【机器学习】Kaggle实战信用卡反欺诈预测(场景解析、数据预处理、特征工程、模型训练、模型评估与优化)
构建信用卡反欺诈预测模型
建模思路

本项目需解决的问题
本项目通过利用信用卡的历史交易数据,进行机器学习,构建信用卡反欺诈预测模型,提前发现客户信用卡被盗刷的事件。
项目背景
数据集包含由欧洲持卡人于2013年9月使用信用卡进行交的数据。此数据集显示两天内发生的交易,其中284,807笔交易中有492笔被盗刷。数据集非常不平衡,
积极的类(被盗刷)占所有交易的0.172%。
它只包含作为PCA转换结果的数字输入变量。不幸的是,由于保密问题,我们无法提供有关数据的原始功能和更多背景信息。特征V1,V2,… V28是使用PCA
获得的主要组件,没有用PCA转换的唯一特征是“时间”和“量”。特征’时间’包含数据集中每个事务和第一个事务之间经过的秒数。特征“金额”是交易金额,此特
征可用于实例依赖的成本认知学习。特征’类’是响应变量,如果发生被盗刷,则取值1,否则为0。
以上取自Kaggle官网对本数据集部分介绍(谷歌翻译),关于数据集更多介绍请参考《Credit Card Fraud Detection》。
场景解析(算法选择)
首先,我们拿到的数据是持卡人两天内的信用卡交易数据,这份数据包含很多维度,要解决的问题是预测持卡人是否会发生信用卡被盗刷。信用卡持卡人是否会发生被盗刷只有两种可能,发生被盗刷或不发生被盗刷。又因为这份数据是打标好的(字段Class是目标列),也就是说它是一个监督学习的场景。于是,我们判定信用卡持卡人是否会发生被盗刷是一个二元分类问题,意味着可以通过二分类相关的算法来找到具体的解决办法,本项目选用的算法是逻辑斯蒂回归(Logistic Regression)。
分析数据
数据是结构化数据 ,不需要做特征抽象。特征V1至V28是经过PCA处理,而特征Time和Amount的数据规格与其他特征差别较大,需要对其做特征缩放,将特征缩放至同一个规格。在数据质量方面 ,没有出现乱码或空字符的数据,可以确定字段Class为目标列,其他列为特征列。
模型评估
这份数据是全部打标好的数据,可以通过交叉验证的方法对训练集生成的模型进行评估。70%的数据进行训练,30%的数据进行预测和评估。
场景总结
现对该业务场景进行总结如下:
- 根据历史记录数据学习并对信用卡持卡人是否会发生被盗刷进行预测,二分类监督学习场景,选择逻辑斯蒂回归(Logistic Regression)算法。
- 数据为结构化数据,不需要做特征抽象,但需要做特征缩放。
数据文件
1、数据预处理
1.1、导包
import numpy as np
import pandas as pd
pd.set_option('display.float_format',lambda x :'%.4f' % x)import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import seaborn as sns
import missingno as msno # 可视化工具,pip install missingnofrom sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_splitfrom sklearn.metrics import auc,roc_auc_score,roc_curve,recall_score,accuracy_score,classification_reportfrom sklearn.preprocessing import StandardScaler
import warnings
warnings.filterwarnings('ignore')
1.2、解码数据
data = pd.read_csv('./creditcard.csv')
data.head()

data.tail()

5 rows × 31 columns
print(data.shape)
data.info()
(284807, 31)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 284807 entries, 0 to 284806
Data columns (total 31 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 Time 284807 non-null float641 V1 284807 non-null float642 V2 284807 non-null float643 V3 284807 non-null float644 V4 284807 non-null float645 V5 284807 non-null float646 V6 284807 non-null float647 V7 284807 non-null float648 V8 284807 non-null float649 V9 284807 non-null float6410 V10 284807 non-null float6411 V11 284807 non-null float6412 V12 284807 non-null float6413 V13 284807 non-null float6414 V14 284807 non-null float6415 V15 284807 non-null float6416 V16 284807 non-null float6417 V17 284807 non-null float6418 V18 284807 non-null float6419 V19 284807 non-null float6420 V20 284807 non-null float6421 V21 284807 non-null float6422 V22 284807 non-null float6423 V23 284807 non-null float6424 V24 284807 non-null float6425 V25 284807 non-null float6426 V26 284807 non-null float6427 V27 284807 non-null float6428 V28 284807 non-null float6429 Amount 284807 non-null float6430 Class 284807 non-null int64
dtypes: float64(30), int64(1)
memory usage: 67.4 MB
data.describe().T

msno.matrix(data)
<AxesSubplot:>
data.isnull().sum().sum()
0
2、特征工程
2.1、目标变量
fig,axs = plt.subplots(1,2,figsize = (14,7))sns.countplot(x = 'Class',data = data,ax = axs[0])
axs[0].set_title('Frequency of each Calss')data['Class'].value_counts().plot(kind = 'pie',ax = axs[1],autopct = '%1.2f%%')
axs[1].set_title('Percent of each Class')
Text(0.5, 1.0, 'Percent of each Class')
data.groupby(by = 'Class').size()
Class
0 284315
1 492
dtype: int64
2.2、特征衍生
data.head() # 时间以秒为单位,离散性太强

5 rows × 31 columns
data['Hour'] = data['Time'].apply(lambda x : divmod(x,3600)[0])
data

284807 rows × 32 columns
2.3、特征选择
2.3.1、信用卡正常消费和盗刷对比
XFraud = data.loc[data['Class'] == 1] # 盗刷
XnonFraud = data.loc[data['Class'] == 0] # 正常消费correlationNonFraud = XnonFraud.loc[:,data.columns != 'Class'].corr()mask = np.zeros_like(correlationNonFraud)index = np.triu_indices_from(correlationNonFraud) # 右上部分的索引
mask[index] = True # mask 面具,0没有面具,1表示有面具kw = {'width_ratios':[1,1,0.05],'wspace':0.2}
f,(ax1,ax2,ax3) = plt.subplots(1,3,gridspec_kw=kw,figsize = (22,9))cmap = sns.diverging_palette(220,8,as_cmap = True) # 一系列颜色
sns.heatmap(correlationNonFraud,ax = ax1,vmin = -1,vmax = 1,square=False,linewidths=0.5,mask = mask,cbar=False,cmap= cmap)
ax1.set_title('Normal')correlationFraud = XFraud.loc[:,data.columns != 'Class'].corr()
sns.heatmap(correlationFraud,vmin = -1,vmax= 1,cmap = cmap,ax = ax2,square=False,linewidths=0.5,mask = mask,yticklabels=True,cbar_ax=ax3,cbar_kws={'orientation':'vertical','ticks':[-1,-0.5,0,0.5,1]})ax2.set_title('Fraud')
Text(0.5, 1.0, 'Fraud')
从上图可以看出,信用卡被盗刷的事件中,部分变量之间的相关性更明显。其中变量V1、V2、V3、V4、V5、V6、V7、V9、V10、V11、V12、V14、V16、V17和V18以及V19之间的变化在信用卡被盗刷的样本中呈性一定的规律。
特征V8、V13 、V15 、V20 、V21 、V22、 V23 、V24 、V25 、V26 、V27 和V28规律不明显!
from matplotlib import colors
plt.colormaps()
['Accent','Accent_r','Blues','Blues_r','BrBG',...'viridis','viridis_r','vlag','vlag_r','winter','winter_r']
2.3.2、交易金额和交易次数
f,(ax1,ax2) = plt.subplots(2,1,sharex=True,figsize = (16,6))ax1.hist(data['Amount'][data['Class'] == 1],bins = 30)
ax1.set_title('Fraud')
plt.yscale('log')ax2.hist(data['Amount'][data['Class'] == 0],bins = 100)
ax2.set_title('Normal')plt.xlabel('Amount($)')
plt.ylabel('count')
plt.yscale('log')

信用卡被盗刷发生的金额与信用卡正常用户发生的金额相比呈现散而小的特点,这说明信用卡盗刷者为了不引起信用卡卡主的注意,更偏向选择小金额消费。
2.3.3、信用卡盗刷时间
参数介绍:
- size 每个面的高度(英寸) 标量
- aspect 纵横比 标量
sns.factorplot(x = 'Hour',data = data,kind = 'count',palette = 'ocean',size = 6,aspect = 3)
<seaborn.axisgrid.FacetGrid at 0x292aee31670>
每天早上9点到晚上11点之间是信用卡消费的高频时间段。
2.3.4、交易金额和交易时间关系
f,(ax1,ax2) = plt.subplots(2,1,sharex=True,figsize = (16,6))cond1 = data['Class'] == 1
ax1.scatter(data['Hour'][cond1],data['Amount'][cond1])
ax1.set_title('Fraud')cond2 = data['Class'] == 0
ax2.scatter(data['Hour'][cond2],data['Amount'][cond2])
ax2.set_title('Normal')
Text(0.5, 1.0, 'Normal')
sns.catplot(x = 'Hour',kind = 'count',data = data[cond1],height=9,aspect=2)
<seaborn.axisgrid.FacetGrid at 0x292af9cd430>
从上图可以看出,在信用卡被盗刷样本中,离群值发生在客户使用信用卡消费更低频的时间段。信用卡被盗刷数量案发最高峰在第一天上午11点达到43次,其余发生信用卡被盗刷案发时间在晚上时间11点至第二早上9点之间,说明信用卡盗刷者为了不引起信用卡卡主注意,更喜欢选择信用卡卡主睡觉时间和消费频率较高的时间点作案;同时,信用卡发生被盗刷的最大值也就只有2,125.87美元。
data['Amount'][cond1].max()
2125.87
2.3.5、特征分布(帮助筛选特征!!!)
data.head()

5 rows × 32 columns
from matplotlib import font_manager
fm = font_manager.FontManager()
[font.name for font in fm.ttflist]
['DejaVu Serif Display','DejaVu Sans Mono','cmss10','DejaVu Serif','DejaVu Sans','STIXSizeFourSym','STIXNonUnicode','cmtt10',....'Century Schoolbook','Calisto MT','Calibri','Malgun Gothic','Britannic Bold','Matura MT Script Capitals']
sns.__version__
'0.11.1'
data

284807 rows × 32 columns
plt.rcParams['font.family'] = 'STKaiti'
v_feat = data.iloc[:,1:29].columns
plt.figure(figsize=(16,4 * 28))
cond1 = data['Class'] == 1
cond2 = data['Class'] == 0gs = gridspec.GridSpec(28,1) # 子视图
for i,cn in enumerate(v_feat):ax = plt.subplot(gs[i])sns.distplot(data[cn][cond1],bins = 50) # 欺诈sns.distplot(data[cn][cond2],bins = 100) # 正常消费ax.set_title('特征概率分布图' + cn)

上图是不同变量在信用卡被盗刷和信用卡正常的不同分布情况,我们将选择在不同信用卡状态下的分布有明显区别的变量。因此剔除变量V8、V13 、V15 、V20 、V21 、V22、 V23 、V24 、V25 、V26 、V27 和V28变量。这也与我们开始用相关性图谱观察得出结论一致。同时剔除变量Time,保留离散程度更小的Hour变量。
droplist = ['V8','V13','V15','V20','V21','V22','V23','V24','V25','V26','V27','V28','Time']data_new = data.drop(labels=droplist,axis = 1)
display(data.shape, data_new.shape)
(284807, 32)(284807, 19)
data_new.head()

特征从31个缩减至18个(不含目标变量)。
2.4、特征缩放
由于特征Hour和Amount的规格和其他特征相差较大,因此我们需对其进行特征缩放。
col = ['Amount','Hour']
sc = StandardScaler() # Z-score归一化data_new[col] = sc.fit_transform(data_new[col])
data_new.head()

data_new.describe().T

2.5、特征重要性排序
feture = list(data_new.columns)
print(feture)
['V1', 'V2', 'V3', 'V4', 'V5', 'V6', 'V7', 'V9', 'V10', 'V11', 'V12', 'V14', 'V16', 'V17', 'V18', 'V19', 'Amount', 'Class', 'Hour']
feture.remove('Class') # 特征名,修改原数据
feture
['V1','V2','V3','V4','V5','V6','V7','V9','V10','V11','V12','V14','V16','V17','V18','V19','Amount','Hour']
- 构建X变量和y变量
X = data_new[feture]
y = data_new['Class']
display(X.head(),y.head())

0 0
1 0
2 0
3 0
4 0
Name: Class, dtype: int64
- 利用随机森林的feature importance对特征的重要性进行排序
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()clf.fit(X,y)
clf.feature_importances_
array([0.01974556, 0.015216 , 0.02202158, 0.03775329, 0.01995699,0.02257269, 0.02873717, 0.04056692, 0.08524621, 0.06078786,0.18454186, 0.12167233, 0.06079882, 0.19714222, 0.03220492,0.01833037, 0.01716956, 0.01553564])
plt.rcParams['figure.figsize'] = (12,6)
plt.style.use('fivethirtyeight')
from matplotlib import stylestyle.available
['Solarize_Light2','_classic_test_patch','bmh','classic','dark_background','fast','fivethirtyeight','ggplot','grayscale','seaborn','seaborn-bright','seaborn-colorblind','seaborn-dark','seaborn-dark-palette','seaborn-darkgrid','seaborn-deep','seaborn-muted','seaborn-notebook','seaborn-paper','seaborn-pastel','seaborn-poster','seaborn-talk','seaborn-ticks','seaborn-white','seaborn-whitegrid','tableau-colorblind10']
len(feture)
18
importances = clf.feature_importances_
feat_name = feture
feat_name = np.array(feat_name)
index = np.argsort(importances)[::-1]plt.bar(range(len(index)),importances[index],color = 'lightblue')
plt.step(range(18),np.cumsum(importances[index]))
_ = plt.xticks(range(18),labels=feat_name[index],rotation = 'vertical',fontsize = 14)

feat_name
['V1','V2','V3','V4','V5','V6','V7','V9','V10','V11','V12','V14','V16','V17','V18','V19','Amount','Hour']
3、模型训练
3.1、过采样
前面提到,目标列Class呈现较大的样本不平衡,会对模型学习造成困扰。样本不平衡常用的解决方法有过采样和欠采样,本项目处理样本不平衡采用的是过采样的方法,具体操作使用SMOTE(SyntheticMinority Oversampling Technique)
# pip install imblearn
from imblearn.over_sampling import SMOTE # 近邻规则,创造一些新数据
print('在过采样之前样本比例:\n',y.value_counts())
在过采样之前样本比例:0 284315
1 492
Name: Class, dtype: int64
smote = SMOTE()
# X,y是数据
X,y = smote.fit_resample(X,y)
print('在过采样之后样本比例是:\n',y)
在过采样之后样本比例是:0 0
1 0
2 0
3 0
4 0..
568625 1
568626 1
568627 1
568628 1
568629 1
Name: Class, Length: 568630, dtype: int64
y.value_counts()
0 284315
1 284315
Name: Class, dtype: int64
3.2、算法建模
3.2.1、准确率
model = LogisticRegression()
model.fit(X,y) # 样本是均衡的
y_ = model.predict(X)
print('逻辑斯蒂回归算准确率是:',accuracy_score(y,y_))
# 信用卡反欺诈,更希望算法,找到盗刷的交易!
# 正常交易,不关心!
逻辑斯蒂回归算准确率是: 0.9380581397393736
混淆矩阵和召回率
from sklearn.metrics import confusion_matrix # 混淆矩阵cm = confusion_matrix(y,y_)
print(cm)
recall = cm[1,1]/(cm[1,1] + cm[1,0])
print('召回率:',recall)
[[276963 7352][ 27870 256445]]
召回率: 0.9019749221813833
def plot_confusion_matrix(cm, classes,title='Confusion matrix',cmap=plt.cm.Blues):"""绘制预测结果与真实结果的混淆矩阵"""plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=0)plt.yticks(tick_marks, classes)thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, cm[i, j],horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.tight_layout()plt.ylabel('True label')plt.xlabel('Predicted label')
import itertools
plot_confusion_matrix(cm,classes=[0,1])

3.2.2、ROC与AUC
proba_ = model.predict_proba(X)[:,1]# 索引1,表示获取类别1的概率,正样本,阳性,信用卡盗刷fpr,tpr,thesholds_ = roc_curve(y,proba_)roc_auc = auc(fpr,tpr) # 曲线下面积# 绘制 ROC曲线
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b',label='AUC = %0.5f'% roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([-0.1,1.0])
plt.ylim([-0.1,1.01])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
Text(0.5, 0, 'False Positive Rate')
4、模型评估与优化
上一个步骤中,我们的模型训练和测试都在同一个数据集上进行,这样导致模型产生过拟合的问题。
一般来说,将数据集划分为训练集和测试集有3种处理方法:
- 留出法(hold-out)
- 交叉验证法(cross-validation)
- 自助法(bootstrapping)
本次项目采用的是交叉验证法划分数据集,将数据划分为3部分:训练集(training set)、验证集
(validation set)和测试集(test set)。让模型在训练集进行学习,在验证集上进行参数调优,最后使用测试集数据评估模型的性能。
模型调优我们采用网格搜索调优参数(grid search),通过构建参数候选集合,然后网格搜索会穷举各种参数组合,根据设定评定的评分机制找到最好的那一组设置。
结合cross-validation和grid search,具体操作我们采用scikit learn模块model_selection中的GridSearchCV方法。
4.1、交叉验证
- 交叉验证筛选参数
%%time
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)# 构建参数组合
param_grid = {'C': [0.01,0.1, 1, 10, 100, 1000,],'penalty': [ 'l1', 'l2']}# 确定模型LogisticRegression,和参数组合param_grid ,cv指定10折
grid_search = GridSearchCV(LogisticRegression(),param_grid,cv=10) grid_search.fit(X_train, y_train) # 使用训练集学习算法
Wall time: 1min 5sGridSearchCV(cv=10, estimator=LogisticRegression(),param_grid={'C': [0.01, 0.1, 1, 10, 100, 1000],'penalty': ['l1', 'l2']})
- 查看最佳参数
results = pd.DataFrame(grid_search.cv_results_)
display(results)
print("Best parameters: {}".format(grid_search.best_params_))
print("Best cross-validation score: {:.5f}".format(grid_search.best_score_))

Best parameters: {'C': 10, 'penalty': 'l2'}
Best cross-validation score: 0.93776
- 测评数据的评估
y_pred = grid_search.predict(X_test)print('准确率:',accuracy_score(y_test,y_pred))
准确率: 0.9391432038408104
- 分类效果评估报告
from sklearn.metrics import classification_report
print(classification_report(y_test,y_pred))
precision recall f1-score support0 0.91 0.98 0.94 569811 0.97 0.90 0.94 56745accuracy 0.94 113726macro avg 0.94 0.94 0.94 113726
weighted avg 0.94 0.94 0.94 1137264.2、混淆矩阵
# 生成测试数据混淆矩阵
cnf_matrix = confusion_matrix(y_test, y_pred)
np.set_printoptions(precision=2)print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))# 绘制模型优化后的混淆矩阵
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=class_names, title='Confusion matrix')
Recall metric in the testing dataset: 0.9031104062031897
从上可以看出,经过交叉验证训练和参数调优后,模型的性能有较大的提升,recall值从0.818上升到
0.9318,上升幅度达到11.34%。
4.3、模型评估
解决不同的问题,通常需要不同的指标来度量模型的性能。例如我们希望用算法来预测癌症是否是恶性的,假设100个病人中有5个病人的癌症是恶性,对于医生来说,尽可能提高模型的查全率(recall)比提高查准率(precision)更为重要,因为站在病人的角度,发生漏发现癌症为恶性比发生误判为癌症是恶性更为严重。
4.3.1、混淆矩阵
# 获得预测概率值
y_pred_proba = grid_search.predict_proba(X_test) thresholds = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9] # 设定不同阈值plt.figure(figsize=(15,10))
np.set_printoptions(precision=2)
j = 1
for t in thresholds:# 根据阈值转换为类别 y_pred = y_pred_proba[:,1] > tplt.subplot(3,3,j)j += 1# 计算混淆矩阵cnf_matrix = confusion_matrix(y_test, y_pred)print("召回率是:", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]),end = '\t')print('准确率是:',(cnf_matrix[0,0] + cnf_matrix[1,1])/(cnf_matrix.sum()))# 绘制混淆矩阵class_names = [0,1]plot_confusion_matrix(cnf_matrix, classes=class_names)
召回率是: 0.9837342497136311 准确率是: 0.8754814202557023
召回率是: 0.957952242488325 准确率是: 0.9291103177813341
召回率是: 0.9321878579610539 准确率是: 0.9376659690835869
召回率是: 0.9182835492113842 准确率是: 0.9406292316620649
召回率是: 0.9031104062031897 准确率是: 0.9391432038408104
召回率是: 0.8919904837430611 准确率是: 0.9371559713697836
召回率是: 0.8860516345052427 准确率是: 0.9368833863848196
召回率是: 0.8795312362322671 准确率是: 0.9348433955296063
召回率是: 0.8651158692395806 准确率是: 0.9291806622935829
从上可以看出,经过交叉验证训练和参数调优后,模型的性能有较大的提升,recall值从0.818上升到
0.9318,上升幅度达到11.34%。
4.3.2、精确率-召回率
from sklearn.metrics import precision_recall_curve
thresholds = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
colors = ['navy', 'turquoise', 'darkorange', 'cornflowerblue', 'teal', 'red', 'yellow', 'green', 'blue']plt.figure(figsize=(12,7))j = 1
for t,color in zip(thresholds,colors):y_pred = y_pred_proba[:,1] > t #预测出来的概率值是否大于阈值 precision, recall, threshold = precision_recall_curve(y_test, y_pred)area = auc(recall, precision)cm = confusion_matrix(y_test,y_pred)# TP/(TP + FN)r = cm[1,1]/(cm[1,0] + cm[1,1])# 绘制 Precision-Recall curveplt.plot(recall, precision, color=color,label='Threshold=%s, AUC=%0.3f, recall=%0.3f' %(t,area,r))plt.xlabel('Recall')plt.ylabel('Precision')plt.ylim([0.0, 1.05])plt.xlim([0.0, 1.0])plt.title('Precision-Recall Curve')plt.legend(loc="lower left")

4.3.3、ROC曲线
thresholds = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
colors = ['navy', 'turquoise', 'darkorange', 'cornflowerblue', 'teal', 'red', 'yellow', 'green', 'blue']plt.figure(figsize=(12,7))j = 1
for t,color in zip(thresholds,colors):
# y_pred = grid_search.predict(X_teste) # 算法预测测试数据的值y_pred = y_pred_proba[:,1] >= t #预测出来的概率值是否大于阈值 (人为) cm = confusion_matrix(y_test,y_pred)# TP/(TP + FP)precision = cm[1,1]/(cm[0,1] + cm[1,1])fpr,tpr,_ = roc_curve(y_test,y_pred)accuracy = accuracy_score(y_test,y_pred)auc_ = auc(fpr,tpr)# 绘制 ROC curveplt.plot(fpr, tpr, color=color,label='Threshold=%s, AUC=%0.3f, precision=%0.3f' %(t , auc_,precision))plt.xlabel('FPR')plt.ylabel('TPR')plt.ylim([0.0, 1.05])plt.xlim([0.0, 1.0])plt.title('ROC Curve')plt.legend(loc="lower right")

4.3.4、各评估指标趋势图
'''
true negatives:`C_{0,0}`
false negatives: `C_{1,0}`
true positives is:`C_{1,1}`
false positives is :`C_{0,1}`
'''
thresholds = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
recalls = [] # 召回率
precisions = [] # 精确度
aucs = [] # 曲线下面积
y_pred_proba = grid_search.predict_proba(X_test)
for threshold in thresholds:y_ = y_pred_proba[:,1] >= thresholdcm = confusion_matrix(y_test,y_)# TP/(TP + FN)recalls.append(cm[1,1]/(cm[1,0] + cm[1,1])) # 召回率,从真的癌症患者中找出来的比例,200,85个,42.5%# TP/(TP + FP)precisions.append(cm[1,1]/(cm[0,1] + cm[1,1])) # 精确率,找到癌症患者,100个,85个真的,15个没病,预测有病fpr,tpr,_ = roc_curve(y_test,y_)auc_ = auc(fpr,tpr)aucs.append(auc_)plt.figure(figsize=(12,6))
plt.plot(thresholds,recalls,label = 'Recall')
plt.plot(thresholds,aucs,label = 'auc')
plt.plot(thresholds,precisions,label = 'precision')
plt.legend()
plt.xlabel('thresholds')
Text(0.5, 0, 'thresholds')
4.4、最优阈值
precision和recall是一组矛盾的变量。从上面混淆矩阵和PRC曲线、ROC曲线可以看到,阈值越小,
recall值越大,模型能找出信用卡被盗刷的数量也就更多,但换来的代价是误判的数量也较大。随着阈值的提高,recall值逐渐降低,precision值也逐渐提高,误判的数量也随之减少。通过调整模型阈值,控制模型反信用卡欺诈的力度,若想找出更多的信用卡被盗刷就设置较小的阈值,反之,则设置较大的阈值。
实际业务中,阈值的选择取决于公司业务边际利润和边际成本的比较;当模型阈值设置较小的值,确实能找出更多的信用卡被盗刷的持卡人,但随着误判数量增加,不仅加大了贷后团队的工作量,也会降低误判为信用卡被盗刷客户的消费体验,从而导致客户满意度下降,如果某个模型阈值能让业务的边际利润和边际成本达到平衡时,则该模型的阈值为最优值。当然也有例外的情况,发生金融危机,往往伴随着贷款违约或信用卡被盗刷的几率会增大,而金融机构会更愿意不惜一切代价守住风险的底线。
相关文章:
【机器学习】Kaggle实战信用卡反欺诈预测(场景解析、数据预处理、特征工程、模型训练、模型评估与优化)
构建信用卡反欺诈预测模型 建模思路 本项目需解决的问题 本项目通过利用信用卡的历史交易数据,进行机器学习,构建信用卡反欺诈预测模型,提前发现客户信用卡被盗刷的事件。 项目背景 数据集包含由欧洲持卡人于2013年9月使用信用卡进行交的…...

【RISC-V CPU debug 专栏 4 -- RV CSR寄存器介绍】
文章目录 Overview1. CSR寄存器访问指令2. 为何CSR地址不是4字节对齐(1) CSR寄存器空间是独立的地址空间(2) 节省编码空间(3) 对硬件实现的简化 3. CSR的物理大小和对齐无关4. RISC-V 中的 GPR 寄存器及其作用GPR 的详细用途CSR(控制状态寄存器)与 GPR 的…...
 完整指南)
Object.defineProperty() 完整指南
Object.defineProperty() 完整指南 1. 基本概念 Object.defineProperty() 方法允许精确地添加或修改对象的属性。默认情况下,使用此方法添加的属性是不可修改的。 1.1 基本语法 Object.defineProperty(obj, prop, descriptor)参数说明: obj: 要定义…...

postgresql函数创建
postgresql的函数创建 1.创建函数的基本语法: CREATE [OR REPLACE] FUNCTION function_name(parameter_list) RETURNS return_type AS $$ BEGIN -- 函数体 END; $$ LANGUAGE language_name;2.创建函数时传入参数示例:add_user tbl_user表 | id | username | …...

ECMAScript 变量
文章目录 前言一、ECMAScript 变量二、var 关键字1、var 声明作用域2、var 声明提升(hoist)三、let 关键字四、const 关键字🔰 总结前言 任何语言的核心所描述的都是这门语言在最基本的层面上如何工作,涉及 语法、操作符、数据类型以及内置功能,在此基础之上才可以构建复…...

CAN总线波形中最后一位电平偏高或ACK电平偏高问题分析
参考:https://zhuanlan.zhihu.com/p/689336144 有时候看到CAN总线H和L的差值波形的最后一位电平会变高很多,这是什么原因呢? 实际上这是正常的现象,最后一位是ACK位。问题描述为:CAN总线ACK电平偏高。 下面分析下原因…...

【C++】22___STL常用算法
目录 一、常用遍历算法 二、常用查找算法 2.1 find 2.2 其它查找算法 三、常用排序算法 3.1 sort 3.2 其它排序算法 四、拷贝 & 替换 4.1 copy 4.2 其它算法 五、常用的算数生成算法 5.1 accumulate 5.2 fill 六、常用集合算法 6.1 set_intersection 6…...

意静明和-十成
十成 责任(健康)、使命(事业)、信念(意义)、自律(排诱)、自修(知识)、总结(四为)、执行(一事不拖)、人情&…...

easyui textbox使用placeholder无效
easyui textbox使用placeholder无效 在easyui 的textbox控件,请使用data-options 设定 示例 <input type text class easyui-textbox data-options "prompt:请输入您的邮箱"/>...

flux中的缓存
1. cache,onBackpressureBuffer。都是缓存。cache可以将hot流的数据缓存起来。onBackpressureBuffer也是缓存,但是当下游消费者的处理速度比上游生产者慢时,上游生产的数据会被暂时存储在缓冲区中,防止丢失。 2. Flux.range 默认…...

代码重定位详解
文章目录 一、段的概念以及重定位的引入1.1 问题的引入1.2 段的概念1.3 重定位 二、如何实现重定位2.1 程序中含有什么?2.2 谁来做重定位?2.3 怎么做重定位和清除BSS段?2.4 加载地址和链接地址的区别 三、散列文件使用与分析3.1 重定位的实质…...
活动预告 | Microsoft 365 在线技术公开课:让组织针对 Microsoft Copilot 做好准备
课程介绍 通过Microsoft Learn免费参加Microsoft 365在线技术公开课,建立您需要的技能,以创造新的机会并加速您对Microsoft云技术的理解。参加我们举办的“让组织针对 Microsoft Copilot for Microsoft 365 做好准备” 在线技术公开课活动,学…...

从0到机器视觉工程师(一):机器视觉工业相机总结
目录 相机的作用 工业相机 工业相机的优点 工业相机的种类 工业相机知名品牌 光源与打光 打光方式 亮暗场照明 亮暗场照明的应用 亮暗场照明的区别 前向光漫射照明 背光照明 背光照明的原理 背光照明的应用 同轴光照明 同轴光照明的应用 总结 相机的作用 相机…...
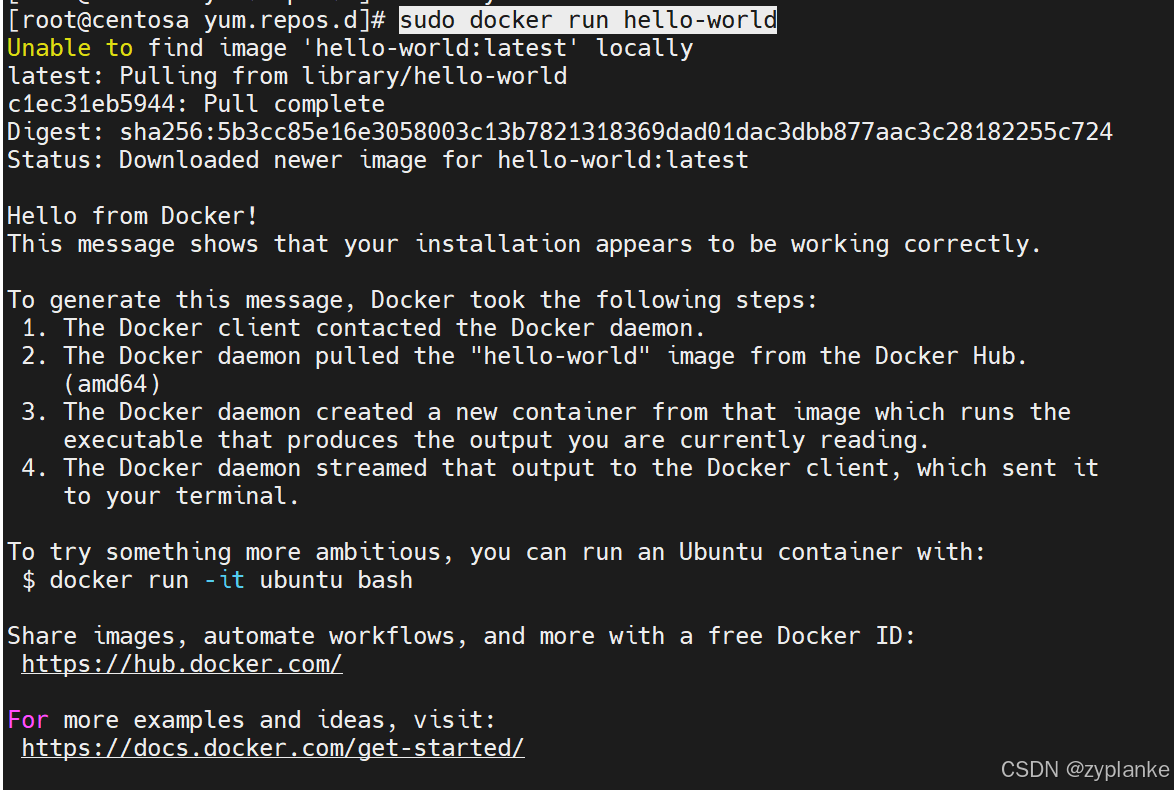
Docker安装(Docker Engine安装)
一、Docker Engine和Desktop区别 Docker Engine 核心组件:Docker Engine是Docker的核心运行时引擎,负责构建、运行和管理容器。它包括守护进程(dockerd)、API和命令行工具客户端(docker)。适用环境&#…...

数组的深度监听deep
场景:组件提供的emit事件可能被占用,在不能使用事件提交的情况下,就要上watch数组监听了,但是是发现只有在数组的长度发生变化的时候才会触发监听,这怎么行。。。。。 对于对象数组的深度监听,如果没有正确…...

点击锁定按钮,锁定按钮要变成解锁按钮,然后状态要从待绑定变成 已锁定(升级版)
文章目录 1、updateInviteCodeStatus2、handleLock3、InviteCodeController4、InviteCodeService5、CrudRepository 点击锁定按钮,锁定按钮要变成解锁按钮,然后状态要从待绑定变成 已锁定:https://blog.csdn.net/m0_65152767/article/details…...

UniApp 性能优化策略
一、引言 在当今数字化时代,移动应用的性能成为影响用户留存与满意度的关键因素。UniApp 作为一款热门的跨平台开发框架,以一套代码适配多端的特性极大提升了开发效率,但同时也面临着性能优化的挑战。优化 UniApp 性能,不仅能够让…...

【Linux报告】实训六 重置超级用户密码
实训六 重置超级用户密码 2018编写-今日公布 【练习一】忘记root密码 步骤一:开启或重启系统,并且要在五秒之内按任何键; 步骤二:按任意键,停止进入系统,按【e】键,跳转新页面,再…...

smolagents:一个用于构建代理的简单库
HF推出 smolagents,一个非常简单的库,它能够解锁语言模型的代理功能。以下是它的简要介绍: from smolagents import CodeAgent, DuckDuckGoSearchTool, HfApiModelagent CodeAgent(tools[DuckDuckGoSearchTool()], modelHfApiModel())agent…...

通过Dockerfile来实现项目可以指定读取不同环境的yml包
通过Dockerfile来实现项目可以指定读取不同环境的yml包 1. 挂载目录2. DockerFile3. 运行脚本deploy.sh4. 运行查看日志进入容器 5. 接口测试修改application-dev.yml 6. 优化Dockerfile7. 部分参数解释8. 优化不同环境下的日志也不同调整 Dockerfile修改部署脚本 deploy.sh重新…...

系统架构设计师-2025年05月综合案例回忆版
试题 试题一(必选题) 某公司开发一个在线大模型训练平台,支持Python代码编写、模型训练和部署,用户通过python编写模型代码,将代码交给系统进行模型代码的解析,最终由系统匹配相应的计算机资源进行输出,用户不需要关心底层硬件平台,在开发该平台架构时,设计了以下质…...

记一次 mac openClaw gateway 启动未正常关闭导致的问题
openclaw 目前是一个比较火的 AI 工具,因为其高权限带来了一系列的风险和安全隐患按照官方步骤删除后,因open claw 的 gateway 没有正常关闭,导致端口一直在后台运行如果您也遇到类似的问题,可在 mac 终端执行如下命令进行关闭1.先…...

我的第一个CANOpen主站:手把手教你用CanFestival-3源码配置心跳、SYNC和PDO映射
我的第一个CANOpen主站:手把手教你用CanFestival-3源码配置心跳、SYNC和PDO映射 当你第一次面对工业现场总线协议时,那种既兴奋又忐忑的心情我至今记忆犹新。CANOpen作为工业自动化领域的"普通话",其主站开发往往是工程师进阶路上的…...

2025最新易支付模板源码 全开源 前台+用户中心+后台三合一
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示三、学习资料下载一、详细介绍 2025最新易支付模板源码 全开源 前台用户中心后台三合一 二、效果展示 1.部分代码 代码如下(示例): case orderList:$sql" 11";if(isse…...

前端工程化19:微前端架构实战,大型中台项目拆分落地方案
前端工程化19:微前端架构实战,大型中台项目拆分落地方案 文章目录 前端工程化19:微前端架构实战,大型中台项目拆分落地方案 前言 一、微前端核心概念 1. 什么是微前端 2. 核心优势 3. 企业主流使用场景 二、主流微前端方案选型对比 三、整体项目架构划分 四、实战搭建 Qian…...

从VBS到VBE:一次搞懂Windows脚本编码器的前世今生与实战避坑
从VBS到VBE:Windows脚本编码器的技术考古与安全实践 在Windows系统管理的工具箱里,VBScript(VBS)曾经是自动化任务的瑞士军刀。尽管如今PowerShell和现代编程语言已成为主流,但理解VBScript及其编码器(VBE&…...

WIFI6 OFDMA工作原理
WiFi6 OFDMA 工作原理 一、OFDMA 基础定义与诞生背景 1. 名词释义 OFDMA:Orthogonal Frequency Division Multiple Access,正交频分多址 前身:WiFi4/WiFi5 使用 OFDM(正交频分复用),仅做单用户频域调制升级…...

移动端测试实战:App兼容性测试的全套解决方案
一、移动端App兼容性测试的核心价值与挑战在移动互联网生态中,设备碎片化、系统版本迭代加速、网络环境多样性等因素,使得App兼容性问题成为影响用户体验与产品口碑的关键变量。据行业数据统计,兼容性问题引发的用户投诉占比超过30%ÿ…...

基于SpringBoot的电影院选座购票系统毕业设计源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot框架的电影院选座购票系统以解决传统影院票务管理中存在的效率低下与用户体验不足等问题。当前电影院票务系统普遍采用单体架…...
)
ESP32玩转1.8寸LCD屏:用TFT_eSPI库做个桌面小时钟(附完整代码)
ESP32打造高颜值桌面时钟:从TFT_eSPI库到完整项目实战 在创客的世界里,将硬件与代码结合创造出实用又有趣的项目总是令人兴奋。今天我们要用ESP32开发板和1.8寸ST7735驱动的LCD屏幕,打造一个功能完善、界面美观的桌面电子时钟。这个项目不仅适…...