【LeetCode】--- MySQL刷题集合
1.组合两个表(外连接)

select p.firstName,p.lastName,a.city,a.state
from Person p left join Address a
on p.personId = a.personId;以左边表为基准,去连接右边的表。取两表的交集和左表的全集
2.第二高的薪水 (子查询、ifnull)

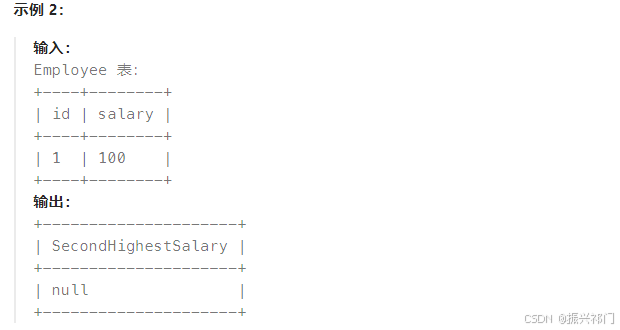
解法一(子查询与LIMIT 子句):
limit的两种写法
limit 起始索引,查询数据的个数
limit 起始索引 offset 查询数据的个数
select
(select distinct salary from Employee order by salary desc limit 1 offset 1)
as SecondHighestSalary;
这样的写法就类似于
select 1+2 as SecondHighestSalary;不需要有数据来源,因为这个表达式的计算结果已经是一个数据了。
这里只是给数据起一个别名。若是子查询数据为空,那么返回的就是null 而不是空了
总之。在 SQL 中使用子查询而没有 FROM 子句的情况通常是为了计算一个表达式或获取一个基于特定逻辑的单一结果,子查询本身提供了数据来源和处理逻辑,无需再通过 FROM 从物理表中获取数据。但在实际应用中,需要考虑性能和可维护性,避免过度复杂的子查询结构。
解法二(使用 IFNULL 和 LIMIT 子句):
select ifnull(
(select distinct salary from Employee order by salary desc limit 1,1),null
)
as SecondHighestSalary;由于若查询结果为空,返回null
因此使用 ifnull 流程控制函数 更加合适
ifnull(value1,value2)
如果value1为null,就返回value2
如果不为空,就返回value1
注意,若是value1为一个sql语句,要给它加上括号
3.第N高的薪水(函数、limit不能跟表达式)

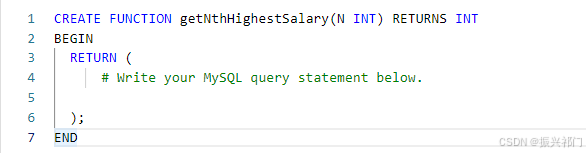
答案:
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
declare M INT;set M = N-1;RETURN (select distinct salary from Employee order by salary desc limit M,1);
END注意,limit中参数不能写成表达式的形式。也就是不能写成N-1
需要单独定义一个变量 M = N-1
代码解释
这个 SQL 代码创建了一个名为 getNthHighestSalary 的函数,该函数接收一个整数参数 N,用于表示要查找第 N 高的薪水。函数的返回值是一个整数,代表第 N 高的薪水值。
变量声明:
declare M INT;变量赋值:
set M = N-1;
查询语句RETURN (select salary from Employee order by salary desc limit M,1 );
4.分数排名(窗口函数(排名函数dense_rank())

窗口函数的基本结构:
<窗口函数>([参数]) OVER ([PARTITION BY <分区列1>, <分区列2>,...][ORDER BY <排序列1> [ASC | DESC], <排序列2> [ASC | DESC],...][ROWS | RANGE <窗口范围说明>]
)各部分解释:
窗口函数:
- 这是核心部分,可以是聚合函数(如
SUM()、AVG()、COUNT()、MAX()、MIN()等)或排名函数(如RANK()、DENSE_RANK()、ROW_NUMBER()等)。OVER 子句:
- 是窗口函数的关键字,表明后面的内容是对窗口的定义。
- PARTITION BY:
这是可选的。用于将数据划分为不同的分区,类似于 GROUP BY 的功能,但不会像 GROUP BY 那样对数据进行聚合操作。窗口函数会在每个分区内独立执行。
例如:partition by ...会将数据按照部门进行分区,窗口函数将在每个部门内分别计算。PARTITION BY department- ORDER BY:
通常是必需的,用于对分区内的数据进行排序。这会影响排名函数的结果,以及聚合函数的计算顺序。
例如:会将分区内的数据按照薪水降序排列。ORDER BY salary DESC- ROWS | RANGE 窗口范围说明:
这也是可选的,用于进一步定义窗口的范围。
ROWS 基于物理行,例如表示当前行的前一行到后一行的范围。ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
RANGE 基于逻辑值,例如表示在当前行的值的基础上,范围是比当前行的值小 10 到大 10 的数据范围。RANGE BETWEEN 10 PRECEDING AND 10 FOLLOWING
排名函数(如
RANK()、DENSE_RANK()、ROW_NUMBER()等)。
方法一:排名函数dense_rank()(推荐)
rank() 排名的特点是 1 2 2 4 5 5 5 8 9
dense_rank() 排名的特点是 1 2 2 3 4 5 5 5 6
ROW_NUMBER() 特点是 1 2 3 4 5 6 7 8 9
select s.score,dense_rank()
over(order by s.score desc) as 'rank'
from Scores s;方法二:使用 COUNT(DISTINCT ...) 的相关子查询
SELECTS1.score,(SELECTCOUNT(DISTINCT S2.score)FROMScores S2WHERES2.score >= S1.score) AS 'rank'
FROMScores S1
ORDER BYS1.score DESC;这段 SQL 代码的主要目的是为 Scores 表中的每个 score 计算排名。它使用了一个相关子查询来计算排名,排名的依据是大于或等于当前分数的不同分数的数量。
主查询:
SELECT S1.score:从 Scores 表中选择 score 列作为主查询的一部分。
子查询部分:
COUNT(DISTINCT S2.score):计算不同分数的数量。
FROM Scores S2:从 Scores 表中选取数据。
WHERE S2.score >= S1.score:这是关键部分,对于主查询中的每个 S1.score,子查询会统计 Scores 表中大于或等于 S1.score 的不同分数的数量。最终结果是通过 ORDER BY S1.score DESC 对主查询的结果按照分数降序排列。
5.连续出现的数字 (自连接)
自连接使用场景
1.比较同一表中不同行的数据:
- 示例场景:查找表中相邻行的数据关系,例如找出连续出现的记录。
2.查找父子关系或层次关系:
- 示例场景:在存储了层次结构信息的表中查找父子节点关系。
3.找出重复记录:
- 示例场景:找出表中具有相同数据的行。
4.时间序列分析:
- 示例场景:在存储了时间序列数据的表中,找出连续时间点的数据。

select distinct l1.num as ConsecutiveNums
from Logs l1,Logs l2,Logs l3
where
l1.id = l2.id-1 and
l2.id = l3.id-1 and
l1.num = l2.num and
l2.num = l3.num;找出至少出现三次的数字。因此进行自连接三次
条件是
第一张表id 等于 第二张表 id-1
第二张表id 等于 第三张表 id-1
且
第一张表num 等于 第二张表 num
第二张表num 等于 第三张表 num
6.超过经理收入的员工(自连接)

解法一:自连接(隐式where语句)
select e1.name as Employee
from Employee e1,Employee e2
where e1.managerId = e2.id and e1.salary > e2.salary; SQL解释
表的自连接:
from Employee e1, Employee e2这里将 Employee 表自连接,使用别名 e1 表示员工,e2 表示经理。
where e1.managerId = e2.id and e1.salary > e2.salary;e1.managerId = e2.id:
这是自连接的关键条件,它将 e1 表中的 managerId 与 e2 表中的 id 进行连接,意味着 e2 表中的员工是 e1 表中员工的经理。
e1.salary > e2.salary:
这是筛选条件,它确保只选择那些员工的工资(e1.salary)高于其经理的工资(e2.salary)的记录。
解法二:自连接(显示on语句)
SELECTa.NAME AS Employee
FROM Employee AS a JOIN Employee AS bON a.ManagerId = b.IdAND a.Salary > b.Salary
;一、自连接过程:
首先,将 Employee 表自连接,形成笛卡尔积。这意味着 e1 和 e2 表的组合将包含所有可能的行对,即每个 e1 中的行将与 e2 中的所有行组合在一起,总共会有 种组合(假设 Employee 表有 n 行)。对于我们的示例表,会有6的平方 = 36 种组合,但很多组合将不符合条件。
e1.managerId = e2.id:
这一条件将确保 e1 中的员工的经理是 e2 中的员工。例如:
对于 e1 中的 Bob(id = 2,managerId = 1),只有当 e2 中的 id = 1 时,这个条件才满足。所以,Bob 可以和 Alice 组合。
e1.salary > e2.salary:
在上述满足 e1.managerId = e2.id 的组合中,进一步筛选出员工(e1)工资高于经理(e2)工资的组合:
对于 Bob(e1)和 Alice(e2)的组合:Bob 的工资是 6000,Alice 的工资是 5000,满足 e1.salary > e2.salary,所以 Bob 会被选中。
注意e1.managerId = e2.id 与 e1.id = e2.managerId的区别
e1.managerId = e2.id
这个条件表示 e2 表中的员工是 e1 表中员工的经理。也就是说,通过 managerId 建立了从员工(e1)到其经理(e2)的关联。
e1.id = e2.managerId:
这个条件表示 e1 表中的员工是 e2 表中员工的经理。与第一个语句相反,这里是通过 managerId 建立了从经理(e1)到其下属员工(e2)的关联。
7.找到重复的电子邮箱(自连接 | group by... having)

法一:自连接(效率低一点)
select distinct p1.email as Email
from Person p1, Person p2
where p1.id <> p2.id and p1.email = p2.email; 法二:(GROUP BY 和临时表) (比自连接效率高)
表子查询
先
select email, count(*) as num from Person group by email得到临时表
再根据这个表找到email数量大于 1 的 email就可以了

select email as Email
from (select email, count(*) as num from Person group by email) t
where num > 1;法三、使用 GROUP BY 和 HAVING 条件 (效率相对高一点)
select email from Person
group by email
having count(*) > 1;分完组之后,再用having count(*)来计算组内的行数。
再筛选组内行数大于1的email
8.从不订购的客户(is null)

注意:判断是否为null 要用 is 而不是 =
法一:列子查询(子查询返回的是一列数据)
select name as Customers from Customers
where id
not in (select customerId from Orders);法二:左连接(Left Join)
select name as Customers from Customers c
left join Orders o
on c.id = o.customerId where customerId is null; 9.部门工资最高的员工
法一:隐式内连接
select d.name Department,e.name Employee,e.salary
from Employee e,Department d
where e.departmentId = d.id
and e.salary >=
all (select salary from Employee t where e.departmentId = t.departmentId);e.salary >= all (select salary from Employee t where e.departmentId = t.departmentId);员工薪资 ≥ 相同部门的薪资。
法二、窗口函数(MAX()+行子查询)

select d.name AS 'Department',e.name AS 'Employee',Salary
FROM Employee e JOIN Department d ON e.DepartmentId = d.Id
where (e.DepartmentId , Salary) in
(select DepartmentId, MAX(Salary) from Employee
GROUP BY DepartmentId);where 条件 绑定了部门 id 和 薪资水平 in
查出来的 部门id 和最高的薪资水平。
select DepartmentId, MAX(Salary) from Employee
GROUP BY DepartmentId;
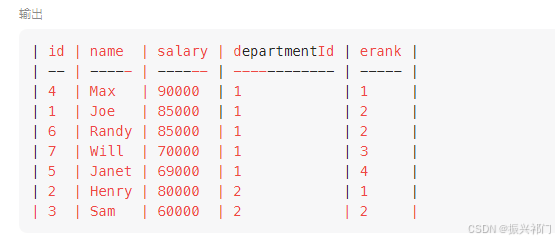
法三:窗口函数(dense_rank() partition by)(推荐)
select d.name AS 'Department',e.name AS 'Employee',e.salary Salary
from
(select *,dense_rank() over(partition by departmentId order by salary desc) as erank
from Employee) e ,Department d
where e.departmentId = d.Id
and erank <= 1;10.部门工资前三高的所有员工

法一:窗口函数(dense_rank())
select d.name as Department, e.name as Employee,salary Salary from
(select *, dense_rank()
over(partition by departmentId order by salary desc) as erank
from Employee) e
left join Department d on e.departmentId = d.id
where erank <= 3;其中
select *, dense_rank() over(partition by departmentId order by salary desc) as erank from Employee;#根据部门id分组,再对组内按照薪水从大到小排序,并生成对应的排名编号
再右连接Deparment表 输出排名编号≤3的
相关文章:
【LeetCode】--- MySQL刷题集合
1.组合两个表(外连接) select p.firstName,p.lastName,a.city,a.state from Person p left join Address a on p.personId a.personId; 以左边表为基准,去连接右边的表。取两表的交集和左表的全集 2.第二高的薪水 (子查询、if…...

基于Python的多元医疗知识图谱构建与应用研究(上)
一、引言 1.1 研究背景与意义 在当今数智化时代,医疗数据呈爆发式增长,如何高效管理和利用这些数据,成为提升医疗服务质量的关键。传统医疗数据管理方式存在数据孤岛、信息整合困难等问题,难以满足现代医疗对精准诊断和个性化治疗的需求。知识图谱作为一种知识表示和管理…...

小哆啦解题记:如何计算除自身以外数组的乘积
小哆啦开始力扣每日一题的第十二天 https://leetcode.cn/problems/product-of-array-except-self/description/ 《小哆啦解题记:如何计算除自身以外数组的乘积》 在一个清晨的阳光下,小哆啦坐在书桌前,思索着一道困扰已久的题目:…...

渐进式图片的实现原理
渐进式图片(Progressive JPEG)的实现原理与传统的基线 JPEG(Baseline JPEG)不同。它通过改变图片的编码和加载方式,使得图片在加载时能够逐步显示从模糊到清晰的图像。 1. 传统基线 JPEG 的加载方式 在传统的基线 JP…...
)
SQL刷题快速入门(三)
其他章节: SQL刷题快速入门(一) SQL刷题快速入门(二) 承接前两个章节,本系列第三章节主要讲SQL中where和having的作用和区别、 GROUP BY和ORDER BY作用和区别、表与表之间的连接操作(重点&…...

mybatis(19/134)
大致了解了一下工具类,自己手敲了一边,java的封装还是真的省去了很多麻烦,封装成一个工具类就可以不用写很多重复的步骤,一个工厂对应一个数据库一个environment就好了。 mybatis中调用sql中的delete占位符里面需要有字符…...

sqlmap 自动注入 -01
1: 先看一下sqlmap 的help: 在kali-linux 系统里面,可以sqlmap -h看一下: Target: At least one of these options has to be provided to define the target(s) -u URL, --urlURL Target URL (e.g. "Salesforce Platform for Application Development | Sa…...

3.8.Trie树
Trie树 Trie 树,又称字典树或前缀树,是一种用于高效存储和检索字符串数据的数据结构,以下是关于它的详细介绍: 定义与原理 定义:Trie 树是一种树形结构,每个节点可以包含多个子节点,用于存储…...

day 21
进程、线程、协程的区别 进程:操作系统分配资源的最小单位,其中可以包含一个或者多个线程,进程之间是独立的,可以通过进程间通信机制(管道,消息队列,共享内存,信号量,信…...

基于模板方法模式-消息队列发送
基于模板方法模式-消息队列发送 消息队列广泛应用于现代分布式系统中,作为解耦、异步处理和流量控制的重要工具。在消息队列的使用中,发送消息是常见的操作。不同的消息队列可能有不同的实现方式,例如,RabbitMQ、Kafka、RocketMQ…...

俄语画外音的特点
随着全球媒体消费的增加,语音服务呈指数级增长。作为视听翻译和本地化的一个关键方面,画外音在确保来自不同语言和文化背景的观众能够以一种真实和可访问的方式参与内容方面发挥着重要作用。说到俄语,画外音有其独特的特点、挑战和复杂性&…...

PyTorch使用教程(10)-torchinfo.summary网络结构可视化详细说明
1、基本介绍 torchinfo是一个为PyTorch用户量身定做的开源工具,其核心功能之一是summary函数。这个函数旨在简化模型的开发与调试流程,让模型架构一目了然。通过torchinfo的summary函数,用户可以快速获取模型的详细结构和统计信息࿰…...

亚博microros小车-原生ubuntu支持系列:5-姿态检测
MediaPipe 介绍参见:亚博microros小车-原生ubuntu支持系列:4-手部检测-CSDN博客 本篇继续迁移姿态检测。 一 背景知识 以下来自亚博官网 MediaPipe Pose是⼀个⽤于⾼保真⾝体姿势跟踪的ML解决⽅案,利⽤BlazePose研究,从RGB视频…...
C语言之高校学生信息快速查询系统的实现
🌟 嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 C语言之高校学生信息快速查询系统的实现 目录 任务陈述与分析 问题陈述问题分析 数据结构设…...

WPF基础 | WPF 基础概念全解析:布局、控件与事件
WPF基础 | WPF 基础概念全解析:布局、控件与事件 一、前言二、WPF 布局系统2.1 布局的重要性与基本原理2.2 常见布局面板2.3 布局的测量与排列过程 三、WPF 控件3.1 控件概述与分类3.2 常见控件的属性、方法与事件3.3 自定义控件 四、WPF 事件4.1 路由事件概述4.2 事…...

迷宫1.2
先发一下上次的代码 #include<bits/stdc.h> #include<windows.h> #include <conio.h> using namespace std; char a[1005][1005]{ " ", "################", "# # *#", "# # # #&qu…...

RabbitMQ---应用问题
(一)幂等性介绍 幂等性是本身是数学中的运算性质,他们可以被多次应用,但是不会改变初始应用的结果 1.应用程序的幂等性介绍 包括很多,有数据库幂等性,接口幂等性以及网络通信幂等性等 就比如数据库的sel…...

Unity自学之旅03
Unity自学之旅03 Unity自学之旅03📝 碰撞体 Collider 基础定义与作用常见类型OnCollisionEnter 事件碰撞触发器 🤗 总结归纳 Unity自学之旅03 📝 碰撞体 Collider 基础 定义与作用 定义:碰撞体是游戏中用于检测物体之间碰撞的组…...

pip 相关
一劳永逸法(pip怎么样都用不了也更新不了): 重下python(卸载旧版本):请输入访问密码 密码:7598 各版本python都有,下3.10.10 python路径建立,pip无法访问方式: 访问pip要…...

vue request 发送formdata
在Vue中,你可以使用axios库来发送包含FormData的请求。以下是一个简单的例子: 首先,确保你已经安装了axios: npm install axios然后,你可以使用axios发送FormData,例如: import axios from a…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

机器学习模型评估中的构念效度:超越基准测试分数的科学推断
1. 项目概述与核心问题在机器学习的日常研究和工程实践中,我们每天都在和各种各样的基准测试(Benchmark)打交道。无论是为了比较新提出的ResNet变体在ImageNet上的Top-1准确率,还是评估一个大型语言模型在MMLU上的常识推理能力&am…...
)
别再乱用npm install了!手把手教你用npx only-allow为项目指定包管理器(支持pnpm/yarn/npm)
用only-allow统一团队包管理器:从配置到CI的全流程指南 你是否曾经在拉取一个新项目后,面对npm install、yarn还是pnpm i的抉择感到困惑?或者更糟的是,团队成员混用不同包管理器导致node_modules结构不一致,引发各种诡…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...
)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)当你在Windows和Ubuntu双系统环境下工作时,是否遇到过这样的窘境:当初安装时给Ubuntu分配的空间捉襟见肘,而Windows…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...
)
Mysql:事务管理(中)
在前面的章节中,我们提到了 MVCC(多版本并发控制),它巧妙地通过“版本快照”解决了“读-写”冲突,实现了非阻塞读。但如果两个事务同时执行 UPDATE 操作修改同一行数据,即 写-写(Write-Write&am…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器
PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为植物大战僵尸PC版设计的综合修改器工具,能够让你…...