlibaba实战入门之路由网关Gateway过滤器(十三)
承接上篇,我们知道除了断言,还有一个重要的功能是过滤器,本节课我们就讲一下常见的网关过滤器及其一般使用。 一、Filter介绍 类似SpringMVC里面的的拦截器Interceptor,Servlet的过滤器。“pre”和“post”分别会在请求被执行前调用和被执行后调用,用来修改请求和响应信…...

电路仿真软件PSIM简介
在从事开关电源相关产品开发的工程师或者正在学习开关电源的学习者,常常会用到各种仿真软件进行电路的仿真,不仅可以快速验证电路参数,还能清楚知道各器件的工作状态。 现在的电路仿真软件很多,例如matlab、Multisim、Simplis&…...
C语言:调试的概念和调试器的选择
所谓调试(Dubug),就是跟踪程序的运行过程,从而发现程序的逻辑错误(思路错误),或者隐藏的缺陷(Bug)。 在调试的过程中,我们可以监控程序的每一个细节ÿ…...

25. C++继承 1 (继承的概念与基础使用, 继承的复制兼容规则,继承的作用域)
⭐上篇模板文章:24. C模板 2 (非类型模板参数,模板的特化与模板的分离编译)-CSDN博客 ⭐本篇代码:c学习 橘子真甜/c-learning-of-yzc - 码云 - 开源中国 (gitee.com) ⭐标⭐是比较重要的部分 目录 一. 继承的基础使用 1.1 继承的格式 1.2 …...

git 退出编辑模式
在使用 Git 时,有时需要进入编辑器来输入提交信息或进行其他编辑操作。不同的系统和配置可能会导致使用不同的编辑器。以下是几种常见 Git 编辑器的退出方法: Vim 编辑器: 保存并退出: 按下 Esc 键退出编辑模式。输入 :w…...

内容营销与传统营销方式有哪些差别?
在互联网高度发达的当下,碎片化的信息接收方式,让用户对于营销信息拥有较高的敏感度。这一现状,也使得众多传统营销方式正在逐渐失效。想要稳定推广效率,内容营销是当下不少品牌的共同选择。接下来,就让我们来了解下内…...

EasyExcel(读取操作和填充操作)
文章目录 1.准备Read.xlsx(具有两个sheet)2.读取第一个sheet中的数据1.模板2.方法3.结果 3.读取所有sheet中的数据1.模板2.方法3.结果 EasyExcel填充1.简单填充1.准备 Fill01.xlsx2.无模版3.方法4.结果 2.列表填充1.准备 Fill02.xlsx2.模板3.方法4.结果 …...
】)
【华为OD-E卷 - 机房布局 100分(python、java、c++、js、c)】
【华为OD-E卷 - 机房布局 100分(python、java、c、js、c)】 题目 小明正在规划一个大型数据中心机房,为了使得机柜上的机器都能正常满负荷工作,需要确保在每个机柜边上至少要有一个电箱。 为了简化题目,假设这个机房…...

【竞技宝】LOL:IG新赛季分组被质疑
北京时间2024年12月31日,今天已经2024年的最后一天,在进入一月之后,英雄联盟将迎来全新的2025赛季。而目前新赛季第一阶段的抽签结果已经全部出炉,其中人气最高的IG战队在本次抽签中抽到了“绝世好签”引来了网友们的质疑。 首先介…...

ChatBI来啦!NBAI 正式上线 NL2SQL 功能
NebulaAI 现已正式上线 NL2SQL 功能,免费开放使用! 什么是 NL2SQL?NL2SQL 即通过自然语言交互,用户可以轻松查询、分析和管理数据库中的数据(ChatBI),从此摆脱传统复杂的数据库操作。 欢迎免费…...
)
8. Web应用程序(Web)
8. Web应用程序(Web) Spring Boot 非常适用于Web应用程序开发。你可以使用嵌入式 Tomcat、Jetty、Undertow或Netty创建一个独立的HTTP服务器。大多是Web应用程序都会使用 spring-boot-starter-web 依赖模块来快速启动和运行项目。你也可以选择使用 spri…...

Linux内核修改内存分配策略
今天遇到了如下的内核报错 Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00007f0e1e06c000, 65536, 1) failed; errorCannot allocate memory (errno12)这个报错是因为,linux会对大部分的内存资源申请都回复允许,以便于运行更…...

六大亮点解析:AI视频监控助力部队训练安全管理
一、用户痛点: 在部队的日常训练和任务执行中,官兵的安全始终是最为重要的保障。然而,传统的监控方式存在显著的局限性,尤其是在高强度、长时间的训练过程中,人工值守监控容易产生疲劳,误判的风险大&#…...

【从零开始入门unity游戏开发之——C#篇33】C#委托(`Delegate`)和事件(`event` )、事件与委托的区别、Invoke()的解释
文章目录 一、委托(Delegate)1、什么是委托?2、委托的基本语法3、定义自定义委托4、如何使用自定义委托5、多播委托6、C# 中的系统委托7、GetInvocationList 获取多个函数返回值8、总结 二、事件(event )1、事件是什么…...

大数据与机器学习(它们有何关系?)
想了解大数据和机器学习吗?我们将为你解释它们是什么、彼此之间有何关联,以及它们为何在数据密集型应用中如此重要。 大数据和机器学习是如何相互关联的? 大数据指的是传统存储方法无法处理的海量数据。机器学习则是计算机系统从观察结果和…...
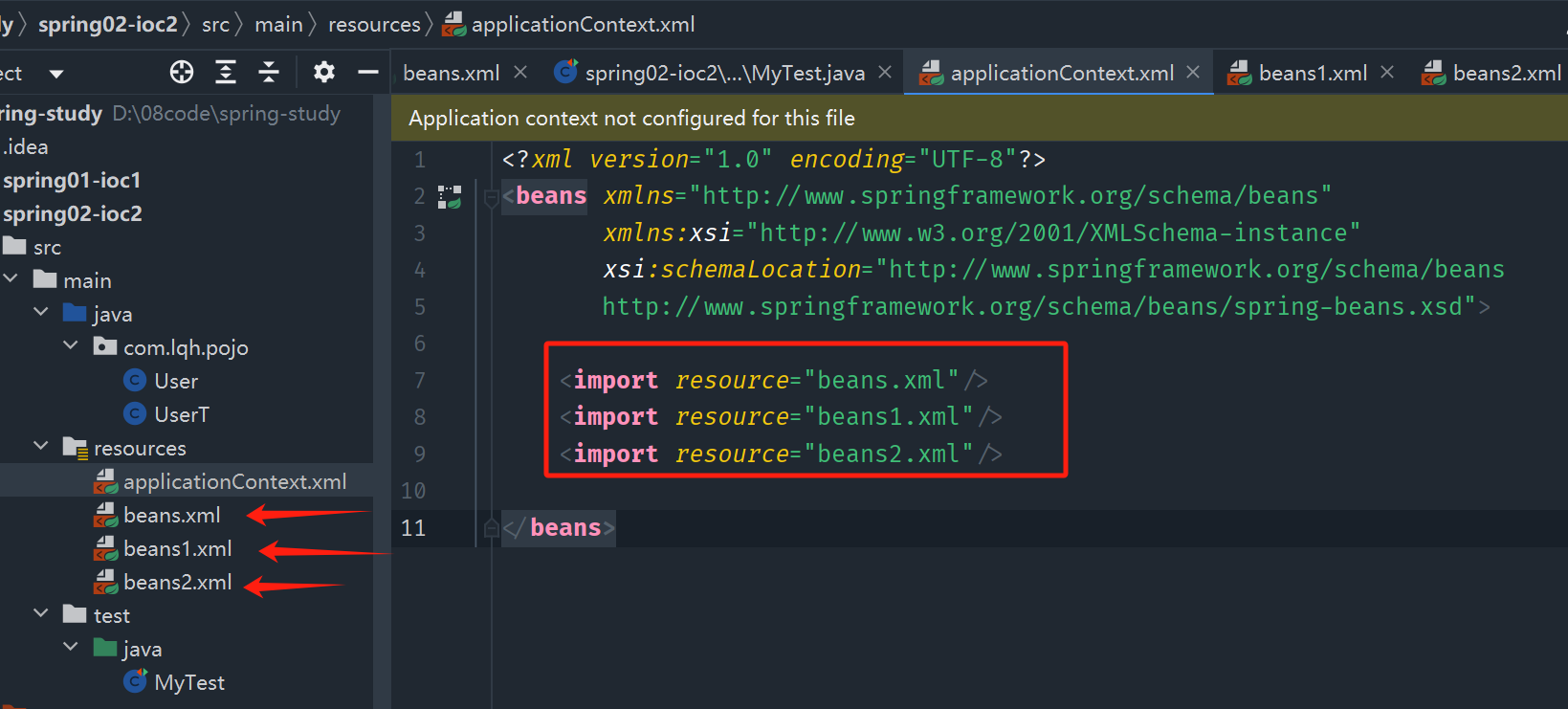
深入浅出 Spring(一) | Spring简介、IOC理论推导、快速上手 Spring
1. spring 1.1 简介 Spring : 春天 —>给软件行业带来了春天 2002年,Rod Jahnson首次推出了Spring框架雏形interface21框架。 2004年3月24日,Spring框架以interface21框架为基础,经过重新设计,发布了1.0正式版。 很难想象…...

IDEA 社区版 SpringBoot不能启动
报错原因,Failed to load class [javax.servlet.Filter] <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-tomcat</artifactId><scope>provided</scope> </dependency>…...

职场常用Excel基础01-数据验证
大家好,excel在职场中使用非常频繁,今天和大家一起分享一下excel中数据验证相关的内容~ 在Excel中,数据验证(Data Validation)是一项非常有用的功能,它可以帮助用户限制输入到单元格中的数据类型和范围&am…...
活动预告 |【Part1】Microsoft Azure 在线技术公开课:数据基础知识
课程介绍 参加“Azure 在线技术公开课:数据基础知识”活动,了解有关云环境和数据服务中核心数据库概念的基础知识。通过本次免费的介绍性活动,你将提升在关系数据、非关系数据、大数据和分析方面的技能。 活动时间:01 月 07 日…...

嵌入式AI转型实战:从传统MCU开发到端侧智能部署
1. 项目概述:当嵌入式遇上AI,一场静默的变革最近和几个在芯片原厂、消费电子和工业控制领域干了十多年的老伙计聊天,话题总绕不开一个词:AI。不是那种高谈阔论的未来畅想,而是实实在在的焦虑和困惑。一个做电机驱动的兄…...

利用Taotoken模型广场为不同任务场景选择合适的大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同任务场景选择合适的大模型 当你的项目需要处理多种类型的任务时,例如同时涉及内容创作、代…...

别再死记硬背了!用Python脚本模拟UDS 28服务,5分钟搞懂通信控制
用Python实战模拟UDS 28服务:5分钟掌握CAN总线通信控制 在汽车电子开发与测试中,UDS诊断协议的理解往往停留在理论层面,而实际动手操作才是掌握精髓的关键。28服务作为ISO14229-1标准中的通信控制核心,直接影响ECU的报文收发行为。…...

RK3568平台OpenCV交叉编译实战:从源码到部署的完整指南
1. 项目概述:为什么要在RK3568上折腾OpenCV?最近在做一个基于瑞芯微RK3568芯片的边缘计算盒子项目,其中一个核心需求就是要在设备上跑实时的图像识别算法。算法框架选型时,我们团队内部有过一些讨论,最终还是决定用Ope…...

Folcolor:让你的Windows文件夹告别“黄脸婆“,用色彩提升3倍工作效率
Folcolor:让你的Windows文件夹告别"黄脸婆",用色彩提升3倍工作效率 【免费下载链接】Folcolor Windows explorer folder coloring utility 项目地址: https://gitcode.com/gh_mirrors/fo/Folcolor 想象一下这样的场景:你的电…...

如何快速获取网易云QQ音乐歌词:3大场景解决你的本地音乐无歌词困扰
如何快速获取网易云QQ音乐歌词:3大场景解决你的本地音乐无歌词困扰 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为本地音乐播放时没有歌词而烦恼吗&am…...

买服装模板机选中捷、川田、杰克还是慧拿?紧凑型流水线升级,空间与适配才是核心决策
在服装智能制造全面普及的今天,线上模板机已经成为服装企业改造紧凑流水线、实现降本增效的核心装备。当前市场上,中捷、川田、杰克、慧拿四大品牌稳居全球服装自动化设备第一梯队,技术实力、产品品质、品牌口碑均处于行业头部水平。面对 “选…...

从Dubbo超时到内存锯齿:高并发服务JVM调优与大对象排查实战
1. 项目背景与问题初现做后端服务开发,尤其是高并发场景下的核心服务,最怕的就是线上服务“抽风”——平时跑得好好的,一到业务高峰期就出现各种超时、失败。最近我就遇到了一个典型的案例,我们团队负责的一个音乐核心服务&#x…...

如何用Perplexity秒级获取NCBI/UniProt/PDB关联知识?——生物学家正在悄悄使用的4层语义穿透法
更多请点击: https://intelliparadigm.com 第一章:如何用Perplexity秒级获取NCBI/UniProt/PDB关联知识?——生物学家正在悄悄使用的4层语义穿透法 Perplexity 不是传统搜索引擎,而是面向科研语义网络的推理型知识代理。当输入一个…...
!)
AI大模型Agent面试,超详细(附答案)!
AI大模型Agent面试,超详细(➕答案)!假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。 接下来告诉你一条最快的邪修路线, 3个月即可成为模型大师,薪资直接起飞。阶段1:大模型基础阶段2:RA…...