第 31 章 - 源码篇 - Elasticsearch 写入流程深入分析
写入源码分析
接收与处理
请求首先会被 Netty4HttpServerTransport 接收,接着交由 RestController 进行路由分发。
private void tryAllHandlers(final RestRequest request, final RestChannel channel, final ThreadContext threadContext) throws Exception {// 从 tier 树中,找到该请求路径对应的 RestHandlerIterator<MethodHandlers> allHandlers = getAllHandlers(request.params(), rawPath);while (allHandlers.hasNext()) {final RestHandler handler;final MethodHandlers handlers = allHandlers.next();if (handlers == null) {handler = null;} else {handler = handlers.getHandler(requestMethod, restApiVersion);}if (handler == null) {if (handleNoHandlerFound(rawPath, requestMethod, uri, channel)) {return;}} else {// 找到后,将本次请求转发给该 RestHandlerdispatchRequest(request, channel, handler, threadContext);return;}}
}
那么 ES 如何知道对应的路由应该由谁处理呢?
在 Node 初始化时,会执行 ActionModule#initRestHandlers(...)
public void initRestHandlers(Supplier<DiscoveryNodes> nodesInCluster) {......// 注册路由registerHandler.accept(new RestIndexAction());......
}
RestIndexAction 注册的路由如下所示
public List<Route> routes() {return List.of(new Route(POST, "/{index}/_doc/{id}"),new Route(PUT, "/{index}/_doc/{id}"),Route.builder(POST, "/{index}/{type}/{id}").deprecated(TYPES_DEPRECATION_MESSAGE, RestApiVersion.V_7).build(),Route.builder(PUT, "/{index}/{type}/{id}").deprecated(TYPES_DEPRECATION_MESSAGE, RestApiVersion.V_7).build());
}
每个 RestHandler 在 prepareRequest(final RestRequest request, final NodeClient client) 都会声明与之绑定的 TransportAction,之后所有逻辑会交由 TransportAction 处理。
其绑定的 TransportAction 为 TransportIndexAction。
RestIndexAction#prepareRequest(...)
public RestChannelConsumer prepareRequest(final RestRequest request, final NodeClient client) throws IOException {......return channel -> client.index(indexRequest,new RestStatusToXContentListener<>(channel, r -> r.getLocation(indexRequest.routing())));
}
AbstractClient#index(final IndexRequest request, final ActionListener<IndexResponse> listener)
@Override
public void index(final IndexRequest request, final ActionListener<IndexResponse> listener) {execute(IndexAction.INSTANCE, request, listener);
}
对于写入类型的 TransportAction 在内部又会通过协调节点(接收客户端请求的就是协调节点)先将请求转发给对应主分片所在的节点,主分片节点写入后,主分片节点又会转发给副本分片,副本分片写入后,返回给主分片,主分片再返回给协调节点,最后协调节点返回给客户端。
整体流程如下图所示:
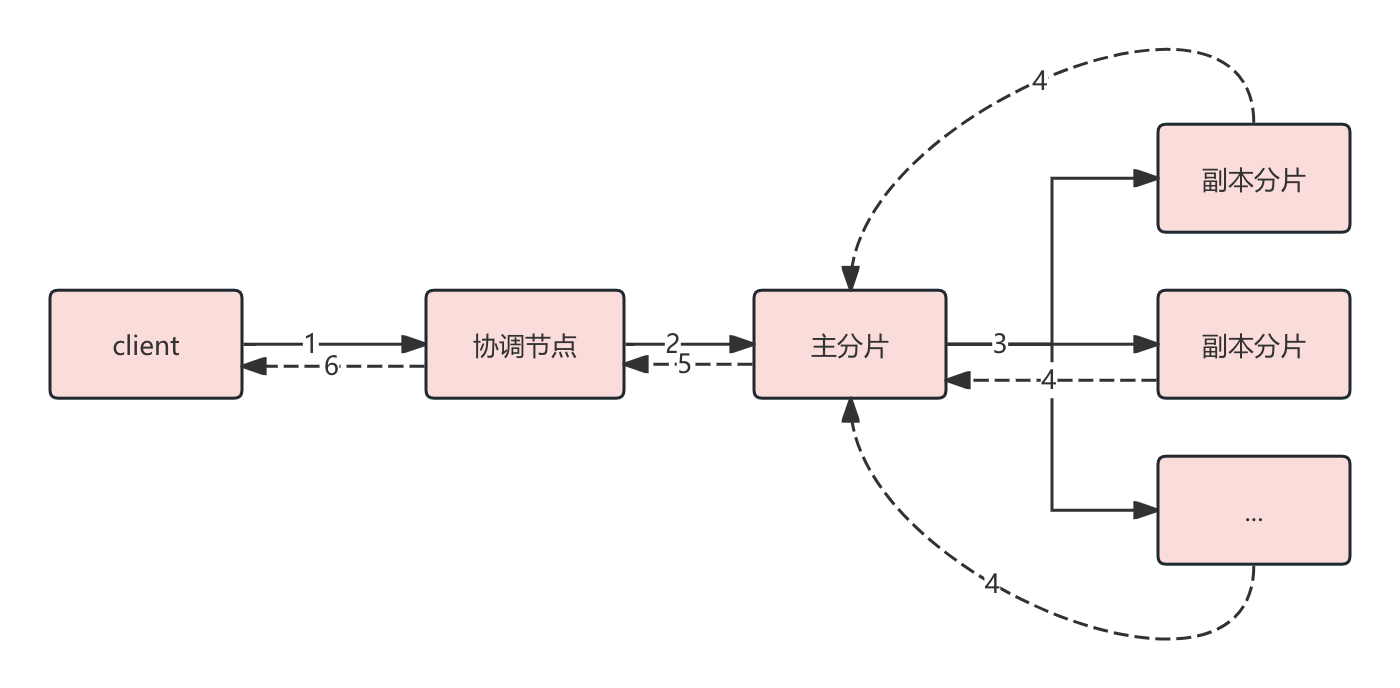
协调节点分发请求
上文 search 读流程有提到,TansportAction 定义了基本流程,每个子类实现 doExecute(...) 方法,自定义执行逻辑,因此我们只需要看 TransportIndexAction#doExecute(...) 即可。
不存在索引则创建
当索引不存在时,则会先创建索引,接着再执行写入操作。如果索引存在,则直接执行写入操作。
TransportBulkAction#doInternalExecute(...)
protected void doInternalExecute(Task task, BulkRequest bulkRequest, String executorName, ActionListener<BulkResponse> listener) {for (String index : autoCreateIndices) {// 创建索引createIndex(index, bulkRequest.timeout(), minNodeVersion, new ActionListener<>() {@Overridepublic void onResponse(CreateIndexResponse result) {// 创建索引成功回调函数,if (counter.decrementAndGet() == 0) {// 执行写入操作threadPool.executor(executorName).execute(new ActionRunnable<>(listener) {@Overrideprotected void doRun() {executeBulk(task,bulkRequest,startTime,listener,executorName,responses,indicesThatCannotBeCreated);}});}}}}
}
executeBulk(..) 方法内部会创建 BulkOperation 交由该类做处理
void executeBulk(Task task,BulkRequest bulkRequest,long startTimeNanos,ActionListener<BulkResponse> listener,String executorName,AtomicArray<BulkItemResponse> responses,Map<String, IndexNotFoundException> indicesThatCannotBeCreated) {new BulkOperation(task, bulkRequest, listener, executorName, responses, startTimeNanos, indicesThatCannotBeCreated).run();}
BulkOperation 继承自 AbstractRunnable。AbstractRunnable 定义了执行的基本流程,子类需要实现 doRun() 方法,因此,只需要关注 BulkOperation#doRun() 方法。
路由计算
BulkOperation#doRun()
protected void doRun() {// 获取路由计算规则IndexRouting indexRouting = concreteIndices.routing(concreteIndex);
}
IndexRouting#fromIndexMetadata(...)
public static IndexRouting fromIndexMetadata(IndexMetadata indexMetadata) {// 索引配置上是否设置 routing_pathif (false == indexMetadata.getRoutingPaths().isEmpty()) {if (indexMetadata.isRoutingPartitionedIndex()) {throw new IllegalArgumentException("routing_partition_size is incompatible with routing_path");}return new ExtractFromSource(indexMetadata.getRoutingNumShards(),indexMetadata.getRoutingFactor(),indexMetadata.getIndex().getName(),indexMetadata.getRoutingPaths());}// 索引配置上是否设置了分区索引相关参数if (indexMetadata.isRoutingPartitionedIndex()) {return new Partitioned(indexMetadata.getRoutingNumShards(),indexMetadata.getRoutingFactor(),indexMetadata.getRoutingPartitionSize());}// 正常写入return new Unpartitioned(indexMetadata.getRoutingNumShards(), indexMetadata.getRoutingFactor());
}
上诉 3 个路由算法,底层算法都是类似的,都是基于一致性 hash 计算对应的路由。
hash 计算函数 Murmur3HashFunction#hash(String routing)
我们可以简单将路由算法理解为如下:
- 先计算 hash
- 再根据 hash 计算路由
计算 hash 可以又分为以下几种情况:
- 如果索引配置了 routing_path,则 hash = Murmur3HashFunction#hash(routing_path_value)
- 如果路径上有路由参数,则 hash = Murmur3HashFunction#hash(routing)
- 否则 hash = Murmur3HashFunction#hash(_id)
根据 hash 计算路由的规则如下:
IndexRouting#hashToShardId(...)
protected final int hashToShardId(int hash) {return Math.floorMod(hash, routingNumShards) / routingFactor;
}
- routingNumShards
值默认依赖主分片数(number_of_shards),如果创建索引时未指定,默认按因子2拆分,并且最多可拆分为1024个分片。例如原索引主分片数为1,则可拆分为1~1024中的任意数;原索引主分片为5,则支持拆分的分片数为:10、20、40、80、160、320以及最大数640(不能超过1024)。 可通过索引的index.number_of_routing_shards配置,但不建议配置。 - routingFactor
默认为routingNumShards/number_of_shards
简单说,你可以将 number_of_routing_shards 理解为虚拟的分片数、 number_of_shards 则为物理的分片数。其本质就是 一致性 hash。
分发请求至主分片
TransportReplicationAction#doExecute(...)
@Override
protected void doExecute(Task task, Request request, ActionListener<Response> listener) {assert request.shardId() != null : "request shardId must be set";runReroutePhase(task, request, listener, true);
}
ReroutePhase#doRun()
protected void doRun() {if (primary.currentNodeId().equals(state.nodes().getLocalNodeId())) { // 主分片节点在协调节点上performLocalAction(state, primary, node, indexMetadata);} else {// 主分片节点不在协调节点上performRemoteAction(state, primary, node);}
}
主分片写入
接收请求
TransportReplicationAction 构造函数,注册了主分片写入的处理函数
protected TransportReplicationAction(......
) {transportService.registerRequestHandler(transportPrimaryAction,executor,forceExecutionOnPrimary,true,in -> new ConcreteShardRequest<>(requestReader, in),this::handlePrimaryRequest);
}
主分片写入
TransportShardBulkAction#dispatchedShardOperationOnPrimary(...)
@Override
protected void dispatchedShardOperationOnPrimary(BulkShardRequest request,IndexShard primary,ActionListener<PrimaryResult<BulkShardRequest, BulkShardResponse>> listener
) {......// 在主分片上执行performOnPrimary(request, primary, updateHelper, threadPool::absoluteTimeInMillis, (update, shardId, mappingListener) -> {...}), listener, threadPool, executor(primary));
}
异步转发请求至副本分片
转发请求至副本分片,是在主分片写入数据后,才执行的
ReplicationOperation#execute(...)
public void execute() throws Exception {......// 执行主分片写入primary.perform(request, ActionListener.wrap(this::handlePrimaryResult, this::finishAsFailed));
}
handlePrimaryResult() 方法是写入主分片后的回调函数
ReplicationOperation#handlePrimaryResult(..)
private void handlePrimaryResult(final PrimaryResultT primaryResult) {...// 异步发送同步副本分片请求performOnReplicas(replicaRequest, globalCheckpoint, maxSeqNoOfUpdatesOrDeletes, replicationGroup, pendingReplicationActions);...
}
副本分片写入
接收请求
类似的,TransportReplicationAction 构造函数,注册了副本分片写入的处理函数
transportService.registerRequestHandler(transportReplicaAction,executor,true,true,in -> new ConcreteReplicaRequest<>(replicaRequestReader, in),this::handleReplicaRequest
);
数据写入
而后请求交给 AsyncReplicaAction#doRun() 处理
@Override
protected void doRun() throws Exception {......// 获取写入许可后,会回调至 AsyncReplicaAction#onResponse() acquireReplicaOperationPermit(replica,replicaRequest.getRequest(),this,replicaRequest.getPrimaryTerm(),replicaRequest.getGlobalCheckpoint(),replicaRequest.getMaxSeqNoOfUpdatesOrDeletes());
}
AsyncReplicaAction#onResponse()
@Override
public void onResponse(Releasable releasable) {...// 执行写入shardOperationOnReplica(...);...
}
调用该函数后,最后代码会走到 TransportShardBulkAction#dispatchedShardOperationOnReplica(...)
@Override
protected void dispatchedShardOperationOnReplica(BulkShardRequest request, IndexShard replica, ActionListener<ReplicaResult> listener) {ActionListener.completeWith(listener, () -> {final long startBulkTime = System.nanoTime();// 执行写入final Translog.Location location = performOnReplica(request, replica);replica.getBulkOperationListener().afterBulk(request.totalSizeInBytes(), System.nanoTime() - startBulkTime);return new WriteReplicaResult<>(request, location, null, replica, logger);});
}
相关文章:
第 31 章 - 源码篇 - Elasticsearch 写入流程深入分析
写入源码分析 接收与处理 请求首先会被 Netty4HttpServerTransport 接收,接着交由 RestController 进行路由分发。 private void tryAllHandlers(final RestRequest request, final RestChannel channel, final ThreadContext threadContext) throws Exception {…...

node.js下载、安装、设置国内镜像源(永久)(Windows11)
目录 node-v20.18.0-x64 工具下载安装设置国内镜像源(永久) node-v20.18.0-x64 工具 系统:Windows 11 下载 官网https://nodejs.org/zh-cn/download/package-manager 版本我是跟着老师选的node-v20.18.0-x64如图选择 Windows、x64、v2…...

小于n的最大数 - 贪心算法 - C++
字节经典面试题 给定一个整数n,并从1~9中给定若干个可以使用的数字,根据上述两个条件,得到每一位都为给定可使用数字的、最大的小于整数n的数,例如,给定可以使用的数字为 {2,3,8} 三个数:给定 n3589&#x…...

【顶刊TPAMI 2025】多头编码(MHE)之极限分类 Part 3:算法实现
目录 1 三种多头编码(MHE)实现1.1 多头乘积(MHP)1.2 多头级联(MHC)1.3 多头采样(MHS)1.4 标签分解策略 论文:Multi-Head Encoding for Extreme Label Classification 作者…...

解决CentOS 8 YUM源更新后报错问题:无法下载AppStream仓库元数据
背景介绍 在尝试更新CentOS 8的YUM源以使用阿里云镜像时,遇到了Failed to download metadata for repo appstream的错误。此错误通常出现在执行yum clean all && yum makecache命令之后,表明系统无法从指定的URL获取AppStream仓库的元数据。本文…...

[python3]Excel解析库-openpyxl
https://openpyxl.readthedocs.io/en/stable/ openpyxl 是一个用于读写 Excel 2010 xlsx/xlsm/xltx/xltm 文件的 Python 库。它允许开发者创建、修改和保存电子表格,而无需依赖 Microsoft Excel 软件本身。openpyxl 支持读取和写入 Excel 的工作簿(Work…...

Docker 远程访问完整配置教程以及核心参数理解
Docker 远程访问完整配置教程 以下是配置 Docker 支持远程访问的完整教程,包括参数说明、配置修改、云服务器安全组设置、主机防火墙配置,以及验证远程访问的详细步骤。 1. 理解 -H fd:// 参数的作用(理解了以后容易理解后面的操作ÿ…...

王老吉药业SRM系统上线 携手隆道共启战略合作新篇章
12月27日,广州王老吉药业股份有限公司(简称“王老吉药业”)SRM项目上线启动会,在王老吉科普教育基地——“吉园”隆重举行。广药集团纪委主任陈耕、王老吉药业总工程师黄晓丹、隆道公司总裁吴树贵、项目经理赵耀、供应商代表郭伟及…...

MyBatis 配置文件全解析
一、MyBatis 配置文件为何至关重要? 在 Java 后端开发领域,MyBatis 作为一款广受欢迎的持久层框架,极大地简化了数据库操作。而 MyBatis 配置文件,恰似整个框架的 “神经中枢”,掌控着其运行的方方面面,对…...

unity学习6:unity的3D项目的基本界面和菜单
目录 1 unity界面的基本认识 1.1 file 文件 1.2 edit 编辑/操作 1.3 Assets 1.4 gameobject 游戏对象 1.5 组件 1.6 windows 2 这些部分之间的关系 2.1 关联1: Assets & Project 2.2 关联2:gameobject & component 2.3 关联3…...

企业二要素如何用C#实现
一、什么是企业二要素? 企业二要素,通过输入统一社会信用代码、企业名称或统一社会信用代码、法人名称,验证两者是否匹配一致。 二、企业二要素适用哪些场景? 例如:信用与金融领域 1.信用评级:信用评级…...

中科院空天院无人机视觉语言导航新基准!AeroVerse:模拟、预训练、微调和评估空中无人机具身世界模型的测试基准
作者: Fanglong Yao, Yuanchang Yue, Youzhi Liu, Xian Sun, Kun Fu 单位:中国科学院空天信息创新研究院网络信息系统技术重点实验室,中国科学院大学电子电气与通信工程学院 原文链接: AeroVerse: UAV-Agent Benchmark Suite fo…...

Python安装(新手详细版)
前言 第一次接触Python,可能是爬虫或者是信息AI开发的小朋友,都说Python 语言简单,那么多学一些总是有好处的,下面从一个完全不懂的Python 的小白来安装Python 等一系列工作的记录,并且遇到的问题也会写出,…...

Oracle DG备库数据文件损坏修复方法(ORA-01578/ORA-01110)
今天负责报表的同事反馈在DG库查询时出现如下报错 ORA-01578:ORACLE数据块损坏(文件号6,块号 2494856)ORA-01110:数据文件6: /oradata/PMSDG/o1 mf users_molczgmn_.dbfORA-26040:数据块是使用 NOLOGGING 选项加载的 可以看到报错是数据文件损坏,提示了file id和b…...

安装Linux
在Linux系统上安装MySQL数据库,可以根据服务器是否有网络连接选择不同的安装方式。以下分别介绍在线安装(通过yum)和离线安装(手动下载.tar包)的详细步骤: 一、在线安装(通过yum) 检…...

【文献精读笔记】Explainability for Large Language Models: A Survey (大语言模型的可解释性综述)(四)
****非斜体正文为原文献内容(也包含笔者的补充),灰色块中是对文章细节的进一步详细解释! 四、提示范式(Explanation for Prompting Paradigm) 随着语言模型规模的扩大,基于提示(prom…...

【OpenCV】使用Python和OpenCV实现火焰检测
1、 项目源码和结构(转) https://github.com/mushfiq1998/fire-detection-python-opencv 2、 运行环境 # 安装playsound:用于播放报警声音 pip install playsound # 安装opencv-python:cv2用于图像和视频处理,特别是…...

SpringCloud(二)--SpringCloud服务注册与发现
一. 引言 前文简单介绍了SpringCloud的基本简介与特征,接下来介绍每个组成部分的功能以及经常使用的中间件。本文仅为学习所用,联系侵删。 二. SpringCloud概述 2.1 定义 Spring Cloud是一系列框架的有序集合,它巧妙地利用了Spring…...

国内Ubuntu环境Docker部署CosyVoice
国内Ubuntu环境Docker部署CosyVoice 本文旨在记录在 国内 CosyVoice项目在 Ubuntu 环境下如何使用 dockermin-conda进行一键部署。 源项目地址: https://github.com/FunAudioLLM/CosyVoice 如果想要使用 dockerpython 进行部署,可以参考我另一篇博客中的…...

嵌入式linux系统中QT信号与槽实现
第一:Qt中信号与槽简介 信号与槽是Qt编程的基础。因为有了信号与槽的编程机制,在Qt中处理界面各个组件的交互操作时变得更加直观和简单。 槽函数与一般的函数不同的是:槽函数可以与一个信号关联,当信号被发射时,关联的槽函数被自动执行。 案例操作与实现: #ifndef …...

从淘宝双十一到日常运维:EagleEye链路追踪如何重塑分布式系统可观测性
1. 当淘宝双十一遇到分布式系统:为什么我们需要EagleEye? 想象一下双十一零点那一刻,数百万用户同时点击"立即购买"按钮。这个看似简单的动作,在淘宝后台会触发数百次跨服务调用——从商品库存查询、优惠计算、风控审核…...
)
Python新手必看:5分钟搞定BMI计算器(附完整代码及format函数详解)
Python新手实战:从零构建BMI计算器与字符串格式化深度解析 在编程学习的起步阶段,能够快速实现一个看得见、用得着的小工具,往往比学习抽象概念更能激发持续学习的动力。BMI(身体质量指数)计算器就是一个绝佳的练手项目…...

G-Helper终极指南:如何用轻量工具彻底替代Armoury Crate提升ROG笔记本性能
G-Helper终极指南:如何用轻量工具彻底替代Armoury Crate提升ROG笔记本性能 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, F…...

AppScale GTS核心组件深度解析:从数据存储到任务队列
AppScale GTS核心组件深度解析:从数据存储到任务队列 【免费下载链接】gts AppScale is an easy-to-manage serverless platform for building and running scalable web and mobile applications on any infrastructure. 项目地址: https://gitcode.com/gh_mirro…...

Mipmap实战解析:从纹理闪烁到视觉平滑的渲染优化之路
1. 纹理闪烁的罪魁祸首:当像素与纹素相爱相杀 第一次在开放世界游戏中看到远处山体像癫痫发作般疯狂闪烁时,我差点以为显卡要烧了。这种被称为"纹理闪烁"的现象,本质上是像素与纹素的比例失衡导致的视觉灾难。想象你站在纽约帝国大…...

从理论到实践:信息量、码元与比特的深度解析及通信系统中的应用
1. 通信基础:从消息到信息的本质跃迁 记得我第一次接触通信原理时,最困惑的就是"消息"和"信息"的区别。老师举了个生动的例子:收到"明天下雨"这条消息,对农民和上班族的信息量完全不同。这让我恍然…...

一文读懂智慧农业|农户必看科普
开篇灵魂拷问:种地累、产量低,难道只能靠天吃饭? 其实不然,智慧农业的出现,正在改变传统种植的困境。很多农户对智慧农业一知半解,觉得是“高科技、离自己很远”,今天就用通俗的话,…...

Vitis HLS Schedule Viewer保姆级解读:从代码到硬件调度,一张图看懂你的设计瓶颈
Vitis HLS Schedule Viewer深度解析:从图形化调度到性能瓶颈精准定位 在FPGA加速设计领域,Vitis HLS作为高层次综合工具,能够将C/C代码转换为高效的硬件描述语言。然而,当设计遇到性能瓶颈时,开发者往往陷入报告数据的…...

为什么92%的企业AI团队还没部署多模态翻译?2026奇点大会公布的5个硬件兼容性陷阱必须今天避开
第一章:2026奇点智能技术大会:多模态翻译系统全景洞察 2026奇点智能技术大会(https://ml-summit.org) 在2026奇点智能技术大会上,多模态翻译系统成为核心议题之一。该系统不再局限于文本到文本的转换,而是深度融合语音、图像、手…...

碧蓝航线智能助手Alas:一键解放双手的全自动游戏管家
碧蓝航线智能助手Alas:一键解放双手的全自动游戏管家 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝…...