Apache Paimon-实时数据湖
一、Apache Paimon是什么?
Flink社区希望能够将 Flink 的 Streaming 实时计算能力和 Lakehouse 新架构优势进一步结合,推出新一代的 Streaming Lakehouse 技术,促进数据在数据湖上真正实时流动起来,并为用户提供实时离线一体化的开发体验。
Flink 社区内部孵化了 Flink Table Store (简称 FTS )子项目,一个真正面向 Streaming 以及 Realtime的数据湖存储项目。
2023年3月12日,FTS进入 Apache 软件基金会 (ASF) 的孵化器,改名为 Apache Paimon (incubating)。
简单来说,Apache Paimon是一个流数据湖平台,兼容Apach Flink、Spark等主流计算引擎,支持流批一体处理、快速查询和性能优化,具有高速数据摄取、变更日志跟踪和高效的实时分析的能力。
目前,24年已经在阿里巴巴集团内大规模应用,目前更新到1.0版本。
官网介绍:
Apache Paimon 是一种 Lake 格式,支持使用 Flink 和 Spark 构建实时 Lakehouse 架构,用于流式和批处理操作。Paimon 创新性地结合了 Lake 格式和 LSM(日志结构合并树)结构,将实时流式更新引入 Lake 架构。
Paimon 提供以下核心功能:
- 实时更新:
- 主键表支持大规模更新的写入,具有非常高的更新性能,通常通过Flink Streaming进行。
- 支持定义合并引擎,按您喜欢的方式更新记录。删除重复项以保留最后一行、部分更新、聚合记录或第一行,您决定。
- 支持定义changelog-producer,为合并引擎的更新生成正确、完整的changelog,简化您的流分析。
- 大量附加数据处理:
- 附加表(无主键)提供大规模批处理和流处理能力。自动小文件合并。
- 支持通过 z 顺序排序进行数据压缩以优化文件布局,并使用 minmax 等索引提供基于数据跳过的快速查询。
- 数据湖功能:
- 可扩展的元数据:支持存储Petabyte大规模数据集,支持存储大量分区。
- 支持 ACID 事务、时间旅行和模式演变。
官网:https://paimon.apache.org/
Github:https://github.com/apache/incubator2、文件-paimon
二、Apache Paimon原理
1、底层存储
Paimon采用LSM树(日志结构合并树)作为文件存储的数据结构,LSM树将文件组织成多个Sorted Run,Sorted Run由一个或多个数据文件组成,并且每个数据文件只属于一个Sorted Run。
写入LSM树的新记录将首先缓存在内存中。当内存缓冲区满时,内存中的所有记录将被排序并刷新到磁盘。
查询LSM树时,必须合并所有Sorted Run。当越来越多的记录写入LSM树时,Sorted Run的数量将会增加。由于查询LSM树需要将所有Sorted Run合并起来,太多Sorted Run将导致查询性能较差,甚至内存不足。为了限制Sorted Run的数量,我们必须偶尔将多个Sorted Run合并为一个大的Sorted Run。这个过程称为Compaction。
但是过于频繁的Compaction可能会导致写入速度变慢,这是查询和写入性能之间的权衡。

2、文件管理
一张表的所有文件都存储在一个基本目录下。Paimon 文件采用分层的方式组织。下图说明了文件布局。从快照文件开始,Paimon 读取器可以递归访问表中的所有记录。

2.1 Snapshot(快照文件)
所有快照文件都存储在snapshot目录中。
快照文件是一个 JSON 文件,改文件包含了:
-
正在使用的架构文件
-
包含此快照所有更改的清单
快照可以捕获表在某个时间点的状态。用户可以通过最新的快照访问表的最新数据。通过时间旅行,用户还可以通过较早的快照访问表的先前状态。
--->类似Hadoop中的镜像文件和编辑日志。
2.2 Manifest Files(清单文件)
所有的清单列表(manifest list)和清单文件(manifest file)都存储在manifest目录中。
清单列表(manifest list)是清单文件名(manifest file)的列表。
清单文件(manifest list)是包含有关 LSM 数据文件和变更日志文件的变更的文件。例如,在相应的快照中创建了哪个 LSM 数据文件以及删除了哪个文件。
2.3 DataFile(数据文件)
数据文件按分区分组。目前,Paimon 支持使用 parquet(默认)、orc 和 avro 作为数据文件的格式。(avro是行存储、parquet和orc是列存储)
2.4 Partition(分区)
Paimon 采用与 Apache Hive 相同的分区概念来分离数据。分区是一种可选方法,可根据日期、城市和部门等特定列的值将表划分为相关部分。每个表可以有一个或多个分区键来标识特定分区。通过分区,用户可以有效地对表中的一段记录进行操作。
2.5 一致性保证
Paimon 写入器使用两阶段提交协议,以原子形式将一批记录提交到表中。每次提交在提交时最多产生两个快照。这取决于增量写入和压缩策略。如果仅执行增量写入而不触发压缩操作,则只会创建增量快照。如果触发了压缩操作,则会创建增量快照和压缩快照。
对于同时修改表的任何两个writer,只要他们不修改同一个分区,他们的提交就可以并行发生。如果他们修改同一个分区,则只能保证快照隔离。也就是说,最终的表状态可能是两次提交的混合,但不会丢失任何更改。有关更多信息,请参阅专用压缩作业。
总结:Paimon通过LSM树(日志结构合并树)和列式存储格式(parquet/orc)实现高查询。
3、主要应用场景
3.1 Flink CDC将数据引入数据湖
Paimon对此进行优化,可以一键摄取整个数据库,引入数据湖,大大降低了架构的复杂性,同时还提供灵活的更新选项,允许应用特定列或不用类型的聚合更新。(支持更新的数据入湖)
3.2 构建流式数据管道
PAIMON可用于构建完整的流式数据管道,其主要功能包括:生成ChangeLog,允许流式读取访问完全更新的记录,从而更轻松地构建强大的流式数据管道。
PAIMON也正在发展为具有消费者机制的消息队列。最新版本引入了变更日志的生命周期管理,可让用户定义它们的保留时间,类似于 Kafka(例如,日志可以存储七天或更长时间)。这创建了一个轻量级、低成本的流媒体管道解决方案。
3.3 超快速OLAP查询
虽然前两个用例可确保实时数据流,但 PAIMON还支持高速 OLAP 查询来分析存储的数据。通过结合LSM和Index,PAIMON 可以实现快速数据分析。其生态系统支持Flink、Spark、StarRocks、Trino等多种查询引擎,都可以高效查询PAIMON中存储的数据。
4、实践案例
案例一:提升实时数据分析效率
问题描述:一家全球大型零售客户,其面临的挑战是如何在门店和电商平台并行的人群中进行实时的用户行为分析和个性化推荐。传统的数据分析架构下,系统无法高效处理大规模实时数据,导致用户体验不佳,推荐系统延迟高。
解决方案:通过引入Apache PAIMON,实时同步用户的购物行为和库存数据,结合Flink进行流式数据处理,客户能够基于最新数据生成个性化推荐。这不仅提升了用户的购物体验,还降低了基础设施成本。
案例二:构建可靠的实时业务监控
问题描述:一家零售客户,其供应链管理系统随着业务规模扩展和复杂性增加,运营与流程管理部门亟需实现对各类业务流程的实时监控,以确保流程的稳定性与高效性。然而,现有系统架构仅支持离线数据,无法满足实时业务需求。
解决方案:通过引入PAIMON数据湖,基于Aliyun EMR + OSS构建了一个实时数据湖。该系统通过Flink和Flink CDC实时收集多个数据源的数据,结合OSS对象存储,确保了数据的可查询性和分层复用。同时在分析层结合Doris,解决了OLAP分析时效性低的问题,提高了报表和监控系统的时效性。
--案例来自Artefact
三、Paimon和Flink神魔关系
Paimon是做湖上的实时化处理,所以他是从Flink社区诞生的,是一种流批统一的数据湖存储格式,他能够与Flink紧密配合,实现实时数据湖。为了更好的了解Paimon,我们要求清楚其他的存储格式Iceberg、Hudi是什么,和Paimon有什么关系。

Apache Hudi、Apache Iceberg 、Apache Paimon都是面向大数据湖的表格式存储管理框架。
- Hudi,发展最早,服务生态齐全,但是参数很多,开发要求较高,维护性差,面向批处理
- Iceberg,表简单,没有很多表引擎,主要面向离线生态,对实时的更新很慢
- Paimon,实时很快,流批一体
四、Paimon的好处
解决Kafka不可查的问题:以前使用Kafka做中间件来进行流处理,但是kafka是不可查的,所以最后还需要一个可以查询的引擎,比如把数据写入StarRocks上进行查询。但是Paimon作为一个湖格式,可以批写批读,也可以流写流读,它把整条streaming链路建立起来,每一层都是事实可查的,架构能够完全实现流批一体。
支持更新的数据入湖: 通过FlinkCDC,可以一键摄取整个数据库,引入数据湖,大大降低了架构的复杂性,同时还提供灵活的更新选项,允许应用特定列或不用类型的聚合更新。
参考文章:
流数据湖平台Apache Paimon(一)概述-阿里云开发者社区
Apache PAIMON:实时数据湖技术框架及其实践
【全网首发】Apache Paimon大厂面试必备系列-基础篇
Apache Paimon大厂面试题必备-进阶篇(一)
Paimon助力数据湖仓架构实时化升级-阿里云开发者社区
Flink+Paimon实时数据湖仓实践分享-CSDN博客
数据湖Iceberg、Hudi和Paimon比较_apache paimon-CSDN博客
相关文章:
Apache Paimon-实时数据湖
一、Apache Paimon是什么? Flink社区希望能够将 Flink 的 Streaming 实时计算能力和 Lakehouse 新架构优势进一步结合,推出新一代的 Streaming Lakehouse 技术,促进数据在数据湖上真正实时流动起来,并为用户提供实时离线一体化的开发体验。 …...

hpm使用笔记————使用usb作为从机接收来自上位机的数据然后通过spi主机发送给spi从机
历程整合 环境要求任务需求任务实现代码实现任务测试功能测试 结束 环境 hpm_sdk v 1.7.0ses v8.10 要求 例程demo USB-CDC 作为从机接收,然后把接收到的数据转发给SPI,SPI传输出去 任务需求 USB使用cherry协议栈进行开发 作为device设备(…...

数据结构(查找算法)
1. 查找的概念 在一堆数据中,找到我们想要的那个数据,就是查找,也称为搜索,很容易想到,查找算法的优劣,取决于两个因素: 数据本身存储的特点查找算法本身的特点 比如,如果数据存储…...

private前端常见算法
1.数组 合并两个有序数组(简单-5) https://leetcode.cn/problems/merge-sorted-array/description/?envTypestudy-plan-v2&envIdtop-interview-150 移除元素(简单-4) https://leetcode.cn/problems/remove-element/descr…...
)
Go语言之十条命令(The Ten Commands of Go Language)
Go语言之十条命令 Go语言简介 Go语言(又称Golang)是由Google开发的一种开源编程语言,首次公开发布于2009年。Go语言旨在提供简洁、高效、可靠的软件开发解决方案,特别强调并发编程和系统编程。 Go语言的基本特征 静态强类…...

Residency 与 Internship 的区别及用法解析
Residency 与 Internship 的区别及用法解析 在英文中,“residency” 和 “internship” 都与职业培训相关,但它们的使用场景和具体含义存在显著差异。本文将详细解析这两个词的区别,以及它们在不同语境下的应用。 Residency 的定义及使用场景…...

成品电池综合测试仪:电子设备性能与安全的守护者|鑫达能
在现代科技和工业领域,电池作为能量储存和转换的关键组件,其性能的稳定性和可靠性至关重要。为了确保电池在各种应用场景中都能发挥最佳性能,成品电池综合测试仪应运而生。这一设备不仅能够对电池的各项性能指标进行全面、准确的检测…...

Taro地图组件和小程序定位
在 Taro 中使用腾讯地图 1.首先在项目配置文件 project.config.json 中添加权限: {"permission": {"scope.userLocation": {"desc": "你的位置信息将用于小程序位置接口的效果展示"}} }2.在 app.config.ts 中配置&#x…...

深入了解 SSL/TLS 协议及其工作原理
深入了解 SSL/TLS 协议及其工作原理 一. 什么是 SSL/TLS?二. SSL/TLS 握手过程三. SSL/TLS 数据加密与传输四. 总结 点个免费的赞和关注,有错误的地方请指出,看个人主页有惊喜。 作者:神的孩子都在歌唱 一. 什么是 SSL/TLS? 安全套接层&am…...

【计算机操作系统:二、操作系统的结构和硬件支持】
第2章 操作系统的结构和硬件支持 2.1 操作系统虚拟机 操作系统虚拟机是一种通过软件技术对硬件资源进行抽象和虚拟化的机制,使用户能够以逻辑方式访问和使用计算机资源。 定义与概念: 虚拟机是操作系统虚拟化技术的核心产物,通过模拟硬件资…...

51单片机——步进电机模块
直流电机没有正负之分,在两端加上直流电就能工作 P1.0-P1.3都可以控制电机,例如:使用P1.0,则需要把线接在J47的1(VCC)和2(OUT1)上 1、直流电机实验 要实现的功能是:直…...

当算法遇到线性代数(四):奇异值分解(SVD)
SVD分解的理论与应用 线性代数系列相关文章(置顶) 1.当算法遇到线性代数(一):二次型和矩阵正定的意义 2.当算法遇到线性代数(二):矩阵特征值的意义 3.当算法遇到线性代数࿰…...

SASS 简化代码开发的基本方法
概要 本文以一个按钮开发的实例,介绍如何使用SASS来简化CSS代码开发的。 代码和实现 我们希望通过CSS开发下面的代码样式,从样式来看,每个按钮的基本样式相同,就是颜色不同。 如果按照传统的方式开发,需要开发btn &…...

40.TryParse尝试转化为int类型 C#例子
也许这个时候学有点晚,但是不管怎样都学了 尝试转化,不能转化就返回bool类型的假 它会直接给括号里面的int类型赋值 代码: using System; using System.Timers; public class Program {static void Main(){int a;bool i;while (true){Get…...

【微服务】2、网关
Spring Cloud微服务网关技术介绍 单体项目拆分微服务后的问题 服务地址问题:单体项目端口固定(如黑马商城为8080),拆分微服务后端口各异(如购物车808、商品8081、支付8086等)且可能变化,前端难…...
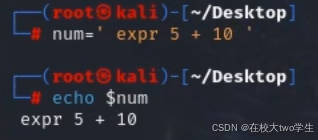
红队-shell编程篇(上)
声明 通过学习 泷羽sec的个人空间-泷羽sec个人主页-哔哩哔哩视频,做出的文章如涉及侵权马上删除文章 笔记的只是方便各位师傅学习知识,以下网站只涉及学习内容,其他的都与本人无关,切莫逾越法律红线,否则后果自负 一、建立Shell文件 1. Shell简介 Shell是一种命令行界面&am…...

电子价签会是零售界的下一个主流?【新立电子】
电子价签,作为一种能够替代传统纸质标签的数字显示屏,已经在零售行业中展现出其巨大的潜力。它具有实时更新、集中管理、高效节能的特点,实现价格的实时更新,大大减少更新价格的工作量和时间。为消费者带来更加便捷、准确的购物体…...

5 分布式ID
这里讲一个比较常用的分布式防重复的ID生成策略,雪花算法 一个用户体量比较大的分布式系统必然伴随着分表分库,分机房部署,单体的部署方式肯定是承载不了这么大的体量。 雪花算法的结构说明 如下图所示: 雪花算法组成 从上图我们可以看…...

SpringBoot | @Autowired 和 @Resource 的区别及原理分析
关注:CodingTechWork 引言 在Spring框架中,Autowired 和 Resource 是两种常用的依赖注入注解,它们都用于自动装配Bean,简化了开发者手动创建和管理Bean的繁琐工作。然而,它们的实现机制和使用方式有所不同。理解这两者…...
)
『SQLite』解释执行(Explain)
摘要:本节主要讲解SQL的解释执行:Explain。 在 sqlite 语句之前,可以使用 “EXPLAIN” 关键字或 “EXPLAIN QUERY PLAN” 短语,用于描述表查询的细节。 基本语法 EXPLAIN 语法: EXPLAIN [SQLite Query]EXPLAIN QUER…...

ANARCI抗体序列编号:生物信息学研究的终极利器
ANARCI抗体序列编号:生物信息学研究的终极利器 【免费下载链接】ANARCI Antibody Numbering and Antigen Receptor ClassIfication 项目地址: https://gitcode.com/gh_mirrors/an/ANARCI 在抗体研究和免疫组库分析中,科学家们面临着一个共同的挑战…...

Xtreme Download Manager:解决大文件下载与视频抓取难题的终极方案
Xtreme Download Manager:解决大文件下载与视频抓取难题的终极方案 【免费下载链接】xdm Powerfull download accelerator and video downloader 项目地址: https://gitcode.com/gh_mirrors/xd/xdm 你是否曾因下载大文件速度缓慢而烦恼?是否想在Y…...

如何永久保存微信聊天记录?三步实现数据自主管理的完整指南
如何永久保存微信聊天记录?三步实现数据自主管理的完整指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/…...

DownKyi视频下载工具:3步快速上手与5大实用技巧
DownKyi视频下载工具:3步快速上手与5大实用技巧 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等)…...

OpenCode实战案例:用AI编程助手快速开发项目,提升10倍编码效率
OpenCode实战案例:用AI编程助手快速开发项目,提升10倍编码效率 1. 为什么选择OpenCode作为AI编程助手 作为一名长期奋战在代码一线的开发者,我一直在寻找能够真正提升开发效率的工具。当我第一次接触OpenCode时,就被它的设计理念…...

为什么finally块中的return会覆盖try块中的return?
在Java异常处理机制中,finally块通常用于执行必须完成的清理操作,但一个令人困惑的现象是:当try和finally块同时存在return语句时,finally中的return会覆盖try中的返回值。这一设计看似违反直觉,却隐藏着语言底层的逻辑…...

RAG 还是 Lucene:私有化部署客服系统的 AI 知识库架构选型捶
在之前的文章中,我们花了大量的篇幅,从记录后端pod真实ip开始说起,然后引入envoy,再解决了各种各样的需求:配置自动重载、流量劫持、sidecar自动注入,到envoy的各种能力:熔断、流控、分流、透明…...

Hunyuan-MT-7B镜像免配置:支持Webhook回调与翻译结果异步通知
Hunyuan-MT-7B镜像免配置:支持Webhook回调与翻译结果异步通知 想快速部署一个高质量的翻译大模型,但又不想折腾复杂的配置?今天介绍的Hunyuan-MT-7B镜像,让你能一键启动一个支持33种语言互译的翻译服务,并且自带Webho…...

Qwen3-VL-2B图文理解系统备份方案:数据安全实战部署
Qwen3-VL-2B图文理解系统备份方案:数据安全实战部署 1. 引言 想象一下,你花了好几天时间,终于把一个能看懂图片、识别文字的AI服务部署上线了。它不仅能帮你分析商品图,还能从复杂的图表里提取数据,甚至辅导孩子做作…...

移动AI部署
移动AI部署:让智能触手可及 在智能手机、无人机、可穿戴设备等移动终端快速普及的今天,人工智能(AI)技术正逐步从云端下沉至边缘设备。移动AI部署将强大的AI能力嵌入便携设备,实现实时响应、隐私保护和离线运行&#…...