浅谈云计算15 | 存储可靠性技术(RAID)
存储可靠性技术
- 一、存储可靠性需求
- 1.1 数据完整性
- 1.2 数据可用性
- 1.3 故障容错性
- 二、传统RAID技术剖析
- 2.1 RAID 0
- 2.2 RAID 1
- 2.3 RAID 5
- 2.4 RAID 6
- 2.5 RAID 10
- 三、RAID 2.0+技术
- 3.1 RAID 2.0+技术原理
- 3.1.1 两层虚拟化管理模式
- 3.1.2 数据分布与重构
- 3.2 RAID 2.0+技术优势
- 3.2.1 自动负载均衡
- 3.2.2 快速重构
- 3.2.3 性能提升

存储可靠性是云计算存储的核心要素,它直接关系到数据的完整性、可用性和安全性。一旦存储系统出现故障,导致数据丢失或损坏,可能会给企业带来巨大的经济损失,甚至影响到其生存与发展。在金融行业,客户的交易记录、账户信息等数据若丢失,不仅会引发客户信任危机,还可能面临法律风险和巨额赔偿。
一、存储可靠性需求
1.1 数据完整性
数据完整性是存储可靠性的核心要素之一,它强调确保数据在整个生命周期中不被篡改、丢失或损坏,始终保持其原始的准确性和一致性 。在云计算存储环境中,数据可能会面临来自内部系统错误、外部恶意攻击等多种威胁,任何数据的完整性遭到破坏,都可能导致严重的后果。在金融交易数据中,若交易金额、账户信息等关键数据被篡改,可能引发资金损失和金融秩序混乱;在医疗记录中,错误的数据可能导致误诊,危及患者生命安全。
1.2 数据可用性
数据可用性是指在用户需要时,数据能够随时被访问和使用的能力 。在云计算环境下,用户对数据的访问需求具有实时性和突发性,因此确保数据的高可用性至关重要。无论是企业的日常业务运营,还是个人用户对云存储中数据的频繁访问,都依赖于数据的随时可用。若数据无法及时获取,将导致业务中断、工作效率降低,甚至影响用户体验和信任度。
1.3 故障容错性
故障容错性是云计算存储系统应对各种硬件故障、软件错误以及网络问题等异常情况的能力 。在复杂的云计算环境中,硬件设备的故障是不可避免的,如硬盘损坏、服务器死机等;软件系统也可能出现漏洞、错误导致数据丢失或服务中断;网络故障则可能导致数据传输中断或延迟。因此,存储系统必须具备强大的故障容错能力,以确保在各种故障场景下,数据的安全性和系统的正常运行。
二、传统RAID技术剖析
2.1 RAID 0
RAID 0 是一种通过数据条带化来显著提升读写性能的磁盘阵列技术。在RAID 0中,数据被分割成大小相等的数据块,这些数据块被均匀且交叉地分布存储在多个磁盘上,形成条带结构。这种分布方式使得数据的读写操作能够在多个磁盘上并行进行,极大地提高了数据的I/O性能。

以一个由四块磁盘组成的RAID 0阵列为例,当存储一个大型文件时,文件会被划分成多个数据块,如Block1、Block2、Block3、Block4等。这些数据块会分别存储在不同的磁盘上,Block1存储在磁盘1,Block2存储在磁盘2,Block3存储在磁盘3,Block4存储在磁盘4。在读取数据时,四个磁盘可以同时工作,并行读取各自存储的数据块,然后将这些数据块快速组合成完整的文件,大大缩短了读取时间。与传统的单个磁盘存储方式相比,RAID 0的读写速度有了显著提升,能够满足对数据处理速度要求极高的应用场景。在视频编辑领域,处理高清视频素材需要大量的数据读写操作。使用RAID 0阵列,视频编辑软件可以快速读取和写入视频数据,减少了素材加载时间和渲染等待时间,提高了视频编辑的效率。在大规模数据处理、科学计算等领域,RAID 0的高性能优势也得到了充分体现。
然而,RAID 0的一个显著缺点是缺乏数据冗余机制。由于数据被分散存储在多个磁盘上,且没有任何冗余备份,一旦其中任何一个磁盘发生故障,就会导致整个数据的丢失。因为数据块是相互关联的,缺少了某个磁盘上的数据块,就无法完整地恢复出原始数据。在一个企业的数据库系统中,如果采用RAID 0存储重要的业务数据,一旦某个磁盘出现故障,可能会导致大量业务数据丢失,给企业带来严重的经济损失和业务中断风险。因此,RAID 0通常适用于对数据可靠性要求不高,但对读写速度有极高要求的场景,如临时数据存储、高速缓存等,并且在使用RAID 0时,需要配合其他数据备份措施来确保数据的安全性。
2.2 RAID 1
RAID 1是一种基于数据镜像技术的磁盘阵列级别,其核心原理是将数据完全相同地复制到两个或多个磁盘上,形成镜像对。在一个由两块磁盘组成的RAID 1阵列中,当用户写入数据时,数据会同时被写入到这两块磁盘上,确保两块磁盘上的数据始终保持一致。这种数据镜像的方式为数据提供了极高的可靠性保障。

一旦其中一个磁盘发生故障,另一个磁盘上的数据副本可以立即接替工作,保证数据的正常访问和系统的持续运行。在金融行业的核心交易系统中,数据的准确性和完整性至关重要。采用RAID 1技术存储交易数据,即使其中一块磁盘出现硬件故障、磁盘损坏等问题,另一块磁盘上的镜像数据依然能够确保交易系统的稳定运行,避免因数据丢失而引发的金融风险和客户信任危机。在医疗领域,患者的病历数据关乎生命健康,不容有失。使用RAID 1对病历数据进行存储,可以有效防止因磁盘故障导致的数据丢失,保障医疗服务的连续性和准确性。
然而,RAID 1的高可靠性是以牺牲存储效率为代价的。由于数据需要在多个磁盘上进行完整复制,实际可用的存储容量仅为磁盘总容量的一半。在一个由两块1TB磁盘组成的RAID 1阵列中,虽然磁盘总容量为2TB,但实际能够用于存储用户数据的容量只有1TB。这意味着在存储成本方面,RAID 1相对较高,对于存储大量数据的场景来说,可能需要投入更多的硬件成本来满足存储需求。因此,RAID 1通常适用于对数据可靠性要求极高,且对存储容量需求相对较小的关键应用场景,如服务器系统盘、数据库关键数据存储等。
2.3 RAID 5
RAID 5是一种广泛应用的磁盘阵列技术,它采用分布式奇偶校验的方式来实现数据冗余和性能优化。在RAID 5阵列中,数据被分块存储在多个磁盘上,同时计算每个数据块的奇偶校验信息,并将这些奇偶校验信息均匀地分布存储在各个磁盘上。

以一个由三块磁盘组成的RAID 5阵列为例,假设要存储的数据块为D1、D2、D3,系统会计算出它们的奇偶校验信息P1(P1 = D1 ⊕ D2 ⊕ D3,其中⊕表示异或运算)。然后,将D1存储在磁盘1,D2存储在磁盘2,D3存储在磁盘3,而奇偶校验信息P1则存储在其中一个磁盘上,比如磁盘1。当读取数据时,系统可以通过读取数据块和相应的奇偶校验信息来验证数据的完整性。如果某个磁盘,如磁盘2发生故障,系统可以利用磁盘1上的D1和P1以及磁盘3上的D3,通过异或运算(D2 = D1 ⊕ P1 ⊕ D3)来重建出丢失的数据块D2,从而保证数据的完整性和可用性。
RAID 5在读写性能方面具有一定的特点。在读取数据时,由于可以并行从多个磁盘读取数据块,因此读取速度相对较快,能够满足大多数应用场景对数据读取的性能需求。在写入数据时,由于需要计算并更新奇偶校验信息,写入操作相对复杂,性能会受到一定影响。但相较于其他一些具有数据冗余的RAID级别,RAID 5在写入性能上仍具有一定的优势。在企业的文件服务器中,存储着大量的日常业务文件,如文档、报表等。采用RAID 5技术,既能保证在单个磁盘故障时数据不丢失,又能在一定程度上满足员工对文件读写的性能要求。同时,RAID 5至少需要三块磁盘才能构建,并且随着磁盘数量的增加,其存储效率也会相应提高,因为奇偶校验信息所占的磁盘空间比例会相对减少。
2.4 RAID 6
RAID 6是在RAID 5基础上发展而来的一种更高级的数据保护技术,它通过引入双重奇偶校验机制,为数据提供了更高的容错能力。在RAID 6阵列中,数据同样被分块存储在多个磁盘上,并且会计算出两组不同的奇偶校验信息,分别存储在不同的磁盘上。

以一个由四块磁盘组成的RAID 6阵列为例,假设要存储的数据块为D1、D2、D3、D4,系统会计算出两组奇偶校验信息P1和Q1(P1 = D1 ⊕ D2 ⊕ D3 ⊕ D4,Q1通过另一种独立的计算方式得出,例如基于不同的算法或数据块组合)。然后,将数据块和奇偶校验信息分布存储在四个磁盘上,如D1存储在磁盘1,D2存储在磁盘2,D3存储在磁盘3,D4存储在磁盘4,P1存储在磁盘1,Q1存储在磁盘2。这样,当任意两个磁盘发生故障时,系统可以利用剩余磁盘上的数据块和奇偶校验信息,通过复杂的算法重建出丢失的数据。如果磁盘1和磁盘3出现故障,系统可以通过磁盘2上的D2、Q1以及磁盘4上的D4和P1,经过一系列的运算(涉及到两种奇偶校验信息的协同计算)来恢复出D1和D3的数据块,从而确保数据的完整性。
RAID 6的双重奇偶校验机制使得它能够容忍两个磁盘同时故障的极端情况,这在数据安全性要求极高的场景中具有重要意义。在大型数据中心,存储着海量的关键业务数据,如金融机构的交易数据、互联网公司的用户数据等,这些数据一旦丢失,可能会带来无法估量的损失。采用RAID 6技术,可以有效降低因磁盘故障导致的数据丢失风险,保障业务的连续性和稳定性。然而,这种高可靠性的实现也带来了一定的代价。由于需要计算和存储两组奇偶校验信息,RAID 6的存储效率相对较低,成本也相对较高。在存储同样数量的数据时,RAID 6需要比RAID 5更多的磁盘空间来存储奇偶校验信息,这意味着硬件成本的增加。同时,由于写入数据时需要更新两组奇偶校验信息,其写入性能也会受到一定程度的影响,相较于RAID 5会更慢一些。
2.5 RAID 10
RAID 10是一种结合了RAID 0的条带化技术和RAID 1的镜像技术的磁盘阵列级别,它融合了两者的优势,既具备高性能的数据读写能力,又拥有高可靠性的数据冗余保障。在RAID 10阵列中,首先将磁盘划分为多个镜像对,然后在这些镜像对之间进行条带化处理。

以一个由八块磁盘组成的RAID 10阵列为例,将这八块磁盘分为四组镜像对,即(磁盘1和磁盘2)、(磁盘3和磁盘4)、(磁盘5和磁盘6)、(磁盘7和磁盘8)。在每组镜像对中,数据以镜像的方式存储,确保数据的冗余性。当写入数据时,数据会同时被写入到每组镜像对中的两个磁盘上,保证数据的安全性。然后,将这四组镜像对进行条带化,即把数据分块后交叉存储在不同的镜像对之间。假设要存储一个大文件,文件被分成多个数据块,Block1存储在磁盘1,Block2存储在磁盘3,Block3存储在磁盘5,Block4存储在磁盘7,而它们的镜像数据分别存储在对应的磁盘2、磁盘4、磁盘6、磁盘8上。在读取数据时,多个镜像对可以同时并行读取数据块,大大提高了数据的读取速度,这体现了RAID 0条带化技术的高性能优势。
由于数据以镜像的方式存储在多个磁盘上,即使某个镜像对中的一个磁盘发生故障,另一个磁盘上的数据副本仍然可以保证数据的可用性。而且,RAID 10能够容忍多个磁盘故障,只要故障磁盘不来自同一镜像对,数据就不会丢失。在一个企业的数据库服务器中,采用RAID 10技术存储数据库数据,既可以满足数据库对大量数据读写的高性能需求,确保业务系统的快速响应,又能在面对磁盘故障时,保障数据的安全可靠,避免因数据丢失而导致的业务中断。因此,RAID 10适用于对数据安全性和读写性能都有较高要求的场景,如大型数据库系统、关键业务应用服务器等。不过,RAID 10需要较多的磁盘数量来构建,硬件成本相对较高,在实际应用中需要根据具体的业务需求和预算进行综合考虑 。
三、RAID 2.0+技术
3.1 RAID 2.0+技术原理
3.1.1 两层虚拟化管理模式
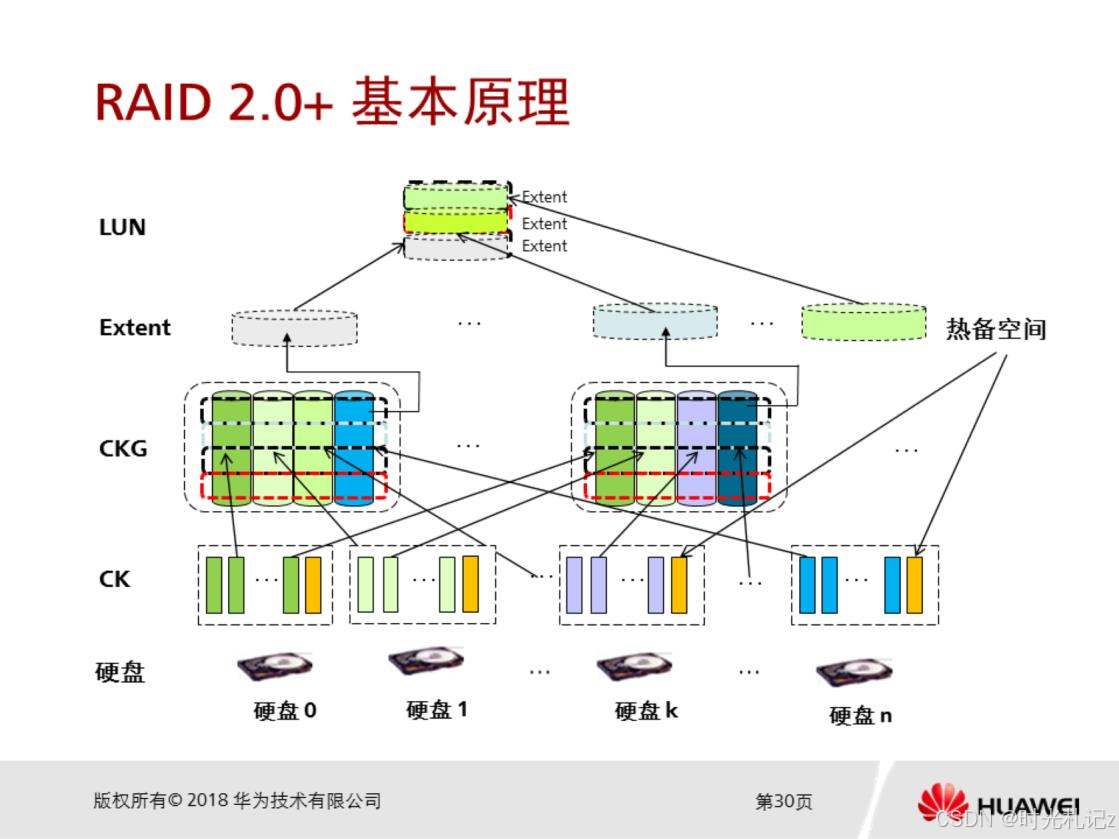
RAID 2.0+技术创新性地采用了两层虚拟化管理模式,这种模式在底层块级虚拟化的硬盘管理基础上,结合上层虚拟化的资源管理,实现了对存储资源的高效、灵活管理 。

在底层,块级虚拟化通过将硬盘划分为CK,为存储资源的管理提供了细粒度的基础。不同硬盘的CK被组合成具有RAID属性的逻辑集合,即Chunk Group(CKG) 。CKG的形成是基于用户在存储系统中设置的“RAID策略”,例如可以选择类似RAID 5、RAID 6等不同的冗余策略来构建CKG。在一个包含多个硬盘的存储池中,系统会根据用户设定的RAID策略,从不同硬盘中选取CK组成CKG,以实现数据的冗余存储和可靠性保障。如果用户选择RAID 5策略,系统会在CKG中计算并存储奇偶校验信息,当某个CK出现故障时,能够利用其他CK和奇偶校验信息进行数据恢复。

在上层,资源管理则是基于存储池进行的。存储池是由多个硬盘域中的资源组成的逻辑容器,所有应用服务器使用的存储空间都来自于存储池。用户在创建逻辑单元号(LUN)时,不再直接与物理硬盘或传统的RAID组相关联,而是从存储池中分配空间。存储池通过对CKG的管理和调度,为用户提供了统一的、灵活的存储空间分配服务。当用户需要创建一个新的LUN时,存储池会根据用户的需求和存储池的资源情况,从合适的CKG中分配相应的CK来组成LUN。这种上层虚拟化的资源管理方式,使得用户无需关心底层物理硬盘的具体情况,只需要关注存储池提供的逻辑存储空间,大大简化了存储资源的管理和使用。
通过底层块级虚拟化和上层虚拟化的协同工作,RAID 2.0+技术实现了对存储资源的高效管理。它不仅提高了存储资源的利用率,还增强了系统的灵活性和可扩展性。在企业业务不断发展,存储需求不断变化的情况下,RAID 2.0+的两层虚拟化管理模式能够方便地对存储资源进行调整和优化。当企业需要增加存储容量时,可以通过向存储池中添加硬盘域的方式,轻松扩展存储池的容量,而无需对上层应用进行大规模的调整。
3.1.2 数据分布与重构
在RAID 2.0+技术中,数据分布采用了独特的策略,以确保数据在存储池中的均匀性和可靠性 。当数据写入存储系统时,会被分割成多个CK,并根据一定的算法均匀地分布到存储池的各个硬盘上。这种算法通常会考虑硬盘的剩余容量、性能等因素,以实现硬盘负载的均衡。在一个由多个不同类型硬盘组成的存储池中,算法会优先将数据分配到剩余容量较大且性能较好的硬盘上,避免某些硬盘因负载过重而影响整个存储系统的性能。同时,数据在分布过程中,会根据用户设置的RAID策略,在CKG中进行冗余存储。如果采用RAID 6策略,数据会在CKG中存储两组不同的奇偶校验信息,以提高数据的容错能力。

当存储系统中的某个硬盘或CK出现故障时,RAID 2.0+技术具备高效的数据重构机制 。与传统RAID技术不同,RAID 2.0+的重构不是局限于单个RAID组内的硬盘,而是涉及到故障硬盘所在硬盘域中的所有同类型硬盘。在一个包含多个硬盘域的存储系统中,每个硬盘域可能包含不同类型的硬盘,如SSD、SAS等。当某个SSD硬盘出现故障时,系统会自动触发重构机制,利用该硬盘域中其他同类型的SSD硬盘上的数据和校验信息,对故障硬盘上的数据进行重构。由于RAID 2.0+技术采用了块虚拟化和多硬盘参与重构的方式,大大增加了参与重构的硬盘数量,使得重构数据流的写带宽不再成为重构速度的瓶颈,从而显著提升了数据重构的速度。在传统RAID 5中,当一块硬盘出现故障时,重构过程可能需要十几个小时甚至几十个小时,而在RAID 2.0+系统中,由于多个硬盘同时参与重构,数据重构时间能够大幅缩短,可能只需要几个小时甚至更短时间,极大地降低了数据丢失的风险,提高了存储系统的可靠性和可用性 。
3.2 RAID 2.0+技术优势
3.2.1 自动负载均衡
当数据写入存储系统时,会被分割成多个CK,并依据特定的算法,均匀地分布到存储池的各个硬盘上。这种算法充分考虑了硬盘的剩余容量、性能等因素,确保数据能够均衡地分配到各个硬盘,避免了数据集中在某些特定硬盘上的情况,确保了也用户数据能够快速、稳定地读写,还延长了硬盘的使用寿命,降低了硬件故障率。
3.2.2 快速重构
RAID 2.0+技术在数据重构方面展现出了显著的优势,极大地提升了存储系统在面对硬盘故障时的恢复能力,有效降低了数据丢失的风险 。在传统RAID技术中,数据重构过程存在诸多局限性。以传统RAID 5为例,当一块硬盘出现故障时,重构过程需要从其他正常硬盘读取数据,并通过奇偶校验信息计算出故障硬盘上的数据,然后将其写入热备盘。由于热备盘的写入速度有限,且在重构过程中,其他正常硬盘的读写操作也会受到一定影响,导致重构速度较慢。在数据量较大的情况下,重构一块硬盘可能需要十几个小时甚至几十个小时。在如此漫长的重构时间内,存储系统处于单冗余状态,一旦其他硬盘再次出现故障,就极有可能导致数据丢失,给企业带来巨大的损失。
相比之下,RAID 2.0+技术采用了创新的块虚拟化和多硬盘参与重构的方式,彻底打破了传统RAID技术重构的性能瓶颈。在RAID 2.0+系统中,当某个硬盘出现故障时,重构机制会自动触发,且涉及到故障硬盘所在硬盘域中的所有同类型硬盘 。由于参与重构的硬盘数量大幅增加,数据重构过程中的写带宽不再成为瓶颈,从而显著提升了重构速度。例如,在某金融机构的数据存储中心,采用了RAID 2.0+技术。一次,一块硬盘突然出现故障,但由于RAID 2.0+的快速重构机制,系统能够迅速利用硬盘域中其他同类型硬盘的数据和校验信息,对故障硬盘上的数据进行重构。整个重构过程仅用了短短几个小时,就完成了数据的恢复,确保了金融业务的正常运行,避免了因数据丢失而可能引发的金融风险和客户信任危机 。
3.2.3 性能提升
RAID 2.0+技术在读写性能方面实现了显著提升,为用户提供了更高效的数据存储和访问体验 。在读取性能上,RAID 2.0+技术通过块虚拟化和条带化技术的协同作用,能够实现数据的并行读取。由于数据被均匀地分布到多个硬盘的CK中,当用户请求读取数据时,多个硬盘可以同时工作,并行读取各自存储的CK数据块,然后将这些数据块快速组合成完整的数据,大大缩短了数据的读取时间。在一个科研项目中,需要频繁读取大量的实验数据进行分析。采用RAID 2.0+技术后,实验数据被分散存储在多个硬盘上,科研人员在读取数据时,多个硬盘能够并行工作,快速将所需数据传输到计算设备中,大大提高了数据分析的效率,加快了科研项目的进展。
在写入性能方面,虽然传统RAID技术在写入数据时,需要计算并更新奇偶校验信息,这会增加写入操作的复杂性和时间开销。而RAID 2.0+技术通过优化数据分布和写入算法,减少了写入操作的性能损耗。在数据写入时,RAID 2.0+系统会根据硬盘的负载情况和性能特点,智能地选择合适的硬盘进行数据写入,避免了传统RAID中可能出现的因写入操作集中在某些硬盘上而导致的性能瓶颈。
通过对RAID 2.0+技术在自动负载均衡、快速重构和性能提升等方面优势的深入分析,可以看出该技术在提升云计算存储可靠性和性能方面具有显著的效果。在实际应用中,越来越多的企业和机构选择采用RAID 2.0+技术来构建其云计算存储系统,以满足日益增长的数据存储和处理需求,为业务的稳定发展提供坚实的技术支撑 。
(注:图片来源网络,如有侵权请联系删除)
相关文章:
浅谈云计算15 | 存储可靠性技术(RAID)
存储可靠性技术 一、存储可靠性需求1.1 数据完整性1.2 数据可用性1.3 故障容错性 二、传统RAID技术剖析2.1 RAID 02.2 RAID 12.3 RAID 52.4 RAID 62.5 RAID 10 三、RAID 2.0技术3.1 RAID 2.0技术原理3.1.1 两层虚拟化管理模式3.1.2 数据分布与重构 3.2 RAID 2.0技术优势3.2.1 自…...

43.Textbox的数据绑定 C#例子 WPF例子
固定最简步骤,包括 XAML: 题头里引入命名空间 标题下面引入类 box和block绑定属性 C#: 通知的类,及对应固定的任务 引入字段 引入属性 属性双触发,其中一个更新block的属性 block>指向box的属性 从Textbo…...
LLM大语言模型的分类
从架构和功能的角度来看,LLM(Large Language Model,大语言模型)主要可以分为以下几种类型: **1. 基础语言模型:** * **定义:** 通过在大规模文本数据上进行预训练,学习语言的规律和模式&#…...
【北京迅为】iTOP-4412全能版使用手册-第八十七章 安装Android Studio
iTOP-4412全能版采用四核Cortex-A9,主频为1.4GHz-1.6GHz,配备S5M8767 电源管理,集成USB HUB,选用高品质板对板连接器稳定可靠,大厂生产,做工精良。接口一应俱全,开发更简单,搭载全网通4G、支持WIFI、蓝牙、…...
【深度学习】神经网络之Softmax
Softmax 函数是神经网络中常用的一种激活函数,尤其在分类问题中广泛应用。它将一个实数向量转换为概率分布,使得每个输出值都位于 [0, 1] 之间,并且所有输出值的和为 1。这样,Softmax 可以用来表示各类别的预测概率。 Softmax 函…...

容器渗透横向
本质上要获得 1.获得容器IP段 2.获得主机IP段 3.获得本机IP 4.通过CNI或Docker0等扫描本机端口 Flannel 容器信息 rootubuntu-linux-22-04-desktop:/home/parallels/Desktop# k get po -A -o wide NAMESPACE NAME …...

黑马Java面试教程_P1_导学与准备篇
系列博客目录 文章目录 系列博客目录导学Why?举例 准备篇企业是如何筛选简历的(筛选简历的规则)HR如何筛选简历部门负责人筛选简历 简历注意事项简历整体结构个人技能该如何描述项目该如何描述 应届生该如何找到合适的练手项目项目来源找到项目后,如何深入学习项目…...
《自动驾驶与机器人中的SLAM技术》ch4:预积分学
目录 1 预积分的定义 2 预积分的测量模型 ( 预积分的测量值可由 IMU 的测量值积分得到 ) 2.1 旋转部分 2.2 速度部分 2.3 平移部分 2.4 将预积分测量和误差式代回最初的定义式 3 预积分的噪声模型和协方差矩阵 3.1 旋转部分 3.2 速度部分 3.3 平移部分 3.4 噪声项合并 4 零偏的…...

Docker部署MySQL 5.7:持久化数据的实战技巧
在生产环境中使用Docker启动MySQL 5.7时,需要考虑数据持久化、配置文件管理、安全性等多个方面。以下是一个详细的步骤指南。 1. 准备工作 (1)创建挂载目录 在宿主机上创建用于挂载的目录,以便持久化数据和配置文件。 sudo mkdi…...

Spring框架 了解
深入浅出Spring框架:为初学者量身定制的入门指南 引言 在现代Java开发中,Spring框架无疑是构建企业级应用的核心技术之一。无论是初学者还是经验丰富的开发者,掌握Spring都能极大地提升你的编程技能和项目开发效率。本文将带你深入了解Spri…...

低代码独特架构带来的编译难点及多线程解决方案
前言 在当今软件开发领域,低代码平台以其快速构建应用的能力,吸引了众多开发者与企业的目光。然而,低代码平台独特的架构在带来便捷的同时,也给编译过程带来了一系列棘手的难点。 一,低代码编译的难点 (1…...

如何使用Ultralytics训练自己的yolo5 yolo8 yolo10 yolo11等目标检测模型
Ultralytics正在以惊人的速度吸收优秀的CV算法,之前Ultralytics定位于YOLOV8,但逐渐地扩展到支持其他版本的YOLO,最新版本的ultralytics全面支持yolo5 yolo7 yolo8 yolo9 yolo10 yolo11,包含模型的训练、验证、预测、部署等。毫无…...

Java技术栈 —— Andorid开发入门
Java技术栈 —— Andorid开发入门 一、搭建开发环境二、HelloWorld三、将Andorid项目打包成APK文件,并安装至手机上四、开发常见问题 一、搭建开发环境 不用Intellij,而是用Andorid Studio(免费),这是专门给Andorid的IDE。 参考文章或视频链…...

Qt天气预报系统获取天气数据
Qt天气预报系统获取天气数据 1、获取天气数据1.1添加天气类头文件1.2定义今天和未来几天天气数据类1.3定义一个解析JSON数据的函数1.4在mainwindow中添加weatherData.h1.5创建今天天气数据和未来几天天气数据对象1.6添加parseJson定义1.7把解析JSON数据添加进去1.8添加错误1.9解…...

力扣 搜索二维矩阵
二分查找,闭区间与开区间的不同解法。 题目 乍一看,不是遍历一下找到元素就可以了。 class Solution {public boolean searchMatrix(int[][] matrix, int target) {for (int[] ints : matrix) {for (int ans : ints) {if (ans target) return true;}}…...

JavaScript 操作符与表达式
Hi, 我是布兰妮甜,编写流畅、愉悦用户体验的程序员。JavaScript 是一种功能强大且灵活的编程语言,广泛应用于前端和后端开发。它提供了一系列丰富的操作符和表达式来处理数据、执行逻辑判断以及控制程序流程。理解这些概念对于编写高效、可读性强的代码至…...
的创建和常用方法)
深度学习 Pytorch 张量(Tensor)的创建和常用方法
1 张量的基本创建及其类型 和Numpy中的array一样,张量的本质也是结构化地组织了大量的数据。 并且在实际操作中,张量的创建和基本功能也与其非常类似。 1.1 张量(Tensor)函数创建方法 张量的最基本创建方法和Numpy中创建Array的格式一致。 # Numpy创建…...

在VMwareFusion中使用Ubuntu
在VMwareFusion使用Ubuntu 在VMwareFusion使用Ubuntu背景在VMwareFusion虚拟机里使用Ubuntu1、集成桌面工具2、主机和虚拟机之间共享剪贴板内容3、设置root用户密码4、设置静态ip4.1、静态ip和动态ip的区别4.2、查看当前ip4.2、linux网络配置文件所在位置4.3、基于ubuntu22.04.…...

%.*s——C语言中printf 函数中的一种格式化输出方式
在C语言中,%.*s 是 printf 函数中的一种格式化输出方式,用于控制字符串的输出长度。具体来说,%.*s 中的 * 表示输出宽度(即最多输出的字符数)是一个变量,这个变量的值在运行时通过 printf 函数的参数传递。…...

基于微信小程序的摄影竞赛系统设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤
从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤在当今数据驱动的时代,对象存储已成为现代应用架构中不可或缺的一部分。MinIO作为高性能、兼容S3协议的开源对象存储解决方案,凭借其轻量级和易用性赢得了众多…...

Unity渲染排序三要素:SortingLayer、Order in Layer与RenderQueue协同原理
1. 为什么刚进Unity的美术和程序总在“图层遮挡”上反复拉扯?“这个UI怎么被背景挡住了?”“粒子特效一开就穿模,明明Z轴没问题!”“我调了Order in Layer到999,还是被另一个Sprite挡住——它连Sorting Layer都没改过&…...
)
Allegro PCB设计小技巧:如何让Route Keepout区域既能走线又能打过孔(附详细步骤图)
Allegro PCB设计实战:Route Keepout区域的灵活控制技巧 在高速PCB设计中,Route Keepout区域的管理常常让工程师陷入两难境地——元件封装自带的限制区域与实际布线需求产生冲突。特别是处理PCIE等高速信号时,这种矛盾尤为突出。传统做法要么完…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...
)
实战对比:用直方图均衡化与CLAHE拯救你的背光/过曝照片(附Python完整代码)
拯救逆光废片:直方图均衡化与CLAHE的实战效果对比每次旅行回来整理照片时,总会有几张因为光线问题几乎要删除的废片——要么是逆光下的人脸黑得看不清五官,要么是天空过曝失去所有云层细节。这些照片往往记录着重要时刻,直接删除实…...

如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南
如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南 【免费下载链接】CrewAI-Studio A user-friendly, multi-platform GUI for managing and running CrewAI agents and tasks. Supports Conda and virtual environments, no coding need…...
)
嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(3)
接前一篇文章:嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(2) 节点查找 API:如何在设备树中定位目标节点 有了数据结构基础,现在我们可以开始讲具体的API了。第一步是找到你要操作的节点。就像你想操…...

ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现
ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 在机器人操作系统(ROS)开发领域,硬件依赖和测试成本一直是制约算法迭代效率的…...

3分钟掌握抖音视频批量下载:解放双手的素材收集革命
3分钟掌握抖音视频批量下载:解放双手的素材收集革命 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为一个个手动保存抖音视频而烦恼吗?想要高效收集创作者素材却苦于没有合适的…...

【C++修仙录02】筑基篇:vector 使用
嗨~大家好,这里是春栀怡铃声的博客~ “做你害怕的事,然后发现,不过如此~” 目录 创建vector 遍历方法 迭代器 reserve 扩容 resize 对size 进行改变 会加值,会减值 insert size capacity empty push_back erase swap c…...