正则表达式基础知识及grep、sed、awk常用命令
文章目录
- 前言
- 一、正则表达式元字符和特性
- 1. 字符匹配
- 2. 量词
- 3. 字符类
- 4. 边界匹配
- 5. 分词和捕获
- 6. 特殊字符
- 7. 位置锚定
- 二、grep常用参数
- 1. -n额外输出行号
- 2. -v 排除匹配的行
- 3. -E 支持扩展正则匹配
- 4. -e进行多规则匹配搜索
- 5. -R 递归匹配目录中的文件内容
- 6. -r递归地搜索目录及其子目录中的文件
- 7. -l只输出包含了匹配项的文件名(可以结合-R使用)
- 8. -A 指定输出匹配行 后的额外行数
- 9. -B 指定输出匹配行 前的额外行数
- 10. -C 指定输出匹配行 前后的额外行数
- 11. -i 忽略大小写
- 12. -o 用于在匹配文本中仅输出匹配的部分,而不是整个行或文件
- 13. -q 用于if逻辑判断 安静模式,不打印任何标准输出
- 14. -c只输出匹配行的计数
- 15. -s 不显示不存在或无匹配文本的错误信息
- 16. -? 同时显示匹配行的上下?行
- 17. -w精确匹配
- 18. -P 启用 Perl 兼容正则表达式
- 三、grep练习
- 1. 从日志中匹配URL
- 2. 取出文件中的行(不包含空行和注释行)
- 3. 匹配以xx开头的行
- 4. 匹配以xx结尾的行
- 5. 匹配包含A或B的行
- 6. 查看指定时间范围的日志
- 7. 取出ip访问量及ip
- 8. 过滤某个时间段的日志
- 9. 获取服务器端口
- 四、sed
- 1. 参数说明
- 2. 示例
- 2.1. 全局替换
- 2.2. 匹配字段并对包含该字段的行进行注释
- 2.3. 删除包含xx的行
- 2.4. 删除空行
- 2.5. 替换指定行
- 2.6. 在第一行前插入一个新行
- 2.7. 在最后一行追加一个新行
- 2.8. 打印指定的行
- 2.9. 查看指定时间区间的日志
- 2.10. 根据行首或行尾进行匹配
- 2.11. 打印行范围
- 五、awk
- 1. 取出文件中的多行
- 2. 取出文件中的最后一行
- 3. 取出文件中的最后一列
- 4. 取出文件中的倒数第n列
- 5. 取出某个时间段的日志
- 六、sort排序、uniq去重
- 1. 了解知识
- 2. 查看日志,根据访问IP统计出某个时间段uv
- 3. 查看日志,根据日志中的访问IP进行UV分组,查看每天的总UV
- 4. 查看日志,根据访问url统计出某个时间段pv
- 5. 查看日志,根据日志中的访问时间进行pv分组,查看每天的总PV
- 6. 统计每天访问URL的TOP3
- 总结
前言
正则表达式是一种用于匹配和操作文本的强大工具,它是由一系列字符和特殊字符组成的模式,用于描述要匹配的文本模式。可以在文本中查找、替换、提取和验证特定的模式以及在日常脚本编写中也是不可缺少的一部分。因此本篇文章主要以正则表达式的基础使用和三剑客命令的使用做出一次分享.
一、正则表达式元字符和特性
1. 字符匹配
普通字符: 普通字符按照字面意义进行匹配,例如匹配字母 "a" 将匹配到文本中的 "a" 字符。元字符: 元字符具有特殊的含义,例如 \d 匹配任意数字字符,\w 匹配任意字母数字字符,. 匹配任意字符(除了换行符)等。
2. 量词
| 字符 | 含哟 |
|---|---|
| * | 匹配前面的模式零次或多次 |
| + | 匹配前面的模式一次或多次 |
| ? | 匹配前面的模式零次或一次 |
| {n} | 匹配前面的模式恰好 n 次 |
| {n,} | 匹配前面的模式至少 n 次 |
| {m,n} | 匹配前面的模式至少 m 次且不超过 n 次 |
3. 字符类
| 字符 | 含义 |
|---|---|
| [] | 匹配括号内的任意一个字符。例如,[abc] 匹配字符 “a”、“b” 或 “c” |
| [^] | 匹配除了括号内的字符以外的任意一个字符。例如,[^abc] 匹配除了字符 “a”、“b” 或 “c” 以外的任意字符 |
4. 边界匹配
| 字符 | 含义 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配以字符串结尾 |
| \b | 匹配单词边界,如"\blike"不会匹配alike,但是会匹配liker |
| \B | 匹配非单词边界 |
5. 分词和捕获
| 字符 | 含义 |
|---|---|
| ( ) | 用于分组和捕获子表达式。标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 ) |
| (?: ) | 用于分组但不捕获子表达式 |
6. 特殊字符
| 字符 | 含义 |
|---|---|
| \ | 转义字符,用于匹配特殊字符本身 |
| . 点 | 匹配任意字符(除了换行符) |
| 管道符 | 用于指定多个模式的选择 |
7. 位置锚定
| 字符 | 含义 |
|---|---|
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v] |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v] |
| \t | 匹配一个制表符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \f | 匹配一个换页符 |
| \d | 匹配一个数字字符。等价于 [0-9] |
| \D | 匹配一个非数字字符。等价于 [^0-9] |
| \w | 匹配字母、数字、下划线。等价于’[A-Za-z0-9_]’ |
| \W | 匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’ |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 [ |
| { | 标记限定符表达式的开始。要匹配 {,请使用 { |
二、grep常用参数
1. -n额外输出行号
代码如下(示例):
[root@localhost ~]# grep -n "青" test.txt
1:1 province 省份 青海省
3:3 subject_no 主体备案号 青ICP备11000289号
4:4 addr 注册地址 青海省西宁市城中区南关街138号
7:7 site_no 网站备案/许可证号 青ICP备11000289号-2
2. -v 排除匹配的行
代码如下(示例):
[root@localhost ~]# grep -v "青" test.txt
2 domain 域名或者ip tianfengyinlou.cn
5 check_time 备案时间, 时间对象 2011-06-23 16:38:00
6 update_time 更新时间, 毫秒级时间戳 1607414120745
8 site_url 站点/网站首页网址 www.tianfengyinlou.cn
9 comp_name 主办单位名称(公司名称) 西宁天丰银楼金银珠宝有限公司
3. -E 支持扩展正则匹配
代码如下(示例):
egrep等价于grep -E
[root@localhost ~]# grep -E '青海省|青ICP' text.txt
[root@localhost ~]# egrep '青海省|青ICP' text.txt
1 province 省份 青海省
3 subject_no 主体备案号 青ICP备11000289号
4 addr 注册地址 青海省西宁市城中区南关街138号
7 site_no 网站备案/许可证号 青ICP备11000289号-2
4. -e进行多规则匹配搜索
代码如下(示例):
[root@localhost ~]# grep -e 2025 -e log o
2025-01-16 08:32:45 - User accessed http://example.com/page1
2025-01-16 08:35:12 - Another request was made to https://secure-site.com/login
2025-01-16 08:36:25 - Error at http://example.com/error
2025-01-16 08:37:55 - API call to https://api.example.com/data?query=test&limit=10
2025-01-16 08:39:11 - User logged in at http://example.com/dashboard
2025-01-16 08:42:00 - Redirect to https://www.example.org/path/to/resource#anchor
2025-01-16 08:45:10 - Some other link without protocol: www.example.com
2025-01-16 08:47:21 - Contact page at http://example.com/contact
2025-01-16 08:50:50 - API failed at https://api.example.com/error?code=404
2025-01-16 08:53:00 - Please visit https://example.net/homepage for more info
5. -R 递归匹配目录中的文件内容
代码如下(示例):有时候,在一个目录中我们并不知道哪个文件内容包含我们想要的结果,此时,可以查找整个目录,输出匹配的文件名以及行记录
[root@localhost ~]# grep -R 青海 /export/wxd/
/export/test.txt:1 province 省份 青海省
/export/test.txt:4 addr 注册地址 青海省西宁市城中区南关街138号
6. -r递归地搜索目录及其子目录中的文件
代码如下(示例):有时候,在一个目录中我们并不知道哪个文件内容包含我们想要的结果,此时,可以查找整个目录,输出匹配的文件名以及行记录
[root@localhost ~]# grep -r --include="*.txt" "hello" /path/to/directory/
#使用 --include 选项来限制搜索的文件类型
7. -l只输出包含了匹配项的文件名(可以结合-R使用)
代码如下(示例):
[root@localhost ~]# grep -Rl 青 /export/sss
/export/sss/test.txt
8. -A 指定输出匹配行 后的额外行数
代码如下(示例):
[root@localhost ~]# grep -A1(额外行数) "ICP" test.txt 额外输出包含"ICP"行的后一行3 subject_no 主体备案号 青ICP备11000289号
4 addr 注册地址 青海省西宁市城中区南关街138号
--
7 site_no 网站备案/许可证号 青ICP备11000289号-2
8 site_url 站点/网站首页网址 www.tianfengyinlou.cn
9. -B 指定输出匹配行 前的额外行数
代码如下(示例): 额外输出包含"ICP"行的前一行
[root@localhost ~]# grep -B1 "ICP" test.txt2 domain 域名或者ip tianfengyinlou.cn
3 subject_no 主体备案号 青ICP备11000289号
--
6 update_time 更新时间, 毫秒级时间戳 1607414120745
7 site_no 网站备案/许可证号 青ICP备11000289号-2
10. -C 指定输出匹配行 前后的额外行数
代码如下(示例):额外输出包含"ICP"行的前后各一行
[root@localhost ~]# grep -C1 "ICP" test.txt2 domain 域名或者ip tianfengyinlou.cn
3 subject_no 主体备案号 青ICP备11000289号
4 addr 注册地址 青海省西宁市城中区南关街138号
--
6 update_time 更新时间, 毫秒级时间戳 1607414120745
7 site_no 网站备案/许可证号 青ICP备11000289号-2
8 site_url 站点/网站首页网址 www.tianfengyinlou.cn
11. -i 忽略大小写
代码如下(示例):
[root@localhost ~]# grep -i user o.log
2025-01-16 08:32:45 - User accessed http://example.com/page1
2025-01-16 08:39:11 - User logged in at http://example.com/dashboard
12. -o 用于在匹配文本中仅输出匹配的部分,而不是整个行或文件
代码如下(示例):
[root@localhost ~]# grep -Eo 'https?://[^\"]+' o.log
http://example.com/page1
https://secure-site.com/login
http://example.com/error
https://api.example.com/data?query=test&limit=10
http://example.com/dashboard
https://www.example.org/path/to/resource#anchor
http://example.com/contact
https://api.example.com/error?code=404
https://example.net/homepage for more info
13. -q 用于if逻辑判断 安静模式,不打印任何标准输出
代码如下(示例):-q 用于if逻辑判断 安静模式,不打印任何标准输出。如果有匹配的内容则立即返回状态值0
如果存在返回值为0,不存在返回值为1
[root@localhost ~]# grep -q 'auth' /etc/pam.d/system-auth
[root@localhost ~]# echo $?
0
[root@localhost ~]# grep -q 'auth required pam_tally2.so' /etc/pam.d/system-auth
[root@localhost ~]# echo $?
1
14. -c只输出匹配行的计数
代码如下(示例):
[root@localhost ~]# grep -c "User" o
2
15. -s 不显示不存在或无匹配文本的错误信息
代码如下(示例):
[root@localhost ~]# grep -s "root" /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
dockerroot:x:996:992:Docker User:/var/lib/docker:/sbin/nologin
16. -? 同时显示匹配行的上下?行
代码如下(示例):配合-n参数使用
[root@localhost ~]# grep -n -2 "root" /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
2-bin:x:1:1:bin:/bin:/sbin/nologin
3-daemon:x:2:2:daemon:/sbin:/sbin/nologin
--
8-halt:x:7:0:halt:/sbin:/sbin/halt
9-mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10:operator:x:11:0:operator:/root:/sbin/nologin
11-games:x:12:100:games:/usr/games:/sbin/nologin
12-ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
17. -w精确匹配
代码如下(示例):必须和要查找的一致,才会返回true,否则返回false
[root@localhost ~]# grep -w User o
2025-01-16 08:32:45 - User accessed http://example.com/page1
2025-01-16 08:39:11 - User logged in at http://example.com/dashboard
18. -P 启用 Perl 兼容正则表达式
代码如下(示例):
启用 Perl 兼容正则表达式,使 grep 能够支持更多功能,如零宽断言、非捕获分组、增强的模式匹配等。
示例:使用 -P 可以在正则表达式中使用一些标准的 Perl 特性,例如:零宽断言((?<=...),(?=...) 等)支持 \K(忽略之前的匹配,只有 \K 后的内容会作为匹配结果)使用非捕获分组 (?:...)
需求:使用 grep -P 来提取一个字符串中的数字部分echo "abc 123 def 456" | grep -oP '\d+'输出 123 456
三、grep练习
1. 从日志中匹配URL
代码如下(示例):
[root@localhost ~]# grep -oP "https?://[\S]+" o
http://example.com/page1
https://secure-site.com/login
http://example.com/error
https://api.example.com/data?query=test&limit=10
http://example.com/dashboard
https://www.example.org/path/to/resource#anchor
http://example.com/contact
https://api.example.com/error?code=404
https://example.net/homepage
[root@localhost ~]# grep -Eo 'https?://[^\"]+' o
http://example.com/page1
https://secure-site.com/login
http://example.com/error
https://api.example.com/data?query=test&limit=10
http://example.com/dashboard
https://www.example.org/path/to/resource#anchor
http://example.com/contact
https://api.example.com/error?code=404
https://example.net/homepage for more info
2. 取出文件中的行(不包含空行和注释行)
代码如下(示例):
[root@localhost ~]# cat /etc/ssh/sshd_config |egrep -v -n "^$|^#"
[root@localhost ~]# cat /etc/ssh/sshd_config |grep -Ev -n "^$|^#"
3. 匹配以xx开头的行
代码如下(示例):
[root@localhost ~]# grep '^hello' file.txt
4. 匹配以xx结尾的行
代码如下(示例):
[root@localhost ~]# grep 'world$' file.txt
5. 匹配包含A或B的行
代码如下(示例):
[root@localhost ~]# grep 'hello\|world' file.txt
6. 查看指定时间范围的日志
代码如下(示例):查询2023-05-05日凌晨01:10-15 – 09:10-15的日志
[root@localhost ~]# grep "05/May/2023:0[1-9]:1[0-5]" access.log
7. 取出ip访问量及ip
代码如下(示例):
[root@localhost ~]# grep '16/Jan/2025' ./access.log | awk '{ ip[$1]++ } END{for (i in ip){print ip[i],i}}'
5 192.168.10.39
3 192.168.10.49
2 192.168.10.67
2 192.168.10.40
1 192.168.10.41
3 192.168.10.51
7 192.168.10.42
1 192.168.10.52
3 192.168.10.43
2 192.168.10.38
8. 过滤某个时间段的日志
代码如下(示例):时间格式: 年-月-日 时-分-秒
[root@localhost ~]# grep -E '2022-Mar-(0[1-9]|1[0-9]|2[0-9]|3[0-1]) (0[0-9]|1[0-9]|2[0-3]):([0-5][0-9]):([0-5][0-9])' sunshine-meetings-test1-20220322191825.log
9. 获取服务器端口
代码如下(示例):
[root@localhost ~]# netstat -lntp |grep -oP ":\K\d+"|sort -n |uniq
22
80
801
1080
1234
6443
8080
8081
8082
8083
9000
9001
9005
9273
四、sed
1. 参数说明
| 参数 | 含义 |
|---|---|
| a | 新增的字串会在新的一行 |
| d | 删除行 |
| i | 通常在当前行的上一行插入 |
| p | 通常与参数-n 一起运行,打印行内容 |
| s | 替换指定内容 |
2. 示例
2.1. 全局替换
[root@localhost ~]# sed -i 's/xx/xx/g' 文件
2.2. 匹配字段并对包含该字段的行进行注释
[root@localhost ~]# sed -i '/9273/s/^/#/' filename
2.3. 删除包含xx的行
[root@localhost ~]# sed -i '/xx/d' 文件
2.4. 删除空行
[root@localhost ~]# sed -i '/^$/d' 文件
2.5. 替换指定行
[root@localhost ~]# sed -i '2s/old-text/new-text/' 文件
2.6. 在第一行前插入一个新行
[root@localhost ~]# sed -i '1i\new-line' 文件
2.7. 在最后一行追加一个新行
[root@localhost ~]# sed -i '$a\new-line' 文件
2.8. 打印指定的行
[root@localhost ~]# sed '2p' 文件
2.9. 查看指定时间区间的日志
[root@localhost ~]# sed -n '/2020-02-19 14:10:00/,/2020-02-19 14:15:00/p elasticjob.log
2.10. 根据行首或行尾进行匹配
[root@localhost ~]# sed '/^pattern/d' input.txt
[root@localhost ~]# sed '/pattern$/d' input.txt
2.11. 打印行范围
[root@localhost ~]# sed '2,4p' 文件 打印第2行和第四行
[root@localhost ~]# sed '2,+3p' 文件 打印第2行和下面3行
五、awk
1. 取出文件中的多行
[root@localhost ~]# cat xx.txt | awk -F '' 'NR>=2 && NR<=5'
2. 取出文件中的最后一行
[root@localhost ~]# cat xx.txt | awk -F '' 'END {print}'
3. 取出文件中的最后一列
[root@localhost ~]# cat xx.txt | awk -F '' '{print $NF}'
4. 取出文件中的倒数第n列
[root@localhost ~]# cat xx.txt | awk -F '' '{print $(NF-1)}'
5. 取出某个时间段的日志
[root@localhost ~]# awk '$2>"14:10:10" && $2<"14:12:59"' elastic-job.log #遵循日志格式和列进行替换即可
六、sort排序、uniq去重
1. 了解知识
uv(独立访客): 访问网站的一个客户端为一个访客(IP)pv(访问量): 页面浏览量或点击量,用户每次刷新即被计算一次sort -k1 -rn 按照第一个字段进行倒序排序-k1 表示根据第一个字段(通常是数字)进行排序-r 表示按降序排列-n 表示按数字的大小进行排序uniq:用于删除相邻的重复行。默认情况下,uniq 只会删除相邻的重复行,因此通常与 sort 命令配合使用,以确保所有重复行都被处理。 -c: 这个选项表示 "count",即统计每个唯一行的出现次数。输出的结果会在每一行前显示该行的出现次数
2. 查看日志,根据访问IP统计出某个时间段uv
[root@localhost ~]# awk '$4>"[26/Apr/2023:21:00:00 +0800]" && $4<"[26/Apr/2023:22:00:00 +0800]"' /servers/nginx/logs/access.log | awk '{print $1}' |sort |uniq -c | wc -l10
3. 查看日志,根据日志中的访问IP进行UV分组,查看每天的总UV
[root@localhost ~]# awk '{print substr($4,2,11) " " $1}' /servers/nginx/logs/access.log | sort -r |uniq | awk '{uv[$1]++;next}END{for (ip in uv) print ip, uv[ip]}'16/Jan/2025 10
4. 查看日志,根据访问url统计出某个时间段pv
[root@localhost ~]# awk '$4>"[16/Jan/2025:11:00:00 +0800]" && $4<"[16/Jan/2025:12:00:00 +0800]"' ./access.log |wc -l
29
5. 查看日志,根据日志中的访问时间进行pv分组,查看每天的总PV
#使用substr函数($4代表时间的列,2,11代表时间列的第二个字符到第11个字符,即按年月日取)
[root@localhost ~]# awk '{print substr($4,2,11)}' /servers/nginx/logs/access.log | sort | uniq -c1 16/Jan/2025 /eureka/apps/CITYEYES-AMP/192.168.30.41:8892?status=UP&lastDirtyTimestamp=17327134445381 16/Jan/2025 /eureka/apps/CITYEYES-AMP/192.168.30.43:8892?status=UP&lastDirtyTimestamp=17327134389941 16/Jan/2025 /eureka/apps/CITYEYES-VAP/192.168.30.40:8891?status=UP&lastDirtyTimestamp=17332135700831 16/Jan/2025 /eureka/apps/CITYEYES-VAP/192.168.30.51:8891?status=UP&lastDirtyTimestamp=17327134466621 16/Jan/2025 /eureka/apps/CITYEYES-VFP/192.168.30.38:8890?status=UP&lastDirtyTimestamp=17327134390101 16/Jan/2025 /eureka/apps/CITYOS-DATA-MANAGEMENT/cityos-xueliang-std10.jdicity.local:cityos-data-management:8787?status=UP&lastDirtyTimestamp=17327134208521 16/Jan/2025 /eureka/apps/CITYOS-DATA-MANAGEMENT/cityos-xueliang-std16.jdicity.local:cityos-data-management:8787?status=UP&lastDirtyTimestamp=17327134390071 16/Jan/2025 /eureka/apps/CITYOS-GATEHUB-ADMIN/cityos-xueliang-std16.jdicity.local:cityos-gatehub-admin:9900?status=UP&lastDirtyTimestamp=17327134390071 16/Jan/2025 /eureka/apps/CITYOS-GATEHUB-GATEWAY/cityos-xueliang-std10.jdicity.local:cityos-gatehub-gateway:9901?status=UP&lastDirtyTimestamp=17327134390271 16/Jan/2025 /eureka/apps/CITYOS-GATEHUB-GATEWAY/cityos-xueliang-std16.jdicity.local:cityos-gatehub-gateway:9901?status=UP&lastDirtyTimestamp=173271343900615 16/Jan/2025 /eureka/apps/delta1 16/Jan/2025 /eureka/apps/MESSAGE-MODULE-CENTER/192.168.30.67:9088?status=UP&lastDirtyTimestamp=17327134389712 16/Jan/2025 /metrics1 16/Jan/2025 /signin
6. 统计每天访问URL的TOP3
#使用substr函数($4代表时间的列,2,11代表时间列的第二个字符到第11个字符,即按年月日取)
[root@localhost ~]# awk '{print substr($4,2,11)" " $7}' /servers/nginx/logs/access.log |sort |uniq -c | sort -rn | head -n 3
15 16/Jan/2025 /eureka/apps/delta
2 16/Jan/2025 /metrics
1 16/Jan/2025 /signin
总结
有不正确的地方请指正,后续随时补充更新!!!
相关文章:

正则表达式基础知识及grep、sed、awk常用命令
文章目录 前言一、正则表达式元字符和特性1. 字符匹配2. 量词3. 字符类4. 边界匹配5. 分词和捕获6. 特殊字符7. 位置锚定 二、grep常用参数1. -n额外输出行号2. -v 排除匹配的行3. -E 支持扩展正则匹配4. -e进行多规则匹配搜索5. -R 递归匹配目录中的文件内容6. -r递归地搜索目…...

redhat安装docker 24.0.7
1、下载docker镜像包 wget https://download.docker.com/linux/static/stable/x86_64/docker-24.0.7.tgz 2、解压 tar -xvf docker-24.0.7.tgz 3、解压的docker文件夹全部移动至/usr/bin目录 cd docker cp -p docker/* /usr/bin 4、注册服务 vi /usr/lib/systemd/syste…...

【excel】VBA简介(Visual Basic for Applications)
文章目录 一、基本概念二、语法2.1 数据类型2.11 基本数据类型2.12 常量2.13 数组 2.2 控制语句2.21 条件语句2.22 循环语句2.23 错误处理:On Error2.24 逻辑运算 2.3 其它语句2.31 注释2.32 with语句 2.4 表达式2.41 常见表达式类型2.42 表达式的优先级 2.5 VBA 的…...

【大厂面试AI算法题中的知识点】方向涉及:ML/DL/CV/NLP/大数据...本篇介绍为什么self-attention可以堆叠多层,这有什么作用?
【大厂面试AI算法题中的知识点】方向涉及:ML/DL/CV/NLP/大数据…本篇介绍为什么self-attention可以堆叠多层,这有什么作用? 【大厂面试AI算法题中的知识点】方向涉及:ML/DL/CV/NLP/大数据…本篇介绍为什么self-attention可以堆叠…...

NanoKVM简单开箱测评和拆解,让普通电脑实现BMC/IPMI远程管理功能
Sipeed推出了NanoKVM,简直是没有BMC的台式机和工作站的福音。有了这个就可以轻松实现以往服务器才有的远程管理功能。 NanoKVM 简介 Lichee NanoKVM 是基于 LicheeRV Nano 的 IP-KVM 产品,继承了 LicheeRV Nano 的极致体积 和 强大功能。 NanoKVM 包含…...

【Idea】编译Spring源码 read timeout 问题
Idea现在是大家工作中用的比较多的开发工具,尤其是做java开发的,那么做java开发,了解spring框架源码是提高自己技能水平的一个方式,所以会从spring 官网下载源码,导入到 Idea 工具并编译,但是发现build的时…...

VSCode的配置与使用(C/C++)
从0开始教你在vscode调试一个C文件 一.首先是配置你的编译环境,添加到环境变量(默认你是全新的电脑,没有安装vs2019之类的) 原因:因为相比于vs2019,vscode只是个代码编辑器,相当于一个彩色的、…...

SpringMVC (1)
目录 1. 什么是Spring Web MVC 1.1 MVC的定义 1.2 什么是Spring MVC 1.3 Spring Boot 1.3.1 创建一个Spring Boot项目 1.3.2 Spring Boot和Spring MVC之间的关系 2. 学习Spring MVC 2.1 SpringBoot 启动类 2.2 建立连接 1. 什么是Spring Web MVC 1.1 MVC的定义 MVC 是…...

本地部署大模型—MiniCPM-V 2.0: 具备领先OCR和理解能力的高效端侧多模态大模型
MiniCPM-V 2.0: 具备领先OCR和理解能力的高效端侧多模态大模型 简介 MiniCPM 系列的最新多模态版本 MiniCPM-V 2.0。该模型基于 [MiniCPM 2.4B和 SigLip-400M 构建,共拥有 2.8B 参数。MiniCPM-V 2.0 具有领先的光学字符识别(OCR)和多模态理解能力。该模型在综合性 OCR 能力…...

国产linux系统(银河麒麟,统信uos)使用 PageOffice 实现后台批量生成PDF文档
PageOffice 国产版 :支持信创系统,支持银河麒麟V10和统信UOS,支持X86(intel、兆芯、海光等)、ARM(飞腾、鲲鹏、麒麟等)、龙芯(LoogArch)芯片架构。 PageOffice 版本&…...

Python 扫描枪读取发票数据导入Excel
财务需要一个扫描枪扫描发票文件,并将主要信息录入Excel 的功能。 文件中sheet表的列名称,依次为:发票编号、发票编码、日期、金额、工号、扫描日期。 扫描的时候,Excel 文件需要关闭,否则会报错。 import openpyxl …...
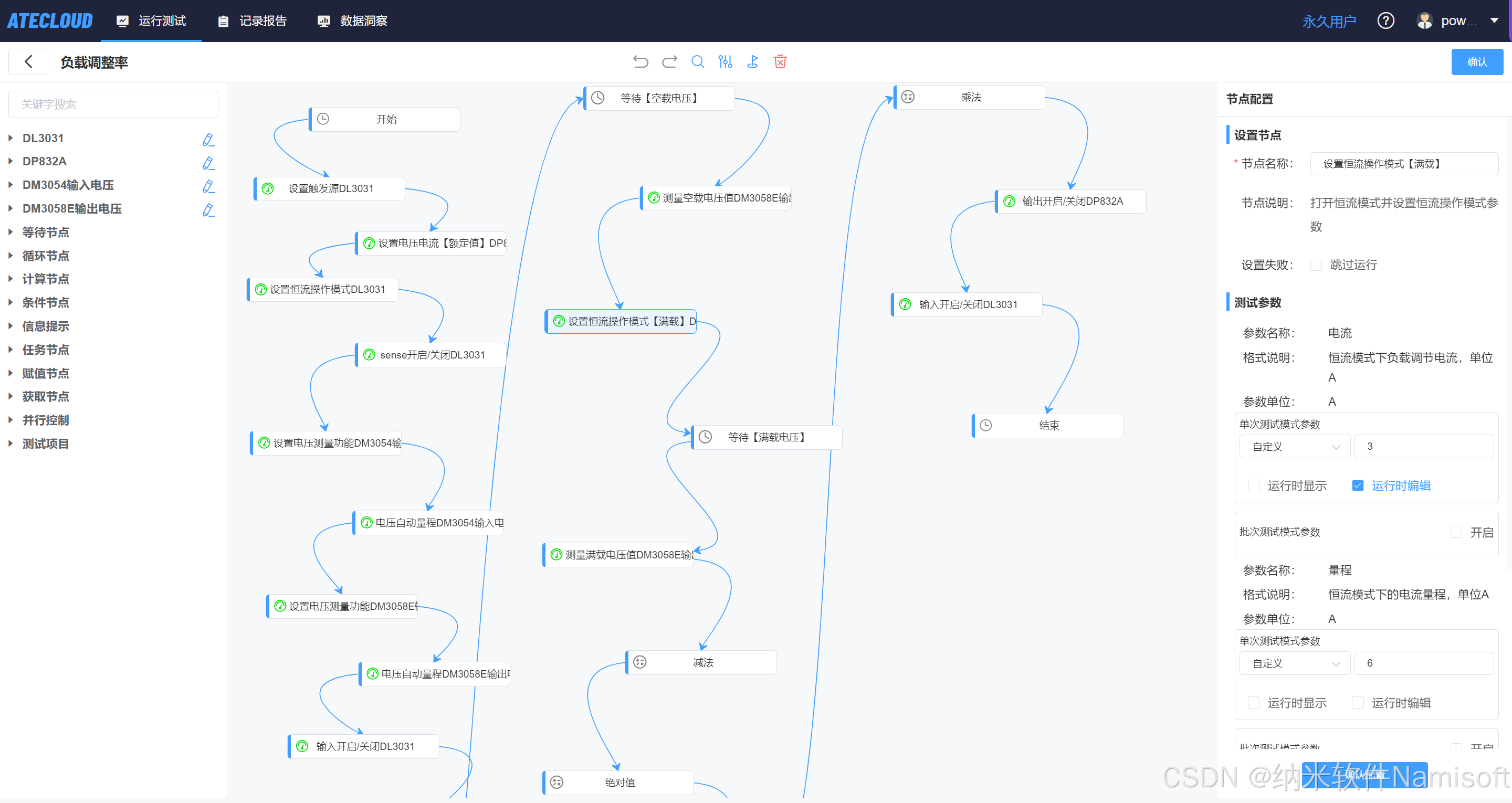
电源自动测试系统中的ate定制化包含哪些内容?
1. 测试项目和指标 基础测试项目:虽然大多数电源模块的基础测试项目(如输入输出电压、电流、效率等)已经包含在测试系统中,但针对特殊或小众的测试项目,如VPX电源测试时的通讯验证,可以根据客户需求进行定…...

人工智能-机器学习之多分类分析(项目实战二-鸢尾花的多分类分析)
Softmax回归听名字,依然好像是做回归任务的算法,但其实它是去做多分类任务的算法。 篮球比赛胜负是二分类,足球比赛胜平负就是多分类 识别手写数字0和1是二分类,识别手写数字0-9就是多分类 Softmax回归算法是一种用于多分类问题…...

多包单仓库(monorepo)实现形式
目录 背景 需求和方案 从0开始搭建一个Monorepo项目 创建 配置全局公共样式 配置全局公共组件 方式1:不需要独立发布的组件包,只在当前项目的子项目中使用 方式2:需要独立发布和版本维护的包 子项目的独立构建和部署 总结 Monorepo优势 便于代码维护、管理 支持…...

Java冒泡排序算法之:变种版
什么是冒泡排序算法? 冒泡排序是一种简单的排序算法,通过多次遍历待排序的数组,逐步将最大的(或最小的)元素“冒泡”到数组的一端。它以其操作过程类似气泡从水底冒至水面而得名。 冒泡排序的工作原理 比较相邻元素&…...

AAPM:基于大型语言模型代理的资产定价模型,夏普比率提高9.6%
“AAPM: Large Language Model Agent-based Asset Pricing Models” 论文地址:https://arxiv.org/pdf/2409.17266v1 Github地址:https://github.com/chengjunyan1/AAPM 摘要 这篇文章介绍了一种利用LLM代理的资产定价模型(AAPM)…...

Spring常见知识
1、什么是spring的ioc? 其实就是控制反转,提前定义了一个bean,到时候使用的时候直接autowire就可以了。目的是减低计算机代码之间的耦合度。 创建三个文件,分别是Bean的定义、Bean的使用、Bean的配置。 IOC通过将对象创建和管理…...

计算机网络的五层协议
计算机网络的五层协议 计算机网络的五层协议模型包括物理层、数据链路层、网络层、传输层和应用层,每一层都有其特定的功能和相关的协议。1 物理层:负责传输原始的比特流,通过线路(有线或无线)将数据转换为…...
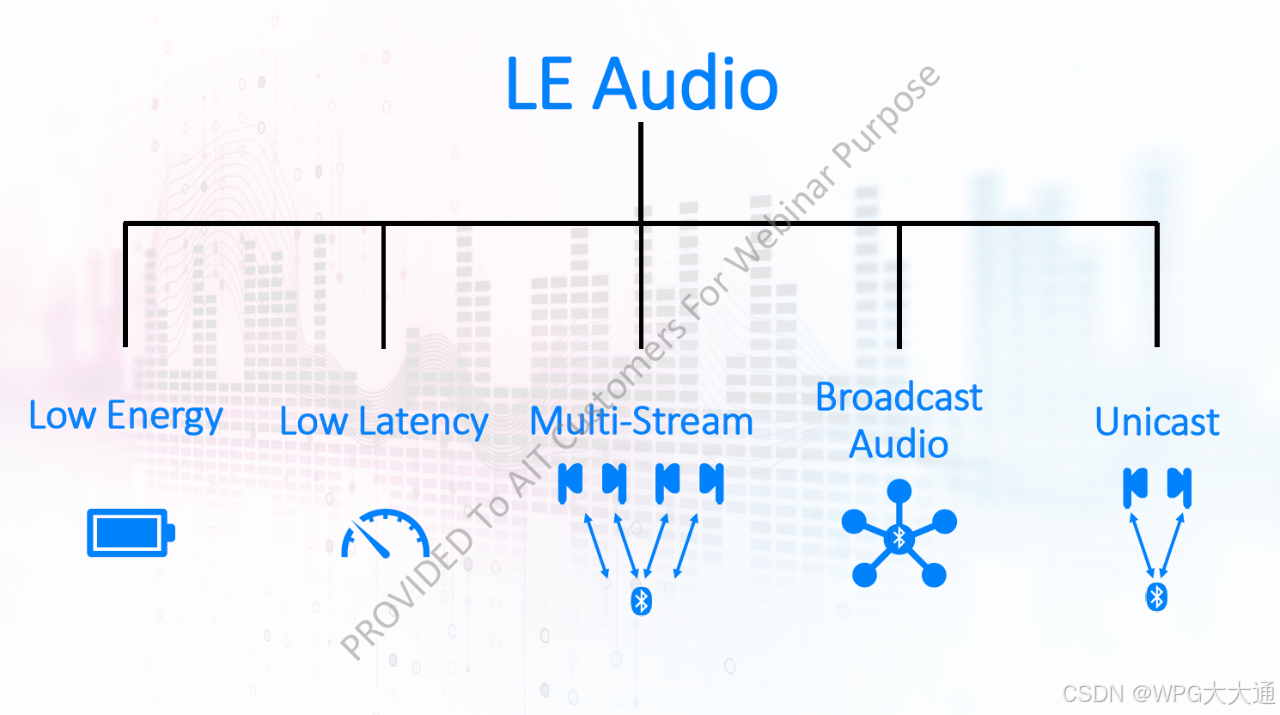
Bluetooth LE Audio - 蓝牙无线音频新应用 (上)
SIG联盟(Bluetooth Special Interest Group)自2020年开始推广新的LE Audio,在穿戴式装置掀起一股热潮,各个品牌商、制造商、第三方软件商都积极的寻找新的LE Audio规格究竟能提供什么样的新应用。究竟LE Audio如何改变你我的生活、…...

如何快速准备数学建模?
前言 大家好,我是fanstuck。数学建模不仅是解决复杂现实问题的一种有效工具,也是许多学科和行业中的关键技能。从工程、经济到生物、环境等多个领域,数学建模为我们提供了将实际问题转化为数学形式,并利用数学理论和方法进行求解的强大能力。然而,对于许多初学者而言,如…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...
)
Windows10下V-REP教育版安装保姆级教程(附百度网盘资源与避坑点)
Windows10系统V-REP教育版完整安装指南:从下载到实战避坑在机器人仿真和自动化控制领域,V-REP(现更名为CoppeliaSim)作为一款功能强大的跨平台机器人仿真软件,已经成为众多工科学生和研究人员的首选工具。特别是其教育…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

对比不同模型在创意生成任务中的效果与token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比不同模型在创意生成任务中的效果与token消耗差异 在为一场创意大赛准备素材时,我们面临一个常见的选择:…...

如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器
如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为想和朋友一起玩游戏却只有一台电脑而烦…...

3步掌握OpenSpeedy:免费开源游戏加速工具使用指南
3步掌握OpenSpeedy:免费开源游戏加速工具使用指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否曾为游戏卡顿而烦恼?是否希望在单机游戏中加快…...

开发者在构建多模态AI应用时如何借助TaoToken简化模型集成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发者在构建多模态AI应用时如何借助TaoToken简化模型集成 构建一个集成了文本、图像等多模态能力的AI应用,开发者常常…...

基于特征工程的电力系统虚假数据注入攻击检测方案
1. 项目概述与核心挑战在电力系统这个庞大而精密的“交响乐团”中,自动发电控制(AGC)系统扮演着指挥家的角色。它的核心任务是根据电网频率和联络线功率的微小波动,实时调整各发电机的出力,确保整个电网的频率稳定在50…...