【文件篇】11.磁盘文件系统
上一篇博客中我们介绍到如果我们要访问文件首先需要打开这个文件,而文件是在磁盘上存储的,也就是说需要在磁盘上找到这个文件的路径。但是磁盘上有很多文件,这些文件都有自己的路径的,这些文件还有内容和属性,它们都是被存储在磁盘上的,这就需要磁盘对它们进行管理,即磁盘文件系统。
一、认识磁盘结构
1.1 认识硬件

• 机械磁盘是电脑中的唯一一个机械设备,但是现在我们使用的大多是ssd了。
• 磁盘最主要的特点就是:速度慢但容量大、价格便宜。
• 机械磁盘组成服务器,服务器组成机柜,机柜组成机房。
1.2 磁盘的物理结构
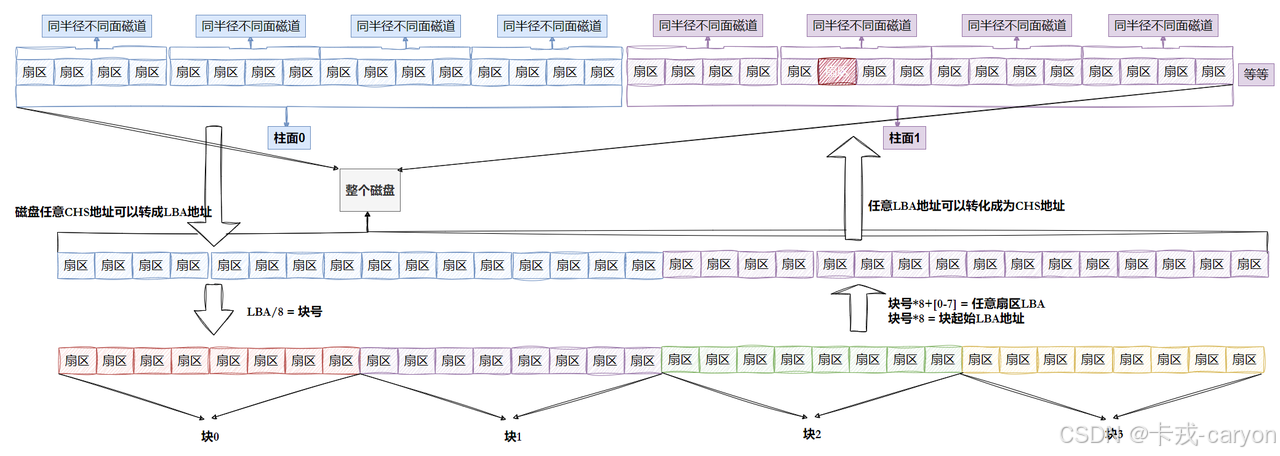
磁盘是怎么保存数据的?
计算机是只能识别二进制的,对应的也就是磁铁的N、S级。

上图就是磁盘的物理结构,磁盘可以顺时针高速旋转,磁头可以在磁盘上来回左右摆动,但是磁盘和磁头是不接触的。
1.3 磁盘的存储结构
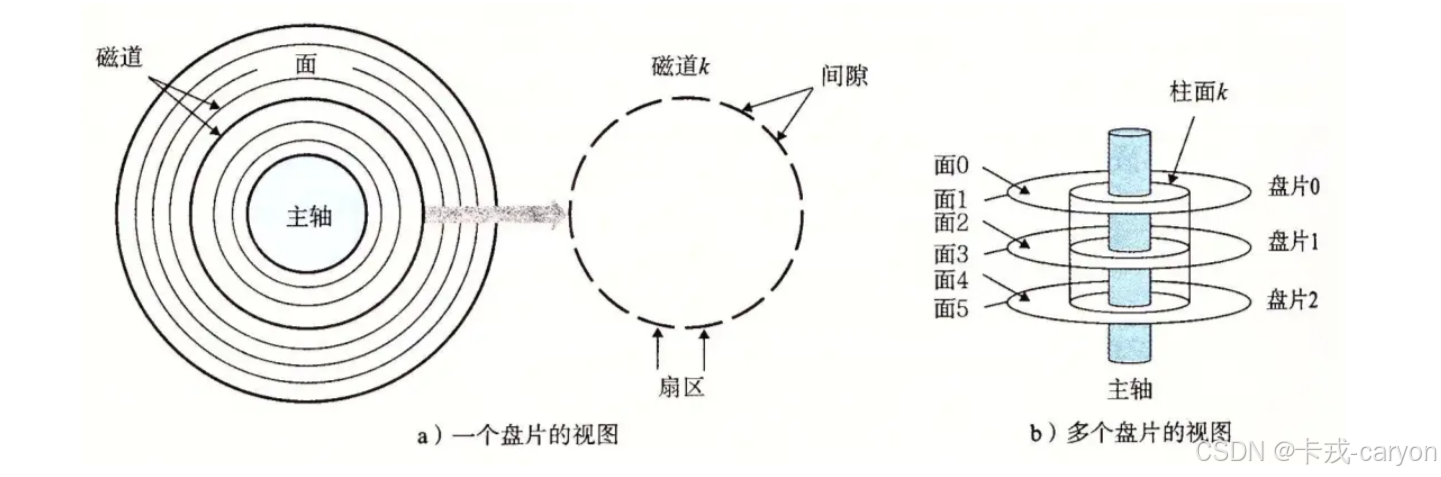
• 磁盘上面有磁道,磁道是由一段一段的扇区构成。以主轴为分割点多个盘片摞在一起构成了柱面,磁盘的正反面都能存储数据。
• 扇区是磁盘存储数据的基本单位,512字节,又被称为块设备。
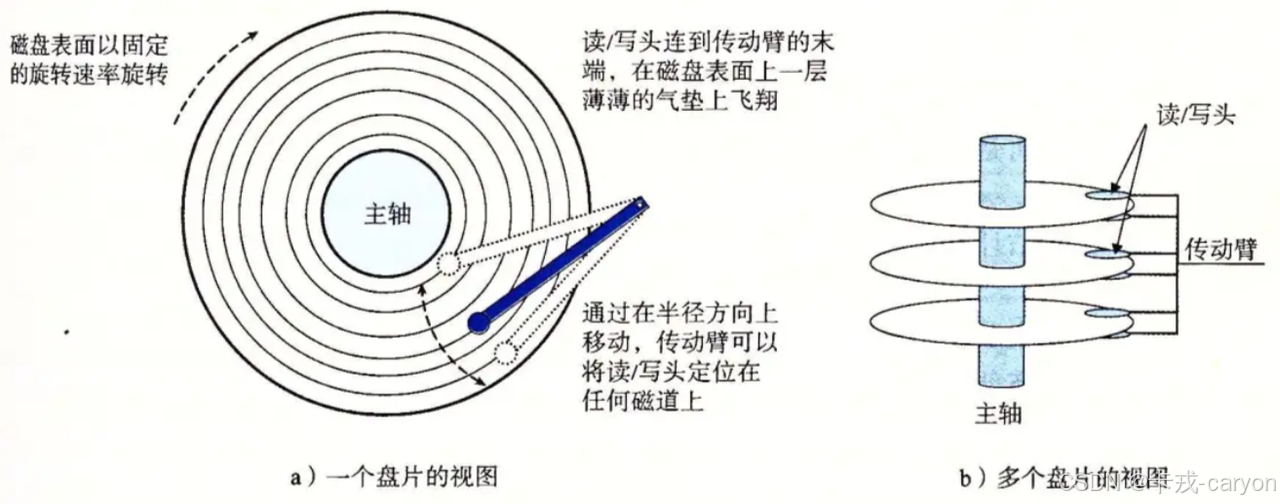
• 传动臂上的磁头是共进退的。
如何定位扇区?
第一步定位柱面(cylinder),第二步定位磁头(header),第三步定位扇区(sector)。这也就是CHS地址定位法。
我们可以使用下面的指令查看磁盘信息:
[root@VM-24-10-centos ~]# fdisk -lDisk /dev/vda: 53.7 GB, 53687091200 bytes, 104857600 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x0009ac89Device Boot Start End Blocks Id System
/dev/vda1 * 2048 104857566 52427759+ 83 Linux
1.4 磁盘的逻辑结构
1.4.1 理解过程
逻辑上我们可以把磁盘想象成为卷在一起的磁带,那么磁盘的逻辑存储结构我们也可以类似于:

这样每一个扇区,就有了一个线性地址(其实就是数组下标),这种地址叫做LBA,扇区的编号通常从1开始。
1.4.2 真实过程
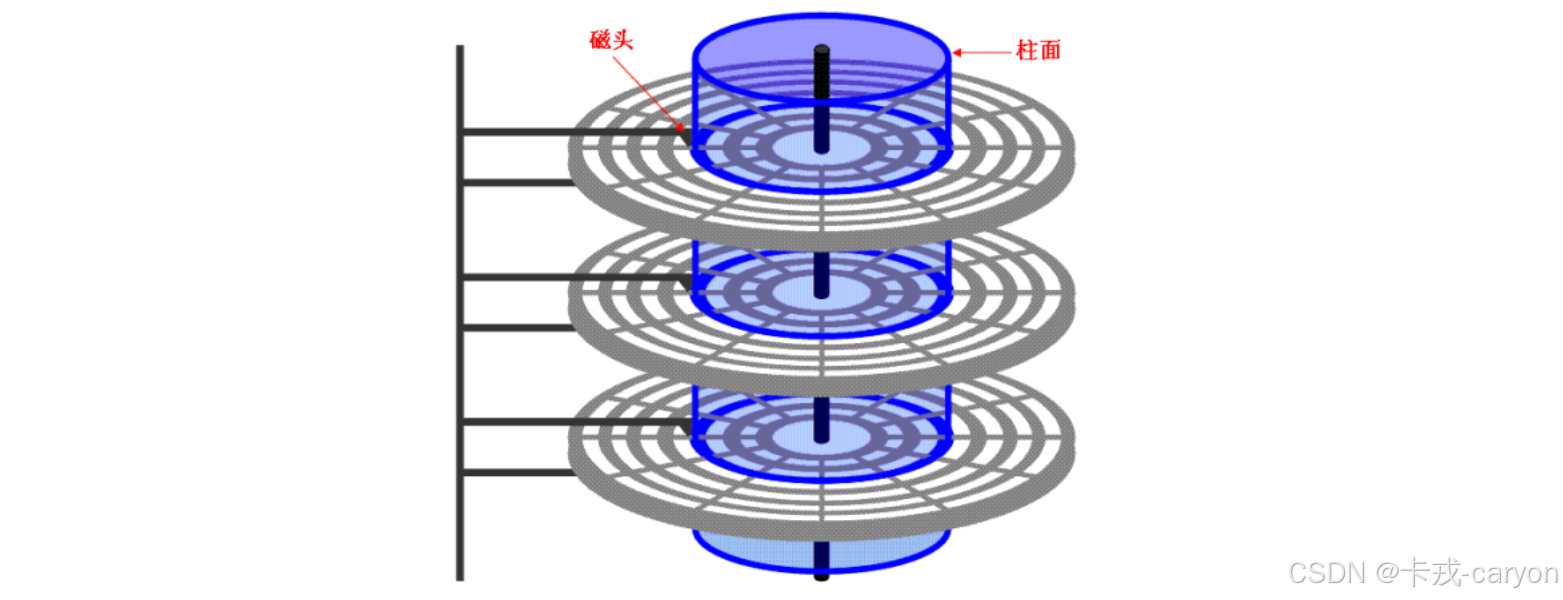
柱面是一个逻辑上的概念,其实就是每一面上,相同半径的磁道逻辑上构成柱面。所以,磁盘物理上分了很多面,但是在我们看来,逻辑上,磁盘整体是由“柱面”卷起来的。
所以,磁盘的真实情况如下:
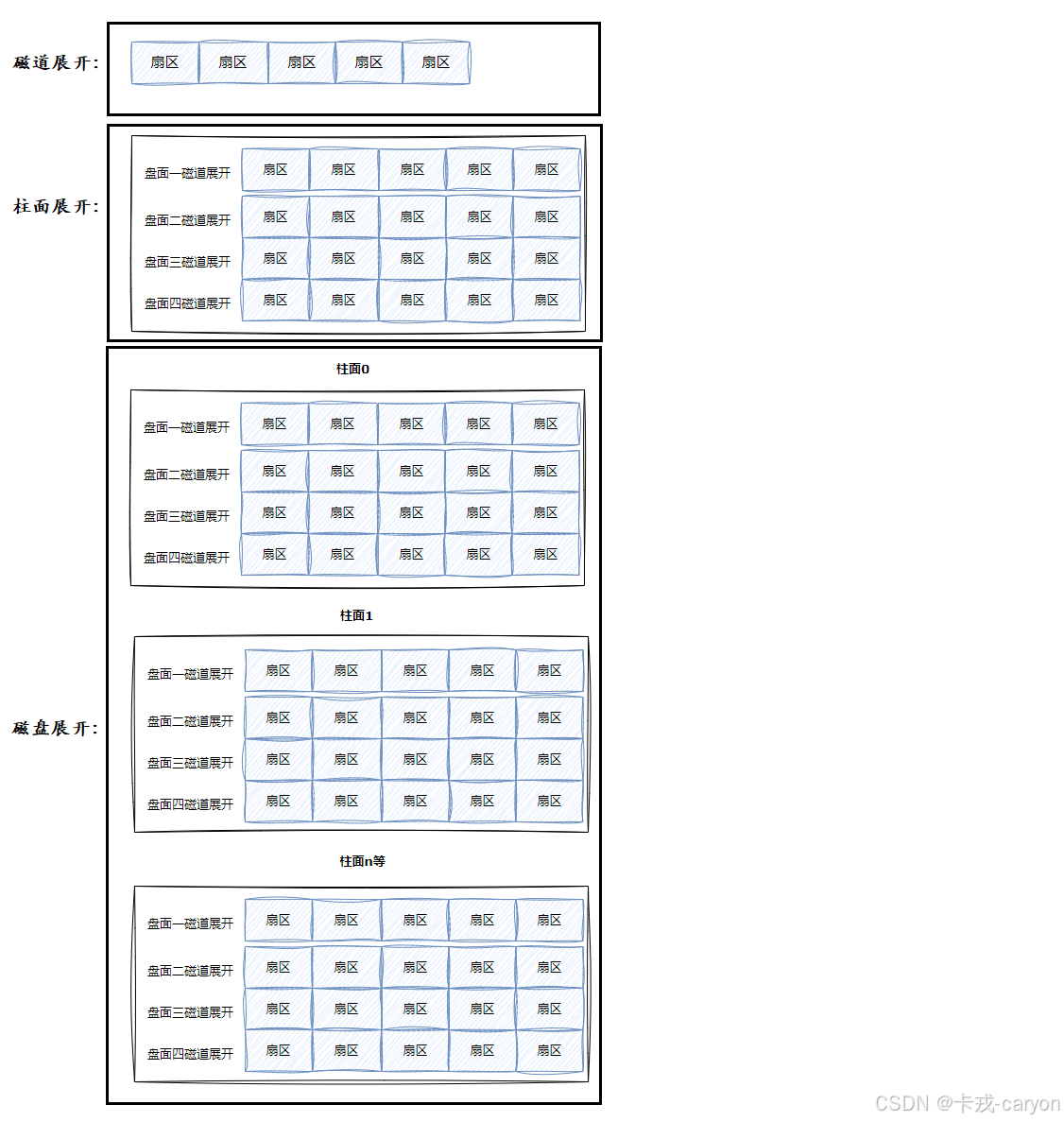
• 可以看出整个磁盘就是三维的扇区数组表,上面我们也有说到寻址一个扇区:先找到哪一个柱面(Cylinder),在确定柱面内哪一个磁道(其实就是磁头位置,Head),在确定扇区(Sector),所以就有了CHS。
• 我们之前学过C/C++的数组,在我们看来,其实全部都是一维数组:
• 一个扇区有一个下标,我们称为LBA(Logical Block Address)地址,其实就是线性地址。但是对于操作系统来说只需要使用LBA就可以了。LBA地址转成CHS地址,CHS地址转成LBA地址这一过程是由磁盘使用固件(硬件电路,伺服系统)来做的。
CHS地址转化为LBA地址:
LBA=柱面号C*(磁头数*每磁道扇区数)+磁头号H*每磁道扇区数+扇区号S-1
LBA地址转化为CHS地址:
柱面号C=LBA//(磁头数*每磁道扇区数)
磁头号H=(LBA%(磁头数*每磁道扇区数))//每磁道扇区数
扇区号S=(LBA%每磁道扇区数)+1
二、文件系统的引入
2.1 块的引入
硬盘是典型的“块”设备,操作系统读取硬盘数据的时候,其实是不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个”块”(block)。
硬盘的每个分区是被划分为一个个的”块”。一个”块”的大小是由格式化的时候确定的,并且不可以更改,最常见的是4KB,即连续八个扇区组成一个”块”。”块”是文件存取的最小单位。
2.2 分区的引入
磁盘是可以被分成多个分区(partition)的,以Windows观点来看,有一块磁盘将它分区成C,D,E盘。那个C,D,E就是分区。分区从实质上说就是对硬盘的一种格式化。但是Linux的设备都是以文件形式存在,那怎么分区的呢?
柱面是分区的最小单位,我们可以利用参考柱面号码的方式来进行分区,其本质就是设置每个区的起始柱面和结束柱面号码。柱面大小一致,扇区个位一致,那么其实只要知道每个分区的起始和结束柱面号,知道每个柱面多少个扇区,那么该分区多大,LBA是多少也就清楚了。

2.3 inode的引入
之前我们说过 文件=文件内容+文件属性 ,我们使用 ls -l 的时候看到的除了看到文件名,还能看到文件属性。除了通过这种方式来读取文件信息,还可以使用stat命令看到更多信息:
[caryon@VM-24-10-centos disk_system]$ stat main.cFile: ‘main.c’Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd01h/64769d Inode: 1179718 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ caryon) Gid: ( 1001/ caryon)
Access: 2025-01-17 15:27:49.331247778 +0800
Modify: 2025-01-17 15:27:49.331247778 +0800
Change: 2025-01-17 15:27:49.331247778 +0800Birth: -
这里我们会思考一个问题,文件内容都储存在”块”中,那么很显然,我们还必须找到一个地方储存文件的属性信息,比如文件的创建者、文件的创建日期、文件的大小等等。储存文件属性信息的区域就是inode。
每一个文件都有对应的inode,也就有唯一的inode编号。inode里面包含了与该文件有关的一些信息。接下来让我们看一下ext2文件系统中inode都包含哪些数据:
/** Structure of an inode on the disk*/
struct ext2_inode {__le16 i_mode; /* File mode */__le16 i_uid; /* Low 16 bits of Owner Uid */__le32 i_size; /* Size in bytes */__le32 i_atime; /* Access time */__le32 i_ctime; /* Creation time */__le32 i_mtime; /* Modification time */__le32 i_dtime; /* Deletion Time */__le16 i_gid; /* Low 16 bits of Group Id */__le16 i_links_count; /* Links count */__le32 i_blocks; /* Blocks count */__le32 i_flags; /* File flags */union {struct {__le32 l_i_reserved1;} linux1;struct {__le32 h_i_translator;} hurd1;struct {__le32 m_i_reserved1;} masix1;} osd1; /* OS dependent 1 */__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */__le32 i_generation; /* File version (for NFS) */__le32 i_file_acl; /* File ACL */__le32 i_dir_acl; /* Directory ACL */__le32 i_faddr; /* Fragment address */union {struct {__u8 l_i_frag; /* Fragment number */__u8 l_i_fsize; /* Fragment size */__u16 i_pad1;__le16 l_i_uid_high; /* these 2 fields */__le16 l_i_gid_high; /* were reserved2[0] */__u32 l_i_reserved2;} linux2;struct {__u8 h_i_frag; /* Fragment number */__u8 h_i_fsize; /* Fragment size */__le16 h_i_mode_high;__le16 h_i_uid_high;__le16 h_i_gid_high;__le32 h_i_author;} hurd2;struct {__u8 m_i_frag; /* Fragment number */__u8 m_i_fsize; /* Fragment size */__u16 m_pad1;__u32 m_i_reserved2[2];} masix2;} osd2; /* OS dependent 2 */
};
/** Constants relative to the data blocks*/
#define EXT2_NDIR_BLOCKS 12
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1)
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1)
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)
//备注:EXT2_N_BLOCKS = 15
注意:
• 文件名属性并未纳入到inode数据结构内部
• inode的大小一般是128字节或者256,我们后面统一128字节
• 任何文件的内容大小可以不同,但是属性大小一定是相同的
三、ext2 文件系统
我们已经知道硬盘是典型的“块”设备,操作系统读取硬盘数据的时候,读取的基本单位是”块”。“块”又是硬盘的每个分区下的结构,难道“块”是随意的在分区上排布的吗?那要怎么找到“块”呢?还有就是上面提到的存储文件属性的inode,是如何放置的呢?接下来我们就要解决这些问题。
3.1 整体认识
我们想要在硬盘上存储文件,必须先把硬盘格式化为某种格式的文件系统,才能存储文件。文件系统的目的就是组织和管理硬盘中的文件。在Linux系统中,最常见的是ext2系列的文件系统。其早期版本为ext2,后来又发展出ext3和ext4。ext3和ext4虽然对ext2进行了增强,但是其核心设计并没有发生变化,我们仍是以较老的ext2演示。
ext2文件系统将整个分区划分成若干个同样大小的块组(Block Group),如下图所示。只要能管理一个分区就能管理所有分区,也就能管理所有磁盘文件。
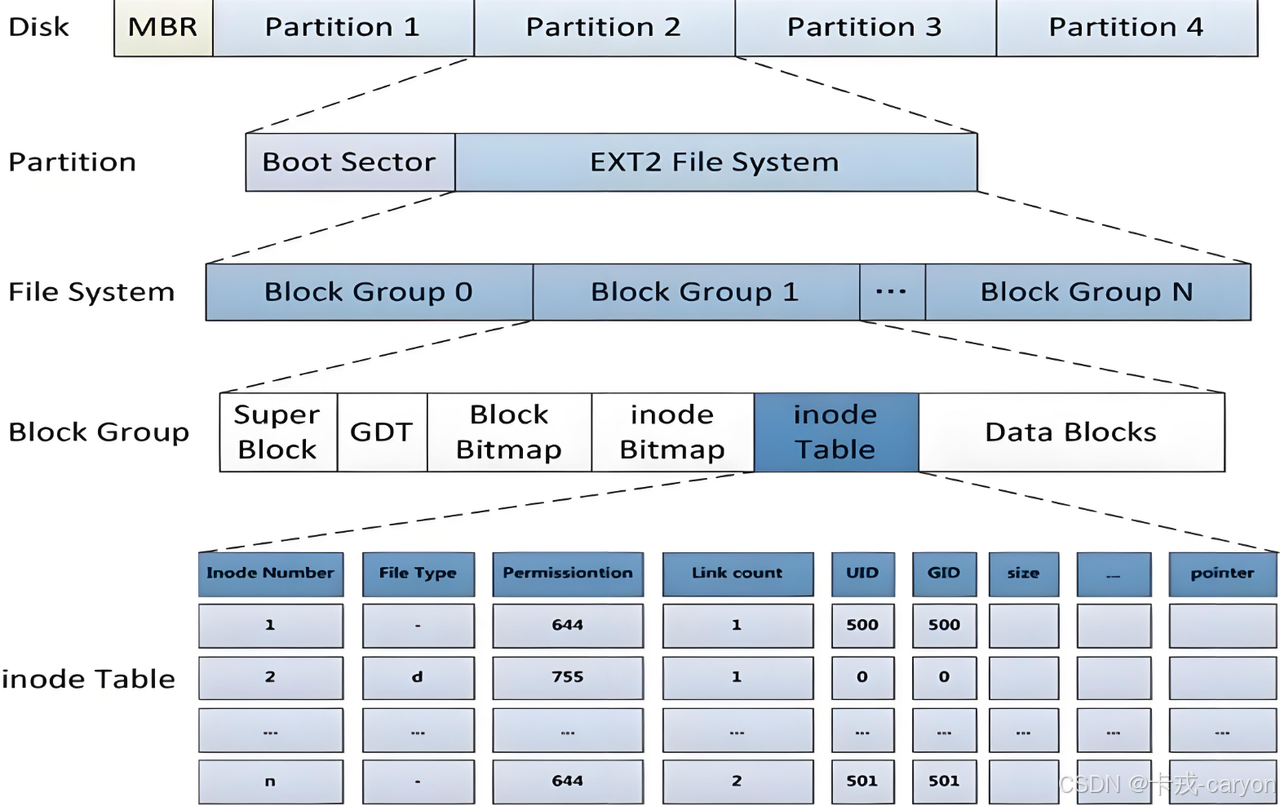
上图中启动块(Boot Sector)的大小是确定的,为1KB,由PC标准规定,用来存储磁盘分区信息和启动信息,任何文件系统都不能修改启动块。启动块之后才是ext2文件系统的开始。
3.2 块组及其内部组成
ext2文件系统会根据分区的大小划分为数个Bloc Group。每个Block Group都有着相同的结构组成。
3.2.1 Super Block(超级块)
Super Block用以存放文件系统本身的结构信息,描述整个分区的文件系统信息。记录的信息主要有:bolck和inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。因此超级块在每个块组的开头都有一份拷贝(第一个块组必须有,后面的块组可以没有)。为了保证文件系统在磁盘部分扇区出现物理问题的情况下还能正常工作,就必须保证文件系统的super block信息在这种情况下也能正常访问。所以一个文件系统的super block会在多个block group中进行备份,这些super block区域的数据保持一致。
/** Structure of the super block*/
struct ext2_super_block {__le32 s_inodes_count; /* Inodes count */__le32 s_blocks_count; /* Blocks count */__le32 s_r_blocks_count; /* Reserved blocks count */__le32 s_free_blocks_count; /* Free blocks count */__le32 s_free_inodes_count; /* Free inodes count */__le32 s_first_data_block; /* First Data Block */__le32 s_log_block_size; /* Block size */__le32 s_log_frag_size; /* Fragment size */__le32 s_blocks_per_group; /* # Blocks per group */__le32 s_frags_per_group; /* # Fragments per group */__le32 s_inodes_per_group; /* # Inodes per group */__le32 s_mtime; /* Mount time */__le32 s_wtime; /* Write time */__le16 s_mnt_count; /* Mount count */__le16 s_max_mnt_count; /* Maximal mount count */__le16 s_magic; /* Magic signature */__le16 s_state; /* File system state */__le16 s_errors; /* Behaviour when detecting errors */__le16 s_minor_rev_level; /* minor revision level */__le32 s_lastcheck; /* time of last check */__le32 s_checkinterval; /* max. time between checks */__le32 s_creator_os; /* OS */__le32 s_rev_level; /* Revision level */__le16 s_def_resuid; /* Default uid for reserved blocks */__le16 s_def_resgid; /* Default gid for reserved blocks *//** These fields are for EXT2_DYNAMIC_REV superblocks only.** Note: the difference between the compatible feature set and* the incompatible feature set is that if there is a bit set* in the incompatible feature set that the kernel doesn't* know about, it should refuse to mount the filesystem.* * e2fsck's requirements are more strict; if it doesn't know* about a feature in either the compatible or incompatible* feature set, it must abort and not try to meddle with* things it doesn't understand...*/__le32 s_first_ino; /* First non-reserved inode */__le16 s_inode_size; /* size of inode structure */__le16 s_block_group_nr; /* block group # of this superblock */__le32 s_feature_compat; /* compatible feature set */__le32 s_feature_incompat; /* incompatible feature set */__le32 s_feature_ro_compat; /* readonly-compatible feature set */__u8 s_uuid[16]; /* 128-bit uuid for volume */char s_volume_name[16]; /* volume name */char s_last_mounted[64]; /* directory where last mounted */__le32 s_algorithm_usage_bitmap; /* For compression *//** Performance hints. Directory preallocation should only* happen if the EXT2_COMPAT_PREALLOC flag is on.*/__u8 s_prealloc_blocks; /* Nr of blocks to try to preallocate*/__u8 s_prealloc_dir_blocks; /* Nr to preallocate for dirs */__u16 s_padding1;/** Journaling support valid if EXT3_FEATURE_COMPAT_HAS_JOURNAL set.*/__u8 s_journal_uuid[16]; /* uuid of journal superblock */__u32 s_journal_inum; /* inode number of journal file */__u32 s_journal_dev; /* device number of journal file */__u32 s_last_orphan; /* start of list of inodes to delete */__u32 s_hash_seed[4]; /* HTREE hash seed */__u8 s_def_hash_version; /* Default hash version to use */__u8 s_reserved_char_pad;__u16 s_reserved_word_pad;__le32 s_default_mount_opts;__le32 s_first_meta_bg; /* First metablock block group */__u32 s_reserved[190]; /* Padding to the end of the block */
};
3.2.2 GDT(块组描述符表)
用以描述块组属性信息,整个分区分成多少个块组就对应有多少个块组描述符。每个块组描述符存储一个块组的描述信息,如在这个块组中从哪里开始是inode Table,从哪里开始是Data Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有一份拷贝。
/** Structure of a blocks group descriptor*/
struct ext2_group_desc
{__le32 bg_block_bitmap; /* Blocks bitmap block */__le32 bg_inode_bitmap; /* Inodes bitmap */__le32 bg_inode_table; /* Inodes table block*/__le16 bg_free_blocks_count; /* Free blocks count */__le16 bg_free_inodes_count; /* Free inodes count */__le16 bg_used_dirs_count; /* Directories count */__le16 bg_pad;__le32 bg_reserved[3];
};
3.3.3 Inode Table(inode结点表)
Inode Table是当前分组中所有inode属性的集合,它存放了文件属性,如inode编号,文件大小,所有者,最近修改时间等。inode编号以分区为单位,整体划分,不可跨分区
3.3.4 Data Block(数据块)
存放文件内容,也就是一个一个的Block。Block号也是按照分区划分,不可跨分区。根据不同的文件类型有以下几种情况:
• 对于普通文件,文件的数据存储在数据块中。
• 对于目录文件,该目录下的所有文件名和目录名存储在所在目录的数据块中,除了文件名外,ls-l命令看到的其它信息均保存在该文件的inode中。
3.3.5 Inode Bitmap(inode位图)
Inode Bitmap中记录着Inode Table中哪个inode已经被占用,哪个inode没有被占用
3.3.6 Block Bitmap(块位图)
Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用
3.4 inode和datablock映射
• 上面给出的inode结构内部存在__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */ ,EXT2_N_BLOCKS =15,就是用来进行inode和block映射的。
• 文件=文件内容+文件属性,我们找到了文件的内容也找到了文件的属性,就找到了文件。
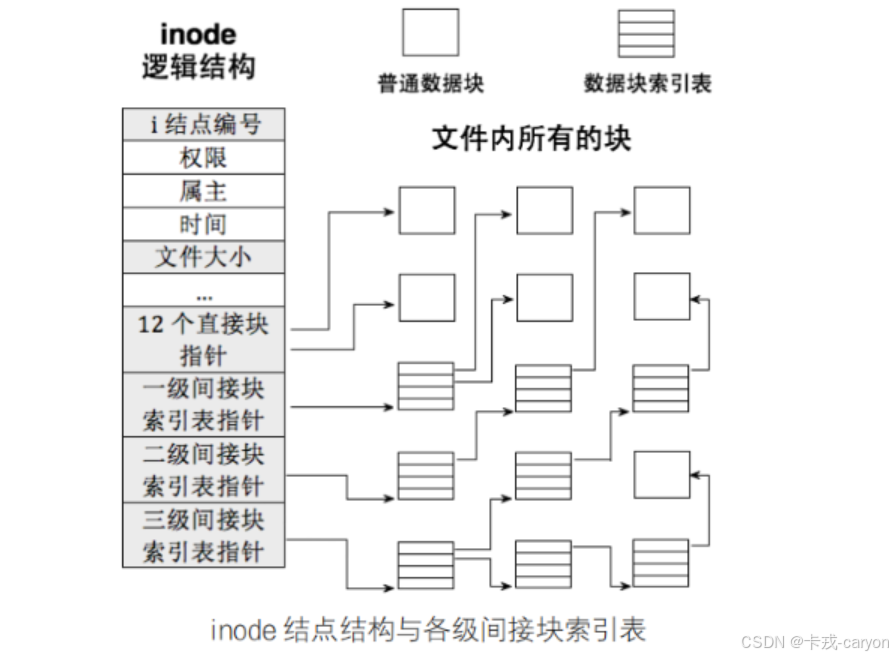
这时我们思考如何将“hello word”写入一个文件?
首先需要操作系统会给这个文件分配一个inode,这就需要在Inode Bitmap中查找到一个未使用的inode的位置,然后将这个位置在Inode Bitmap中由0置1,接着将inode的编号在Inode Table中的对应位置填充这个文件的属性信息来初始化。存储完文件属性还要存储文件内容。首先在Block Bitmap中查找到一个未使用的inode的位置,将该位置在Block Bitmap中由0置1,然后拿着对应的块号在Block Table中对应位置填充文件的内容信息“hello world”,最后在inode中将块号的信息记录下来,完成映射。
上面的这个这个过程也就可以帮助理解了文件的增删查改了。
分区之后的格式化操作,就是对分区进行分组,在每个分组中写入SB、GDT、Block Bitmap、Inode Bitmap等管理信息,这些管理信息统称为文件系统,只要知道文件的inode号,就能在指定分区中确定是哪一个分组,进而在哪一个分组确定是哪一个inode,我们一旦拿到inode,文件属性和内容就全部都有了。
3.5 目录与文件名
那我们现在就有个问题了,我们访问文件,都是用的文件名,没用过inode号啊?目录是文件吗?如何理解目录?
• 目录也是文件,磁盘上没有目录的概念,只有文件属性+文件内容的概念。
• 目录的属性不用多说,目录的内容保存的是文件名和Inode号的映射关系。
这里我们进行验证一下:
// readdir.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <unistd.h> int main(int argc, char *argv[])
{ if (argc != 2) { fprintf(stderr, "Usage: %s <directory>\n", argv[0]); exit(EXIT_FAILURE); } DIR *dir = opendir(argv[1]); if (!dir) { perror("opendir"); exit(EXIT_FAILURE); } struct dirent *entry; while ((entry = readdir(dir)) != NULL) { // Skip the "." and ".." directory entries if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..")== 0) continue; printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned long)entry->d_ino); } closedir(dir); return 0;
}
[caryon@VM-24-10-centos disk_system]$ ./readdir /
Filename: mnt, Inode: 393723
Filename: opt, Inode: 393724
Filename: sys, Inode: 393218
Filename: media, Inode: 393722
Filename: lib, Inode: 25
Filename: etc, Inode: 262147
Filename: home, Inode: 393721
Filename: boot, Inode: 262152
Filename: lost+found, Inode: 11
Filename: usr, Inode: 14
Filename: proc, Inode: 393217
Filename: bin, Inode: 3505
Filename: dev, Inode: 262145
Filename: var, Inode: 393220
Filename: shared_dir, Inode: 3014657
Filename: run, Inode: 262146
Filename: data, Inode: 399635
Filename: root, Inode: 393219
Filename: lib64, Inode: 27
Filename: sbin, Inode: 33
Filename: srv, Inode: 393725
Filename: tmp, Inode: 8193
[caryon@VM-24-10-centos disk_system]$ ls -li /
total 763505 lrwxrwxrwx. 1 root root 7 Mar 7 2019 bin -> usr/bin262152 dr-xr-xr-x. 5 root root 4096 Feb 19 2024 boot399635 drwxr-xr-x 2 root root 4096 Nov 5 2019 data1026 drwxr-xr-x 19 root root 3040 Apr 14 2024 dev262147 drwxr-xr-x. 94 root root 12288 Dec 28 17:59 etc393721 drwxr-xr-t. 5 root root 4096 Sep 14 15:43 home25 lrwxrwxrwx. 1 root root 7 Mar 7 2019 lib -> usr/lib27 lrwxrwxrwx. 1 root root 9 Mar 7 2019 lib64 -> usr/lib6411 drwx------. 2 root root 16384 Mar 7 2019 lost+found393722 drwxr-xr-x. 2 root root 4096 Apr 11 2018 media393723 drwxr-xr-x. 2 root root 4096 Apr 11 2018 mnt393724 drwxr-xr-x. 4 root root 4096 Apr 14 2024 opt1 dr-xr-xr-x 131 root root 0 Apr 14 2024 proc393219 dr-xr-x---. 11 root root 4096 Dec 28 18:09 root487 drwxr-xr-x 27 root root 980 Jan 13 17:45 run33 lrwxrwxrwx. 1 root root 8 Mar 7 2019 sbin -> usr/sbin
3014657 drwxr-xrwt 2 root root 4096 Dec 16 19:32 shared_dir393725 drwxr-xr-x. 2 root root 4096 Apr 11 2018 srv1 dr-xr-xr-x 13 root root 0 Jul 11 2024 sys8193 drwxrwxrwt. 22 root root 4096 Jan 17 17:09 tmp14 drwxr-xr-x. 14 root root 4096 Jan 8 2021 usr393220 drwxr-xr-x. 20 root root 4096 Jan 8 2021 var
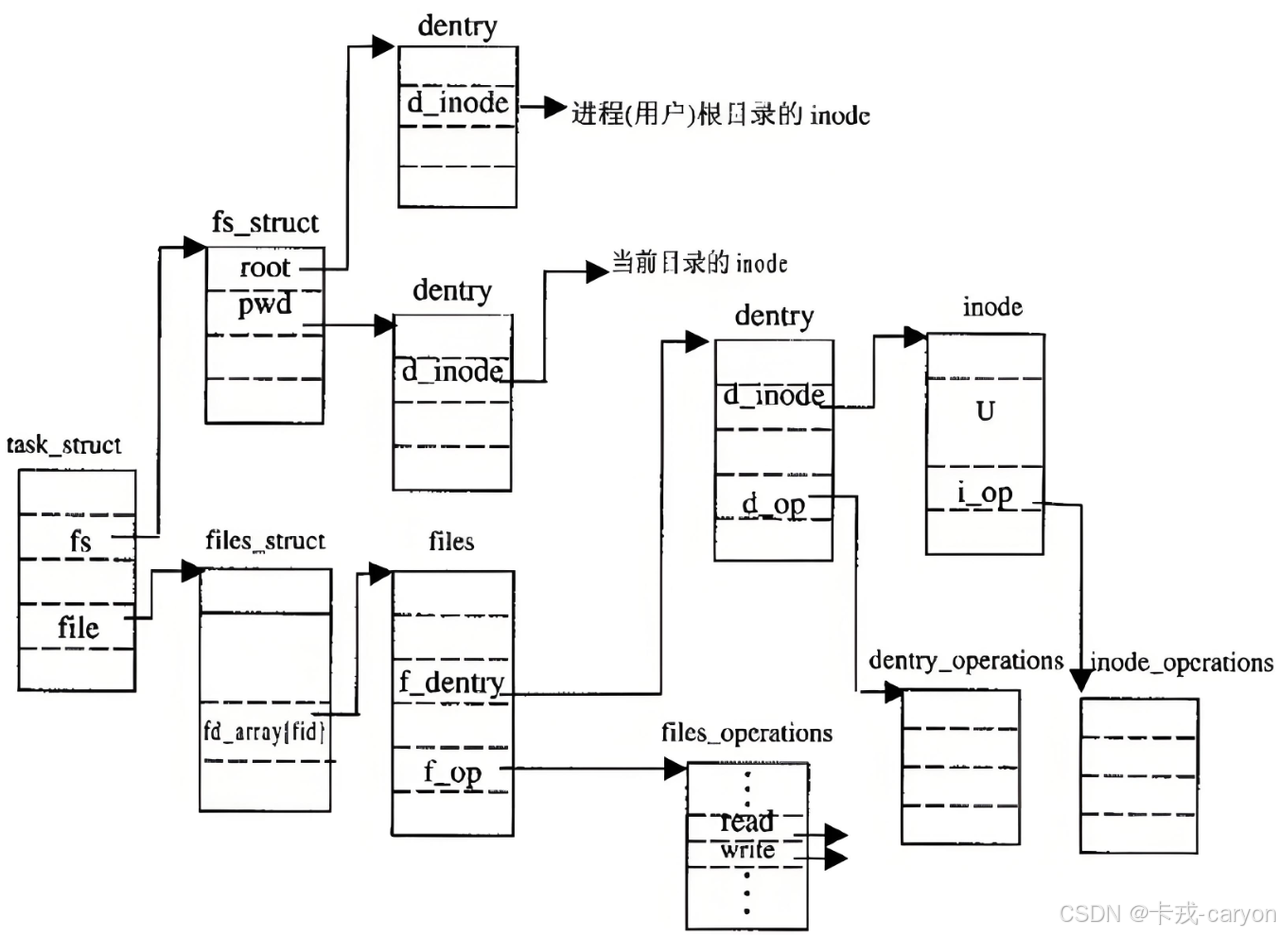
所以,访问文件,必须打开当前目录,根据文件名,获得对应的inode号,然后进行文件访问。这也就解释了rwx权限对目录的作用,访问文件必须要知道当前工作目录,本质是必须能打开当前工作目录文件,查看目录文件的内容。
打开当前工作目录文件,查看当前工作目录文件的内容,当前工作目录不也是文件吗?我们访问当前工作目录不也是只知道当前工作目录的文件名吗?要访问它,不也得知道当前工作目录的inode吗?
要打开当前工作目录的上级目录,类似于"递归",需要把路径中所有的目录全部解析,出口是"/"根目录。实际上,任何文件,都有路径,访问目标文件,比如:/home/caryon/linux/test/test.c都要从根目录开始,依次打开每一个目录,根据目录名,依次访问每个目录下指定的目录,直到访问到test.c。这个过程叫做Linux路径解析。
可是路径谁提供?可是最开始的路径从哪里来?
访问文件,都是指令/工具访问,本质是进程访问,进程有CWD!进程提供路径。当我们open文件时就提供了路径
所以Linux为什么要有根目录,根目录下为什么要有那么多缺省目录?为什么要有家目录,为什么自己可以新建目录?
上面所有行为本质就是在磁盘文件系统中,新建目录文件。而新建的任何文件,都在你或者系统指定的目录下新建,这不就是天然就有路径了嘛!因此系统和用户共同构建Linux路径结构。
但是当我们访问完/home/caryon/linux/test/test.c后,我们又想访问/home/caryon/linux/test/code.c,这难道还需要我们重新推导吗?
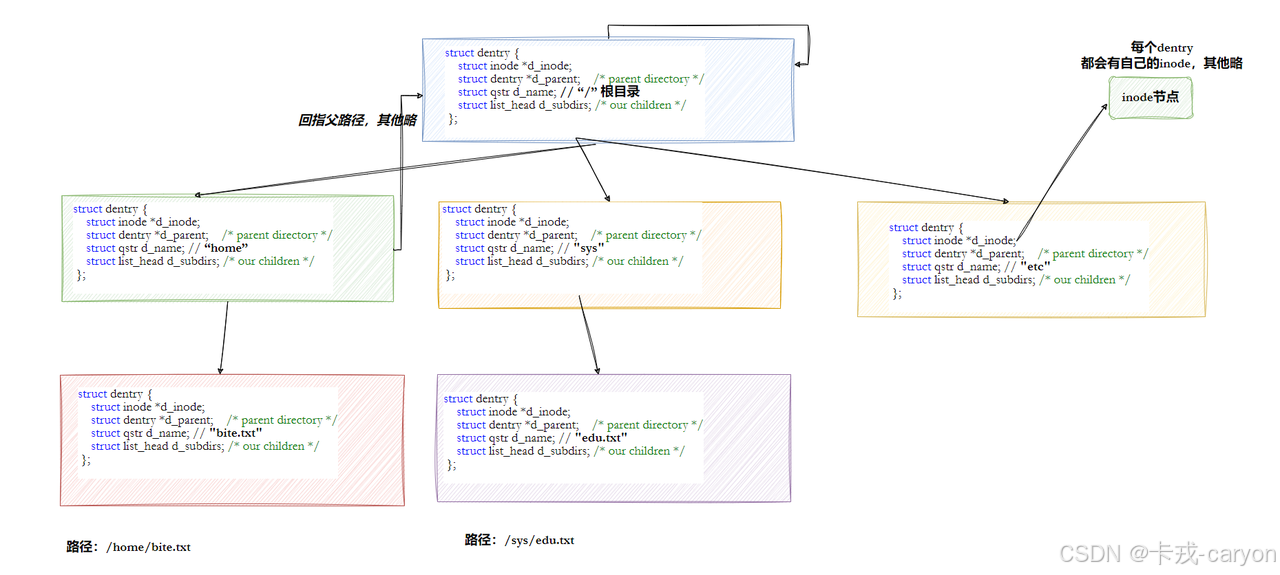
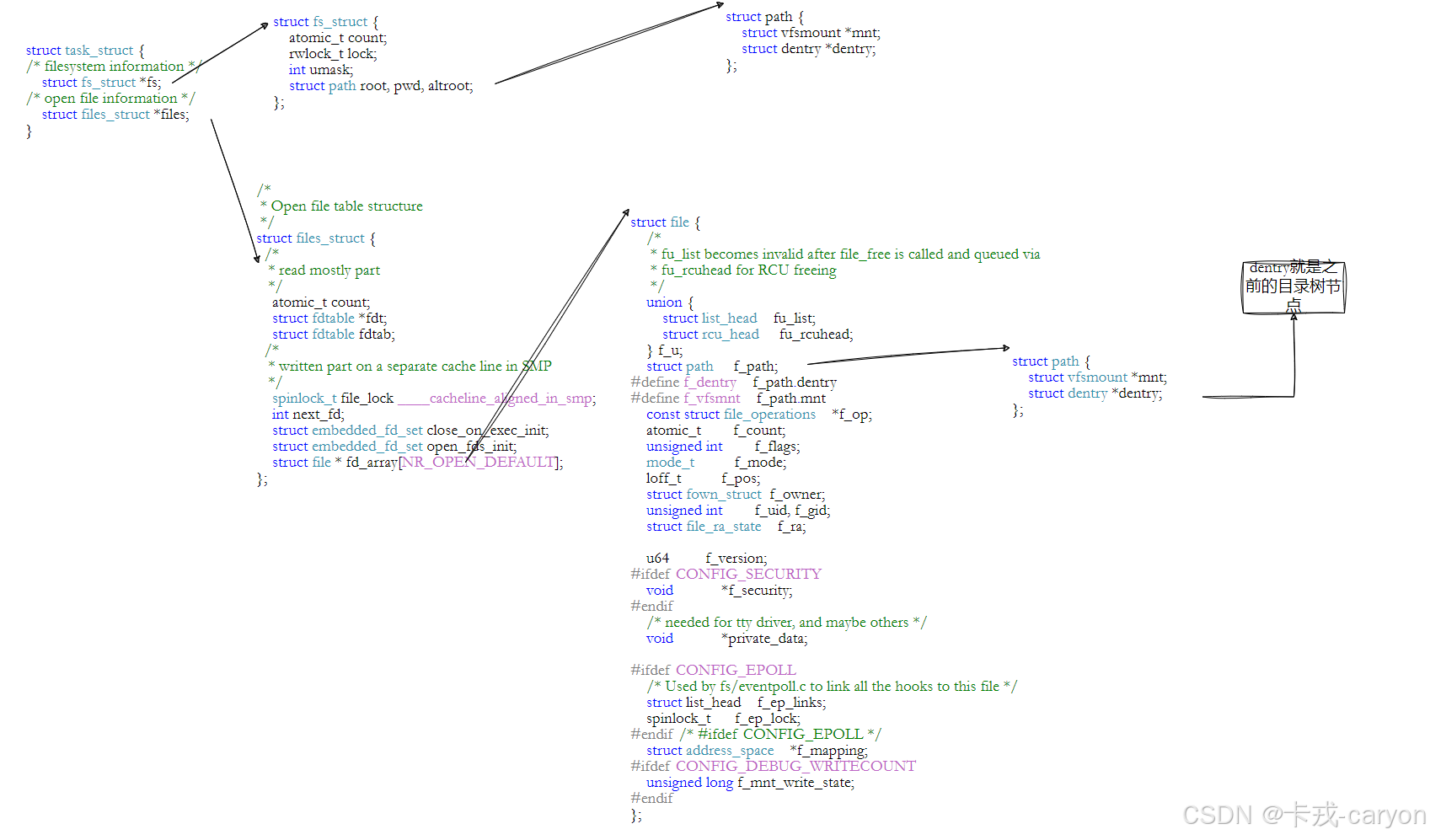
原则上是,但是这样太慢,所以Linux会缓存历史路径结构。Linux中,在内核中维护树状路径结构的内核结构体叫做: struct dentry ,下面是源码:
struct dentry {atomic_t d_count;unsigned int d_flags; /* protected by d_lock */spinlock_t d_lock; /* per dentry lock */struct inode *d_inode; /* Where the name belongs to - NULL is* negative *//** The next three fields are touched by __d_lookup. Place them here* so they all fit in a cache line.*/struct hlist_node d_hash; /* lookup hash list */struct dentry *d_parent; /* parent directory */struct qstr d_name;struct list_head d_lru; /* LRU list *//** d_child and d_rcu can share memory*/union {struct list_head d_child; /* child of parent list */struct rcu_head d_rcu;} d_u;struct list_head d_subdirs; /* our children */struct list_head d_alias; /* inode alias list */unsigned long d_time; /* used by d_revalidate */struct dentry_operations *d_op;struct super_block *d_sb; /* The root of the dentry tree */void *d_fsdata; /* fs-specific data */
#ifdef CONFIG_PROFILINGstruct dcookie_struct *d_cookie; /* cookie, if any */
#endifint d_mounted;unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};
注意:
• 每个文件其实都要有对应的dentry结构,包括普通文件。这样所有被打开的文件,就可以在内存中形成整个树形结构。
• 整个树形节点也同时会隶属于LRU(Least Recently Used,最近最少使用)结构中,进形节点淘汰。
• 整个树形节点也同时会隶属于Hash,方便快速查找。
• 更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何文件,都在先在这棵树下根据路径进行查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry结构,缓存新路径。
3.6 挂载分区
我们已经能够根据inode号在指定分区找文件了,也已经能根据目录文件内容,找指定的inode了,在指定的分区内,我们可以为所欲为了。可是:inode不是不能跨分区吗?Linux不是可以有多个分区吗?我怎么知道我在哪一个分区???
[root@VM-24-10-centos ~]# dd if=/dev/zero of=./disk.img bs=1M count=5
5+0 records in
5+0 records out
5242880 bytes (5.2 MB) copied, 0.00338181 s, 1.6 GB/s
[root@VM-24-10-centos ~]# mkfs.ext4 disk.img
mke2fs 1.42.9 (28-Dec-2013)
disk.img is not a block special device.
Proceed anyway? (y,n) y
Discarding device blocks: done
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
1280 inodes, 5120 blocks
256 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=5242880
1 block group
8192 blocks per group, 8192 fragments per group
1280 inodes per groupAllocating group tables: done
Writing inode tables: done
Creating journal (1024 blocks): done
Writing superblocks and filesystem accounting information: done[root@VM-24-10-centos ~]# mkdir /mnt/mydisk
[root@VM-24-10-centos ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 989M 0 989M 0% /dev
tmpfs 1000M 24K 1000M 1% /dev/shm
tmpfs 1000M 864K 999M 1% /run
tmpfs 1000M 0 1000M 0% /sys/fs/cgroup
/dev/vda1 50G 6.8G 41G 15% /
tmpfs 200M 0 200M 0% /run/user/0
tmpfs 200M 0 200M 0% /run/user/1001
[root@VM-24-10-centos ~]# mount -t ext4 ./disk.img /mnt/mydisk/
[root@VM-24-10-centos ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 989M 0 989M 0% /dev
tmpfs 1000M 24K 1000M 1% /dev/shm
tmpfs 1000M 860K 999M 1% /run
tmpfs 1000M 0 1000M 0% /sys/fs/cgroup
/dev/vda1 50G 6.8G 41G 15% /
tmpfs 200M 0 200M 0% /run/user/0
tmpfs 200M 0 200M 0% /run/user/1001
/dev/loop0 3.9M 53K 3.5M 2% /mnt/mydisk
[root@VM-24-10-centos ~]# umount /mnt/mydisk
[root@VM-24-10-centos ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 989M 0 989M 0% /dev
tmpfs 1000M 24K 1000M 1% /dev/shm
tmpfs 1000M 860K 999M 1% /run
tmpfs 1000M 0 1000M 0% /sys/fs/cgroup
/dev/vda1 50G 6.8G 41G 15% /
tmpfs 200M 0 200M 0% /run/user/0
tmpfs 200M 0 200M 0% /run/user/1001
注意:
/dev/loop0 在Linux系统中代表第一个循环设备(loop device)。循环设备,也被称为回环设备或者loopback设备,是一种伪设备(pseudo-device),它允许将文件作为块设备(block device)来使用。这种机制使得可以将文件(比如ISO镜像文件)挂载(mount)为文件系统,就像它们是物理硬盘分区或者外部存储设备一样。
因此分区写入文件系统,无法直接使用,需要和指定的目录关联,进行挂载才能使用。所以,可以根据访问目标文件的"路径前缀"准确判断在哪一个分区。
3.7 文件系统总结
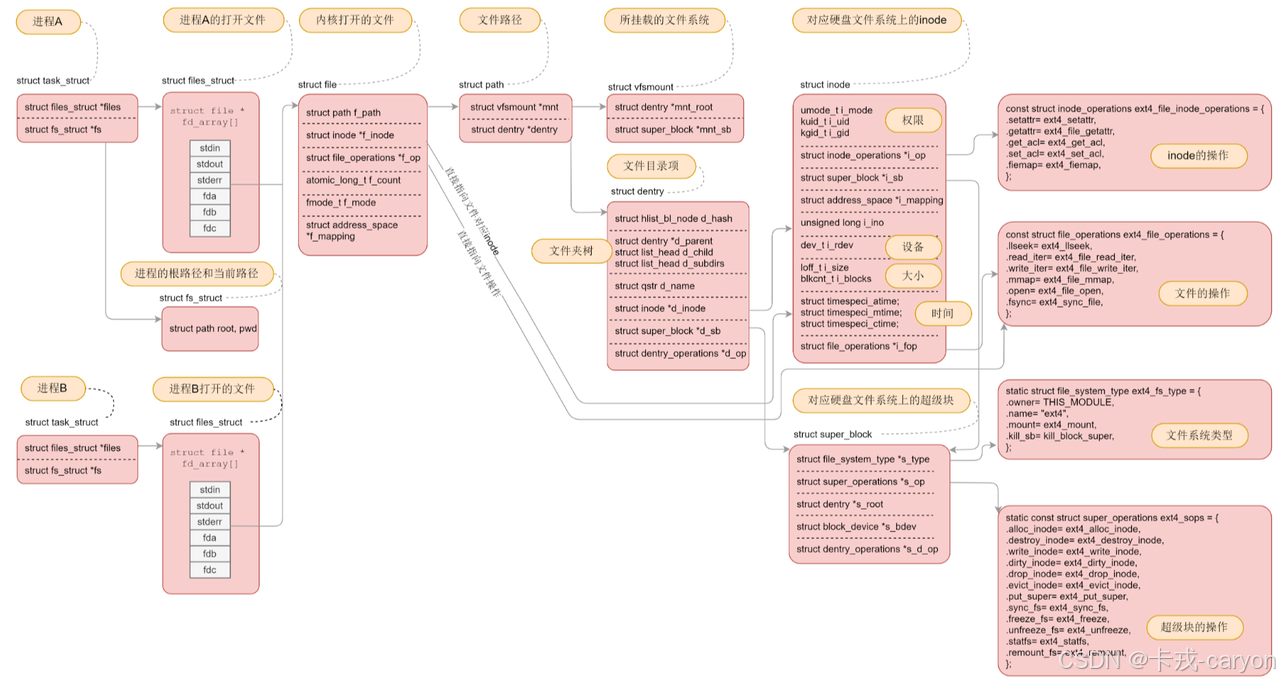
四、软硬链接
4.1 硬链接
[caryon@VM-24-10-centos temp]$ ll -i
total 0
1179731 -rw-rw-r-- 1 caryon caryon 0 Jan 19 11:51 file.txt
[caryon@VM-24-10-centos temp]$ ln file.txt file-hard.link
[caryon@VM-24-10-centos temp]$ ll -i
total 0
1179731 -rw-rw-r-- 2 caryon caryon 0 Jan 19 11:51 file-hard.link
1179731 -rw-rw-r-- 2 caryon caryon 0 Jan 19 11:51 file.txt
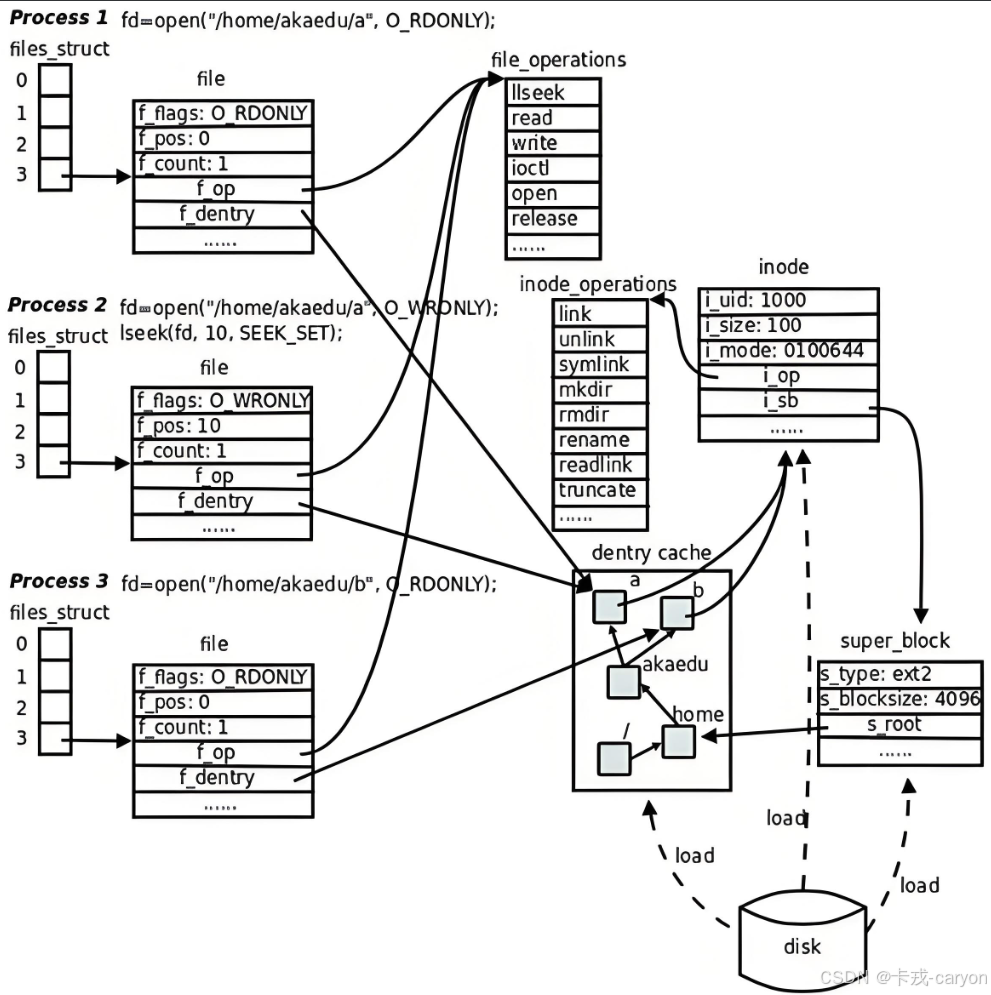
• 上面我们说到过,真正找到磁盘上文件的并不是通过文件名,而是inode。因此在linux中可以让多个文件名对应于同一个inode。因此硬链接实质就是一组文件名和已经存在的文件的映射关系。
• file.txt和file-hard.link的链接状态完全相同,它们被称为指向文件的硬链接。内核记录了这个连接数(引用计数),inode 1179731 的硬连接数为2。
• 当我们在删除文件时实际上做了两件事情:1.在目录中将对应的记录删除 2.将硬连接数-1,如果为0,则将对应的磁盘释放。
为什么这个文件夹(
1179732 drwxrwxr-x 3 caryon caryon 4096 Jan 19 11:59 dir1)的硬连接数为3?
这是因为它自身带有隐藏文件 . ,然后它的内部还有一个文件夹,该文件夹内部还有隐藏文件…
因此硬链接的主要目的是备份文件。
Linux中不允许对目录新建硬链接,因为会成环路径,. 和 … 是linux系统的特殊处理。
4.2 软链接
[caryon@VM-24-10-centos temp]$ ll -i
total 0
1179731 -rw-rw-r-- 2 caryon caryon 0 Jan 19 11:51 file-hard.link
1179731 -rw-rw-r-- 2 caryon caryon 0 Jan 19 11:51 file.txt
[caryon@VM-24-10-centos temp]$ ln file.txt -s file-soft.link
[caryon@VM-24-10-centos temp]$ ll -i
total 0
1179731 -rw-rw-r-- 2 caryon caryon 0 Jan 19 11:51 file-hard.link
1179734 lrwxrwxrwx 1 caryon caryon 8 Jan 19 12:03 file-soft.link -> file.txt
1179731 -rw-rw-r-- 2 caryon caryon 0 Jan 19 11:51 file.txt
• 当我们向file.txt中写入后,我们可以在file-soft.link查看到,这说明在用户层使用软链接文件等同使用原文件。
• 硬链接是通过inode引用另外一个文件,软链接是通过名字引用另外一个文件,但实际上,新的文件和被引用的文件的inode不同,可以想象成一个快捷方式。
相关文章:
【文件篇】11.磁盘文件系统
上一篇博客中我们介绍到如果我们要访问文件首先需要打开这个文件,而文件是在磁盘上存储的,也就是说需要在磁盘上找到这个文件的路径。但是磁盘上有很多文件,这些文件都有自己的路径的,这些文件还有内容和属性,它们都是…...

嵌入式产品级-超小尺寸热成像相机(从0到1 硬件-软件-外壳)
Thermal_Imaging_Camera This is a small thermal imaging camera that includes everything from hardware and software. 小尺寸热成像相机-Pico-LVGL-RTOS 基于RP2040 Pico主控与RTOS,榨干双核性能实现LVGL和成图任务并行。ST7789驱动240280屏,CST8…...

三维扫描赋能文化:蔡司3D扫描仪让木质文化遗产焕发新生-沪敖3D
挪威文化历史博物馆在其修复工作中融入现代3D扫描技术,让数百年的历史焕发新生。 文化历史博物馆的工作 文化历史博物馆是奥斯陆大学的一个院系。凭借其在文化历史管理、研究和传播方面的丰富专业知识,该博物馆被誉为挪威博物馆研究领域的领先机构。馆…...
《自动驾驶与机器人中的SLAM技术》ch8:基于预积分和图优化的紧耦合 LIO 系统
目录 1 预积分 LIO 系统的经验 2 预积分图优化的顶点 3 预积分图优化的边 3.1 NDT 残差边(观测值维度为 3 维的单元边) 4 基于预积分和图优化 LIO 系统的实现 4.1 IMU 静止初始化 4.2 使用预积分预测 4.3 使用 IMU 预测位姿进行运动补偿 4.4 位姿配准部…...

Linux下PostgreSQL-12.0安装部署详细步骤
一、安装环境 postgresql-12.0 CentOS-7.6 注意:确认linux系统可以正常连接网络,因为在后面需要添加依赖包。 二、pg数据库安装包下载 下载地址:PostgreSQL: File Browser 选择要安装的版本进行下载: 三、安装依赖包 在要安…...

STL—stack与queue
目录 Stack stack的使用 stack的模拟实现 queue queue的使用 queue的模拟实现 priority_queue priority_queue的用法 priority_queue的模拟实现 容器适配器 种类 Stack http://www.cplusplus.com/reference/stack/stack/?kwstack stack是栈,后入先出 stack的…...

docker 使用远程镜像启动一个容器
使用前提: 首先你得安装docker,其次你得拥有一个远程镜像 docker run --name io_11281009 --rm -it -p 2233:22 -v .:/root/py -e ed25519_rootAAAAC3NzaC1lZDI1********Oy7zR7l7aUniR2rul ghcr.lizzie.fun/fj0r/io srv对上述命令解释: 1.docker run:…...

简述mysql 主从复制原理及其工作过程,配置一主两从并验证
第一种基于binlog的主从同步 首先对主库进行配置: [rootopenEuler-1 ~]# vim /etc/my.cnf 启动服务 [rootopenEuler-1 ~]# systemctl enable --now mysqld 主库的配置 从库的配置 第一个从库 [rootopenEuler-1 ~]# vim /etc/my.cnf [rootopenEuler-1 ~]# sys…...

oracle之行转列
对于Oracle的行转列功能一直云里雾里,马马虎虎,对行转列的使用场景和使用方法都不够深刻,最近有空理解一下。 Oracle 11g后有专门的函数pivot,对于特定的场景可以直接套用。 需求:求各份job不同员工工资是多少…...
Windows电脑安装USB Redirector并实现内外网跨网USB共享通信访问
文章目录 前言1. 安装下载软件1.1 内网安装使用USB Redirector1.2 下载安装cpolar内网穿透 2. 完成USB Redirector服务端和客户端映射连接3. 设置固定的公网地址 前言 我们每天都在与各种智能设备打交道,从手机到电脑,再到各种外设,它们已经…...

kafka学习笔记4-TLS加密 —— 筑梦之路
1. 准备证书文件 mkdir /opt/kafka/pkicd !$# 生成CA证书 openssl req -x509 -nodes -days 3650 -newkey rsa:4096 -keyout ca.key -out ca.crt -subj "/CNKafka-CA"# 生成私钥 openssl genrsa -out kafka.key 4096# 生成证书签名请求 (CSR) openssl req -new -key …...

grafana + Prometheus + node_exporter搭建监控大屏
本文介绍生产系统监控大屏的搭建,比较实用也是实际应用比较多的方式,希望能够帮助大家对监控系统有一定的认识。 0、规划 grafana主要是展示和报警,Prometheus用于保存监控数据,node_exporter用于实时采集各个应用服务器的事实状…...

深度学习在语音识别中的应用
引言 语音识别技术是人工智能领域中的一个重要分支,它使得机器能够理解和转换人类的语音为文本。深度学习的出现极大地推动了语音识别技术的发展。本文将介绍如何使用深度学习构建一个基本的语音识别系统,并提供一个实践案例。 环境准备 在开始之前&a…...

RabbitMQ 高级特性
目录 1.消息确认 1.1 消息确认机制 1.2 手动确认方法 1. 2.1肯定确认 1.2.2 否定确认 1.3 SpringBoot 代码示例 1.3.1 配置确认机制 1.3.2 配置队列,交换机,绑定关系 1.3.3 生产者(向 rabbitmq 发送消息) 1.3.4 消费者(消费队列中的信息) 2.持久性 2.1 交换机…...

第01章 07 MySQL+VTK C++示例代码,实现医学影像数据的IO数据库存储
要实现将医学影像数据(如DICOM文件或其他医学图像格式)存储到MySQL数据库中,并使用VTK进行数据读取和处理的C示例代码,可以按照以下步骤进行。这个示例将展示如何将DICOM图像数据存储到MySQL数据库,然后使用VTK读取并显…...

Mysql创建定时任务
mysql查看存储过程 SHOW PROCEDURE STATUS;查看event_scheduler show events;查看当前event_scheduler的状态 SHOW VARIABLES LIKE event_scheduler;关闭event_scheduler set GLOBAL event_schedulerOFF;删除event_scheduler drop event event_name;创建存储过程 -- 创建存…...

【MySQL篇】使用mysqldump导入报错Unknown collation: ‘utf8mb4_0900_ai_ci‘的问题解决
💫《博主介绍》:✨又是一天没白过,我是奈斯,从事IT领域✨ 💫《擅长领域》:✌️擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(…...

专业学习|最优化理论(目标函数、约束条件以及解题三板斧)
个人学习使用资料,请勿传播,若有侵权联系删除,资料来源:fairy girl。 一、最优化理论:让决策更科学,让模型更高效 (一)什么是最优化理论? 最优化理论是数学的一个分支,它研究如何在一定约束条件下找到使目标函数达到最大值或最小值的最优解。 关键概念:最优化理论的…...

【Linux】gawk编辑器二
一、变量 gawk编程语言支持两种变量:内建变量和自定义变量。 1、内建变量 gawk使用内建变量来引用一些特殊的功能。 字段和记录分隔符变量 数据字段变量 此变量允许使用美元符号($)和字段在记录中的位置值来引用对应的字段。要引用记录…...

Hadoop美食推荐系统 爬虫1.8w+数据 协同过滤余弦函数推荐美食 Springboot Vue Element-UI前后端分离
Hadoop美食推荐系统 爬虫1.8w数据 协同过滤余弦函数推荐美食 Springboot Vue Element-UI前后端分离 【Hadoop项目】 1. data.csv上传到hadoop集群环境 2. data.csv数据清洗 3.MapReducer数据汇总处理, 将Reducer的结果数据保存到本地Mysql数据库中 4. SpringbootEchartsMySQL 显…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...

如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南
如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重新焕发活力&a…...

从API调用成功率看Taotoken服务的稳定性与容灾表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API调用成功率看Taotoken服务的稳定性与容灾表现 在将大模型能力集成到自动化流程或日常开发工具链时,服务的稳定性和…...

Safe Exam Browser虚拟机绕过实战:深度解析与安全研究指南
Safe Exam Browser虚拟机绕过实战:深度解析与安全研究指南 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass 在数字化教育快速发展的今天&…...

C语言预处理指令全解析
第六章 预处理命令在c语言中,所有# 开头的指令,被称为预处理指令。gcc 编译预处理 所有的预处理指令,都要在这步处理完汇编编译连接#include包含头文件。 全局变量的声明,函数的声明, 自定义构造类型声明, …...

终极指南:5分钟搞定淘宝淘金币全任务自动化脚本
终极指南:5分钟搞定淘宝淘金币全任务自动化脚本 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 你是否厌倦…...

YOLO训练前数据检查必备:一个脚本批量转换LabelImg的txt标签并可视化核对
YOLO训练前数据检查实战:批量转换与可视化核验脚本开发指南 在计算机视觉项目的实际落地过程中,数据质量往往比模型架构更能决定最终效果的上限。许多团队花费大量时间调整超参数和网络结构,却忽略了最基础的标注数据验证环节。当使用LabelIm…...

三步解锁WeMod专业版:终极本地增强工具配置指南
三步解锁WeMod专业版:终极本地增强工具配置指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费用烦恼吗…...

Windows安卓应用安装终极指南:APK Installer让你的电脑变身安卓平台
Windows安卓应用安装终极指南:APK Installer让你的电脑变身安卓平台 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为无法在Windows电脑上直接安装安卓…...