python爬虫--小白篇【selenium自动爬取文件】
一、问题描述
在学习或工作中需要爬取文件资源时,由于文件数量太多,手动单个下载文件效率低,操作麻烦,采用selenium框架自动爬取文件数据是不二选择。如需要爬取下面网站中包含的全部pdf文件,并将其转为Markdown格式。
 二、解决办法
二、解决办法
首先查看网页的源代码,定位到具体的pdf文件下载链接:
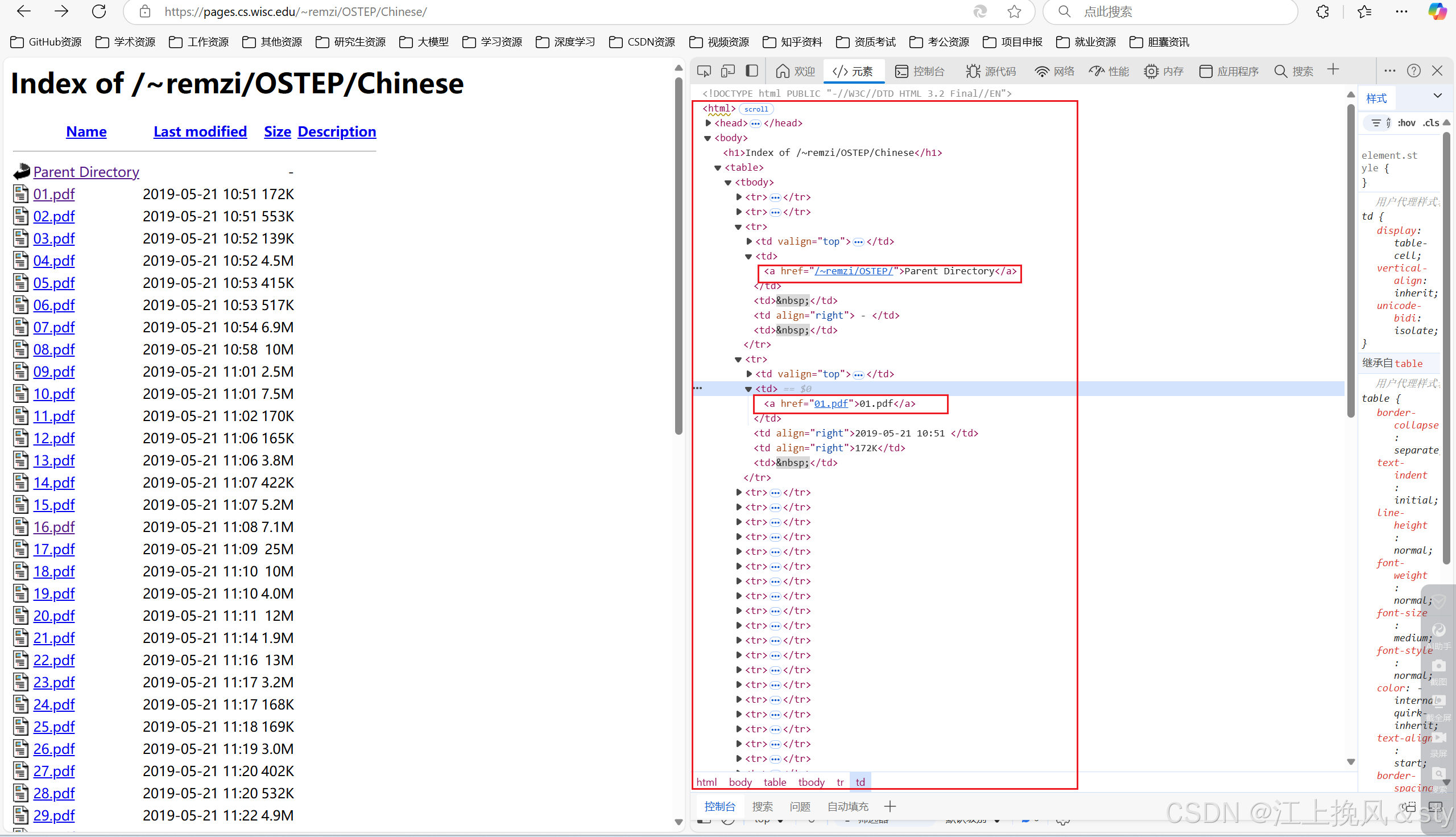
编写脚本,自动爬取网页pdf文件资源:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import timedownload_dir = r"D:\ProjectCode\Spider\StudySpider08\PDF" # 设置下载目录
# 设置Selenium WebDriver
service = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')
options = Options()
options.add_experimental_option("prefs", {"download.default_directory": download_dir, # 设置默认下载路径"download.prompt_for_download": False, # 禁用下载前的确认对话框"download.directory_upgrade": True,"plugins.always_open_pdf_externally": True # 禁用PDF预览,直接下载
})driver = webdriver.Edge(service=service, options=options)# 目标网页URL
url = "https://pages.cs.wisc.edu/~remzi/OSTEP/Chinese/"# 使用get方法打开网页
driver.get(url)
driver.maximize_window()
time.sleep(2)# 等待页面加载完成
WebDriverWait(driver, 20).until(EC.presence_of_all_elements_located((By.XPATH, "/html/body/table/tbody/tr[68]/td[4]")))pdf_links = driver.find_elements(By.XPATH, "/html/body/table/tbody/tr/td[2]/a") # Adjusted XPathfor index, link in enumerate(pdf_links):if index == 16:continue # 跳过第一个链接if link.is_displayed(): # 检查元素是否可见href = link.get_attribute('href') # 获取PDF链接print(href)driver.execute_script("window.open('');") # 在新标签页打开链接driver.switch_to.window(driver.window_handles[-1]) # 切换到新标签页driver.get(href) # 获取PDF链接time.sleep(5) # 等待PDF下载完成driver.close() # 关闭新标签页driver.switch_to.window(driver.window_handles[0]) # 切换回原标签页# 关闭浏览器
driver.quit()下载得到全部的pdf文件并保存到本地:
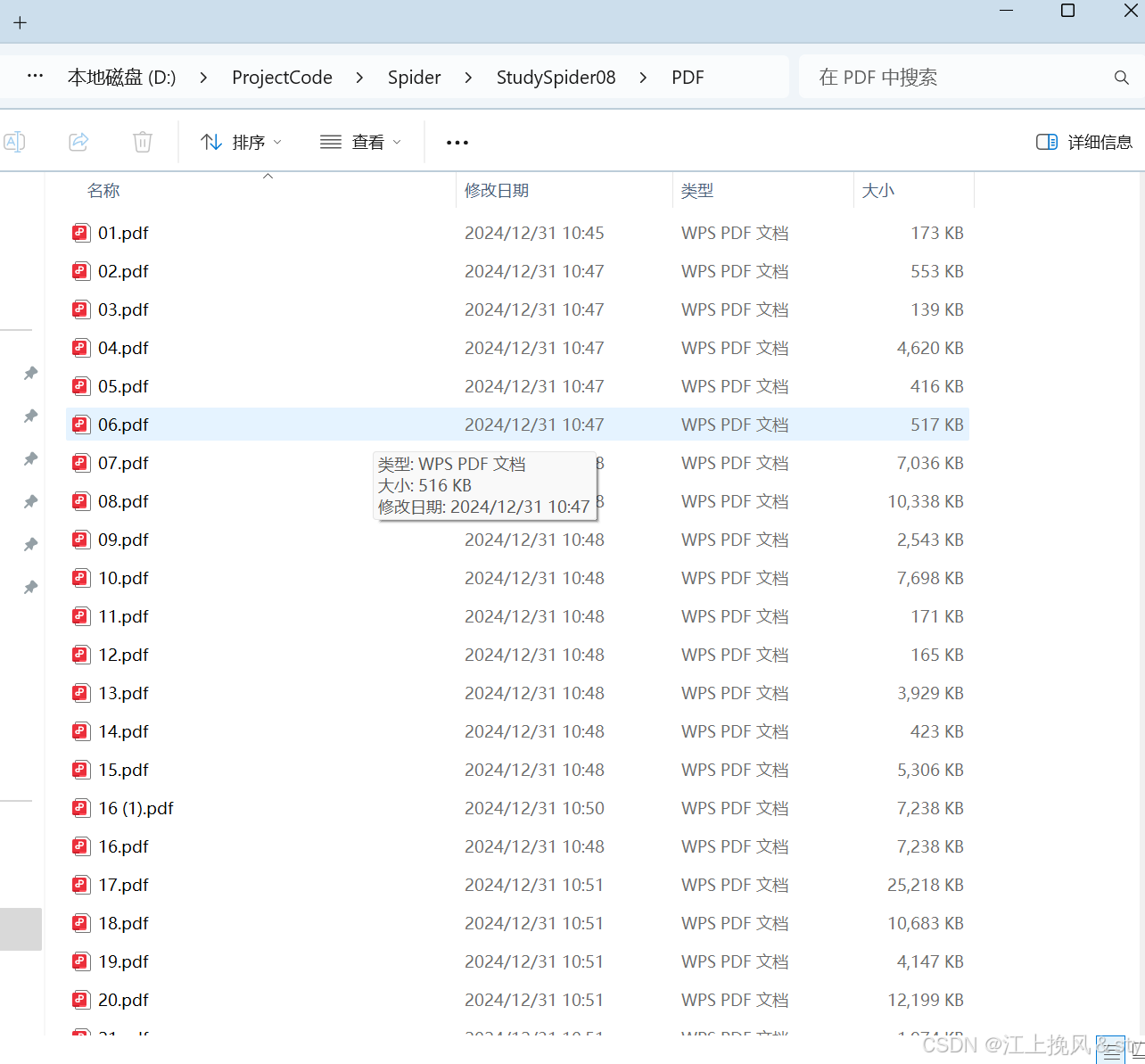
将本地保存的pdf文件全部转为Markdown格式:
# 首先先安装pdfminer.six库
pip install pdfminer.six"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :pdf2md
@Time :2024/12/31 10:38
@Motto:一直努力,一直奋进,保持平常心"""
import os
from pdfminer.high_level import extract_text# 定义包含PDF文件的文件夹路径
pdf_folder_path = 'D:\ProjectCode\Spider\StudySpider08\PDF'
# 定义输出Markdown文件的文件夹路径
md_folder_path = 'D:\ProjectCode\Spider\StudySpider08\MD'# 确保Markdown文件夹存在
if not os.path.exists(md_folder_path):os.makedirs(md_folder_path)# 遍历文件夹中的所有文件
for filename in os.listdir(pdf_folder_path):if filename.lower().endswith('.pdf'):# 构建PDF文件的完整路径pdf_path = os.path.join(pdf_folder_path, filename)# 构建Markdown文件的完整路径md_filename = os.path.splitext(filename)[0] + '.md'md_path = os.path.join(md_folder_path, md_filename)# 提取PDF文件中的文本text = extract_text(pdf_path)# 将提取的文本保存为Markdown文件with open(md_path, 'w', encoding='utf-8') as md_file:md_file.write(text)print(f"{md_filename}已转成功!")print("PDF to Markdown conversion is complete.")得到转换后的MD格式文件:
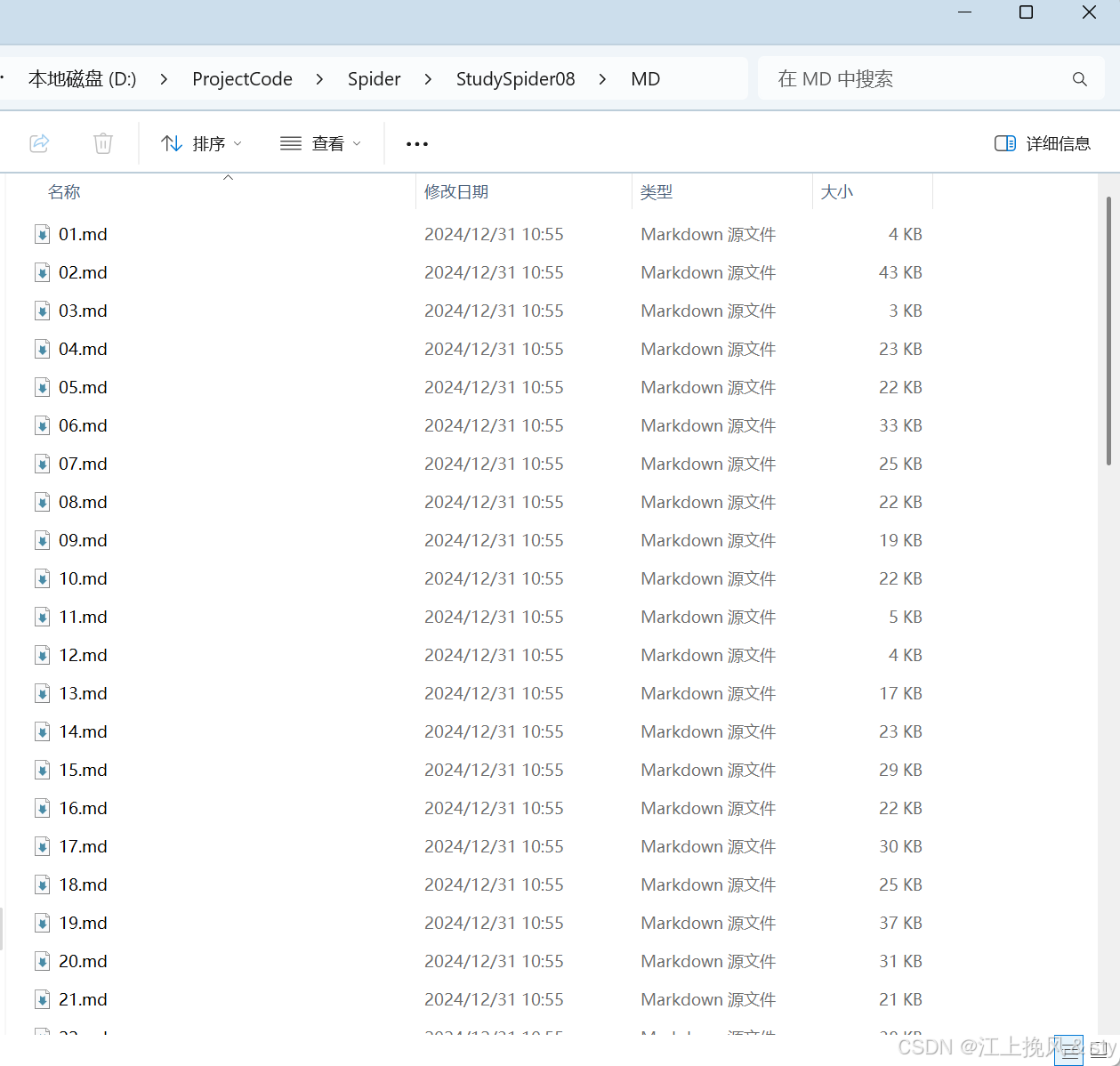
原本觉得效率不是很高,想采用多线程的方式提升效率,但结果表明效率也没提升多少。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.edge.options import Options
import time
from concurrent.futures import ThreadPoolExecutor# 定义下载PDF文件的函数
def download_pdf(index, link, driver_options, download_dir):service = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')driver = webdriver.Edge(service=service, options=driver_options)# 目标网页URLurl = link.get_attribute('href')# 使用get方法打开网页driver.get(url)driver.maximize_window()time.sleep(2)# 等待页面加载完成WebDriverWait(driver, 20).until(EC.presence_of_all_elements_located((By.TAG_NAME, "body")))# 等待PDF下载完成time.sleep(5) # 这里可能需要根据实际情况调整等待时间# 关闭浏览器driver.quit()# 设置下载目录
download_dir = r"D:\ProjectCode\Spider\StudySpider08\PDF"
# 设置Selenium WebDriver
options = Options()
options.add_experimental_option("prefs", {"download.default_directory": download_dir, # 设置默认下载路径"download.prompt_for_download": False, # 禁用下载前的确认对话框"download.directory_upgrade": True,"plugins.always_open_pdf_externally": True # 禁用PDF预览,直接下载
})# 目标网页URL
url = "https://pages.cs.wisc.edu/~remzi/OSTEP/Chinese/"# 使用get方法打开网页
driver = webdriver.Edge(service=Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe'), options=options)
driver.get(url)
driver.maximize_window()
time.sleep(2)# 等待页面加载完成
WebDriverWait(driver, 20).until(EC.presence_of_all_elements_located((By.XPATH, "/html/body/table/tbody/tr[68]/td[4]")))pdf_links = driver.find_elements(By.XPATH, "/html/body/table/tbody/tr/td[2]/a") # Adjusted XPath# 创建一个包含四个线程的线程池
with ThreadPoolExecutor(max_workers=4) as executor:for index, link in enumerate(pdf_links):if index == 0:continue # 跳过第一个链接if link.is_displayed(): # 检查元素是否可见executor.submit(download_pdf, index, link, options, download_dir)# 关闭浏览器
driver.quit()print("所有PDF文件下载完成。")
相关文章:
python爬虫--小白篇【selenium自动爬取文件】
一、问题描述 在学习或工作中需要爬取文件资源时,由于文件数量太多,手动单个下载文件效率低,操作麻烦,采用selenium框架自动爬取文件数据是不二选择。如需要爬取下面网站中包含的全部pdf文件,并将其转为Markdown格式。…...

TI毫米波雷达原始数据解析之Lane数据交换
TI毫米波雷达原始数据解析之Lane数据交换 背景Lane 定义Lane 确认确认LVDS Lane 数量的Matlab 代码数据格式参考 背景 解析使用mmWave Studio 抓取的ADC Data Lane 定义 芯片与DCA100之间的数据使用LVDS接口传输,使用mmWave Studio 配置过程中有一个选项是LVDS L…...

overscroll-behavior-解决H5在ios上过度滚动的默认行为
1. 问题 开发H5的过程中,经常会有android和ios两边系统需要兼容的情况。在ios上一直有个问题是当H5内容触及到页面顶部或底部时,还是可以被人为的往下或往下拉动界面。当然可能有的情况是比较适用的,比如你往下拉动,然后在导航栏…...

Nacos配置中心总结
Nacos配置中心总结 Nacos配置文件的加载顺序和优先级 加载顺序 nacos作为配置中心时,需要在bootstrap.yml文件中添加nacos config相关的配置,这样系统启动时就能先去拉取nacos server上的配置了。拉取过来后会和本地配置文件进行合并。 bootstrap.ym…...

rouyi(前后端分离版本)配置
从gitee上下载,复制下载地址,到 点击Clone,下载完成, 先运行后端,在运行前端 运行后端: 1.配置数据库,在Navicat软件中,连接->mysql->名字自己起(rouyi-vue-blog),用户名roo…...

超大规模分类(一):噪声对比估计(Noise Contrastive Estimation, NCE)
NCE损失对应的论文为《A fast and simple algorithm for training neural probabilistic language models》,发表于2012年的ICML会议。 背景 在2012年,语言模型一般采用n-gram的方法,统计单词/上下文间的共现关系,比神经概率语言…...

Windows 下安装 triton 教程
目录 背景解决方法方法一:(治标不治本)方法二:(triton-windows)- 安装 MSVC 和 Windows SDK- vcredist 安装- whl 安装- 验证 背景 triton 目前官方只有Linux 版本,若未安装,则会出…...

复盘与导出工具最新版9.15重磅发布-全新UI兼容所有windows系统
在9.11版本的基础上大更新: 1.应付费用户需求修复当更换明亮风格时软件超过电脑屏幕的bug!!!!! 2.支持所有windows版本,32/64位的win xp/7/8/10/11 3.修复开盘啦涨停原因排序bug 4.全新ui风格 5提前爆料:.9.2版本的分开…...

家用电器销售系统|Java|SSM|JSP|
【技术栈】 1⃣️:架构: B/S、MVC 2⃣️:系统环境:Windowsh/Mac 3⃣️:开发环境:IDEA、JDK1.8、Maven、Mysql5.7 4⃣️:技术栈:Java、Mysql、SSM、Mybatis-Plus、JSP、jquery,html 5⃣️数据库可…...

NRF24L01模块通信实验
NRF24L01简要介绍 这里主要介绍模块的最重要的参数,废话就不多介绍了。 该模块是一款无线通信模块,一个模块即可同时具备发射和接收数据的功能,但是要想实现通信必须使用两个模块之间才能进行通信。NRF24L01模块使用的总线控制方式为SPI总…...

2024年12月CCF-GESP编程能力等级认证Scratch图形化编程三级真题解析
本文收录于《Scratch等级认证CCF-GESP图形化真题解析》专栏,专栏总目录:点这里,订阅后可阅读专栏内所有文章。 一、单选题(一共 15 个题目,每题 2 分,共 30 分) 第 1 题 2024 年 10 月 8 日,诺贝尔物理学奖“意外地”颁给了两位计算机科学家约翰霍普菲尔德(John J. …...

【MySQL系列】VARCHAR为啥一般是255
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

图文教程:使用PowerDesigner导出数据库表结构为Word/Html文档
1、第一种情况-无数据库表,但有数据模型 1.1 使用PowerDesigner已完成数据建模 您已经使用PowerDesigner完成数据库建模,如下图: 1.2 Report配置和导出 1、点击:Report->Reports,如下图: 2、点击&…...

Coroutine 基础五 —— Flow 之 Channel 篇
1、Channel 与 Flow 简介与对比 所有知识都可总结为一个字 —— 流。包括数据流、事件流、状态流。 开发中最常用的 StateFlow 提供状态订阅。可以将一些信息包进 StateFlow 中进行保存。比如界面上显示的字符串,或者系统级别的信息,如用户状态。装进 …...

快速掌握Elasticsearch检索之二:滚动查询(scrool)获取全量数据(golang)
Elasticsearch8.17.0在mac上的安装 Kibana8.17.0在mac上的安装 Elasticsearch检索方案之一:使用fromsize实现分页 1、滚动查询的使用场景 滚动查询区别于上一篇文章介绍的使用from、size分页检索,最大的特点是,它能够检索超过10000条外的…...
)
C++设计模式:状态模式(自动售货机)
什么是状态模式? 状态模式是一种行为型设计模式,它允许一个对象在其内部状态发生改变时,动态改变其行为。通过将状态相关的逻辑封装到独立的类中,状态模式能够将状态管理与行为解耦,从而让系统更加灵活和可维护。 通…...

【网络安全实验室】脚本关实战详情
难道向上攀爬的那条路,不是比站在顶峰更让人热血澎湃吗 1.key又又找不到了 点击链接,burp抓包,发送到重放模块,点击go 得到key 2.快速口算 python3脚本 得到key 3.这个题目是空的 试了一圈最后发现是 4.怎么就是不弹出key呢…...

ts总结一下
ts基础应用 /*** 泛型工具类型*/ interface IProps {id: string;title: string;children: number[]; } type omita Omit<IProps, id | title>; const omitaA: omita {children: [1] }; type picka Pick<IProps, id | title>; const pickaA: picka {id: ,title…...

MySQL数据库笔记——主从复制
大家好,这里是Good Note,关注 公主号:Goodnote,本文详细介绍 MySQL的主从复制,从原理到配置再到同步过程。 文章目录 简介核心组件主从复制的原理作用主从复制的线程模型主从复制的模式形式复制的方式设计复制机制主从…...

OpenAI发布o3:圣诞前夜的AI惊喜,颠覆性突破还是技术焦虑?
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

从‘假阳性’到精准匹配:深入解读NAAF如何用‘负面线索’优化你的多模态搜索系统
从‘假阳性’到精准匹配:NAAF框架如何重塑多模态搜索系统的评估逻辑 当用户在电商平台搜索"白色连衣裙 蕾丝边 长袖"时,系统返回的前几条结果中混入了无袖款式;内容审核系统将"沙滩排球比赛"的文本描述错误匹配到一群孩子…...

ESP32秒变双模调试器:一份代码实现有线DAP-LINK与无线WiFi调试自由切换
ESP32双模调试器实战:有线DAP-LINK与无线WiFi的智能切换方案 在嵌入式开发领域,调试工具的选择往往决定了开发效率的上限。传统调试方案通常需要在有线连接的高性能和无线调试的灵活性之间做出取舍,而ESP32芯片的出现为这个困境提供了全新的…...

机器学习入门实战指南:从零搭建环境到完成第一个分类项目
1. 项目概述:从零开始的机器学习之旅“机器学习”这个词,听起来是不是既酷炫又让人望而生畏?你可能在新闻里看到它驱动着自动驾驶汽车,在手机里体验过它带来的智能推荐,甚至听说它正在改变各行各业。但当你真正想自己动…...

别再手动改端口了!用这个OrCAD小补丁,3分钟搞定原理图端口标准化
告别混乱设计:OrCAD端口标准化高效解决方案 在复杂的电子设计项目中,原理图的整洁与规范程度直接影响着团队协作效率和后期维护成本。当多位工程师共同参与同一项目时,端口类型和朝向的不统一往往成为困扰PCB设计团队的常见问题。这种看似微小…...

保姆级教程:用QGIS 3.22.16给火星遥感影像‘抠图’,从创建矢量图层到GDAL裁剪一步到位
火星地质勘探实战:用QGIS精准提取毅力号影像的五大核心技巧 当第一缕阳光掠过火星杰泽罗陨石坑的悬崖,毅力号传回的遥感影像中藏着无数科学秘密。作为太空数据分析师,我们常需要从广袤的火星地表影像中精确"抠"出目标区域——就像地…...

终极指南:HS2-HF_Patch汉化补丁完全免费使用手册
终极指南:HS2-HF_Patch汉化补丁完全免费使用手册 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的日文界面而烦恼吗ÿ…...
)
用Proteus玩转Arduino?别忘了这些电阻的‘潜规则’(附光敏电阻模拟方案)
用Proteus玩转Arduino?别忘了这些电阻的‘潜规则’(附光敏电阻模拟方案) 在虚拟原型开发领域,Proteus与Arduino的结合为创客们提供了无限可能。但许多开发者往往忽略了电路仿真中最基础的元件——电阻的巧妙运用。本文将揭示那些鲜…...

测试工程师必知的10个Linux命令:提升工作效率的利器
在软件测试领域,Linux系统是绕不开的重要工具。绝大多数应用后台都部署在Linux服务器上,从环境搭建、日志分析到性能监控,熟练掌握Linux命令能让测试工程师的工作效率大幅提升。不同职级的测试工程师对Linux的需求各有侧重:初级工…...

如何构建拼多多数据采集系统:面向电商决策者的战略投资方案
如何构建拼多多数据采集系统:面向电商决策者的战略投资方案 【免费下载链接】scrapy-pinduoduo 拼多多爬虫,抓取拼多多热销商品信息和评论 项目地址: https://gitcode.com/gh_mirrors/sc/scrapy-pinduoduo 在拼多多平台占据中国电商市场重要份额的…...

告别传统编程:用AI语音命令5倍速开发Godot游戏
告别传统编程:用AI语音命令5倍速开发Godot游戏 【免费下载链接】Godot-MCP An MCP for Godot that lets you create and edit games in the Godot game engine with tools like Claude 项目地址: https://gitcode.com/gh_mirrors/god/Godot-MCP 还在为复杂的…...