【C语言】字符串函数详解
文章目录
- Ⅰ. strcpy -- 字符串拷贝
- 1、函数介绍
- 2、模拟实现
- Ⅱ. strcat -- 字符串追加
- 1、函数介绍
- 2、模拟实现
- Ⅲ. strcmp -- 字符串比较
- 1、函数介绍
- 2、模拟实现
- Ⅳ. strncpy、strncat、strncmp -- 可限制操作长度
- Ⅴ. strlen -- 求字符串长度
- 1、函数介绍
- 2、模拟实现(三种方式)
- ① 计数器的方式
- ② 递归的方式
- ③ 指针-指针的方式
- Ⅵ. strstr -- 字符串查找
- 1、函数介绍
- 2、模拟实现
- Ⅶ. strtok -- 字符串分割
- Ⅷ. strerror、perror -- 错误报告函数

Ⅰ. strcpy – 字符串拷贝
1、函数介绍
char *strcpy(char *Destination, const char *Source);
strcpy 函数是一个用于拷贝字符串的函数,即将一个字符串中的内容拷贝到另一个字符串中(会覆盖原字符串内容)。它的参数是两个指针,第一个指向的是拷贝字符串的目的地的起始位置,即要将字符串拷贝到什么地方;第二个指向的是要拷贝字符串的内容的起始位置,即需要拷贝的字符串。它的返回值是目标空间的起始位置。
💥注意:
- 源字符串(需要被拷贝的字符串)必须以
\0结束。 - 会将源字符串中的
\0一同拷贝到目标空间。 - 目标空间必须足够大,以确保能存放源字符串。
- 目标空间必须可变。
举个例子,比如我们要将 arr2 数组中的 "def" 拷贝到 arr1 数组中。
#include<stdio.h>
#include<string.h>
int main()
{char arr1[10] = "abc";char arr2[] = "def";strcpy(arr1, arr2);printf("%s", arr1);return 0;
}// 运行结果
def
注意: 拷贝结束后 arr1 数组中只有 "def",因为 "abc" 被覆盖了。
2、模拟实现
char* my_strcpy(char* dest, const char* src)
{if (dest == NULL || src == NULL)return NULL;char* p = dest;while (*p++ = *src++) // 当遇到\0赋值之后判断为0则退出循环,达到了我们的目的{}return dest;
}
在这个代码中,我们首先添加了一个错误处理机制,以防止传递给 strcpy 函数的参数是 NULL 指针。如果参数是 NULL 指针,则函数将返回 NULL,main 函数将输出一条错误消息并退出程序。
此外,我们还使用了 const 关键字来指示源字符串 src 是只读的,这可以帮助我们防止无意中修改源字符串。
Ⅱ. strcat – 字符串追加
1、函数介绍
char *strcat(char *Destination, const char *Source);
strcat 函数是一个用于追加字符串的函数,即将一个字符串中的内容追加到另一个字符串后面(不会覆盖原字符串内容)。它的参数是两个指针,第一个指向的是追加字符串的目的地的起始位置,即要将字符串追加到什么地方;第二个指向的是要追加字符串的内容的起始位置,即需要追加的字符串。它的返回值是目标空间的起始位置。
💥注意:
- 源字符串必须以
\0结束。 - 目标空间必须足够大,能容纳下源字符串的内容。
- 目标空间必须可修改。
- 字符串不能给自己追加(
\0被覆盖,无终止条件)。
举个例子,比如我们要将 arr2 数组中的 “liren!” 追加到 arr1 数组的后面。
#include<stdio.h>
#include<string.h>
int main()
{char arr1[20] = "hello ";char arr2[] = "liren!";strcat(arr1, arr2);printf("%s", arr1);return 0;
}// 运行结果:
hello liren!
2、模拟实现
char* my_strcat(char* dest, const char* src)
{char* p = dest;while (*p != '\0') // 找到目标空间的'\0'{p++;}while (*p++ = *src++) // 当遇到\0赋值之后判断为0则退出循环,达到了我们的目的{}return dest;
}
这个实现中,首先定义了两个指针,一个指向目标字符串的末尾,一个指向源字符串的开头。然后,使用 while 循环将源字符串中的每个字符逐个复制到目标字符串的末尾,直到源字符串末尾为止。最后,在目标字符串的末尾添加一个 NULL 字符,表示字符串的结束。
需要注意的是,在本函数的实现中,目标字符串必须具有足够的空间来容纳源字符串,否则会导致缓冲区溢出和未定义行为。此外,源字符串必须是一个 const char* 类型的指针,以防止在函数内部修改源字符串的内容。
Ⅲ. strcmp – 字符串比较
1、函数介绍
int strcmp(const char *string1, const char *string2);
strcmp 函数是一个用于比较两个字符串内容的函数。它的参数是两个指针,指针分别指向两个待比较字符串的起始位置。它的返回值是一个整型数字。当 string1 大于 string2 的时候返回一个大于 0 的数;当 string1 等于 string2 的时候返回 0;当 string1 小于 string2 的时候返回一个小于 0 的数。
💥注意:
- 字符串比较的不是字符串长度的大小,而是两个字符串中对应位置字符的
ASCII值。
举个例子,比如比较字符串 "hello world!" 和字符串 "hello liren!" 的大小。
#include<stdio.h>
#include<string.h>
int main()
{char arr1[20] = "hello world!";char arr2[20] = "hello csdn!";printf("%d\n", strcmp(arr1, arr2));printf("%d\n", strcmp(arr2, arr1));return 0;
}// 运行结果:
1
-1
2、模拟实现
int my_strcmp(const char *s1, const char *s2)
{while (*s1 == *s2) {if(*s1 == '\0')return 0;s1++;s2++;}return *(const unsigned char*)s1 - *(const unsigned char*)s2;
}
这个实现中,使用 while 循环比较两个字符串中的每个字符。如果两个字符相等,则继续比较下一个字符;如果不相等,则返回它们的 ASCII 码之差。需要注意的是,由于有符号和无符号字符之间的比较会产生未定义行为,因此我们将两个指针都转换为 const unsigned char * 类型。
如果两个字符串完全相等,则返回值为 0。如果 s1 小于 s2,则返回一个负整数,反之则返回一个正整数。
需要注意的是,在使用 strcmp 函数比较字符串时,一定要确保两个字符串都以 NULL 字符结尾。如果没有以 NULL 字符结尾,会导致函数在比较过程中访问到未知的内存区域,从而导致未定义行为。
Ⅳ. strncpy、strncat、strncmp – 可限制操作长度
我们发现 strcpy 是将一个字符串全部拷贝到另一个字符串,strcat 是将一个字符串全部追加到另一个字符串后面,strcmp 也是比较两个字符串的全部内容,这类操作函数称为长度不受限制的字符串操作函数。
那么我们如果操作字符串时并不想操作整个字符串,而只想操作字符串的一部分怎么办呢❓❓❓
库函数中的 strncpy、strncat、strncmp 便解决了这个问题。
char *strncpy(char *Dest, const char *Source, size_t count);
char *strncat(char *Dest, const char *Source, size_t count);
int strncmp(const char *string1, const char *string2, size_t count);
这里就不细讲用法了,比较简单,自行尝试!
Ⅴ. strlen – 求字符串长度
1、函数介绍
size_t strlen( const char *string );
strlen 函数是一个用于求字符串长度的库函数。它的参数是被求长度的字符串的起始地址,返回值是一个无符号整型。
💥注意:
- 参数指向的字符串要以
\0结束。 strlen返回的是在字符串中\0之前出现的字符个数(不包含\0)。- 注意函数的返回值为
size_t,是无符号的(易错)。
举个例子,比如我们要求字符串 "abcdef" 的长度。
#include<stdio.h>
#include<string.h>
int main()
{char arr[] = "abcdef";size_t ret = strlen(arr);printf("%d\n", ret);return 0;
}// 运行结果:
6
2、模拟实现(三种方式)
① 计数器的方式
我们定义一个变量为 count,如果传入的指针指向的内容不是 \0,那么 count++,同时指针后移一位,循环往复,直到找到 \0 时返回 count 即可。
size_t my_strlen(const char* str)
{size_t count = 0; // 计数器while (*str){count++;str++;}return count;
}
② 递归的方式
我们一进入函数体就判断传入指针指向的内容是否为 \0,如果是就返回 0,不是就返回 1 + my_strlen(str+1),如此进行下去,直到递归到内层时找到 \0,这时再一步步将值返回回来即可。
size_t my_strlen(const char* str)
{if (*str == '\0')return 0;elsereturn 1 + my_strlen(str + 1);
}
③ 指针-指针的方式
进入函数体时,我们事先定义一个指针变量将传入的指针保存下来,然后将传入的指针向后移,直到遇到 \0 时,我们返回当前指针与保存的指针的差值即可。(指针与指针的差的绝对值是两个指针之间的元素个数)
size_t my_strlen(const char* str)
{const char* p = str; // 保存起始位置while (*str != '\0')str++;return str - p;
}
Ⅵ. strstr – 字符串查找
1、函数介绍
char *strstr(const char *string, const char *strCharSet);
strstr 函数可以在一个字符串(字符串1)中查找另一个字符串(字符串2),如果字符串2存在于该字符串1中,那么就返回被字符串2在字符串1中第一次出现的起始位置,如果在字符串1中找不到字符串2,那么就返回空指针(NULL)。它的第一个参数是字符串1的起始位置,第二个参数是字符串2的起始位置。
💥注意:
- 若字符串2为空字符串,则返回字符串1的起始位置。
举个例子,比如我们在字符串 “abcdefbcd” 中查找字符串 “bcd”。
#include<stdio.h>
#include<string.h>
int main()
{char arr1[] = "abcdefbcd";char arr2[] = "bcd";char* ret = strstr(arr1, arr2); // 在arr1中查找arr2字符串第一次出现的位置if (ret != NULL)printf("%s\n", ret);elseprintf("找不到\n");return 0;
}// 运行结果:
bcdefbcd
注意:strstr 函数的返回值是字符串 "bcd" 在字符串 "abcdefbcd" 中 第一次出现的位置的起始位置,而不是出现几次就返回几个起始位置。
2、模拟实现
strstr 函数的模拟实现相对复杂,在实现过程中我们需要设置3个指针变量来辅助实现函数功能。
cp指针: 记录每次开始匹配时的起始位置,当从该位置开始匹配时就找到了目标字符串,便于返回目标字符串出现的起始位置;当从该位置开始没有匹配成功时,则从cp++处开始下一次的匹配。p1、p2指针: 通过判断p1和p2指针解引用后是否相等来判断每个字符是否匹配成功,若成功,则指针后移比较下一对字符;若失败,p1指针返回cp指针处,p2指针返回待查找字符串的起始位置。
例如,在字符串"abbbcdef"中查找字符串"bbc":
刚刚开始时3个指针的指向如图所示:

若p1与p2匹配不成功,则cp指针后移,接着将cp指针赋值给p1指针:

此时,p1与p2匹配成功,那么cp指针不动,p1和p2指针后移继续比较:

当p1与p2匹配不成功时,cp指针后移一位,p1返回cp位置,p2返回待查找字符串起始位置:

从此位置开始下一轮的比较:

直到当p2指向的内容为\0时,便说明待查找字符串中的字符已经被找完,也说明了从当前cp位置开始匹配能够找到目标字符串,所以此时返回指针cp即可。
char* my_strstr(const char* str1, const char* str2)
{assert(str1 != NULL); // 断言,当str1为空指针报错assert(str2 != NULL); // 断言,当str2为空指针报错const char* cp = str1; // 记录开始匹配时的起始位置if (*str2 == '\0') // 要查找的字符串为空字符串return (char*)str1;while (*cp){const char* p1 = cp;const char* p2 = str2;while ((*p1!='\0') && (*p2!='\0') && (*p1 == *p2)){p1++;p2++;}if (*p2 == '\0') // 目标字符串已被查找完return (char*)cp;cp++;}return NULL; // 找不到目标字符串
}
但是这种算法的时间复杂度比较高,优化方法就是 KMP 算法,具体可以看 KMP 算法的笔记!
Ⅶ. strtok – 字符串分割
char *strtok(char *strToken, const char *strDelimit);
strtok 函数能通过给定的一系列字符将一个字符串分割成许多子字符串的函数。它的第一个参数是需要被分割的字符串的首地址;第二个参数是一个字符串的首地址,该字符串是用作分隔符的字符集合。返回值是查找到的标记的首地址。
💥注意:
- 找到 strToken 中的一个标记时,会将其用 \0 结尾并返回这个标记的首地址。
- strtok 函数是会改变 strToken 的,所以在使用 strtok 函数切分的字符串都是临时拷贝的内容并且可修改。
- 第一个参数不为 NULL 时,函数将找到 strToken 中的第一个标记,并保存它在字符串中的位置。
- 第一个参数为 NULL 时,函数将从同一个字符串中被保存的位置开始查找它的下一个标记。
- 若字符串中不存在更多的标记,则返回 NULL 指针。
举个例子,比如我们要将字符串"2916776007@qq.com"以"@“字符和”."字符分割开。
#include<stdio.h>
#include<string.h>
int main()
{char arr1[] = "2916776007@qq.com"; // 待分割字符串char arr2[] = "@."; // 分隔符的字符集合char arr3[20] = { 0 };strcpy(arr3, arr1); // 将数据拷贝一份使用,防止原数据被修改char* token = strtok(arr3, arr2); // 第一次传参需传入待分割字符串首地址while (token != NULL) // 说明还未分割完{printf("%s\n", token);token = strtok(NULL, arr2); // 对同一个字符串进行分割,第二次及以后的第一个参数为NULL}return 0;
}// 运行结果:
2916776007
qq
com
注意: 当 strtok 函数找到第一个标记时,将其后的 ’@‘ 字符改为 ’\0’ 并返回第一个标记的首地址,所以我们以返回的地址为首地址开始打印字符串的时候就只会打印出 2916776007,第二次再对该字符串调用 strtok 函数时将从 ’@’ 字符后面开始寻找下一个标记。
Ⅷ. strerror、perror – 错误报告函数
char *strerror(int errnum);
strerror 函数可以把错误码转换为对应的错误信息,返回错误信息对应字符串的起始地址。
void perror(const char *string);
perror 函数可以打印一个错误信息,无返回值。
我们需要知道,库函数在使用的时候如果发生错误,都会有对应的错误码,而这些错误码都会被存放在 errno 这个全局变量中,如果要使用这个全局变量,我们需要引其对应的头文件:#include<errno.h>
举个例子:(注:fopen函数的功能是打开一个文件,当其执行成功时会返回打开文件的首地址,执行失败时会返回一个空指针)
#include<stdio.h>
#include<string.h>
#include<errno.h>
int main()
{FILE* pf = fopen("test.txt", "r");//打开test.txt文件阅读if (pf == NULL){printf("%s\n", strerror(errno));perror("fopen");}return 0;
}// 运行结果:
No such file or directory
fopen: No such file or directory
当我们要打开一个不存在的文件(test.txt)来阅读的时候,显然fopen函数会执行失败,于是pf指针接收的便是空指针(NULL)。
- strerror: 只负责将错误码转换为对应的错误信息,不打印。
- perror: 直接打印错误信息,并且我们可以自己加上注释来明确错误来源于哪个库函数。
相关文章:
【C语言】字符串函数详解
文章目录 Ⅰ. strcpy -- 字符串拷贝1、函数介绍2、模拟实现 Ⅱ. strcat -- 字符串追加1、函数介绍2、模拟实现 Ⅲ. strcmp -- 字符串比较1、函数介绍2、模拟实现 Ⅳ. strncpy、strncat、strncmp -- 可限制操作长度Ⅴ. strlen -- 求字符串长度1、函数介绍2、模拟实现(…...
)
【Vim Masterclass 笔记14】S07L29 + L30:练习课08 —— Vim 文本对象同步练习(含点评课内容)
文章目录 L29 Exercise 08 - Text Objects1 训练目标2 操作指令2.1. 打开 textobjectspractice.txt 文件2.2. 单词对象练习 Word Objects2.3. 区块对象 ( ) 练习 Block Object ( )2.4. 引用字符串练习 Quoted Strings2.5. 区块对象 [ ] 练习 Block Object [ ]2.6. 区块对象 <…...
一览)
非PHP开源内容管理系统(CMS)一览
在现代网站开发中,内容管理系统(CMS)是不可或缺的工具。虽然许多广泛使用的CMS(如WordPress和Joomla)是基于PHP开发的,但其他编程语言同样诞生了许多优秀的开源CMS,适用于不同需求和技术栈的项目…...

WEB 攻防-通用漏-XSS 跨站脚本攻击-反射型/存储型/DOMBEEF-XSS
XSS跨站脚本攻击技术(一) XSS的定义 XSS攻击,全称为跨站脚本攻击,是指攻击者通过在网页中插入恶意脚本代码,当用户浏览该网页时,恶意脚本会被执行,从而达到攻击目的的一种安全漏洞。这些恶意脚…...

SQLAlchemy -批量插入时忽略重复
PostgreSQL 有一个很棒的INSERT() ON CONFLICT DO NOTHING子句,您可以将其与 SQLAlchemy 一起使用: from sqlalchemy.dialects.postgresql import insert session.execute(insert(MyTable).values(my_entries).on_conflict_do_nothing())MySQL 有类似的INSERT IGNORE子句,但…...

1月13日学习
[HITCON 2017]SSRFme 直接给了源代码,题目名称还是ssrf,那么该题大概率就是SSRF的漏洞,进行代码审计。 <?php// 检查是否存在 HTTP_X_FORWARDED_FOR 头,如果存在,则将其拆分为数组,并将第一个 IP 地址…...

Steam个人开发者注册备记
具体的注册过程有很多同志已经写过了,这里只写一点自己搞得有点费劲的地方。有点久了记得也不多了。 1.姓名用汉语拼音,参考护照上的,一般是Zhang Sanli这样的格式,姓一个单词,名字一个单词(不管1个字还是…...

django在线考试系统
Django在线考试系统是一种基于Django框架开发的在线考试平台,它提供了完整的在线考试解决方案。 一、系统概述 Django在线考试系统旨在为用户提供便捷、高效的在线考试环境,满足教育机构、企业、个人等不同场景下的考试需求。通过该系统,用…...

Laravel 中 Cache::remember 的基本用途
在 Laravel 中,Cache::remember 方法用于缓存数据,以提高应用程序的性能。当需要从数据库或其他较慢的数据源中检索数据时,可以使用 Cache::remember 来检查请求的数据是否已经被缓存。如果数据已缓存,则直接从缓存中读取…...

前端进程和线程及介绍
前端开发中经常涉及到进程和线程的概念,特别是在浏览器中。理解这两个概念对于理解浏览器的工作机制和前端性能优化非常重要。以下是详细介绍: 1. 什么是进程和线程? 进程: 是操作系统分配资源的基本单位。一个程序启动后…...

OpenGL —— 基于Qt的视频播放器 - ffmpeg硬解码,QOpenGL渲染yuv420p或nv12视频(附源码)
运行效果 工程说明 源码 vertex.glsl...

Vue Router
Vue Router4 匹配 Vue3;Vue Router3 匹配 Vue2。 Vue Router 是 Vue.js 官方的路由管理器。Vue Router 基于路由和组件的映射关系,监听页面路径的变化,渲染对应的组件。 安装: npm install vue-router。 基本使用: …...
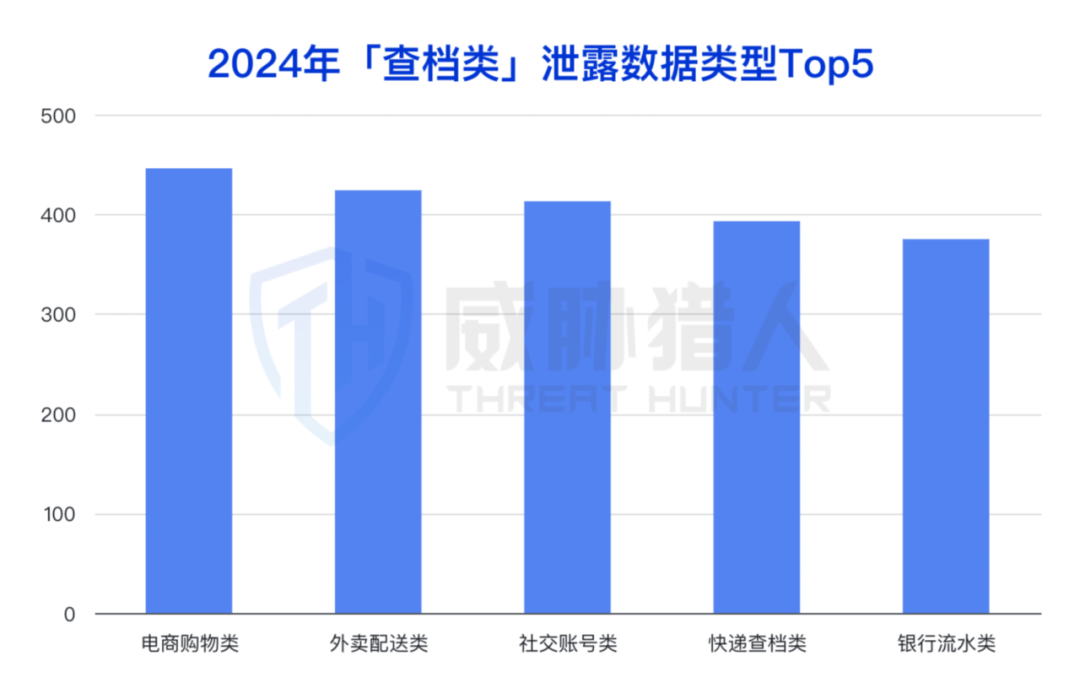
【黑灰产】人工查档业务产业链
2024年“查档”类型泄露事件快速上涨,涉及电商、外卖、社交、快递等行业数据。 近年来,陆续关注到非法数据交易产业链中游频繁出现的“查档”数据泄露情况,例如通过一个手机号,就可以查询这个手机号相关的所有身份信息࿰…...

114周二复盘 (178)
1、打新包,测试 2、白天为打包开始冲刺,问题不少,一堆细节问题, 但还是傍晚打包,不到3分钟,1.77G。 速度超预期。 3、开始测试。 基本还是达到预期的,但还是很多问题。 好在打包速度很快&am…...

day10_Structured Steaming
文章目录 Structured Steaming一、结构化流介绍(了解)1、有界和无界数据2、基本介绍3、使用三大步骤(掌握)4.回顾sparkSQL的词频统计案例 二、结构化流的编程模型(掌握)1、数据结构2、读取数据源2.1 File Source2.2 Socket Source…...

Python的秘密基地--[章节11] Python 性能优化与多线程编程
第11章:Python 性能优化与多线程编程 在开发复杂系统时,性能优化和并发编程是不可忽视的重点。Python 提供了多种工具和技术用于优化代码性能,并通过多线程、多进程等方式实现并发处理。本章将探讨如何在 Python 中提升性能,并实…...

drawDB docker部属
docker pull xinsodev/drawdb docker run --name some-drawdb -p 3000:80 -d xinsodev/drawdb浏览器访问:http://192.168.31.135:3000/...

探索图像编辑的无限可能——Adobe Photoshop全解析
文章目录 前言一、PS的历史二、PS的应用场景三、PS的功能及工具用法四、图层的概念五、调整与滤镜六、创建蒙版七、绘制形状与路径八、实战练习结语 前言 在当今数字化的世界里,视觉内容无处不在,而创建和编辑这些内容的能力已经成为许多行业的核心技能…...

【Vim Masterclass 笔记13】第 7 章:Vim 核心操作之——文本对象与宏操作 + S07L28:Vim 文本对象
文章目录 Section 7:Text Objects and MacrosS07L28 Text Objects1 文本对象的含义2 操作文本对象的基本语法3 操作光标所在的整个单词4 删除光标所在的整个句子5 操作光标所在的整个段落6 删除光标所在的中括号内的文本7 删除光标所在的小括号内的文本8 操作尖括号…...

Spring Boot教程之五十五:Spring Boot Kafka 消费者示例
Spring Boot Kafka 消费者示例 Spring Boot 是 Java 编程语言中最流行和使用最多的框架之一。它是一个基于微服务的框架,使用 Spring Boot 制作生产就绪的应用程序只需很少的时间。Spring Boot 可以轻松创建独立的、生产级的基于 Spring 的应用程序,您可…...
)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南(附软件包)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南 当你第一次拿起ESP8266模块时,可能会被这个小巧的Wi-Fi模块惊艳到——它只有指甲盖大小,却蕴含着强大的无线通信能力。但很快,这种惊艳就会变成困惑:为什…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

组态王通用扫码枪配置
使用组态王扫码枪驱动,是绑定变量,扫码后直接就可以显示扫码内容。解决每次扫码输入数据时必须先用鼠标点进输入框内的问题。驱动安装先添加驱动,亚控网站的文件为 barcodescanner,这个文件是组态王通用扫码枪的驱动,但…...
)
别再用SonarQube凑数了!DeepSeek原生圈复杂度引擎的6大颠覆性能力(含GitHub私有部署密钥)
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与范式革命 DeepSeek圈复杂度分析并非传统McCabe度量的简单复刻,而是基于控制流图(CFG)动态重构与语义感知路径裁剪的双重机制构建的新范式。…...

WPF虚拟桌宠组件:可嵌入、高性能、工程化UI生命体
1. 这不是“桌面宠物”,而是一个可嵌入的WPF UI组件化生命体你可能在Windows XP时代见过那只晃着尾巴、偶尔打哈欠的3D小猫,也可能在Win10系统托盘里点开过一个会眨眼的像素狐狸——但那些是独立进程、是系统级小工具、是“看一眼就关掉”的轻量娱乐。而…...

千亿镁合金产业集群正在成形:成都、抚州、池州的新版图
一个新赛道的地理坐标 如果要在中国地图上标注一条正在成形的新兴产业集群走廊,高强镁合金这条线,值得被认真画出来。 成都龙泉驿——江西抚州临川——安徽池州高新区,三个坐标,三条生产线,一家公司,两年内…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

VMware ESXi 9.1.0.0集成NVME+网卡驱动版发布|新特性+驱动集成+部署升级+FAQ全指南
一、ESXi 9.1.0.0 正式版核心新特性 VMware ESXi 9.1.0.0(2026 年 5 月发布)是 vSphere 9.1 核心组件,聚焦硬件兼容扩展、性能跃升、安全加固、运维简化四大方向,重点强化 NVMe 存储与网卡生态适配,以下为关键更新&am…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...