预训练深度双向 Transformers 做语言理解
大家读完觉得有意义记得关注和点赞!!!
与 GPT 一样,BERT 也基于 transformer 架构, 从诞生时间来说,它位于 GPT-1 和 GPT-2 之间,是有代表性的现代 transformer 之一, 现在仍然在很多场景中使用,
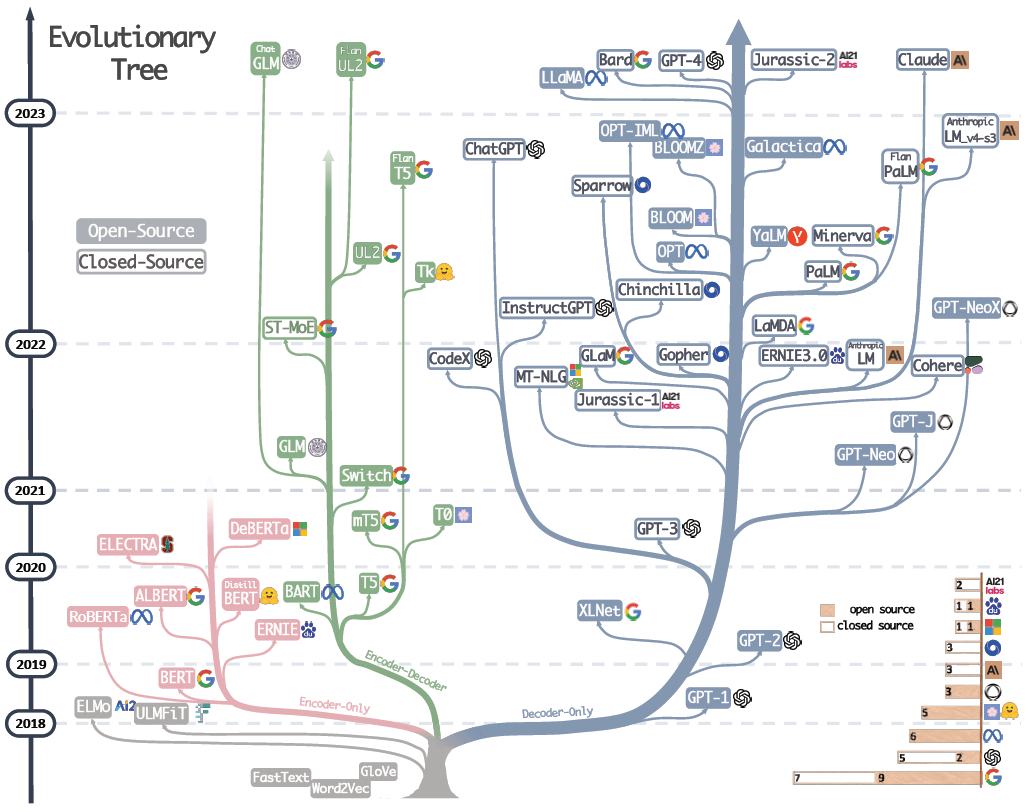
大模型进化树,可以看到 BERT 所处的年代和位置。来自 大语言模型(LLM)综述与实用指南(Amazon,2023)。
根据 Transformer 是如何工作的:600 行 Python 代码实现 self-attention 和两类 Transformer(2019), BERT 是首批 在各种自然语言任务上达到人类水平的 transformer 模型之一。 预训练和 fine-tuning 代码:github.com/google-research/bert。
BERT 模型只有 0.1b ~ 0.3b 大小,因此在 CPU 上也能较流畅地跑起来。
目录
摘要
1 引言
1.1 Pre-trained model 适配具体下游任务的两种方式
1.2 以 OpenAI GPT 为代表的单向架构存在的问题
1.3 BERT 创新之处
1.4 本文贡献
2 相关工作
2.1 无监督基于特征(Unsupervised Feature-based)的方法
2.2 无监督基于微调(Unsupervised Fine-tuning)的方法
2.3 基于监督数据的转移学习(Transfer Learning from Supervised Data)
3 BERT
3.0 BERT 架构
3.0.1 BERT 模型架构和参数
3.0.2 输入/输出表示
3.1 预训练 BERT
3.1.1 任务 :掩码语言模型(Masked LM)#1
3.1.2 任务 :下一句预测(Next Sentence Prediction, NSP)#2
3.1.3 预训练数据集
3.2 微调 BERT
3.3 各种场景
4 实验
4.1 GLUE(一般语言理解评估)
4.1.1 Fine-tune 工作
4.1.2 参数设置
4.1.3 结果
4.2 SQuAD(斯坦福问答数据集)v1.1
4.3 SQuAD v2.0
4.4 SWAG(对抗性世代的情况)
5 对照研究
5.1 预训练任务(MLM/NSP)的影响
5.1.1 训练组
5.1.2 结果对比
5.1.3 与 ELMo 的区别
5.2 模型大小的影响
5.3 BERT 基于特征的方式
5.3.1 基于特征的方式适用的场景
5.3.2 实验
5.3.3 结果
6 总结
附录
A. BERT 的其他详细信息
A.1 训练前任务示例
A.2 训练前程序
A.3 微调程序
A.4 BERT、ELMo 和 OpenAI GPT 的比较
A.5 对不同任务进行微调的插图
B. 详细的实验设置
C. 其他消融研究
参考文献
摘要
本文提出 BERT(Bidirectional Encoder Representations from Transformers, 基于 Transformers 的双向 Encoder 表示) —— 一种新的语言表示模型 (language representation model)。
- 与最近的语言表示模型(Peters 等,2018a; Radford 等,2018)不同, BERT 利用了所有层中的左右上下文(both left and right context in all layers), 在无标签文本(unlabeled text)上 预训练深度双向表示(pretrain deep bidirectional representations)。
- 只需添加一个额外的输出层,而无需任何 task-specific 架构改动,就可以对预训练的 BERT 模型进行微调, 创建出用于各种下游任务(例如问答和语言推理)的高效模型。
BERT 在概念上很简单,实际效果却很强大,在 11 个自然语言处理任务中刷新了目前业界最好的成绩,包括,
- GLUE score to 80.5% (7.7% point absolute improvement)
- MultiNLI accuracy to 86.7% (4.6% absolute improvement)
- SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement)
- SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement)
1 引言
业界已证明,语言模型预训练(Language model pre-training) 能显著提高许多自然语言处理(NLP)任务的效果(Dai 和 Le,2015; Peters 等,2018a; Radford 等,2018; Howard 和 Ruder,2018)。 这些任务包括:
sentence-level tasks:例如自然语言推理(Bowman 等,2015; Williams 等,2018);paraphrasing(Dolan 和 Brockett,2005):整体分析句子来预测它们之间的关系;token-level tasks:例如 named entity recognition 和问答,其模型需要完成 token 级别的细粒度输出(Tjong Kim Sang 和 De Meulder,2003; Rajpurkar 等,2016)。
1.1 Pre-trained model 适配具体下游任务的两种方式
将预训练之后的语言表示(pre-trained language representations)应用到下游任务,目前有两种策略:
- 基于特征的方式(feature-based approach):例如
ELMo(Peters 等,2018a),使用任务相关的架构,将预训练表示作为附加特征。 - 微调(fine-tuning):例如
Generative Pre-trained Transformer(OpenAIGPT)(Radford 等,2018), 引入最少的 task-specific 参数,通过微调所有预训练参数来训练下游任务。
这两种方法都是使用单向语言模型来学习通用语言表示。
1.2 以 OpenAI GPT 为代表的单向架构存在的问题
我们认为,以上两种方式(尤其是微调)限制了 pre-trained language representation 的能力。 主要是因为其语言模型是单向的,这限制了预训练期间的架构选择范围。
例如,OpenAI GPT 使用从左到右的架构(Left-to-Right Model, LRM),因此 Transformer self-attention 层中的 token 只能关注它前面的 tokens(只能用到前面的上下文):
- 对于句子级别的任务,这将导致次优结果;
- 对 token 级别的任务(例如问答)使用 fine-tuning 方式效果可能非常差, 因为这种场景非常依赖双向上下文(context from both directions)。
1.3 BERT 创新之处
本文提出 BERT 来改进基于微调的方式。
受 Cloze(完形填空)任务(Taylor,1953)启发,BERT 通过一个“掩码语言模型”(masked language model, MLM)做预训练, 避免前面提到的单向性带来的问题,
- MLM 随机掩盖输入中的一些 token ,仅基于上下文来预测被掩盖的单词(单词用 ID 表示)。
- 与从左到右语言模型的预训练不同,MLM 能够同时利用左侧和右侧的上下文, 从而预训练出一个深度双向 Transformer。
除了掩码语言模型外,我们还使用“下一句预测”(next sentence prediction, NSP) 任务来联合预训练 text-pair representation。
1.4 本文贡献
- 证明了双向预训练对于语言表示的重要性。 与 Radford 等(2018)使用单向模型预训练不同,BERT 使用掩码模型来实现预训练的深度双向表示。 这也与 Peters 等(2018a)不同,后者使用独立训练的从左到右和从右到左的浅连接。
- 展示了 pre-trained representations 可以减少对许多 task-specific 架构的重度工程优化。 BERT 是第一个在大量 sentence-level 和 token-level 任务上达到了 state-of-the-art 性能的 基于微调的表示模型,超过了许多 task-specific 架构。
- BERT 刷新了 11 个自然语言处理任务的最好性能。
代码和预训练模型见 github.com/google-research/bert。
2 相关工作
(这节不是重点,不翻译了)。
There is a long history of pre-training general language representations, and we briefly review the most widely-used approaches in this section.
2.1 无监督基于特征(Unsupervised Feature-based)的方法
Learning widely applicable representations of words has been an active area of research for decades, including non-neural (Brown et al., 1992; Ando and Zhang, 2005; Blitzer et al., 2006) and neural (Mikolov et al., 2013; Pennington et al., 2014) methods. Pre-trained word embeddings are an integral part of modern NLP systems, offering significant improvements over embeddings learned from scratch (Turian et al., 2010). To pretrain word embedding vectors, left-to-right language modeling objectives have been used (Mnih and Hinton, 2009), as well as objectives to discriminate correct from incorrect words in left and right context (Mikolov et al., 2013).
These approaches have been generalized to coarser granularities, such as
sentence embeddings(Kiros et al., 2015; Logeswaran and Lee, 2018)paragraph embeddings(Le and Mikolov, 2014).
To train sentence representations, prior work has used objectives to rank candidate next sentences (Jernite et al., 2017; Logeswaran and Lee, 2018), left-to-right generation of next sentence words given a representation of the previous sentence (Kiros et al., 2015), or denoising autoencoder derived objectives (Hill et al., 2016).
ELMo and its predecessor (Peters et al., 2017, 2018a) generalize traditional word embedding research along a different dimension. They extract context-sensitive features from a left-to-right and a right-to-left language model. The contextual representation of each token is the concatenation of the left-to-right and right-to-left representations. When integrating contextual word embeddings with existing task-specific architectures, ELMo advances the state of the art for several major NLP benchmarks (Peters et al., 2018a) including
- question answering (Rajpurkar et al., 2016)
- sentiment analysis (Socher et al., 2013)
- named entity recognition (Tjong Kim Sang and De Meulder, 2003)
Melamud et al. (2016) proposed learning contextual representations through a task to predict a single word from both left and right context using LSTMs. Similar to ELMo, their model is feature-based and not deeply bidirectional. Fedus et al. (2018) shows that the cloze task can be used to improve the robustness of text generation models.
2.2 无监督基于微调(Unsupervised Fine-tuning)的方法
As with the feature-based approaches, the first works in this direction only pre-trained word embedding parameters from unlabeled text (Collobert and Weston, 2008).
More recently, sentence or document encoders which produce contextual token representations have been pre-trained from unlabeled text and fine-tuned for a supervised downstream task (Dai and Le, 2015; Howard and Ruder, 2018; Radford et al., 2018). The advantage of these approaches is that few parameters need to be learned from scratch.
At least partly due to this advantage, OpenAI GPT (Radford et al., 2018) achieved previously state-of-the-art results on many sentencelevel tasks from the GLUE benchmark (Wang et al., 2018a). Left-to-right language model ing and auto-encoder objectives have been used for pre-training such models (Howard and Ruder, 2018; Radford et al., 2018; Dai and Le, 2015).
2.3 基于监督数据的转移学习(Transfer Learning from Supervised Data)
There has also been work showing effective transfer from supervised tasks with large datasets, such as natural language inference (Conneau et al., 2017) and machine translation (McCann et al., 2017).
Computer vision research has also demonstrated the importance of transfer learning from large pre-trained models, where an effective recipe is to fine-tune models pre-trained with ImageNet (Deng et al., 2009; Yosinski et al., 2014).
3 BERT
本节介绍 BERT 架构及实现。训练一个可用于具体下游任务的 BERT 模型,分为两个步骤:
- 预训练:使用不带标签的数据进行训练,完成多种不同的预训练任务。
- 微调:首先使用预训练参数进行初始化,然后使用下游任务的数据对所有参数进行微调。 每个下游任务最终都得到一个独立的微调模型。
3.0 BERT 架构
图 1 是一个问答场景的训练+微调,我们以它为例子讨论架构:
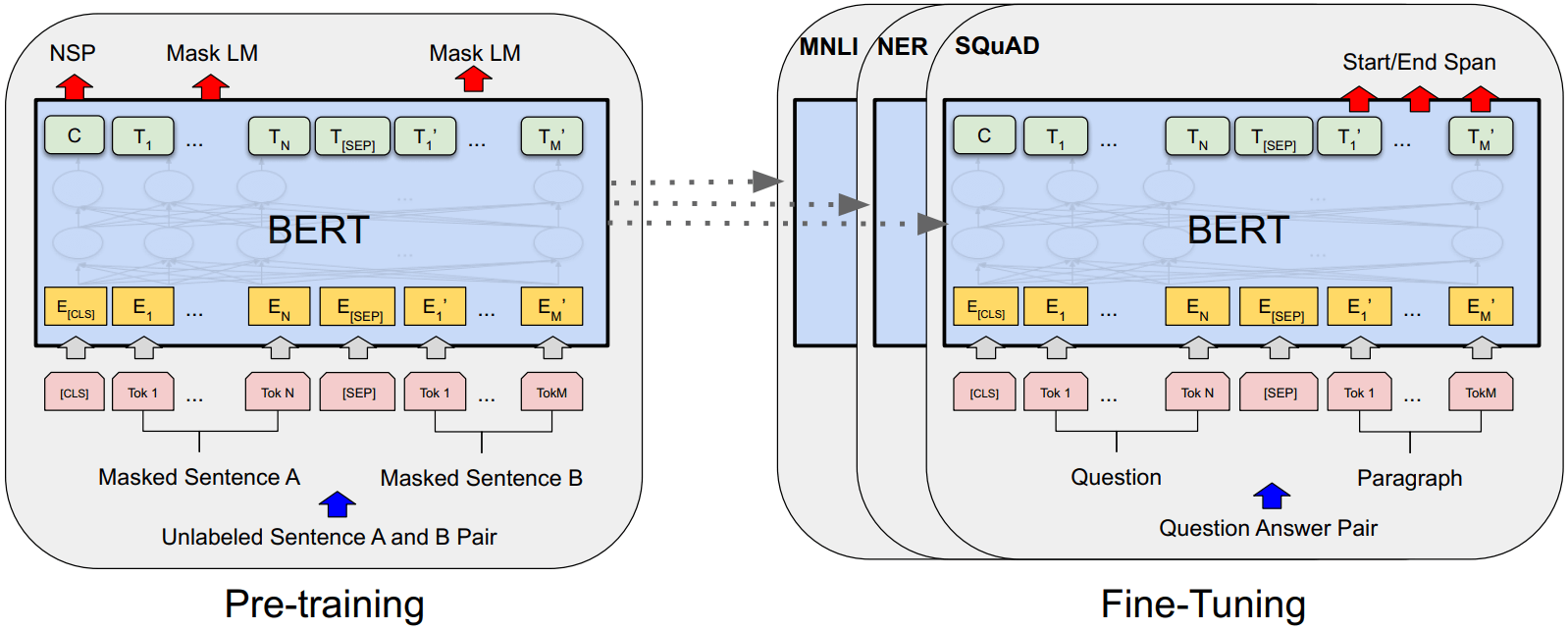
Figure 1: BERT pre-training 和 fine-tuning 过程。 预训练模型和微调模型的输出层不一样,除此之外的架构是一样的。
左:用无标注的句子进行预训练,得到一个基础模型(预训练模型)。
右:用同一个基础模型作为起点,针对不同的下游任务进行微调,这会影响模型的所有参数。[CLS] 是加到每个输入开头的一个特殊 token; [SEP] 是一个特殊的 separator token (e.g. separating questions/answers)
BERT 的一个独特之处是针对不同任务使用统一架构。 预训练架构和最终下游架构之间的差异非常小。
3.0.1 BERT 模型架构和参数
我们的实现基于 Vaswani 等(2017)的原始实现和我们的库 tensor2tensor 。 Transformer 大家已经耳熟能详,并且我们的实现几乎与原版相同,因此这里不再对架构背景做详细描述, 需要补课的请参考 Vaswani 等(2017)及网上一些优秀文章,例如 The Annotated Transformer。
本文符号表示,
L层数(i.e., Transformer blocks)H隐藏层大小(embedding size)Aself-attention head 数量
In all cases we set the feed-forward/filter size to be 4H, i.e., 3072 for the H = 768 and 4096 for the H = 1024.
本文主要给出两种尺寸的模型:
- BERTBASE(L=12,H=768,A=12,总参数=
110M),参数与 OpenAI GPT 相同,便于比较; - BERTLARGE(L=24,H=1024,A=16,总参数=
340M)
如果不理解这几个参数表示什么意思,可参考 Transformer 是如何工作的:600 行 Python 代码实现两个(文本分类+文本生成)Transformer(2019)。 译注。
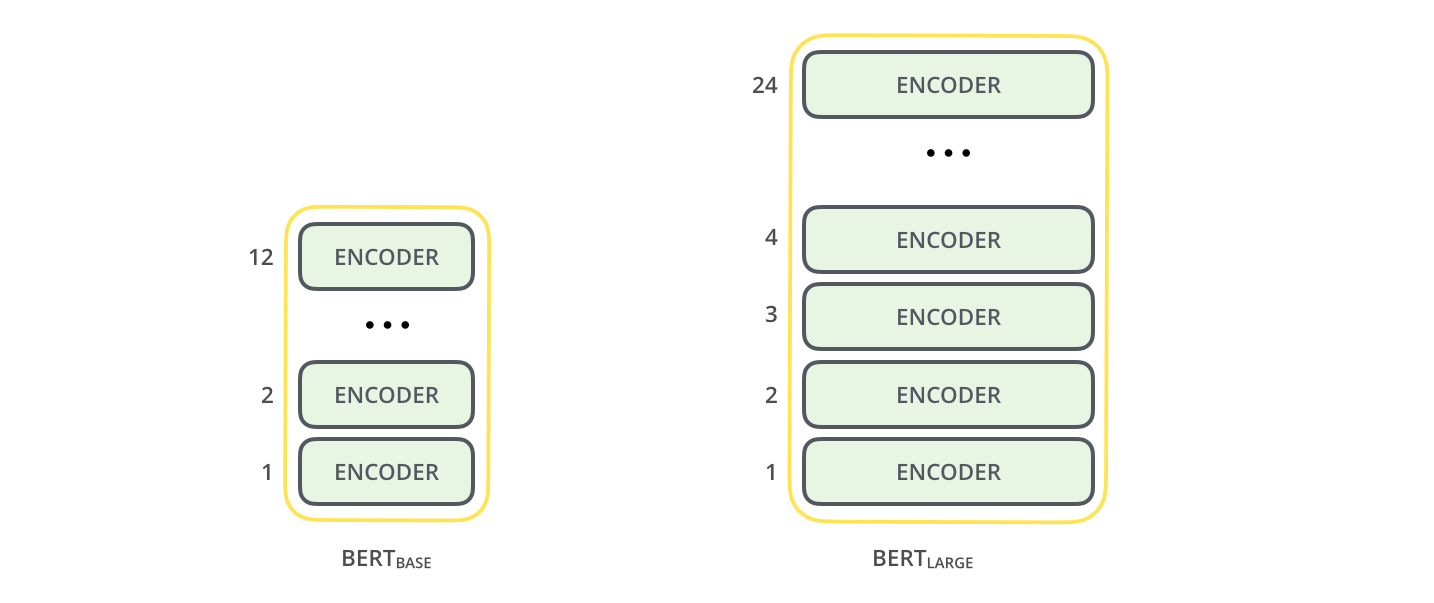
两个 size 的 BERT,图中的 encoder 就是 transformer。译注。图片来源
BERT Transformer 使用双向 self-attention,而 GPT Transformer 使用受限制的 self-attention, 其中每个 token 只能关注其左侧的上下文。
我们注意到,在文献中,
双向 Transformer通常被称为“Transformer 编码器”,而 仅左上下文版本称为“Transformer 解码器”,因为它可用于文本生成。
3.0.2 输入/输出表示
为了使 BERT 能够处理各种下游任务,在一个 token 序列中,我们的输入要能够明确地区分:
- 单个句子(a single sentence)
- 句子对(a pair of sentences)例如,问题/回答。
这里,
- “句子”可以是任意一段连续的文本,而不是实际的语言句子。
- “序列”是指输入给 BERT 的 token 序列,可以是单个句子或两个句子组合在一起。
我们使用 30,000 个词元词汇的 WordPiece 嵌入(Wu et al., 2016)。
这个 vocabulary 长什么样,可以看一下 bert-base-chinese(官方专门针对中文训练的基础模型): bert-base-chinese/blob/main/vocab.txt。 译注。
我们 input/output 设计如下:
-
每个序列的第一个 token 都是特殊的 classification token ;
[CLS]在最终输出中(最上面一行),这个 token (hidden state) 主要用于分类任务, 再接一个分类器就能得到一个分类结果(其他的 tokens 全丢弃),如下图所示,
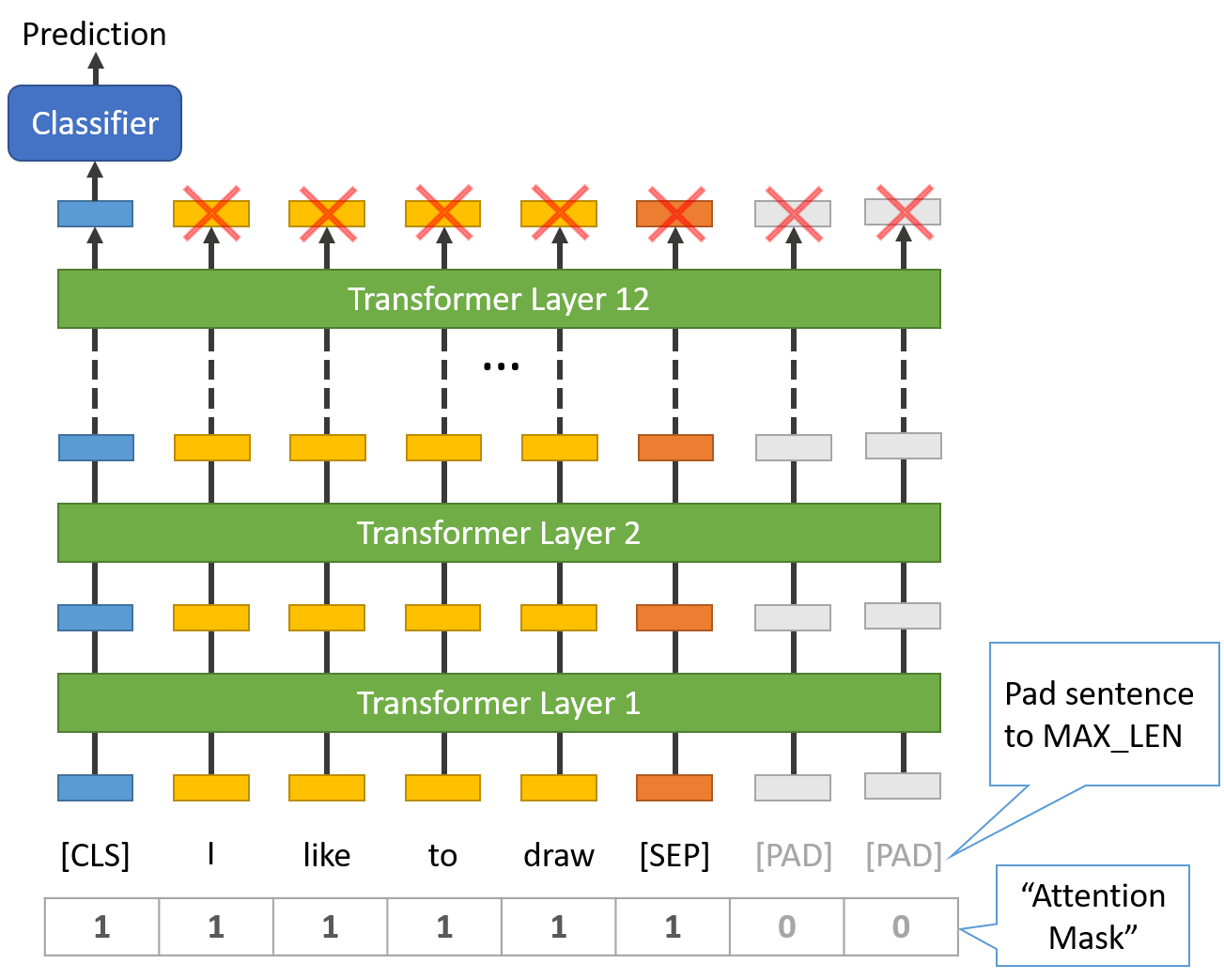
BERT 用于分类任务,classifier 执行 Feed-forward + softmax 操作,译注。图片来源
-
将 sentence-pair 合并成单个序列。通过两种方式区分,
- 使用特殊 token 来分隔句子;
[SEP] - 为每个 token 添加一个学习到的 embedding ,标识它属于句子 A 还是句子 B。
- 使用特殊 token 来分隔句子;
图 1: BERT pre-training 和 fine-tuning 过程。 预训练模型和微调模型的输出层不一样,除此之外的架构是一样的。
左:用无标注的句子进行预训练,得到一个基础模型(预训练模型)。
右:用同一个基础模型作为起点,针对不同的下游任务进行微调,这会影响模型的所有参数。[CLS] 是加到每个输入开头的一个特殊 token;[SEP] 是一个特殊的 separator token(例如,分隔问题/答案)
再回到图 1 所示,我们将
-
输入 embedding 表示为E,
对于给定的 token ,它的输入表示是通过将 3 个 embeddings 相加来构建的,如图 2,
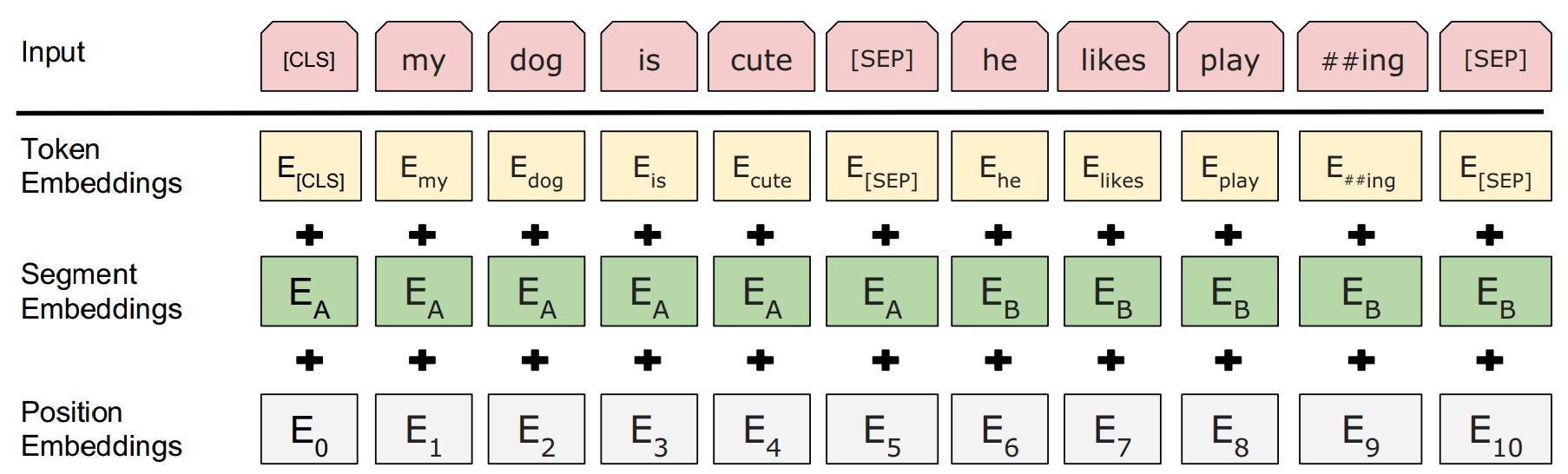
图 2:BERT 输入表示。
- token embedding:输入文本经过 tokenizer 之后得到的输出;
- segment embedding:表示 token embedding 在这个位置的 token 是属于句子 A 还是句子 B;
- position embedding:token 在 token embedding 中的位置,,因为 BERT 最长支持 512 token 输入(除非自己从头开始预训练,可以改参数)。
0,1,2,3...,511
- 第 i 个输入 token 的在最后一层的表示(最终隐藏向量)为我T我,。T我∈ℝH
[CLS]token 在最后一层的表示(最终隐藏向量)为C, C \in \mathbb{R}^{H} ,C∈ℝH
3.1 预训练 BERT
图 1 的左侧部分。
Figure 1: BERT 的 pre-training 和 fine-tuning 过程。
与 Peters 等(2018a)和 Radford 等(2018)不同,我们不使用传统的从左到右或从右到左的模型来预训练 BERT, 而是用下面两个无监督任务(unsupervised tasks)来预训练 BERT。
3.1.1 任务 :掩码语言模型(Masked LM)#1
从直觉上讲,深度双向模型比下面两个模型都更强大:
- 从左到右的单向模型(LRM);
- 简单拼接(shallow concatenation)了一个左到右模型(LRM)与右到左模型(RLM)的模型。
不幸的是,标准的条件语言模型(conditional language models)只能从左到右或从右到左进行训练, 因为 bidirectional conditioning 会使每个单词间接地“看到自己”,模型就可以轻松地在 multi-layered context 中预测目标词。
为了训练一个深度双向表示,我们简单地随机屏蔽一定比例的输入 tokens, 然后再预测这些被屏蔽的 tokens。 我们将这个过程称为“掩码语言模型”(MLM) —— 这种任务通常也称为 Cloze(完形填空)(Taylor,1953)。
在所有实验中,我们随机屏蔽每个序列中 15% 的 token。 与 denoising auto-encoders(Vincent 等,2008)不同,我们只预测被屏蔽的单词,而不是重建整个输入。
这种方式使我们获得了一个双向预训练模型,但造成了预训练和微调之间的不匹配, 因为微调过程中不会出现 [MASK] token。 为了减轻这个问题,我们并不总是用 token 替换“掩码”单词: 训练数据生成器(training data generator)随机选择 15%的 token positions 进行预测。 如果选择了第 i 个 token ,我们将第 i 个 token 用以下方式替换:[MASK]
- 80% 的概率用
[MASK]token 替换, - 10% 的概率用
随机token 替换, - 10% 的概率
保持不变。
然后,使用 来预测原始 token ,并计算交叉熵损失(cross entropy loss)。 附录 C.2 中比较了这个过程的几个变种。Ti
3.1.2 任务 :下一句预测(Next Sentence Prediction, NSP)#2
许多重要的下游任务,如问答(Question Answering, QA) 和自然语言推理(Natural Language Inference, NLI) 都基于理解两个句子之间的关系, 而语言建模(language modeling)并无法直接捕获这种关系。
为了训练一个能理解句子关系的模型,我们预先训练了一个二元的下一句预测任务(a binarized next sentence prediction task): 给定两个句子 A 和 B,判断 B 是不是 A 的下一句。
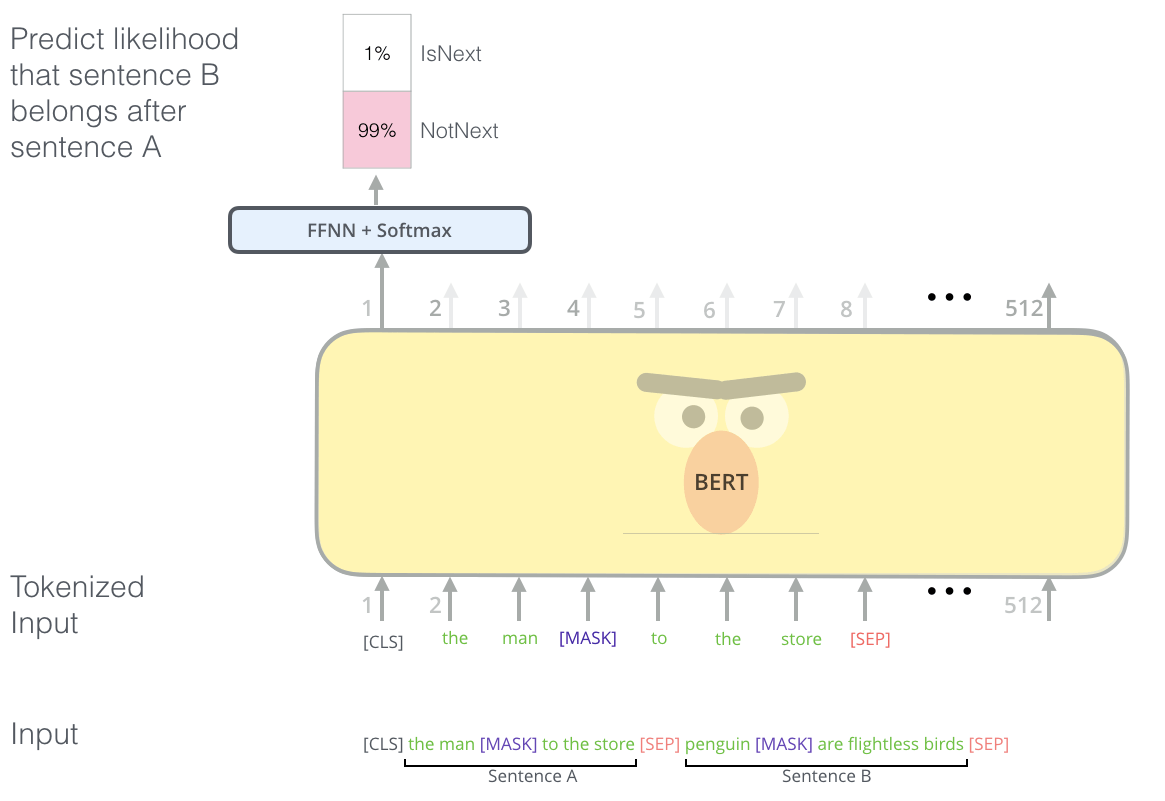
BERT 用于“下一句预测”(NSP)任务,译注。Image Source
这个任务可以用任何单语语料库(monolingual corpus),具体来说,在选择每个预训练示例的句子 A 和 B 时,
- 50%的概率 B 是 A 的下一个句子(labeled as
IsNext), - 50%的概率 B 是语料库中随机一个句子(labeled as
NotNext)。
再次回到图 1, 这个 yes/no 的判断还是通过 classifier token 的最终嵌入向量 C 预测的,
Figure 1: BERT pre-training 和 fine-tuning 过程。 预训练模型和微调模型的输出层不一样,除此之外的架构是一样的。
左:用无标注的句子进行预训练,得到一个基础模型(预训练模型)。
右:用同一个基础模型作为起点,针对不同的下游任务进行微调,这会影响模型的所有参数。[CLS] 是加到每个输入开头的一个特殊 token; [SEP] 是一个特殊的 separator token (e.g. separating questions/answers)
最终我们的模型达到了 97~98% 的准确性。 尽管它很简单,但我们在第 5.1 节中证明,针对这个任务的预训练对于 QA 和 NLI 都非常有益。
The vector C is not a meaningful sentence representation without fine-tuning, since it was trained with NSP。
NSP 任务与 Jernite 等(2017)和 Logeswaran 和 Lee(2018)使用的 representation learning 有紧密关系。 但是他们的工作中只将句子 embedding 转移到了下游任务,而 BERT 是将所有参数都转移下游,初始化微调任务用的初始模型。
3.1.3 预训练数据集
预训练过程跟其他模型的预训练都差不多。对于预训练语料库,我们使用了
- BooksCorpus (800M words) (Zhu et al., 2015)
- English Wikipedia (2,500M words)。只提取文本段落,忽略列表、表格和标题。
使用文档语料库而不是像 Billion Word Benchmark(Chelba 等,2013) 这样的 shuffled sentence-level 语料库非常重要,因为方便提取长连续序列。
3.2 微调 BERT
Transformer 中的 self-attention 机制允许 BERT 对任何下游任务建模 —— 无论是 single text 还是 text pairs —— 只需要适当替换输入和输出,因此对 BERT 进行微调是非常方便的。
对于 text-pair 类应用,一个常见的模式是在应用 bidirectional cross attention 之前,独立编码 text-pair ,例如 Parikh 等(2016);Seo 等(2017)。
但 BERT 使用 self-attention 机制来统一预训练和微调这两个阶段,因为使用 self-attention 对 concatenated text-pair 进行编码, 有效地包含了两个句子之间的 bidirectional cross attention。
对于每个任务,只需将任务特定的输入和输出插入到 BERT 中,并对所有参数进行端到端的微调。 预训练阶段,input 句子 A 和 B 的关系可能是:
- 句子对
- 蕴含中的假设-前提对
- 问答中的问答对
- 文本分类或序列打标(sequence tagging)中的 degenerate 。
text-? pair
在输出端,
- 普通 token representations 送到 token-level 任务的输出层,例如 sequence tagging 或问答,
[CLS]token representation 用于分类,例如 entailment or sentiment analysis。
与预训练相比,微调的成本相对较低。从完全相同的预训练模型开始, 本文中所有结果都可以在最多 1 小时内在单个 Cloud TPU 上复制,或者在 GPU 上几个小时内。 第 4 节会介绍一些细节。更多细节见附录 A.5。
3.3 各种场景

图 4.BERT 用于不同任务场景,来自 paper 附录。
(a) 句子对分类;(b) 单句分类;(c) 问答;(d) 单句打标。
4 实验
在本节中,我们展示了 11 个 NLP 任务的 BERT 微调结果。
4.1 GLUE(一般语言理解评估)
GLUE benchmark (Wang et al., 2018a) 是一个自然语言理解任务集, 更多介绍见 Appendix B.1。
4.1.1 Fine-tune 工作
针对 GLUE 进行 fine-tune 所做的工作:
- 用第 3 节介绍的方式表示 input sequence (for single sentence or sentence pairs)
- 用
final hidden vector C判断类别; - fine-tuning 期间增加的唯一参数 是分类层的权重 W \in \mathbb{R}^{K \times H},其中 K 是 labels 数量。 我们用 C 和 W 计算一个标准的分类损失,例如 \log({\rm softmax}(CW^T)))。W∈ℝK×HKCW日志(softm一个X(CWT))
4.1.2 参数设置
- 批量大小 32
- 3 个 epoch
- 学习率:对于每个任务,我们选择了最佳的微调学习率 (在
5e-5、4e-5、3e-5 和 2e-5中)在 Dev 集中。
另外,我们发现 BERTLARGE 在小数据集上 finetuning 有时候不稳定, 所以我们会随机重启几次,从得到的模型中选效果最好的。 随机重启使用相同的 pre-trained checkpoint 但使用不同的数据重排和分类层初始化 (data shuffling and classifier layer initialization)。
4.1.3 结果
结果如 Table 1 所示,
| 系统 | MNLI-(米/毫米) | QQP的 | QNLI | SST-2 型 | 可乐 | STS-B 系列 | MRPC | 即食 | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| 392 千米 | 363 千米 | 108 千米 | 67 千米 | 8,5 千米 | 5,7 千米 | 3,5 千米 | 2,5 千米 | - | |
| OpenAI SOTA 之前 | 80.6/80.1 | 66.1 | 82.3 | 93.2 | 35.0 | 81.0 | 86.0 | 61.7 | 74.0 |
| BiLSTM+ELMo+Attn | 76.4/76.1 | 64.8 | 79.8 | 90.4 | 36.0 | 73.3 | 84.9 | 56.8 | 71.0 |
| OpenAI GPT | 82.1/81.4 | 70.3 | 87.4 | 91.3 | 45.4 | 80.0 | 82.3 | 56.0 | 75.1 |
| 伯特贝斯 | 84.6/83.4 | 71.2 | 90.5 | 93.5 | 52.1 | 85.8 | 88.9 | 66.4 | 79.6 |
| BERTLARGE 公司 | 86.7/85.9 | 72.1 | 92.7 | 94.9 | 60.5 | 86.5 | 89.3 | 70.1 | 82.1 |
表 1:GLUE 测试结果,由评估服务器评分 (https://gluebenchmark.com/leaderboard)。 每个任务下方的数字表示训练样本的数量。“Average” 列略有不同 比官方 GLUE 分数,因为我们排除了有问题的 WNLI 集.8 BERT 和 OpenAI GPT 是单模型、单任务。报告 QQP 和 MRPC 的 F1 分数,报告 STS-B 的 Spearman 相关性,并报告其他任务的准确性分数。我们排除了使用 BERT 作为其组件之一的条目。
双 BERTBASE 和 BERTLARGE 在所有任务上的性能都大大优于所有系统,获得 与之前的最新技术相比,平均精度分别提高了 4.5% 和 7.0%。请注意, BERTBASE 和 OpenAI GPT 几乎相同 在模型架构方面,除了注意力掩盖之外。对于最大和最广泛的 上报的 GLUE 任务、MNLI、BERT 获得 4.6% 绝对精度提升。在官方 GLUE 排行榜,BERTLARGE 获得分数 80.5,而 OpenAI GPT 获得 72.8 截至撰写之日。
我们发现 BERTLARGE 在所有任务中都明显优于 BERTBASE,尤其是那些 训练数据非常少。模型的作用 size 在 Section 5.2 中进行了更彻底的探讨。
4.2 SQuAD(斯坦福问答数据集)v1.1
SQuAD v1.1 包含了 100k 个众包问题/答案对(Rajpurkar 等人, 2016). 给定一个问题和一段来自 维基百科包含答案,任务是 预测文章中的答案文本跨度。
如图 1 所示,在问答任务中, 我们将输入的问题和段落表示为单个打包序列,问题使用 A 嵌入,段落使用 B 嵌入。在微调过程中,我们只引入了一个起始向量 S \in \mathbb{R}^H 和一个结束向量 E \in \mathbb{R}^H。 单词 i 作为答案范围开头的概率计算为 T_i 和 S 之间的点积,后跟段落中所有单词的软最大值:P_i = \frac{e^{S{\cdot}T_i}}{\sum_j e^{S{\cdot}T_j}}。类似公式用于答案 span 的结尾。从位置 i 到位置 j 的候选跨度的分数定义为 S{\cdot}T_i + E{\cdot}T_j,其中 j \geq i 用作预测的最大分数跨度。训练目标是正确开始和结束位置的对数似然之和。我们微调了 3 个 epoch,学习率为 5e-5,批量大小为 32。一个BS∈ℝHE∈ℝH我T我SP我=eS⋅T我∑jeS⋅Tj我jS⋅T我+E⋅TjJ≥i
表 2 还显示了排行榜上排名靠前的条目 作为顶级已发表系统的结果(Seo 等人, 2017;Clark 和 Gardner,2018 年;Peters 等人, 2018 年a;胡等人,2018 年)。
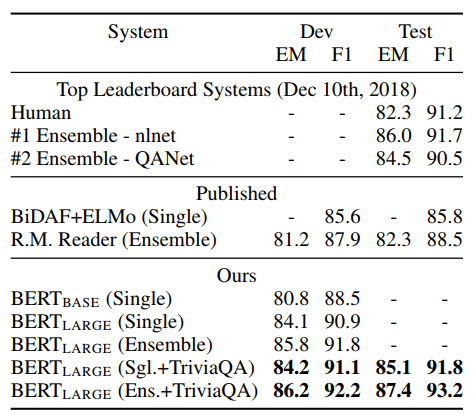
表 2:SQuAD 1.1 结果。BERT 集成 是 7x 系统,它们使用不同的预训练检查点和微调种子。
排名靠前的结果来自 SQuAD 排行榜没有最新的公共 系统描述可用,11 并且允许 在训练他们的系统时使用任何公共数据。 因此,我们在 我们的系统首先在 TriviaQA (Joshi et al., 2017)进行微调。 我们表现最好的系统优于顶级系统 排行榜系统增加 +1.5 F1 在 ensembling 和 +1.3 F1 作为单个系统。事实上,我们的单个 BERT 模型在 F1 分数方面优于顶级集成系统。没有 TriviaQA 罚款 - 调整数据,我们只损失了 0.1-0.4 F1,仍然大大优于所有现有系统12。
4.3 SQuAD v2.0
SQuAD 2.0 任务扩展了 SQuAD 1.1 通过允许可能性来定义问题 提供的段落中不存在简短的答案,这使得问题更加现实。 我们使用一种简单的方法来扩展 SQuAD v1.1 BERT 模型。我们将没有答案的问题视为具有答案跨度,其 start 和 end 位于 [CLS] 令牌处。开始和结束的概率空间 答案 span 位置扩展为包括 [CLS] 令牌的位置。
为了进行预测,我们将无答案范围的分数:s_{\tt null} = S{\cdot}C + E{\cdot}C 与最佳非空范围的分数 \hat{s_{i,j}} = {\tt max}_{j \geq i} S{\cdot}T_i + E{\cdot}T_j。 我们预测当 \hat{s_{i,j}} > s_{\tt null} + \tau 时,我们会得到一个非空的答案, 其中,阈值 \tau 在 dev set 上被选中以最大化 F1。我们没有将 TriviaQA 数据用于此模型。我们微调了 2 个 epoch,学习率为 5e-5,批量大小为 48。s你好=S⋅C+E⋅Csi,j^米AXJ≥iS⋅T我+E⋅Tjsi,j^>s你好+ττ
结果与之前的排行榜条目和最高发表的作品(Sun et al., 2018; Wang et al., 2018b)的分析结果如图 3 所示,不包括使用 BERT 作为其组件之一的系统。我们观察到 F1 比 +5.1 以前的 Best 系统。
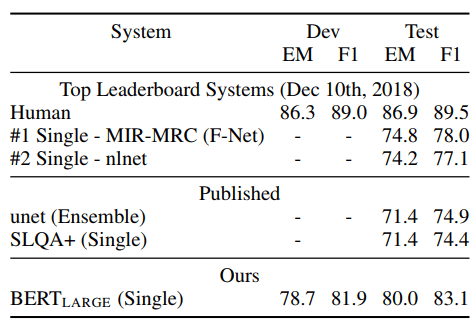
表 3:SQuAD 2.0 结果。我们排除 使用 BERT 作为其组件之一。
4.4 SWAG(对抗性世代的情况)
SWAG 数据集包含 113k 个句子对完成示例,用于评估扎根的常识推理(Zellers et al., 2018)。
给定一个句子,任务是在四个选项中选择最合理的延续。 在 SWAG 数据集上进行微调时,我们 构建四个输入序列,每个序列包含 给定句子的串联 (sentence A) 和可能的延续(句子 B)。这 仅引入特定于任务的参数是一个向量,其点积与 [CLS] 标记表示 C 表示每个选项的分数 该图层使用 SoftMax 图层进行标准化。
我们使用 学习率为 2e-5,batch size 为 16。结果如表 4 所示。
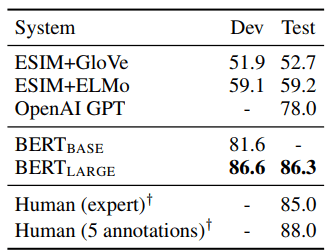
表 4:SWAG 开发和测试的准确性。 正如 SWAG 论文中报道的那样,用 100 个样本来测量人类的表现。
BERTLARGE 的性能比作者的基线 ESIM+ELMo 系统高出 +27.1%,比 OpenAI GPT 高出 8.3%。
5 对照研究
本节研究去掉 BERT 的一些功能,看看在不同任务上性能损失多少,
- 句子级(例如,SST-2)
- 句子对级别(例如,MultiNLI)
- 字级(例如 NER)
- span 级别(例如 SQuAD)
以更好地理解它们的相对重要性。更多相关信息见附录 C。
5.1 预训练任务(MLM/NSP)的影响
5.1.1 训练组
通过以下几组来验证 BERT 深度双向性的重要性,它们使用与 BERTBASE 完全相同的预训练数据、微调方案和超参数:
NO NSP:即去掉“下一句预测”任务,这仍然是一个双向模型,使用“掩码语言模型”(MLM)进行训练,只是训练时不做 NSP 任务;LTR & NO NSP:不仅去掉 NSP,还使用标准的从左到右(Left-to-Right, LTR)模型进行训练,而非使用双向模型。 在微调中也遵从 left-only 约束,否则会导致预训练和微调不匹配,降低下游性能。此外,该模型没有用 NSP 任务进行预训练。 这与 OpenAI GPT 直接可比,但我们使用了更大的训练数据集、我们自己的输入表示和我们的微调方案。+ BiLSTM:在 fine-tuning 期间,在 基础上添加了一个随机初始化的 BiLSTM。LTR & NO NSP
5.1.2 结果对比
结果如表 5,
| Tasks | MNLI-m (Acc) | QNLI (Acc) | MRPC (Acc) | SST-2 (Acc) | SQuAD (F1) |
|---|---|---|---|---|---|
| BERTBASE | 84.4 | 88.4 | 86.7 | 92.7 | 88.5 |
| No NSP | 83.9 | 84.9 | 86.5 | 92.6 | 87.9 |
| LTR & No NSP | 82.1 | 84.3 | 77.5 | 92.1 | 77.8 |
| + BiLSTM | 82.1 | 84.1 | 75.7 | 91.6 | 84.9 |
Table 5: Ablation over the pre-training tasks using the BERTBASE architecture.
分析:
- 第二组 vs 第一组:去掉 NSP 任务带来的影响:在 QNLI、MNLI 和 SQuAD 1.1 上性能显著下降。
-
第三组 vs 第二组:去掉双向表示带来的影响:第二行实际上是 , 可以看出 LTR 模型在所有任务上的表现都比 MLM 模型差,尤其是 MRPC 和 SQuAD。
MLM & NO NSP- 对于 SQuAD,可以清楚地看到 LTR 模型在 token 预测上表现不佳,因为 token 级别的隐藏状态没有右侧上下文。
- 为了尝试增强 LTR 系统,我们在其上方添加了一个随机初始化的双向 LSTM。 这确实在 SQuAD 上改善了结果,但结果仍远远不及预训练的双向模型。另外, 双向 LSTM 降低了在 GLUE 上的性能。
5.1.3 与 ELMo 的区别
ELMo 训练了单独的从左到右(LTR)和从右到左(RTL)模型,并将每个 token 表示为两个模型的串联。 然而:
- 这比单个双向模型训练成本高一倍;
- 对于像 QA 这样的任务,这不直观,因为 RTL 模型将无法 condition the answer on the question;
- 这比深度双向模型弱,因为后者可以在每层使用左右上下文。
5.2 模型大小的影响
为探讨模型大小对微调任务准确性的影响,我们训练了多个 BERT 模型。 表 6 给出了它们在 GLUE 任务上的结果。
| L (层数) | H (hidden size) | A (attention head 数) | LM (ppl) | MNLI-m | MRPC | SST-2 |
| 3 | 768 | 12 | 5.84 | 77.9 | 79.8 | 88.4 |
| 6 | 768 | 3 | 5.24 | 80.6 | 82.2 | 90.7 |
| 6 | 768 | 12 | 4.68 | 81.9 | 84.8 | 91.3 |
| 12 | 768 | 12 | 3.99 | 84.4 | 86.7 | 92.9 |
| 12 | 1024 | 16 | 3.54 | 85.7 | 86.9 | 93.3 |
| 24 | 1024 | 16 | 3.23 | 86.6 | 87.8 | 93.7 |
Table 6: Ablation over BERT model size. “LM (ppl)” is the masked LM perplexity of held-out training data
In this table, we report the average Dev Set accuracy from 5 random restarts of fine-tuning.
可以看到,更大的模型在四个数据集上的准确性都更高 —— 即使对于只有 3,600 个训练示例的 MRPC, 而且这个数据集与预训练任务差异还挺大的。 也许令人惊讶的是,在模型已经相对较大的前提下,我们仍然能取得如此显著的改进。例如,
- Vaswani 等(2017)尝试的最大 Transformer 是(L=6,H=1024,A=16),编码器参数为 100M,
- 我们在文献中找到的最大 Transformer 是(L=64,H=512,A=2),具有 235M 参数(Al-Rfou 等,2018)。
- 相比之下,BERTBASE 包含 110M 参数,BERTLARGE 包含 340M 参数。
业界早就知道,增加模型大小能持续改进机器翻译和语言建模等大规模任务上的性能, 表 6 的 perplexity 列也再次证明了这个结果, 然而,我们认为 BERT 是第一个证明如下结果的研究工作:只要模型得到了充分的预训练, 那么将模型尺寸扩展到非常大时(scaling to extreme model sizes), 对非常小规模的任务(very small scale tasks)也能带来很大的提升(large improvements)。
另外,
- Peters 等(2018b)研究了将 pre-trained bi-LM size(预训练双向语言模型大小)从两层增加到四层,对下游任务产生的影响,
- Melamud 等(2016)提到将隐藏维度从 200 增加到 600 有所帮助,但进一步增加到 1,000 并没有带来更多的改进。
这两项工作都使用了基于特征的方法,而我们则是直接在下游任务上进行微调,并仅使用非常少量的随机初始化附加参数, 结果表明即使下游任务数据非常小,也能从更大、更 expressive 的预训练表示中受益。
5.3 BERT 基于特征的方式
到目前为止,本文展示的所有 BERT 结果都使用的微调方式: 在预训练模型中加一个简单的分类层,针对特定的下游任务对所有参数进行联合微调。
5.3.1 基于特征的方式适用的场景
不过,基于特征的方法 —— 从预训练模型中提取固定特征(fixed features)—— 在某些场景下有一定的优势,
- 首先,不是所有任务都能方便地通过 Transformer encoder 架构表示,因此这些不适合的任务,都需要添加一个 task-specific model architecture。
- 其次,昂贵的训练数据表示(representation of the training data)只预训练一次, 然后在此表示的基础上使用更轻量级的模型进行多次实验,可以极大节省计算资源。
5.3.2 实验
本节通过 BERT 用于 CoNLL-2003 Named Entity Recognition (NER) task (Tjong Kim Sang and De Meulder, 2003) 来比较这两种方式。
- BERT 输入使用保留大小写的 WordPiece 模型,并包含数据提供的 maximal document context。
- 按照惯例,我们将其作为打标任务(tagging task),但在输出中不使用 CRF 层。
- 我们将第一个 sub-token 的 representation 作 token-level classifier 的输入,然后在 NER label set 上进行实验。
为了对比微调方法的效果,我们使用基于特征的方法,对 BERT 参数不做任何微调, 而是从一个或多个层中提取激活(extracting the activations)。 这些 contextual embeddings 作为输入,送给一个随机初始化的 two-layer 768-dimensional BiLSTM, 最后再送到分类层。
5.3.3 结果
结果见表 7。BERTLARGE 与业界最高性能相当,
| System | Dev F1 | Test F1 |
| ELMo (Peters et al., 2018a) | 95.7 | 92.2 |
| CVT (Clark et al., 2018) | - | 92.6 |
| CSE (Akbik et al., 2018) | - | 93.1 |
Fine-tuning approach | ||
| BERTLARGE | 96.6 | 92.8 |
| BERTBASE | 96.4 | 92.4 |
Feature-based approach (BERTBASE) | ||
| Embeddings | 91.0 | - |
| Second-to-Last Hidden | 95.6 | - |
| Last Hidden | 94.9 | - |
| Weighted Sum Last Four Hidden | 95.9 | - |
| Concat Last Four Hidden | 96.1 | - |
| 加权总和所有 12 个图层 | 95.5 | - |
表 7:CoNLL-2003 命名实体识别结果。超参数是使用 Dev 设置。报告的 Dev 和 Test 分数取平均值 使用这些超参数进行 5 次随机重启
性能最佳的方法是将 来自预训练 Transformer 的顶部四个隐藏层的 token 表示形式,它只是 0.3 F1 落后于微调整个模型。
这表明 微调和基于特征的方法在 BERT 上都是有效的。
6 总结
由于转移而带来的近期实证改进 使用语言模型进行学习已证明 丰富的、无监督的预训练是一个不可或缺的 许多语言理解系统的一部分。在 特别是,这些结果甚至使资源不足 任务从深度单向架构中受益。
我们的主要贡献是将这些发现进一步推广到深处 双向架构,允许相同的预训练模型 成功处理广泛的 NLP 任务。
附录
A. BERT 的其他详细信息
A.1 训练前任务示例
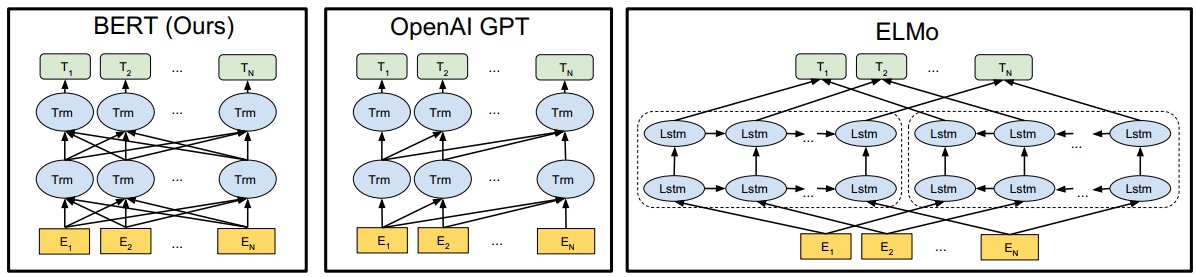
图 3:预训练模型架构的差异。BERT 使用双向 Transformer。OpenAI GPT 使用从左到右的 Transformer。ELMo 使用独立训练的从左到右和从右到左的 LSTM 的串联来为下游任务生成特征。在这三个中,只有 BERT 表示是共同的 在所有图层的 Left 和 Right 上下文中都受到条件限制。除了架构差异之外,BERT 和 OpenAI GPT 是微调方法,而 ELMo 是一种基于功能的方法。
A.2 训练前程序
A.3 微调程序
对于微调,大多数模型超参数是 与预训练中相同,但 批量大小、学习率和训练 epoch 数。退出概率始终为 保持在 0.1。最佳超参数值 是特定于任务的,但我们发现了以下范围 的可能值,以便在所有任务中正常工作:
- 批量大小: 16, 32
- 学习率 (Adam):5e-5、3e-5、2e-5
- 纪元数:2、3、4
我们还观察到,大型数据集(例如 100k+ 标记的训练样本)要少得多 对超参数选择比小数据敏感 集。微调通常非常快,因此只需对 上述参数并选择 在开发集上表现最佳。
A.4 BERT、ELMo 和 OpenAI GPT 的比较
A.5 对不同任务进行微调的插图
B. 详细的实验设置
图 4.BERT 用于不同任务场景,来自 paper 附录。
(a) 句子对分类;(b) 单句分类;(c) 问答;(d) 单句打标。
C. 其他消融研究
参考文献
- 艾伦·阿克比克、邓肯·布莱斯和罗兰·沃尔格拉夫。2018. 用于序列标记的上下文字符串嵌入。第 27 届计算语言学国际会议论文集,第 1638-1649 页。
- Rami Al-Rfou、Dokook Choe、Noah Constant、Mandy Guo 和 Llion Jones。2018. 具有更深自我注意的字符级语言建模。arXiv 预印本 arXiv:1808.04444。
- Rie Kubota Ando(久保田理惠)和 Tong Zhang(张彤)。2005. 从多个任务和未标记数据中学习预测结构的框架。机器学习研究杂志,6(Nov):1817–1853。
- 路易莎·本蒂沃利、贝尔纳多·马格尼尼、伊多·达甘、华庄当和达尼洛·詹皮科洛。2009. 第五届 PASCAL 识别文本蕴涵挑战赛。在 TAC.NIST.
- 约翰·布利策、瑞安·麦克唐纳和费尔南多·佩雷拉。2006. 具有结构对应学习的域适应。在 2006 年自然语言处理经验方法会议论文集中,第 120-128 页。计算语言学协会。
- 塞缪尔·鲍曼 (Samuel R. Bowman)、加博尔·安吉利 (Gabor Angeli)、克里斯托弗·波茨 (Christopher Potts) 和克里斯托弗·曼宁 (Christopher D. Manning)。2015. 用于学习自然语言推理的大型注释语料库。在 EMNLP.计算语言学协会。
- Peter F Brown、Peter V Desouza、Robert L Mercer、Vincent J Della Pietra 和 Jenifer C Lai。1992. 基于类的自然语言 n-gram 模型。计算语言学, 18(4):467–479。
- Daniel Cer、Mona Diab、Eneko Agirre、Inigo Lopez-Gazpio 和 Lucia Specia。2017. https://doi.org/10.18653/v1/S17-2001 Semeval-2017 任务 1:语义文本相似性多语言和跨语言重点评估。第 11 届语义评估国际研讨会 (SemEval-2017) 会议记录,第 1-14 页,加拿大温哥华。计算语言学协会。
- Ciprian Chelba、Tomas Mikolov、Mike Schuster、Qi Ge、Thorsten Brants、Phillipp Koehn 和 Tony Robinson。2013. 用于衡量统计语言建模进展的 10 亿字基准。arXiv 预印本 arXiv:1312.3005。
- Z. Chen、H. Zhang、X. Zhang 和 L. Zhao。2018. https://data.quora.com/First-Quora-Dataset-Release-Question-Pairs Quora 问题对。
- 克里斯托弗·克拉克 (Christopher Clark) 和马特·加德纳 (Matt Gardner)。2018. 简单有效的多段阅读理解。在 ACL.
- Kevin Clark、Minh-Thang Luong、Christopher D Manning 和 Quoc Le。2018. 具有交叉视图训练的半监督序列建模。在 2018 年自然语言处理经验方法会议论文集中,第 1914-1925 页。
- 罗南·科洛伯特 (Ronan Collobert) 和杰森·韦斯顿 (Jason Weston)。2008.newblock 自然语言处理的统一架构:具有多任务学习的深度神经网络。第 25 届机器学习国际会议论文集,第 160-167 页。ACM 的。
- Alexis Conneau、Douwe Kiela、Holger Schwenk、Lo“ic Barrault 和 Antoine Bordes。2017. https://www.aclweb.org/anthology/D17-1070 从自然语言推理数据中监督学习通用句子表示。在 2017 年自然语言处理经验方法会议论文集,第 670-680 页,丹麦哥本哈根。计算语言学协会。
- Andrew M Dai 和 Quoc V Le.2015. 半监督序列学习。在神经信息处理系统的进展中,第 3079-3087 页。
- J. 邓, W. Dong, R. Socher, L.-J.李、K. Li 和 L. Fei-Fei。2009. ImageNet:大规模分层图像数据库。在 CVPR09 中。
- 威廉 B 多兰和克里斯布罗克特。2005. 自动构建 sentential 释义语料库。在第三届释义国际研讨会论文集 (IWP2005)。
- William Fedus、Ian Goodfellow 和 Andrew M Dai。2018. Maskgan:通过填写 the_ 更好地生成文本。arXiv 预印本 arXiv:1801.07736。
- 丹·亨德利克斯 (Dan Hendrycks) 和凯文·金佩尔 (Kevin Gimpel)。2016. http://arxiv.org/abs/1606.08415 用高斯误差线性单位桥接非线性和随机正则化器。CoRR,abs/1606.08415。
- Felix Hill、Kyunghyun Cho 和 Anna Korhonen。2016. 从未标记的数据中学习句子的分布式表示。在计算语言学协会北美分会 2016 年会议记录中:人类语言技术。计算语言学协会。
- 杰里米·霍华德 (Jeremy Howard) 和塞巴斯蒂安·鲁德 (Sebastian Ruder)。2018. http://arxiv.org/abs/1801.06146 用于文本分类的通用语言模型微调.在 ACL.计算语言学协会。
- 胡明浩、彭宇兴、黄振、邱希鹏、魏芙如和周明。2018. 用于机器阅读理解的增强助记符阅读器。在 IJCAI.
- Yacine Jernite、Samuel R. Bowman 和 David Sontag。2017. http://arxiv.org/abs/1705.00557 基于话语的快速无监督句子表示学习的目标。CoRR,abs/1705.00557。
- Mandar Joshi、Eunsol Choi、Daniel S Weld 和 Luke Zettlemoyer。2017. Triviaqa:用于阅读理解的大规模远程监督挑战数据集。在 ACL.
- Ryan Kiros、Yukun Zhu、Ruslan R Salakhutdinov、Richard Zemel、Raquel Urtasun、Antonio Torralba 和 Sanja Fidler。2015. 跳跃思维向量。在神经信息处理系统的进展中,第 3294-3302 页。
- Quoc Le 和 Tomas Mikolov。2014. 句子和文档的分布式表示。在机器学习国际会议中,第 1188-1196 页。
- 赫克托·莱维斯克、欧内斯特·戴维斯和莱奥拉·摩根斯特恩。2011. winograd 模式挑战赛。在 Aaai 春季研讨会:常识推理的逻辑形式化,第 46 卷,第 47 页。
- Lajanugen Logeswaran 和 Honglak Lee。2018. https://openreview.net/forum?id=rJvJXZb0W 学习句子表示的有效框架.在学习表征国际会议上。
- Bryan McCann、James Bradbury、Caim Xiong 和 Richard Socher。2017. 在翻译中学习:情境化词向量。在 NIPS.
- Oren Melamud、Jacob Goldberger 和 Ido Dagan。2016. context2vec:使用双向 LSTM 学习通用上下文嵌入。在 CoNLL 中。
- 托马斯·米科洛夫、伊利亚·萨茨克弗、凯·陈、格雷格·科拉多和杰夫·迪恩。2013. 单词和短语的分布式表示及其组合性。在神经信息处理系统进展 26,第 3111-3119 页。Curran Associates, Inc.
- Andriy Mnih 和 Geoffrey E Hinton。2009. http://papers.nips.cc/paper/3583-a-scalable-hierarchical-distributed-language-model.pdf 可扩展的分层分布式语言模型.在 D. Koller、D. Schuurmans、Y. Bengio 和 L. Bottou 编辑的《神经信息处理系统进展》第 21 期,第 1081-1088 页。Curran Associates, Inc.
- Ankur P Parikh、Oscar T“ackstr”om、Dipanjan Das 和 Jakob Uszkoreit。2016. 用于自然语言推理的可分解注意力模型。在 EMNLP.
- 杰弗里·彭宁顿 (Jeffrey Pennington)、理查德·索彻 (Richard Socher) 和克里斯托弗·曼宁 (Christopher D. Manning)。2014. http://www.aclweb.org/anthology/D14-1162 手套:单词表示的全局向量。在自然语言处理的经验方法 (EMNLP) 中,第 1532-1543 页。
- 马修·彼得斯 (Matthew Peters)、瓦利德·阿马尔 (Waleed Ammar)、钱德拉·博加瓦图拉 (Chandra Bhagavatula) 和罗素·鲍尔 (Russell Power)。2017. 使用双向语言模型的半监督序列标记。在 ACL.
- 马修·彼得斯、马克·诺伊曼、莫希特·艾耶尔、马特·加德纳、克里斯托弗·克拉克、肯顿·李和卢克·泽特尔莫耶。2018\natexlaba.深度上下文化的单词表示。在 NAACL.
- Matthew Peters、Mark Neumann、Luke Zettlemoyer 和 温-tau Yih。2018\natexlabb.剖析上下文词嵌入:架构和表示。在 2018 年自然语言处理经验方法会议论文集中,第 1499-1509 页。
- Alec Radford、Karthik Narasimhan、Tim Salimans 和 Ilya Sutskever。2018. 通过无监督学习提高语言理解。技术报告,OpenAI。
- Pranav Rajpurkar、Jian Zhang、Konstantin Lopyev 和 Percy Liang。2016. 小队:100,000+ 机器理解文本的问题。在 2016 年自然语言处理经验方法会议论文集中,第 2383-2392 页。
- Minjoon Seo、Aniruddha Kembhavi、Ali Farhadi 和 Hannaneh Hajishirzi。2017. 机器理解的双向注意力流。在 ICLR.
- Richard Socher、Alex Perelygin、Jean Wu、Jason Chuang、Christopher D Manning、Andrew Ng 和 Christopher Potts。2013. 情感树库语义组合性的递归深度模型。在 2013 年自然语言处理经验方法会议论文集中,第 1631-1642 页。
- Fu Sun, Linyang Li, Xipeng Qiu, 和 Yang Liu.2018. U-net:带有无法回答的问题的机器阅读理解。arXiv 预印本 arXiv:1810.06638。
- 威尔逊 L 泰勒。1953. “完形填空程序”:一种测量可读性的新工具。新闻通报,30(4):415–433。
- Erik F Tjong Kim Sang 和 Fien De Meulder。2003. conll-2003 共享任务简介:与语言无关的命名实体识别。在 CoNLL 中。
- 约瑟夫·图里安、列夫·拉蒂诺夫和约书亚·本吉奥。2010. 单词表示:一种简单而通用的半监督学习方法。在计算语言学协会第 48 届年会论文集,ACL '10,第 384-394 页。
- Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N Gomez、Lukasz Kaiser 和 Illia Polosukhin。2017. 注意力就是你所需要的。在神经信息处理系统进展中,第 6000-6010 页。
- 帕斯卡尔·文森特、雨果·拉罗谢尔、约书亚·本吉奥和皮埃尔-安托万·曼扎戈尔。2008. 使用去噪自动编码器提取和组合稳健特征。第 25 届机器学习国际会议论文集,第 1096-1103 页。ACM 的。
- Alex Wang、Amanpreet Singh、Julian Michael、Felix Hill、Omer Levy 和 Samuel Bowman。2018\natexlaba.Glue:用于自然语言理解的多任务基准和分析平台。在 2018 年 EMNLP 研讨会 BlackboxNLP 的会议记录中:分析和解释 NLP 的神经网络,第 353-355 页。
- Wei Wang、Ming Yan 和 Chen Wu。2018\natexlabb.用于阅读理解和问答的多粒度分层注意力融合网络。在计算语言学协会第 56 届年会的会议记录中(第 1 卷:长篇论文)。计算语言学协会。
- 亚历克斯·沃斯塔特 (Alex Warstadt)、阿曼普雷特·辛格 (Amanpreet Singh) 和塞缪尔·鲍曼 (Samuel R Bowman)。2018. 神经网络可接受性判断。arXiv 预印本 arXiv:1805.12471。
- 阿迪娜·威廉姆斯、尼基塔·南吉亚和塞缪尔·鲍曼。2018. 通过推理理解句子的广泛覆盖挑战语料库。在 NAACL.
- Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. 2016.Google 的神经机器翻译系统:弥合人工翻译和机器翻译之间的鸿沟。arXiv 预印本 arXiv:1609.08144。
- Jason Yosinski、Jeff Clune、Yoshua Bengio 和 Hod Lipson。2014. 深度神经网络中的特征的可转移性如何?在神经信息处理系统的进展中,第 3320-3328 页。
- Adams Wei Yu、David Dohan、Minh-Thang Luong、Rui Zhao、Kai Chen、Mohammad Norouzi 和 Quoc V Le。2018. QANet:将局部卷积与全局自我注意相结合进行阅读理解。在 ICLR.
- 罗文·泽勒斯 (Rowan Zellers)、约纳坦·比斯克 (Yonatan Bisk)、罗伊·施瓦茨 (Roy Schwartz) 和崔叶珍 (Yejin Choi)。2018. Swag:用于扎根常识推理的大规模对抗数据集。在 2018 年自然语言处理经验方法会议 (EMNLP) 的会议记录中。
- Yukun Zhu、Ryan Kiros、Rich Zemel、Ruslan Salakhutdinov、Raquel Urtasun、Antonio Torralba 和 Sanja Fidler。2015. 对齐书籍和电影:通过看电影和读书来实现故事般的视觉解释。在 IEEE 计算机视觉国际会议论文集中,第 19-27 页。
相关文章:
预训练深度双向 Transformers 做语言理解
大家读完觉得有意义记得关注和点赞!!! 与 GPT 一样,BERT 也基于 transformer 架构, 从诞生时间来说,它位于 GPT-1 和 GPT-2 之间,是有代表性的现代 transformer 之一, 现在仍然在很多…...

理解js闭包,原型,原型链
闭包 一个函数嵌套了另一个函数,内部函数引用了外部函数的变量,这样,当外部函数在执行环境中执行完毕后,因为某个变量被引用就无法被GC回收,导致这个变量会一直保持在内存中不能被释放。因此可以用来封装一个私有变量…...

linux tar 文件解压压缩
文件压缩和解压 tar -c: 建立压缩档案 -x:解压 -t:查看内容 -r:向压缩归档文件末尾追加文件 -u:更新原压缩包中的文件 -z:有gzip属性的 -j:有bz2属性的 -v:显示所有过程 -O:…...

【SQL server】教材数据库(5)
使用教材数据库(1)中的数据表完成以下题目: 1 根据上面基本表的信息定义视图显示每个学生姓名、应缴书费 2 观察基本表数据变化时,视图中数据的变化。 3利用视图,查询交费最高的学生。 1、create view 学生应缴费视…...

Oracle 11G还有新BUG?ORACLE 表空间迷案!
前段时间遇到一个奇葩的问题,在开了SR和oracle support追踪两周以后才算是有了不算完美的结果,在这里整理出来给大家分享。 1.问题描述 12/13我司某基地MES全厂停线,系统卡死不可用,通知到我排查,查看alert log看到是…...

java实现预览服务器文件,不进行下载,并增加水印效果
通过文件路径获取文件,对不同类型的文件进行不同处理,将Word文件转成pdf文件预览,并早呢更加水印,暂不支持Excel文件,如果浏览器不支持PDF文件预览需要下载插件。文中currentUser.getUserid(),即为增加的水…...

SAP月结、年结前重点检查事项(后勤与财务模块)
文章目录 一、PP生产模块相关的事务检查二、SD销售模块相关的事务检查:三、MM物料管理模块相关的事务检查四、FICO财务模块相关的事务检查五、年结前若干注意事项【SAP系统PP模块研究】 #SAP #生产订单 #月结 #年结 一、PP生产模块相关的事务检查 1、月末盘点后,生产用料的…...

MYSQL 高阶语句
目录 1、排列查询 2、区间判断 3、对结果进行分组查询 4、limit和distinct 5、设置别名 通配符 6、子查询 7、exists语句,判断子查询的结果是否为空 8、视图表 9、连接查询 1. 内连接 2. 左连接 3. 右连接 create table info ( id int primary key, name…...

VS Code中怎样查看某分支的提交历史记录
VsCode中无法直接查看某分支的提交记录,需借助插件才行,常见的插件如果git history只能查看某页面的改动记录,无法查看某分支的整体提交记录,我们可以安装GIT Graph插件来解决这个问题 1.在 VSCode的插件库中搜索 GIT Graph安装&a…...
)
知识库搭建实战一、(基于 Qianwen 大模型的知识库搭建)
基于 Qianwen 大模型的知识库开发规划 基础环境搭建可以参考文章:基础环境搭建 在构建智能应用时,知识库是一个重要的基础模块。以下将基于 Qianwen 大模型,详细介绍构建一个标准知识库的设计思路及其实现步骤。 知识库的核心功能模块 知识库开发的核心功能模块主要包括…...

ctr方法下载的镜像能用docker save进行保存吗?
ctr 和 docker 是两个不同的容器运行时工具,它们使用的镜像存储格式是兼容的(都是 OCI 标准镜像),但它们的镜像管理方式和存储路径不同。因此,直接使用 docker save 保存 ctr 拉取的镜像可能会遇到问题。 关键点 ctr 和 docker 的镜像存储位置不同: ctr(containerd)的镜…...

win32汇编环境下,窗口程序中生成listview列表控件及显示
;运行效果 ;抄下面源码在radasm里面,可以直接编译运行。重要部分加了备注。 ;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>&…...

运维之网络安全抓包—— WireShark 和 tcpdump
为什么要抓包?何为抓包? 抓包(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。为什么要抓包?因为在处理 IP网络…...

【复刻】数字化转型是否赋能企业新质生产力发展?(2015-2023年)
参照赵国庆(2024)的做法,对来自产业经济评论《企业数字化转型是否赋能企业新质生产力发展——基于中国上市企业的微观证据》一文中的基准回归部分进行复刻基于2015-2023年中国A股上市公司数据,实证分析企业数字化转型对新质生产力…...

【数据仓库】spark大数据处理框架
文章目录 概述架构spark 架构角色下载安装启动pyspark启动spark-sehll启动spark-sqlspark-submit经验 概述 Spark是一个性能优异的集群计算框架,广泛应用于大数据领域。类似Hadoop,但对Hadoop做了优化,计算任务的中间结果可以存储在内存中&a…...

2 秒杀系统架构
第一步 思考面临的问题和业务场景 秒杀系统面临的问题: 短时间内并发非常高,如果按照秒杀的并发做相应的承载会造成大量资源的浪费。第二解决超卖的问题。 第二步 思考目前的处境和解决方案 因为秒杀系统属于短时间内的高并发问题,我们不可能使用那么…...

UNI-APP_i18n国际化引入
官方文档:https://uniapp.dcloud.net.cn/tutorial/i18n.html vue2中使用 1. 新建文件 locale/index.js import en from ./en.json import zhHans from ./zh-Hans.json import zhHant from ./zh-Hant.json const messages {en,zh-Hans: zhHans,zh-Hant: zhHant }…...

【详解】AndroidWebView的加载超时处理
Android WebView的加载超时处理 在Android开发中,WebView是一个常用的组件,用于在应用中嵌入网页。然而,当网络状况不佳或页面加载过慢时,用户可能会遇到加载超时的问题。为了提升用户体验,我们需要对WebView的加载超时…...

RedisDesktopManager新版本不再支持SSH连接远程redis后
背景 RedisDesktopManager(又名RDM)是一个用于Windows、Linux和MacOS的快速开源Redis数据库管理应用程序。这几天从新下载RedisDesktopManager最新版本,结果发现新版本开始不支持SSH连接远程redis了。 解决方案 第一种 根据网上有效的信息,可以回退版…...

开源 SOAP over UDP
简介 看到有人想要实现两个 EXE 之间的互动。这可以采用 RPC 的方式嘛。 Delphi 现成的 RPC 框架,比如 WebService,比如 DataSnap; 当然,github 上面还有第三方开源的 XMLRPC 等等。 为啥要搞一个 UDP Delphi 的 WebService …...
)
告别编译失败:Qt 6.6.0交叉编译到ARM平台最常见的5个错误及解决方法(基于gcc-linaro-14.0.0)
告别编译失败:Qt 6.6.0交叉编译到ARM平台最常见的5个错误及解决方法(基于gcc-linaro-14.0.0) 最近在将Qt 6.6.0交叉编译到i.MX6ULL开发板时,遇到了不少坑。作为一个经历过多次编译失败的老手,我整理了几个最容易导致编…...

SecGPT-14B+OpenClaw联调指南:解决模型响应超时问题
SecGPT-14BOpenClaw联调指南:解决模型响应超时问题 1. 问题背景与场景定位 上周在尝试用OpenClaw调用SecGPT-14B分析一份12万字的网络安全报告时,遭遇了令人头疼的响应超时问题。这个场景很典型——当我们需要处理长文本安全分析时,模型推理…...

PyDuinoBridge:Python与Arduino串口通信的变量级桥梁
1. PyDuinoBridge:嵌入式系统与Python协同开发的双向通信桥梁 PyDuinoBridge 是一个轻量级、透明、面向工程实践的串行通信中间件库,专为解决嵌入式微控制器(以Arduino平台为代表)与上位机Python环境之间高效、可靠、低侵入式数据…...

# 系列文10:突破Activiti限制!政务工作流任意流转,支持跳退
系列文10:突破Activiti限制!政务工作流任意流转,支持跳退回退 非科班野生程序员,深耕政务信息化20年,这套自研Java Web框架支撑过省级新农保、全国首例跨省医保结算等核心民生系统,18年稳定运行至今。本系…...

如何快速实现文件格式伪装?apate工具完整使用指南
如何快速实现文件格式伪装?apate工具完整使用指南 【免费下载链接】apate 简洁、快速地对文件进行格式伪装 项目地址: https://gitcode.com/gh_mirrors/apa/apate 在当今数字时代,文件格式伪装技术已经成为保护数据隐私和突破平台限制的重要工具。…...

并联型有源电力滤波器APF的三相三线制模型及其Simulink仿真研究——基于瞬时无功功率理论...
并联型有源电力滤波器APF三相三线模型都包括,simulink仿真利用基于瞬时无功功率理论的ip-iq谐波检测算法,对三相三线制并联型APF控制系统进行建模与Matlab仿真最近在搞三相三线制并联型APF的仿真,发现基于ip-iq谐波检测的方案确实挺有意思。这…...

论文降重降AI难?自带双功能黑科技的实用工具盘点
论文降重和消除AI生成痕迹是很多创作者面临的双重难题,选对工具能节省大量时间精力。下面整理了几款自带降AIGC率功能的实用工具,覆盖中文、英文、应急、轻量优化等不同使用场景,附实际使用效果与核心特点,帮你快速找到适配需求的…...

PyTorch 2.8镜像效果实测:RTX 4090D上Qwen2-VL图文理解准确率对比报告
PyTorch 2.8镜像效果实测:RTX 4090D上Qwen2-VL图文理解准确率对比报告 1. 测试环境与配置 1.1 硬件与系统配置 本次测试使用的硬件配置为: GPU:NVIDIA RTX 4090D 24GB显存CPU:10核心处理器内存:120GB存储ÿ…...

Pandas读写Parquet文件避坑指南:pyarrow和fastparquet引擎怎么选?columns参数真能省内存吗?
Pandas读写Parquet文件避坑指南:引擎选择与内存优化实战解析 当你第一次听说Parquet格式能比CSV节省80%存储空间时,可能和我一样兴奋地立刻把项目里的数据全转成了.parquet后缀。但真正在生产环境部署时,却发现pd.read_parquet()在不同机器上…...

hakchi2安全使用指南:如何确保不损坏原始系统
hakchi2安全使用指南:如何确保不损坏原始系统 【免费下载链接】hakchi2 Tool that allows you to add more games to your NES/SNES Classic Mini. WARNING: hakchi2 is no longer supported. Please use hakchi2 CE. 项目地址: https://gitcode.com/gh_mirrors/h…...