C++ 的 pair 和 tuple
1 std::pair
1.1 C++ 98 的 std::pair
1.1.1 std::pair 的构造
C++ 的二元组 std::pair<> 在 C++ 98 标准中就存在了,其定义如下:
template<class T1, class T2> struct pair;
std::pair<> 是个类模板,它有两个成员:first 和 second,类型分别是模板参数指定的 T1 和 T2。可以用以下几种方法构造 std::pair<> 类型的变量(对象实例):
std::pair<int, double> ap1; //默认的构造函数
std::pair<int, double> ap2(5,2.8);
std::pair<int, double> ap3(ap2); //拷贝构造函数
ap1 = std::make_pair(6, 7.2); //使用 make_pair函数
std::pair<int, std::string> p4{5, "ak47"}; //C++ 11 初始化列表
std::pair ap5(5, "ak47"); //C++ 17 推断指示语法,将在 1.3 节介绍
1.1.2 赋值与转换
对 std::pair<> 的访问也很简单,直接操作它的两个成员:
std::pair<int, double> ap(5,2.8);
std::cout << ap.first << ", " << ap.second;
ap.first = 42;
如果你的数据中有两个数据耦合比较紧密,经常需要在一起成对出现,而你又不想额外定义一个 struct 的时候,可以考虑使用 std::pair<>。另外,std::pair<> 也可用于函数返回值的类型,这样就可以用一个 return 语句返回两个值。
对于 C++ 来说,std::pair<char, int> 与 std::pair<int, char> 是两个完全不同的类型,它们之间的差别就像 std::string 和 std::vector 的差别一样大。一般来说,两个不同类型的 std::pair<> 变量是不能互相赋值的,但是如果两个 std::pair<> 变量对应的 first 和 second 属性能够对应进行隐式类型转换,则这样的赋值是允许的,比如:
std::pair<char, int> p1('A', 4);
std::pair<int, double> p2 = p1; //OK,隐式转换char -> int, int -> double
除了 C++ 内建的隐式转换,通过自定义构造函数进行的隐式转换也是可以的,比如:
struct FooTest {FooTest(int a){ value = std::format("{}", a); }std::string value;
};std::pair<char, int> p1('A', 4);
std::pair<int, FooTest> p2 = p1; //OK, FooTest(int a) 构造函数完成隐式转换
1.1.3 比较
两个 std::pair<> 变量可以互相比较大小,比较的原则就是先比较 first 属性,如果 first 属性的值相等(按照严格弱序比较)则继续比较 second 属性的值,来看个比较的例子:
std::pair<int, std::string> p1(5, "ak47");
std::pair<int, std::string> p2(5, "ak57");assert(p1 < p2); //5==5,但是 "ak47" < "ak57"
1.2 C++ 11 和 C++ 14 的改进
C++ 11 对 std::pair<> 进行了一些扩展,增加了一个成员函数 swap(),用于和另一个同类型的 std::pair<> 变量交换内容,比如:
std::pair<int, std::string> p1(42, "Hello");
std::pair<int, std::string> p2;
p2.swap(p1);
assert(p2.first == 42);
assert(p1.first == 0);
和其他类型一样,C++ 11 全局的 std::swap() 函数也支持 std::pair<> ,上面的交换代码也可以这样写:
std::swap(p1, p2);
C++ 11 提供的 std::get<> 函数也支持 std::pair<>,可以通过索引(0 或 1)获取一个 std::pair<> 变量的内容,C++ 14 又进行了补充,即可以根据类型匹配获取一个 std::pair<> 变量的内容,比如:
std::pair<int, std::string> p1(42, "Hello");assert(std::get<0>(p1) == std::get<int>(p1));
assert(std::get<1>(p1) == std::get<std::string>(p1));
需要注意,类型匹配的方式只适用于两个不同类型的数据组成的 pair。
此外,一些用于 tuple 类型的操作也可以用于 std::pair<>,比如在编译期获取 std::tuple<> 类型中元素个数的 std::tuple_size,还有在编译期获取 std::tuple<> 类型中每个位置的元素类型的 std::tuple_element<N,T> 等等。对于 std::pair<> 来说,std::tuple_size 得到的值固定是 2,来看个例子:
std::cout << std::tuple_size<std::pair<int, std::string>>::value; //输出 2std::tuple_element<0, std::pair<int, double>>::type a; //变量 a 的类型是 int
这两个方法配合,可以在编译期决断一些事情,比如这个例子:
template<class T>
void Test(const T& t) {int a[std::tuple_size<T>::value] = { 0 }; //定义数组typename std::tuple_element<0, T>::type myValue;myValue = t.first;
}std::pair<int, std::string> p1(5, "ak47");
Test(p1); //此时 myValue 是 int 类型
Test(std::make_pair('A', 4)); //此时 myValue 是 char 类型
1.3 C++ 17 的推断指引
C++ 17 引入了推断指引(Deduction Guides)语法,当然,std::pair<> 也支持推断指引。没有推断指引的时候,构造一个 std::pair <>的对象实例需要指定具体的类型,也就是 std::pair<> 的两个模板参数,就是这样:
std::pair<int, std::string> p1(5, "ak47");
有了推断指引语法之后,代码就可以简化成这个样子:
std::pair p1(5, "ak47");
因为编译器能够从构造 p1 的两个参数中推断出它们的类型,所以就不需要显示指定具体的类型了。推断指引是个好东西,能少敲几次键盘,节省体力。
2 std::tuple
std::tuple 元组是 C++ 11 提供的标准库扩展,利用扩展的参数包语法,std::tuple 实现了对任意个数的非同质元素的聚合。元组是个好东西,有了它可以代替很多琐碎的、毫无价值的传统数据结构(struct)定义。同时,它还支持右值和移动语义,作为参数或返回值传递的时候,比某些构造不良的 struct 具有更好的效率。
2.1 std::tuple 的语法
2.1.1 std::tuple 的构造
std::tuple<> 是个模板类型,其定义如下:
template< class... Types >
class tuple;
class… Types 是参数包语法,Types 就是具体的类型列表。构造 std::tuple<> 对象实例可以借助于构造函数,也可以使用 std::make_tuple() 方法:
std::tuple<int, std::string, double> t1; //默认构造函数
std::tuple<int, std::string, double> t2 = {42, "hello", 2.7};
std::tuple<int, std::string, double> t3{ 42, "hello", 2.7 }; // C++ 11 初始化列表
std::tuple<int, std::string, double> t4(42, "hello", 2.7); //拷贝构造
t1 = t4;
std::tuple<int, std::string, double> t5 = std::make_tuple(42, "hello", 2.7); //右值拷贝构造(move)
auto t5 = std::make_tuple(42, "hello", 2.7); //等价于上一行
std::tuple t6(42, "hello", 2.7); //C++ 17 的推断指示语法,将在 2.2 节介绍
元组中可以使用引用类型,在构造元组的时候指定引用绑定的对象即可,绑定引用对象时可以使用 std::ref,也可以不使用:
int value = 3;
std::tuple<int&, std::string, double> t9(std::ref(value), "hello", 2.7);
//std::tuple<int&, std::string, double> t9(value, "hello", 2.7); 效果一样
std::get<0>(t9) = 4;
std::cout << "value=" << value << ", t9[0]=" << std::get<0>(t9) << std::endl; //4,4
需要注意的是,尽管一些过时的资料中提到 std::tuple<> 采用链式结构存放每个元素的值,但是实际情况并不是这样的。无论 GCC 还是 Visual C++,对元组的存储都是在内存中连续存放的,并且每个同类型的元组使用的内存大小是一样的。以 Visual C++ 为例,元组变量在内存中按照类型列表的倒序方式连续存储在一个内存块中,当然,如果一个对象中使用了指针属性,元组只存储这个对象的内容(包含指针),对象指针属性指向的内容则由对象自己负责存储和释放。
2.1.2 赋值和转换
std::tuple<> 的内部实现是借助于模板的递归推导机制做的,所以无法像 std::pair<> 那样提供成员属性用于访问元组内的各个元素,但是可以借助于同样模板化的 std::get() 方法访问和修改各个元素的值。来看下面的代码:
std::tuple<int, std::string, double> t1(42, "hello", 2.7);
std::cout << std::get<0>(t1); //输出 42
std::get<1>(t1) = "NiHao";
std::cout << std::get<1>(t1); //输出 NiHao
注意,std::get() 中的模板参数 N 不支持动态绑定,即这样写代码是无法编译的:
std::tuple<int, std::string, double> t1(42, "hello", 2.7); for (int i = 0; i < 3; i++)std::cout << i + 1 << ": " << std::get<i>(t1) << std::endl; // 编译错误
当然,可以使用 std::tuple_size 和 std::tuple_element<N,T> 在编译期获得元素的个数和元组各个元素的类型:
// 以下两行代码等价,都输出 3
std::cout << std::tuple_size<std::tuple<int, std::string, double>>::value << std::endl;
std::cout << std::tuple_size<std::tuple<int, std::string, double>>() << std::endl;std::tuple<int, std::string, double> t1(42, "hello", 2.7);
std::cout << std::tuple_size<decltype(t1)>::value << std::endl; //使用 decltypestd::tuple_element<2, std::tuple_size<std::tuple<int, std::string, double>>::type a; //double 类型
std::tuple_element<2, std::tuple_size<decltype(t1)>::type b; //double 类型
std::tuple<> 同样提供了 swap() 方法用于和另一个同类型(或可隐式转换)的 std::tuple<> 对象实例交换内容,当然全局的 std::swap() 方法也支持 std::tuple<>:
std::tuple<int, std::string, double> t1;
std::tuple<int, std::string, double> t2 = {42, "hello", 2.7};t1.swap(t2); //效果与 std::swap(t1, t2); 一样
一般来说,两个不同类型的元组变量是不可以赋值的,但是如果对应位置的元素类型可以隐式转换,那么赋值是可以接受的,比如:
std::tuple<char, double> t16('A', 2.7);
std::tuple<double, std::string> t17 = t16; //错误,无法赋值
std::tuple<int, double> t17 = t16; //OK, char 可以隐式转换成 int
如果元组中的元素类型支持通过构造函数隐式转换,赋值也是可以的,请参考 1.1.2 节 FooTest 的例子,这里不再赘述。
2.1.3 tie 和 ignore
除了使用 std::get() 访问元素的元素,还可以使用 std::tie() 方法将元组内的元素与某个具名的变量关联,将元组的内容传递给具名变量。来看个例子:
std::tuple<int, std::string, double> t1(3, "Kitty", 2.7); int age;
std::string name;
double weight;
std::tie(age, name, weight) = t1;std::cout << "Name: " << name << ", Age: " << age << ", Weight: " << weight << " Kg(s)" << std::endl;age = 10; //修改 age 的值不影响 t1
显然,使用具名变量可以提高代码的可读性,毕竟,一个有具体名字的变量比生冷的 std::get<0> 要强多了。但是需要注意,std::tie() 的捆绑效果是单向的,并且是一次性的,std::tie() 之后再修改具名变量的值不会影响关联的元组的值。
如果关联到的时候对某个元素不感兴趣,可以使用 std::ignore 占位符,比如:
std::tuple<int, std::string, double> t1(3, "Kitty", 2.7); int age;
double weight;
std::tie(age, std::ignore, weight) = t1; //只关心年龄和体重,不关心名字
2.1.4 拼接元组
可以使用 std::tuple_cat() 拼接两个元组变量,得到一个更大的元组,看看这个例子:
std::tuple<int, std::string, double> t1(3, "Kitty", 2.7); auto t2 = std::tuple_cat(t1, std::make_tuple("Garfield", "United Kingdom"));assert(std::tuple_size<decltype(t2)>::value == 5);
拼接后 t2 有五个元素,分别是 (3, “Kitty”, 2.7, “Garfield”, “United Kingdom”)。
2.1.5 std::forward_as_tuple()
2.1.1 节提到了在定义 std::tuple<> 的时候可以使用左值引用类型的元组元素,既然能使用左值引用,当然也可以使用右值引用类型。std::forward_as_tuple() 的作用是返回一个 std::tuple<> 对象,其元素类型是给定的函数参数类型对应的右值引用类型。这句话有点难以理解,用这行代码做例子来理解这个函数:
std::tuple<int&&, FooTest&&> k = std::forward_as_tuple(42, FooTest(5));
当我们传递两个值给 std::forward_as_tuple() 方法时,它的返回值类型是对应的 std::tuple<int&&, FooTest&&>。这个方法存在意义是什么呢?当然是为了参数传递的效率。我们用 std::make_tuple() 跟他做个对比,在对比之前,先看看 FooTest 的实现,我们增加了很多打印信息跟踪这个对象实例的构造和销毁:
struct FooTest {FooTest(const FooTest& f){ std::cout << "FooTest(const FooTest&)" << std::endl; }FooTest(FooTest&& f){ std::cout << "FooTest(FooTest&&)" << std::endl; }FooTest(){ std::cout << "FooTest()" << std::endl; }FooTest(int a){ std::cout << "FooTest(int)" << std::endl; }~FooTest(){ std::cout << "~FooTest()" << std::endl; }
};
先来看看 std::make_tuple() 的执行情况,对于这行代码:
auto kk = std::make_tuple(42, FooTest(5));
打印输出结果如下,执行了两次对象的构造和销毁,其中一次右值构造是因为构造函数返回时产生了一个将亡值临时对象:
FooTest(int)
FooTest(FooTest&&)
~FooTest()
~FooTest()
好了,现在看看 std::forward_as_tuple() 是什么情况,同样的代码:
auto kk = std::forward_as_tuple(42, FooTest(5));
对应的打印结果是:
FooTest(int)
~FooTest()
看到了吗?只在 FooTest(5) 调用时产生了一次 FooTest 对象实例的构造,随后这个对象实例被转发出来,最后随着 kk 销毁的时候一起销毁。现在明白这个方法为什么叫 forward_as_tuple() 了吧?因为它的作用和 std::forward() 类似,具有相同的语意。
由此可见,C++ 对效率的追求到了近乎偏执的地步。类似的右值转发对效率提升是非常显著的,如果有恰当设计的函数配合,右值对象可以“一镜到底”:
void print_Tuple(std::tuple<int&&, FooTest&&> pack)
{ std::cout << std::get<0>(pack) << std::endl; }print_Tuple(std::forward_as_tuple(42, FooTest(5)));
输出结果是:
FooTest(int)
42
~FooTest()
你想到了吗?
2.2 C++ 17 的改进
2.2.1 推断指引
std::tuple<> 也支持推断指引,像这样繁琐的代码:
std::tuple<int, std::string, double, std::string, std::string> t10(3, "Kitty", 2.7, "Garfield", "United Kingdom");
可以简化为:
std::tuple t1(3, "Kitty", 2.7, "Garfield", "United Kingdom");
你只负责想象,剩下的交给编译器。
2.2.2 结构化绑定
使用 std::tie() 可以将元组内的元素关联到一些具名变量上,提高代码的可读性,但是 std::tie() 的使用并不友好,变量需要提前定义好,写代码很繁琐。C++ 17 引入的结构化绑定语法也适用于 std::tuple<>,使用结构化绑定可以简化代码的实现,2.1.3 节的例子可以这样简单地实现:
std::tuple<int, std::string, double> t1(3, "Kitty", 2.7); auto [age, name, weight] = t1; //无需事先声明 age, name 和 weight
前面提到过,std::tie() 关联具名变量是单向的一次性动作,结构化绑定虽然也是一次性动作,但是可以通过引用绑定方式修改被关联对象实例的值,比如:
std::tuple<int, std::string, double> t1(3, "Kitty", 2.7); auto& [age, name, weight] = t1; //引用绑定
age = 4; //同时修改了 t1 的值
assert(std::get<0>(t1) == 4);
除此之外,std::tie() 还有一个局限,那就是它只能用于关联到一个左值类型对象实例,不能用于右值,但是结构化绑定可以,来看一个函数返回值的例子:
std::tuple<int, std::string, double> GetInfo(const std::string& name) {return std::make_tuple(42, "Simon", 108.2);
}int age;
std::string name;
double weight;
std::tie<age, name, weight> = GetInfo("Kitty"); //错误,函数返回值不是左值auto [aa, nn, ww] = GetInfo("Kitty"); //OK,结构化绑定可以
使用结构化绑定的结果就是 aa、nn 和 ww 分别是对应类型的右值引用类型,没有任何临时对象拷贝的开销,非常 nice。
关注作者的算法专栏
https://blog.csdn.net/orbit/category_10400723.html
关注作者的出版物《算法的乐趣(第二版)》
https://www.ituring.com.cn/book/3180
相关文章:

C++ 的 pair 和 tuple
1 std::pair 1.1 C 98 的 std::pair 1.1.1 std::pair 的构造 C 的二元组 std::pair<> 在 C 98 标准中就存在了,其定义如下: template<class T1, class T2> struct pair;std::pair<> 是个类模板,它有两个成员&#x…...

Zookeeper 集群安装
Zookeeper 集群 主机 IP SoftWare Port OS Myidnode1 192.168.230.128 apache-zookeeper-3.7.1 2181 Centos 7 1 node2 192.168.230.129 apache-zookeeper-3.7.1...

git merge与rebase区别以及实际应用
在 Git 中,merge 和 rebase 是两种将分支的更改合并到一起的常用方法。虽然它们都可以实现类似的目标,但它们的工作方式和效果有所不同。 1. Git Merge 定义:git merge 是将两个分支的历史合并在一起的一种操作。当你执行 git merge 时&…...

kvm虚拟机出现应用程序无法正常启动报0xc0000142错误
场景:我的是window10虚拟机,在运行我的软件的时候,出现0xc0000142错误,原因可能是cpu型号问题,某些虚拟cpu可能没有特定的指令,只需要修改虚拟机配置文件以下参数即可...

Redis 安装与 Spring Boot 集成指南
安装 Redis 和将其与 Spring Boot 应用集成是构建高效缓存解决方案的常见步骤。以下是详细的指南,帮助你在本地环境中安装 Redis,并在 Spring Boot 项目中配置和使用它。 1. 安装 Redis Windows 环境 Redis 官方并不直接支持 Windows,但你…...
拿来即用的案例)
Flink集成TDEngine来批处理或流式读取数据进行流批一体化计算(Flink SQL)拿来即用的案例
Flink 以其流批一体化的编程模型而备受青睐。它支持高吞吐、低延迟的实时流计算,同时在批处理方面也表现出色。Flink 提供了丰富的 API,如 DataStream API 和 DataSet API,方便开发者进行数据处理操作,包括转换、聚合、连接等,使得开发者能够轻松构建复杂的数据处理逻辑。…...

【STM32】利用SysTick定时器定时1s
1.SysTick简单介绍 SysTick定时器是一个24位的倒计数定时器,当计数到0时,将从RELOAD寄存器中自动重装载定时初值,开始新一轮计数。 SysTick定时器用于在每隔一定的时间产生一个中断,即使在系统睡眠模式下也能工作。 关于SysTic…...

Python中的format格式化、填充与对齐、数字格式化方式
文章目录 一、format语法二、format格式化的用法2.1、按照先后顺序替换{}2.2、按照索引进行匹配替换{0}2.3、按关键字索引进行匹配替换2.4、通过列表索引格式化字符串2.5、使用元组2.6、通过字典设置格式化字符串2.7、混合使用 三、字符串填充与对齐3.1、左对齐及填充3.2、右对…...
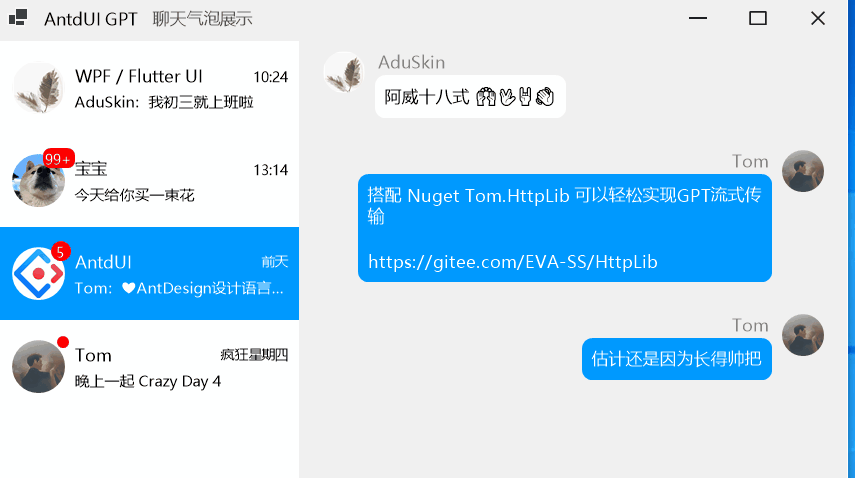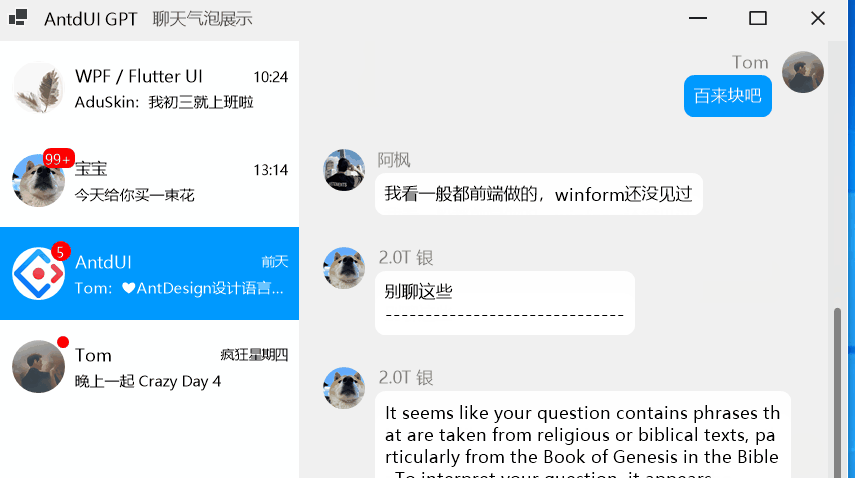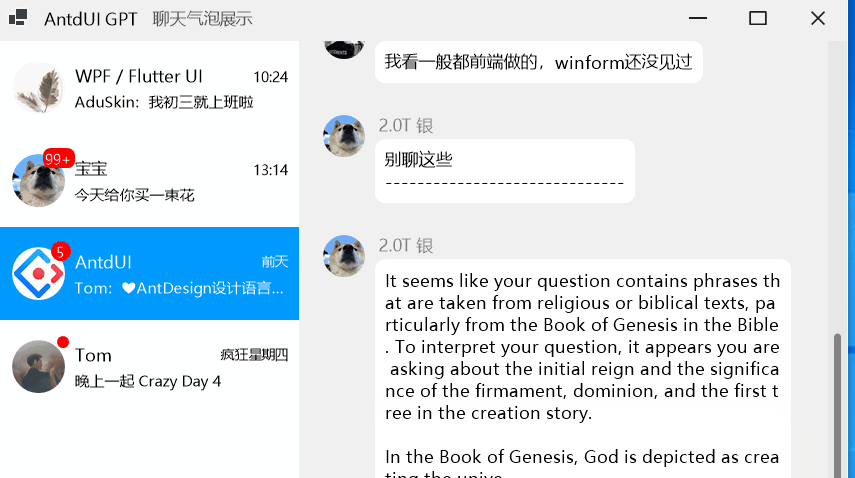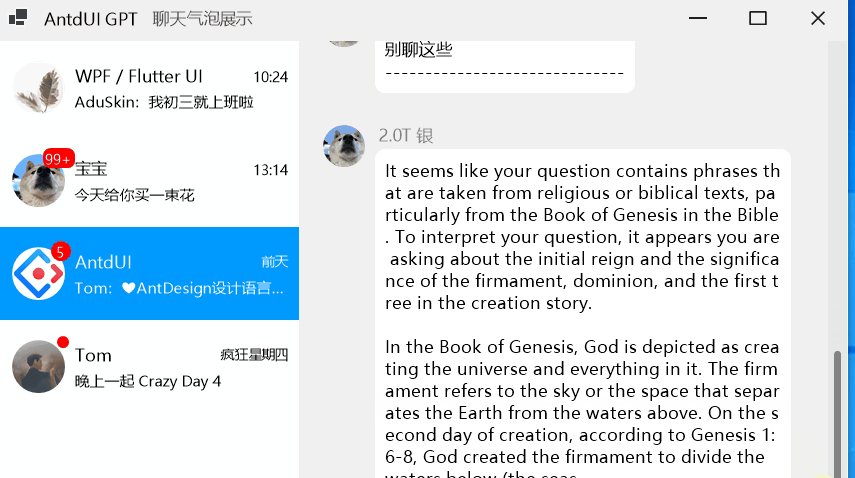
winform第三方界面开源库AntdUI的使用教程保姆级环境设置篇
1. AntdUI 1.1. 导入项目 1.1.1. 首先新建一个空白的基于.net的Winfrom项目1.1.2. 复制AntdUI中src目录到我们的解决方案下面1.1.3. 解决方案下添加现有项目1.1.4. 添加项目引用 1.2. 编写代码 1.2.1. 改写Form1类,让其继承自public partial class Form1 : AntdUI.W…...

如何使用Yarn Workspaces实现Monorepo模式在一个仓库中管理多个项目
Yarn Workspaces是Yarn提供的一种依赖管理机制,它支持在单个代码仓库中管理多个包的依赖。这种机制非常适合需要多个相互依赖的包的项目,能够减少重复依赖,加快依赖安装速度,并简化依赖管理。下面将详细介绍如何使用Yarn Workspac…...

SpringCloud系列教程:微服务的未来(十一)服务注册、服务发现、OpenFeign快速入门
本篇博客将通过实例演示如何在 Spring Cloud 中使用 Nacos 实现服务注册与发现,并使用 OpenFeign 进行服务间调用。你将学到如何搭建一个完整的微服务通信框架,帮助你快速开发可扩展、高效的分布式系统。 目录 前言 服务注册和发现 服务注册 编辑 …...

物联网:七天构建一个闭环的物联网DEMO
我计划用七天的时间, 基于开源物联网平台, 打造一款物联网案例的闭环。 为了增加感观体验,欢迎大家与我保持亲密的沟通。 我们来看一段代码: Slf4j Component public class MqttSendManager {Resourceprivate MqttSendHandler m…...

景联文科技提供高质量多模态数据处理服务,驱动AI新时代
在当今快速发展的AI时代,多模态数据标注成为推动人工智能技术进步的关键环节。景联文科技作为行业领先的AI数据服务提供商,专注于为客户提供高质量、高精度的多模态数据标注服务,涵盖图像、语音、文本、视频及3D点云等多种类型的数据。通过专…...

c#13新特性
C# 13 即 .NET 9 按照计划会在2024年11月发布,目前一些新特性已经定型,让我们来预览一个比较大型比较重要的新特性。 正文 扩展类型 Extension types 在5月份的微软 Build 大会中的 What’s new in C# 13 会议上,两位大佬花了很长的篇幅来…...

LeetCode LCP17速算机器人
速算机器人:探索字符指令下的数字变换 在编程的奇妙世界里,我们常常会遇到各种有趣的算法问题,这些问题不仅考验我们的逻辑思维,还能让我们感受到编程解决实际问题的魅力。今天,就让我们一同探讨一个关于速算机器人的…...

杭州铭师堂的云原生升级实践
作者:升学e网通研发部基建团队 公司介绍 杭州铭师堂,是一个致力于为人的全面发展而服务的在线教育品牌。杭州铭师堂秉持“用互联网改变教育,让中国人都有好书读”的使命,致力于用“互联网教育”的科技手段让更多的孩子都能享有优…...

计算机网络之---MAC协议
MAC协议的作用 在数据链路层中,MAC(媒介访问控制)协议负责控制设备如何访问共享的通信介质(如以太网、无线电波等),确保在多台设备共享同一传输媒介时能够有效地进行数据传输,避免冲突、控制流…...

微服务面试相关
Spring Cloud Spring Cloud五大组件 注册中心:Eureka、Nacos Ribbon负载均衡、负载均衡策略、自定义负载均衡 Ribbon负载均衡流程 Ribbon负载均衡策略 自定义负载均衡 服务雪崩、熔断降级 微服务监控-skywalking 业务相关 微服务限流(令牌桶、漏桶算法…...

Google发布图像生成新工具Whisk:无需复杂提示词,使用图像和人工智能将想法可视化并重新混合
Whisk 是 Google Labs 的一项新实验,可使用图像进行快速而有趣的创作过程。Whisk不会生成带有长篇详细文本提示的图像,而是使用图像进行提示。只需拖入图像,即可开始创建。 whisk总结如下: Whisk 是 Google 实验室最新的生成图像实…...

docker pull(拉取镜像)的时候,无法下载或者卡在Waiting的解决方法
docker pull的时候,卡在Waiting的解决方法 一般情况(大部分镜像都可以拉取)更换镜像源 进一步(如es等拉取不到)在镜像同步站搜索详细步骤 还可以在挂载的时候,让其下载对应的版本 一般情况(大部…...

STM32按键状态机:从消抖到复杂事件处理的嵌入式编程范式
1. 项目概述:从“按键抖动”到“状态机思维”的跨越在嵌入式开发,尤其是基于STM32这类MCU的项目中,按键处理是几乎每个项目都绕不开的基础功能。很多新手朋友在拿到开发板,点亮第一个LED后,下一步往往就是尝试用按键来…...

HC7251晨芯阳科技内置MOS开关降压型LED恒流驱动器
HC7251是一款内置60V功率MOS 高效率、高精度的开关降压型大功率LED 恒流驱动芯片。HC7251采用固定关断时间的峰值电流控制方式,关断时间可通过外部电容进行调节,工作频率可根据用户要求而改变。HC7251通过调节外置的电流采样电阻,能控制高亮度…...
)
Git提交者信息填错了?别慌,手把手教你用config命令修正(全局/本地/取消设置全攻略)
Git提交者信息填错了?别慌,手把手教你用config命令修正(全局/本地/取消设置全攻略) 刚提交完代码到Git仓库,突然发现用户名和邮箱填错了?别担心,这种情况几乎每个开发者都遇到过。提交者信息错误…...

终极AI自瞄系统:5分钟搭建你的智能游戏瞄准助手
终极AI自瞄系统:5分钟搭建你的智能游戏瞄准助手 【免费下载链接】RookieAI_yolov8 基于yolov8实现的AI自瞄项目 AI self-aiming project based on yolov8 项目地址: https://gitcode.com/gh_mirrors/ro/RookieAI_yolov8 还在为游戏中的精准瞄准而烦恼吗&…...
)
告别CentOS!Debian 11 + VMware 保姆级教程:搞定那些只支持国产系统的Linux客户端(以aTrust为例)
Debian 11 VMware 全栈解决方案:无缝运行国产Linux客户端软件 在开源世界的版图中,CentOS曾经是企业级Linux的代名词,但随着Red Hat战略调整和CentOS Stream的转型,许多传统解决方案正在面临前所未有的兼容性挑战。特别是在需要对…...

不只是连线:深入理解模拟版图中电阻的‘Segment’与‘M’参数对实际阻值的影响
不只是连线:深入理解模拟版图中电阻的‘Segment’与‘M’参数对实际阻值的影响 在模拟集成电路设计中,电阻作为最基本的无源元件之一,其版图实现往往被初学者视为简单的金属连线问题。然而,当设计从原理图转向物理实现时ÿ…...

小白程序员必看:收藏这份AI大模型学习指南,抢占高薪新赛道!
文章指出,随着AI技术的飞速发展,传统后端开发面临挑战,而懂AI的复合型人才成为稀缺资源。学校教育与企业需求存在错位,导致大学生毕业时所学与企业所需不符。AI智能应用开发、大模型开发等方向成为高薪热门领域,懂AI的…...

RK3588/RK3568嵌入式开发:从通用镜像到定制分区镜像的完整实践指南
1. 项目概述:从“通用”到“专属”的镜像进化最近在折腾RK3588和RK3568平台时,我发现了一个挺有意思的升级点:开发板和核心板的镜像支持定制分区了。这听起来可能有点技术化,但说白了,就是以前我们拿到的系统镜像&…...
监听FreeSWITCH事件并自动录音)
实战指南:用Python ESL(greenswitch库)监听FreeSWITCH事件并自动录音
实战指南:用Python ESL(greenswitch库)监听FreeSWITCH事件并自动录音 在通信系统开发中,FreeSWITCH作为强大的开源软交换平台,其Event Socket接口为开发者提供了深度集成的可能。本文将聚焦如何利用Python生态中的gre…...

测试TVS:SP0503BAHTG
简 介: 本文测试了SP0503BAHTG三通道TVS二极管阵列的特性。通过设计测试电路板,测量了该器件对1kHz正弦波的限幅效果,测得反向导通电压约-0.8V,顶部饱和电压6.3V。在1MHz高频测试中观察到快速响应特性,通过矩形波上升沿…...