数据的高级处理——pandas模块进阶——数据的统计运算
今天的学习用有好几处与书上的内容有出入,不只是因为pycharm中函数更新、弃用的问题,还是作者有些疏忽。不过影响不大,运行报错,GPT分析一下,原因很简单。这里不进行详细书名,在下边的代码上已经进行详细的备注,这里不浪费时间了。
主要内容:
1、数据的统计运算,包括求和、平均值、最值、分别要用到sum()函数、mean()函数、max()函数、min()函数。
2、获取数值分布情况,在pandas模块中的describe()函数可以按列获取数据表中所有数值数据的分布情况, 包括数据的个数、均值、最值、方差、分位数等。
3、计算相关系数,使用corr()函数计算数据表data中各列之间的相关系数,如果仅计算数值数据,则在corr()函数添加参数numeric_only=True。
4、分组汇总数据,pandas模块中的groupby()函数可以对数据进行分组,依据“产品”列对数据进行分组,在对分组后的数据分别进行求和运算。b=data.groupby("产品").sum()
5、创建数据透视表,a=pd.pivot_table(data,values="利润(元)",index="产品",aggfunc="sum") 这句代码中,参数values用于指定要计算的列; 参数index用于指定一个列作为数据透视表的行标签; 参数aggfunc表示values的计算类型,sum表示求和。当然也可以指定多列,b=pd.pivot_table(data,values=["利润(元)","成本(元)"],index="产品",aggfunc="sum")
##############################
##作者:白雪公主的后妈
##时间:2024年1月1日
##主题:数据的高级处理——pandas模块进阶——数据的统计运算
##主要内容:常见的统计运算包括求和、平均值、最值、分别要用到sum()函数、mean()函数、max()函数、min()函数。
##############################
#1、数据的统计运算
#1.1求和 #pandas模块中的sum()函数可以对数据的每一列数据分别进行求和。
import pandas as pd
data=pd.read_excel("E:\\python\\Python_Code\\Excel\\产品统计表.xlsx",sheet_name=0)
a=data.sum()
print(a)
'''
运行结果:
编号 a001a002a003a004a005a006a007
产品 背包钱包背包手提包钱包单肩包单肩包
成本价(元/个) 364
销售价(元/个) 899
数量(个) 358
成本(元) 20802
收入(元) 48157
利润(元) 27319
dtype: object
#从运行结果可以看出,对非数值数据,运算结果是将它们依次来连接得到一个字符串;
对于数值数据,运算结果才是数据之和。
'''
#############也可以对某一列进行求和
a=data["利润(元)"].sum()
print(a)
'''
运行结果:
27319
'''
#1.2、求平均值 在pandas模块中mean()函数可以对所有数值数据列分别计算平均值。
data=pd.read_excel("E:\\python\\Python_Code\\Excel\\产品统计表.xlsx",sheet_name=0)
c=data.mean(numeric_only=True) #在python爬虫、数据分析与可视化中132页,小编直接c=data.mean() 即可,我认为有两种可能,一种小编可能忘写了,另外一种使用的pycharm版本的函数不同。
print(c)
'''
运行结果:
成本价(元/个) 52.000000
销售价(元/个) 128.428571
数量(个) 51.142857
成本(元) 2971.714286
收入(元) 6879.571429
利润(元) 3902.714286
dtype: float64
'''
################
d=data["利润(元)"].mean() #对某一列计算其平均值
print(d)
'''
运行结果:
3902.714285714286
'''
#1.3求最值 max()和min()函数
e=data.max()
print(e)
'''
运行结果:
编号 a007
产品 钱包
成本价(元/个) 90
销售价(元/个) 187
数量(个) 78
成本(元) 7020
收入(元) 14586
利润(元) 7566
dtype: object
'''
########对数据表中某一列进行求解最大值
f=data["利润(元)"].max()
print(f)
'''
运行结果:
7566
'''
#2、获取数值分布情况
'''
在pandas模块中的describe()函数可以按列获取数据表中所有数值数据的分布情况,
包括数据的个数、均值、最值、方差、分位数等
'''
data=pd.read_excel("E:\\python\\Python_Code\\Excel\\产品统计表.xlsx",sheet_name=0)
a=data.describe()
print(a)
'''
运行结果:成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
count 7.000000 7.000000 7.000000 7.000000 7.000000 7.000000
mean 52.000000 128.428571 51.142857 2971.714286 6879.571429 3902.714286
std 31.112698 50.483849 20.053500 2391.447659 4352.763331 2005.138957
min 16.000000 65.000000 23.000000 368.000000 1495.000000 1127.000000
25% 26.000000 94.500000 38.000000 948.000000 3861.000000 2895.000000
50% 58.000000 124.000000 58.000000 3364.000000 7192.000000 3828.000000
75% 74.000000 167.000000 61.500000 4077.000000 8581.000000 4504.000000
max 90.000000 187.000000 78.000000 7020.000000 14586.000000 7566.000000
'''
###########也可以单独看成一列数据
b=data["利润(元)"].describe()
print(b)
'''
运行结果:
count 7.000000
mean 3902.714286
std 2005.138957
min 1127.000000
25% 2895.000000
50% 3828.000000
75% 4504.000000
max 7566.000000
Name: 利润(元), dtype: float64
'''
#3、计算相关系数
'''
相关系数通常用来衡量两个或者多个元素间的相关程度,使用pandas模块中的corr()函数可以计算相关系数。
'''
import pandas as pd
data=pd.read_excel("E:\\python\\Python_Code\\Excel\\相关性分析.xlsx",sheet_name=0)
print(data)
'''
运行结果:代理商编号 年销售额(万元) 年广告费投入额(万元) 成本费用(万元) 管理费用(万元)
0 A-001 20.5 5.6 2.00 0.80
1 A-003 24.5 16.7 2.54 0.94
2 B-002 31.8 20.4 2.96 0.88
3 B-006 34.9 22.6 3.02 0.79
4 B-008 39.4 25.7 3.14 0.84
5 C-003 44.5 28.8 4.00 0.80
6 C-004 49.6 32.1 6.86 0.85
7 C-007 54.8 35.9 5.60 0.91
8 D-006 58.5 38.7 6.45 0.90
'''
##########使用corr()函数计算数据表data中各列之间的相关系数。
a=data.corr(numeric_only=True) #numeric_only=True表示只处理数值型列表
print(a)
'''
运行结果:年销售额(万元) 年广告费投入额(万元) 成本费用(万元) 管理费用(万元)
年销售额(万元) 1.000000 0.976664 0.913472 0.218317
年广告费投入额(万元) 0.976664 1.000000 0.875142 0.306296
成本费用(万元) 0.913472 0.875142 1.000000 0.283494
管理费用(万元) 0.218317 0.306296 0.283494 1.000000
'''
##################如果只想查看某一列与其他列的相关系数,可以用列表签来指定列。
b=data.corr(numeric_only=True)["年销售额(万元)"]
print(b)
'''
运行结果:
年销售额(万元) 1.000000
年广告费投入额(万元) 0.976664
成本费用(万元) 0.913472
管理费用(万元) 0.218317
Name: 年销售额(万元), dtype: float64
'''
#4、分组汇总数据
#pandas模块中的groupby()函数可以对数据进行分组
import numpy as np
data=pd.read_excel("E:\\python\\Python_Code\\Excel\\产品统计表.xlsx",sheet_name=0)
a=data.groupby("产品")
print(a)
'''
运行结果:
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001751C0BC470>
不能直观的展现,需要配合1节介绍的函数对其进行求和、求平均值、求最值等特定的汇总计算
'''
#########举例:依据“产品”列对数据进行分组,在对分组后的数据分别进行求和运算
# 删除编号列
data = data.drop(columns=['编号']) #书中不用加这行直接运行后出现一下运行结果,但是我运行以后存在编号列,需要对“编号”列继续删除
b=data.groupby("产品").sum()
print(b)
'''
运行结果:成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
产品
单肩包 116 248 121 7018 15004 7986
手提包 36 147 26 936 3822 2886
背包 32 130 83 1328 5395 4031
钱包 180 374 128 11520 23936 12416
'''
c=data.groupby("产品")["利润(元)"].sum()
print(c)
'''
运行结果:
产品
单肩包 7986
手提包 2886
背包 4031
钱包 12416
Name: 利润(元), dtype: int64
'''
#######当然也可以选择多列进行分组后汇总计算
d=data.groupby("产品")[["数量(个)","利润(元)"]].sum() #这里与书中的也有所不同d=data.groupby("产品")["数量(个)","利润(元)"].sum()
print(d)
'''
运行结果:数量(个) 利润(元)
产品
单肩包 121 7986
手提包 26 2886
背包 83 4031
钱包 128 12416
'''
#5、创建数据透视表
import numpy as np
data=pd.read_excel("E:\\python\\Python_Code\\Excel\\产品统计表.xlsx",sheet_name=0)
a=pd.pivot_table(data,values="利润(元)",index="产品",aggfunc="sum")
print(a)
'''
a=pd.pivot_table(data,values="利润(元)",index="产品",aggfunc="sum")
这句代码中,参数values用于指定要计算的列;
参数index用于指定一个列作为数据透视表的行标签;
参数aggfunc表示values的计算类型,sum表示求和。
运行结果:利润(元)
产品
单肩包 7986
手提包 2886
背包 4031
钱包 12416
'''
###########可以计算多列
b=pd.pivot_table(data,values=["利润(元)","成本(元)"],index="产品",aggfunc="sum")
print(b)
'''利润(元) 成本(元)
产品
单肩包 7986 7018
手提包 2886 936
背包 4031 1328
钱包 12416 11520
'''相关文章:

数据的高级处理——pandas模块进阶——数据的统计运算
今天的学习用有好几处与书上的内容有出入,不只是因为pycharm中函数更新、弃用的问题,还是作者有些疏忽。不过影响不大,运行报错,GPT分析一下,原因很简单。这里不进行详细书名,在下边的代码上已经进行详细的…...

【Leetcode】3280. 将日期转换为二进制表示
文章目录 题目思路代码复杂度分析时间复杂度空间复杂度 结果总结 题目 题目链接🔗 给你一个字符串 date,它的格式为 yyyy-mm-dd,表示一个公历日期。 date 可以重写为二进制表示,只需要将年、月、日分别转换为对应的二进制表示&a…...
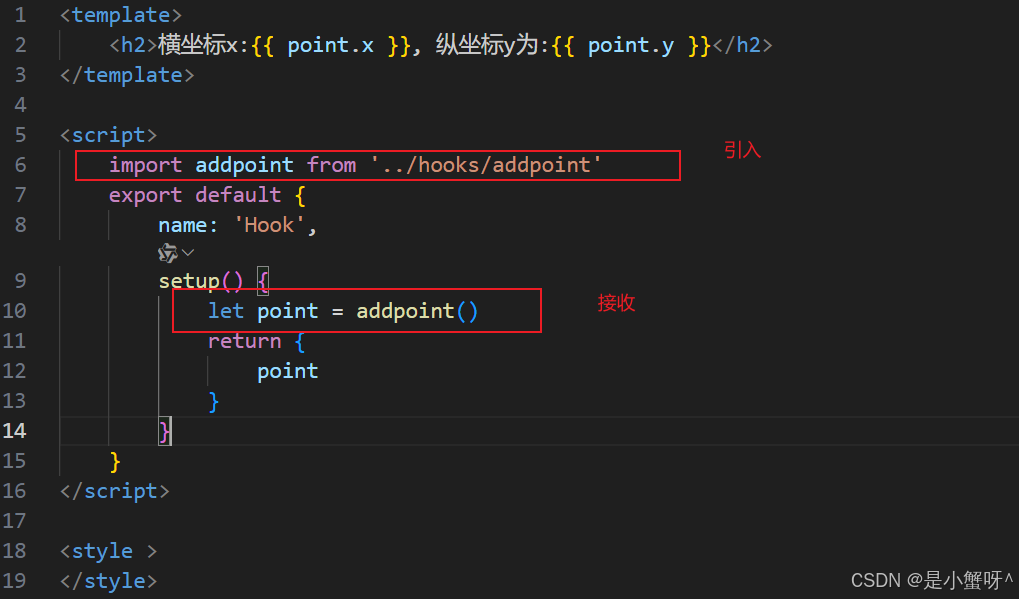
Vue3 中自定义hook
什么是hook?—— 本质是一个函数,把setup函数中使用的Composition API进行了封装,类似于vue2.x中的mixin。 自定义hook的优势:复用代码, 让setup中的逻辑更清楚易懂。 场景需求:现在我需要获取当前鼠标所点击的地方的…...

嵌入式系统 第七讲 ARM-Linux内核
• 7.1 ARM-Linux内核简介 • 内核:是一个操作系统的核心。是基于硬件的第一层软件扩充, 提供操作系统的最基本的功能,是操作系统工作的基础,它负责管理系统的进程、内存、设备驱动程序、文件和网络系统, 决定着系统的…...

音视频入门基础:MPEG2-PS专题(2)——使用FFmpeg命令生成ps文件
一、错误的命令 通过FFmpeg命令可以将mp4文件转换为ps文件,PS文件中包含PS流数据。 由于PS流/PS文件对应的FFInputFormat结构为: const FFInputFormat ff_mpegps_demuxer {.p.name "mpeg",.p.long_name NULL_IF_CONFIG_SMALL…...

Embedding
Embedding 在机器学习中,Embedding 主要是指将离散的高维数据(如文字、图片、音频)映射到低纬度的连续向量空间。这个过程会生成由实数构成的向量,用于捕捉原始数据的潜在关系和结构。 Text Embedding工作原理 词向量化&#x…...

Android Studio学习笔记
01-课程前面的话 02-Android 发展历程 03-Android 开发机器配置要求 04-Android Studio与SDK下载安装 05-创建工程与创建模拟器...
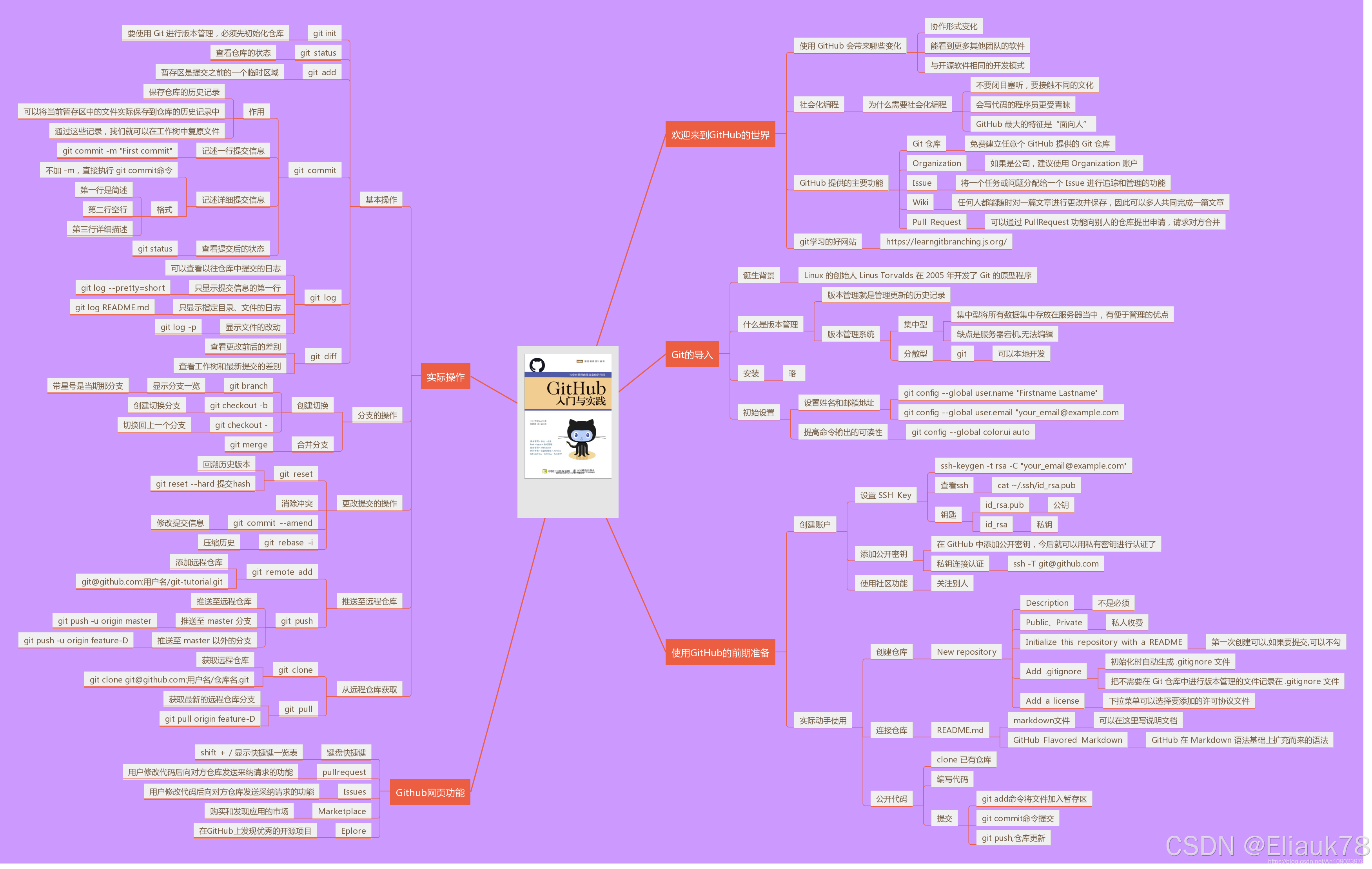
Git的使用流程(详细教程)
目录 01.Git是什么? 1.1 Git简介 1.2 SVN与Git的最主要的区别 1.3 GIt主要特点 02.Git是干什么的? 2.1.Git概念汇总 2.2 工作区/暂存区/仓库 2.3 Git使用流程 03.Git的安装配置 3.1 Git的配置文件 3.2 配置-初始化用户 3.3 Git可视化…...
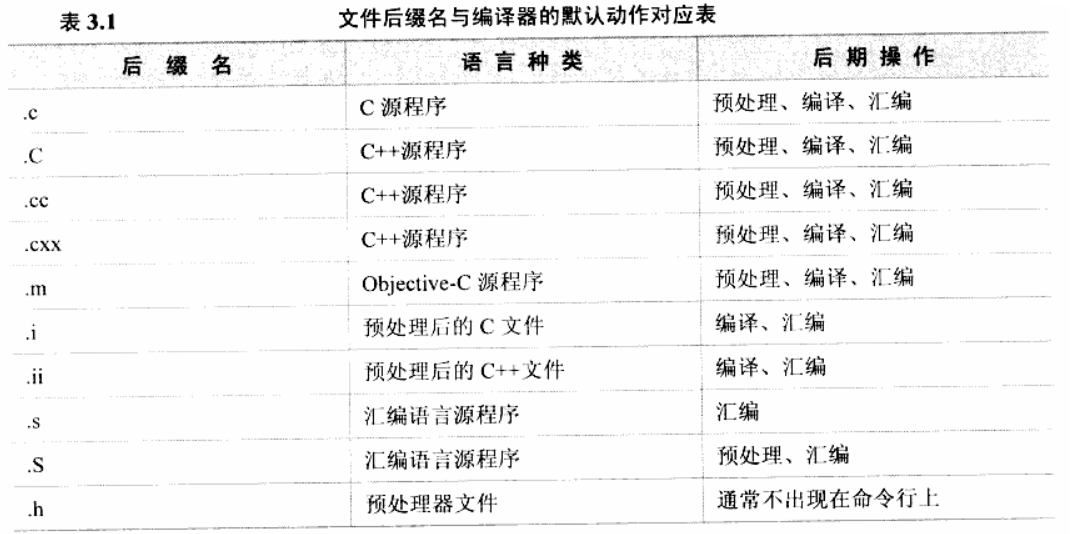
Keil中的gcc
文章目录 一、IDE背后的命令1.1 IDE是什么1.2 IDE的背后是命令1.3 有两套主要的编译器 二、准备工作2.1 arm-linux-gcc和gcc是类似的2.2 Code::Blocks2.2.1 设置windows环境变量2.2.2 命令行示例 三、gcc编译过程详解3.1 程序编译4步骤3.2 gcc的使用方法3.2.1 gcc使用示例3.2.2…...

bilibili 哔哩哔哩小游戏SDK接入
小游戏的文档 简介 bilibili小游戏bilibili小游戏具有便捷、轻量、免安装的特点。游戏包由云端托管,在哔哩哔哩APP内投放和运行,体验流畅,安全可靠。https://miniapp.bilibili.com/small-game-doc/guide/intro/ 没想过接入这个sdk比ios还难…...
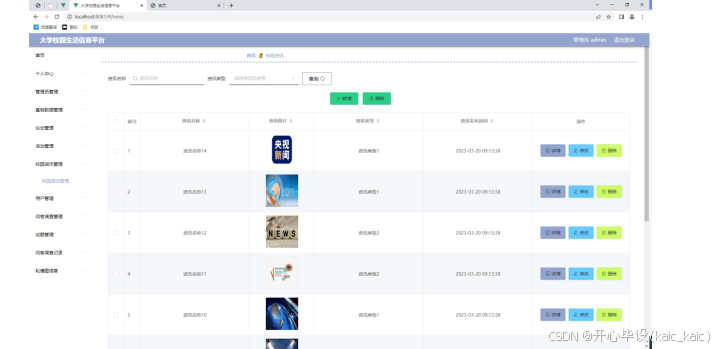
springboot523基于Spring Boot的大学校园生活信息平台的设计与实现(论文+源码)_kaic
摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本大学校园生活信息平台就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大的数据…...

【YOLO算法改进】ALSS-YOLO:无人机热红外图像|野生动物小目标检测
目录 论文信息 论文创新点 1.自适应轻量通道分割和洗牌(ALSS)模块 2.轻量坐标注意力(LCA)模块 3.单通道聚焦模块 4.FineSIOU损失函数 摘要 架构设计 轻量高效网络架构 - ALSS模块 LCA模块 单通道聚焦模块 损失函数优…...
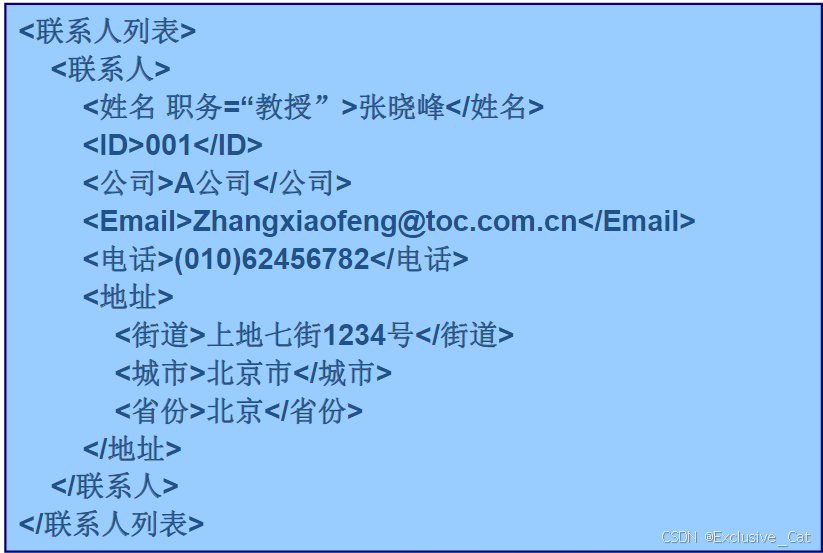
XML解析
一,XML概述 1.什么是XML XML即为可扩展的标记语言(eXtensible Markup Language) XML是一套定义语义标记的规则,这些标记将文档分成许多部件并对这些部件加以标识 2.XML和HTML不同之处 XML主要用于说明文档的主题,而…...

PlasmidFinder:质粒复制子的鉴定和分型
质粒(Plasmid)是一种细菌染色体外的线性或环状DNA分子,也是一种重要的遗传元素,它们具有自主复制能力,可以在细菌之间传播,并携带多种重要的基因(如耐药基因与毒力基因等)功能。根据质粒传播的特性…...

PTA数据结构作业一
6-1 链表的插入算法 本题要求实现一个插入函数,实现在链表llist中的元素x之后插入一个元素y的操作。 函数接口定义: int InsertPost_link(LinkList llist, DataType x, DataType y); 其中 llist是操作的链表,x是待插入元素y的前驱节点元素…...

2024年总结【第五年了】
2024年总结 北国绕院扫雪,南方围炉烹茶,且饮一杯无? 执笔温暖不曾起舞日子里的点点滴滴,誊写一段回忆,还以光阴一段副本。 那么你要听一支新故事吗?第五年总结的片碎。 衣单天寒,走趟流星孤骑…...

java实现一个kmp算法
1、什么是KMP算法 Kmp 算法是由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,改进字符串匹配的算法; Kmp 算法的核心是利用匹配失败的信息,尽量减少模式串与主串的匹配次数,以达到 快速匹配的目的; Kmp 算法的时…...

强化学习方法分类详解
强化学习方法分类详解 引言 强化学习(Reinforcement Learning, RL)是一种通过智能体与环境互动来学习如何做出最佳决策的方法。根据不同的优化中心、策略特性、环境模型、奖励函数、动作空间类型以及行为策略和目标策略的一致性,RL可以分为…...
)
雅思真题短语(二十八)
真题短语收录在合辑。 541法律官员 work as a solicitor 542前卫 a radical and expensive scheme 543反对者们 objectors 544破坏 demolishing buildings 545蒸汽机车 steam locomotives 546冷凝 steam could be condensed 547烟雾 smoke and fumes 548通风井 ventilation sh…...

在Linux系统中使用字符图案和VNC运行Qt Widgets程序
大部分服务器并没有GUI,运行的是基础的Linux系统,甚至是容器。如果我们需要在这些系统中运行带有GUI功能的Qt程序,一般情况下就会报错,比如: $ ./collidingmice qt.qpa.xcb: could not connect to display qt.qpa.plu…...

Perplexity症状查询功能性能对比白皮书:横向测试12家竞品,它在罕见病关键词召回率上领先41.6%,但时间敏感场景响应超时率达23.8%
更多请点击: https://intelliparadigm.com 第一章:Perplexity症状查询功能概览 Perplexity 是一款面向开发者与临床信息学研究人员设计的轻量级症状语义推理工具,其核心能力在于将自然语言描述的症状短语映射至标准化医学本体(如…...

5分钟搞定飞书文档转换:这款免费文档转换工具让你效率翻倍!
5分钟搞定飞书文档转换:这款免费文档转换工具让你效率翻倍! 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 还在为飞书文档格式转换而烦恼吗&a…...

51单片机计算器DIY:除了加减乘除,你的LCD1602和矩阵键盘还能这样玩?
51单片机计算器进阶指南:解锁LCD1602与矩阵键盘的隐藏玩法 当你在51单片机上成功实现了一个基础计算器后,是否想过这两个核心外设——LCD1602液晶屏和4x4矩阵键盘——还能玩出什么新花样?本文将带你超越简单的加减乘除,探索硬件模…...
)
手把手教你用Cubic为团队批量定制Ubuntu服务器模板镜像(含安全加固步骤)
企业级Ubuntu镜像定制实战:基于Cubic的自动化安全加固方案 在DevOps和云原生技术普及的今天,标准化系统镜像已成为企业IT基础设施的关键组成部分。想象一下这样的场景:当新服务器上线或集群需要扩容时,运维团队不再需要逐台安装系…...

Hi3403开发板内核升级至Linux 6.6:驱动适配与稳定性调优实战
1. 项目概述:一次内核升级背后的工程实践最近,我们团队完成了对迅为iTOP-Hi3403开发板配套SDK的一次重要更新,将内核版本从之前的长期支持版(LTS)升级到了最新的Linux 6.6。这不仅仅是一个版本号的跳动,对于…...

百度网盘macOS版加速插件完全指南:三步破解限速限制
百度网盘macOS版加速插件完全指南:三步破解限速限制 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 你是否也曾面对百度网盘macOS版那令人绝…...

Ubuntu下编译与测试libwebsockets:从x86环境验证到嵌入式移植
1. 项目概述与背景 在嵌入式开发中,尤其是涉及到网络通信模块时,我们常常会遇到一个典型的困境:直接在资源受限的目标板(比如ARM架构的开发板)上进行代码的编译、调试和功能验证,过程往往非常痛苦。编译速…...

Windows热键冲突终结者:Hotkey Detective深度解析与实战指南
Windows热键冲突终结者:Hotkey Detective深度解析与实战指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 想…...

JetBrains IDE试用期重置工具:开发者的智能许可证管家
JetBrains IDE试用期重置工具:开发者的智能许可证管家 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 当开发工具的试用期倒计时成为你编码时的心理负担,当每次启动IDE都要面对那个令人焦虑…...
)
从零开始:手把手教你用Python解析MMD的PMX模型文件(附完整代码)
从零开始:手把手教你用Python解析MMD的PMX模型文件(附完整代码) 在3D图形与游戏开发领域,MMD(MikuMikuDance)的PMX模型文件因其丰富的表情骨骼系统和精致的二次元风格而广受欢迎。本文将带领你从二进制层面…...