0基础跟德姆(dom)一起学AI 自然语言处理18-解码器部分实现
1 解码器介绍
解码器部分:
- 由N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接

- 说明:
- 解码器层中的各个部分,如,多头注意力机制,规范化层,前馈全连接网络,子层连接结构都与编码器中的实现相同. 因此这里可以直接拿来构建解码器层.
2 解码器层
2.1 解码器层的作用
- 作为解码器的组成单元, 每个解码器层根据给定的输入向目标方向进行特征提取操作,即解码过程.
2.2 解码器层的代码实现
# 解码器层类 DecoderLayer 实现思路分析
# init函数 (self, size, self_attn, src_attn, feed_forward, dropout)# 词嵌入维度尺寸大小size 自注意力机制层对象self_attn 一般注意力机制层对象src_attn 前馈全连接层对象feed_forward# clones3子层连接结构 self.sublayer = clones(SublayerConnection(size,dropout),3)
# forward函数 (self, x, memory, source_mask, target_mask)# 数据经过子层连接结构1 self.sublayer[0](x, lambda x:self.self_attn(x, x, x, target_mask))# 数据经过子层连接结构2 self.sublayer[1](x, lambda x:self.src_attn(x, m, m, source_mask))# 数据经过子层连接结构3 self.sublayer[2](x, self.feed_forward)class DecoderLayer(nn.Module):def __init__(self, size, self_attn, src_attn, feed_forward, dropout):super(DecoderLayer, self).__init__()# 词嵌入维度尺寸大小self.size = size# 自注意力机制层对象 q=k=vself.self_attn = self_attn# 一遍注意力机制对象 q!=k=vself.src_attn = src_attn# 前馈全连接层对象self.feed_forward = feed_forward# clones3子层连接结构self.sublayer = clones(SublayerConnection(size, dropout), 3)def forward(self, x, memory, source_mask, target_mask):m = memory# 数据经过子层连接结构1x = self.sublayer[0](x, lambda x:self.self_attn(x, x, x, target_mask))# 数据经过子层连接结构2x = self.sublayer[1](x, lambda x:self.src_attn (x, m, m, source_mask))# 数据经过子层连接结构3x = self.sublayer[2](x, self.feed_forward)return x
- 函数调用
def dm_test_DecoderLayer():d_model = 512vocab = 1000 # 词表大小是1000# 输入x 是一个使用Variable封装的长整型张量, 形状是2 x 4x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))emb = Embeddings(d_model, vocab)embr = emb(x)dropout = 0.2max_len = 60 # 句子最大长度x = embr # [2, 4, 512]pe = PositionalEncoding(d_model, dropout, max_len)pe_result = pe(x)x = pe_result # 获取位置编码器层 编码以后的结果# 类的实例化参数与解码器层类似, 相比多出了src_attn, 但是和self_attn是同一个类.head = 8d_ff = 64size = 512self_attn = src_attn = MultiHeadedAttention(head, d_model, dropout)# 前馈全连接层也和之前相同ff = PositionwiseFeedForward(d_model, d_ff, dropout)x = pe_result# 产生编码器结果 # 注意此函数返回编码以后的结果 要有返回值en_result = dm_test_Encoder()memory = en_resultmask = Variable(torch.zeros(8, 4, 4))source_mask = target_mask = mask# 实例化解码器层 对象dl = DecoderLayer(size, self_attn, src_attn, ff, dropout)# 对象调用dl_result = dl(x, memory, source_mask, target_mask)print(dl_result.shape)print(dl_result)
- 输出效果
torch.Size([2, 4, 512])
tensor([[[-27.4382, 0.6516, 6.6735, ..., -42.2930, -44.9728, 0.1264],[-28.7835, 26.4919, -0.5608, ..., 0.5652, -2.9634, 9.7438],[-19.6998, 13.5164, 45.8216, ..., 23.9127, 22.0259, 34.0195],[ -0.1647, 0.2331, -36.4173, ..., -20.0557, 29.4576, 2.5048]],[[ 29.1466, 50.7677, 26.4624, ..., -39.1015, -27.9200, 19.6819],[-10.7069, 28.0897, -0.4107, ..., -35.7795, 9.6881, 0.3228],[ -6.9027, -16.0590, -0.8897, ..., 4.0253, 2.5961, 37.4659],[ 9.8892, 32.7008, -6.6772, ..., -11.4273, -21.4676, 32.5692]]],grad_fn=<AddBackward0>)
2.3 解码器层总结¶
-
学习了解码器层的作用:
- 作为解码器的组成单元, 每个解码器层根据给定的输入向目标方向进行特征提取操作,即解码过程.
-
学习并实现了解码器层的类: DecoderLayer
- 类的初始化函数的参数有5个, 分别是size,代表词嵌入的维度大小, 同时也代表解码器层的尺寸,第二个是self_attn,多头自注意力对象,也就是说这个注意力机制需要Q=K=V,第三个是src_attn,多头注意力对象,这里Q!=K=V, 第四个是前馈全连接层对象,最后就是droupout置0比率.
- forward函数的参数有4个,分别是来自上一层的输入x,来自编码器层的语义存储变量mermory, 以及源数据掩码张量和目标数据掩码张量.
- 最终输出了由编码器输入和目标数据一同作用的特征提取结果.
3 解码器
3.1 解码器的作用
- 根据编码器的结果以及上一次预测的结果, 对下一次可能出现的'值'进行特征表示.
3.2 解码器的代码分析
# 解码器类 Decoder 实现思路分析
# init函数 (self, layer, N):# self.layers clones N个解码器层clones(layer, N)# self.norm 定义规范化层 LayerNorm(layer.size)
# forward函数 (self, x, memory, source_mask, target_mask)# 数据以此经过各个子层 x = layer(x, memory, source_mask, target_mask)# 数据最后经过规范化层 return self.norm(x)# 返回处理好的数据class Decoder(nn.Module):def __init__(self, layer, N):# 参数layer 解码器层对象# 参数N 解码器层对象的个数super(Decoder, self).__init__()# clones N个解码器层self.layers = clones(layer, N)# 定义规范化层self.norm = LayerNorm(layer.size)def forward(self, x, memory, source_mask, target_mask):# 数据以此经过各个子层for layer in self.layers:x = layer(x, memory, source_mask, target_mask)# 数据最后经过规范化层return self.norm(x)
- 函数调用
# 测试 解码器
def dm_test_Decoder():d_model = 512vocab = 1000 # 词表大小是1000# 输入x 是一个使用Variable封装的长整型张量, 形状是2 x 4x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))emb = Embeddings(d_model, vocab)embr = emb(x)dropout = 0.2max_len = 60 # 句子最大长度x = embr # [2, 4, 512]pe = PositionalEncoding(d_model, dropout, max_len)pe_result = pe(x)x = pe_result # 获取位置编码器层 编码以后的结果# 分别是解码器层layer和解码器层的个数Nsize = 512d_model = 512head = 8d_ff = 64dropout = 0.2c = copy.deepcopy# 多头注意力对象attn = MultiHeadedAttention(head, d_model)# 前馈全连接层ff = PositionwiseFeedForward(d_model, d_ff, dropout)# 解码器层layer = DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout)N = 6# 输入参数与解码器层的输入参数相同x = pe_result# 产生编码器结果en_result = demo238_test_Encoder()memory = en_result# 掩码对象mask = Variable(torch.zeros(8, 4, 4))# sorce掩码 target掩码source_mask = target_mask = mask# 创建 解码器 对象de = Decoder(layer, N)# 解码器对象 解码de_result = de(x, memory, source_mask, target_mask)print(de_result)print(de_result.shape)
- 输出结果
tensor([[[ 0.1853, -0.8858, -0.0393, ..., -1.4989, -1.4008, 0.8456],[-1.0841, -0.0777, 0.0836, ..., -1.5568, 1.4074, -0.0848],[-0.4107, -0.1306, -0.0069, ..., -0.2370, -0.1259, 0.7591],[ 1.2895, 0.2655, 1.1799, ..., -0.2413, 0.9087, 0.4055]],[[ 0.3645, -0.3991, -1.2862, ..., -0.7078, -0.1457, -1.0457],[ 0.0146, -0.0639, -1.2143, ..., -0.7865, -0.1270, 0.5623],[ 0.0685, -0.1465, -0.1354, ..., 0.0738, -0.9769, -1.4295],[ 0.3168, 0.6305, -0.1549, ..., 1.0969, 1.8775, -0.5154]]],grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
相关文章:
0基础跟德姆(dom)一起学AI 自然语言处理18-解码器部分实现
1 解码器介绍 解码器部分: 由N个解码器层堆叠而成每个解码器层由三个子层连接结构组成第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接第三个子层连接结构包括一个前馈全连接子层…...

我的创作纪念日——我与CSDN一起走过的365天
目录 一、机缘:旅程的开始 二、收获:沿路的花朵 三、日常:不断前行中 四、成就:一点小确幸 五、憧憬:梦中的重点 一、机缘:旅程的开始 最开始开始写博客是在今年一二月份的时候,也就是上一…...

C++:bfs解决多源最短路与拓扑排序问题习题
1. 多源最短路 其实就是将所有源头都加入队列, 01矩阵 LCR 107. 01 矩阵 - 力扣(LeetCode) 思路 求每个元素到离其最近0的距离如果我们将1当做源头加入队列的话,无法处理多个连续1的距离存储,我们反其道而行之&…...

【面试题】JVM部分[2025/1/13 ~ 2025/1/19]
JVM部分[2025/1/13 ~ 2025/1/19] 1. JVM 由哪些部分组成?2. Java 的类加载过程是怎样的?3. 请你介绍下 JVM 内存模型,分为哪些区域?各区域的作用是什么?4. JVM 垃圾回收调优的主要目标是什么?5. 如何对 Jav…...

文献综述相关ChatGPT提示词分享
文献综述 ChatGPT 可以帮助提高文献综述的有效性和全面性。ChatGPT可以高效搜索和审查与宝子们课题研究相关的文献资料来源。一些给力的插件工具还可以帮助您总结复杂的研究论文并提取信息以更快更好地消化信息。合理的运用ChatGPT和GPTs可以提高文献综述的清晰度和质量&#…...

Excel 技巧14 - 如何批量删除表格中的空行(★)
本文讲如何批量删除表格中的空行。 1,如何批量删除表格中的空行 要点就是按下F5,然后选择空值条件以定位所有空行,然后删除即可。 按下F5 点 定位条件 选 空值,点确认 这样就选中了空行 然后点右键,选 删除 选中 下方…...

图片生成Prompt编写技巧
1. 图片情绪(场景氛围) 一张图片一般都会有一个情绪基调,因为作画本质上也是在传达一些情绪,一般都会借助图片的氛围去转达。例如:比如家庭聚会一般是欢乐、喜乐融融。断壁残垣一般是悲凉。还有萧瑟、孤寂等。 2.补充细…...

【STM32-学习笔记-4-】PWM、输入捕获(PWMI)
文章目录 1、PWMPWM配置 2、输入捕获配置3、编码器 1、PWM PWM配置 配置时基单元配置输出比较单元配置输出PWM波的端口 #include "stm32f10x.h" // Device headervoid PWM_Init(void) { //**配置输出PWM波的端口**********************************…...
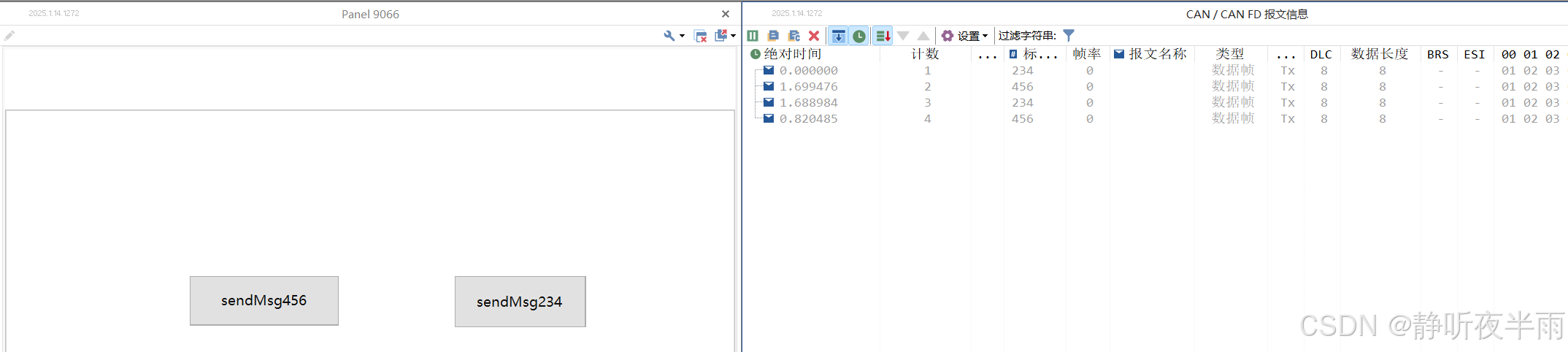
TOSUN同星TsMaster使用入门——3、使用系统变量及c小程序结合panel面板发送报文
本篇内容将介绍TsMaster中常用的Panel面板控件以及使用Panel控件通过系统变量以及c小程序来修改信号的值,控制报文的发送等。 目录 一、常用的Panel控件介绍 1.1系统——启动停止按钮 1.2 显示控件——文本框 1.3 显示控件——分组框 1.4 读写控件——按钮 1.…...

【Web】2025-SUCTF个人wp
目录 SU_blog SU_photogallery SU_POP SU_blog 先是注册功能覆盖admin账号 以admin身份登录,拿到读文件的权限 ./article?filearticles/..././..././..././..././..././..././etc/passwd ./article?filearticles/..././..././..././..././..././..././proc/1…...

React进阶之react.js、jsx模板语法及babel编译
React React介绍React官网初识React学习MVCMVVM JSX外部的元素props和内部的状态statepropsstate 生命周期constructorgetDerivedStateFromPropsrendercomponentDidMount()shouldComponentUpdategetSnapshotBeforeUpdate(prevProps, prevState) 创建项目CRA:create-…...

在Linux上如何让ollama在GPU上运行模型
之前一直在 Mac 上使用 ollama 所以没注意,最近在 Ubuntu 上运行发现一直在 CPU 上跑。我一开始以为是超显存了,因为 Mac 上如果超内存的话,那么就只用 CPU,但是我发现 Llama3.2 3B 只占用 3GB,这远没有超。看了一下命…...

R 语言科研绘图第 20 期 --- 箱线图-配对
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

suctf2025
Suctf2025 --2标识为看的wp,没环境复现了 所有参考资料将在文本末尾标明 WEB SU_photogallery 思路👇 构造一个压缩包,解压出我们想解压的部分,然后其他部分是损坏的,这样是不是就可以让整个解压过程是出错的从而…...

Quinlan C4.5剪枝U(0,6)U(1,16)等置信上限如何计算?
之前看到Quinlan中关于C4.5决策树算法剪枝环节中,关于错误率e置信区间估计,为啥 当E=0时,U(0,1)=0.75,U(0,6)=0.206,U(0,9)=0.143? 而当E不为0时,比如U(1,16)=0.157,如图: 关于C4.5决策树,Quinlan写了一本书,如下: J. Ross Quinlan (Auth.) - C4.5. Programs f…...

计算机组成原理--笔记二
目录 一.计算机系统的工作原理 二.计算机的性能指标 1.存储器的性能指标 2.CPU的性能指标 3.系统整体的性能指标(静态) 4.系统整体的性能指标(动态) 三.进制计算 1.任意进制 > 十进制 2.二进制 <> 八、十六进制…...

麒麟系统中删除权限不够的文件方法
在麒麟系统中删除权限不够的文件,可以尝试以下几种方法: 通过修改文件权限删除 打开终端:点击左下角的“终端”图标,或者通过搜索功能找到并打开终端 。定位文件:使用cd命令切换到文件所在的目录 。修改文件权限&…...

自定义提示确认弹窗-vue
最初可运行代码 弹窗组件代码: (后来发现以下代码可运行,但打包 typescript 类型检查出错,可打包的代码在文末) <template><div v-if"isVisible" class"dialog"><div class&quo…...

运行fastGPT 第五步 配置FastGPT和上传知识库 打造AI客服
运行fastGPT 第五步 配置FastGPT和上传知识库 打造AI客服 根据上一步的步骤,已经调试了ONE API的接口,下面,我们就登陆fastGPT吧 http://xxx.xxx.xxx.xxx:3000/ 这个就是你的fastGPT后台地址,可以在configer文件中找到。 账号是…...

CSS 合法颜色值
CSS 颜色 CSS 中的颜色可以通过以下方法指定: 十六进制颜色带透明度的十六进制颜色RGB 颜色RGBA 颜色HSL 颜色HSLA 颜色预定义/跨浏览器的颜色名称使用 currentcolor 关键字 十六进制颜色 用 #RRGGBB 规定十六进制颜色,其中 RR(红色&…...

Jetson Orin Nano 升级jetpack5.1.2刷机过程记录
一.刷机起因 orin nano 接了个IMX477的摄像头,用 命令行DISPLAY:0.0 nvgstcapture-1.0 显示的画面有撕裂,让卖家查问题,卖家测试没有撕裂,对比环境,orin nano出厂默认的是jetpack5.1.1,卖家用的jetpack5.1.2版本,为了解决差异,要升级jetpack版本,前后搞了2天半,记录一下. 另外…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

基于ESP32与MQTT的家庭环境监测系统:从传感器选型到数据可视化实战
1. 项目概述与核心价值最近几年,我身边越来越多的朋友开始关注家里的空气质量、温湿度这些看不见摸不着,但又实实在在影响生活舒适度和健康的环境指标。从新装修的房子担心甲醛,到有老人小孩的家庭在意PM2.5和二氧化碳浓度,再到南…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

具身智能:面向新兴交叉学科建设的思考与建议 2026
这份由 CCF YOCSEF 长三角五地学术委员会 2026 年 5 月发布的白皮书,聚焦具身智能作为新兴交叉学科的建设,明确其并非 AI 与机器人学的简单拼接,而是围绕物理交互中的智能行为形成的新问题域,提出 “三大基本问题 一个应用需求”…...

学了几天 Web 安全,终于搞懂什么是 XSS 了
xss的详细介绍最近开始正式学习 Web 安全。前面陆续学了:HTTPCookieSessionJWT RBAC然后发现很多地方都会提到一个东西:XSS以前一直感觉这个漏洞很抽象。网上很多文章一上来就是:<script>alert(1)</script>然后说:“弹…...