【2024年华为OD机试】 (C卷,200分)- 反射计数(Java JS PythonC/C++)

一、问题描述
题目解析
题目描述
给定一个包含 0 和 1 的二维矩阵,一个物体从给定的初始位置出发,在给定的速度下进行移动。遇到矩阵的边缘时会发生镜面反射。无论物体经过 0 还是 1,都不影响其速度。请计算并给出经过 t 时间单位后,物体经过 1 点的次数。
输入描述
-
第一行为初始信息:
<w> <h> <x> <y> <sx> <sy> <t>w和h为矩阵的宽和高。x和y为起始位置。sx和sy为初始速度。t为经过的时间。
-
第二行开始一共
h行,为二维矩阵信息。
输出描述
输出经过 1 的个数。注意初始位置也要计算在内。
用例
输入
12 7 2 1 1 -1 13
001000010000
001000010000
001000010000
001000010000
001000010000
001000010000
001000010000
输出
3
说明
- 初始位置为
(2, 1),速度为(1, -1)。 - 经过 13 个时间单位后,物体经过
1的个数为3。
题目解析
问题分析
-
目标
计算物体在t时间单位内经过1的点的次数。 -
关键点
- 物体在矩阵中移动,遇到边缘时会发生镜面反射。
- 每次移动的时间单位为
1,不考虑小于1个时间单位内经过的点。 - 初始位置如果是
1,也要计算在内。
-
问题转化
模拟物体在矩阵中的移动过程,记录经过1的点的次数。
解题思路
-
初始化
- 读取矩阵的宽
w和高h。 - 读取初始位置
(x, y)和速度(sx, sy)。 - 读取时间
t。 - 读取矩阵数据。
- 读取矩阵的宽
-
模拟移动过程
- 对于每个时间单位,更新物体的位置。
- 如果位置超出矩阵边界,则进行镜面反射,并调整速度方向。
- 检查当前位置是否为
1,如果是,则计数加1。
-
输出结果
- 输出经过
1的点的次数。
- 输出经过
示例分析
输入
12 7 2 1 1 -1 13
001000010000
001000010000
001000010000
001000010000
001000010000
001000010000
001000010000
步骤
-
初始化:
w = 12,h = 7。- 初始位置
(x, y) = (2, 1)。 - 速度
(sx, sy) = (1, -1)。 - 时间
t = 13。 - 矩阵数据:
001000010000 001000010000 001000010000 001000010000 001000010000 001000010000 001000010000
-
模拟移动过程:
- 初始位置
(2, 1)是1,计数加1。 - 移动 13 个时间单位,每次更新位置并检查是否为
1。 - 经过 13 个时间单位后,物体经过
1的点的次数为3。
- 初始位置
-
输出结果:
3。
复杂度分析
-
时间复杂度
- 模拟移动过程的时间复杂度为
O(t),其中t是时间单位。 - 总时间复杂度为
O(t)。
- 模拟移动过程的时间复杂度为
-
空间复杂度
- 存储矩阵数据的空间复杂度为
O(w * h)。 - 总空间复杂度为
O(w * h)。
- 存储矩阵数据的空间复杂度为
总结
本题的核心是通过模拟物体在矩阵中的移动过程,记录经过 1 的点的次数。关键在于:
- 处理物体在矩阵边缘的镜面反射。
- 每次移动后检查当前位置是否为
1。 - 时间复杂度为
O(t),适合处理t较小的输入。
二、JavaScript算法源码
这段 JavaScript 代码的功能是模拟一个在矩阵中“移动”的过程,并根据指定的规则统计符合条件的格子数。以下是代码的逐步解析。
代码概述
-
输入
w、h:矩阵的宽度和高度(列数和行数)。x、y:起始位置的横坐标和纵坐标(列号和行号)。sx、sy:水平和垂直的速度,表示每次移动的步数。t:模拟的最大时间步数。
-
矩阵
- 输入的矩阵由字符
'0'和'1'组成,其中'1'代表一个特定的目标。
- 输入的矩阵由字符
-
目标
- 目标是根据给定的规则在矩阵中移动并统计遇到的
'1'的个数。
- 目标是根据给定的规则在矩阵中移动并统计遇到的
逐行分析
const rl = require("readline").createInterface({ input: process.stdin });
var iter = rl[Symbol.asyncIterator]();
const readline = async () => (await iter.next()).value;
- 使用 Node.js 的
readline模块来异步读取输入。 iter是readline的异步迭代器,通过readline()获取每一行输入。
let [w, h, x, y, sx, sy, t] = (await readline()).split(" ").map(Number);
- 读取输入的第一行,并将其拆分成数字:
w:矩阵的列数。h:矩阵的行数。x:起始的列坐标(水平坐标)。y:起始的行坐标(纵坐标)。sx:水平移动步数(速度)。sy:垂直移动步数(速度)。t:移动的最大步数(时间)。
const matrix = [];
for (let i = 0; i < h; i++) {matrix.push(await readline());
}
- 初始化一个空的二维矩阵
matrix。 - 使用
for循环读取h行,填充matrix。
let ans = 0;
ans用于记录遇到的'1'的数量。
while (t >= 0) {if (matrix[y][x] == "1") {ans++;}
- 开始一个
while循环,循环次数为t。 - 如果当前位置的格子是
'1',则统计计数器ans加 1。
y += sy;x += sx;
- 更新位置,
y按照垂直方向的速度sy变化,x按照水平方向的速度sx变化。
if (x < 0) {x = 1;sx = -sx;} else if (x >= w) {x = w - 2;sx = -sx;}
- 检查
x(列坐标)是否越界:- 如果
x小于 0(即超出了左边界),将x设为 1,并且反转水平移动速度sx(使其向右)。 - 如果
x超出了右边界(即x >= w),将x设为w - 2,并反转水平速度sx(使其向左)。
- 如果
if (y < 0) {y = 1;sy = -sy;} else if (y >= h) {y = h - 2;sy = -sy;}
- 检查
y(行坐标)是否越界:- 如果
y小于 0(即超出了上边界),将y设为 1,并反转垂直移动速度sy(使其向下)。 - 如果
y超出了下边界(即y >= h),将y设为h - 2,并反转垂直速度sy(使其向上)。
- 如果
t--;
}
- 每次循环结束后,减少
t,表示已经消耗了一个时间步。
console.log(ans);
- 输出统计的
'1'的数量,即在矩阵中遇到的目标数。
总结
-
问题本质:
- 这段代码模拟了一个物体在矩阵中根据给定的规则进行移动的过程。
- 如果当前位置是
'1',就增加计数器,最终输出计数器的值。
-
坐标的变化和边界处理:
- 通过检查坐标是否越界,并反转方向的方式确保物体在矩阵中“反弹”。
- 水平和垂直坐标的处理是独立的,根据具体的方向反转速度。
-
边界处理:
- 代码中明确处理了矩阵的上下左右边界,一旦超出边界,坐标反转。
输入输出示例
假设输入如下:
5 5 0 0 1 1 10
00000
00000
00100
00000
00000
w = 5, h = 5:矩阵的大小为 5x5。x = 0, y = 0:起始坐标是左上角。sx = 1, sy = 1:每次水平方向和垂直方向都移动 1 步。t = 10:模拟 10 步。
矩阵如下:
00000
00000
00100
00000
00000
- 起始时,坐标
(0, 0)处的值是'0',然后按规则向下、向右移动。 - 每次遇到
'1'统计一次。 - 代码会输出在 10 步内遇到的
'1'的个数。
三、Java算法源码
这段 Java 代码的功能与之前的 JavaScript 代码类似,目的是在矩阵中模拟一个物体的移动过程,并根据规则统计移动过程中经过的 '1' 的数量。让我们逐行分析这段代码:
代码分析
import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner sc = new Scanner(System.in);
- 使用
Scanner类读取输入数据。sc是一个Scanner对象,用于从标准输入读取数据。
int w = sc.nextInt();int h = sc.nextInt();int x = sc.nextInt();int y = sc.nextInt();int sx = sc.nextInt();int sy = sc.nextInt();int t = sc.nextInt();
- 读取输入数据:矩阵的宽度
w、高度h,起始位置(x, y),每步的水平和垂直速度sx和sy,以及模拟的最大时间步数t。
char[][] matrix = new char[h][w];for (int i = 0; i < h; i++) {matrix[i] = sc.next().toCharArray();}
- 初始化一个二维字符数组
matrix,用于存储矩阵中的每个字符。 - 使用循环读取矩阵的每一行,并将其转换为字符数组存储在
matrix中。
int ans = 0;
- 初始化
ans变量,用于统计遇到的'1'的数量。
while (t >= 0) {
- 开始一个
while循环,直到t为负,表示已经完成所有时间步。
if (matrix[y][x] == '1') {ans++;}
- 检查当前位置的格子是否为
'1',如果是,增加ans。
y += sy;x += sx;
- 更新当前位置
(x, y)。y按垂直方向速度sy变化,x按水平方向速度sx变化。
if (x < 0) {x = 1;sx = -sx;} else if (x >= w) {x = w - 2;sx = -sx;}
- 判断水平方向的越界情况:
- 如果
x小于 0(即超出了左边界),将x设置为 1,并反转水平方向速度sx(即使得物体向右移动)。 - 如果
x超过了右边界(即x >= w),将x设置为w - 2,并反转水平方向速度sx(即使得物体向左移动)。
- 如果
if (y < 0) {y = 1;sy = -sy;} else if (y >= h) {y = h - 2;sy = -sy;}
- 判断垂直方向的越界情况:
- 如果
y小于 0(即超出了上边界),将y设置为 1,并反转垂直方向速度sy(即使得物体向下移动)。 - 如果
y超过了下边界(即y >= h),将y设置为h - 2,并反转垂直方向速度sy(即使得物体向上移动)。
- 如果
t--;}
- 每次循环结束后,减少
t,表示时间步数已经消耗。
System.out.println(ans);}
}
- 输出统计结果
ans,即在整个过程中遇到的'1'的数量。
总结
这段 Java 代码模拟了一个物体在一个矩阵中按给定规则移动的过程,并统计经过的 '1' 的数量。代码中的关键步骤包括:
- 输入处理:通过
Scanner读取矩阵的尺寸、起始坐标、速度以及最大时间步数。 - 矩阵处理:根据输入的矩阵,使用二维数组
matrix存储每个格子的值('0'或'1')。 - 边界检测:在每次移动后,检查是否越界,如果越界则反转物体的移动方向,并根据规则修正坐标。
- 统计
'1'的数量:在每个时间步,检查当前位置是否是'1',如果是则增加计数。
示例输入输出
假设输入如下:
5 5 0 0 1 1 10
00000
00000
00100
00000
00000
w = 5, h = 5:矩阵的宽度和高度分别为 5 和 5。x = 0, y = 0:起始位置为左上角。sx = 1, sy = 1:每次水平方向和垂直方向都移动 1 步。t = 10:模拟 10 步。
矩阵如下:
00000
00000
00100
00000
00000
输出:
1
代码的复杂度分析
-
时间复杂度:每次循环中,更新位置、检查边界、统计
'1'等操作都是常数时间操作。最坏情况下,循环会执行t次,所以时间复杂度是O(t)。 -
空间复杂度:存储矩阵的空间复杂度是
O(w * h),即矩阵的大小。
因此,整体的时间复杂度为 O(t),空间复杂度为 O(w * h)。
四、Python算法源码
下面是对这段 Python 代码的详细注释和讲解:
1. 输入部分
w, h, x, y, sx, sy, t = map(int, input().split())
matrix = [input() for _ in range(h)]
-
w, h, x, y, sx, sy, t = map(int, input().split()):- 使用
input().split()获取一行输入并将其按空格分割,然后用map(int, ...)将所有值转换为整数。它们分别代表:w:矩阵的列数(宽度)。h:矩阵的行数(高度)。x:起始列坐标(水平坐标)。y:起始行坐标(垂直坐标)。sx:水平移动的速度(步长)。sy:垂直移动的速度(步长)。t:总的时间步数,模拟物体移动的步数。
- 使用
-
matrix = [input() for _ in range(h)]:- 这里使用列表推导式,循环
h次,读取每一行矩阵并存储为字符列表。每行是一个字符串,表示矩阵中的一行。 - 例如,若输入矩阵的某一行是
00100,则matrix[i]将是这个字符串。
- 这里使用列表推导式,循环
2. 算法部分
def getResult():global x, y, sx, sy, tans = 0
- 定义
getResult函数,其中global x, y, sx, sy, t表示在该函数中会使用和修改外部定义的变量x, y, sx, sy, t。 ans = 0:初始化一个变量ans来统计遇到的'1'的数量。
while t >= 0:
- 进入一个
while循环,循环的条件是t >= 0。每次循环代表一次时间步长,直到t减少为负值为止。
if matrix[y][x] == '1':ans += 1
- 在当前的坐标
(x, y)位置,检查矩阵中的字符是否为'1'。如果是'1',就将ans加 1,表示遇到一个目标。
y += syx += sx
- 更新当前坐标
(x, y):y += sy:垂直坐标y按照垂直速度sy更新,向上或向下移动。x += sx:水平坐标x按照水平速度sx更新,向左或向右移动。
if x < 0:x = 1sx = -sxelif x >= w:x = w - 2sx = -sx
- 处理水平边界:
- 如果
x < 0(即移动超出了左边界),则将x设置为 1,并反转水平速度sx(即使得物体开始向右移动)。 - 如果
x >= w(即移动超出了右边界),则将x设置为w - 2(确保物体不再越过边界),并反转水平速度sx(即物体开始向左移动)。
- 如果
if y < 0:y = 1sy = -syelif y >= h:y = h - 2sy = -sy
- 处理垂直边界:
- 如果
y < 0(即移动超出了上边界),则将y设置为 1,并反转垂直速度sy(即物体开始向下移动)。 - 如果
y >= h(即移动超出了下边界),则将y设置为h - 2(确保物体不再越过边界),并反转垂直速度sy(即物体开始向上移动)。
- 如果
t -= 1
- 每次循环后,减少
t,表示已经消耗了一个时间步。
3. 返回结果
return ans
- 当时间步数
t用完时,返回统计的结果ans,即物体经过的'1'的总数。
4. 算法调用部分
print(getResult())
- 调用
getResult()函数并打印返回的结果,输出遇到的'1'的数量。
完整工作流程
-
输入数据:
- 程序首先从用户输入中读取矩阵的尺寸、起始位置、速度和最大时间步数。
- 然后读取矩阵的内容,每个字符代表矩阵中的一部分。
-
模拟运动:
- 在矩阵中从起始位置
(x, y)开始,按照给定的速度sx和sy移动。 - 每一步移动后检查当前位置是否是
'1',如果是,则增加ans计数。 - 碰到矩阵边界时,会反转运动方向,继续在矩阵中反弹。
- 在矩阵中从起始位置
-
返回结果:
- 当经过所有时间步
t后,返回统计的'1'数量。
- 当经过所有时间步
示例说明
假设输入如下:
5 5 0 0 1 1 10
00000
00000
00100
00000
00000
w = 5, h = 5:矩阵的宽度和高度是 5。x = 0, y = 0:起始位置在矩阵的左上角。sx = 1, sy = 1:每次水平方向和垂直方向都移动 1 步。t = 10:模拟 10 步。
矩阵如下:
00000
00000
00100
00000
00000
运行过程:
- 从起始位置
(0, 0)开始,向右向下移动。 - 第 3 步时,物体移动到
(2, 2),矩阵位置是'1',计数器ans加 1。 - 随后物体反弹继续移动,直到时间步数
t结束。
输出结果:
1
总结
这段代码通过模拟一个物体在矩阵中的移动,并根据碰到的 '1' 进行计数,最终输出物体经过的 '1' 的个数。关键的技术点包括边界检测和反弹的处理,每次越界时反转方向,确保物体不超出矩阵的范围。
五、C/C++算法源码:
模拟了一个物体在矩阵中按指定的速度移动,并统计它经过的 '1' 的数量。我们将逐步讲解每个部分,并转换为 C++ 版本。
C 语言代码转换为 C++ 代码
1. C 语言代码部分:
#include <stdio.h>#define MAX_SIZE 100int main() {int w, h, x, y, sx, sy, t;scanf("%d %d %d %d %d %d %d", &w, &h, &x, &y, &sx, &sy, &t);getchar();char matrix[MAX_SIZE][MAX_SIZE];for (int i = 0; i < h; i++) {gets(matrix[i]);}int ans = 0;while (t >= 0) {// 注意本题横纵坐标是反的,因此y其实是行号,x是列号if (matrix[y][x] == '1') {ans++;}y += sy;x += sx;if (x < 0) {x = 1;sx = -sx;} else if (x >= w) { // 注意本题横纵坐标是反的,因此x是列号,w是矩阵列数x = w - 2;sx = -sx;}if (y < 0) {y = 1;sy = -sy;} else if (y >= h) { // 注意本题横纵坐标是反的,因此y是行号,h是矩阵行数y = h - 2;sy = -sy;}t--;}printf("%d\n", ans);return 0;
}
转换为 C++ 代码
在 C++ 中,我们通常使用 iostream 来替代 stdio.h 来进行输入输出,使用 std::vector 或 std::string 来管理矩阵而不是固定大小的数组。我们还要避免使用 gets(),因为它已经被废弃。我们改为使用 std::cin 和 std::getline() 来读取输入。
C++ 代码
#include <iostream>
#include <vector>
#include <string>#define MAX_SIZE 100using namespace std;int main() {int w, h, x, y, sx, sy, t;// 读取矩阵的宽度、高度、起始位置、速度和时间cin >> w >> h >> x >> y >> sx >> sy >> t;cin.ignore(); // 读取整行数据时,忽略前面换行符vector<string> matrix(h); // 使用 string 类型的 vector 存储每行的矩阵for (int i = 0; i < h; i++) {getline(cin, matrix[i]); // 读取每行矩阵}int ans = 0;while (t >= 0) {// 检查当前位置是否是 '1'if (matrix[y][x] == '1') {ans++;}// 更新当前位置y += sy;x += sx;// 水平方向越界检测if (x < 0) {x = 1;sx = -sx;} else if (x >= w) {x = w - 2;sx = -sx;}// 垂直方向越界检测if (y < 0) {y = 1;sy = -sy;} else if (y >= h) {y = h - 2;sy = -sy;}t--; // 每次模拟步数减 1}cout << ans << endl; // 输出遇到的 '1' 的数量return 0;
}
详细注释和讲解
1. 输入处理
cin >> w >> h >> x >> y >> sx >> sy >> t;
cin.ignore();
cin >> w >> h >> x >> y >> sx >> sy >> t;:通过cin从标准输入读取 7 个整数,分别代表矩阵的宽度w、高度h,起始位置(x, y),水平速度sx,垂直速度sy,以及最大时间步数t。cin.ignore();:在读取完整数后,使用cin.ignore()忽略掉换行符,防止在读取矩阵时受到干扰。
2. 矩阵输入
vector<string> matrix(h);
for (int i = 0; i < h; i++) {getline(cin, matrix[i]);
}
vector<string> matrix(h);:使用vector<string>来存储矩阵,h表示矩阵的行数。getline(cin, matrix[i]);:每行输入用getline来读取。getline读取一整行并存储为字符串。
3. 变量初始化
int ans = 0;
ans用来统计经过的'1'的数量,初始值为 0。
4. 模拟过程
while (t >= 0) {if (matrix[y][x] == '1') {ans++;}y += sy;x += sx;if (x < 0) {x = 1;sx = -sx;} else if (x >= w) {x = w - 2;sx = -sx;}if (y < 0) {y = 1;sy = -sy;} else if (y >= h) {y = h - 2;sy = -sy;}t--;
}
while (t >= 0):每次循环代表一个时间步,直到t小于 0 为止。if (matrix[y][x] == '1') { ans++; }:检查当前坐标(x, y)是否为'1',如果是则ans增加 1。y += sy; x += sx;:更新当前位置(x, y),根据水平速度sx和垂直速度sy移动。- 边界检测:
- 水平方向:如果
x < 0,表示超出了左边界,则将x设置为 1,并反转水平速度sx;如果x >= w,表示超出了右边界,则将x设置为w - 2,并反转水平速度sx。 - 垂直方向:如果
y < 0,表示超出了上边界,则将y设置为 1,并反转垂直速度sy;如果y >= h,表示超出了下边界,则将y设置为h - 2,并反转垂直速度sy。
- 水平方向:如果
- 每次时间步结束后,
t--。
5. 输出结果
cout << ans << endl;
- 输出统计到的
ans,即遇到的'1'的数量。
总结
- 本代码模拟了一个物体在一个矩阵中按照给定的速度进行移动,并统计物体经过的
'1'数量。 - 使用
vector<string>存储矩阵内容,避免了固定大小数组的限制,同时也更方便处理动态大小的矩阵。 - 边界检测和反弹处理确保物体在矩阵边缘反弹,而不是超出边界。
- 最后通过
cout输出遇到的'1'的总数。
示例输入输出
输入:
5 5 0 0 1 1 10
00000
00000
00100
00000
00000
输出:
1
六、尾言
什么是华为OD?
华为OD(Outsourcing Developer,外包开发工程师)是华为针对软件开发工程师岗位的一种招聘形式,主要包括笔试、技术面试以及综合面试等环节。尤其在笔试部分,算法题的机试至关重要。
为什么刷题很重要?
-
机试是进入技术面的第一关:
华为OD机试(常被称为机考)主要考察算法和编程能力。只有通过机试,才能进入后续的技术面试环节。 -
技术面试需要手撕代码:
技术一面和二面通常会涉及现场编写代码或算法题。面试官会注重考察候选人的思路清晰度、代码规范性以及解决问题的能力。因此提前刷题、多练习是通过面试的重要保障。 -
入职后的可信考试:
入职华为后,还需要通过“可信考试”。可信考试分为三个等级:- 入门级:主要考察基础算法与编程能力。
- 工作级:更贴近实际业务需求,可能涉及复杂的算法或与工作内容相关的场景题目。
- 专业级:最高等级,考察深层次的算法以及优化能力,与薪资直接挂钩。
刷题策略与说明:
2024年8月14日之后,华为OD机试的题库转为 E卷,由往年题库(D卷、A卷、B卷、C卷)和全新题目组成。刷题时可以参考以下策略:
-
关注历年真题:
- 题库中的旧题占比较大,建议优先刷历年的A卷、B卷、C卷、D卷题目。
- 对于每道题目,建议深度理解其解题思路、代码实现,以及相关算法的适用场景。
-
适应新题目:
- E卷中包含全新题目,需要掌握全面的算法知识和一定的灵活应对能力。
- 建议关注新的刷题平台或交流群,获取最新题目的解析和动态。
-
掌握常见算法:
华为OD考试通常涉及以下算法和数据结构:- 排序算法(快速排序、归并排序等)
- 动态规划(背包问题、最长公共子序列等)
- 贪心算法
- 栈、队列、链表的操作
- 图论(最短路径、最小生成树等)
- 滑动窗口、双指针算法
-
保持编程规范:
- 注重代码的可读性和注释的清晰度。
- 熟练使用常见编程语言,如C++、Java、Python等。
如何获取资源?
-
官方参考:
- 华为招聘官网或相关的招聘平台会有一些参考信息。
- 华为OD的相关公众号可能也会发布相关的刷题资料或学习资源。
-
加入刷题社区:
- 找到可信的刷题交流群,与其他备考的小伙伴交流经验。
- 关注知名的刷题网站,如LeetCode、牛客网等,这些平台上有许多华为OD的历年真题和解析。
-
寻找系统性的教程:
- 学习一本经典的算法书籍,例如《算法导论》《剑指Offer》《编程之美》等。
- 完成系统的学习课程,例如数据结构与算法的在线课程。
积极心态与持续努力:
刷题的过程可能会比较枯燥,但它能够显著提升编程能力和算法思维。无论是为了通过华为OD的招聘考试,还是为了未来的职业发展,这些积累都会成为重要的财富。
考试注意细节
-
本地编写代码
- 在本地 IDE(如 VS Code、PyCharm 等)上编写、保存和调试代码,确保逻辑正确后再复制粘贴到考试页面。这样可以减少语法错误,提高代码准确性。
-
调整心态,保持冷静
- 遇到提示不足或实现不确定的问题时,不必慌张,可以采用更简单或更有把握的方法替代,确保思路清晰。
-
输入输出完整性
- 注意训练和考试时都需要编写完整的输入输出代码,尤其是和题目示例保持一致。完成代码后务必及时调试,确保功能符合要求。
-
快捷键使用
- 删除行可用
Ctrl+D,复制、粘贴和撤销分别为Ctrl+C,Ctrl+V,Ctrl+Z,这些可以正常使用。 - 避免使用
Ctrl+S,以免触发浏览器的保存功能。
- 删除行可用
-
浏览器要求
- 使用最新版的 Google Chrome 浏览器完成考试,确保摄像头开启并正常工作。考试期间不要切换到其他网站,以免影响考试成绩。
-
交卷相关
- 答题前,务必仔细查看题目示例,避免遗漏要求。
- 每完成一道题后,点击【保存并调试】按钮,多次保存和调试是允许的,系统会记录得分最高的一次结果。完成所有题目后,点击【提交本题型】按钮。
- 确保在考试结束前提交试卷,避免因未保存或调试失误而丢分。
-
时间和分数安排
- 总时间:150 分钟;总分:400 分。
- 试卷结构:2 道一星难度题(每题 100 分),1 道二星难度题(200 分)。及格分为 150 分。合理分配时间,优先完成自己擅长的题目。
-
考试环境准备
- 考试前请备好草稿纸和笔。考试中尽量避免离开座位,确保监控画面正常。
- 如需上厕所,请提前规划好时间以减少中途离开监控的可能性。
-
技术问题处理
- 如果考试中遇到断电、断网、死机等技术问题,可以关闭浏览器并重新打开试卷链接继续作答。
- 出现其他问题,请第一时间联系 HR 或监考人员进行反馈。
祝你考试顺利,取得理想成绩!
相关文章:
【2024年华为OD机试】 (C卷,200分)- 反射计数(Java JS PythonC/C++)
一、问题描述 题目解析 题目描述 给定一个包含 0 和 1 的二维矩阵,一个物体从给定的初始位置出发,在给定的速度下进行移动。遇到矩阵的边缘时会发生镜面反射。无论物体经过 0 还是 1,都不影响其速度。请计算并给出经过 t 时间单位后&#…...

AI编程工具使用技巧——通义灵码
活动介绍通义灵码1. 理解通义灵码的基本概念示例代码生成 2. 使用明确的描述示例代码生成 3. 巧妙使用注释示例代码生成 4. 注意迭代与反馈原始代码反馈后生成优化代码 5. 结合生成的代码进行调试示例测试代码 其他功能定期优化生成的代码合作与分享结合其他工具 总结 活动介绍…...

挖掘机检测数据集,准确识别率91.0%,4327张原始图片,支持YOLO,COCO JSON,PASICAL VOC XML等多种格式标注
挖掘机检测数据集,准确识别率91.0%,4327张图片,支持YOLO,COCO JSON,PASICAL VOC XML等多种格式标注 数据集详情 数据集分割 训练组70% 3022图片 有效集20% 870图片 测试集10&…...

使用Docker部署postgresql
使用Docker部署postgresql postgresql数据库在Docker中的镜像的名称为postgres,可以从DockerHub中pull下来,如果pull不下来那么很大概率是网络问题导致的,这时候你可能需要在网上找一些能用的镜像源,以成功拉取postgres镜像。 有…...
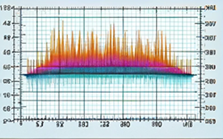
LabVIEW时域近场天线测试
随着通信技术的飞速发展,特别是在5G及未来通信技术中,天线性能的测试需求日益增加。对于短脉冲天线和宽带天线的时域特性测试,传统的频域测试方法已无法满足其需求。时域测试方法在这些应用中具有明显优势,可以提供更快速和精准的…...

LabVIEW桥接传感器数据采集与校准程序
该程序设计用于采集来自桥接传感器的数据,执行必要的设置(如桥接配置、信号采集参数、时间与触发设置),并进行适当的标定和偏移校正,最终通过图表呈现采集到的数据信息。程序包括多个模块,用于配置通道、触…...
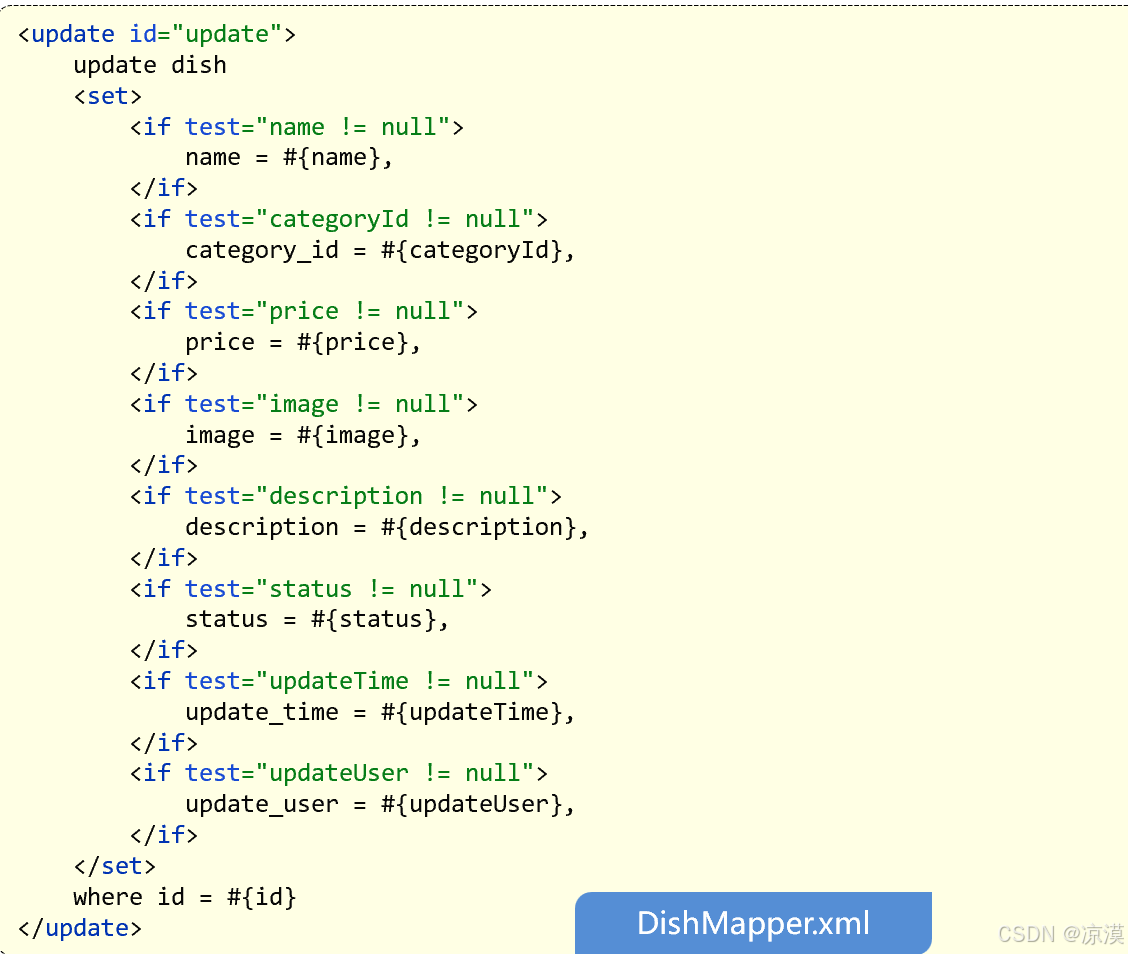
菜品管理(day03)
公共字段自动填充 问题分析 业务表中的公共字段: 而针对于这些字段,我们的赋值方式为: 在新增数据时, 将createTime、updateTime 设置为当前时间, createUser、updateUser设置为当前登录用户ID。 在更新数据时, 将updateTime 设置为当前时间…...

深入理解 Android 混淆规则
在 Android 开发中,混淆(Obfuscation)是一种保护代码安全的重要手段,通常通过 ProGuard 或 R8 工具来实现。本文将详细介绍 Android 混淆规则的基本原理、配置方法以及最佳实践,帮助开发者更好地保护应用代码。 博主博…...

《Keras 3 在 TPU 上的肺炎分类》
Keras 3 在 TPU 上的肺炎分类 作者:Amy MiHyun Jang创建日期:2020/07/28最后修改时间:2024/02/12描述:TPU 上的医学图像分类。 (i) 此示例使用 Keras 3 在 Colab 中查看 GitHub 源 简介 设置 本教程将介…...
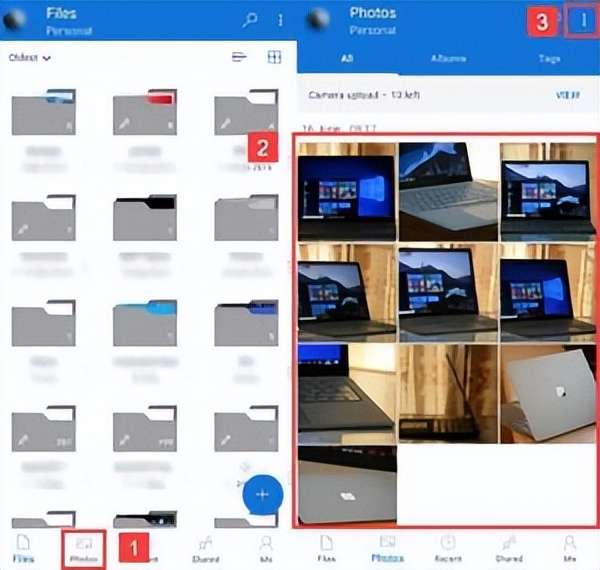
从 Android 进行永久删除照片恢复的 5 种方法
从 Android 设备中丢失珍贵的照片可能是一种毁灭性的经历。无论是由于意外删除、软件故障还是系统更新,如何从 Android 永久恢复已删除的照片是一个普遍的问题。 幸运的是,有一些解决方案可以帮助找回丢失的记忆。本指南将涵盖您需要了解的有关如何检索…...

SDL2:Android APP编译使用
SDL2:Android APP编译使用 3. SDL2:Android APP编译使用3.1 Android Studio环境准备:3.2 构建Android APP(1)方式一:快速构建APK工程(2)方式二:自定义APK工程(…...
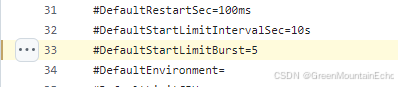
linux systemd 服务连续启动失败,不会再重启分析
1. 问题现象 在Linux 系统中,将自已写的可执行文件放到 systemd 服务中做成service 服务,以支持开机自启和失败重启。但是发现服务在重启多次失败后再也起不来,服务状态是 failed,并且报 start request repeated too quickly. 2.…...
【云岚到家】-day03-门户缓存方案选择
【云岚到家】-day03-门户缓存方案选择 1.门户常用的技术方案 什么是门户 说到门户马上会想到门户网站,中国比较早的门户网站有新浪、网易、搜狐、腾讯等,门户网站为用户提供一个集中的、易于访问的平台,使他们能够方便地获取各种信息和服务…...
在IDEA中使用通义灵码插件:全面提升开发效率的智能助手
在IDEA中使用通义灵码插件:全面提升开发效率的智能助手 随着软件开发行业对效率和质量要求的不断提高,开发者们一直在寻找能够简化工作流程、提升代码质量的工具。阿里云推出的通义灵码插件正是这样一个旨在帮助开发者更高效地编写高质量代码的强大工具…...

【正则表达式】从0开始学习正则表达式
正则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE) 一、推荐学习网站 正则表达式 – 语法 | 菜鸟教程 正则表达式30分钟入门教程 | 菜鸟教程 编程胶囊-打造学习编程的最好系统 二、必知必记 2.1 元字符…...
PHP智慧小区物业管理小程序
🌟智慧小区物业管理小程序:重塑社区生活,开启便捷高效新篇章 🌟 智慧小区物业管理小程序是一款基于PHPUniApp精心雕琢的智慧小区物业管理小程序,它犹如一股清新的科技之风,吹进了现代智慧小区的每一个角落…...
)
Linux安装Docker教程(详解)
如果想要系统学习docker,建议进入官方文档中学习:docker官方文档 一. 基本概念 Docker Desktop 和 Docker Engine 有什么区别? Docker Desktop for Linux 提供用户友好的图形界面,可简化容器和服务的管理。它包括 Docker Engine,…...
开源AI微调指南:入门级简单训练,初探AI之路
112,如何让 113? 简单的微调你的 AI, 微调前的效果,怎么调教它都是 112. 要对其进行微调(比如训练113),可以按以下步骤进行。 确保你已经安装了以下工具和库: ollamallama3.2Pyt…...

Leetcode 91. 解码方法 动态规划
原题链接:Leetcode 91. 解码方法 自己写的代码: class Solution { public:int numDecodings(string s) {int ns.size();vector<int> dp(n,1);if(s[n-1]0) dp[n-1]0;for(int in-2;i>0;i--){if(s[i]!0){string ts.substr(i,2);int tmpatoi(t.c…...
ASP .NET Core 学习(.NET9)配置接口访问路由
新创建的 ASP .NET Core Web API项目中Controller进行请求时,是在地址:端口/Controller名称进行访问的,这个时候Controller的默认路由配置如下 访问接口时,是通过请求方法(GET、Post、Put、Delete)进行接口区分的&…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参
Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参 【免费下载链接】gz-sim Open source robotics simulator. The latest version of Gazebo. 项目地址: https://gitcode.com/gh_mirrors/gz/gz-sim Gazebo Sim是一款功能强大的开源机器人模拟器ÿ…...

在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型 开发代码辅助工具时,选择合适的模型是平衡效果与成本的关…...

别再乱建索引了!用Explain的key_len字段,一眼看穿你的MySQL联合索引到底生效了几个字段
解密MySQL联合索引:用key_len精准判断索引生效范围 在数据库性能优化领域,联合索引的使用一直是个既基础又容易踩坑的话题。很多开发者虽然知道"最左匹配原则"这个名词,但在实际业务场景中,面对复杂的查询条件组合时&a…...

微信红包助手终极指南:无需ROOT的智能抢红包解决方案
微信红包助手终极指南:无需ROOT的智能抢红包解决方案 【免费下载链接】WeChatLuckyMoney :money_with_wings: WeChats lucky money helper (微信抢红包插件) by Zhongyi Tong. An Android app that helps you snatch red packets in WeChat groups. 项目地址: ht…...

观察不同模型在统一 API 下的响应速度与输出风格差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在统一 API 下的响应速度与输出风格差异 在为大语言模型应用选择模型时,开发者通常会关注两个核心维度&am…...

OpenCore Legacy Patcher完整指南:让老旧Mac焕发新生,运行最新macOS
OpenCore Legacy Patcher完整指南:让老旧Mac焕发新生,运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台被苹…...

UnityExplorer:如何在游戏运行时实时调试和修改Unity项目
UnityExplorer:如何在游戏运行时实时调试和修改Unity项目 【免费下载链接】UnityExplorer An in-game UI for exploring, debugging and modifying IL2CPP and Mono Unity games. 项目地址: https://gitcode.com/gh_mirrors/un/UnityExplorer UnityExplorer是…...

白嫖Codex!一行代码不花接入国产DeepSeek-v4-pro,从此告别ChatGPT月费
Codex 如何接入国产模型 DeepSeek-v4-pro 保姆级教程 使用 Claude Code、Codex 已经好几个月了,不得不感叹现在的 AI 工具真的太强大了。目前市面上很多 Claude Code 如何接入大模型的教程,但 Codex 却比较少,一方面因为 Codex 需要 ChatGPT …...

免费解锁八大网盘限速!LinkSwift直链下载助手终极指南
免费解锁八大网盘限速!LinkSwift直链下载助手终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...