动态规划六——两个数组的dp问题
目录
题目一——1143. 最长公共子序列 - 力扣(LeetCode)
题目二——1035. 不相交的线 - 力扣(LeetCode)
题目三——115. 不同的子序列 - 力扣(LeetCode)
题目四—— 44. 通配符匹配 - 力扣(LeetCode)
题目五——10. 正则表达式匹配 - 力扣(LeetCode)
题目六——97. 交错字符串 - 力扣(LeetCode)
题目七——712. 两个字符串的最小ASCII删除和 - 力扣(LeetCode)
题目八——718. 最长重复子数组 - 力扣(LeetCode)
题目一——1143. 最长公共子序列 - 力扣(LeetCode)


这题是经典中的经典!!!
1.状态表示:
对于两个数组的动态规划,我们的定义状态表示的经验就是:
- i. 选取第一个数组[0, i]区间以及第二个数组[0, j]区间。
- ii. 结合题目要求,定义状态表示。
在这道题中,我们根据定义状态表示为:
dp[i][j]表示s1的[0, i]区间以及s2的[0, j]区间内的所有的子序列中,最长公共子序列的长度。
2.状态转移方程:
分析状态转移方程的经验就是根据「最后一个位置」的状况,分情况讨论。
对于dp[i][j],我们可以根据s1[i]与s2[j]的字符分情况讨论:
i. 两个字符相同,即s1[i] = s2[j]:那么最长公共子序列就在s1的[0, i - 1]区间以及s2的[0, j - 1]区间上找到一个最长的,然后再加上s1[i]即可。因此dp[i][j] = dp[i - 1][j - 1] + 1;
ii. 两个字符不相同,即s1[i] != s2[j]:那么最长公共子序列一定不会同时以s1[i]和s2[j]结尾。那么我们找最长公共子序列时,有下面三种策略:
- 去s1的[0, i - 1]以及s2的[0, j]区间内找:此时最大长度为dp[i - 1][j];
- 去s1的[0, i]以及s2的[0, j - 1]区间内找:此时最大长度为dp[i][j - 1];
- 去s1的[0, i - 1]以及s2的[0, j - 1]区间内找:此时最大长度为dp[i - 1][j - 1]。
我们要三者的最大值即可。但是我们细细观察会发现,第三种包含在第一种和第二种情况里面,但是我们求的是最大值,并不影响最终结果。因此只需求前两种情况下的最大值即可。
综上,状态转移方程为:
- if(s1[i] == s2[j]) dp[i][j] = dp[i - 1][j - 1] + 1;
- if(s1[i] != s2[j]) dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])。
3.初始化:
我们知道状态转移方程会使用dp[i - 1][j - 1],那对于i==0和j==0的情况,那这个dp[i - 1][j - 1]不是会越界吗,为了防止这个情况的发生,我们可以将dp表多开一行一列,但是这样子会影响到和原数组的下标映射关系,所以我们可以在原字符串前加一个空字符,这样子就不会有下标映射的困扰了

此外,当s1为空时,没有长度,同理s2也是。因此dp表里面第一行和第一列里面的值初始化为0即可保证后续填表是正确的。
- a. 「空串」是有研究意义的,因此我们将原始dp表的规模多加上一行和一列,表示空串。
- b. 引入空串后,大大的方便我们的初始化。
- c. 但也要注意「下标的映射关系」,以及里面的值要「保证后续填表是正确的」。
4.填表顺序:
根据「状态转移方程」得:从上往下填写每一行,每一行从左往右。
5.返回值:
根据「状态表示」得:返回dp[m][n]。
代码如下:
class Solution {
public:int longestCommonSubsequence(string text1, string text2) {int m=text1.size(),n=text2.size();vector<vector<int>>dp(m+1,vector<int>(n+1,0));text1=' '+text1;text2=' '+text2;int ret=0;for(int i=1;i<=m;i++){for(int j=1;j<=n;j++){if(text1[i]==text2[j]){dp[i][j]=dp[i-1][j-1]+1;}else{dp[i][j]=max(dp[i-1][j],dp[i][j-1]);}ret=max(ret,dp[i][j]);}}return ret;}
}; 
题目二——1035. 不相交的线 - 力扣(LeetCode)


如果要保证两条直线不相交,那么我们「下⼀个连线」必须在「上⼀个连线」对应的两个元素的 「后⾯」寻找相同的元素。这不就转化成「最⻓公共⼦序列」的模型了嘛。
那就是在这两个数组中 寻找「最⻓的公共⼦序列」。 只不过是在整数数组中做⼀次「最⻓的公共⼦序列」,代码⼏乎⼀模⼀样,这⾥就不再赘述算法原理啦~

class Solution {
public:int maxUncrossedLines(vector<int>& nums1, vector<int>& nums2) {int m=nums1.size(),n=nums2.size();vector<vector<int>>dp(m+1,vector<int>(n+1,0));int ret=0;for(int i=1;i<=m;i++){for(int j=1;j<=n;j++){if(nums1[i-1]==nums2[j-1])//注意下标映射关系{dp[i][j]=dp[i-1][j-1]+1;}else{dp[i][j]=max(dp[i-1][j],dp[i][j-1]);}ret=max(ret,dp[i][j]);}}return ret;}
};
题目三——115. 不同的子序列 - 力扣(LeetCode)


1.状态表示:
对于两个字符串之间的 dp 问题,我们⼀般的思考⽅式如下:
- i. 选取第⼀个字符串的 [0, i] 区间以及第⼆个字符串的[0, j] 区间当成研究对象,结合题⽬的要求来定义「状态表⽰」;
- ii. 然后根据两个区间上「最后⼀个位置的字符」,来进⾏「分类讨论」,从⽽确定「状态转移 ⽅程」。
我们可以根据上⾯的策略,解决⼤部分关于两个字符串之间的 dp 问题。
dp[i][j] 表⽰:在字符串 s 的 [0, j] 区间内的所有子序列中,有多少个 t字符串 的 [0, i] 区间的子序列。
2.状态转移方程:
接下来,我们根据两个区间上“最后一个位置的字符”来进行分类讨论,以确定状态转移方程。
-
当
t[i] == s[j]时,此时的子序列有两种选择:-
一种选择是选择s[i]为结尾:这意味着问题就是在字符串
s的[0, j]区间内的所有子序列中,有多少个t字符串 的[0, i]区间的子序列。这意味着,在dp[i - 1][j - 1]中的所有符合要求的子序列的后面,再加上一个字符s[j]。因此,dp[i][j]=dp[i - 1][j - 1]。 -
另一种选择是不选择s[i]为结尾:这意味着问题就是在字符串
s的[0, j-1]区间内的所有子序列中,有多少个t字符串 的[0, i]区间的子序列。这意味着,我们直接继承了dp[i][j - 1]中所有符合要求的子序列。因此,dp[i][j]=dp[i][j - 1]。 -
综合两种情况,当
t[i] == s[j]时,dp[i][j] = dp[i - 1][j - 1] + dp[i][j - 1]。
-
-
当
t[i] != s[j]时,由于s[j]与t[i]不匹配,此时的子序列只能从dp[i][j - 1]中选择所有符合要求的子序列。也就是说,我们只能继承上一个状态中求得的子序列。因此,dp[i][j] = dp[i][j - 1]。
综上所述,状态转移方程可以总结为:
- 在所有情况下,
dp[i][j]都可以继承上一次的结果,即dp[i][j] = dp[i][j - 1]。 - 当
t[i] == s[j]时,除了继承上一次的结果外,还可以多选择一种情况,即dp[i][j] += dp[i - 1][j - 1]。
3.初始化
我们知道状态转移方程会出现j-1或者i-1,那当j=0或者i=0的时候那不是会越界吗?这可不行,所以我们需要另外开一行一列,这样子就能防止越界情况的发生了。
只不过这样子的新dp表的下标和原数组的下标是对不上的。是需要经过-1才能得到原数组的下标的。为了避免这种麻烦,我们直接给两个字符串的最前面加上一个空字符串' ',这样就可以免去下标映射的痛苦。
此外,当 s 为空时, t 的⼦串中有⼀个空串和它⼀样,因此初始化第⼀⾏全部为 1 。

4.填表顺序
我们看状态转移方程 dp[i][j] += dp[i - 1][j - 1]。
这就决定了dp[i - 1][j - 1]一定比dp[i][j]先出现,所以是从左往右,从上往下。
5.返回值
dp[i][j] 表⽰:在字符串 s 的 [0, j] 区间内的所有子序列中,有多少个 t字符串 的 [0, i] 区间的子序列。
所以我们返回dp[t.size()][s.size()]。即可
本题有⼀个巨恶⼼的地⽅,题⽬上说结果不会超过 int 的最⼤值,但是实际在计算过程会会超。为了避免报错,我们选择 double 存储结果。
class Solution {
public:int numDistinct(string s, string t) {int n=s.size(),m=t.size();vector<vector<double>>dp(m+1,vector<double>(n+1));for(int j = 0; j <= n; j++) dp[0][j] = 1; // 初始化s=' '+s;t=' '+t;for(int i=1;i<=m;i++){for(int j=1;j<=n;j++){if(s[j]==t[i]){dp[i][j]=dp[i][j-1]+dp[i-1][j-1];}else{dp[i][j]=dp[i][j-1];}}}return dp[m][n];}
};
题目四—— 44. 通配符匹配 - 力扣(LeetCode)


嗯?这个和我们的Linux里面的通配符是一模一样的啊!!!
1.状态表示
对于两个字符串之间的DP问题,我们通常的思考方式如下:
- 将第一个字符串
s的[0, i]区间和第二个字符串p的[0, j]区间作为研究对象。 - 定义状态
dp[i][j]来表示某种关系或属性,这个关系或属性通常与s的前i+1个字符和p的前j+1个字符有关。
在这个上下文中,我们可以定义 dp[i][j] 为:
dp[i][j]表示s的【0,i】区间的字符串能否与p的【0,j】区间的字符串相匹配。
2.推导状态转移方程
首先啊,这种题目都是在最后一个字符做文章啊!!!
一共有三种情况
- 当 s[i] == p[j]或者p[j] == '?' 的时候
- 当
p[j] == '*'的时候 - 当 p[j] 不是特殊字符,且不与 s[i] 相等时
当 s[i] == p[j]或者p[j] == '?' 的时候,此时两个字符串匹配上了当前的⼀个字 符,只能从 dp[i - 1][j - 1] 中看当前字符前⾯的两个⼦串是否匹配。只能继承上个 状态中的匹配结果, dp[i][j] = dp[i-1][j - 1] ;
当 p[j] == '*' 的时候,此时匹配策略有多种情况:
* 匹配空字符串,此时相当于它匹配了一个寂寞,直接继承状态 dp 数组的前一个状态,即 dp[i][j-1],此时 dp[i][j] = dp[i][j - 1];
* 匹配s字符串里的一个字符,直接继承状态 dp 数组的前一个状态,即dp[i-1][j-1],此时dp[i][j]=dp[i-1][j-1]

* 匹配s字符串里的两个字符时,,直接继承状态 dp 数组的前一个状态,即dp[i-2][j-1],此时dp[i][j]=dp[i-2][j-1]

那么匹配3个字符,4个字符……啥的就不说了啊!!
* 向前匹配 1 ~ n 个字符,直⾄匹配上整个 s 串。此时相当于 从 dp[k][j - 1] (0 <= k <= i) 中所有匹配情况中,选择性继承可以成功的 情况。此时 dp[i][j] = dp[k][j - 1] (0 <= k <= i) ;
优化:当我们发现,计算⼀个状态的时候,需要⼀个循环才能搞定的时候,我们要想到去优化。优化的⽅向就是⽤⼀个或者两个状态来表⽰这⼀堆的状态。通常就是把它写下来,然后⽤数学的⽅式 做⼀下等价替换。
在这里,我们发现只要这个dp[i][j] = dp[k][j - 1] (0 <= k <= i) ,只要dp[i][j] = dp[k][j - 1] (0 <= k <= i) 里面任何一个是true,那么dp[i][j]就是true。
当 p[j] == '*' 时,状态转移⽅程为:dp[i][j] = dp[i][j - 1] || dp[i - 1][j - 1] || dp[i - 2][j - 1] ......
但是当我们不断的修改i的值,我们就会发现下面这个情况
- dp[i][j] = dp[i][j - 1] || dp[i - 1][j - 1] || dp[i - 2][j - 1] ......
- dp[i - 1][j] = dp[i - 1][j - 1] || dp[i - 2][j - 1] || dp[i - 3] [j - 1] ......
大家惊奇的发现dp[i][j]=dp[i-1][j] || dp[i][j-1];
那不就很简单了吗?循环也省去了。
当 p[j] 不是特殊字符,且不与 s[i] 相等时,⽆法匹配。
三种情况加起来,就是所有可能的匹配结果。
- 当 s[i] == p[j]或者p[j] == '?' 的时候:此时dp[i][j]=dp[i-1][j-1]
- 当
p[j] == '*'的时候,此时dp[i][j]=dp[i-1][j]||dp[i][j-1] - 当 p[j] 不是特殊字符,且不与 s[i] 相等时,此时dp[i][j]=false;
3. 初始化:
我们知道状态转移方程会使用dp[i - 1][j - 1],那对于i==0和j==0的情况,那这个dp[i - 1][j - 1]不是会越界吗,为了防止这个情况的发生,我们可以将dp表多开一行一列,但是这样子会影响到和原数组的下标映射关系,所以我们可以在原字符串前加一个空字符,这样子就不会有下标映射的困扰了
为了防止大家搞混和原字符串的下标映射关系,我们可以在原字符串前面加一个空字符。这样子下标映射就没有问题了。

由于 dp 数组的值设置为是否匹配,为了不与答案值混淆,我们需要将整个数组初始化为 false 。 由于需要⽤到前⼀⾏和前⼀列的状态,我们初始化第⼀⾏、第⼀列即可。
- dp[0][0] 表⽰两个空串能否匹配,答案是显然的,初始化为 true 。
- 第⼀⾏(dp[0][j])表⽰ s 是⼀个空串, p 串和空串只有⼀种匹配可能,即 p 串表⽰为"***" ,此时也相当于空串匹配上空串。所以,我们可以遍历 p 串,把所有前导为 "*" 的p ⼦串和空串的 dp 值设为 true 。
- 第⼀列表⽰ p 是⼀个空串,不可能匹配上 s 串,跟随数组初始化即可。
4. 填表顺序:
从上往下填每⼀⾏,每⼀⾏从左往右。
5. 返回值:
根据状态表⽰,返回 dp[m][n] 的 值。
class Solution {
public:bool isMatch(string s, string p) {int m=s.size(),n=p.size();s=' '+s;p=' '+p;//初始化vector<vector<bool>>dp(m+1,vector<bool>(n+1,false));dp[0][0]=true;for(int j = 1; j <= n; j++){ if(p[j] == '*') {dp[0][j] = true;}else {break;}}for(int i=1;i<=m;i++){for(int j=1;j<=n;j++){if(s[i]==p[j]||p[j]=='?'){dp[i][j]=dp[i-1][j-1];}else if(p[j]=='*'){dp[i][j]=dp[i-1][j]||dp[i][j-1];}}}return dp[m][n];}
};
题目五——10. 正则表达式匹配 - 力扣(LeetCode)


我们仔细看一下题目
我觉得大家最不理解的就是这个*,我来讲一下
- *不能单独存在,只能和它前面那个字符搭配使用
a*表示a可以出现零次或多次- 题目保证每次出现字符
*时,前面都匹配到有效的字符
1.状态表示
对于两个字符串之间的DP问题,我们通常的思考方式如下:
- 将第一个字符串
s的[0, i]区间和第二个字符串p的[0, j]区间作为研究对象。 - 定义状态
dp[i][j]来表示某种关系或属性,这个关系或属性通常与s的前i+1个字符和p的前j+1个字符有关。
在这个上下文中,我们可以定义 dp[i][j] 为:
dp[i][j]表示s的【0,i】区间的字符串能否与p的【0,j】区间的字符串相匹配。
2.推导状态转移方程
首先啊,这种题目都是在最后一个字符做文章啊!!!
一共有三种情况
- 当 s[i] == p[j]或者p[j] == '.' 的时候
- 当
p[j] == '*'的时候 - 当 p[j] 不是特殊字符,且不与 s[i] 相等时
当 s[i] == p[j]或者p[j] == '.' 的时候,此时两个字符串匹配上了当前的⼀个字 符,只能从 dp[i - 1][j - 1] 中看当前字符前⾯的两个⼦串是否匹配。只能继承上个 状态中的匹配结果, dp[i][j] = dp[i-1][j - 1] ;
当 p[j] == '*' 的时候,和上道题稍有不同的是,上道题 "*" 本⾝便可匹配 0 ~ n 个字符,但此题是要带着 p[j - 1] 的字符⼀起,匹配 0 ~ n 个和 p[j - 1] 相同的字 符。
按照上题的思路,我们可能会像下面这样子干
p[j-1]* 变成空字符串,这个时候我不需要管你s[i]是什么,我直接将p[j-1]*设置为一个空串,此时相当于它匹配了一个寂寞,直接继承状态 dp 数组的前一个状态,即 dp[i][j-2],此时 dp[i][j] = dp[i][j - 2];
p[j-1]*匹配s字符串里的一个字符时,此时p[j-1]==s[i]或者p[j-1]=='.',直接继承状态 dp 数组的前一个状态,即dp[i-1][j-2],此时dp[i][j]=dp[i-1][j-2]
p[j-1]* 匹配s字符串里的两个字符时,此时p[j-1]==s[i]或者p[j-1]=='.',直接继承状态 dp 数组的前一个状态,即dp[i-2][j-2],此时dp[i][j]=dp[i-2][j-2]
那么p[j-1]* 匹配3个字符,4个字符……啥的就不说了啊!!
p[j-1]* 向前匹配 1 ~ n 个字符,直⾄匹配上整个 s 串。此时相当于 从 dp[k][j - 1] (0 <= k <= i) 中所有匹配情况中,选择性继承可以成功的 情况。此时 dp[i][j] = dp[k][j - 2] (0 <= k <= i) ;
优化:当我们发现,计算⼀个状态的时候,需要⼀个循环才能搞定的时候,我们要想到去优化。优化的⽅向就是⽤⼀个或者两个状态来表⽰这⼀堆的状态。通常就是把它写下来,然后⽤数学的⽅式 做⼀下等价替换。
在这里,我们发现只要这个dp[i][j] = dp[k][j - 2] (0 <= k <= i) ,只要dp[i][j] = dp[k][j - 2] (0 <= k <= i) 里面任何一个是true,那么dp[i][j]就是true。
当 p[j] == '*' 时,状态转移⽅程为:dp[i][j] = dp[i][j - 1] || dp[i - 1][j - 1] || dp[i - 2][j - 1] ......
但是当我们不断的修改i的值,我们就会发现下面这个情况
- dp[i][j] = dp[i][j - 2] || dp[i - 1][j - 2] || dp[i - 2][j - 2] ......
- dp[i - 1][j] = dp[i - 1][j - 2] || dp[i - 2][j - 2] || dp[i - 3] [j - 2] ......
大家惊奇的发现dp[i][j]=dp[i-1][j] || dp[i][j-2];
但是后面这个dp[i-1][j]是有前提的——p[j-1] == s[i] || p[j-1] == '.'。
- dp[i][j] = dp[i][j-2] || (dp[i-1][j] && (p[j-1] == s[i] || p[j-1] == '.'));
那不就很简单了吗?循环也省去了。
当 p[j] 不是特殊字符,且不与 s[i] 相等时,⽆法匹配。
三种情况加起来,就是所有可能的匹配结果。
- 当 s[i] == p[j]或者p[j] == '?' 的时候:此时dp[i][j]=dp[i-1][j-1]
- 当
p[j] == '*'的时候,此时dp[i][j] = dp[i][j-2] || (dp[i-1][j] && (p[j-1] == s[i] || p[j-1] == '.')); - 当 p[j] 不是特殊字符,且不与 s[i] 相等时,此时dp[i][j]=false
3. 初始化:
由于 dp 数组的值用于表示是否匹配,为了避免与答案值混淆,我们需要将整个数组初始化为 false。由于需要用到前一行和前一列的状态,我们需要特别初始化第一行和第一列。
-
dp[0][0]表示两个空串能否匹配,答案显然是true,因为空串与空串总是匹配的。 -
第一行是dp[0][j],这表示 s 是一个空串,而
p串和空串的匹配情况只有一种可能,即p串全部字符表示为“ 任意字符 +*”,此时也相当于空串匹配上空串。所以,我们可以遍历 p 串,把所有前导为"任⼀字符+*" 的 p ⼦串和空串的 dp 值设为 true -
第一列表示
p是一个空串,此时不可能匹配上s串(除非p本身就是一个空串或者由*组成的表示空串的模式,但这种情况已经在第一行处理过了),因此第一列(除了dp[0][0])应该全部初始化为false。
4. 填表顺序:
从上往下填每一行,每一行从左往右。即按照 dp[i][j] 的顺序,其中 i 从 0 到 m(s 的长度),j 从 0 到 n(p 的长度)。
5. 返回值:
根据状态表示,最终返回 dp[m][n] 的值,它表示 s 串和 p 串是否匹配。
class Solution {
public:bool isMatch(string s, string p) {int m=s.size(),n=p.size();s=' '+s;p=' '+p;vector<vector<bool>>dp(m+1,vector<bool>(n+1,false));//初始化dp[0][0] = true; //本来应该是for(int i=1;i<=n;i+=2)的,但是我们p=' '+p;,//所以真正的第二个字符的下标是2for(int i=2;i<=n;i+=2){if(p[i] == '*') dp[0][i] = true;elsebreak;}for(int i=1;i<=m;i++){for(int j=1;j<=n;j++){if(s[i]==p[j]||p[j]=='.'){dp[i][j]=dp[i-1][j-1];}else if(p[j]=='*'){dp[i][j] = dp[i][j-2] || (dp[i-1][j] && (s[i] == p[j-1] || p[j-1] == '.'));}}}return dp[m][n];}
}; 
题目六——97. 交错字符串 - 力扣(LeetCode)




1.状态表示
对于两个字符串之间的 dp 问题,我们⼀般的思考⽅式如下:
- 选取第⼀个字符串的 [0, i] 区间以及第⼆个字符串的 [0, j] 区间当成研究对象,结合题⽬的要求来定义「状态表⽰」;
- 然后根据两个区间上「最后⼀个位置的字符」,来进⾏「分类讨论」,从⽽确定「状态转移 ⽅程」。
我们可以根据上⾯的策略,解决⼤部分关于两个字符串之间的 dp 问题。 但是这道题目有3个字符串。我们的经验还能用吗?应该是可以的

我们定了s1和s2的长度,那肯定能知道此时它们能匹配上的s3的长度。
dp[i][j] 表示字符串 s1 的【0,i】和字符串 s2 的【0,j】能否拼接成字符串 s3 的【0,i+j-1】里面的字符。
大家可能看这个i+j-1不太顺眼,所以我们可以进行一下优化。
我们先把所有原字符串进行预处理,也就是s1 = " " + s1, s2 = " " + s2, s3 = " " + s3 。
dp[i][j] 表示字符串 s1 的【1,i】和字符串 s2 的【1,j】能否拼接成字符串 s3 的【1,i+j】里面的字符。
2.推导状态转移方程
先分析⼀下题⽬,题⽬中交错后的字符串为 s1 + t1 + s2 + t2 + s3 + t3...... ,看似⼀个 s ⼀个 t 。实际上 s1 能够拆分成更⼩的⼀个字符,进⽽可以细化成 s1 + s2 + s3 + t1 + t2 + s4...... 。
也就是说,并不是前⼀个⽤了s 的⼦串,后⼀个必须要⽤ t 的⼦串。这⼀点理解,对我们的状态转移很重要。
继续根据两个区间上「最后⼀个位置的字符」,结合题⽬的要求,来进⾏「分类讨论」:
(注意:下标是从1开始的)
- 当
s3[i+j] = s1[i]时:- 这意味着
s3的当前最后一个字符与s1的当前最后一个字符匹配。 - 因此,为了判断整个字符串能否交错组成,我们需要检查
s1的前i-1个字符与s2的前j个字符是否能交错形成s3的前i+j-1个字符,即dp[i-1][j]。 - 此时,更新规则为:
dp[i][j] = dp[i-1][j](如果s1的这部分与s2的已考虑部分能匹配s3的对应部分)。
- 这意味着
- 当
s3[i+j] = s2[j]时:- 这意味着
s3的当前最后一个字符与s2的当前最后一个字符匹配。 - 因此,为了判断整个字符串能否交错组成,我们需要检查
s1的前i个字符与s2的前j-1个字符是否能交错形成s3的前i+j-1个字符,即dp[i][j-1]。 - 此时,更新规则为:
dp[i][j] = dp[i][j-1](如果s2的这部分与s1的已考虑部分能匹配s3的对应部分)。
- 这意味着
- 当
s3[i+j]既不等于s1[i]也不等于s2[j]时:- 这表明
s3的当前最后一个字符既不能与s1的当前最后一个字符匹配,也不能与s2的当前最后一个字符匹配。 - 因此,
dp[i][j]在这种情况下必然为False,因为无法通过添加s1或s2的下一个字符来形成s3的当前部分。
- 这表明
但是我们仔细思考一下s3[i+j] = s1[i]和s3[i+j] = s2[j]这两种情况任意一个满足,都是符合条件的,有的人可能就会像下面这样子写
// 检查s1的当前字符是否与s3的当前位置匹配,并考虑前一个状态if (s1[i] == s3[i + j]) {dp[i][j] = dp[i - 1][j];}// 检查s2的当前字符是否与s3的当前位置匹配,并考虑前一个状态else if (s2[j] == s3[i + j]) {dp[i][j] = dp[i][j - 1];}// 如果都不匹配,则dp[i][j]保持为false(默认初始化值)但是这只能判断到一种情况,明显不对啊,有人做出下面这个改进
// 检查s1的当前字符是否与s3的当前位置匹配,并考虑前一个状态if (s1[i] == s3[i + j]) {dp[i][j] = dp[i - 1][j];}// 检查s2的当前字符是否与s3的当前位置匹配,并考虑前一个状态if (s2[j] == s3[i + j]) {dp[i][j] = dp[i][j - 1];}// 如果都不匹配,则dp[i][j]保持为false(默认初始化值)那要是我s1[i]==s2[j]==s3[i+j],dp[i-1][j]是true,dp[i][j-1]是false,你不就炸了吗?
我们接着改进
if(s1[i] == s3[i + j]||s2[j] == s3[i + j])
{dp[i][j] =dp[i-1][j]||dp[i][j-1];
}那要是我s1[i]==s3[i+j],dp[i-1][j]是false,dp[i][j-1]是true,你不就炸了吗?
接下来我告诉大家一种方法
所以我们只能是下面这个情况!
dp[i][j] = (s1[i] == s3[i + j] && dp[i - 1][j])|| (s2[j] == s3[i + j] && dp[i][j - 1]);其实这括号里面最前面是表示这括号的值对应的情况,后面部分则是这种情况里dp[i][j]应该被赋予的值。
大家看这个式子可能有点懵,或者感觉有点晕:
- 当s1[i] == s3[i + j]时,s1[i] == s3[i + j]为true,s1[i] == s3[i + j]||dp[i - 1][j]的值取决于dp[i - 1][j],如果dp[i - 1][j]是true,那s1[i] == s3[i + j] && dp[i - 1][j]就是true,如果dp[i - 1][j]是false,那s1[i] == s3[i + j] && dp[i - 1][j]就是false
- 当s2[j] == s3[i + j]时,s2[j] == s3[i + j]为true,s2[j] == s3[i + j]||dp[i][j-1]的值取决于dp[i][j-1],如果dp[i][j-1]是true,那s1[i] == s3[i + j] && dp[i][j-1]就是true,如果dp[i][j-1]是false,那s1[i] == s3[i + j] && dp[i][j-1]就是false
- 中间连接部分使用||的原因是:只要上述条件中有一个成立,
dp[i][j]的结果就为True,代表字符串s1的【1,i】和字符串s2的【1,j】能拼接成字符串s3的【1,i+j】里面的字符。
综上所述,状态转移方程可以总结为:
dp[i][j] = (s1[i] == s3[i+j] && dp[i-1][j]) || (s2[j] == s3[i+j] && dp[i][j-1])
3. 初始化过程:
在进行动态规划填表之前,我们需要对dp数组进行初始化。由于状态转移方程中涉及到了i-1和j-1位置的值,因此我们需要特别注意“第一个位置”(即dp[0][j]和dp[i][0])以及“第一行”和“第一列”的初始化。
-
dp[0][0]的初始化:dp[0][0] = true,因为空串与空串相加仍然是一个空串,所以它们能够匹配。 -
第一行的初始化:
当s1为空串时(即i=0的情况,但注意在数组中我们用dp[0][j]来表示,其中j代表s2的【1,j】区间的字符),我们只需要考虑s2的【1,j】区间的字符是否能匹配s3的【1,j】区间的字符。状态转移方程为:dp[0][j] = (s2[j] == s3[j] && dp[0][j-1]); -
第一列的初始化:
当s1为空串时(即j=0的情况,但注意在数组中我们用dp[i][0]来表示,其中j代表s1的【1,i】区间的字符),我们只需要考虑s1的【1,i】区间的字符是否能匹配s3的【1,i】区间的字符。状态转移方程为:dp[i][0] = (s1[i] == s3[i] && dp[i-1][0]);
4. 填表顺序:
根据状态转移方程,我们需要按照“从上往下”的顺序逐行填写dp数组,而在每一行内,又需要“从左往右”地逐个填写元素。这样的填表顺序可以确保在计算每个dp[i][j]时,其所依赖的前置状态dp[i-1][j]和dp[i][j-1]都已经被计算出来。
5. 返回值:
最终,我们需要返回dp[m][n]的值,它表示s1的所有字符与s2的所有字符是否能够交错拼接成s3的所有字符。
class Solution {
public:bool isInterleave(string s1, string s2, string s3) {int m = s1.size(), n = s2.size(); // 使用s1和s2的实际长度if (m + n != s3.size()) { return false;}// s3的长度应该在调用此函数之前就已经验证过是否等于m+n,但这里没有显式检查vector<vector<bool>> dp(m + 1, vector<bool>(n + 1, false));// 为了方便索引,给s1, s2, s3前都加一个空格(相当于在dp数组中从1开始考虑字符)s1 = ' ' + s1;s2 = ' ' + s2;s3 = ' ' + s3;// 初始化dp数组dp[0][0] = true; // 空串+空串能构成空串// 初始化第一列(只考虑s1的情况)for (int i = 1; i <= m; ++i) {dp[i][0] = (s1[i] == s3[i] && dp[i - 1][0]);}// 初始化第一行(只考虑s2的情况)for (int j = 1; j <= n; ++j) {dp[0][j] = (s2[j] == s3[j] && dp[0][j - 1]);}// 填充dp数组的其余部分for (int i = 1; i <= m; ++i) {for (int j = 1; j <= n; ++j) {dp[i][j] = (s1[i] == s3[i + j] && dp[i - 1][j])|| (s2[j] == s3[i + j] && dp[i][j - 1]);}}// 返回结果return dp[m][n];}
};
题目七——712. 两个字符串的最小ASCII删除和 - 力扣(LeetCode)


正难则反:求两个字符串的最⼩ ASCII 删除和,其实就是找到两个字符串中所有的公共⼦序列 ⾥⾯, ASCII 最⼤和。
面对求解两个字符串的最小ASCII删除和的问题,我们可以转换思路,通过寻找两个字符串中的所有公共子序列,并计算这些公共子序列中的ASCII最大和来间接求解。这是因为,最小ASCII删除和实际上等于两个字符串的总ASCII码和减去公共子序列的ASCII最大和的两倍。
1.状态表示:
dp[i][j] 表示字符串 s1 的 [0, i] 区间以及字符串 s2 的 [0, j-1] 区间内的所有子序列中,公共子序列的ASCII最大和。
2.状态转移方程:
- 当
s1[i] == s2[j]时:
应该在 s1 的 [0, i-1] 区间以及 s2 的 [0, j-1] 区间内找到一个公共子序列的最大和,然后在其后添加一个 s1[i-1](或 s2[j-1],因为它们是相等的)字符。
此时,dp[i][j] = dp[i-1][j-1] + s1[i-1](注意这里 s1[i-1] 是字符,需要转换为对应的ASCII值进行计算,但为简化表述,这里仍用 s1[i-1] 表示)。
- 当
s1[i-1] != s2[j-1]时:
公共子序列的最大和可能存在于以下三种情况中
s1的[0, i-1]区间以及s2的[0, j]区间内:dp[i][j] = dp[i-1][j]s1的[0, i]区间以及s2的[0, j-1]区间内:dp[i][j] = dp[i][j-1]s1的[0, i-1]区间以及s2的[0, j-1]区间内:dp[i][j] = dp[i-1][j-1]
但由于前两种情况已经包含了第三种情况的可能性(即不选择当前字符作为公共子序列的一部分),因此只需考虑前两种情况下的最大值。
综上,状态转移方程为:dp[i][j] = max(dp[i-1][j], dp[i][j-1])
3.初始化:
为了方便处理空串的情况,我们在原始的 dp 表上额外增加一行和一列,用于表示空串。
初始化时,第一行和第一列的值都设为0,因为当其中一个字符串为空时,公共子序列的ASCII和为0。
4.填表顺序:
从上往下逐行填写 dp 表,每行从左往右填写。
5.返回值:
根据状态表示,我们不能直接返回 dp 表中的某个值。
首先找到 dp[m+1][n+1](注意这里 m 和 n 分别是 s1 和 s2 的长度,由于我们增加了额外的行和列,所以这里是 m+1 和 n+1),它表示两个字符串的最长公共子序列的ASCII最大和。
然后统计两个字符串的总ASCII码和 sum。
最后返回 sum - 2 * dp[m+1][n+1],即为所求的最小ASCII删除和。
class Solution {
public:int minimumDeleteSum(string s1, string s2) {int m = s1.size(), n = s2.size();vector<vector<int>> dp(m + 1, vector<int>(n + 1));for (int i = 1; i <= m; i++)for (int j = 1; j <= n; j++) {if(s1[i-1]==s2[j-1]){dp[i][j]=dp[i-1][j-1]+s1[i-1];}else{dp[i][j]=max(dp[i-1][j],dp[i][j-1]);}}int sum = 0; //统计元素和for(auto s : s1) sum += s;for(auto s : s2) sum += s;return sum - 2*dp[m][n];}
};
题目八——718. 最长重复子数组 - 力扣(LeetCode)

子数组是数组中“连续”的一段,我们习惯上“以某一个位置为结尾”来研究。由于是两个数组,因此我们可以尝试以第一个数组的 i 位置为结尾以及第二个数组的 j 位置为结尾来解决问题。
1.状态表示:
dp[i][j] 表示以第一个数组的 i 位置为结尾,以及第二个数组的 j 位置为结尾的公共的、长度最长的“子数组”的长度。
2.状态转移方程:
对于 dp[i][j],当 nums1[i-1] == nums2[j-1](注意数组下标从0开始,但dp数组下标从1开始,所以这里是 i-1 和 j-1)的时候,才有意义。此时最长重复子数组的长度应该等于 1 加上除去最后一个位置时,以 i-1, j-1 为结尾的最长重复子数组的长度。
因此,状态转移方程为:dp[i][j] = 1 + dp[i-1][j-1](当 nums1[i-1] == nums2[j-1]);否则 dp[i][j] = 0。
3.初始化:
添加一行和一列,dp 数组的下标从 1 开始,这样处理起来更方便,无需额外判断越界。
第一行和第一列表示其中一个数组为空的情况,此时没有重复子数组,因此里面的值设置成 0。
4.填表顺序:
根据状态转移,我们需要从上往下填每一行,每一行从左往右。
5.返回值:
根据状态表示,我们需要返回 dp 表里面的“最大值”。
class Solution {
public:int findLength(vector<int>& nums1, vector<int>& nums2) {int m = nums1.size(), n = nums2.size();vector<vector<int>> dp(m + 1, vector<int>(n + 1));int ret = 0;for (int i = 1; i <= m; i++)for (int j = 1; j <= n; j++)if (nums1[i - 1] == nums2[j - 1])dp[i][j] = dp[i - 1][j - 1] + 1, ret = max(ret, dp[i][j]);return ret;}
};
相关文章:
动态规划六——两个数组的dp问题
目录 题目一——1143. 最长公共子序列 - 力扣(LeetCode) 题目二——1035. 不相交的线 - 力扣(LeetCode) 题目三——115. 不同的子序列 - 力扣(LeetCode) 题目四—— 44. 通配符匹配 - 力扣(…...

项目优化之策略模式
目录 策略模式基本概念 策略模式的应用场景 实际项目中具体应用 项目背景: 策略模式解决方案: 计费模块策略模式简要代码 策略模式基本概念 策略模式(Strategy Pattern) 是一种行为型设计模式,把算法的使用放到环境类中,而算…...

[读书日志]从零开始学习Chisel 第四篇:Scala面向对象编程——操作符即方法(敏捷硬件开发语言Chisel与数字系统设计)
3.2操作符即方法 3.2.1操作符在Scala中的解释 在其它语言中,定义了一些基本的类型,但这些类型并不是我们在面向对象中所说的类。比如说1,这是一个int类型常量,但不能说它是int类型的对象。针对这些数据类型,存在一些…...

三子棋游戏
目录 1.创建项目 2.主函数编写 3.菜单函数编写 4.宏定义棋盘行和列 5.棋盘初始化 6.打印棋盘 7.玩家下棋 8.电脑下棋 9.平局判断 10.输赢判断 11.game函数 三子棋游戏(通过改变宏定义可以变成五子棋),玩家与电脑下棋 1.创建项目…...

MyBatis执行一条sql语句的流程(源码解析)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 MyBatis执行一条sql语句的流程(源码解析) MyBatis执行sql语句的流程加载配置文件加载配置文件的流程 创建sqlsessionFactory对象解析Mapper创建sqlses…...

【电机控制】低通滤波器及系数配置
【电机控制】低通滤波器及系数配置 文章目录 [TOC](文章目录) 前言一、低通滤波器原理二、理论计算三、代码四、参考资料总结 前言 提示:以下是本篇文章正文内容,下面案例可供参考 一、低通滤波器原理 二、理论计算 三、代码 //低通滤波 pv->Ealpha…...

ArcgisServer过了元旦忽然用不了了?许可过期
昨天过完元旦之后上班发现好多ArcgisServer的站点运行出错了,点击日志发现,说是许可过去,也就是当时安装ArcgisServer时读取的ecp文件过期了,需要重新读取。 解决方法 1.临时方法,修改系统时间,早于2024年…...
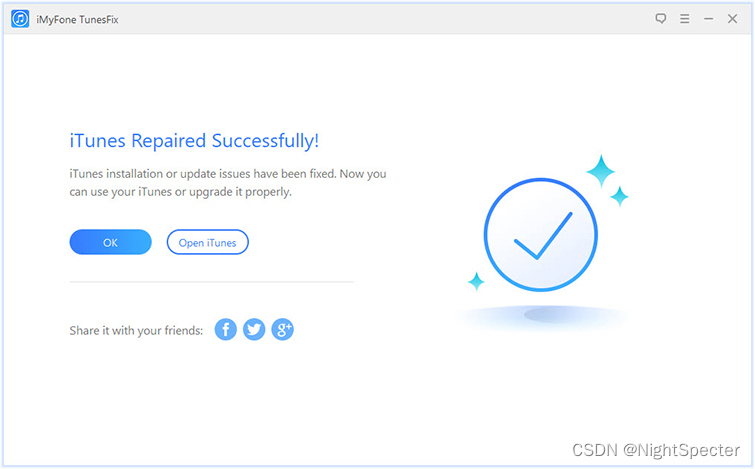
如何在不丢失数据的情况下从 IOS 14 回滚到 IOS 13
您是否后悔在 iPhone、iPad 或 iPod touch 上安装 iOS 14?如果你这样做,你并不孤单。许多升级到 iOS 14 beta 的 iPhone、iPad 和 iPod touch 用户不再适应它。 如果您在正式发布日期之前升级到 iOS 14 以享受其功能,但您不再适应 iOS 14&am…...

【算法刷题】链表
文章目录 环形链表判断是否有环找出环的入口位置 双指针反转链表(Reverse a Linked List)移除链表中的指定元素(Remove Linked List Elements) 环形链表 判断是否有环 环形链表是指链表中的某些节点的 next 指针指向了链表中的某…...

计算机网络 —— 网络编程实操(1)(UDP)
计算机网络 —— 网络编程实操(UDP) 套接字端口套接字的定义为什么需要套接字? 套接字的分类1. 按照通信协议分类2. 按照地址族(Address Family)分类3. 按照通信模式分类 socket APIsockaddr结构 使用接口套接字初始化…...

selenium 确保页面完全加载
在使用Python和Selenium进行Web自动化时,确保页面完全加载是非常重要的。为了实现这一点,Selenium提供了两种主要类型的等待:显式等待(Explicit Waits)和隐式等待(Implicit Waits)。此外&#x…...

[极客大挑战 2019]HardSQL 1
看了大佬的wp,没用字典爆破,手动试出来的,屏蔽了常用的关键字,例如:order select union and 最搞的是,空格也有,这个空格后面让我看了好久,该在哪里加括号。 先传入1’ 1试试&#…...

vip与haproxy构建nginx高可用集群传递客户端真实ip
问题 系统使用了vip与haproxy实现高可用以及对nginx进行负载均衡,但是发现在上游的应用服务无法拿到客户端的请求ip地址,拿到的是主haproxy机器的ip,以下是nginx与haproxy的缩减配置: location ~* ^/(xx|xx) {proxy_pass http:/…...

Easticsearch介绍|实战?
Elasticsearch 是一个分布式的、RESTful 风格的搜索和数据分析引擎,适用于各种用例,如日志分析、全文搜索、实时应用监控等。它设计用来处理大量数据,并且可以快速地提供相关的搜索结果。以下是一些 Elasticsearch 的实战应用场景以及如何在这…...
Tkinter笔记(二十一):Messagebox信息提示功能控件)
Python图形界面(GUI)Tkinter笔记(二十一):Messagebox信息提示功能控件
messagebox 就像是 tkinter 库里的一个好帮手,它能帮你弹出各种各样的消息框给用户看。这些消息框可以告诉用户很多东西,比如提示、警告或者错误信息之类的。在 tkinter 库里,messagebox 这个模块有很多不同的函数,每个函数都能弹出一种特定的消息框。用这些函数,开发者可…...

vue3+ts+element-plus 表单el-form取消回车默认提交
问题描述:在表单el-form中的el-input中按回车后,页面会刷新,url也会改变, 回车前: 回车后: 相关代码: 解决方法1:在 el-form 上阻止默认的 submit 事件,增加 submit.pre…...

Web Services 简介
Web Services 简介 1. 引言 Web Services 是一种基于网络的软件服务,它允许不同的应用程序在互联网上相互通信和交互。这种技术是基于开放的互联网标准,如HTTP、XML、SOAP和WSDL,使得不同平台和编程语言的应用程序能够轻松地实现互操作性。Web Services 的出现,极大地推动…...

Vue3苦逼的学习之路
从一名测试转战到全栈是否可以自学做到,很多朋友肯定会说不可能,或就算转了也是个一般水平,我很认同,毕竟没有经过各种项目的摧残,但是还是得踏足一下这个领域。所以今天和大家分享vue3中的相关内容,大佬勿…...

AcWing练习题:两点间的距离
给定两个点 P1 和 P2,其中 P1P1 的坐标为 (x1,y1),P2 的坐标为 (x2,y2),请你计算两点间的距离是多少。 distance√(x2−x1)^2(y2−y1)^2 输入格式 输入共两行,每行包含两个双精度浮点数 xi,yi,表示其中一个点的坐标…...

文献分享:RoarGraph——跨模态的最邻近查询
文章目录 1. \textbf{1. } 1. 导论 1.1. \textbf{1.1. } 1.1. 研究背景 1.2. \textbf{1.2. } 1.2. 本文的研究 1.3. \textbf{1.3. } 1.3. 有关工作 2. \textbf{2. } 2. 对 OOD \textbf{OOD} OOD负载的分析与验证 2.1. \textbf{2.1. } 2.1. 初步的背景及其验证 2.1.1. \textbf{2…...
)
Unity Addressable可寻址系统 -- 核心概念与工程导入实战 -- 新手上路(一)
1. 为什么需要Addressable系统 刚接触Unity开发时,我最头疼的就是资源管理问题。记得第一次做手游项目,把所有贴图、模型、音频一股脑塞进Resources文件夹,结果打包后发现APK体积直接飙到2GB。更糟的是每次修改一个小资源,整个包都…...

StarUML 4.0.1导出清晰UML图,手把手教你修改JS文件去除烦人水印
StarUML 4.0.1导出清晰UML图的完整解决方案 你是否遇到过这样的困扰:精心设计的UML图在导出时被强制添加了"未注册"水印,严重影响专业文档的呈现效果?这个问题困扰着许多使用StarUML进行软件设计的开发者和学生。本文将为你提供一个…...

AI Agent Harness Engineering 决策偏差修正:如何提升智能体在复杂场景下的可靠性?
AI Agent Harness Engineering 决策偏差修正:如何提升智能体在复杂场景下的可靠性? 摘要/引言 你是否曾经遇到过这样的情况:你精心设计的AI智能体在测试环境中表现完美,但一旦部署到真实世界的复杂场景中,就开始做出令人费解的决策?从自动驾驶汽车在罕见天气条件下的误…...

人工智能入门:图解Qwen3-ASR-0.6B语音识别模型的工作原理
人工智能入门:图解Qwen3-ASR-0.6B语音识别模型的工作原理 你有没有想过,当你对着手机说“嘿,Siri”或者“小爱同学”时,它到底是怎么听懂你说话的?这背后,就是语音识别技术在默默工作。今天,我…...

工业级标注数据价值:SenseVoice-Small ONNX模型泛化能力实测报告
工业级标注数据价值:SenseVoice-Small ONNX模型泛化能力实测报告 1. 模型核心能力解析 SenseVoice-Small ONNX模型是一个经过量化的语音识别模型,专注于高精度多语言语音识别、情感辨识和音频事件检测。这个模型最大的特点是采用了工业级的大规模标注数…...

专业NCM文件解密指南:高效解锁网易云音乐加密音频的完整解决方案
专业NCM文件解密指南:高效解锁网易云音乐加密音频的完整解决方案 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 项目概述与技术原理 NCMDump是一款专注于解密网易云音乐NCM加密格式的专业工具,它能够将受版…...

**发散创新:基于Go语言的纳米服务架构实践与代码实战**在微服务架构日益复杂的今天,**
发散创新:基于Go语言的纳米服务架构实践与代码实战 在微服务架构日益复杂的今天,“纳米服务”(Nano-Service) 正成为云原生领域的新趋势——它强调极致轻量、快速启动、独立部署,并通过边缘计算和容器化技术实现资源最…...

为什么92%的AGI项目注定无法跃迁至超级智能?——基于IEEE标准框架的4层能力缺口诊断
第一章:AGI与超级智能的关系探讨 2026奇点智能技术大会(https://ml-summit.org) 通用人工智能(AGI)指具备跨领域认知、自主学习、抽象推理与目标建模能力的系统,其核心在于泛化性而非任务专用性;而超级智能ÿ…...
)
基于西门子PLCS7-1200的程序仿真立体车库设计报告(含硬件原理图和CAD)
立体车库设计,基于西门子plcs7-1200带程序仿真,报告(过1w),硬件原理图和cad 功能具体如下: 地面层配备七个停车位的升降系统能够有效执行车位的垂直转移在该层,四个停车位安装有自动升降装置࿰…...

纯 AI 高级攻击是伪命题?平庸的工业化才是未来三年最大的网络风险
在2026年的全球网络安全版图上,没有任何一个话题比“AI与网络攻击”更能撕裂行业共识。乐观派宣称AI将成为防御者的终极护城河,能自动识别并拦截所有未知威胁;悲观派则不断渲染“天网降临”的恐慌,声称具备自我意识的自主恶意软件…...