week05_nlp大模型训练·词向量文本向量
1、词向量训练
1.1 CBOW(两边预测中间)
一、CBOW 基本概念
CBOW 是一种用于生成词向量的方法,属于神经网络语言模型的一种。其核心思想是根据上下文来预测中心词。在 CBOW 中,输入是目标词的上下文词汇,输出是该目标词。
二、CBOW 的网络结构
1、输入层:
- 对于给定的一个窗口大小 (通常是一个奇数,例如n=5 ),考虑目标词wt及其前后各(n-1)/2个词作为上下文。假设我们的词汇表大小为V,每个词都可以表示为一个V维的 one-hot 向量。
- 对于上下文词
 和
和 (其中 ),它们的 one-hot 向量被输入到网络中。
(其中 ),它们的 one-hot 向量被输入到网络中。

2、投影层:
- 输入层的多个 one-hot 向量会被映射到一个投影层。
- 对于每个输入的 one-hot 向量,它会激活隐藏层中的一个神经元,而隐藏层的权重矩阵W(维度为V x N ,其中N是词向量的维度)将这些输入进行加权求和,得到一个N维的向量。



从数学上看,如果xi是第i个上下文词的 one-hot 向量,那么投影层的向量h可以表示为:

其中C = n-1是上下文词的数量。
3、隐藏层:
- 投影层的结果作为隐藏层的输入,隐藏层通常不进行非线性变换,直接将结果传递给输出层。
4、输出层:
- 输出层是一个 softmax 层,其神经元的数量等于词汇表的大小V 。
- 输出层的权重矩阵为
 (维度为 N x V),使用 softmax 函数将隐藏层的输出转换为概率分布:
(维度为 N x V),使用 softmax 函数将隐藏层的输出转换为概率分布:
其中 。
。 
三、训练过程
-
损失函数:
- 通常使用交叉熵损失函数:

其中 yj是真实目标词的 one-hot 向量, p(wj)是预测词的概率。
-
优化算法:
- 常用的优化算法是随机梯度下降(SGD)或其变种,如 Adagrad、Adadelta 等。
- 在训练过程中,通过反向传播算法更新权重矩阵 和 ,以最小化损失函数。
四、CBOW 的优点
-
考虑上下文信息:
- CBOW 利用了上下文信息来预测中心词,能够捕捉到词与词之间的语义关系。
-
计算效率:
- 对于每个训练样本,由于使用了上下文词的平均作为输入,CBOW 比 Skip-gram 在训练时计算量相对较小,尤其是在处理大规模语料库时,CBOW 可以更快地训练出较为不错的词向量。
五、CBOW 的缺点
- 对低频词不敏感:
CBOW 侧重于根据上下文预测中心词,对于低频词,由于它们在语料库中出现的频率低,在训练过程中得到的学习机会相对较少,因此生成的词向量可能不能很好地表示低频词的语义信息。
六、应用场景
-
词向量初始化:
- CBOW 可以为下游的 NLP 任务提供预训练的词向量,如文本分类、情感分析、命名实体识别等。将文本中的词替换为其对应的 CBOW 词向量,可以将文本表示为一个向量序列,为后续任务提供良好的输入表示。
-
词相似度计算:
- 训练好的词向量可以计算词与词之间的相似度,例如使用余弦相似度:

七、与 Skip-gram 的对比
- Skip-gram 与 CBOW 的区别在于,Skip-gram 是根据中心词预测上下文词,而 CBOW 是根据上下文词预测中心词。Skip-gram 更适合处理少量数据和低频词,因为它为每个中心词 - 上下文词对都进行单独的训练,而 CBOW 更适合处理大规模数据,因为它在计算上更高效。
八、示例代码(使用 gensim)
from gensim.models import Word2Vec
sentences = [["I", "love", "natural", "language", "processing"],["Word", "embeddings", "are", "useful"],["This", "is", "an", "example", "sentence"]]
# CBOW 模型训练,window 是窗口大小,min_count 是最小词频,sg=0 表示 CBOW 算法
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, sg=0)
# 获取词向量
vector = model.wv['love']
print(vector)#coding:utf8import torch
import torch.nn as nn
import numpy as np"""
基于pytorch的词向量CBOW
模型部分
"""class CBOW(nn.Module):def __init__(self, vocab_size, embedding_size, window_length):super(CBOW, self).__init__()self.word_vectors = nn.Embedding(vocab_size, embedding_size)self.pooling = nn.AvgPool1d(window_length)self.projection_layer = nn.Linear(embedding_size, vocab_size)def forward(self, context):context_embedding = self.word_vectors(context) #batch_size * max_length * embedding size 1*4*4#transpose: batch_size * embedding size * max_length -> pool: batch_size * embedding_size * 1 -> squeeze:batch_size * embeddig_sizecontext_embedding = self.pooling(context_embedding.transpose(1, 2)).squeeze()#batch_size * embeddig_size -> batch_size * vocab_sizepred = self.projection_layer(context_embedding)return predvocab_size = 8 #词表大小
embedding_size = 4 #人为指定的向量维度
window_length = 4 #窗口长度
model = CBOW(vocab_size, embedding_size, window_length)
#假如选取一个词窗口【1,2,3,4,5】·
context = torch.LongTensor([[1,2,4,5]]) #输入1,2,4,5, 预期输出3, 两边预测中间
pred = model(context)
print("预测值:", pred)# print("词向量矩阵")
# print(model.state_dict()["word_vectors.weight"])1.2 简单词向量模型(自主选择 CBOW or SkipGram 方法)
import json
import jieba
import numpy as np
import gensim
from gensim.models import Word2Vec
from collections import defaultdict'''
词向量模型的简单实现
'''#训练模型
#corpus: [["cat", "say", "meow"], ["dog", "say", "woof"]]
#corpus: [["今天", "天气", "不错"], ["你", "好", "吗"]]
#dim指定词向量的维度,如100
def train_word2vec_model(corpus, dim):model = Word2Vec(corpus, vector_size=dim, sg=1)model.save("model.w2v")return model#输入模型文件路径
#加载训练好的模型
def load_word2vec_model(path):model = Word2Vec.load(path)return modeldef main():sentences = []with open("corpus.txt", encoding="utf8") as f:for line in f:sentences.append(jieba.lcut(line))model = train_word2vec_model(sentences, 128)return modelif __name__ == "__main__":# model = main() #训练model = load_word2vec_model("model.w2v") #加载print(model.wv.most_similar(positive=["男人", "母亲"], negative=["女人"])) #类比while True: #找相似string = input("input:")try:print(model.wv.most_similar(string))except KeyError:print("输入词不存在")函数部分:
train_word2vec_model 函数:
- 功能:使用
Word2Vec类训练一个词向量模型。 - 参数:
corpus:输入的语料库,应该是一个由词汇列表组成的列表,例如[["cat", "say", "meow"], ["dog", "say", "woof"]]。dim:词向量的维度,例如128。
- 实现细节:
model = Word2Vec(corpus, vector_size=dim, sg=1):创建一个Word2Vec模型,其中vector_size表示词向量的维度,sg=1表示使用 Skip-gram 算法进行训练(sg=0表示使用 CBOW 算法)。model.save("model.w2v"):将训练好的模型保存到文件model.w2v中。
load_word2vec_model 函数:
- 功能:从文件中加载已经训练好的
Word2Vec模型。 - 参数:
path:存储Word2Vec模型的文件路径,例如"model.w2v"。
- 实现细节:
model = Word2Vec.load(path):从指定的文件路径加载Word2Vec模型。
main 函数:
- 实现细节:
sentences = []:初始化一个空列表用于存储分词后的句子。with open("corpus.txt", encoding="utf8") as f:以 UTF-8 编码打开文件corpus.txt。for line in f: sentences.append(jieba.lcut(line)):逐行读取文件,并使用jieba.lcut对每行进行分词,将分词结果添加到sentences列表中。model = train_word2vec_model(sentences, 128):调用train_word2vec_model函数,使用分词后的sentences作为语料库,维度为128训练词向量模型。
1.3 基于pytorch的语言模型

核心算法:
y = Wx + Utanh(hx+d) + b
#coding:utf8import torch
import torch.nn as nn
import numpy as np"""
基于pytorch的语言模型
与基于窗口的词向量训练本质上非常接近
只是输入输出的预期不同
不使用向量的加和平均,而是直接拼接起来
"""class LanguageModel(nn.Module):def __init__(self, vocab_size, max_len, embedding_size, hidden_size):super(LanguageModel, self).__init__()self.word_vectors = nn.Embedding(vocab_size, embedding_size)self.inner_projection_layer = nn.Linear(embedding_size * max_len, hidden_size)self.outter_projection_layer = nn.Linear(hidden_size, hidden_size)self.x_projection_layer = nn.Linear(embedding_size * max_len, hidden_size)self.projection_layer = nn.Linear(hidden_size, vocab_size)def forward(self, context):#context shape = batch_size, max_lengthcontext_embedding = self.word_vectors(context) #output shape = batch_size, max_length, embedding_size#总体计算 y = b+Wx+Utanh(d+Hx), 其中x为每个词向量的拼接#词向量的拼接x = context_embedding.view(context_embedding.shape[0], -1) #shape = batch_size, max_length*embedding_size#hx + dinner_projection = self.inner_projection_layer(x) #shape = batch_size, hidden_size#tanh(hx+d)inner_projection = torch.tanh(inner_projection) #shape = batch_size, hidden_size#U * tanh(hx+d) + boutter_project = self.outter_projection_layer(inner_projection) # shape = batch_size, hidden_size#Wxx_projection = self.x_projection_layer(x) #shape = batch_size, hidden_size#y = Wx + Utanh(hx+d) + by = x_projection + outter_project #shape = batch_size, hidden_size#softmax后输出预测概率, 训练的目标是让y_pred对应到字表中某个字y_pred = torch.softmax(y, dim=-1) #shape = batch_size, hidden_sizereturn y_predvocab_size = 8 #词表大小
embedding_size = 5 #人为指定的向量维度
max_len = 4 #输入长度
hidden_size = vocab_size #由于最终的输出维度应当是字表大小的,所以这里hidden_size = vocab_size
model = LanguageModel(vocab_size, max_len, embedding_size, hidden_size)
#假如选取一个文本窗口“天王盖地虎”
#输入:“天王盖地” —> 输出:"虎"
#假设词表embedding中, 天王盖地虎 对应位置 12345
context = torch.LongTensor([[1,2,3,4]]) #shape = 1, 4 batch_size = 1, max_length = 4
pred = model(context)
print("预测值:", pred)
print("loss可以使用交叉熵计算:", nn.functional.cross_entropy(pred, torch.LongTensor([5])))print("词向量矩阵")
matrix = model.state_dict()["word_vectors.weight"]print(matrix.shape) #vocab_size, embedding_size
print(matrix)2、KMeans(词向量的应用——聚类)
1)将一句话或一段文本分成若干个词
2)找到每个词对应的词向量
3)所有词向量加和求平均或通过各种网络模型,得到文本向量
4)使用文本向量计算相似度或进行聚类等
KMeans
随机选择k个点作为初始质心
repeat
将每个点指派到最近的质心,形成k个簇
重新计算每个簇的质心
until
质心不发生变化

KMeans优点:
1.速度很快,可以支持很大量的数据
2.样本均匀特征明显的情况下,效果不错
KMeans缺点:
1.人为设定聚类数量
2.初始化中心影响效果,导致结果不稳定
3.对于个别特殊样本敏感,会大幅影响聚类中心位置
4.不适合多分类或样本较为离散的数据
KMeans一些使用技巧:
1.先设定较多的聚类类别
2.聚类结束后计算类内平均距离
3.排序后,舍弃类内平均距离较长的类别
4.计算距离时可以尝试欧式距离、余弦距离或其他距离
5.短文本的聚类记得先去重,以及其他预处理
代码实例
import numpy as np
import random
import sys
'''
Kmeans算法实现
原文链接:https://blog.csdn.net/qingchedeyongqi/article/details/116806277
'''class KMeansClusterer: # k均值聚类def __init__(self, ndarray, cluster_num):self.ndarray = ndarrayself.cluster_num = cluster_numself.points = self.__pick_start_point(ndarray, cluster_num)def cluster(self):result = []for i in range(self.cluster_num):result.append([])for item in self.ndarray:distance_min = sys.maxsizeindex = -1for i in range(len(self.points)):distance = self.__distance(item, self.points[i])if distance < distance_min:distance_min = distanceindex = iresult[index] = result[index] + [item.tolist()]new_center = []for item in result:new_center.append(self.__center(item).tolist())# 中心点未改变,说明达到稳态,结束递归if (self.points == new_center).all():sum = self.__sumdis(result)return result, self.points, sumself.points = np.array(new_center)return self.cluster()def __sumdis(self,result):#计算总距离和sum=0for i in range(len(self.points)):for j in range(len(result[i])):sum+=self.__distance(result[i][j],self.points[i])return sumdef __center(self, list):# 计算每一列的平均值return np.array(list).mean(axis=0)def __distance(self, p1, p2):#计算两点间距tmp = 0for i in range(len(p1)):tmp += pow(p1[i] - p2[i], 2)return pow(tmp, 0.5)def __pick_start_point(self, ndarray, cluster_num):if cluster_num < 0 or cluster_num > ndarray.shape[0]:raise Exception("簇数设置有误")# 取点的下标indexes = random.sample(np.arange(0, ndarray.shape[0], step=1).tolist(), cluster_num)points = []for index in indexes:points.append(ndarray[index].tolist())return np.array(points)x = np.random.rand(100, 8)
kmeans = KMeansClusterer(x, 10)
result, centers, distances = kmeans.cluster()
print('result:', result)
print('centers:', centers)
print('distances:', distances)#!/usr/bin/env python3
#coding: utf-8#基于训练好的词向量模型进行聚类
#聚类采用Kmeans算法
import math
import re
import json
import jieba
import numpy as np
from gensim.models import Word2Vec
from sklearn.cluster import KMeans
from collections import defaultdict#输入模型文件路径
#加载训练好的模型
def load_word2vec_model(path):model = Word2Vec.load(path)return modeldef load_sentence(path):sentences = set()with open(path, encoding="utf8") as f:for line in f:sentence = line.strip()sentences.add(" ".join(jieba.cut(sentence)))print("获取句子数量:", len(sentences))return sentences#将文本向量化
def sentences_to_vectors(sentences, model):vectors = []for sentence in sentences:words = sentence.split() #sentence是分好词的,空格分开vector = np.zeros(model.vector_size)#所有词的向量相加求平均,作为句子向量for word in words:try:vector += model.wv[word]except KeyError:#部分词在训练中未出现,用全0向量代替vector += np.zeros(model.vector_size)vectors.append(vector / len(words))return np.array(vectors)def main():model = load_word2vec_model(r"model.w2v") #加载词向量模型sentences = load_sentence("titles.txt") #加载所有标题vectors = sentences_to_vectors(sentences, model) #将所有标题向量化n_clusters = int(math.sqrt(len(sentences))) #指定聚类数量print("指定聚类数量:", n_clusters)kmeans = KMeans(n_clusters) #定义一个kmeans计算类kmeans.fit(vectors) #进行聚类计算sentence_label_dict = defaultdict(list)for sentence, label in zip(sentences, kmeans.labels_): #取出句子和标签sentence_label_dict[label].append(sentence) #同标签的放到一起for label, sentences in sentence_label_dict.items():print("cluster %s :" % label)for i in range(min(10, len(sentences))): #随便打印几个,太多了看不过来print(sentences[i].replace(" ", ""))print("---------")if __name__ == "__main__":main()#coding: utf-8#基于训练好的词向量模型进行聚类
#聚类采用Kmeans算法
#Kmeans基础上实现按照类内距离排序
import math
import re
import json
import jieba
import numpy as np
from gensim.models import Word2Vec
from sklearn.cluster import KMeans
from collections import defaultdict#输入模型文件路径
#加载训练好的模型
def load_word2vec_model(path):model = Word2Vec.load(path)return modeldef load_sentence(path):sentences = set()with open(path, encoding="utf8") as f:for line in f:sentence = line.strip()sentences.add(" ".join(jieba.cut(sentence)))print("获取句子数量:", len(sentences))return sentences#将文本向量化
def sentences_to_vectors(sentences, model):vectors = []for sentence in sentences:words = sentence.split() #sentence是分好词的,空格分开vector = np.zeros(model.vector_size)#所有词的向量相加求平均,作为句子向量for word in words:try:vector += model.wv[word]except KeyError:#部分词在训练中未出现,用全0向量代替vector += np.zeros(model.vector_size)vectors.append(vector / len(words))return np.array(vectors)def main():model = load_word2vec_model("model.w2v") #加载词向量模型sentences = load_sentence("titles.txt") #加载所有标题vectors = sentences_to_vectors(sentences, model) #将所有标题向量化n_clusters = int(math.sqrt(len(sentences))) #指定聚类数量print("指定聚类数量:", n_clusters)kmeans = KMeans(n_clusters) #定义一个kmeans计算类kmeans.fit(vectors) #进行聚类计算sentence_label_dict = defaultdict(list)for sentence, label in zip(sentences, kmeans.labels_): #取出句子和标签sentence_label_dict[label].append(sentence) #同标签的放到一起#计算类内距离density_dict = defaultdict(list)for vector_index, label in enumerate(kmeans.labels_):vector = vectors[vector_index] #某句话的向量center = kmeans.cluster_centers_[label] #对应的类别中心向量distance = cosine_distance(vector, center) #计算距离density_dict[label].append(distance) #保存下来for label, distance_list in density_dict.items():density_dict[label] = np.mean(distance_list) #对于每一类,将类内所有文本到中心的向量余弦值取平均density_order = sorted(density_dict.items(), key=lambda x: x[1], reverse=True) #按照平均距离排序,向量夹角余弦值越接近1,距离越小#按照余弦距离顺序输出for label, avg_distance in density_order:print("cluster %s , avg distance %s: " % (label, avg_distance))sentences = sentence_label_dict[label]for i in range(min(10, len(sentences))): #随便打印几个,太多了看不过来print(sentences[i].replace(" ", ""))print("---------")#向量余弦距离
def cosine_distance(vec1, vec2):vec1 = vec1 / np.sqrt(np.sum(np.square(vec1))) #A/|A|vec2 = vec2 / np.sqrt(np.sum(np.square(vec2))) #B/|B|return np.sum(vec1 * vec2)#欧式距离
def eculid_distance(vec1, vec2):return np.sqrt((np.sum(np.square(vec1 - vec2))))if __name__ == "__main__":main()3、 词向量训练总结
一、根据词与词之间关系的某种假设,制定训练目标
二、设计模型,以词向量为输入
三、随机初始化词向量,开始训练
四、训练过程中词向量作为参数不断调整,获取一定的语义信息
五、使用训练好的词向量做下游任务
词向量总结:
1.质变:将离散的字符转化为连续的数值
2.通过向量的相似度代表语义的相似度
3.词向量的训练基于很多不完全正确的假设,但是据此训练的词向量是有意义的
4.使用无标注的文本的一种好方法
词向量存在的问题:
1)词向量是“静态”的。每个词使用固定向量,没有考虑前后文
2)一词多义的情况。西瓜 - 苹果 - 华为
3)影响效果的因素非常多
维度选择、随机初始化、skip-gram/cbow/glove、分词质量、词频截断、未登录词、窗口大小、迭代轮数、停止条件、语料质量等
4)没有好的直接评价指标。常需要用下游任务来评价
相关文章:
week05_nlp大模型训练·词向量文本向量
1、词向量训练 1.1 CBOW(两边预测中间) 一、CBOW 基本概念 CBOW 是一种用于生成词向量的方法,属于神经网络语言模型的一种。其核心思想是根据上下文来预测中心词。在 CBOW 中,输入是目标词的上下文词汇,输出是该目标…...

【RabbitMQ消息队列原理与应用】
RabbitMQ消息队列原理与应用 一、消息队列概述 (一)概念 消息队列(Message Queue,简称MQ)是一种应用程序间的通信方式,它允许应用程序通过将消息放入队列中,而不是直接调用其他应用程序的接口…...
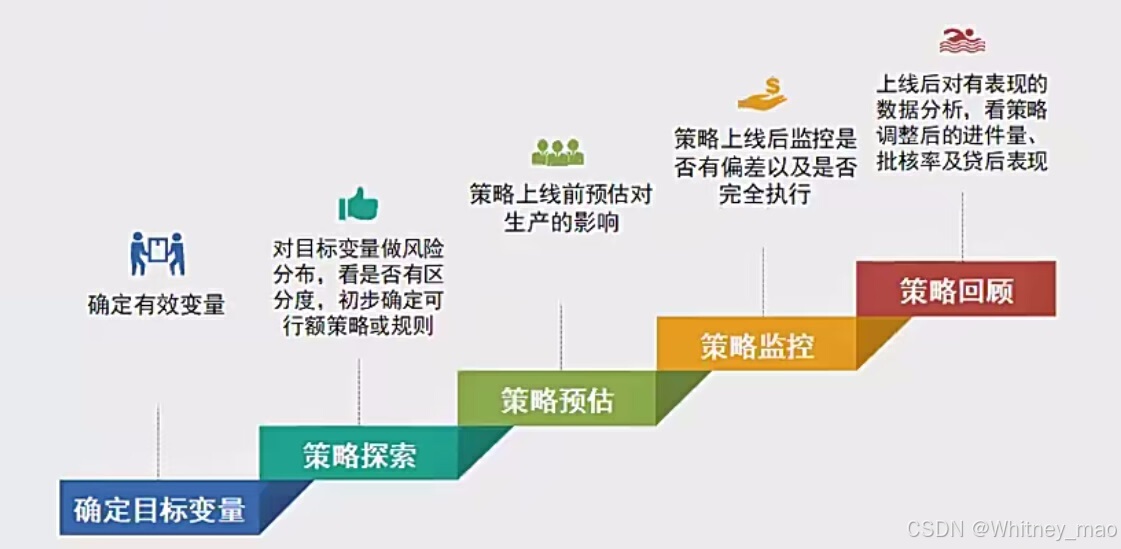
反欺诈风控体系及策略
本文详细介绍了互联网领域金融信贷行业的反欺诈策略。首先,探讨了反欺诈的定义、重要性以及在当前互联网发展背景下欺诈风险的加剧。接着,分析了反欺诈的主要手段和基础技术,包括对中介和黑产的了解、欺诈风险的具体类型和表现方式࿰…...

Mac 12.1安装tiger-vnc问题-routines:CRYPTO_internal:bad key length
背景:因为某些原因需要从本地mac连接远程linxu桌面查看一些内容,必须使用桌面查看,所以ssh无法满足,所以决定安装vnc客户端。 问题: 在mac上通过 brew install tiger-vnc命令安装, 但是报错如下: > D…...

【代码分析】Unet-Pytorch
1:unet_parts.py 主要包含: 【1】double conv,双层卷积 【2】down,下采样 【3】up,上采样 【4】out conv,输出卷积 """ Parts of the U-Net model """import torch im…...

【LLM入门系列】01 深度学习入门介绍
NLP Github 项目: NLP 项目实践:fasterai/nlp-project-practice 介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化、部署和应用,分享大模型算法工程师的日常工作和实战经验 AI 藏经阁:https://gitee.com/fasterai/a…...

安卓系统主板_迷你安卓主板定制开发_联发科MTK安卓主板方案
安卓主板搭载联发科MT8766处理器,采用了四核Cortex-A53架构,高效能和低功耗设计。其在4G网络待机时的电流消耗仅为10-15mA/h,支持高达2.0GHz的主频。主板内置IMG GE832 GPU,运行Android 9.0系统,内存配置选项丰富&…...

关键点检测——HRNet原理详解篇
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题 🍊专栏推荐:深度学习网络原理与实战 🍊近期目标:写好专栏的每一篇文章 🍊支持小苏:点赞👍🏼、…...

25考研总结
11408确实难,25英一直接单科斩杀😭 对过去这一年多备考的经历进行复盘,以及考试期间出现的问题进行思考。 考408的人,政治英语都不能拖到最后,408会惩罚每一个偷懒的人! 政治 之所以把政治写在最开始&am…...

网络安全态势感知
一、网络安全态势感知(Cyber Situational Awareness)是一种通过收集、处理和分析网络数据来理解当前和预测未来网络安全状态的能力。它的目的是提供实时的、安全的网络全貌,帮助组织理解当前网络中发生的事情,评估风险,…...

在K8S中,节点状态notReady如何排查?
在kubernetes集群中,当一个节点(Node)的状态变为NotReady时,意味着该节点可能无法运行Pod或不能正确相应kubernetes控制平面。排查NotReady节点通常涉及以下步骤: 1. 获取基本信息 使用kubectl命令行工具获取节点状态…...

深度学习在光学成像中是如何发挥作用的?
深度学习在光学成像中的作用主要体现在以下几个方面: 1. **图像重建和去模糊**:深度学习可以通过优化图像重建算法来处理模糊图像或降噪,改善成像质量。这涉及到从低分辨率图像生成高分辨率图像,突破传统光学系统的分辨率限制。 …...

树莓派linux内核源码编译
Raspberry Pi 内核 托管在 GitHub 上;更新滞后于上游 Linux内核,Raspberry Pi 会将 Linux 内核的长期版本整合到 Raspberry Pi 内核中。 1 构建内核 操作系统随附的默认编译器和链接器被配置为构建在该操作系统上运行的可执行文件。原生编译使用这些默…...
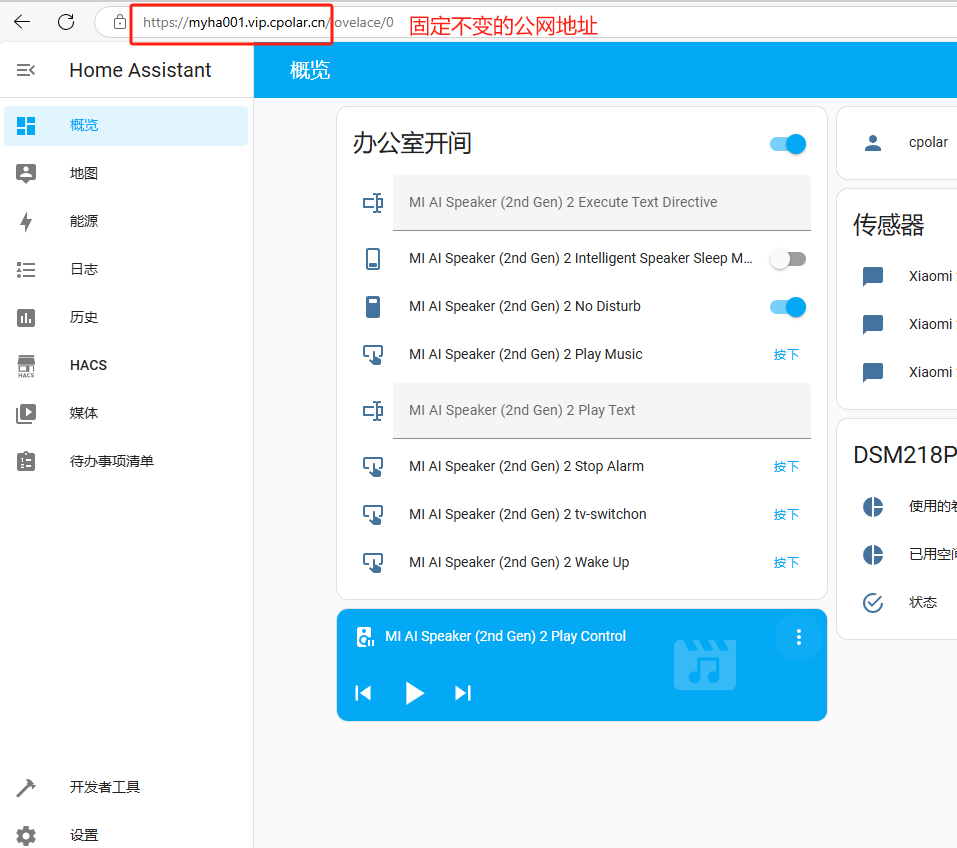
本地小主机安装HomeAssistant开源智能家居平台打造个人AI管家
文章目录 前言1. 添加镜像源2. 部署HomeAssistant3. HA系统初始化配置4. HA系统添加智能设备4.1 添加已发现的设备4.2 添加HACS插件安装设备 5. 安装cpolar内网穿透5.1 配置HA公网地址 6. 配置固定公网地址 前言 大家好!今天我要向大家展示如何将一台迷你的香橙派Z…...

SpringBoot返回文件让前端下载的几种方式
01 背景 在后端开发中,通常会有文件下载的需求,常用的解决方案有两种: 不通过后端应用,直接使用nginx直接转发文件地址下载(适用于一些公开的文件,因为这里不需要授权)通过后端进行下载&#…...

人工智能及深度学习的一些题目
1、一个含有2个隐藏层的多层感知机(MLP),神经元个数都为20,输入和输出节点分别由8和5个节点,这个网络有多少权重值? 答:在MLP中,权重是连接神经元的参数,每个连接都有一…...

15-利用dubbo远程服务调用
本文介绍利用apache dubbo调用远程服务的开发过程,其中利用zookeeper作为注册中心。关于zookeeper的环境搭建,可以参考我的另一篇博文:14-zookeeper环境搭建。 0、环境 jdk:1.8zookeeper:3.8.4dubbo:2.7.…...

【Rust自学】8.5. HashMap Pt.1:HashMap的定义、创建、合并与访问
8.5.0. 本章内容 第八章主要讲的是Rust中常见的集合。Rust中提供了很多集合类型的数据结构,这些集合可以包含很多值。但是第八章所讲的集合与数组和元组有所不同。 第八章中的集合是存储在堆内存上而非栈内存上的,这也意味着这些集合的数据大小无需在编…...

未来网络技术的新征程:5G、物联网与边缘计算(10/10)
一、5G 网络:引领未来通信新潮流 (一)5G 网络的特点 高速率:5G 依托良好技术架构,提供更高的网络速度,峰值要求不低于 20Gb/s,下载速度最高达 10Gbps。相比 4G 网络,5G 的基站速度…...

LLM(十二)| DeepSeek-V3 技术报告深度解读——开源模型的巅峰之作
近年来,大型语言模型(LLMs)的发展突飞猛进,逐步缩小了与通用人工智能(AGI)的差距。DeepSeek-AI 团队最新发布的 DeepSeek-V3,作为一款强大的混合专家模型(Mixture-of-Experts, MoE&a…...

用51单片机+DAC0832做个信号发生器:5种波形可调,附Proteus仿真和Keil源码
51单片机DAC0832信号发生器实战指南:从硬件搭建到波形调频 在电子设计领域,信号发生器是基础但极其重要的工具。传统商用设备往往价格昂贵且功能固定,而基于51单片机和DAC0832的自制信号发生器不仅成本低廉,还能根据需求灵活定制。…...

企业邮箱代理:谷歌企业邮箱安全防护架构与合规应用解析
前言谷歌企业邮箱凭借全球通用 IP 信誉、海外节点覆盖广等优势,成为外贸企业对接欧美、东南亚海外客户的首选办公邮箱。但国内企业直接使用,容易出现登录卡顿、邮件发送延迟、大批量开发信被限制等问题,做好针对性优化,才能最大化…...

从零上手RP2040:为树莓派Pico注入MicroPython灵魂
1. 为什么选择MicroPython? 对于刚接触树莓派Pico(RP2040)的新手来说,选择MicroPython作为开发语言是个明智的决定。这就像第一次学骑自行车时选择带辅助轮的车子——它降低了入门门槛,让你能快速感受到编程的乐趣。Mi…...

LabVIEW生产者消费者模式进阶:从单队列到多队列的架构设计与实战
1. 生产者/消费者循环的进阶架构:从“一对一”到“一对多”在上一季的分享中,我们详细拆解了生产者/消费者循环的基础模型,即一个生产者任务对应一个消费者任务。这种结构清晰、易于理解,是处理异步任务、解耦数据生成与处理的经典…...

CTF学习规划————1、如何入门CTF
CTF学习规划————1、如何入门CTF 无意中发现了一个巨牛巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,小白也能学,而且非常风趣幽默,还时不时有内涵段子,像看小说一样࿰…...

JDK 17文本块实战:告别繁琐拼接,拥抱多行字符串新写法
1. 为什么我们需要文本块? 如果你写过Java代码,肯定遇到过这样的场景:需要处理多行字符串,比如HTML模板、SQL语句或者JSON数据。在JDK 17之前,我们只能通过字符串拼接的方式来实现,代码看起来就像是一团乱麻…...
)
从Python到Shell:给AI/开发者的极简跨语言编程指南(附避坑对比)
从Python到Shell:给AI/开发者的极简跨语言编程指南(附避坑对比) 当Python开发者第一次接触Shell脚本时,往往会陷入两种极端:要么低估了Shell的能力,认为它只是简单的命令拼接;要么高估了它的复…...

TeXstudio红色波浪线强迫症拯救方案:从拼写检查到参考文献问号的全链路排错
TeXstudio红色波浪线全攻略:从诊断到根治的LaTeX高效写作指南 当你沉浸在LaTeX写作中时,突然出现的红色波浪线就像咖啡杯里的蟑螂——不仅打断思路,还让人浑身不自在。这些看似小问题的背后,往往隐藏着从拼写检查到编译顺序的复杂…...

如何用QTTabBar彻底告别Windows资源管理器的混乱:一个完整的高效文件管理解决方案
如何用QTTabBar彻底告别Windows资源管理器的混乱:一个完整的高效文件管理解决方案 【免费下载链接】qttabbar QTTabBar is a small tool that allows you to use tab multi label function in Windows Explorer. https://www.yuque.com/indiff/qttabbar 项目地址:…...

西安小程序制作优质服务推荐
在西安,小程序制作已成为众多企业实现数字化转型的核心一步。企业在这个领域的选择尤为重要,因为市场上的服务供应商数量庞大、难以判断其服务质量。因此专业背景、以往案例以及客户评价,这些都能够反映出公司的整体实力。还有,成…...