《MambaIR:一种基于状态空间模型的简单图像修复基线方法》学习笔记
paper:2402.15648
目录
摘要
一、引言
1、模型性能的提升依赖于网络感受野的扩大:
2、全局感受野和高效计算之间存在固有矛盾:
3、改进版 Mamba的巨大潜力
4、Mamba 在图像修复任务中仍面临以下挑战:
5、方法
6、主要贡献
二、相关工作
1、图像恢复
2、空间状态模型(State Space Models, SSMs)
三、框架
1、预备知识
2、整体架构
1. 浅层特征提取
2. 深层特征提取
3. 高质量重建
3、残差状态空间组 Residual State-Space Block (RSSB)
4、视觉状态空间模块 Vision State-Space Module (VSSM)
5、二维选择性扫描模块 2D Selective Scan Module (2D-SSM)
6、损失函数
四、实验
1、数据集
2、实验细节
3、消融实验
4、超分辨率对比实验
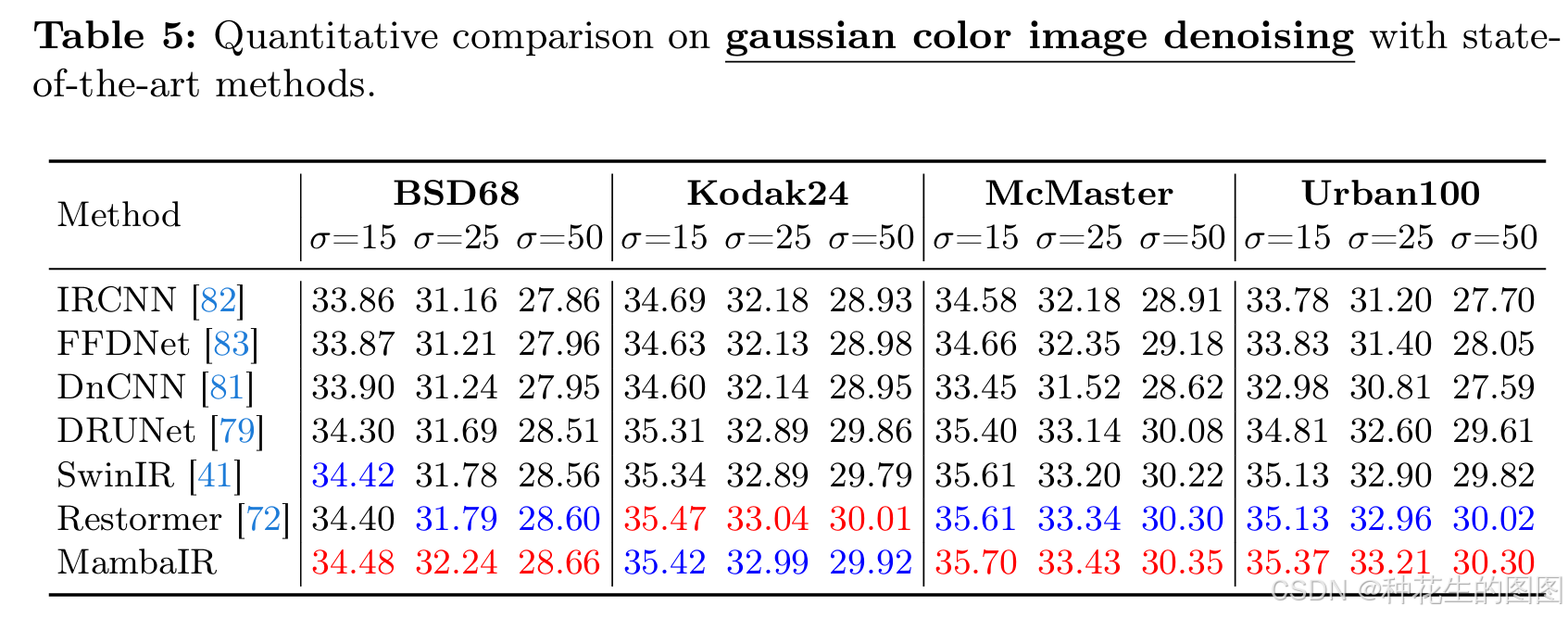
5、图像去噪对比实验
摘要
近年来,图像修复取得了显著进展,这主要得益于现代深度神经网络(如 CNN 和 Transformers)的发展。然而,现有的修复骨干网络在实际应用中往往面临全局感受野与高效计算之间的矛盾。最近,选择性结构化状态空间模型(Selective Structured State Space Model),尤其是改进版本 Mamba,在长距离依赖建模方面表现出巨大的潜力,并且其复杂度为线性级别,这为解决上述矛盾提供了一种可能。然而,标准的 Mamba 在低级视觉任务中仍面临一些挑战,例如局部像素信息丢失和通道冗余问题。
在这项工作中,我们提出了一种简单但有效的基线方法,称为 MambaIR。该方法在原始 Mamba 的基础上引入了局部增强和通道注意力机制,从而利用了局部像素的相似性并减少了通道冗余。大量实验表明,我们的方法具有显著的优越性。例如,在图像超分辨率(Image Super-Resolution)任务中,MambaIR 以类似的计算成本超越了 SwinIR,性能提升高达 0.45dB,同时还保留了全局感受野的优势。
一、引言
图像修复(Image Restoration)的目标是从给定的低质量输入中重建高质量图像。这是计算机视觉中的一个长期研究问题,并包括许多子任务,例如超分辨率(Super-Resolution)、图像去噪(Image Denoising)等。近年来,随着现代深度学习模型的引入(如 CNN 和 Transformer),图像修复技术的性能不断刷新。
1、模型性能的提升依赖于网络感受野的扩大:
- 更大的感受野可以让网络从更广泛的区域中捕获信息,有助于参考更多像素来重建目标像素。
- 较大的感受野能够提取图像中的高级模式和结构,这对于某些需要保持结构的任务(如图像去噪)至关重要。
- 基于 Transformer 的方法通常具有更大的感受野,在实验中优于基于 CNN 的方法,且研究表明,激活更多像素通常会带来更好的修复效果。
2、全局感受野和高效计算之间存在固有矛盾:
- CNN 修复网络尽管感受野有限,但由于卷积的并行计算效率,适合在资源受限的设备上部署。
- 基于 Transformer 的方法通常需要处理与图像分辨率一致数量的“token”,导致计算复杂度呈二次增长,即使引入高效注意力机制(如窗口注意力),以牺牲全局感受野为代价。
3、改进版 Mamba的巨大潜力
- Mamba 使用离散化的状态空间方程,可以通过特殊设计的结构化重新参数化来建模长距离依赖。
- Mamba 的并行扫描算法允许在 GPU 等现代硬件上高效训练。
4、Mamba 在图像修复任务中仍面临以下挑战:
- 局部像素遗忘问题:Mamba 将图像展平为 1D 序列处理,导致空间上相邻的像素可能在序列中变得相距遥远,从而丢失局部信息。
- 通道冗余问题:为了记忆长序列依赖,状态空间方程通常需要大量隐藏状态,导致关键通道特征学习受限。
5、方法
为了解决上述问题,作者提出了 MambaIR,一种简单而有效的基线模型,通过以下三阶段适配 Mamba 于图像修复任务:
- 浅层特征提取:使用简单的卷积层提取浅层特征。
- 深层特征提取:使用堆叠的残差状态空间块(Residual State Space Block, RSSB)。RSSB 的核心改进包括:
- 局部卷积:缓解局部像素遗忘问题。
- 通道注意力:减少隐藏状态引起的通道冗余。
- 可学习跳跃连接因子:优化特征传递。
- 高质量图像重建:整合浅层和深层特征,输出高质量图像。
MambaIR 结合了全局有效感受野与线性计算复杂度,为图像修复提供了一种全新备选骨干网络。
6、主要贡献
- 首次将状态空间模型适配于低级图像修复:通过大量实验,提出了一个有效的替代方法 MambaIR。
- 设计残差状态空间块(RSSB):通过局部增强和通道冗余降低,提升了标准 Mamba 的能力。
- 实验验证:在多项任务中,MambaIR 优于其他强基线,为图像修复任务提供了强大的骨干网络解决方案。
二、相关工作
1、图像恢复
图像恢复旨在从低质量图像重建出高质量图像,其研究已经因为深度学习的引入而取得显著进展。一些开创性工作为图像超分辨率(如 SRCNN )、图像去噪(如 DnCNN)以及 JPEG 压缩伪影还原(如 ARCNN)提供了基础。早期的深度学习方法通常通过卷积神经网络(CNN),结合残差连接 和密集连接等技术,提升模型的表达能力。然而,尽管这些方法取得了成功,CNN 在建模全局依赖性上仍面临挑战。
近年来,Transformer 在多任务场景中的表现(如时间序列、三维点云和多模态学习 )证明了其强大的建模能力。这促使研究者将 Transformer 引入到图像恢复任务中。然而,Transformer 的自注意力机制因其二次方计算复杂度限制了其在高分辨率图像上的直接应用。为此,IPT将图像分割为多个小块,分别应用自注意力机制进行处理;SwinIR则通过引入滑动窗口注意力改进了性能。此外,许多工作专注于设计高效注意力机制来进一步提升恢复性能。尽管如此,这些高效注意力机制设计往往以牺牲全局感受野为代价,未能本质上解决计算效率和全局建模之间的平衡问题。
2、空间状态模型(State Space Models, SSMs)
状态空间模型(SSMs)源自经典的控制理论,近年来被引入深度学习领域,成为一种在状态转换中具有竞争力的骨干网络。其在线性扩展序列长度方面表现出的出色建模长距离依赖能力,吸引了广泛关注。例如,结构化状态空间序列模型(S4)是深度状态空间模型的开创性工作之一,通过结构化重参数化实现了对长距离依赖的建模;随后,S5 层 在 S4 基础上引入了多输入多输出(MIMO)SSM 和高效的并行扫描。此外,H3实现了性能上的显著提升,几乎弥补了 SSM 与 Transformer 在自然语言任务中的表现差距。研究者还通过门控单元增强 S4,提出了门控状态空间层(Gated State Space Layer),进一步提高了其能力。
最近,Mamba]作为一种基于数据的 SSM,引入了选择性机制和高效硬件设计,不仅在自然语言任务上超越了 Transformer,还具有线性扩展输入长度的优异特性。此外,Mamba 已被初步应用于视觉任务,如图像分类 、视频理解和生物医学图像分割等领域。然而,其在图像恢复任务中的潜力尚未充分挖掘。本研究通过针对图像恢复任务的特定设计,将 Mamba 应用于图像恢复,提出了一种简单但有效的基线方法,为未来研究提供借鉴。
三、框架
1、预备知识
结构化状态空间序列模型(S4)的最新进展受到连续线性时不变(Linear Time-Invariant, LTI)系统的启发。LTI 系统通过隐式的潜在状态 将一维输入函数或序列
映射为输出序列
。其数学形式可以通过以下线性常微分方程(ODE)表示:
其中 N 为状态维度,矩阵 ,以及标量
]是模型参数。
为了将上述连续系统转化为适用于深度学习的形式,通常需要进行离散化操作。设 为时间步长参数,离散化过程通常采用零阶保持(Zero-Order Hold, ZOH)规则,定义如下:
其中 和
分别为离散化后的参数。
离散化后,上述系统的表达式可以改写为递归神经网络(RNN)的形式:
其中 为离散时间步
的隐状态,
和
分别为输入和输出。
进一步地,等价的数学推导可以将上述 RNN 表达式转化为卷积神经网络(CNN)的形式:
其中为输入序列的长度,
表示卷积操作,
是一个结构化卷积核。
Mamba 模型的改进
在 S4 的基础上,Mamba模型通过引入输入依赖性优化了参数、
和
,从而实现了动态特征表达能力。具体来说,Mamba 继承了 S4 的递归形式,使得模型能够记忆超长序列,并激活更多像素以辅助恢复任务。同时,其并行扫描算法 允许模型在享有卷积形式所带来高效训练的同时,进一步提升计算效率。
在图像恢复任务中,Mamba 利用 S4 模型对长距离依赖建模的优势,不仅能够处理高分辨率图像,还能通过动态调整特征表示适应不同图像场景。这种特性为高效图像恢复提供了一种具有竞争力的解决方案。
2、整体架构
如图所示,MambaIR 模型的整体架构包含三个主要阶段:浅层特征提取(Shallow Feature Extraction)、深层特征提取(Deep Feature Extraction)和高质量重建(High-Quality Reconstruction)。

1. 浅层特征提取
给定一个低质量输入图像,首先通过一个
的卷积层提取浅层特征:
其中 表示浅层特征,
和
分别为输入图像的高度与宽度,
为通道数。该阶段旨在对输入图像进行初步特征编码,为后续深层特征提取阶段提供基础表示。
2. 深层特征提取
浅层特征 进一步进入深层特征提取阶段,经过多层堆叠后生成深层特征
,其中
表示第
层。该阶段通过多个残差状态空间组(Residual State-Space Groups, RSSGs)实现特征提炼。
每个 RSSG 包含若干个残差状态空间块(Residual State-Space Blocks, RSSBs),每个 RSSB 基于状态空间模型设计,用以捕获超长依赖特征。为了进一步优化特征提取效果,每个 RSSG 末尾附加了一个卷积层,用于对 RSSB 输出特征进行细化。经过多个 RSSG 的堆叠,模型逐层深化输入图像的全局上下文表征。
RSSG 的结构优势在于通过状态空间模型的动态特性,对多尺度图像特征进行高效建模,兼顾了全局感受野和计算效率。
3. 高质量重建
完成深层特征提取后,将最终的深层特征 与浅层特征
进行逐元素加和(element-wise sum):
其中 是重建阶段的输入特征。通过重建模块,
被进一步处理以生成高质量的输出图像
:
重建阶段的设计旨在结合浅层和深层特征,以有效提升输出图像的细节质量和整体视觉效果。
3、残差状态空间组 Residual State-Space Block (RSSB)
RSSB 是专为 MambaIR 设计的基础模块,旨在结合状态空间模块(SSM)的长程依赖建模能力和传统卷积的局部特征提取优势,从而实现高效的图像恢复。
-
对比 Transformer 的传统模块设计
现有基于 Transformer 的图像恢复网络大多遵循 Norm → Attention → Norm → MLP 的设计模式。然而,尽管 Attention 和 SSM 都可以建模全局依赖,但二者在行为特性上存在差异。简单地用 SSM 替代 Attention 往往会导致次优结果,因此需要重新设计适配 SSM 的模块结构。 -
局部特征的补充问题
SSM 模块通过将特征图展平成一维序列进行处理,其局部像素感知能力受限于展平策略。例如,四方向展开策略会导致空间上相邻像素在 1D 序列中变得距离较远,导致局部像素特征丢失。为此,引入局部卷积层来补偿邻域特征。 -
通道冗余问题
SSM 往往引入大量隐藏状态以建模长程依赖,但这会导致显著的通道冗余现象。为了避免这一问题,引入通道注意力机制(CA)选择关键通道,从而提升通道表达能力。
RSSB 的设计如图所示,其输入为第层的深层特征
,输出为下一层的特征
。

以下是 RSSB 的具体处理流程:
-
长程依赖建模(Vision State-Space Module, VSSM)
- 首先通过 LayerNorm 对输入特征
进行归一化。
- 将归一化特征传入 VSSM,提取空间维度上的长程依赖。
- 使用一个可学习的缩放因子
对跳跃连接进行加权,形成第一阶段输出:
- 首先通过 LayerNorm 对输入特征
-
局部特征补偿
- 为解决 SSM 中的局部像素遗忘问题,对
进行 LayerNorm 归一化,并通过局部卷积层补偿邻域特征。
- 卷积层采用瓶颈结构:通道首先压缩为原来的
,然后再扩展回原始大小,公式如下:
- 为解决 SSM 中的局部像素遗忘问题,对
其中卷积操作包含通道压缩和扩展的过程。
-
通道注意力(Channel Attention, CA)
- 在局部卷积后的特征上,应用通道注意力机制选择关键通道,从而提升模块的表达能力并减少通道冗余:
-
最终输出
- 最后,通过残差连接将
与
调节残差路径,形成模块的最终输出:
- 最后,通过残差连接将
4、视觉状态空间模块 Vision State-Space Module (VSSM)
VSSM(Vision State-Space Module)在图像恢复任务中引入了状态空间方程(State-Space Equation)来建模长程依赖性。与传统的Transformer网络通常通过分割图像为小块或采用平移窗口注意力(shifted window attention)来限制全图层级的交互不同,VSSM通过线性复杂度高效地捕捉长程依赖性,避免了上述限制。
VSSM的架构如图所示

输入特征 会通过两个并行分支进行处理:
-
第一分支:
- 输入特征的通道数通过线性层扩展到
,其中
是预定义的通道扩展因子。
- 接下来,特征通过深度卷积(depth-wise convolution)、SiLU 激活函数、2D SSM 层以及 LayerNorm 进行处理。
- 输入特征的通道数通过线性层扩展到
-
第二分支:
- 输入特征同样通过线性层将通道数扩展到
- 输入特征同样通过线性层将通道数扩展到
两条分支的输出通过 Hadamard 乘积(元素级乘法)进行聚合,最后将通道数投影回原始的 ,以生成输出特征
,其形状与输入特征相同。
-
第一分支:
对输入特征
进行线性扩展、深度卷积、激活函数、2D SSM 和 LayerNorm 处理:
-
第二分支:
对输入特征进行线性扩展和 SiLU 激活:
-
聚合与输出:
通过 Hadamard 乘积将两个分支的特征进行聚合,并将通道数恢复到
:
其中 表示 Hadamard 乘积,即元素级的乘法。
5、二维选择性扫描模块 2D Selective Scan Module (2D-SSM)
在标准的 Mamba 网络中,由于其因果处理的特性,输入数据只能局部处理,这种方式适合处理具有序列性质的自然语言处理(NLP)任务。然而,当这种结构应用于图像等非因果数据时,便会遇到显著的挑战。为了更好地利用图像中的二维空间信息,我们采用了2D Selective Scan Module (2D-SSM)。

如图所示,2D-SSM 对输入的图像特征进行处理。首先,将二维图像特征展平成一维序列,并沿四个不同方向进行扫描,具体如下:
- 从左上角到右下角(top-left to bottom-right)
- 从右下角到左上角(bottom-right to top-left)
- 从右上角到左下角(top-right to bottom-left)
- 从左下角到右上角(bottom-left to top-right)
然后,使用离散的状态空间方程来捕捉每个序列的长程依赖性。最后,将所有扫描序列进行求和,并通过 reshape 操作恢复其原始的二维结构。
6、损失函数
采用 L1 损失函数来优化 MambaIR 以进行图像超分辨率(SR)。具体损失函数公式如下:
其中 表示 L1 范数。
对于图像去噪任务,我们使用 Charbonnier 损失,其公式为:
其中 为一个小的常数,用于稳定计算并避免数值问题。
四、实验
1、数据集
为了进行图像恢复任务的实验,我们遵循先前工作的设置 ,涵盖了图像超分辨率(包括经典超分辨率、轻量级超分辨率、真实超分辨率)、图像去噪(包括高斯彩色图像去噪和真实世界图像去噪)以及 JPEG 压缩伪影去除(JPEG CAR)。我们使用了以下数据集来训练和评估模型:
-
图像超分辨率(SR):
-
训练数据集:DIV2K和 Flickr2K用于经典超分辨率模型的训练;仅使用 DIV2K 来训练轻量级超分辨率模型。
-
测试数据集:Set5 、Set14、B100、Urban100和 Manga109 用于评估不同超分辨率方法的效果。
-
-
高斯彩色图像去噪:
-
训练数据集:DIV2K 、Flickr2K、BSD500 和 WED。
-
测试数据集:BSD68、Kodak24 、McMaster和 Urban100。
-
-
真实图像去噪:
-
训练数据集:使用来自 SIDD 数据集的320张高分辨率图像进行训练。
-
测试数据集:使用 SIDD 测试集和 DND数据集进行测试。
-
模型评估:所有任务的性能均通过在 YCbCr 颜色空间的 Y 通道上计算 PSNR 和 SSIM 来进行评估。当测试时使用自集成策略时,模型被称为 MambaIR+。
2、实验细节
根据先前的工作,我们对数据进行了增强,方法包括水平翻转和随机旋转(90°、180°、270°)。此外,在训练过程中,我们将原始图像裁剪为 64×64 的图像块用于超分辨率任务,裁剪为 128×128 的图像块用于去噪任务。
-
图像超分辨率(SR)训练:
我们使用 ×2 模型的预训练权重来初始化 ×3 和 ×4 模型的权重,并通过减半学习率和训练总迭代次数来减少训练时间。 -
批量大小调整:
为了确保公平比较,我们将图像超分辨率的训练批量大小调整为 32,图像去噪的训练批量大小调整为 16。 -
优化器与学习率:
我们使用 Adam 优化器,其超参数为,
。初始学习率设置为
,并在训练达到特定的里程碑时将学习率减半。
-
硬件配置:
我们的 MambaIR 模型使用 8 台 NVIDIA V100 GPU 进行训练。
3、消融实验

4、超分辨率对比实验

5、图像去噪对比实验
相关文章:
《MambaIR:一种基于状态空间模型的简单图像修复基线方法》学习笔记
paper:2402.15648 目录 摘要 一、引言 1、模型性能的提升依赖于网络感受野的扩大: 2、全局感受野和高效计算之间存在固有矛盾: 3、改进版 Mamba的巨大潜力 4、Mamba 在图像修复任务中仍面临以下挑战: 5、方法 6、主要贡献…...

链式前向星的写法
【图论02】动画说图的三种保存方式 降低理解门槛 邻接表 链式前向星 邻接矩阵_哔哩哔哩_bilibili 杭电ACM刘老师-算法入门培训-第12讲-拓扑排序及链式前向星_哔哩哔哩_bilibili 图论003链式前向星_哔哩哔哩_bilibili(链式前向星的遍历) head数组的下标…...

【逆境中绽放:万字回顾2024我在挑战中突破自我】
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:“没有罗马,那就自己创造罗马~” 文章目录 一、引言二、个人成长与盘点情感与心理成长学习与技能提升其它荣誉 三、年度创作历程回顾创作内容概…...
)
尺取法(算法优化技巧)
问题和序列的区间有关,且需要操作两个变量,可以用两个下标(指针)i 和 j 扫描区间。 1,反向扫描,i 从头,j 从尾,在中间相遇。 例1.1(P37) 找指定和的整数对…...

基于 K-Means 聚类分析实现人脸照片的快速分类
注:本文在创作过程中得到了 ChatGPT、DeepSeek、Kimi 的智能辅助支持,由作者本人完成最终审阅。 在 “视频是不能 P 的” 系列文章中,博主曾先后分享过人脸检测、人脸识别等相关主题的内容。今天,博主想和大家讨论的是人脸分类问题。你是否曾在人群中认错人,或是盯着熟人的…...
【漏洞预警】FortiOS 和 FortiProxy 身份认证绕过漏洞(CVE-2024-55591)
文章目录 一、产品简介二、漏洞描述三、影响版本四、漏洞检测方法五、解决方案 一、产品简介 FortiOS是Fortinet公司核心的网络安全操作系统,广泛应用于FortiGate下一代防火墙,为用户提供防火墙、VPN、入侵防御、应用控制等多种安全功能。 FortiProxy则…...
7.5.4 MVCC优化测试
作者: h5n1 原文来源: https://tidb.net/blog/4e02d900 1. 背景 由于MVCC 版本数量过多导致rocksdb扫描key数量过多影响SQL执行时间是tidb经常出现问的问题,tidb也一直在致力于优化该问题。 一些优化方式包括比: (1) 从传统…...

STM32 FreeRTOS 事件标志组
目录 事件标志组简介 基本概念 1、事件位(事件标志) 2、事件组 事件组和事件位数据类型 事件标志组和信号量的区别 事件标志组相关API函数介绍 事件标志组简介 基本概念 当在嵌入式系统中运行多个任务时,这些任务可能需要相互通信&am…...

生成树机制实验
1 实验内容 1、基于已有代码,实现生成树运行机制,对于给定拓扑(four_node_ring.py),计算输出相应状态下的生成树拓扑 2、构造一个不少于7个节点,冗余链路不少于2条的拓扑,节点和端口的命名规则可参考four_node_ring.py,使用stp程序计算输出生成树拓扑 2 实验原理 一、…...

企业分类相似度筛选实战:基于规则与向量方法的对比分析
文章目录 企业表相似类别筛选实战项目背景介绍效果展示基于规则的效果基于向量相似的效果 说明相关文章推荐 企业表相似类别筛选实战 项目背景 在当下RAG(检索增强生成)技术应用不断发展的背景下,掌握文本相似算法不仅能够助力信息检索&…...
2024年博客之星年度评选—创作影响力评审入围名单公布
2024年博客之星活动地址https://www.csdn.net/blogstar2024 TOP 300 榜单排名 用户昵称博客主页 身份 认证 评分 原创 博文 评分 平均 质量分评分 互动数据评分 总分排名三掌柜666三掌柜666-CSDN博客1001002001005001wkd_007wkd_007-CSDN博客1001002001005002栗筝ihttps:/…...

递归40题!再见递归
简介:40个问题,有难有易,均使用递归完成,需要C/C的指针、字符串、数组、链表等基础知识作为基础。 1、数字出现的次数 由键盘录入一个正整数,求该整数中每个数字出现的次数。 输入:19931003 输出…...

社区版Dify实现文生视频 LLM+ComfyUI+混元视频
社区版Dify实现文生视频 LLMComfyUI混元视频 一、 社区版Dify实现私有化混元视频效果二、为什么社区版Dify可以在对话框实现文生视频?LLMComfyUI混元视频 实现流程图(重点)1. 文生视频模型支持ComfyUI2. ComfyUI可以轻松导出API实现封装3. Di…...

【LLM】Openai-o1及o1类复现方法
note 可以从更为本质的方案出发,通过分析强化学习的方法,看看如何实现o1,但其中的核心就是在于,如何有效地初始化策略、设计奖励函数、实现高效的搜索算法以及利用强化学习进行学习和优化。 文章目录 note一、Imitate, Explore, …...

jlatexmath-android如何实现自定义渲染字符
使用jlatexmath-android的过程,如果出现个别字符渲染不了,会导致无法显示 常用的做法是新增自定义字体切换系统默认字体渲染,下面我们介绍第2种方法。 修改流程: 1、到jlatexmath-android的官网下载源码到本地,导入…...

dockerhub上一些镜像
K8s下网络排障工具 https://hub.docker.com/r/nicolaka/netshoot ex kubectl run tmp-shell --rm -i --tty --image nicolaka/netshoot -- /bin/bash # 主机的net ns下运行 kubectl run tmp-shell --rm -i --tty --overrides{"spec": {"hostNetwork": tru…...

Python 爬虫学习指南与资料分享
Python爬虫学习资料 Python爬虫学习资料 Python爬虫学习资料 在数字化浪潮中,Python 爬虫作为强大的数据获取工具,为众多领域提供关键支持。想要系统掌握这门技术,以下的学习指南与资料分享将为你照亮前行道路。 一、学习指南 入门奠基 …...

TypeScript特有运算符和操作符
文章目录 TypeScript 特有运算符1. keyof2. typeof3. in4. extends5. is6. as 和 <Type>7. never8. readonly9. ?10. []11. | 和 &12. !13. ?? 和 ?. 总结 TypeScript 特有运算符 1. keyof 作用:用于获取对象类型的所有键(属性名&#x…...

介绍下常用的前端框架及时优缺点
以下是一些常用的前端框架及其优缺点介绍: React • 优点 • 组件化架构:可构建可复用的UI组件,提高开发效率和组件可维护性。 • 虚拟DOM:高效更新页面,减少直接操作DOM的性能开销。 • 灵活性和可扩展性…...
)
MATLAB算法实战应用案例精讲-【数模应用】图形变换和复杂图形组合(附python和MATLAB代码实现)
目录 前言 算法原理 变换 1二维变换 1.1缩放 1.2 翻转 1.3剪切 1.4 旋转 2齐次坐标 2.1引入齐次坐标的原因 2.2 二维齐次坐标 2.3二维仿射变换 2.4逆变换 4组合变换 5三维变换(由二维变换推理而来) 5.1三维齐次坐标 5.2 三维仿射变换 5.3 缩放和平移 5.4…...

从零到一:深度解析BertTokenizer.from_pretrained的加载机制与实战技巧
1. 初识BertTokenizer.from_pretrained:你的NLP敲门砖 第一次接触Hugging Face的Transformers库时,我被BertTokenizer.from_pretrained()这个方法深深吸引了。它就像是一把万能钥匙,能快速打开各种预训练语言模型的大门。记得当时我尝试用传统…...
 实战:如何用USRP搭建你的第一个5G仿真环境(附避坑指南))
OpenAirInterface (OAI) 实战:如何用USRP搭建你的第一个5G仿真环境(附避坑指南)
OpenAirInterface (OAI) 实战:如何用USRP搭建你的第一个5G仿真环境(附避坑指南) 当5G技术从实验室走向商业化时,开源软件无线电平台OpenAirInterface(OAI)正成为开发者验证创新想法的关键工具。不同于商业设…...

Qwen3-TTS作品分享:听AI朗读你的日记、诗歌和故事
Qwen3-TTS作品分享:听AI朗读你的日记、诗歌和故事 1. 为什么你需要一个会"读心"的语音合成工具 想象一下这样的场景:深夜写完日记,点击播放键,听到一个温暖的声音将你的文字娓娓道来;创作完一首诗…...

Windows更新修复新范式:Reset-Windows-Update-Tool的系统化解决方案
Windows更新修复新范式:Reset-Windows-Update-Tool的系统化解决方案 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-Tool …...

ROS2 Humble下,如何用MoveIt! Action接口让机械臂“听话”?一个抓取demo的完整复盘
ROS2 Humble下机械臂精准控制实战:从MoveIt! Action接口到完整抓取任务 在工业自动化和服务机器人领域,机械臂的精准运动控制一直是核心挑战。ROS2 Humble版本中的MoveIt!框架为这一挑战提供了优雅的解决方案,而理解其Action接口的运作机制则…...

OBS多平台直播同步解决方案:从配置到优化的完整指南
OBS多平台直播同步解决方案:从配置到优化的完整指南 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 在当今内容创作领域,多平台同步直播已成为扩大受众覆盖的关键…...

判断一个链表是否是环形链表
给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索…...

s2-pro实战落地:跨境电商产品介绍多语种语音批量生成
s2-pro实战落地:跨境电商产品介绍多语种语音批量生成 1. 场景痛点与解决方案 跨境电商企业面临一个共同挑战:如何高效地为全球不同语言市场的产品生成专业语音介绍。传统方案需要雇佣多语种配音人员,成本高、周期长,且难以保证语…...

Qwen3-14B镜像轻量化设计:50GB系统盘+40GB数据盘高效空间管理
Qwen3-14B镜像轻量化设计:50GB系统盘40GB数据盘高效空间管理 1. 镜像概述与核心优势 Qwen3-14B私有部署镜像是一款专为RTX 4090D 24GB显存显卡优化的轻量化解决方案。通过精心设计的50GB系统盘40GB数据盘架构,实现了大模型部署的空间效率最大化。这个镜…...

视频硬字幕提取终极指南:用本地AI工具10倍提升你的字幕制作效率
视频硬字幕提取终极指南:用本地AI工具10倍提升你的字幕制作效率 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测…...