P8打卡——YOLOv5-C3模块实现天气识别
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
1.检查GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
2.查看数据
import random
data_dir='data/weather_photos'
data_dir=pathlib.Path(data_dir)
data_paths=list(data_dir.glob('*'))
classNames=[str(path).split('\\')[2] for path in data_paths]
classNames
3.划分数据集
train_transforms=transforms.Compose([transforms.Resize([224,224]),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.482,0.456,0.406],std=[0.229,0.224,0.225])
])
test_transforms=transforms.Compose([transforms.Resize([224,224]),transforms.ToTensor(),transforms.Normalize(mean=[0.482,0.456,0.406],std=[0.229,0.224,0.225])
])
total_data=datasets.ImageFolder("data/weather_photos/",transform=train_transforms)
total_datatotal_data.class_to_idxtrain_size=int(0.8*len(total_data))
test_size=len(total_data)-train_size
train_data,test_data=torch.utils.data.random_split(total_data,[train_size,test_size])
train_data,test_databatch_size=4
train_dl=torch.utils.data.DataLoader(train_data,batch_size,shuffle=True,num_workers=1)
test_dl=torch.utils.data.DataLoader(test_data,batch_size,shuffle=True,num_workers=1)for X,y in train_dl:print(X.shape)print(y.shape)break

4.创建模型
import torch.nn.functional as Fdef autopad(k, p=None): # kernel, padding# Pad to 'same'if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolutiondef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):return self.act(self.bn(self.conv(x)))class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C3(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))class model_K(nn.Module):def __init__(self):super(model_K, self).__init__()# 卷积模块self.Conv = Conv(3, 32, 3, 2) # C3模块1self.C3_1 = C3(32, 64, 3, 2)# 全连接网络层,用于分类self.classifier = nn.Sequential(nn.Linear(in_features=802816, out_features=100),nn.ReLU(),nn.Linear(in_features=100, out_features=4))def forward(self, x):x = self.Conv(x)x = self.C3_1(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return xdevice = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = model_K().to(device)
modelimport torchsummary as summary
summary.summary(model,(3,224,224))





5.编译及训练模型
def train(dataloader,model,loss_fn,optimizer):size=len(dataloader.dataset)num_batches=len(dataloader)train_loss,train_acc=0,0for X,y in dataloader:X,y =X.to(device),y.to(device)pred=model(X)loss=loss_fn(pred,y)#反向传播optimizer.zero_grad()loss.backward()optimizer.step()train_loss+=loss.item()train_acc+=(pred.argmax(1)==y).type(torch.float).sum().item()train_acc/=sizetrain_loss/=num_batchesreturn train_acc,train_lossdef test(dataloader,model,loss_fn):size=len(dataloader.dataset)num_batches=len(dataloader)test_loss,test_acc=0,0with torch.no_grad():for imgs,target in dataloader:imgs,target=imgs.to(device),target.to(device)target_pred=model(imgs)loss=loss_fn(target_pred,target)test_loss+=loss.item()test_acc+=(target_pred.argmax(1)==target).type(torch.float).sum().item()test_acc/=sizetest_loss/=num_batchesreturn test_acc,test_lossimport copy
optimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss()
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0
for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)# 保存最佳模型到 best_modelif epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)lr = optimizer.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth'
torch.save(model.state_dict(), PATH)
print('Done')
6.结果可视化
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.rcParams['figure.dpi']=100epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
7.模型评估
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)epoch_test_acc, epoch_test_lossepoch_test_acc
总结:
1.C3模块

import torch.nn.functional as Fdef autopad(k, p=None): # kernel, padding# Pad to 'same'if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolutiondef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):return self.act(self.bn(self.conv(x)))class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C3(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))class model_K(nn.Module):def __init__(self):super(model_K, self).__init__()# 卷积模块self.Conv = Conv(3, 32, 3, 2) # C3模块1self.C3_1 = C3(32, 64, 3, 2)# 全连接网络层,用于分类self.classifier = nn.Sequential(nn.Linear(in_features=802816, out_features=100),nn.ReLU(),nn.Linear(in_features=100, out_features=4))def forward(self, x):x = self.Conv(x)x = self.C3_1(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return xdevice = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = model_K().to(device)
model
相关文章:
P8打卡——YOLOv5-C3模块实现天气识别
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 1.检查GPU import torch import torch.nn as nn import torchvision.transforms as transforms import torchvision from torchvision import transforms, dat…...

基于微信小程序的校园点餐平台的设计与实现(源码+SQL+LW+部署讲解)
文章目录 摘 要1. 第1章 选题背景及研究意义1.1 选题背景1.2 研究意义1.3 论文结构安排 2. 第2章 相关开发技术2.1 前端技术2.2 后端技术2.3 数据库技术 3. 第3章 可行性及需求分析3.1 可行性分析3.2 系统需求分析 4. 第4章 系统概要设计4.1 系统功能模块设计4.2 数据库设计 5.…...

PyTorch快速入门教程【小土堆】之完整模型训练套路
视频地址完整的模型训练套路(一)_哔哩哔哩_bilibili import torch import torchvision from model import * from torch import nn from torch.utils.data import DataLoader# 准备数据集 train_data torchvision.datasets.CIFAR10(root"CIFAR10&…...

【AIGC】 ChatGPT实战教程:如何高效撰写学术论文引言
💥 欢迎来到我的博客!很高兴能在这里与您相遇! 首页:GPT-千鑫 – 热爱AI、热爱Python的天选打工人,活到老学到老!!!导航 - 人工智能系列:包含 OpenAI API Key教程, 50个…...

TTL 传输中过期问题定位
问题: 工作环境中有一个acap的环境,ac的wan口ip是192.168.186.195/24,ac上lan上有vlan205,其ip子接口地址192.168.205.1/24,ac采用非nat模式,而是路由模式,在上级路由器上有192.168.205.0/24指向…...

非docker方式部署openwebui过程记录
之前一直用docker方式部署openwebui,结果这东西三天两头升级,我这一升级拉取docker镜像硬盘空间嗖嗖的占用,受不了,今天改成了直接部署,以下是部署过程记录。 一、停止及删除没用的docker镜像占用的硬盘空间 docker s…...

大模型的prompt的应用二
下面总结一些在工作中比较实用的prompt应用。还可以到以下网站参考更多的prompt AI Prompts - WayToAGI 举个例子,让大模型写一份周报 # 角色:智能周报编写助手 ## 背景: 需要根据产品经理提供的简要周报框架,补充完整的周报内容。 ## 注意事项: 言简意赅,重点突…...

ubuntu 22.04安装ollama
1. 顺利的情况 按照官网的提示,执行下面的命令: curl -fsSL https://ollama.com/install.sh | sh如果网络畅通,github访问也没有问题,那就等待安装完成就行 2. 不顺利的情况 由于众所周知的情况,国内网络访问githu…...
从企业级 RAG 到 AI Assistant,阿里云 Elasticsearch AI 搜索技术实践
在过去一年中,基座大模型技术的快速迭代推动了 AI 搜索的演进,主要体现在以下几个方面: 1.搜索技术链路重构 基于大模型的全面重构正在重塑 AI 搜索的技术链路。从数据采集、文档解析、向量检索到查询分析、意图识别、排序模型和知识图谱等…...

Redis--高可用(主从复制、哨兵模式、分片集群)
高可用(主从复制、哨兵模式、分片集群) 高可用性Redis如何实现高可用架构?主从复制原理1. 全量同步2. 命令传播3. 增量同步 Redis Sentinel(哨兵模式)为什么要有哨兵模式?哨兵机制是如何工作的?…...
框架(Mybatis配置日志)
mybatis配置日志输出 先导入日志依赖 <dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency> 编写log4j.properties配置文件 # Root logger option log4j.rootLogge…...

人工智能-Python上下文管理器-with
概念 Python提供了 with 语句的这种写法,既简单又安全,并且 with 语句执行完成以后自动调用关闭文件操作,即使出现异常也会自动调用关闭文件操作;其效果等价于try-except-finally with 拥有以下两个魔术方法 __enter__() 上文管理…...
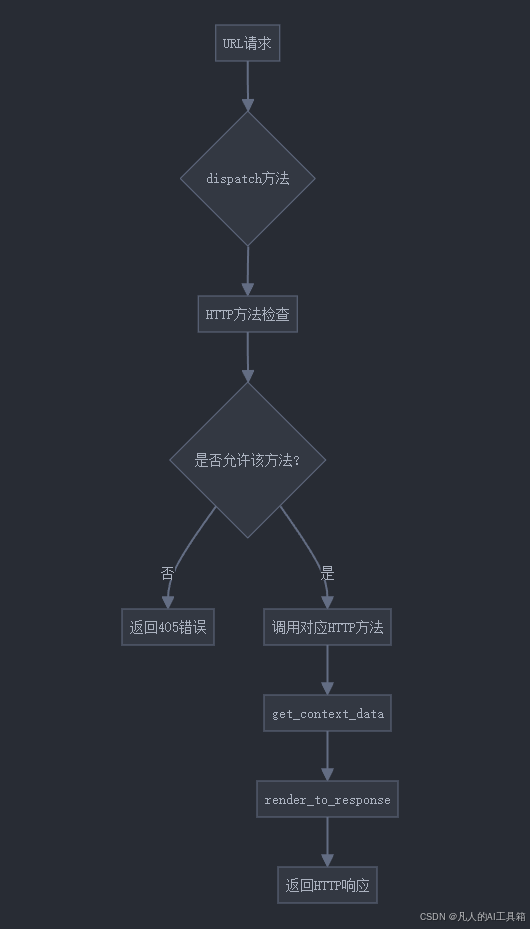
每天40分玩转Django:Django类视图
Django类视图 一、知识要点概览表 类别知识点掌握程度要求基础视图View、TemplateView、RedirectView深入理解通用显示视图ListView、DetailView熟练应用通用编辑视图CreateView、UpdateView、DeleteView熟练应用Mixin机制ContextMixin、LoginRequiredMixin理解原理视图配置U…...
自动化测试之Pytest框架(万字详解)
Pytest测试框架 一、前言二、安装2.1 命令行安装2.2 验证安装 三、pytest设计测试用例注意点3.1 命名规范3.2 断言清晰3.3 fixture3.4 参数化设置3.5 测试隔离3.6 异常处理3.7 跳过或者预期失败3.8 mocking3.9 标记测试 四、以案例初入pytest4.1 第一个pytest测试4.2 多个测试分…...

基于51单片机(STC32G12K128)和8X8彩色点阵屏(WS2812B驱动)的小游戏《贪吃蛇》
目录 系列文章目录前言一、效果展示二、原理分析三、各模块代码1、定时器02、矩阵按键模块3、8X8彩色点阵屏 四、主函数总结 系列文章目录 前言 《贪吃蛇》,一款经典的、怀旧的小游戏,单片机入门必写程序。 以《贪吃蛇》为载体,熟悉各种屏幕…...
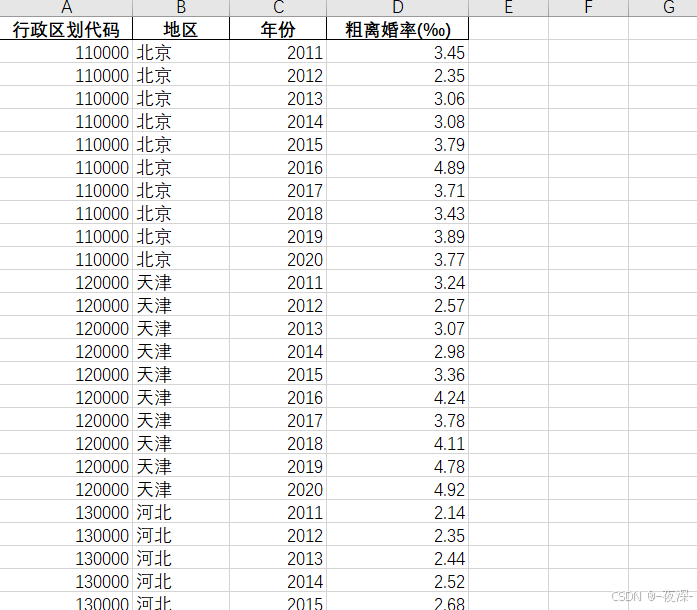
2011-2020年各省粗离婚率数据
2011-2020年各省粗离婚率数据 1、时间:2011-2020年 2、来源:国家统计局 3、指标:地区、年份、粗离婚率 4、范围:31省 5、指标解释:粗离婚率指某地区当年离婚对数占该地区年平均人口的比重。计算公式为:…...

C++高级编程技巧:模板元编程与性能优化实践
C高级编程技巧:模板元编程与性能优化实践 在C编程的世界里,模板元编程(Template Metaprogramming)是一项强大的技术,它允许程序员在编译时而非运行时进行计算和类型操作。这项技术的核心在于C模板系统,它…...

Mac 版本向日葵退出登录账号
找遍整个软件,Mac 版本的向日葵甚至逆天到没有提供退出登录的功能… 随后我发现可以直接删除向日葵的配置文件达到退出登录的效果,具体操作如下: cd /etc # 确认存在 orayconfig.conf 文件 ls orayconfig.conf # 删除 sudo rm -f oray…...
SOLIDWORKS Composer在产品设计、制造与销售中的应用
SOLIDWORKS Composer是一款专为技术团队设计的高效沟通工具,广泛应用于产品设计、制造、销售及售后等领域。它能从复杂的CAD数据中提取关键信息,轻松转化为高质量的产品文档、交互式3D动画及说明视频,显著提升产品沟通效率。 Composer擅长制…...
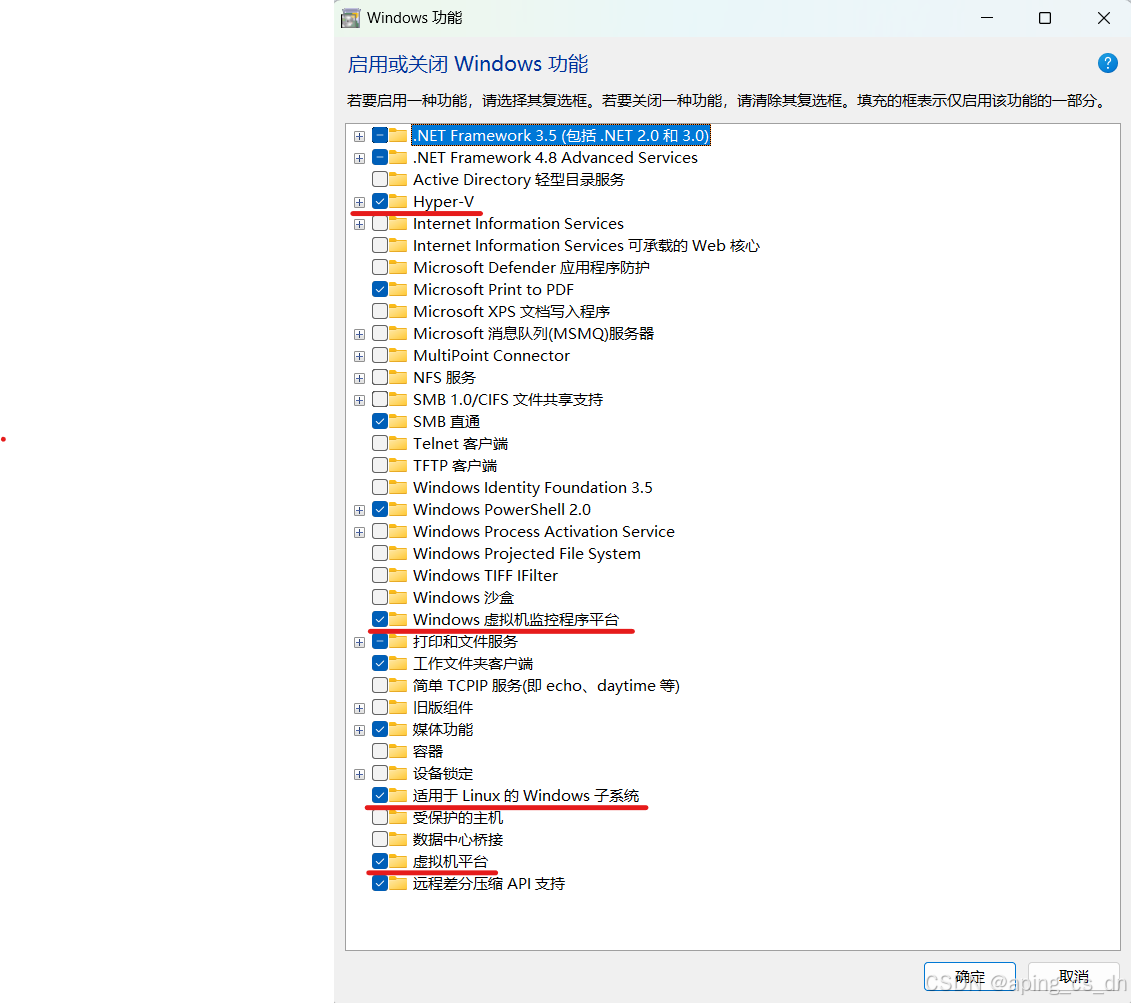
Win11+WLS Ubuntu 鸿蒙开发环境搭建(一)
参考文章 Windows11安装linux子系统 WSL子系统迁移、备份与导入全攻略 如何扩展 WSL 2 虚拟硬盘的大小 Win10安装的WSL子系统占用磁盘空间过大如何释放 《Ubuntu — 调整文件系统大小命令resize2fs》 penHarmony南向开发笔记(一)开发环境搭建 一&a…...

ANFIS驱动的电力系统稳定控制器方法【附代码】
✨ 长期致力于电力系统稳定性、PSS2A、ANFIS研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于减法聚类与混合学习的ANFIS结构自动生成方法…...
)
NotebookLM大纲自动生成正在淘汰传统笔记法(内部白皮书泄露:Google Labs 2024 Q2 A/B测试结果首次公开)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM大纲自动生成正在淘汰传统笔记法(内部白皮书泄露:Google Labs 2024 Q2 A/B测试结果首次公开) Google Labs 2024年第二季度A/B测试数据显示,启用…...

通过 curl 命令快速测试 Taotoken 各大模型 API 的连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 curl 命令快速测试 Taotoken 各大模型 API 的连通性 在将大模型能力集成到应用或服务之前,验证 API 的连通性、密…...

终极风扇控制指南:FanControl免费软件让你的电脑散热更智能
终极风扇控制指南:FanControl免费软件让你的电脑散热更智能 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendi…...

基于rsync的嵌入式Ubuntu系统镜像定制与批量部署实战
1. 项目概述:为什么我们需要在开发板上“冻结”Ubuntu文件系统?在基于ARM架构的嵌入式开发中,尤其是使用像飞凌OK3399-C这样搭载RK3399处理器的开发板时,我们常常会面临一个看似简单却非常实际的痛点:环境部署的效率问…...

LLM函数调用工程化:从基础概念到智能体框架设计实战
1. 项目概述:从“函数调用”到智能体交互的范式演进最近在GitHub上看到一个名为“SKY-lv/function-calling”的项目,这个标题乍一看平平无奇,甚至有些过于直白。但作为一名长期混迹在AI应用开发一线的工程师,我立刻嗅到了一丝不寻…...
)
ChatGPT支付功能现状深度研判(2024Q2最新政策+OpenAI开发者文档交叉验证)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT实时支付功能在哪里 ChatGPT 本身并不原生支持实时支付功能。OpenAI 官方发布的 ChatGPT(包括免费版、Plus 订阅版及 Team/Enterprise 版)定位为人工智能对话助手&#x…...
)
紧急通知:FAO 2024渔业AI伦理新规已生效!NotebookLM合规使用红线清单(含数据脱敏、模型可解释性、渔民知情权三重校验表)
更多请点击: https://intelliparadigm.com 第一章:FAO 2024渔业AI伦理新规核心要义与NotebookLM适配总览 联合国粮农组织(FAO)于2024年3月发布的《人工智能在渔业与水产养殖中的伦理应用指南》,首次将“可追溯性权”“…...

百度网盘提取码智能获取:如何用3行命令告别密码搜索烦恼
百度网盘提取码智能获取:如何用3行命令告别密码搜索烦恼 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾经遇到过这样的情况:在网络上找到一份宝贵的学习资料,点击百度网盘分享链接…...

Unity问题记录
一个物体在Scene窗口看不见,Game窗口能看见。选中它时,打开Gizmos也看不见身上碰撞体的线框。也无法被射线检测到。换成其他Mesh:Open Asset In Context正常显示:把它Revert回预制体,还是不显示。Ctrl D复制一个&#…...