JVM实战—11.OOM的原因和模拟以及案例
大纲
1.线上系统突然由于OOM内存溢出挂掉
2.什么是内存溢出及哪些区域会发生内存溢出
3.Metaspace如何因类太多而发生内存溢出
4.无限制调用方法如何让线程的栈内存溢出
5.对象太多导致堆内存实在放不下而内存溢出
6.模拟JVM Metaspace内存溢出的场景(动态生成268个类占10M)
7.模拟JVM栈内存溢出的场景(线程调用6000次方法占1M栈内存)
8.模拟JVM堆内存溢出的场景(36万个Object对象才占10M堆内存)
9.一个超大数据量处理系统的OOM(数据缓存本地 + 重试发送直到Kafka恢复)
10.两个新手误写代码如何导致OOM(方法循环调用自己 + 动态代理没缓存)
1.线上系统突然由于OOM内存溢出挂掉
(1)最常遇到的故障——系统OOM
(2)如何处理OOM
(1)最常遇到的故障——系统OOM
作为Java程序员,先不考虑系统依赖的缓存、消息队列、数据库等挂掉。就Java系统本身而言,最常见的故障原因就是OOM,即内存溢出。
所谓OOM内存溢就是:JVM内存有限,但系统程序不断往JVM内存里面创建对象,结果JVM内存放不下对象,就直接溢出了。如下图示:

一旦系统程序不停地往JVM内存里放入大量对象,JVM实在放不下后,就会OutOfMemory内存溢出,直接瘫痪不能工作了。
通常而言,内存溢出会对Java系统造成毁灭性打击,因为这代表JVM内存不足以支撑系统程序的运行。
所以一旦发生OOM,就会导致系统程序直接停止运转,甚至会导致JVM进程直接崩溃掉,进程都没了。这时线上看起来的场景就是,用户突然发现点击APP、点击没反应了。然后大量投诉和反馈给客服,客服转移给运营,运营反馈给技术。
(2)如何处理OOM
当发生OOM之后,系统到底为什么会突然OOM?系统代码到底产生了多少对象、为什么会产生这么多对象?JVM为什么会放不下这么多对象?怎么排查这个问题、又如何解决?
2.什么是内存溢出及哪些区域会发生内存溢出
(1)一个常见的问题
(2)运行一个Java系统就是运行一个JVM进程
(3)JVM进程怎么执行编写好的那些代码
(4)Java虚拟机栈:让线程执行各种方法
(5)堆内存:存放代码中创建的各种对象
(1)一个常见的问题
JVM里的内存溢出到底指的是什么,哪些区域有可能会发生内存溢出?接下来从JVM核心运行原理出发,介绍哪些地方可能会发生内存溢出。
(2)运行一个Java系统就是运行一个JVM进程
首先需要清楚的是:启动一个Java系统,其本质就是启动一个JVM进程。比如下面的一段代码:运行这个代码时,会发生哪些事情?
public class HelloWorld {public static void main(String[] args) {String message = "Hello World";System.out.println(message);}}
写好的代码都是后缀为".java"的源代码,这种代码是不能运行的。所以第一步就是先把".java"源代码文件编译成一个".class"字节码文件,这个字节码文件才是可以运行的。如下图示:

接着对于这种编译好的字节码文件,比如HelloWorld.class。如果HelloWorld.java里面包含了main方法,那么就可以在命令行中使用"java命令"来执行这个字节码文件。
一旦执行了java命令,就会启动一个JVM进程,这个JVM进程就会负责执行写好的那些代码。如下图示:

所以首先要清楚的是:运行一个Java系统,本质上就是启动一个JVM进程。由这个JVM进程来负责执行编写好的代码,而且JVM进程就会从指定代码的main方法入手,开始执行代码。
(3)JVM进程怎么执行编写好的那些代码
Java作为面向对象的语言,最基本的代码组成单元就是类。Java开发平时写的Java代码,就是写一个一个的类。然后在一个个的类里定义各种变量、方法、数据结构,实现业务逻辑。所以JVM要执行代码,首先需要把写好的类加载到内存里。
在JVM的内存区域里有一块区域叫永久代,JDK 1.8以后叫Metaspace。这块内存区域是用来存放各种类的信息,包括JDK自身的一些类的信息。
JVM有一套类加载的机制,类加载器会负责从编译好的.class字节码文件中把类加载到内存。如下图示:

既然Metaspace是用来存放类信息的,那么就有可能发生OOM。所以第一块可能发生OOM的区域,就是存放类信息的Metaspace区域。
(4)Java虚拟机栈:让线程执行各种方法
写好的Java代码虽然是一个个的类,但核心代码逻辑一般都封装在类里的各种方法中。比如JVM加载HelloWorld类到内存后,会怎样执行里面的代码呢?
Java语言中的一个通用的规则是:JVM进程总是从main方法开始执行的。既然在HelloWorld中写了main()方法,那么JVM就会执行该方法的代码。
一.JVM进程里会如何执行main()方法
其实所有方法的执行,都必须依赖JVM进程中的某个线程去执行,所以可以理解为线程才是执行代码的核心主体。JVM进程启动之后默认会有一个main线程,这个main线程就是专门负责执行main()方法的。

二.方法里的局部变量放在哪里
现在又有一个问题,在main()方法里定义了一个局部变量message,方法里的局部变量可能会有很多,那么这些局部变量是放在哪里的呢?
每个线程都会有一个自己的虚拟机栈,就是所谓的栈内存。每个线程执行一个方法就会为方法创建一个栈桢放入自己的虚拟机栈里,然后就会在这个方法的栈桢里放入该方法中定义的各种局部变量。如下图示:

可以设置JVM中每个线程的虚拟机栈的内存大小,一般设置为1M。既然每个线程的虚拟机栈的内存大小是固定的,那也可能会发生OOM。所以第二块可能发生OOM的区域,就是每个线程的虚拟机栈内存。
(5)堆内存:存放代码中创建的各种对象
在一些方法中,可能会频繁创建各种各样的对象,这些对象都是放在堆内存里的。如下图示:

通常在JVM中分配给堆内存的空间是固定的,所以当程序不停在堆内存创建对象时,堆内存也有可能发生内存溢出。因此第三块可能发生OOM的区域,就是堆内存空间。
(6)总结
可能发生OOM的区域有三块:
第一块是存放类信息的Metaspace区域
第二块是每个线程的虚拟机栈内存
第三块是堆内存空间
3.Metaspace如何因类太多而发生内存溢出
(1)Metaspace区域是如何触发内存溢出的
(2)什么情况下会发生Metaspace内存溢出
(1)Metaspace区域是如何触发内存溢出的
在启动一个JVM时是可以设置很多参数,其中有一些参数就是专门用来设置Metaspace区域的内存大小。如下所示:
-XX:MetaspaceSize=512m-XX:MaxMetaspaceSize=512m
这限定了Metaspace区域的内存大小为512M。

所以在一个JVM中,Metaspace区域的大小是固定的,比如512M。如果JVM不停加载类,加载了很多类导致Metaspace满了,此时会如何?
此时由于Metaspace区域满了,就会触发FGC。FGC会进行Young GC回收新生代、会进行Old GC回收老年代、并且尝试回收Metaspace区域中的类。

一.当Metaspace区域满了就会触发FGC,尝试回收Metaspace的类
那么什么样的类才是可以被回收的呢?这个条件是相当的苛刻,包括但不限于以下一些:比如这个类的类加载器要被回收、这个类的所有对象实例也要被回收等。所以当Metaspace区域满了,未必能回收掉里面很多的类。如果回收不了多少类,但程序还在加载类放到Metaspace中,会怎么样?
二.FGC尝试回收了Metaspace中的类之后发现还是没能腾出足够空间
此时还要继续往Metaspace中放入更多的类,就会引发内存溢出的问题。一旦发生内存溢出就说明JVM已经没办法继续运行下去,系统就崩溃了。
以上一二两点便是Metaspace区域发生内存溢出的根本原因:Metaspace满了之后先FGC -> 发现回收不了足够空间就OOM。
(2)什么情况下会发生Metaspace内存溢出
Metaspace这块区域一般很少发生内存溢出,如果发生内存溢出一般都是由于如下两个原因:
原因一:系统上线时使用默认的JVM参数,没有设置Metaspace区域的大小。这就可能会导致默认的Metaspace区域才几十M而已。对于一个大系统,它自己会有很多类+依赖jar包的类,几十M可能不够。所以对于这种原因,通常在上线系统时设置好Metaspace大小如512M。
原因二:开发人员有时候会用CGLIB之类的技术动态生成一些类。一旦代码中没有控制好,导致生成的类过多时,那么就容易把Metaspace给占满,从而引发内存溢出。
(3)总结
Metaspace区域发生内存溢出的原理是:Metaspace满了之后先FGC -> 发现回收不了足够空间就OOM。
两种常见的触发Metaspace内存溢出原因是:默认JVM参数导致Metaspace区域过小 + CGLIB等动态生成类过多。
因此只要合理分配Metaspace区域的内存大小,避免无限制地动态生成类,一般Metaspace区域都是比较安全的,不会触发OOM内存溢出。
4.无限制调用方法如何让线程的栈内存溢出
(1)一个线程调用多个方法时的入栈和出栈
(2)方法的栈桢也要占用内存
(3)导致JVM栈内存溢出的原因
(4)导致JVM栈内存溢出的场景
JVM加载写好的类到内存之后,下一步就是去通过线程去执行方法,此时就会有方法栈帧的入栈和出栈相关操作,所以接下来分析线程栈内存溢出的原因。
(1)一个线程调用多个方法时的入栈和出栈
如下是一个相对完整的JVM运行原理图:

先看如下代码:
public class HelloWorld {public static void main(String[] args) {String message = "HelloWorld";System.out.println(message);sayHello(message);}public static void sayHello(String name) {System.out.println(name);}}
按前面介绍:JVM启动后,HelloWorld类会被加载到内存,然后会通过main线程执行main()方法。
此时在main线程的虚拟机栈里,就会压入main()方法对应的栈桢,main()方法对应的栈桢里就会放入main()方法中的局部变量。
此外可以手动设置每个线程的虚拟机栈的内存大小,一般默认设置1M。所以,main线程的虚拟机栈内存大小一般也是固定的。
上面代码在main()方法中又继续调用了一个sayHello()方法,而且sayHello()方法中也有自己的局部变量,所以会将sayHello()方法的栈桢压入到main线程的虚拟机栈中去。如下图示:

接着sayHello()方法运行完毕,不需要在内存中为该方法保存其信息了,此时就会将sayHello()方法对应的栈桢从main线程的虚拟机栈里出栈。如下图示:

接着当main()方法运行完毕,会将其栈桢从main线程的虚拟机栈里出栈。
(2)方法的栈桢也会占用内存
每个线程的虚拟机栈的大小是固定的,比如可能就是1M。而一个线程每调用一个方法,就会将该方法的栈桢压入虚拟机栈中。方法的栈桢里就会存放该方法的局部变量,从而也会占用内存。
(3)导致JVM栈内存溢出的原因
既然一个线程的虚拟机栈内存大小是有限的,比如1M。如果不停地让一个线程去调用各种方法,然后不停地把调用的方法所对应的栈桢压入虚拟机栈里,那么就会不断地占用这个线程1M的栈内存。
大量方法的栈桢就会消耗完这个1M的线程栈内存,最终导致出现栈内存溢出的问题,如下图示:

(4)导致JVM栈内存溢出的场景
即便线程的栈内存只有128K或256K,都能进行一定深度的方法调用。但是如果执行的是一个递归方法调用,那就不一定了。如下代码所示:
public static void sayHello(String name) {sayHello(name);}
一旦出现上述递归代码,一个线程就会不停地调用同一个方法。即使是同一个方法,每一次方法调用也会产生一个栈桢压入栈里。比如线程对sayHello()进行100次递归调用,就会有100个栈桢压入中。所以如果运行上述代码,就会不停地将sayHello()方法的栈桢压入栈里。最终一定会消耗掉线程的栈内存,引发栈内存溢出。但发生栈内存溢出,往往都是代码bug导致的,正常情况下很少发生。
(5)总结
栈内存溢出的原因和场景:原因是大量的栈帧会消耗完线程的栈内存 + 场景是方法无限递归调用。
所以只要避免代码出现无限方法递归,一般就能避免栈内存溢出。
5.对象太多导致堆内存实在放不下而内存溢出
(1)对象首先在Eden区分配之后触发YGC
(2)高并发场景下导致YGC后存活对象太多
(3)什么场景会发生堆内存的溢出
前面分析了Metaspace和栈内存两块内存区域发生内存溢出的原因,同时介绍了较为常见的引发它们内存溢出的场景。一般只要注意代码,都不太容易引发Metaspace和栈内存的内存溢出。真正容易引发内存溢出的,其实是堆内存区域。如果系统创建出来的对象实在太多,那么就会导致堆内存溢出。
(1)对象首先在Eden区分配之后触发YGC
首先,系统在运行时会不断创建对象,大量的对象会填满Eden区。一旦Eden区满了之后,就会触发一次YGC,然后存活对象进入S区。如下图示:


(2)高并发场景下导致YGC后存活对象太多
一旦出现高并发场景,可能导致进行YGC时很多请求还没处理完毕。然后YGC后就会存活较多对象,并且在Survivor区放不下。此时这些存活对象只能进入到老年代中,于是老年代也会很快被占满。如下图示:

一旦老年代被占满就会触发FGC,如下图示:

假设YGC过后有一批存活对象,Survivor放不下。此时就等着要进入老年代,然后老年代也满了。那么就得等老年代进行GC来回收一批对象,才能存放YGC后存活的对象。但是不幸的事情发生了,老年代GC过后依然存活下来很多对象。
由于新生代YGC后有一批存活对象还在等着放进老年代,但此时老年代GC后空间依然不足。所以这批新生代YGC后的存活对象没法存放了,只能内存溢出。
这个就是典型的:堆内存实在放不下过多对象而导致内存溢出的原因。当老年代都已经占满了,还要往里面放对象。而且已经触发FGC回收了,老年代还是没有足够内存空间,那只能发出内存溢出的异常。
(3)什么场景会发生堆内存的溢出
发生堆内存溢出的原因:
有限的内存中放了过多对象,而且大多都是存活的,此时即使FGC后还是有大部分对象存活,要继续放入更多对象已经不可能,只能引发内存溢出。
发生内存溢出有几种场景:
场景一:系统承载高并发请求,因为请求量过大导致大量对象都是存活的
此时无法继续往堆内存里放入新的对象了,就会引发OOM系统崩溃。
场景二:系统有内存泄漏,创建了很多对象,结果对象都是存活的没法回收
由于不能及时取消对它们的引用,导致触发FGC后还是无法回收。此时只能引发内存溢出,因为老年代已经放不下更多的对象了。
场景三:代码问题创建的对象占用了大量内存,且该方法一直在长时间运行
这样导致占用大量内存的对象一直不释放。
因此引发堆内存OOM的原因可能是:系统负载过高、存在内存泄漏、创建大量对象长时间运行,不过OOM一般是由代码写得差或设计缺陷引发的。
(4)总结
一.发生堆内存OOM的根本原因
对象太多且都是存活的,即使FGC过后还是没有空间,此时放不下新对象,只能OOM。
二.发生堆内存OOM的常见场景
系统负载过高 + 内存泄露 + 代码问题创建大量对象长时间运行。
6.模拟JVM Metaspace内存溢出的场景(动态生成268个类占10M)
(1)Metaspace内存溢出原理
(2)一段CGLIB动态生成类的代码示例
(3)限制Metaspace大小看看内存溢出效果
(1)Metaspace内存溢出原理
Metaspace区域发生内存溢出的一个场景就是:不停地动态生成类,导致程序不停加载类到Metaspace区域里,而且这些动态生成的类还不能被回收掉。
这样一旦Metaspace区域满了,就会触发FGC回收Metaspace中的类,但此时的类大多不能被回收。
因此即使触发过FGC后,Metaspace区域还是不能放下任何一个类,此时就会导致Metaspace区域的内存溢出,导致JVM也崩溃掉。
(2)一段CGLIB动态生成类的代码示例
如果要用CGLIB来动态生成一些类,可以在pom.xml中引入以下依赖:
<dependency><groupId>cglib</groupId><artifactId>cglib</artifactId><version>3.3.0</version></dependency>
接着使用CGLIB来动态生成类,代码如下:
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;public class CglibDemo {public static void main(String[] args) {while (true) {Enhancer enhancer = new Enhancer();enhancer.setSuperclass(Car.class);enhancer.setUseCache(false);enhancer.setCallback(new MethodInterceptor() {@Overridepublic Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {if (method.getName().equals("run")) {System.out.println("Check before run");return methodProxy.invokeSuper(o, objects);} else {return methodProxy.invokeSuper(o, objects);}}});Car car = (Car) enhancer.create();car.run();}}static class Car {public void run() {System.out.println("Run...");}}
}main()方法会通过CGLIB的Enhancer类生成一个Car类的子类,首先main()方法后会定义一个Car类,它有一个run()方法。
static class Car {public void run() {System.out.println("Run...");}}
接着在下面的代码片段中,会设置动态生成类:
Enhancer enhancer = new Enhancer();enhancer.setSuperclass(Car.class);enhancer.setUseCache(false);
其中Enhancer类就是用来动态生成类的,给enhancer设置SuperClass,表示动态生成的类是Car类的子类。既然动态生成的类是Car的子类,那么该类也有Car的run()方法,于是通过如下代码对动态生成的类的run()方法进行改动。
enhancer.setCallback(new MethodInterceptor() {@Overridepublic Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {if (method.getName().equals("run")) {System.out.println("Check before run");return methodProxy.invokeSuper(o, objects);} else {return methodProxy.invokeSuper(o, objects);}}
});这个片段的意思是:如果调用子类对象的方法,会先被这里的MethodInterceptor拦截。拦截之后就会判断,如果调用的是run方法,那么就增加打印。之后通过methodProxy.invokeSuper(o, objects)调用父类Car.run()方法。
这样就通过CGLIB的Enhancer类动态生成了一个Car类的子类了,且定义好调用这个子类所继承父类的run()方法时的额外逻辑,这就是动态创建类。
(3)限制Metaspace大小看看内存溢出效果
首先设置一下这个程序的JVM参数,限制Metaspace区域小一点。如下所示,把这个程序的JVM中的Metaspace区域设置为仅仅10M:
-XX:MetaspaceSize=10m -XX:MaxMetaspaceSize=10m然后在上述代码中加入一个计数器,看看当前创建了多少个子类,如下所示:
long counter = 0;while (true) {System.out.println("正在动态创建第" + (++counter) + "个子类");...}
接着用上述JVM参数来运行程序,可以看到如下所示的打印输出:
正在动态创建第268个子类
Exception in thread "main" java.lang.OutOfMemoryError: Metaspaceat java.lang.Class.forName0(Native Method)at java.lang.Class.forName(Class.java:348)at net.sf.cglib.core.ReflectUtils.defineClass(ReflectUtils.java:467)at net.sf.cglib.core.AbstractClassGenerator.generate(AbstractClassGenerator.java:339)at net.sf.cglib.proxy.Enhancer.generate(Enhancer.java:492)at net.sf.cglib.core.AbstractClassGenerator$ClassLoaderData.get(AbstractClassGenerator.java:117)at net.sf.cglib.core.AbstractClassGenerator.create(AbstractClassGenerator.java:294)at net.sf.cglib.proxy.Enhancer.createHelper(Enhancer.java:480)at net.sf.cglib.proxy.Enhancer.create(Enhancer.java:305)at com.demo.rpc.test.CglibDemo.main(CglibDemo.java:29)目前创建了268个Car类的子类了,在创建了268个类时,10M的Metaspace区域就被耗尽了,接着就会看到如下异常:
java.lang.OutOfMemoryError: Metaspace这个OutOfMemoryError: Metaspace就是经典的元数据区内存溢出,而且明确显示是Metaspace这块区域发生内存溢出了。一旦内存溢出,正常运行的JVM进程直接会崩溃掉,程序就会退出。
7.模拟JVM栈内存溢出的场景(线程调用6000次方法占1M栈内存)
(1)JVM中的栈内存会占多大
(2)栈内存溢出的原理
(3)栈内存溢出的代码示例
(1)JVM中的栈内存会占多大
一个问题:JVM进程到底会占用机器多少内存?先不考虑其他内存区域,仅仅考虑核心区域:Metaspace区域、堆内存区域、各个线程的栈内存区域。
一.Metaspace区域一般会分配512M
只要代码里不胡乱生成类,一般都能存放一个系统运行时需要的类(1.3万个)。
二.堆内存区域一般会分配机器内存的一半大小
毕竟还要考虑机器的其他进程对内存的使用。
三.栈内存区域
考虑一个最基本的4核8G的线上机器配置:其中给Metaspace有512M、给堆内存4G,操作系统自己也用一些内存。那么可以认为有剩余一两G的内存是能留给栈内存的。
通常会设置每个线程的栈内存就是1M,假设一个JVM进程内一共有1000个线程,这些线程包括:JVM的后台线程 + 系统依赖的第三方组件的后台线程 + 系统核心工作线。如果每个线程的栈内存需要1M,那1000个线程就需要1G的栈内存空间。所以基本上这套内存模型是比较合理的。
其实一般来说,4核8G机器上运行的JVM进程,Tomcat内部所有线程加起来大概几百个线程,也就占据几百M内存。如果线程太多,4核CPU负载也会过高,也不好。
所以JVM对机器内存的总消耗就是:Metaspace区域内存 + 堆内存 + 几百个线程的栈内存。
如果给每个线程的栈内存分配过大空间,那么能创建的线程数就会变少。如果给每个线程的栈内存分配过小空间,那么能创建的线程数就会较多。当然一般建议给栈内存分配1M的大小就可以了。
(2)栈内存溢出的原理
其实每个线程的栈内存是固定的,如果一个线程无限制地调用方法,每次方法调用都会有一个栈桢入栈,此时就会导致线程的栈内存被消耗殆尽。
通常而言我们的线程不会连续调用几千次甚至几万次方法。一般发生这种情况,只有一个原因,就是代码有bug,出现了死循环调用或者是无限制的递归调用。最后连续调用几万次方法后,没法放入更多方法栈桢,栈内存就溢出了。
(3)栈内存溢出的代码示例
public class Demo {public static long counter = 0;public static void main(String[] args) {work();}public static void work() {System.out.println("第" + (++counter) + "次调用");work();}}
上面的代码非常简单:就是work()方法调用自己,进入一个无限制的递归调用,陷入死循环。在main线程的栈中,会不停压入work()方法的栈桢,直到耗尽1M内存。然后需要设置这个程序的JVM的栈内存为1M。
-XX:ThreadStackSize=1m接着运行这段代码,会看到如下打印输出:
第5791次调用java.lang.StackOverflowError当这个线程调用5790次方法后,线程的虚拟机栈里会压入5790个栈桢。最终这5790个栈桢把1M的栈内存给塞满了,引发栈内存溢出,StackOverflowError就是线程栈内存溢出。
(4)总结
可以看到1M的栈内存可让线程连续调用5000次以上的方法。其实这个数量已经很多了,除了递归,线程一般不会调用几千个方法。所以这种栈内存溢出是极少出现的,一般出现也都是代码中的bug导致。
8.模拟JVM堆内存溢出的场景(36万个Object对象才占10M堆内存)
(1)堆内存溢出的原因
(2)堆内存溢出的代码示例
Metaspace区域和栈内存的溢出,一般都是极个别情况下才会发生。堆内存溢出才是非常普遍的现象。一旦系统负载过高,比如并发量过大、数据量过大、出现内存泄漏等,就很容易导致JVM内存不够用,从而导致堆内存溢出,然后系统崩溃。所以接下来就模拟一下堆内存溢出的场景。
(1)堆内存溢出的原因
假设现在系统负载很高,不停地创建对象放入内存。一开始会将对象放入到新生代的Eden区,但因系统负载太高,很快Eden区就被占满,于是触发YGC。
但YGC时发现,由于高负载,Eden区里的对象大多都是存活的,而S区也放不下这些存活的对象,这时只能把存活对象放入老年代中。
由于每次YGC都有大批对象进入老年代,几次YGC后老年代就会被占满。在接下来的一次YGC后又有一大批对象要进入老年代时,就会触发FGC。
但是这次FGC之后,老年代里还是占满了由于高负载而依然存活的对象。这时YGC的存活对象在FGC后还是无法放入老年代,于是就堆内存溢出。
(3)用示例代码来演示堆内存溢出的场景
如下代码所示:
public class Demo {public static void main(String[] args) {long counter = 0;List<Object> list = new ArrayList<Object>();while(true) {list.add(new Object());System.out.println("当前创建了第" + (++counter) + "个对象");}}}
代码很简单,就是在一个while循环里不停地创建对象,而且对象全部都是放在List里面被引用的,也就是不能被回收。不停地创建对象,Eden区满了,这些对象全部存活便全部转移到老年代。反复几次后老年代满了,然后Eden区再次满的时候触发YGC。此时YGC后存活对象再次进入老年代,老年代会先FGC。但这次FGC回收不了任何对象,因此YGC后的存活对象无法进入老年代。
所以接下来用下面的JVM参数来运行一下代码:限制堆内存大小总共就只有10m,这样可以尽快触发堆内存的溢出。
-Xms10m -Xmx10m在控制台打印的信息中可以看到如下的信息:
当前创建了第360145个对象Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
所以从这里就可以看到:在10M的堆内存中,用最简单的Object对象占满老年代需要36万个对象。然后当堆内存实在放不下任何其他对象时,就会OutOfMemory。而且会明确显示是Java heap space,也就是堆空间发生了内存溢出。
9.一个超大数据量处理系统的OOM(数据缓存本地 + 重试发送直到Kafka恢复)
(1)超大数据量处理系统的案例
(2)针对Kafka故障设计的高可用场景
(3)无法释放的内存最终导致OOM
(4)如何处理这个问题
(1)超大数据量处理系统的案例
前面提过一个大数据量的计算引擎系统,用该系统案例分析过GC问题。因为它处理的数据量实在是太大,负载也过高。所以该系统除了GC问题外,其实还有OOM问题。
该系统的工作流程就是,不停地从数据存储中加载大量的数据到内存里来进行复杂的计算。如下图示:

这个系统会不停地加载数据到内存里来计算,每次少则加载几十万条数据,多则加载上百万条数据,所以系统的内存负载压力是非常大的。
这个系统每次加载数据到内存里计算完毕后,就需要将计算好的数据推送给另一个系统。两个系统间的数据推送和交互,最适合基于消息中间件来实现。因此选择将数据先推送到Kafka,另一个系统再从Kafka里取数据。这就是这个系统完整的运行流程:加载数据 -> 计算数据 -> 推送数据,如下图示:

(2)针对Kafka故障设计的高可用场景
数据计算系统要推送计算结果到Kafka去,万一Kafka挂了怎么办?此时就必须设计一个针对Kafka故障的高可用机制。
刚开始负责这块的工程师选择了一个思考欠佳的技术方案:一旦发现Kafka故障,就将数据都留存在内存里。然后从内存取出数据不停地进行重试,直到Kafka恢复。如下图示:

这时就有一个隐患了,万一真的遇上Kafka故障。那么一次计算对应的数据就驻留内存无法释放,一直重试等Kafka恢复。然后数据计算系统还在不停地加载数据到内存里来处理,每次计算完的数据还无法推送到Kafka,又全部驻留在在内存里等待着。如此循环往复,必然导致内存里的数据越来越多,这绝对是一个不合理的方案。
(3)无法释放的内存最终导致OOM
使用上面这个不合理的方案时,刚好发生了Kafka的短暂临时故障。此时系统无法将计算后的数据推送给Kafka,便全部驻留在内存里等待。与此同时,数据计算系统还在不停加载数据到内存里计算,这必然会导致内存里的数据越来越多。
每次Eden区占满后,大量存活的对象必须转入老年代,而且老年代里的这些对象还无法释放,最终老年代一定会被占满。从而在某一次Eden区满了之后,一大批对象又要转移到老年代时,此时老年代即使FGC后还是没有空间能放得下存活对象,于是OOM。最后这个系统全线崩溃,无法正常运行。
(4)如何处理这个问题
其实很简单,当时就临时直接取消了Kafka故障下的重试机制。一旦Kafka故障,直接丢弃掉本地计算结果,释放大量数据占用的内存。
后续的改进:一旦Kafka故障,则将计算结果写本地磁盘,允许内存中的数据被回收。这就是一个真实的线上系统设计不合理导致的内存溢出问题。
10.两个新手误写代码如何导致OOM(方法循环调用自己 + 动态代理没缓存)
(1)案例一:写出了一个无限循环调用
(2)案例二:没有缓存的动态代理
(3)总结
(1)案例一:写出了一个无限循环调用
这是由一位实习生写出一个bug,导致线上系统出现栈内存溢出的场景。当时有一个非常重要的系统,我们设计了一个链路监控机制。也就是会在一个比较核心的链路节点,写一些重要日志到ES集群里去,事后会基于ELK进行核心链路日志的一些分析。
同时对这个机制做了规定:如果在某节点写日志时发生异常,此时也需要将该异常写入ES集群里。因为后续在分析时,需要知道系统运行到这里有一个异常。因此当时那位实习生写出来的伪代码大致如下:
try {//业务逻辑...log();
} catch (Exception e) {log();
}public void log() {try {//将日志写入ES集群...} catch (Ezception e) {log();}
}上述代码中:log()方法出现异常(ES集群出现故障),会在catch中再次调用log()方法。
有一次ES短暂故障了,结果导致log()方法写日志到ES时抛异常。一旦log()方法抛异常进入catch语句块时,又会再次重新调用log()方法。然后log()方法再次写ES抛异常,继续进入catch块,于是出现循环调用。
在ES集群故障时,线上系统本来不应该有什么问题的。因为核心业务逻辑都是可以运行,最多就是无法把日志写入ES集群而已。
但是因为这个循环调用的bug,导致在ES故障时:所有系统全部写日志都会陷入一个无限循环调用log()方法的困境中,而一旦方法在无限循环调用它自己,一定会导致线程的栈内存溢出,从而导致JVM崩溃。
改进措施:系统居然因为这么一个小问题崩溃了,这就是一次非真实的线上案例。后续通过严格的持续集成 + 严格的Code Review标准来避免此类问题,每个人每天都会写一点代码,这个代码必须配套单元测试可以运行的。然后代码会被提交到持续集成服务器上,并被集成到整体代码里。在持续集成服务器上,整体代码会自动运行单元测试 + 集成测试。
在单元测试+集成测试中:都会要求针对一些try catch中可能走到catch的分支写一些测试的。一旦有这类代码,只要提交到持续集成系统上,就会自动运行测试触发。此外每次提交的代码也必须交给指定的其他同事进行Code Review。别人需要仔细审查提交的每一行代码,一旦发现问题就重新修改代码。从此之后,这种低端的问题再也没有发生过。
(2)案例二:没有缓存的动态代理
这个案例同样是之前的一个新手工程师写的。因为经验不足,有一次在实现一块代码机制时,犯了一个很大的错误。
简单来说,当时他想实现一个动态代理机制:即在系统运行时,针对已有的某个类生成一个动态代理类(动态生成类),然后对那个类的一些方法调用做些额外的处理。
大概的伪代码与下面的代码是类似的:
while (true) {Enhancer enhancer = new Enhancer();enhancer.setSuperclass(Car.class);enhancer.setUseCache(false);enhancer.setCallback(new MethodInterceptor() {@Overridepublic Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {if (method.getName().equals("run")) {System.out.println("Check before run");return methodProxy.invokeSuper(o, objects);} else {return methodProxy.invokeSuper(o, objects);}}});Car car = (Car) enhancer.create();car.run();
}类似这种代码有个问题:当使用CGLIB的Enhancer针对某个类动态生成一个子类后,这个动态生成类(Enhancer对象)完全可以缓存起来。这样下次直接用这个已经生成好的子类来创建对象即可,如下所示:
private volatile Enhancer enhancer = null;
public void doSomething() {if (enhancer == null) {this.enhancer = new Enhancer();enhancer.setSuperclass(Car.class);enhancer.setUseCache(false);enhancer.setCallback(new MethodInterceptor() {@Overridepublic Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {if (method.getName().equals("run")) {System.out.println("Check before run");return methodProxy.invokeSuper(o, objects);} else {return methodProxy.invokeSuper(o, objects);}}});Car car = (Car) enhancer.create();car.run();}
}其实这个动态生成类(Enhancer对象)只要生成一次就可以了,下次可以直接用这个动态生成类(Enhancer对象)创建一个对象。但是当时没有缓存这个动态生成类,每次调用方法都生成一个类。
有一次线上系统负载很高,于是这个框架瞬间创建了一大堆类,塞满Metaspace并无法回收。进而导致Metaspace区域直接内存溢出,系统也崩溃了。
后来对于这类问题的改进措施是:严格要求每次上线必须走自动化压力测试。在高并发压力下系统是否正常运行支撑24小时,以此判断是否可以上线。
这样类似于这类代码在上线之前就会被压力测试露出马脚,因为压力一大瞬间会引发这个问题。
(3)总结
上线前必须做代码Review + 自动化压力测试。
相关文章:
JVM实战—11.OOM的原因和模拟以及案例
大纲 1.线上系统突然由于OOM内存溢出挂掉 2.什么是内存溢出及哪些区域会发生内存溢出 3.Metaspace如何因类太多而发生内存溢出 4.无限制调用方法如何让线程的栈内存溢出 5.对象太多导致堆内存实在放不下而内存溢出 6.模拟JVM Metaspace内存溢出的场景(动态生成268个类占1…...

LLM - 使用 LLaMA-Factory 部署大模型 HTTP 多模态服务 教程 (4)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/144881432 大模型的 HTTP 服务,通过网络接口,提供 AI 模型功能的服务,允许通过发送 HTTP 请求,交互大模型,通常基于云计算架构,无需在本地部署复杂的模型和硬件,…...
)
Clickhouse集群部署(3分片1副本)
Clickhouse集群部署 3台Linux服务器,搭建Clickhouse集群3分片1副本模式 1、安装Java、Clickhouse、Zookeeper dpkg -i clickhouse-client_23.2.6.34_amd64.deb dpkg -i clickhouse-common-static_23.2.6.34_amd64.deb dpkg -i clickhouse-server_23.2.6.34_amd64…...

刷服务器固件
猫眼淘票票 大麦 一 H3C通用IP 注:算力服务器不需要存储 二 刷服务器固件 1 登录固定IP地址 2 升级BMC版本 注 虽然IP不一致但是步骤是一致的 3 此时服务器会出现断网现象,若不断网等上三分钟ping一下 4 重新登录 5 断电拔电源线重新登录查看是否登录成功...

数据结构C语言描述9(图文结合)--二叉树和特殊书的概念,二叉树“最傻瓜式创建”与前中后序的“递归”与“非递归遍历”
前言 这个专栏将会用纯C实现常用的数据结构和简单的算法;有C基础即可跟着学习,代码均可运行;准备考研的也可跟着写,个人感觉,如果时间充裕,手写一遍比看书、刷题管用很多,这也是本人采用纯C语言…...

CSS——2.书写格式一
<!DOCTYPE html> <html><head><meta charset"UTF-8"><title></title></head><body><!--css书写中:--><!--1.css 由属性名:属性值构成--><!--style"color: red;font-size: 20px;&quo…...

Elasticsearch 创建索引 Mapping映射属性 索引库操作 增删改查
Mapping Type映射属性 mapping是对索引库中文档的约束,有以下类型。 text:用于分析和全文搜索,通常适用于长文本字段。keyword:用于精确匹配,不会进行分析,适用于标签、ID 等精确匹配场景。integer、long…...

【NLP高频面题 - 分布式训练篇】ZeRO主要为了解决什么问题?
【NLP高频面题 - 分布式训练篇】ZeRO主要为了解决什么问题? 重要性:★★ 零冗余优化器技术由 DeepSpeed 代码库提出,主要用于解决数据并行中的模型冗余问题,即每张 GPU 均需要复制一份模型参数。 ZeRO的全称是Zero Redundancy …...

kubernetes-循序渐进了解coredns
文章目录 概要基础知识Kubernetes 集群中对对象名称的 DNS 流量解析 Kubernetes 集群外的名称的 DNS 流量CoreDNS 如何确定向哪个本地 DNS 请求解析?修改 CoreDNS 的配置 概要 CoreDNS 是 Kubernetes 的核心组件之一。只有在 Kubernetes 集群中安装了 容器网络接口…...

mysql8 从C++源码角度看 客户端发送的sql信息 mysql服务端从网络读取到buff缓存中
MySQL 8 版本中的客户端-服务器通信相关,特别是在接收和解析网络请求的数据包时。以下是对代码各个部分的详细解释,帮助您更好地理解这些代码的作用。 代码概述 这段代码主要负责从网络读取数据包,它包含了多个函数来处理网络数据的读取、缓…...

pygame飞机大战
飞机大战 1.main类2.配置类3.游戏主类4.游戏资源类5.资源下载6.游戏效果 1.main类 启动游戏。 from MainWindow import MainWindow if __name__ __main__:appMainWindow()app.run()2.配置类 该类主要存放游戏的各种设置参数。 #窗口尺寸 #窗口尺寸 import random import p…...

【Vim Masterclass 笔记08】第 6 章:Vim 中的文本变换及替换操作 + S06L20:文本的插入、变更、替换,以及合并操作
文章目录 Section 6:Transforming and Substituting TextS06L21 Inserting, Changing, Replacing, and Joining1 定位到行首非空字符,并启用插入模式2 在紧挨光标的下一个字符位置启动插入模式3 定位到一行末尾,并启用插入模式4 定位到光标的…...

Tailwind CSS 实战:动画效果设计与实现
在现代网页设计中,动画效果就像是一位优秀的舞者,通过流畅的动作为用户带来愉悦的视觉体验。记得在一个产品展示网站项目中,我们通过添加精心设计的动画效果,让用户的平均停留时间提升了 35%。今天,我想和大家分享如何使用 Tailwind CSS 打造优雅的动画效果。 设计理念 设计动…...

【动手学电机驱动】STM32-MBD(3)Simulink 状态机模型的部署
STM32-MBD(1)安装 Simulink STM32 硬件支持包 STM32-MBD(2)Simulink 模型部署入门 STM32-MBD(3)Simulink 状态机模型的部署 【动手学电机驱动】STM32-MBD(3)Simulink 状态机模型部署…...

Linux 服务器启用 DNS 加密
DNS 加密的常用协议包括 DNS over HTTPS (DoH)、DNS over TLS (DoT) 和 DNSCrypt。以下是实现这些加密的步骤和工具建议: 1. 使用 DoH (DNS over HTTPS) 工具推荐: cloudflared(Cloudflare 提供的客户端)doh-client(…...

PyTorch不同优化器比较
常见优化器介绍 - SGD(随机梯度下降):是最基本的优化器之一,通过在每次迭代中沿着损失函数的负梯度方向更新模型参数。在大规模数据集上计算效率高,对于凸问题和简单模型效果较好。但收敛速度慢,容易陷入局…...

stm32的掉电检测机制——PVD
有时在一些应用中,我们需要检测系统是否掉电了,或者要在掉电的瞬间需要做一些处理。 STM32内部自带PVD功能,用于对MCU供电电压VDD进行监控。 STM32就有这样的掉电检测机制——PVD(Programmable Voltage Detecter),即可编程电压检…...
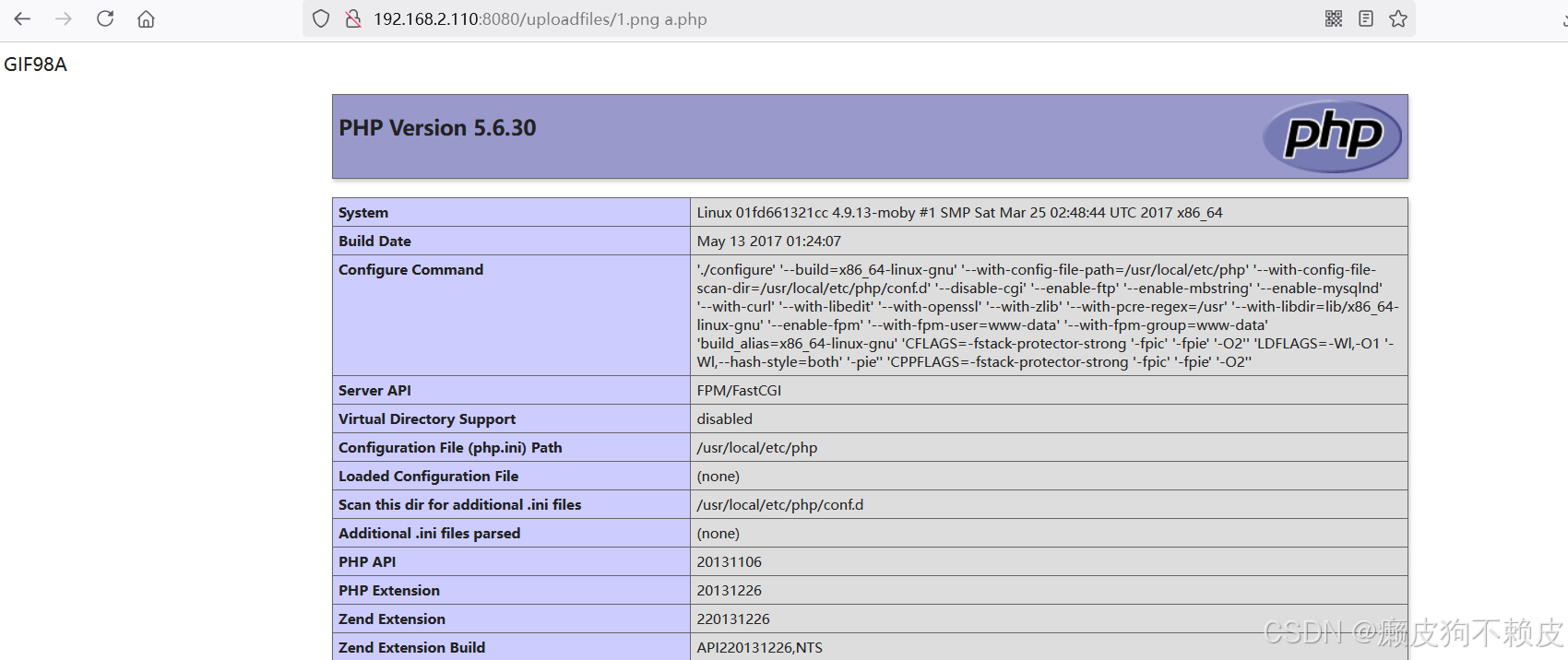
Nginx 文件名逻辑漏洞(CVE-2013-4547)
目录 漏洞原理 影响版本 漏洞复现 漏洞原理 CGI:是一种协议,定义了web服务器传递的数据格式。 FastCGI:优化版的CGI程序 PHP-CGI:PHP解释器,能够对PHP文件进行解析并返回相应的解析结果 PHP-FPM:Fas…...

Java 21 优雅和安全地处理 null
在 Java 21 中,判断 null 依然是开发中常见的需求。通过使用现代 Java 提供的工具和特性,可以更加优雅和安全地处理 null。 1. 使用 Objects.requireNonNull Objects.requireNonNull 是标准的工具方法,用于快速判断并抛出异常。 示例 import java.util.Objects;public c…...

AWS Glue基础知识
AWS Glue 是一项完全托管的 ETL(提取、转换、加载)服务,与考试相关,尤其是在数据集成、处理和分析方面。 1.数据集成和 ETL(提取、转换、加载) AWS Glue 主要用于构建 ETL 管道以准备数据以进行分析。作为…...

OpCore-Simplify:黑苹果配置终极简化指南,告别繁琐手动调试
OpCore-Simplify:黑苹果配置终极简化指南,告别繁琐手动调试 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为黑苹果配置的…...

别再死记硬背代码了!从‘简单计算器’题深入理解C++分支结构的本质与应用场景
从计算器案例看C分支结构:如何写出更优雅的条件判断 记得第一次参加信息学奥赛训练时,我对着OpenJudge平台上那道"简单计算器"题目发呆了半小时。不是不会写,而是在纠结到底该用switch还是if-else。这可能是每个C初学者都会遇到的…...

从AT89C51到STC89C52:一个老电子工程师的51单片机“进化史”与避坑心得
从AT89C51到STC89C52:一个老电子工程师的51单片机“进化史”与避坑心得 记得2003年第一次接触51单片机时,实验室里那台笨重的高压编程器发出的"滴滴"声至今难忘。二十年过去,我的工具箱从AT89C51编程器变成了USB转串口线࿰…...

告别物理光驱:WinCDEmu虚拟光驱工具完整使用指南
告别物理光驱:WinCDEmu虚拟光驱工具完整使用指南 【免费下载链接】WinCDEmu 项目地址: https://gitcode.com/gh_mirrors/wi/WinCDEmu 还在为找不到光驱而烦恼?还在为ISO文件无法直接使用而困扰?今天我要向你介绍一款Windows平台上的终…...

终极宽屏体验:如何让《植物大战僵尸》在现代显示器上完美重生 [特殊字符]
终极宽屏体验:如何让《植物大战僵尸》在现代显示器上完美重生 🎮 【免费下载链接】PvZWidescreen Widescreen mod for Plants vs Zombies 项目地址: https://gitcode.com/gh_mirrors/pv/PvZWidescreen PvZWidescreen 是一款专门为经典游戏《植物大…...

设计拆迁补偿专项资金流水监管编程工具,定向登记专款收支,异动挪用账目,自动标红预警留痕。
一、实际应用场景描述场景设定:某地方政府或城投公司设立 “拆迁补偿专项资金账户”,用于:- 房屋拆迁补偿- 安置房建设- 搬迁过渡费发放- 附属物及青苗补偿监管要求:- 专款专用(不能挪作基建、发工资等)- 每…...

Photoshop-Export-Layers-to-Files-Fast:告别繁琐图层导出的终极解决方案 [特殊字符]
Photoshop-Export-Layers-to-Files-Fast:告别繁琐图层导出的终极解决方案 🚀 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in sc…...

暗黑破坏神2存档编辑器:5分钟掌握D2/D2R角色修改技巧
暗黑破坏神2存档编辑器:5分钟掌握D2/D2R角色修改技巧 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor d2s-editor是一款功能强大的暗黑破坏神2存档修改工具,专为D2和D2R玩家设计。这款基于Web的开源编辑器…...
)
iOS App审核被拒?手把手教你搞定MFI配件PPID配置(以Honeywell Captuvo为例)
iOS App审核被拒?手把手教你搞定MFI配件PPID配置(以Honeywell Captuvo为例) 当你兴冲冲地将集成了Honeywell Captuvo SDK的iOS应用提交到App Store审核,却收到苹果冰冷的拒绝邮件时,那种挫败感我深有体会。作为经历过三…...

5分钟搞定Windows和Office永久激活:KMS智能激活工具完整教程
5分钟搞定Windows和Office永久激活:KMS智能激活工具完整教程 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否厌倦了Windows系统不断弹出的激活提醒?是否因为Office…...