0 Token 间间隔 100% GPU 利用率,百度百舸 AIAK 大模型推理引擎极限优化 TPS
1. 什么是大模型推理引擎
大模型推理引擎是生成式语言模型运转的发动机,是接受客户输入 prompt 和生成返回 response 的枢纽,也是拉起异构硬件,将物理电能转换为人类知识的变形金刚。
大模型推理引擎的基本工作模式可以概括为,接收包括输入 prompt 和采样参数的并发请求,分词并且组装成 batch 输入给引擎,调度 GPU 执行前向推理,处理计算结果并转为词元返回给用户。
- 和人类大脑处理语言的机制类似,大模型首先会把输入的 prompt 进行统一理解,形成具有记忆能力的上下文。这个阶段通常称为 Prefill 阶段。
- 在结束 Prefill 阶段之后,大模型引擎会根据生成的上下文不停地推断下一个可能出现的词语,如此往复循环,直到遇到停止符或者满足采样参数中的停止条件。这是一个自回归过程,通常称为 Decoder 阶段。
由于 Prefill 阶段和 Decoder 阶段所完成的任务不同,通常来讲,会从用户视角出发使用 SLO(Service Level Object): TTFT(Time To First Token)和TPOT(Time Per Output Token)去评测引擎。
- TTFT 就是首 token 延迟,用于衡量 Prefill 阶段的性能。也就是用户发出请求之后,收到第一个词元返回的间隔,也就是系统的反应时间。对于客户来说,这个指标越低越好。
- TPOT 就是出字间隔,用于衡量 Decoder 阶段的性能。也就是每生成两个词元之间的间隔。通常需要比人眼阅读文字的速度要快,这个指标同样也是越低越好。
当然,只用这些 SLO 并不能完全评测推理引擎对资源的使用状态,所以,和其他使用异构资源的系统一样,会使用吞吐来评测引擎对资源的使用效率,常用的指标就是极限出字率。
极限出字率 TPS(Tokens Per Second )就是系统在满载的情况下,使用所有可用的资源在 1s 内可以生成的词元的最大数量。这个指标越高,代表硬件的效率越高,可以支持的用户规模就越多。
目前市面上流行的推理引擎有很多,比如说 vLLM、SGLang、LMDeploy、TRT-LLM 等。其中 vLLM 是业界第一个完美解决了大模型不定长特性来各种问题的推理引擎,也是市面上使用最多,社区最活跃的推理引擎。
vLLM 的原创性高效显存管理、高吞吐、极易用、易拓展、模式众多、新特性支持快,社区活跃等特性是其受欢迎的原因。但是,vLLM 对复杂调度逻辑的处理没有做到极致,引入了大量的 CPU 操作,拉长了 TPOT。TPOT 的拉长会降低用户体验,降低了出字率,造成了 GPU 资源浪费。
2. 影响 TPOT 的罪魁祸首 —— Token 间间隔
区别于小模型推理以 batch 为最小推理单位,大模型推理的最小单位是 step。这也是由大模型推理中自回归的特点所决定的。
每一次 step 会给 batch 内部的每个请求生成一个词元,如果有请求生成了结束符,那么这个请求将会提前结束,并且从下个 step 的 batch 中剔除,空余出来的资源将会被引擎动态的分配给其余正在排队的请求。用户可以感知到的观测指标 TPOT,就是每次 step 的执行时间。
每个 step 的执行逻辑可以简单的概括为一下两部分:前向推理和 Token 间间隔。
- 前向推理是调用 GPU 计算资源对 Transfomer 结构进行运算的过程,是一个典型的 GPU 密集计算型任务。
- Token 间间隔,则负责做词元拼接、结束检测、用户响应、请求调度、输入准备等工作,是典型的 CPU 逻辑密集型任务。
优化推理引擎的终极目标其实就是,极限提升前向推理的吞吐,同时极限压缩 Token 间间隔,最终提高极限出字率。
然而,vLLM 的实现中,这两者天然存在着矛盾。极限提升前向推理的吞吐,(即充分发挥 GPU 算力)要求在适当范围内尽可能增加 batch 内的请求数。然而更多的请求数却拉长了 Token 间间隔,这样不仅会使 TPOT 拉长,还会导致 GPU 断流,出现空闲。在最差的情况下(比如 batch 为 256),Token 间间隔和前向推理时间几乎相同,GPU 的利用率只有 50%-60%。
为了提升极限出字率,同时确保高 GPU 利用率,优化 Token 间间隔成为了提升推理速度的关键。
3. 百度百舸 AIAK 优化 Token 间间隔的方案
百度百舸的 AI 加速套件 AIAK 完美继承了 vLLM 的优势,在优化 TPOT 持续发力,并且始终保持着对社区在同周期的技术领先。
3.1. 解决方案 1:多进程架构
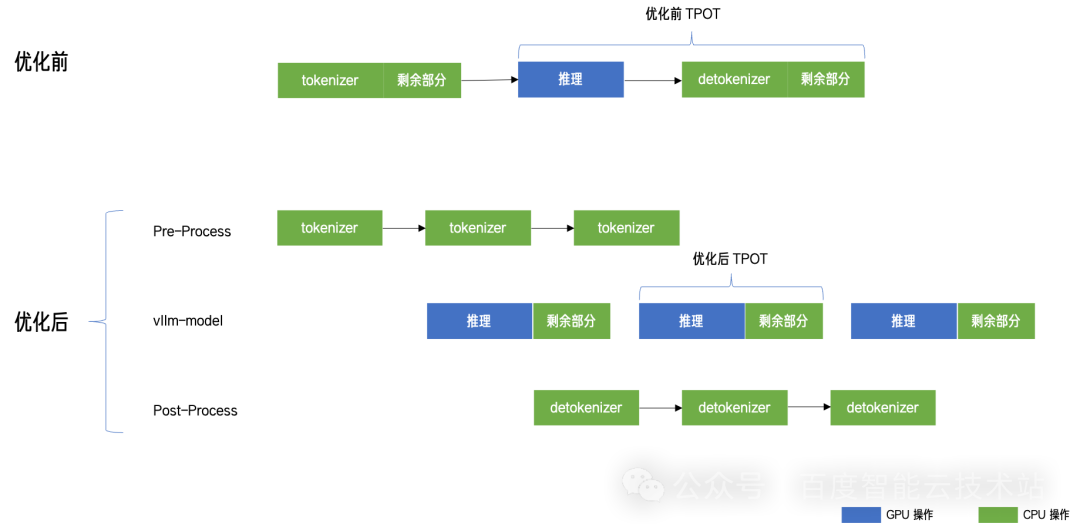
这个方案的目标是尽可能缩短 Token 间间隔,将 detokenizer 所耗费的时间从 TPOT 中拿去。
我们发现在处理输入请求和生成返回的过程中,tokenize/detokenize 过程(token id 和字符串的转换)是完全可以独立于 GPU 推理运算的逻辑操作。
所以,我们借助 NVIDIA Triton 框架,将 tokenize/detokenize 的过程从推理流程中抽象出来作为单独的 Triton 模型部署,借助 Triton 的 ensemble 机制,把串行过程转变为 3 阶段( 3 进程)流水,实现了 tokenize/detokenize 和 GPU 推理 overlap,有效缩短了 Token 间隔时间。尽管这个优化只把 Token 间间隔中一部分 CPU 操作消除了,但是依然有将近 10% 的收益。
3.2. 解决方案 2:静态 Slot 方案
这个方案主要改造了 vLLM 的调度逻辑,全方位优化了词元拼接、结束检测、用户响应、请求调度、输入准备,提高了各个模块的并行效率,实现了对上一个方案中的「剩余部分」耗时的压缩。
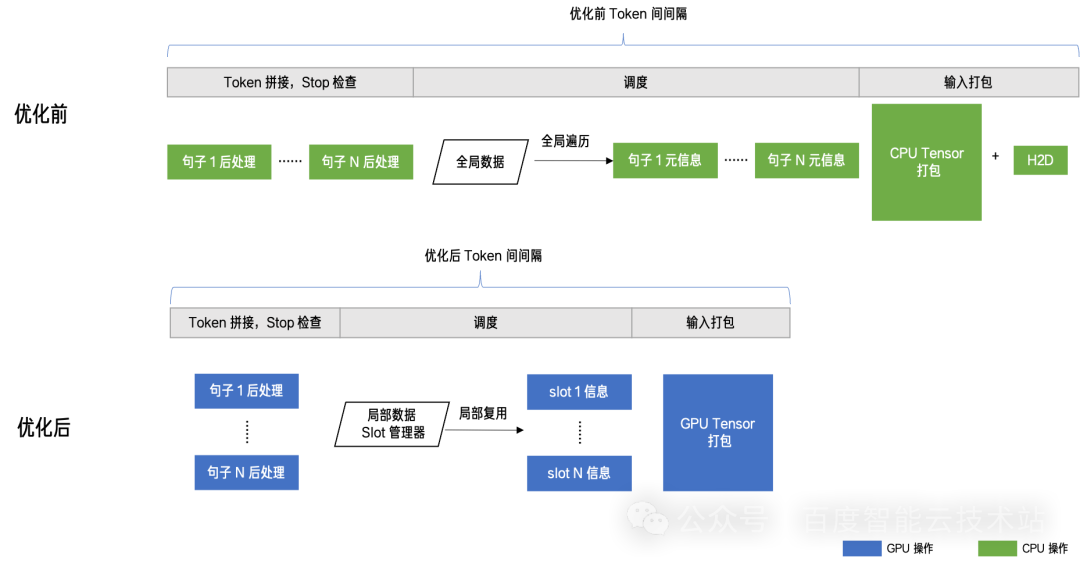
我们发现 vLLM 的调度逻辑是面向全局视角的。也就是说每个 step 的调度都会从全局中进行重新筛选,相当于当前 step 结束之后,调度器会把当前 batch 中的句子「放回」全局请求池子中,然后在下一个 step 开始前,从这个全局池子中「取回」适当请求进行运算,这一放一取引入了额外的 overhead。
为了实现全局调度,vLLM 在词元拼接等其他环节引入了大量的 for 循环去串行的处理每个请求,由于这些操作都在发生在 CPU 上,导致在输入打包过程中,必须要引入耗时较长的 host to device 操作。
事实上,step 之间的很多信息是可以复用的(每次放回去的请求和取回来的请求很大一部分是重复的)。也正是基于这个洞见,百度百舸的 AIAK 把 GPU 每次可以迭代的 batch 当成一批固定的 slot,一旦某个请求被调度到某个 slot 后,在完成请求所有推理迭代之前,都不会被唤出,也正是有了这些固定 slot 抽象,AIAK 实现了:
- 将全局调度改造为局部调度。也就是在下一个 step 调度时,最大程度复用上一个 step 的信息,避免全局搜索,只做增量调度。
- 串行转并行。也正是有了 slot 的引入,词元拼接、结束检测等这些原本串行的操作可以用 CUDA Kernel 做并发处理,耗时从 ms 级别降低到 us 级别。
- 避开 host to device 操作。输入打包的工作得以复用前序的显存,有效避开了 host to device 操作。
3.3. 方案 3:异步化执行
多进程架构将逻辑上容易独立的部分解耦到其他进程做流水并行,静态 Slot 方案则直面 token 间耗时问题,优化调度模式压榨各个环节的耗时。有了这两个方案,Token 间间隔已经从 35ms 降低到 14ms,GPU 的利用率已经从 50% 提升到了 75%,但是距离 100% 的 GPU 利用率和零耗时 Token 间间隔的目标还有不少距离。
百度百舸 AIAK 通过异步调度模式,将前一个方案中的「剩余部分」全部取出,最终实现了上述极限目标。
简单来讲,就是将 CPU 操作密集的 Token 间间隔和 GPU 计算密集的前向推理完全分开到两条流水线上做二级流水并行。
- 从逻辑上来讲,核心调度逻辑摆脱了对前向推理的同步依赖,实现异步化调度。
- 从效果上来说,GPU 避免 token 间同步导致的断流问题,处于一直繁忙状态,实现了推理过程中 100% 利用率和 0 Token 间间隔。
为了简化实现,我们将操作相对简单的前向推理当做一个任务放在后台线程中进行运行,主线程则运行核心的复杂的调度逻辑。两个线程通过一个队列进行交互,分别冲当生产者和消费者,通过线程信号量和 GPU 流上的事件进行信号同步,实现二级流互相 overlap。

和其他任何使用 GPU 类似的硬件作为加速器的系统一样,追求 100% 的利用率一直是所有工程师的终极目标。百度百舸的 AI 加速套件 AIAK 在优化 TPOT,同时打满 GPU 利用率这一目标上经历漫长而又艰辛的探索,最终才彻底实现了 0 Token 间间隔和 100% 利用率这一目标。
当然,除去在这个过程中使用的诸多巧妙的优化手段外,百度百舸的 AIAK 还在量化、投机式、服务化、分离式、多芯适配等领域做了大量工作,致力于实现一个适用于全场景、多芯片、高性能的推理引擎,助力用户在「降低推理成本,优化用户体验上」更上一层楼。
相关文章:
0 Token 间间隔 100% GPU 利用率,百度百舸 AIAK 大模型推理引擎极限优化 TPS
1. 什么是大模型推理引擎 大模型推理引擎是生成式语言模型运转的发动机,是接受客户输入 prompt 和生成返回 response 的枢纽,也是拉起异构硬件,将物理电能转换为人类知识的变形金刚。 大模型推理引擎的基本工作模式可以概括为,…...

js:事件流
事件流 事件流是指事件完整执行过程中的流动路径 一个事件流需要经过两个阶段:捕获阶段,冒泡阶段 捕获阶段是在dom树里获取目标元素的过程,从大到小 冒泡阶段是获取以后回到开始,从小到大,像冒泡一样 实际开发中大…...

Linux对比Windows
1. 性能和资源占用 Linux 更轻量级:Linux 内核设计简洁,占用系统资源(如内存、CPU)较少,适合高负载的服务器环境。 高效的多任务处理:Linux 在多任务处理和并发请求方面表现优异,适合处理大量并…...

Excel 技巧03 - 如何对齐小数位数? (★)如何去掉小数点?如何不四舍五入去掉小数点?
这几个有点儿关联,我都给放到一起了,不影响大家分别使用。 目录 1,如何对齐小数位数? 2,如何去掉小数点? 3,如何不四舍五入去掉小数点? 1,如何对齐小数位数ÿ…...

Vue3国际化多语言的切换
参考链接: link Vue3国际化多语言的切换 一、安装 vue-i18n 和 element-plus vue-i18n 是一个国际化插件,专为 Vue.js 应用程序设计,用于实现多语言支持。它允许你将应用程序的文本、格式和消息转换为用户的首选语言,从而提供本地化体验。…...
使用XAML语言仿写BiliBil登录界面
实现步骤 实现左右布局 使用了Grid两列的网格布局,第一列宽度占35%,第二列宽度占65%。使用容器布局Border包裹左右布局内容,设置背景色、设置圆角 <!-- 定义两列--> <Grid.ColumnDefinitions><ColumnDefinition Width &quo…...

机器学习和深度学习
机器学习(Machine Learning,简称 ML)和深度学习(Deep Learning,简称 DL)都是人工智能(AI)领域的重要技术,它们的目标是使计算机通过数据学习和自主改进,从而完…...

Word表格批量提取数据到Excel,Word导出到Excel,我爱excel
Word表格批量提取数据到Excel,Word导出到Excel - 我爱Excel助你高效办公 在日常办公中,Word表格常常用于记录和整理数据,但将这些数据从Word提取到Excel,特别是当涉及多个文件时,常常让人头疼。如果你经常需要将多个W…...

SpringSecurity抛出异常但AccessDeniedHandler不生效
文章目录 复现原因 复现 Beanpublic SecurityFilterChain securedFilterChain(HttpSecurity http) throws Exception {//...//异常http.exceptionHandling(except -> {except.authenticationEntryPoint(new SecurityAuthenticationEntryPoint());except.accessDeniedHandle…...

高清绘画素材3600多张动漫线稿线描上色练习参考插画原画
工作之余来欣赏一波线稿,不务正业版... 很多很多的线稿... 百度网盘 请输入提取码...

EXCEL技巧
1. EXCEL技巧 1.1. 截取表格内某个字符之前的所有字符 1.1.1.样例 在单元格内输入函数: # 截取A1单元格内“分”字符左边的所有字符 LEFT(A1,FIND("分",A1)-1)1.1.2.截图...

python制作翻译软件
本文复刻此教程:制作属于自己的翻译软件-很简单【Python】_哔哩哔哩_bilibili 一、明确需求(以搜狗翻译为例) (1)网址:https://fanyi.sogou.com/text (2) 数据:翻译内容…...

ollama+FastAPI部署后端大模型调用接口
ollamaFastAPI部署后端大模型调用接口 记录一下开源大模型的后端调用接口过程 一、ollama下载及运行 1. ollama安装 ollama是一个本地部署开源大模型的软件,可以运行llama、gemma、qwen等国内外开源大模型,也可以部署自己训练的大模型 ollama国内地…...

BERT:深度双向Transformer的预训练用于语言理解
摘要 我们介绍了一种新的语言表示模型,名为BERT,全称为来自Transformer的双向编码器表示。与最近的语言表示模型(Peters等,2018a;Radford等,2018)不同,BERT旨在通过在所有层中联合调…...

【AI-23】深度学习框架中的神经网络3
神经网络有多种不同的类型,每种类型都针对特定的任务和数据类型进行优化。根据任务的特点和所需的计算能力,可以选择适合的神经网络类型。以下是一些主要的神经网络类型及其适用的任务领域。 1. 深度神经网络(DNN) 结构…...

网站运营数据pv、uv、ip
想要彻底弄清楚pv uv ip的区别,首先要知道三者的定义: IP(独立IP)的定义: 即Internet Protocol,指独立IP数。24小时内相同公网IP地址只被计算一次。 PV(访问量)的定义: 即Page View,即页面浏览量或点击量,用户每次刷…...
)
高阶知识库搭建实战五、(向量数据库Milvus安装)
以下是关于在Windows环境下直接搭建Milvus向量数据库的教程: 本教程分两部分,第一部分是基于docker安装,在Windows环境下直接安装Milvus向量数据库,目前官方推荐的方式是通过Docker进行部署,因为Milvus的运行环境依赖于Linux系统。 如果你希望在Windows上直接运行Milvus…...

【TR369】RTL8197FH-VG+RTL8812F增加TR369 command节点
sdk说明 ** Gateway/AP firmware v3.4.14b – Aug 26, 2019** Wireless LAN driver changes as: Refine WiFi Stability and Performance Add 8812F MU-MIMO Add 97G/8812F multiple mac-clone Add 97G 2T3R antenna diversity Fix 97G/8812F/8814B MP issu…...

FPGA实现UART对应的电路和单片机内部配合寄存器实现的电路到底有何区别?
一、UART相关介绍 UART是我们常用的全双工异步串行总线,常用TTL电平标准,由TXD和RXD两根收发数据线组成。 那么,利用硬件描述语言实现UART对应的电路和51单片机内部配合寄存器实现的电路到底有何区别呢?接下来我们对照看一下。 …...

数据库模型全解析:从文档存储到搜索引擎
目录 前言1. 文档存储(Document Store)1.1 概念与特点1.2 典型应用1.3 代表性数据库 2. 图数据库(Graph DBMS)2.1 概念与特点2.2 典型应用2.3 代表性数据库 3. 原生 XML 数据库(Native XML DBMS)3.1 概念与…...

Qwen3-TTS声音设计入门:零代码实现中文、英文、日语语音合成
Qwen3-TTS声音设计入门:零代码实现中文、英文、日语语音合成 1. 为什么选择Qwen3-TTS进行语音合成 语音合成技术已经发展了几十年,但大多数工具要么需要复杂的参数调整,要么生成的声音机械感明显。Qwen3-TTS-12Hz-1.7B-VoiceDesign的出现改…...

UE5 Nanite 虚拟化几何体与 Lumen 全局光照
虚幻引擎5(UE5)的Nanite虚拟化几何体与Lumen全局光照技术,彻底改变了实时渲染的边界。这两项核心技术不仅让开发者能够创建电影级画质的3A级游戏,还大幅降低了高性能渲染的技术门槛。Nanite通过虚拟化几何体技术,实现了…...

Go语言的sync.RWMutex性能优化
Go语言中的sync.RWMutex是并发编程中常用的读写锁,它在高并发场景下对共享资源的保护至关重要。随着业务规模的扩大,RWMutex的性能瓶颈可能成为系统吞吐量的制约因素。本文将深入探讨如何优化RWMutex的使用,帮助开发者提升程序性能。 **减少…...

Phi-3-mini-4k-instruct-gguf在科研辅助中的应用:论文摘要润色、图表说明生成、基金申请要点提炼
Phi-3-mini-4k-instruct-gguf在科研辅助中的应用:论文摘要润色、图表说明生成、基金申请要点提炼 1. 科研写作的痛点与解决方案 科研工作者在日常工作中常常面临三大写作挑战:论文摘要需要精炼表达、图表说明需要清晰准确、基金申请需要突出亮点。传统…...

《电磁波也会“转圈圈“?极化特性才是雷达识别的“指纹密码“!》思考题解答
思考题 1:为什么圆极化天线接收相反旋向的圆极化波时,理论损耗是 3dB 而不是无穷大?解答:这个问题需要澄清一个常见的误解。理想情况下,相反旋向的圆极化是完全正交的,理论损耗应为无穷大(完全接…...

IEEE1588v2深度解析:PTP路径时延测量的两种机制对比与应用场景
1. IEEE1588v2与PTP协议基础扫盲 第一次接触IEEE1588v2协议时,我被满屏的"主时钟"、"从时钟"、"透明时钟"这些术语绕得头晕。后来在工业自动化项目里实际调试设备同步时才发现,这套协议就像个隐形的指挥家,让…...

HarmonyOS 6学习:短时效权限与无感相册保存
在HarmonyOS应用开发中,实现内容分享到相册是一个常见需求。无论是保存生成的图片、用户截图,还是应用内的重要信息快照,将其写入设备相册是完成分享闭环的关键一步。然而,传统的保存方案面临一个核心矛盾:用户体验与系…...

Windows平台下基于CMake与VS2022的SOEM EtherCAT主站开发环境搭建指南
1. 环境准备:工欲善其事必先利其器 在Windows下玩转EtherCAT主站开发,首先得把工具链配齐。我当年第一次搭环境时,光是找齐这些工具就花了半天时间,现在把踩坑经验一次性打包给你。 必备三件套: Visual Studio 2022&am…...

VSCode Colab扩展挂载Google Drive失败?别急,这3个替代方案帮你搞定文件传输
VSCode Colab扩展挂载Google Drive失败?3种高效替代方案详解 当你在VSCode中使用Colab扩展时,是否遇到过无法挂载Google Drive的困扰?这个问题确实让许多依赖云端存储的开发者和数据科学家感到头疼。本文将深入分析问题根源,并提供…...

GPU算力适配优化:Pixel Epic智识终端在A10/A100/V100上的部署差异
GPU算力适配优化:Pixel Epic智识终端在A10/A100/V100上的部署差异 1. 引言:当像素冒险遇上GPU算力 Pixel Epic智识终端作为一款融合游戏化体验与专业研究功能的创新工具,其核心的AgentCPM-Report大模型对GPU算力有着独特需求。不同型号的NV…...