强化学习的基础概念
目录
强化学习的基本概念
state和state space
Action和Action Space
State transition
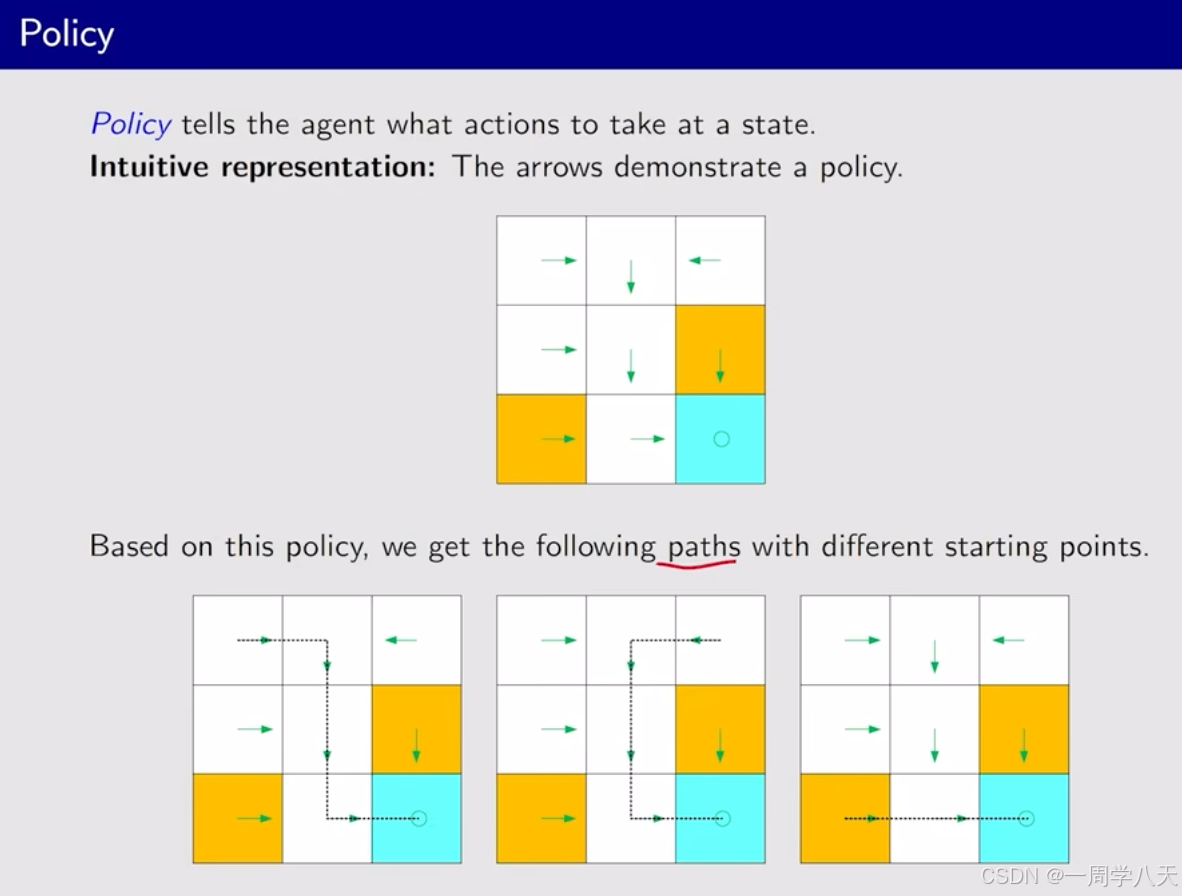
Policy
Reward
trajectory
return的作用:通过一个具体的数值,可以用来形容哪个policy更好。而不是人类直观地感受出来的。
Discounted return
Episode
Markov decision process(MDP)
强化学习的基本概念
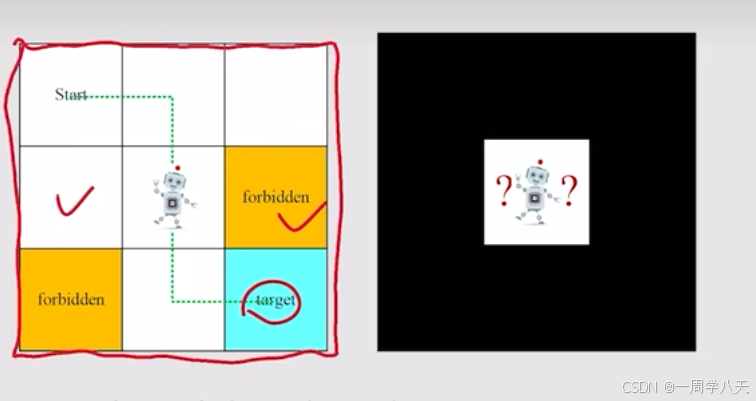
state和state space

Action和Action Space

State transition
- forbidden area可以进入,但是进入这个区域会被惩罚
- forbidden area不可以进去


Policy
Reward
trajectory
return的作用:通过一个具体的数值,可以用来形容哪个policy更好。而不是人类直观地感受出来的。
Discounted return
Episode
- 将target这一个state的所有action选择改为只有一个action选择——就是在这个状态重复(a5) ,还要再讲这里获得的所有reward都设置为0。这样就实现了将target state转换为absorbing state
- 将target state认为是一个普通的状态。然后选择一个策略,如果策略的结果好的话就会一直重复这个策略,不好的话也可以跳出来。
Markov decision process(MDP)
- State:状态集合
- Action:A(s)
- Reward:奖励的集合R(s,a)
- p(s'|s,a)
- p(r|s,a)
相关文章:
强化学习的基础概念
这节课会介绍一些基本的概念,并结合例子讲解。 在马尔科夫决策框架下介绍这些概念 本博客是基于西湖大学强化学习课程的视屏进行笔记的,这是链接: 课程链接 目录 强化学习的基本概念 state和state space Action和Action Space State transiti…...
)
excel怎么删除右边无限列(亲测有效)
excel怎么删除右边无限列(亲测有效) 网上很多只用第1步的,删除了根本没用,还是存在,但是隐藏后取消隐藏却是可以的。 找到右边要删除的列的第一个空白列,选中整个列按“ctrlshift>(向右的小箭头)”&am…...

STM32-笔记23-超声波传感器HC-SR04
一、简介 HC-SR04 工作参数: • 探测距离:2~600cm • 探测精度:0.1cm1% • 感应角度:<15 • 输出方式:GPIO • 工作电压:DC 3~5.5V • 工作电流:5.3mA • 工作温度:-40~85℃ 怎么…...

Linux | Ubuntu零基础安装学习cURL文件传输工具
目录 介绍 检查安装包 下载安装 手册 介绍 cURL是一个利用URL语法在命令行下工作的文件传输工具,首次发行于1997年12。cURL支持多种协议,包括FTP、FTPS、HTTP、HTTPS、TFTP、SFTP、Gopher、SCP、Telnet、DICT、FILE、LDAP、LDAPS、IMAP、POP3…...

什么是 GPT?Transformer 工作原理的动画展示
大家读完觉得有意义记得关注和点赞!!! 目录 1 图解 “Generative Pre-trained Transformer”(GPT) 1.1 Generative:生成式 1.1.1 可视化 1.1.2 生成式 vs. 判别式(译注) 1.2 Pr…...
)
SpringCloudAlibaba实战入门之路由网关Gateway过滤器(十三)
承接上篇,我们知道除了断言,还有一个重要的功能是过滤器,本节课我们就讲一下常见的网关过滤器及其一般使用。 一、Filter介绍 类似SpringMVC里面的的拦截器Interceptor,Servlet的过滤器。“pre”和“post”分别会在请求被执行前调用和被执行后调用,用来修改请求和响应信…...

电路仿真软件PSIM简介
在从事开关电源相关产品开发的工程师或者正在学习开关电源的学习者,常常会用到各种仿真软件进行电路的仿真,不仅可以快速验证电路参数,还能清楚知道各器件的工作状态。 现在的电路仿真软件很多,例如matlab、Multisim、Simplis&…...
C语言:调试的概念和调试器的选择
所谓调试(Dubug),就是跟踪程序的运行过程,从而发现程序的逻辑错误(思路错误),或者隐藏的缺陷(Bug)。 在调试的过程中,我们可以监控程序的每一个细节ÿ…...

25. C++继承 1 (继承的概念与基础使用, 继承的复制兼容规则,继承的作用域)
⭐上篇模板文章:24. C模板 2 (非类型模板参数,模板的特化与模板的分离编译)-CSDN博客 ⭐本篇代码:c学习 橘子真甜/c-learning-of-yzc - 码云 - 开源中国 (gitee.com) ⭐标⭐是比较重要的部分 目录 一. 继承的基础使用 1.1 继承的格式 1.2 …...

git 退出编辑模式
在使用 Git 时,有时需要进入编辑器来输入提交信息或进行其他编辑操作。不同的系统和配置可能会导致使用不同的编辑器。以下是几种常见 Git 编辑器的退出方法: Vim 编辑器: 保存并退出: 按下 Esc 键退出编辑模式。输入 :w…...

内容营销与传统营销方式有哪些差别?
在互联网高度发达的当下,碎片化的信息接收方式,让用户对于营销信息拥有较高的敏感度。这一现状,也使得众多传统营销方式正在逐渐失效。想要稳定推广效率,内容营销是当下不少品牌的共同选择。接下来,就让我们来了解下内…...

EasyExcel(读取操作和填充操作)
文章目录 1.准备Read.xlsx(具有两个sheet)2.读取第一个sheet中的数据1.模板2.方法3.结果 3.读取所有sheet中的数据1.模板2.方法3.结果 EasyExcel填充1.简单填充1.准备 Fill01.xlsx2.无模版3.方法4.结果 2.列表填充1.准备 Fill02.xlsx2.模板3.方法4.结果 …...
】)
【华为OD-E卷 - 机房布局 100分(python、java、c++、js、c)】
【华为OD-E卷 - 机房布局 100分(python、java、c、js、c)】 题目 小明正在规划一个大型数据中心机房,为了使得机柜上的机器都能正常满负荷工作,需要确保在每个机柜边上至少要有一个电箱。 为了简化题目,假设这个机房…...

【竞技宝】LOL:IG新赛季分组被质疑
北京时间2024年12月31日,今天已经2024年的最后一天,在进入一月之后,英雄联盟将迎来全新的2025赛季。而目前新赛季第一阶段的抽签结果已经全部出炉,其中人气最高的IG战队在本次抽签中抽到了“绝世好签”引来了网友们的质疑。 首先介…...

ChatBI来啦!NBAI 正式上线 NL2SQL 功能
NebulaAI 现已正式上线 NL2SQL 功能,免费开放使用! 什么是 NL2SQL?NL2SQL 即通过自然语言交互,用户可以轻松查询、分析和管理数据库中的数据(ChatBI),从此摆脱传统复杂的数据库操作。 欢迎免费…...
)
8. Web应用程序(Web)
8. Web应用程序(Web) Spring Boot 非常适用于Web应用程序开发。你可以使用嵌入式 Tomcat、Jetty、Undertow或Netty创建一个独立的HTTP服务器。大多是Web应用程序都会使用 spring-boot-starter-web 依赖模块来快速启动和运行项目。你也可以选择使用 spri…...

Linux内核修改内存分配策略
今天遇到了如下的内核报错 Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00007f0e1e06c000, 65536, 1) failed; errorCannot allocate memory (errno12)这个报错是因为,linux会对大部分的内存资源申请都回复允许,以便于运行更…...

六大亮点解析:AI视频监控助力部队训练安全管理
一、用户痛点: 在部队的日常训练和任务执行中,官兵的安全始终是最为重要的保障。然而,传统的监控方式存在显著的局限性,尤其是在高强度、长时间的训练过程中,人工值守监控容易产生疲劳,误判的风险大&#…...

【从零开始入门unity游戏开发之——C#篇33】C#委托(`Delegate`)和事件(`event` )、事件与委托的区别、Invoke()的解释
文章目录 一、委托(Delegate)1、什么是委托?2、委托的基本语法3、定义自定义委托4、如何使用自定义委托5、多播委托6、C# 中的系统委托7、GetInvocationList 获取多个函数返回值8、总结 二、事件(event )1、事件是什么…...

大数据与机器学习(它们有何关系?)
想了解大数据和机器学习吗?我们将为你解释它们是什么、彼此之间有何关联,以及它们为何在数据密集型应用中如此重要。 大数据和机器学习是如何相互关联的? 大数据指的是传统存储方法无法处理的海量数据。机器学习则是计算机系统从观察结果和…...

为内部工具集成大模型能力时如何选择与接入 Taotoken
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部工具集成大模型能力时如何选择与接入 Taotoken 在企业内部开发数据分析、客服助手、代码生成等工具时,引入大模型…...

APK Installer:Windows平台上无缝安装Android应用的技术实现与实战指南
APK Installer:Windows平台上无缝安装Android应用的技术实现与实战指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾在Windows电脑上想要运行某…...

Claude Code cli 以及vscode版本的各种命令参考手册
Claude Code 各种命令参考手册版本说明: 截至 2026 年 4 月,Claude Code 官方文档共收录超过 70 条内置命令与绑定技能。其中约一半为内置命令(行为由 CLI 代码实现),另一半为绑定技能(通过 Prompt 机制实现…...

5分钟掌握FanControl:Windows风扇控制终极指南,告别噪音与过热烦恼
5分钟掌握FanControl:Windows风扇控制终极指南,告别噪音与过热烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode…...

STM32CUBEMX+Keil AC6编译提速实战:解决LWIP和绝对地址警告的坑
STM32CUBEMXKeil AC6编译提速实战:解决LWIP和绝对地址警告的坑 当STM32开发者从Keil AC5编译器切换到AC6时,往往会遇到两个典型问题:LWIP编译错误和绝对地址警告。本文将深入分析这些问题的根源,并提供经过验证的解决方案…...
)
OpenClaw 接入 DeepSeek 模型完整配置教程(2026 最新版)
OpenClaw 接入 DeepSeek 模型完整配置教程 一、前置准备 已安装并正常运行 OpenClaw Windows 客户端;OpenClaw 顶部 Gateway 状态保持在线;电脑网络正常,可稳定访问 DeepSeek 开放平台;准备可接收验证码的手机号或微信账号&…...

Nginx、Tengine、OpenRestry的http和tcp后端健康检查【20260520-003篇】
文章目录 一、Nginx 开源版(无第三方模块) 1. 被动健康检查(内置,默认) TCP 后端(stream 四层) HTTP 后端(http 七层) 2. Nginx + 第三方模块(主动检查) 编译 Nginx 加模块 HTTP 主动检查 TCP 主动检查 二、Tengine(原生带主动检查) HTTP 健康检查 TCP 健康检查 查…...

Redis分布式锁进阶第六十一篇
一、本篇前置衔接 第九十二篇我们完成Redisson源码拆解、手写复刻、底层内核穿透,彻底明白分布式锁代码层、脚本层、线程层原理。到此为止,代码、源码、坑点、运维、监控、面试全部讲透。但很多开发最大的困惑依旧存在:不同体量公司为什么锁架…...

用Tableau分析酒店数据:手把手教你做地区均价条形图和价格等级饼图
用Tableau分析酒店数据:手把手教你做地区均价条形图和价格等级饼图 酒店行业的数据分析往往需要快速洞察不同地区的价格分布和消费层级特征。作为全球领先的商业智能工具,Tableau能以直观的可视化方式呈现这些关键指标。本文将带你从零开始,用…...

从DJI N3到PX4:高飞老师组px4ctrl状态机实战解析与避坑指南
从DJI N3到PX4:状态机设计与控制逻辑迁移实战指南 在无人机飞控系统开发领域,状态机设计一直是核心难点之一。当开发者需要从DJI N3平台迁移到PX4生态时,控制逻辑的差异往往成为最大的技术障碍。本文将深入解析两种平台的状态机实现差异&…...