【深度学习】数据预处理
为了能用深度学习来解决现实世界的问题,我们经常从预处理原始数据开始,
而不是从那些准备好的张量格式数据开始。
在Python中常用的数据分析工具中,我们通常使用pandas软件包。
像庞大的Python生态系统中的许多其他扩展包一样,pandas可以与张量兼容。
本节我们将简要介绍使用pandas预处理原始数据,并将原始数据转换为张量格式的步骤。
后续将介绍更多的数据预处理技术。
读取数据集
举一个例子,我们首先(创建一个人工数据集,并存储在CSV(逗号分隔值)文件)../data/house_tiny.csv中。
以其他格式存储的数据也可以通过类似的方式进行处理。下面我们将数据集按行写入CSV文件中。
下面先简单介绍一下CSV文件
CSV(Comma-Separated Values)文件,即逗号分隔值文件,是一种常见的简单文件格式,用于存储表格数据。特点和用途- **简单易读**:CSV 文件以纯文本形式存储表格数据,每行数据表示一条记录,**字段之间用逗号分隔**(也可以使用其他字符如分号等作为分隔符,但逗号是最常见的)。
- **广泛支持**:几乎所有的电子表格软件(如Microsoft Excel、Google Sheets等)和数据分析工具(如Python的pandas库、R语言等)都支持CSV文件的读取和写入,使其成为数据交换的通用格式。
- **数据存储和传输**:常用于在不同系统和软件之间传输和存储数据,例如从数据库中导出数据、在网站上提供数据下载等。CSV文件因其简单性和通用性,在数据处理和分析领域中被广泛应用,是数据存储和交换的重要格式之一。
import osos.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:f.write('NumRooms,Alley,Price\n') # 列名f.write('NA,Pave,127500\n') # 每行表示一个数据样本f.write('2,NA,106000\n')f.write('4,NA,178100\n')f.write('NA,NA,140000\n')
以下是对这段代码的解读:### 1. 导入`os`模块import os`os`模块提供了与操作系统交互的功能,例如文件和目录操作等。### 2. 创建目录os.makedirs(os.path.join('..', 'data'), exist_ok=True)- `os.path.join('..', 'data')`:使用`os.path.join`函数将`'..'`(上一级目录)和`'data'`拼接成一个完整的路径,表示要在上一级目录下创建一个名为`data`的目录。
- `os.makedirs`:用于创建多层目录。`exist_ok=True`表示如果目录已经存在,不会引发异常,而是直接跳过创建操作。### 3. 定义数据文件路径data_file = os.path.join('..', 'data', 'house_tiny.csv')再次使用`os.path.join`将上一级目录、`data`目录和文件名`house_tiny.csv`拼接成完整的文件路径,并将其赋值给变量`data_file`,以便后续操作该文件。### 4. 写入CSV文件内容with open(data_file, 'w') as f:f.write('NumRooms,Alley,Price\n') # 列名f.write('NA,Pave,127500\n') # 每行表示一个数据样本f.write('2,NA,106000\n')f.write('4,NA,178100\n')f.write('NA,NA,140000\n')- `with open(data_file, 'w') as f`:使用`with`语句打开文件`data_file`,以写入模式(`'w'`)打开。`with`语句可以确保在操作完成后自动关闭文件,即使在操作过程中出现异常也能正确关闭文件,避免资源泄漏。
- 接下来的几行`f.write`语句分别写入了CSV文件的列名(`NumRooms,Alley,Price`)和几行数据样本,每行数据样本由逗号分隔的字段组成,分别对应房屋的房间数量(`NumRooms`)、小巷类型(`Alley`)和价格(`Price`)。其中`NA`表示缺失值。这段代码的主要作用是创建一个目录和一个简单的CSV文件,并向该文件中写入一些房屋数据,为后续的数据处理和分析提供基础数据。例如,可以使用`pandas`等库读取这个CSV文件进行进一步的操作。
要[从创建的CSV文件中加载原始数据集],我们导入pandas包并调用read_csv函数。该数据集有四行三列。其中每行描述了房间数量(“NumRooms”)、巷子类型(“Alley”)和房屋价格(“Price”)。
import pandas as pddata = pd.read_csv(data_file)
print(data)

处理缺失值
注意,“NaN”项代表缺失值。[为了处理缺失的数据,典型的方法包括 插值法 和 删除法,]
其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。在(这里,我们将考虑插值法)。
通过位置索引iloc,我们将data分成inputs和outputs,
其中前者为data的前两列,而后者为data的最后一列。
对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
print(inputs)

[对于inputs中的类别值或离散值,我们将“NaN”视为一个类别。]
由于“巷子类型”(“Alley”)列只接受两种类型的类别值“Pave”和“NaN”,pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。
巷子类型为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。缺少巷子类型的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)

转换为张量格式
[现在inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式。]
当数据采用张量格式后,可以通过在 :numref:sec_ndarray中引入的那些张量函数来进一步操作。
import torchX = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
X, y

相关文章:
【深度学习】数据预处理
为了能用深度学习来解决现实世界的问题,我们经常从预处理原始数据开始, 而不是从那些准备好的张量格式数据开始。 在Python中常用的数据分析工具中,我们通常使用pandas软件包。 像庞大的Python生态系统中的许多其他扩展包一样,pan…...
day01-HTML-CSS——基础标签样式表格标签表单标签
目录 此篇为简写笔记下端1-3为之前笔记(强迫症、保证文章连续性)完整版笔记代码模仿新浪新闻首页完成审核不通过发不出去HTMLCSS1 HTML1.1 介绍1.1.1 WebStrom中基本配置 1.2 快速入门1.3 基础标签1.3.1 标题标签1.3.2 hr标签1.3.3 字体标签1.3.4 换行标…...

无需昂贵GPU:本地部署开源AI项目LocalAI在消费级硬件上运行大模型
无需昂贵GPU:本地部署开源AI项目LocalAI在消费级硬件上运行大模型 随着人工智能技术的快速发展,越来越多的AI模型被广泛应用于各个领域。然而,运行这些模型通常需要高性能的硬件支持,特别是GPU(图形处理器)…...
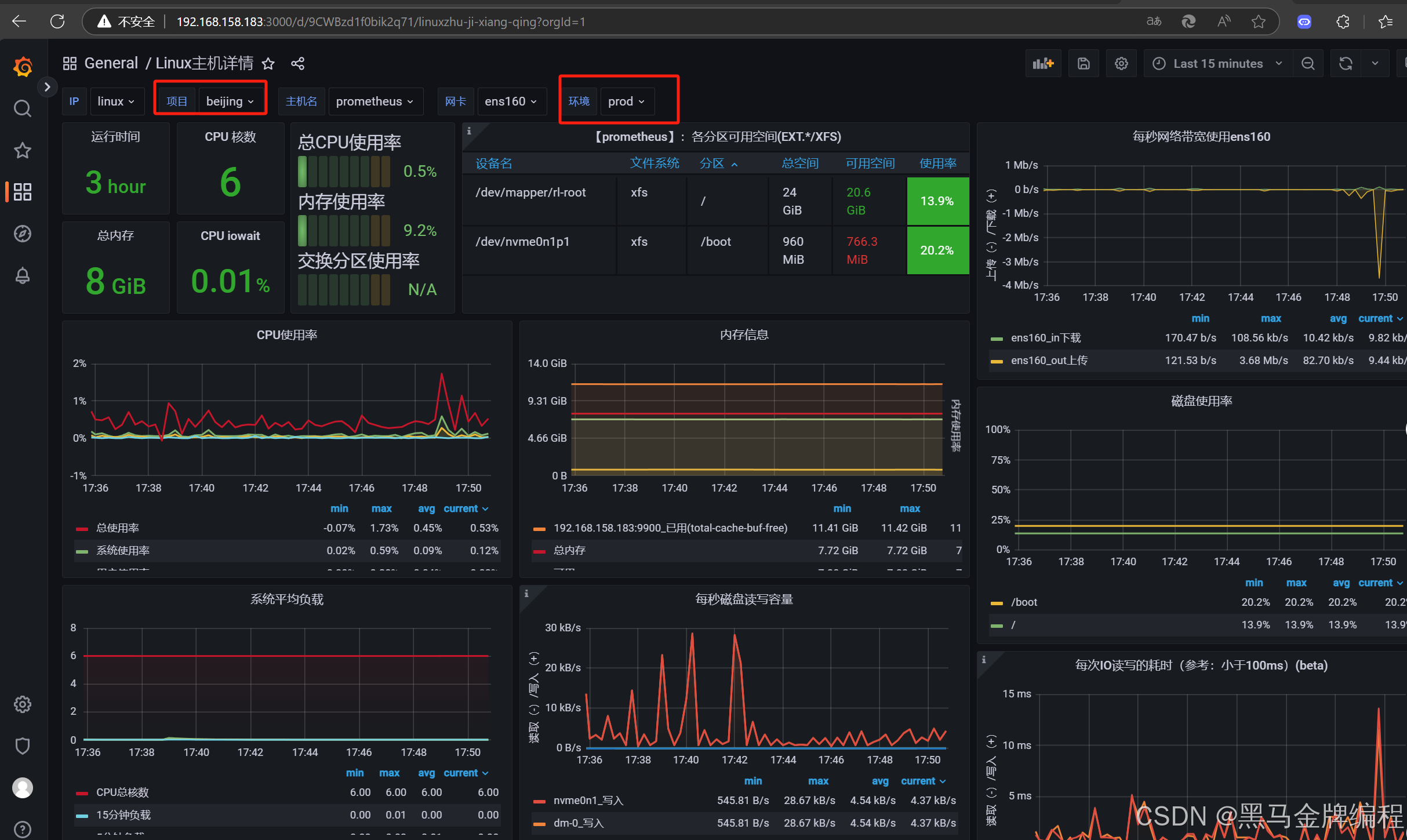
搭建prometheus+grafana监控系统抓取Linux主机系统资源数据
Prometheus 和 Grafana 是两个非常流行的开源工具,通常结合使用来实现监控、可视化和告警功能。它们在现代 DevOps 和云原生环境中被广泛使用。 1. Prometheus 定义:Prometheus 是一个开源的系统监控和告警工具包,最初由 SoundCloud 开发&am…...
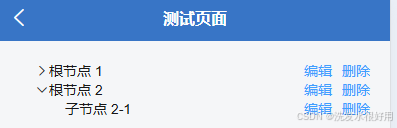
uni-app无限级树形组件简单实现
因为项目一些数据需要树形展示,但是官网组件没有。现在简单封装一个组件在app中使用,可以无线嵌套,展开,收缩,获取子节点数据等。 简单效果 组件TreeData <template><view class"tree"><te…...

基于华为ENSP的OSPF状态机、工作过程、配置保姆级别详解(2)
本篇技术博文摘要 🌟 基于华为enspOSPF状态机、OSPF工作过程、.OSPF基本配置等保姆级别具体详解步骤;精典图示举例说明、注意点及常见报错问题所对应的解决方法 引言 📘 在这个快速发展的技术时代,与时俱进是每个IT人的必修课。我…...

请求方式(基于注解实现)
1.编写web.xml文件配置启动信息 <!DOCTYPE web-app PUBLIC"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN""http://java.sun.com/dtd/web-app_2_3.dtd" > <web-app><display-name>Archetype Created Web Application</di…...

day38 tcp 并发 ,linux下的IO模型----IO多路复用
TCP 并发 由于tcp协议只能实现一对一的通信模式。为了实现一对多,有以下的的处理方式 1. 多进程 开销大 效率低 2. 多线程 创建线程需要耗时 3. 线程池 多线程模型创建线程耗时问题,提前创建 4. IO多路复用 在不创建进程和线程的前提下,对…...
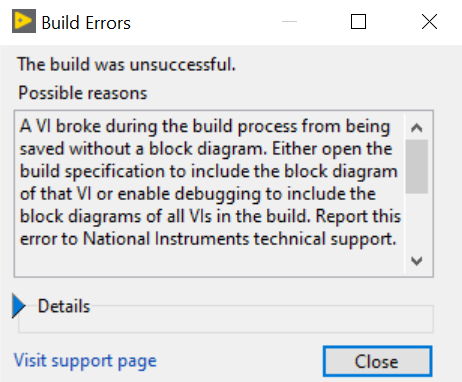
更新Office后,LabVIEW 可执行程序生成失败
问题描述: 在计算机中,LabVIEW 开发的源程序运行正常,但在生成可执行程序时提示以下错误: A VI broke during the build process from being saved without a block diagram. Either open the build specification to include…...
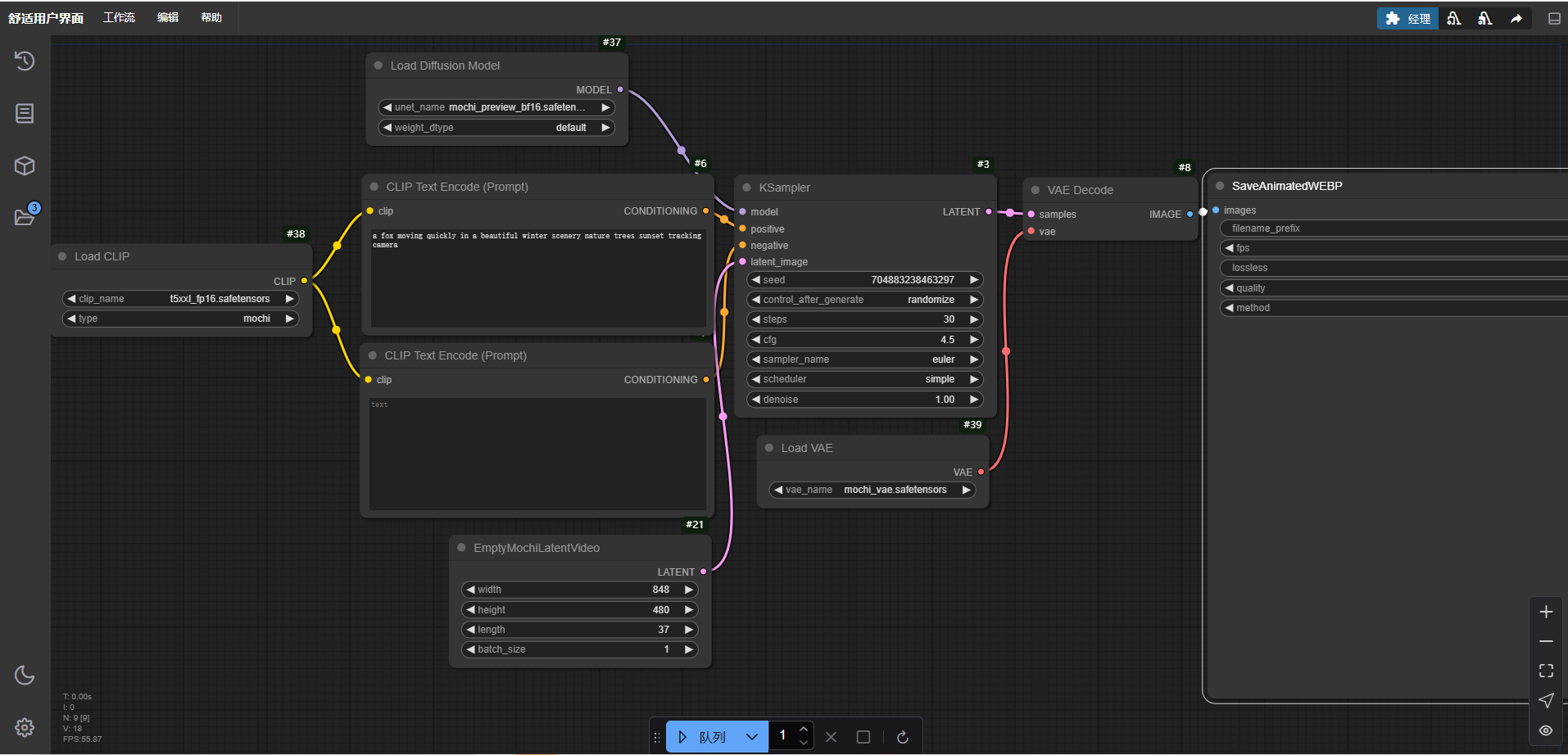
重塑视频创作的格局!ComfyUI-Mochi本地部署教程
一、介绍 mochi是近期Genmo公司开源的先进视频生成模型,具有高保真运动和强大的提示遵循性。此模型的发布极大的缩小了闭源和开源视频生成系统之间的差距。 目前,视频生成模型与现实之间存在巨大差距。其中最影响视频生成的两个关键功能也就是运动质量和…...

如何理解机器学习中的非线性模型 ?
在机器学习中,非线性模型是指能够捕捉输入特征与输出之间复杂非线性关系的一类模型。与线性模型不同,非线性模型的假设更加灵活,因此可以更好地处理真实世界中复杂、多样的数据分布。以下是对非线性模型的理解: 1. 非线性模型的核…...

Web 品质样式表
《Web 品质样式表》是一个重要的指南,旨在帮助开发者提升网站的整体质量和用户体验。以下是一些关键点: 避免使用 <font> 标签:应使用 CSS 来设置显示网页上的字体尺寸。使用 <font> 标签会增加文档的规模,且使每次改…...

计算机网络 笔记 数据链路层3(局域网,广域网,网桥,交换机)
局域网: LAN:在某一区域内由多台计算机互联成的计算机组,使用广播信道 特点: 覆盖范围有限:通常局限在几千米范围内,比如一栋办公楼、一个校园或一个工厂等相对较小的地理区域。 数据传输速率高:一般能达到 10Mbps…...
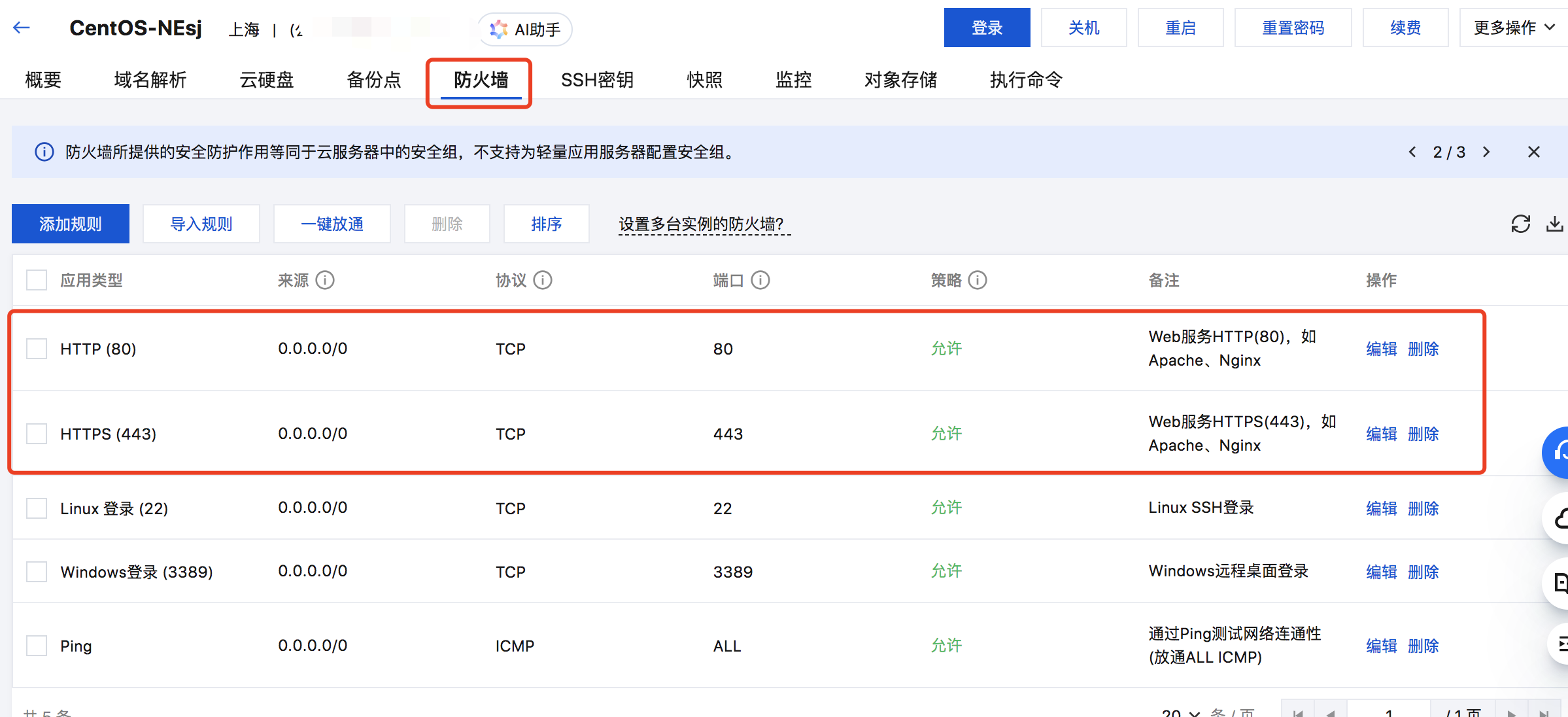
centos7.6 安装nginx 1.21.3与配置ssl
1 安装依赖 yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel2 下载Nginx wget http://nginx.org/download/nginx-1.21.3.tar.gz3 安装目录 mkdir -p /data/apps/nginx4 安装 4.1 创建用户 创建用户nginx使用的nginx用户。 #添加www组 # groupa…...
redis 内存管理和持久化机制
文章目录 前言一、内存管理1、Redis过期策略1.1、惰性过期1.2、定期过期清理频率配置清理流程 2、Redis淘汰策略策略流程算法分析1、LRU2、LFU 二、持久化1、RDB2、AOF 前言 redis 内存管理与持久化 一、内存管理 redis我们的数据都是放在内存里面的,但是内存是有…...
python-42-使用selenium-wire爬取微信公众号下的所有文章列表
文章目录 1 seleniumwire1.1 selenium-wire简介1.2 获取请求和响应信息2 操作2.1 自动获取token和cookie和agent2.3 获取所有清单3 异常解决3.1 请求url失败的问题3.2 访问链接不安全的问题4 参考附录1 seleniumwire Selenium WebDriver本身并不直接提供获取HTTP请求头(header…...

机器人碳钢去毛刺,用大扭去毛刺主轴可轻松去除
在碳钢精密加工的最后阶段,去除毛刺是确保产品质量的关键步骤。面对碳钢这种硬度较高的材料,采用大扭矩的SycoTec去毛刺主轴,成为了行业内的高效解决方案。SycoTec作为精密加工领域的领军品牌,其生产的高速电主轴以其卓越的性能&a…...

day05_Spark SQL
文章目录 day05_Spark SQL课程笔记一、今日课程内容二、Spark SQL 基本介绍(了解)1、什么是Spark SQL**为什么 Spark SQL 是“SQL与大数据之间的桥梁”?****实际意义**为什么要学习Spark SQL呢?**为什么 Spark SQL 像“瑞士军刀”࿱…...

Java线程的异常处理:确保线程安全运行
哈喽,各位小伙伴们,你们好呀,我是喵手。运营社区:C站/掘金/腾讯云/阿里云/华为云/51CTO;欢迎大家常来逛逛 今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互…...
nvim 打造成可用的IDE(2)
上一个 文章写的太长了, 后来再写东西 就一卡一卡的,所以新开一个。 主要是关于 bufferline的。 之前我的界面是这样的。 这个图标很不舒服有。 后来发现是在这里进行配置。 我也不知道,这个配置 我是从哪 抄过来的。 测试结果࿱…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

利用FTDI芯片MPSSE模式构建Arduino兼容开发环境
1. 项目概述:当FTDI芯片遇上Arduino生态如果你手头有一些闲置的FTDI USB转串口模块,比如常见的FT232R、FT2232H,或者像我一样,从某个旧设备上拆下来一块FT2232C的老古董,除了用来给单片机烧录程序或者做串口调试&#…...
【php语法学习,iscc校赛wp】)
学习日志(三)【php语法学习,iscc校赛wp】
1. 任务 1.1.1.1.1.1. 知识部分 rce看【之前的笔记?】php的知识点学习继续jwt token好像是比赛的题目考察内容,我看看php伪协议 1.1.1.1.1.2. 题目 参加iscc比赛【五一】rce题目 1.1.1.1.1.3. 环境配置 把vscode搞好,上学期没有把Php配…...

UE4SS终极指南:从零开始掌握虚幻引擎脚本系统
UE4SS终极指南:从零开始掌握虚幻引擎脚本系统 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE4S…...

Lovable电商网站搭建:如何用不到3人技术团队,72小时内上线PCI-DSS合规MVP版本?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署能力。本章将指导你从零开始搭建一个具备商品展示、…...

LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案
LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_mirror…...

AI算法工程师如何进行模型部署?这2个工具+3个技巧,快速上线
对于软件测试从业者来说,模型部署并不是一个陌生的概念——随着AI功能逐渐渗透到各类应用软件中,测试工程师不仅需要验证模型输出的准确性,更需要理解部署流程对模型稳定性、响应速度和结果一致性的影响。很多测试同学会有这样的困惑…...