Java 实现 Elasticsearch 查询当前索引全部数据
Java 实现 Elasticsearch 查询当前索引全部数据
- 需求背景
- 通常情况
- Java 实现查询 Elasticsearch 全部数据
- 写在最后
需求背景
通常情况下,Elasticsearch 为了提高查询效率,对于不指定分页查询条数的查询语句,默认会返回10条数据。那么这就会有一种情况,当你需要一次性返回 Elasticsearch 索引中的全部数据时,就无法实现了。这个时候你可能会考虑,比如我将每页取值的size 设置的很大,这样或许可以解决问题,但是数据量的上升你是无法控制的,最终会有一天数据量会超过你此时设置的最大 size,那么这就是一个雷点。并且如果一次查询很大量数据的话,即便是 Elasticsearch 查询效率高的索引结构可能也会导致查询时长较长,甚至响应超时。那么是否有一种查询效率高,且相对灵活的方式可以查询 Elasticsearch 的索引中全部数据呢?答案是:有的。
通常情况
下面来看一下在不设置 size 大小的情况下,执行 Elasticsearch 查询语句默认返回几条数据,结果是默认返回 10条。执行如下查询命令
GET crm_meiqia_conversation/_search
返回结果如图,这时我们看到返回了 10 条数据

此时如果你需要查询更多数据的话,你就可以通过指定 size 大小来查询更多数据,比如执行如下命令
GET crm_meiqia_conversation/_search
{"size":20
}
执行查询语句后返回的结果如图所示,索引查询会返回你指定 size 大小的数据

很明显,在一些特殊的场景下,想要一次性查询指定条件下的所有数据改如何操作呢,下面就来基于 Java 实现查询指定条件下的所有数据操作。
Java 实现查询 Elasticsearch 全部数据
在具体讲解如何通过 Java 实现查询 Elasticsearch 全部数据之前,我们可以先来看一下我已经实现之后的查询效果。这里你可以看到滚动州已经变得很小,这就是因为我查询出了指定条件下的全部数据导致的,而不是默认的 10 条数据

而如果没有实现查询指定索引指定条件下的全部数据时,看到的效果应该是这样的,默认只能一次性查询 10 条数据返回

下面再来讲一下如何通过 Java 实现 查询 es 全部数据,我们由浅入深来讲解,首先来看一下默认查询 es 10条数据的代码,Java 通过如下 SearchRequestBuilder searchRequest = client.prepareSearch(indexProperties.getMeiqiaConversationIndex()).setTypes(indexProperties.getMeiqiaConversationType()).setQuery(query); 构造查询 es 索引代码,这种情况没有设置 size 大小,默认的话就是查询指定索引下 10条数据,完整代码如下:
public AjaxResult getMeiqiaUidList(MeiqiaConversation meiqiaConversation) {BoolQueryBuilder query = QueryBuilders.boolQuery();BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();//会话idLong convId = meiqiaConversation.getConvId();if (convId != null) {boolQuery.filter(QueryBuilders.termQuery("convId",convId));}//会话日期String convStartDate = (String) meiqiaConversation.getParams().get("convStartDate");String convEndDate = (String) meiqiaConversation.getParams().get("convEndDate");if (StringUtils.isNotEmpty(convStartDate)) {Date date = DateUtils.stringToDate(convStartDate, DateUtils.SDF_YMDHMS);boolQuery.filter(QueryBuilders.rangeQuery("convStartDate").gte(date.getTime()));}if (StringUtil.isNotEmptyString(convEndDate)) {Date date = DateUtils.stringToDate(convEndDate, DateUtils.SDF_YMDHMS);boolQuery.filter(QueryBuilders.rangeQuery("convEndDate").lte(date.getTime()));}//会话日期Date convStartDate2 = meiqiaConversation.getConvStartDate();Date convEndDate2 = meiqiaConversation.getConvEndDate();if (Objects.nonNull(convStartDate2)) {boolQuery.filter(QueryBuilders.rangeQuery("convStartDate").gte(convStartDate2.getTime()));}if (Objects.nonNull(convEndDate2)) {boolQuery.filter(QueryBuilders.rangeQuery("convEndDate").lte(convEndDate2.getTime()));}//学号String uid = (String) meiqiaConversation.getParams().get("uid");if (StringUtils.isNotEmpty(uid)) {if (uid.contains("#")) {String replace = uid.replace("#", "");boolQuery.filter(QueryBuilders.termQuery("clientInfo.name",replace));}else {boolQuery.filter(QueryBuilders.termQuery("clientInfo.uid",uid));}}//客服工号String agentId = (String) meiqiaConversation.getParams().get("agentId");if (StringUtils.isNotEmpty(agentId)) {boolQuery.filter(QueryBuilders.termQuery("agentId",agentId));}// 会话内容String content = (String) meiqiaConversation.getParams().get("content");if (StringUtils.isNotEmpty(content)) {boolQuery.filter(QueryBuilders.matchPhrasePrefixQuery("convContent.content",content));}query.must(boolQuery);// 初始化搜索请求构建器,用于构造搜索请求SearchRequestBuilder searchRequest = client.prepareSearch(indexProperties.getMeiqiaConversationIndex())// 设置搜索的类型.setTypes(indexProperties.getMeiqiaConversationType())// 设置查询条件.setQuery(query);// 使用SearchRequest获取搜索响应SearchResponse searchResponse = searchRequest.get();// 初始化存储所有搜索结果的列表List<EsMeiqiaConversation> rows = new ArrayList<>();// 格式化搜索响应中的数据,并添加到rows列表中List<EsMeiqiaConversation> list1 = formatMeiqiaDto(searchResponse);rows.addAll(list1);//记录返回的uid nameList<MeiqiaConversation> list = new ArrayList<>();if (CollectionUtils.isNotEmpty(rows)) {//获取 uid nameMap<String, List<EsMeiqiaConversation>> collect = rows.stream().collect(Collectors.groupingBy(EsMeiqiaConversation::getClientUid, Collectors.toList()));Set<String> uids = collect.keySet();for (String u : uids) {MeiqiaConversation conv = new MeiqiaConversation();conv.setUid(u);//同一个uid 对应同一个 nameList<EsMeiqiaConversation> esconv = collect.get(u);String name = esconv.get(0).getClientName();conv.setName(name);list.add(conv);}}return AjaxResult.success(list);}
那么如何实现 一次查询满足条件的全部 es 数据呢,这就需要通过 scroll 实现,在初始化索引查询构造器时通过 SearchRequestBuilder searchRequest = client.prepareSearch(indexProperties.getMeiqiaConversationIndex()).setTypes(indexProperties.getMeiqiaConversationType()).setQuery(query).setSize(100).setScroll(TimeValue.timeValueMinutes(1)); 设置 scroll 参数来实现,同时需要再后续增加再次查询索引逻辑,将 scorllId 循环传递 获取全部数据,最终改造后的获取全部数据的代码如下
public AjaxResult getMeiqiaUidList(MeiqiaConversation meiqiaConversation) {BoolQueryBuilder query = QueryBuilders.boolQuery();BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();//会话idLong convId = meiqiaConversation.getConvId();if (convId != null) {boolQuery.filter(QueryBuilders.termQuery("convId",convId));}//会话日期String convStartDate = (String) meiqiaConversation.getParams().get("convStartDate");String convEndDate = (String) meiqiaConversation.getParams().get("convEndDate");if (StringUtils.isNotEmpty(convStartDate)) {Date date = DateUtils.stringToDate(convStartDate, DateUtils.SDF_YMDHMS);boolQuery.filter(QueryBuilders.rangeQuery("convStartDate").gte(date.getTime()));}if (StringUtil.isNotEmptyString(convEndDate)) {Date date = DateUtils.stringToDate(convEndDate, DateUtils.SDF_YMDHMS);boolQuery.filter(QueryBuilders.rangeQuery("convEndDate").lte(date.getTime()));}//会话日期Date convStartDate2 = meiqiaConversation.getConvStartDate();Date convEndDate2 = meiqiaConversation.getConvEndDate();if (Objects.nonNull(convStartDate2)) {boolQuery.filter(QueryBuilders.rangeQuery("convStartDate").gte(convStartDate2.getTime()));}if (Objects.nonNull(convEndDate2)) {boolQuery.filter(QueryBuilders.rangeQuery("convEndDate").lte(convEndDate2.getTime()));}//学号String uid = (String) meiqiaConversation.getParams().get("uid");if (StringUtils.isNotEmpty(uid)) {if (uid.contains("#")) {String replace = uid.replace("#", "");boolQuery.filter(QueryBuilders.termQuery("clientInfo.name",replace));}else {boolQuery.filter(QueryBuilders.termQuery("clientInfo.uid",uid));}}//客服工号String agentId = (String) meiqiaConversation.getParams().get("agentId");if (StringUtils.isNotEmpty(agentId)) {boolQuery.filter(QueryBuilders.termQuery("agentId",agentId));}// 会话内容String content = (String) meiqiaConversation.getParams().get("content");if (StringUtils.isNotEmpty(content)) {boolQuery.filter(QueryBuilders.matchPhrasePrefixQuery("convContent.content",content));}query.must(boolQuery);// 初始化搜索请求构建器,用于构造搜索请求SearchRequestBuilder searchRequest = client.prepareSearch(indexProperties.getMeiqiaConversationIndex())// 设置搜索的类型.setTypes(indexProperties.getMeiqiaConversationType())// 设置查询条件.setQuery(query)// 设置返回结果的数量为100.setSize(100)// 设置滚动查询的时间间隔为1分钟.setScroll(TimeValue.timeValueMinutes(1));// 使用SearchRequest获取搜索响应SearchResponse searchResponse = searchRequest.get();// 初始化存储所有搜索结果的列表List<EsMeiqiaConversation> rows = new ArrayList<>();// 格式化搜索响应中的数据,并添加到rows列表中List<EsMeiqiaConversation> list1 = formatMeiqiaDto(searchResponse);rows.addAll(list1);// 使用Scroll方式遍历所有搜索结果do {// 准备下一次Scroll搜索,设置滚动时间为1分钟// 将scorllId循环传递 获取全部数据searchResponse = client.prepareSearchScroll(searchResponse.getScrollId()).setScroll(TimeValue.timeValueMinutes(1)).execute().actionGet();// 格式化新一批搜索结果,并添加到rows列表中List<EsMeiqiaConversation> list = formatMeiqiaDto(searchResponse);if (CollectionUtils.isNotEmpty(list)) {rows.addAll(list);}// 当搜索结果为空时,结束循环// 当searchHits的数组为空的时候结束循环,至此数据全部读取完毕} while (searchResponse.getHits().getHits().length != 0);// 创建一个ClearScrollRequest实例,用于清除滚动查询的会话。ClearScrollRequest clearScrollRequest = new ClearScrollRequest();// 将上一次查询返回的滚动ID添加到请求中,以便清除这个特定的会话。// 这是必要的,因为ClearScrollRequest需要至少一个滚动ID才能执行清除操作。clearScrollRequest.addScrollId(searchResponse.getScrollId());// 发送ClearScroll请求并获取操作的结果。// 这一步是必需的,因为它实际执行了清除滚动会话的操作,并允许我们处理结果或任何异常。client.clearScroll(clearScrollRequest).actionGet();//记录返回的uid nameList<MeiqiaConversation> list = new ArrayList<>();if (CollectionUtils.isNotEmpty(rows)) {//获取 uid nameMap<String, List<EsMeiqiaConversation>> collect = rows.stream().collect(Collectors.groupingBy(EsMeiqiaConversation::getClientUid, Collectors.toList()));Set<String> uids = collect.keySet();for (String u : uids) {MeiqiaConversation conv = new MeiqiaConversation();conv.setUid(u);//同一个uid 对应同一个 nameList<EsMeiqiaConversation> esconv = collect.get(u);String name = esconv.get(0).getClientName();conv.setName(name);list.add(conv);}}return AjaxResult.success(list);}
那么这段的核心代码是增加了滚动查询数据的操作,如图所示

同时再执行循环查询时将 scrollId 循环传递,并将查询结果 addAll 到当前list 的集合中

查询结束之后,最后是清除滚动会话的操作
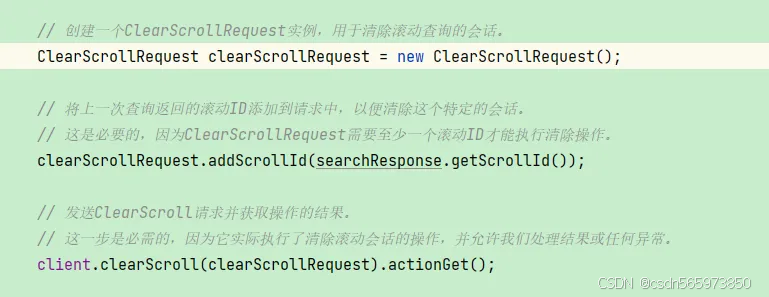
到这里关于 Java 实现 es 查询指定条件下的全部数据操作就结束了,整个操作过程比较容易理解,增加了 es 滚动查询 scroll 操作来实现查询 es 全部数据。
写在最后
最后想要说的是,对于 es 查询,通常情况下是不需要一次性查询出当前索引所有条件下的数据的,毕竟数据量比较大,但是也有特殊的场景,这个时候不得不一次性查询出所有的数据,这就需要上文中用到的办法了,希望对大家有帮助。
相关文章:
Java 实现 Elasticsearch 查询当前索引全部数据
Java 实现 Elasticsearch 查询当前索引全部数据 需求背景通常情况Java 实现查询 Elasticsearch 全部数据写在最后 需求背景 通常情况下,Elasticsearch 为了提高查询效率,对于不指定分页查询条数的查询语句,默认会返回10条数据。那么这就会有…...
android刷机
android ota和img包下载地址: https://developers.google.com/android/images?hlzh-cn android启动过程 线刷 格式:ota格式 模式:recovery 优点:方便、简单,刷机方法通用,不会破坏手机底层数据࿰…...

【25考研】西南交通大学计算机复试重点及经验分享!
一、复试内容 上机考试:考试题型为编程上机考试,使用 C 语言,考试时长包括 15 分钟模拟考试和 120 分钟正式考试,考试内容涵盖顺序结构、选择结构、循环结构、数组、指针、字符串处理、函数、递归、结构体、动态存储、链表等知识点…...
将视差图(disparity map)重投影到三维空间中函数reprojectImageTo3D()的使用)
OpenCV相机标定与3D重建(49)将视差图(disparity map)重投影到三维空间中函数reprojectImageTo3D()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将视差图像重投影到3D空间。 cv::reprojectImageTo3D 是 OpenCV 库中的一个函数,用于将视差图(disparity map)…...

学习HTTP Range
HTTP Range 请求 一种通过指定文件字节范围加载部分数据的技术,广泛用于断点续传、流媒体播放、分布式文件系统的数据分片加载等场景。 请求格式-在请求头中使用 Range 字段指定所需的字节范围 Range: bytes0-1023// bytes0-1023:表示请求文件的第 0 …...

大语言模型训练的数据集从哪里来?
继续上篇文章的内容说说大语言模型预训练的数据集从哪里来以及为什么互联网上的数据已经被耗尽这个说法并不专业,再谈谈大语言模型预训练数据集的优化思路。 1. GPT2使用的数据集是WebText,该数据集大概40GB,由OpenAI创建,主要内…...

Webpack和Vite的区别
一、构建速度方面 webpack默认是将所有模块都统一打包成一个js文件,每次修改都会重写构建整个项目,自上而下串行执行,所以会随着项目规模的增大,导致其构建打包速度会越来越慢 vite只会对修改过的模块进行重构,构建速…...

【再谈设计模式】模板方法模式 - 算法骨架的构建者
一、引言 在软件工程、软件开发过程中,我们经常会遇到一些算法或者业务逻辑具有固定的流程步骤,但其中个别步骤的实现可能会因具体情况而有所不同的情况。模板方法设计模式(Template Method Design Pattern)就为解决这类问题提供了…...

Bytebase 3.1.1 - 可定制的快捷访问首页
🚀 新功能 可定制的快捷访问首页。 支持查询 Redis 集群中所有节点。 赋予项目角色时,过期时间可以定义精确到秒级的时间点。 🔔 重大变更 移除 Database 消息里的实例角色信息。调用 GetInstance 或 ListInstanceRoles 以获取实例角色信息…...

Java阶段四04
第4章-第4节 一、知识点 CSRF、token、JWT 二、目标 理解什么是CSRF攻击以及如何防范 理解什么是token 理解什么是JWT 理解session验证和JWT验证的区别 学会使用JWT 三、内容分析 重点 理解什么是CSRF攻击以及如何防范 理解什么是token 理解什么是JWT 理解session验…...

B2C API安全警示:爬虫之外,潜藏更大风险挑战
在数字化时代,B2C(Business-to-Consumer)电子商务模式已成为企业连接消费者、推动业务增长的重要桥梁。而B2C API(应用程序编程接口)作为企业与消费者之间数据交互的桥梁,其安全性更是至关重要。然而&#…...

OCR文字识别—基于PP-OCR模型实现ONNX C++推理部署
概述 PaddleOCR 是一款基于 PaddlePaddle 深度学习平台的开源 OCR 工具。PP-OCR是PaddleOCR自研的实用的超轻量OCR系统。它是一个两阶段的OCR系统,其中文本检测算法选用DB,文本识别算法选用CRNN,并在检测和识别模块之间添加文本方向分类器&a…...

如何播放视频文件
文章目录 1. 概念介绍2. 使用方法2.1 实现步骤2.2 具体细节3. 示例代码4. 内容总结我们在上一章回中介绍了"如何获取文件类型"相关的内容,本章回中将介绍如何播放视频.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 播放视频是我们常用的功能,不过Flutter官方…...

MySQL -- 约束
1. 数据库约束 数据库约束时关系型数据库的一个重要功能,主要的作用是保证数据的有效性,也可以理解为数据的正确性(数据本身是否正确,关联关系是否正确) 人工检查数据的完整性工作量非常大,在数据库中定义一些约束,那么数据在写入数据库的时候,就会帮我们做一些校验.并且约束一…...

php 使用simplexml_load_string转换xml数据格式失败
本文介绍如何使用php函数解析xml数据为数组。 <?php$a <xml><ToUserName><![CDATA[ww8b77afac71336111]]></ToUserName><FromUserName><![CDATA[sys]]></FromUserName><CreateTime>1736328669</CreateTime><Ms…...
net-http-transport 引发的句柄数(协程)泄漏问题
Reference 关于 Golang 中 http.Response.Body 未读取导致连接复用问题的一点研究https://manishrjain.com/must-close-golang-http-responsehttps://www.reddit.com/r/golang/comments/13fphyz/til_go_response_body_must_be_closed_even_if_you/?rdt35002https://medium.co…...

高级软件工程-复习
高级软件工程复习 坐标国科大,下面是老师说的考试重点。 Ruby编程语言的一些特征需要了解要能读得懂Ruby程序Git的基本命令操作知道Rails的MVC工作机理需要清楚,Model, Controller, View各司什么职责明白BDD的User Story需要会写,SMART要求能…...

eslint.config.js和.eslintrc.js有什么区别
eslint.config.js 和 .eslintrc.js 的主要区别在于它们所对应的 ESLint 版本和配置方法: 1. .eslintrc.js: 这是 ESLint v8 及更早版本使用的配置文件格式。 它使用层级式的配置系统。 现在被称为"旧版"配置格式 。 2. eslint.config.js&am…...

如何使用MVC模式设计和实现校园自助点餐系统的微信小程序
随着智慧校园的普及,校园自助点餐系统在提高学生用餐效率、减轻食堂运营压力方面发挥了重要作用。 在开发这类系统时,MVC(Model-View-Controller)模式是一种非常适合的架构,它将系统的业务逻辑、用户界面和数据交互清晰…...

继续坚持与共勉
经过期末考试后,又要开始学习啦。 当时一直在刷算法题就很少写博客了,现在要继续坚持写博客,将每天对于题的感悟记录下来。 同时我将会在学习Linux操作系统,对于过去学习的内容进行回顾!! 在此ÿ…...

从怀疑到真香!2026我日常办公离不开的这款在线文字转换器太好用了
刚入职那半年我踩过太多坑:一周三次新人培训,怕漏记知识点全程录音,下课手动整理1小时录音要熬3小时,知识点散得根本没法复习;部门周会做完记录,散会就要我出整理好的纪要,赶工赶得饭都吃不上&a…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南
如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download 在数字时代,百度网盘已成为我们存储和分享大型文件的默认…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

基于STM32与LoRa的低功耗物联网气象站DIY全攻略
1. 项目概述:打造一个低功耗的家庭气象站前阵子想给家里的智能家居系统加点“环境感知”能力,琢磨着搞个能实时监测室外温湿度、风速风向的小玩意儿。市面上成品气象站要么数据出不来,要么功耗感人,不适合长期户外部署。于是&…...
)
从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表)
更多请点击: https://codechina.net 第一章:从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表) 向事件驱动架构(EDA)演进不是功能迭代&…...

基于ATmega328P与TFT屏的园艺环境监控系统:硬件选型与软件架构详解
1. 项目概述:打造你的家庭园艺数据监控中心如果你和我一样,是个喜欢在阳台或后院捣鼓花草的园艺爱好者,同时又对电子DIY有点兴趣,那么这个项目绝对会让你兴奋。我们不是在简单地种花,而是在用数据“聆听”植物的需求。…...

Taotoken的APIKey管理与访问控制功能保障了企业级安全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的APIKey管理与访问控制功能保障了企业级安全 当团队开始规模化使用大语言模型时,一个核心挑战随之而来&#…...