机器学习算法基础知识1:决策树
机器学习算法基础知识1:决策树
- 一、本文内容与前置知识点
- 1. 本文内容
- 2. 前置知识点
- 二、场景描述
- 三、决策树的训练
- 1. 决策树训练方式
- (1)分类原则-Gini
- (2)分类原则-entropy
- (3)加权系数-样本量
- (3)程序是如何实现的
- 2. 决策树构建结果
- 三、测试集验证
- 四、其他知识
- 五、参考文献
一、本文内容与前置知识点
1. 本文内容
介绍决策树是什么,使用场景有哪些
2. 前置知识点
- 概率论基本知识:信息熵增益
二、场景描述
- 鸢尾花的类别存在Setosa,Versicolour,Virginica三种,我们希望制作一个模型,对鸢尾花进行分类。
- 我们会提供一些我们已经采集的样本,并且手动提取了每朵花的部分特征,数据集一共包括150个样本,每个样本包括花萼长度,花萼宽度,花瓣长度,花瓣宽度特征,以及对应鸢尾花类别的标签第5列为鸢尾花的类别(包括Setosa,Versicolour,Virginica三类)。
三、决策树的训练
我们把150个样本,取出120个作为训练集,来进行决策树的训练,目的希望决策树这个分类器有如下效果:
(1)对于训练集的样本能有比较好的分类效果
(2)对于测试集的样本能有比较好的分类效果
1. 决策树训练方式
(1)分类原则-Gini
每一层会选取一个特征进行分类,以二分类为主,分类原则遵循贪心算法,希望尽可能的把样本区分开。
使用了基尼系数作为样本分类效果的评估指标:
G i n i = 1 − ∑ i = 1 n p i 2 Gini=1-\sum^n_{i=1}p_i^2 Gini=1−i=1∑npi2
可以看到样本分布越均匀,基尼系数越大,我们希望完成分类,也就是让基尼系数尽可能小,样本完全由同一类别构成的时候,基尼系数为0。
(2)分类原则-entropy
信息熵,同样的,样本的分布越均匀熵越大。
E n t r o p y = − ∑ i = 0 n p i log 2 ( p i ) Entropy=-\sum^n_{i=0}p_i\log_2{(p_i)} Entropy=−i=0∑npilog2(pi)
(3)加权系数-样本量
直观的考虑以下场景,三个类别个数分别为9,4,2,记为(9,4,2):
下一级分类有两种方案:
方案A:[(1,0,0),(8,4,2)]
方案B:[(8,0,0),(1,4,2)]
两种方案信息熵或基尼系数的加和相同,但是显然B尽可能多的把第一类分出去了,直观会认为更好。
从上述可以看出,分出的堆的大小同样应该被考虑进去进行loss的计算。
所以实际的loss会被记录为(二分类为例):
l o s s = m G i n i m + n G i n i n loss = mGini_m + nGini_n loss=mGinim+nGinin
m和n分别是所分出两堆的大小,用该等式计算信息量显然方案B会更小,方案B更合适。
(3)程序是如何实现的
程序枚举每个特征和阈值,在每层的数据中找出信息量最小的分类方式进行分类,逐层以这种贪心的方式进行分类
我们只要当好调包侠就行,不需要反复造轮子。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import tree
import matplotlib.pyplot as plt# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建决策树分类器
clf = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=42)
clf.fit(X_train, y_train)
print(iris.feature_names)
print(iris.target_names)
# 可视化决策树
plt.figure(figsize=(12, 8))
tree.plot_tree(clf, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()# 测试准确率
accuracy = clf.score(X_test, y_test)
print("测试集准确率:", accuracy)2. 决策树构建结果
(1)决策树常用作分类器,通过逐级进行条件判断的方式,将样本进行逐级分类,如下图:
(2)这个决策树通过逐级二分类的方式,将鸢尾花按照不同的特征进行分类。
(3)每个子节点得出最终分类结果,这个决策树是三层的,对于整个鸢尾花的分类结果上看,120个样本大部分都得到了很好的分类。但是有一个白色的子节点,仍然含有4朵花是vriginica,被识别成了versicolor。
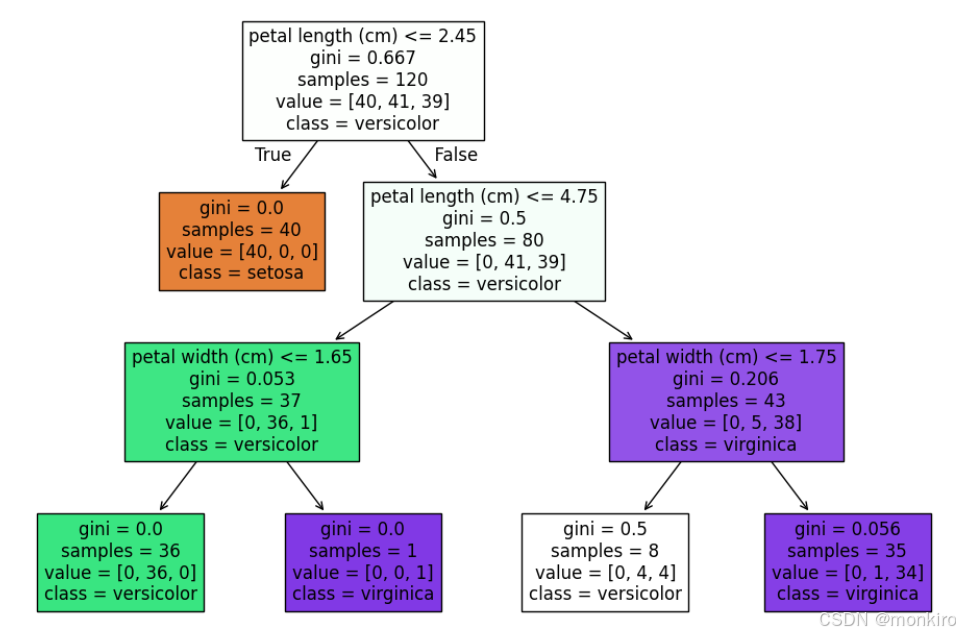
方框中每一行分别是
- 分类条件
- 基尼系数(表征样本的无序程度,假设样本全都是同一种,则基尼系数=0)
- 样本数
- 第四行是当前节点在分类中的归属类别。
三、测试集验证
把测试集放进去进行训练得到结果,验证决策树的训练效果
accuracy = clf.score(X_test, y_test)
print("测试集准确率:", accuracy)
四、其他知识
- 这里只介绍了决策树用于分类的做法,事实上还可以用于回归。
- 这里只介绍了Gini和信息熵增益的训练方式,事实上还有别的。
- 树的构建最大层数是需要合理考虑的,过浅分不出来,过深会由于一些极端点导致过拟合,设置合理的层数,允许一些训练集的点分类错误,都是常见的策略。
- 决策树本质上是不断的在线性空间进行线性分割,这一点有一点像SVM?
- 合理的树的深度会使用交叉验证的方式来进行估算
五、参考文献
五分钟机器学习:决策树
相关文章:
机器学习算法基础知识1:决策树
机器学习算法基础知识1:决策树 一、本文内容与前置知识点1. 本文内容2. 前置知识点 二、场景描述三、决策树的训练1. 决策树训练方式(1)分类原则-Gini(2)分类原则-entropy(3)加权系数-样本量&am…...
[Qt] 信号和槽(1) | 本质 | 使用 | 自定义
目录 一、信号和槽概述 二、本质 底层实现 1. 函数间的相互调用 2. 类成员中的特殊角色 三、使用 四. 自定义信号和槽 1. 基本语法 (1) 自定义信号函数书写规范 (2) 自定义槽函数书写规范 (3) 发送信号 (4) 示例 A. 示例一 B. 示例二 —— 老师说“上课了”&…...

33. 简易内存池
1、题目描述 ● 请实现一个简易内存池,根据请求命令完成内存分配和释放。 ● 内存池支持两种操作命令,REQUEST和RELEASE,其格式为: ● REQUEST请求的内存大小 表示请求分配指定大小内存,如果分配成功,返回分配到的内存…...
win32汇编环境,对话框程序模版,含文本框与菜单简单功能
;运行效果 ;win32汇编环境,对话框程序模版,含文本框与菜单简单功能 ;直接抄进RadAsm可编译运行。 ;下面为asm文件 ;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>&g…...

人工智能与传统编程的主要区别是什么?
传统编程:开发者预先编写软件行为规则,代码基于程序员定义逻辑处理输入并产生确定输出,具有确定性、手动编写规则和结构化逻辑特点,如垃圾邮件分类程序基于预设关键词等规则。AI 编程:从数据中学习而非手动编写规则&am…...

实战交易策略 篇十一:一揽子交易策略
文章目录 系列文章适用条件核心策略小额大量投资行业或主题聚焦同步操作优势系列文章 实战交易策略 篇一:奥利弗瓦莱士短线交易策略 实战交易策略 篇二:杰西利弗莫尔股票大作手操盘术策略 实战交易策略 篇三:333交易策略 实战交易策略 篇四:价值投资交易策略 实战交易策略…...
doris 2.1 -Data Manipulation-Transaction
注意:doris 只能控制读一致性,并不能rollback 1 Explicit and Implicit Transactions 1.1 Explicit Transactions 1.1.1 Explicit transactions require users to actively start, commit transactions. Only insert into values statement is supported in 2.1. BEGIN; …...
多模态融合:阿尔茨海默病检测
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 一、实验介绍 本实验包含 645 名阿尔茨海默病受试者,分为 AD、CN 和 MCI 组,数据集包含 3D MRI 图像与一份CSV数据,MRI数据…...
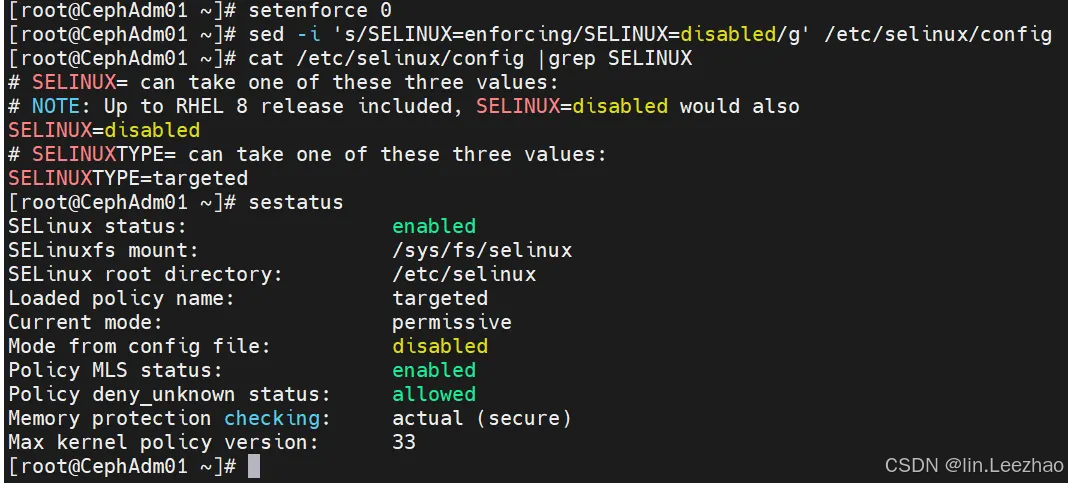
Ceph 手动部署(CentOS9)
#Ceph手动部署、CentOS9、squid版本、数字版本19.2.0 #部署服务:块、对象、文件 一、部署前规划 1、兼容性确认 2、资源规划 节点类型节点名称操作系统CPU/内存硬盘网络组件安装集群节点CephAdm01CentOS94U/8GOS:40G,OSD:2*100GIP1:192.169.0.9(管理&集群),IP2:…...
家政预约小程序05活动管理
目录 1 搭建活动管理页面2 搭建活动规则页面3 搭建规则新增页面3 配置规则跳转4 搭建活动参与记录总结 上一篇我们介绍了活动管理的表结构设计,本篇我们介绍一下后台功能。 1 搭建活动管理页面 我们一共搭建了三个表,先搭建主表的后台功能。打开我们的后…...

解决安装pynini和WeTextProcessing报错问题
点击这里,访问博客 0. 背景 最近在给别人有偿部署ASR-LLM-TTS项目时遇到安装pynini和WeTextProcessing依赖报错的问题,报错信息如下: IC:\Program Files (x86)\Windows Kits\10\include\10.0.22621.0\ucrt" "-IC:\Program Files…...

【PCIe 总线及设备入门学习专栏 4.1 -- PCI 总线的地址空间分配】
文章目录 Overview 本文转自:https://blog.chinaaet.com/justlxy/p/5100053219 Overview PCI 总线具有32位数据/地址复用总线,所以其存储地址空间为 2324GB。也就是PCI上的所有设备共同映射到这4GB上,每个PCI设备占用唯一的一段PCI地址&…...
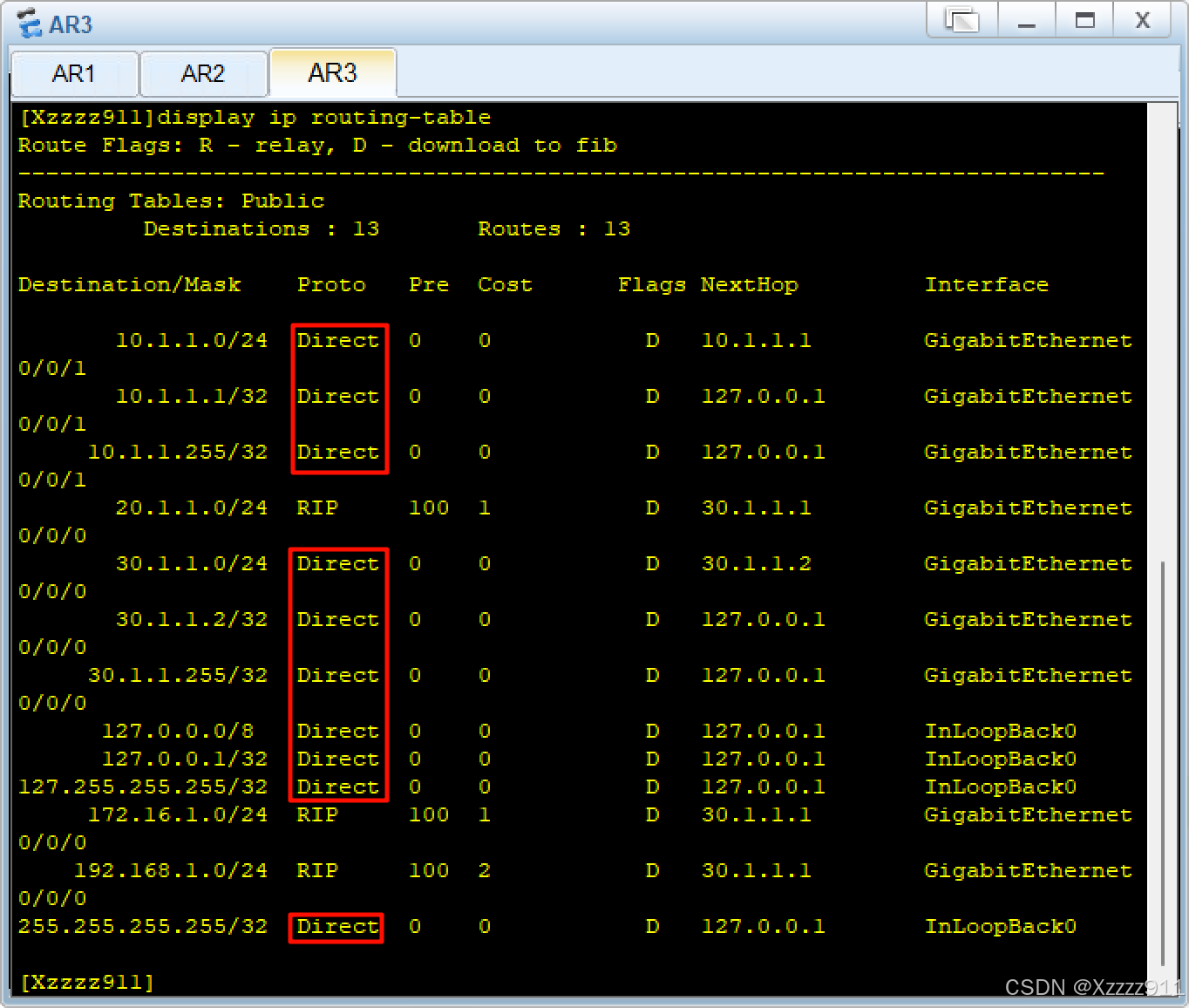
华为配置 之 RIP
简介: RIP(路由信息协议)是一种广泛使用的内部网关协议,基于距离向量算法来决定路径。它通过向全网广播路由控制信息来动态交换网络拓扑信息,从而计算出最佳路由路径。RIP易于配置和理解,非常适用于小型网络…...

探寻AI Agent:开启知识图谱自动生成新篇章(17/30)
一、AI Agent 与知识图谱:智能时代的双雄 在当今科技飞速发展的时代,人工智能如同一股汹涌澎湃的浪潮,正以前所未有的力量重塑着我们的世界。而在这股浪潮中,AI Agent 与知识图谱无疑是两颗最为璀璨的明珠,它们各自发挥…...
卸载wps后word图标没有变成白纸恢复
这几天下载了个wps教育版,后头用完了删了 用习惯的2019图标 给兄弟我干没了??? 其他老哥说什么卸载关联重新下 ,而且还要什么撤销保存原来的备份什么,兄弟也是不得不怂了 后头就发现了这个半宝藏博主&…...

LeetCode 热题 100_二叉树的直径(40_543_简单_C++)(二叉树;递归)
LeetCode 热题 100_二叉树的直径(40_543) 题目描述:输入输出样例:题解:解题思路:思路一(递归): 代码实现代码实现(思路一(递归)&#…...

【数据结构】线性数据结构——链表
1. 定义 链表是一种线性数据结构,由多个节点(Node)组成。每个节点存储数据和指向下一个节点的指针。与数组不同,链表的节点不需要在内存中连续存储。 2. 特点 动态存储: 链表的大小不固定,可以动态增加或…...

开源存储详解-分布式存储与ceph
ceph体系结构 rados:reliable, autonomous, distributed object storage, rados rados采用c开发 对象存储 ceph严格意义讲只提供对象存储能力,ceph的块存储能力实际是基于对象存储库librados的rbd 对象存储特点 对象存储采用put/get/delete…...

[算法] [leetcode-509] 斐波那契数
509 斐波那契数 斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是: F(0) 0,F(1) 1 F(n) F(n - 1) F(n - 2),其中 n…...

运维人员的Go语言学习路线
以下是一份更为详细的适合运维人员的Go语言学习路线图: 一、基础环境搭建与入门(第 1 - 2 周) 第 1 周 环境搭建 在本地开发机和常用的运维服务器环境(如 Linux 系统)中安装 Go 语言。从官方网站(https://…...

仓储AGV“大脑“江湖:这家公司拿下37%市场,却仍亏损1.7亿,还马上冲港股
导语大家好,这里是智能仓储物流技术研习社:专注分享智能制造和智能仓储物流等内容。专业书籍:《智能物流系统构成与技术实践》|《智能仓储项目英语手册》|《智能仓储项目必坑手册》|《智能仓储项目甲方必读》|《12大行业智能仓储实战指南》做…...

如何在Windows上完美使用苹果触控板:终极配置指南
如何在Windows上完美使用苹果触控板:终极配置指南 【免费下载链接】mac-precision-touchpad Windows Precision Touchpad Driver Implementation for Apple MacBook / Magic Trackpad 项目地址: https://gitcode.com/gh_mirrors/ma/mac-precision-touchpad 还…...

从‘看到’到‘看懂’:VSRN模型如何像人一样进行视觉语义推理?一个生动的案例拆解
从‘看到’到‘看懂’:VSRN模型如何像人一样进行视觉语义推理?一个生动的案例拆解 想象这样一个场景:你看到一张照片,画面中一只棕色的狗在绿色的草地上追逐飞盘。几乎瞬间,你的大脑就完成了从视觉感知到语义理解的完整…...

VS Code 迎来史诗级更新:全新 Agents 窗口发布
VS Code 在前几年古法编程时代,那就是 IDE 的王者。随着 AI Coding 的不断进步。虽然 VS Code 依托 github copilot 早早的就集成了 AI Coding 的能力。但是由于 VSCode 本身是一个 IDE ,它的核心能力还是文本编辑器。但是在 Claude, xcode 等…...

基于Next.js与Shadcn/ui的现代Web仪表盘开发实战指南
1. 项目概述与核心价值 最近在折腾一个开源项目,叫 openclaw-dashboard ,是 anis-marrouchi 大佬在 GitHub 上开源的一个仪表盘项目。光看名字,你可能会觉得这又是一个平平无奇的“又一个仪表盘”,但实际深入把玩之后&#x…...
)
从FLAN-T5到你的专属模型:如何用公司内部客服聊天记录做领域微调(附DialogSum实操对比)
从FLAN-T5到业务专属模型:领域微调实战指南 当通用大模型遇上垂直业务场景,性能落差往往令人沮丧。想象一个酒店预订客服场景:FLAN-T5可能把"我需要延迟入住"总结成"客户确认了入住时间",这种"幻觉"…...

搞定银河麒麟V10+飞腾平台Qt开发环境后,我总结的3个必做配置和1个字体坑
银河麒麟V10飞腾平台Qt开发环境深度调优指南 在国产化技术栈中,银河麒麟V10操作系统搭配飞腾D2000处理器的组合正逐渐成为自主可控解决方案的主流选择。对于需要在此平台上进行Qt开发的工程师而言,成功安装Qt仅仅是万里长征的第一步。本文将深入剖析三个…...

4步快速上手ESP32 Arduino开发:从零基础到第一个物联网项目
4步快速上手ESP32 Arduino开发:从零基础到第一个物联网项目 【免费下载链接】arduino-esp32 Arduino core for the ESP32 family of SoCs 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 还在为ESP32开发环境的复杂配置而烦恼吗࿱…...

通达信缠论智能分析插件:5分钟实现专业K线结构可视化
通达信缠论智能分析插件:5分钟实现专业K线结构可视化 【免费下载链接】Indicator 通达信缠论可视化分析插件 项目地址: https://gitcode.com/gh_mirrors/ind/Indicator 你是否曾在K线图中迷失方向,看着密密麻麻的蜡烛图却不知如何判断市场趋势&am…...

Python结构化日志实战:5 个让AI Agent 输出可调试的工程技巧
读完你能直接把“turn_id / tokens / tool / latency”这些关键字段写进 JSON 日志,并用一段 Python 在 10 秒内定位最费 token 的轮次。你可能遇到过:Agent 一开始很稳,过一阵子开始不稳定;你去查原因,日志只有 Turn …...