(1)STM32 USB设备开发-基础知识
开篇感谢:
【经验分享】STM32 USB相关知识扫盲 - STM32团队 ST意法半导体中文论坛
单片机学习记录_桃成蹊2.0的博客-CSDN博客
USB_不吃鱼的猫丿的博客-CSDN博客
1、USB鼠标_哔哩哔哩_bilibili
usb_冰糖葫的博客-CSDN博客
USB_lqonlylove的博客-CSDN博客
USB -- STM32F103 USB AUDIO(音频)Speaker同步传输(Out传输)讲解(七)_stm32 usb audio-CSDN博客
基于SMT32的USB键盘制作(附稚晖君键盘方案分析)_大颜u的博客-CSDN博客
基础知识
等级划分:

接口类型:


STM32基础型(F1系列)所带的USB是全速。
电气属性
USB的通信都是由主机发起的,这一点与IIC协议是类似的。
数据线
USB使用差分传输模式,有两条数据线,分别是:
USB数据正信号线,USB Data Positive,即USB-DP线,简写为D+
USB数据负信号线,USB Data Minus, 即USB-DM线,简写为D-
剩下的就是电源线(5V-Vbus)和地线(GND)。
USB主机是如何识别设备是高速设备/全速设备/低速设备?
主机的D+和D-都接有15K下拉电阻。
全速USB设备的数据线D+接有1.5K的上拉电阻,一旦接入主机,主机的D+被拉高
低速USB设备的数据线D-接有1.5K的上拉电阻,一旦接入主机,主机的D-会被拉高
因此,主机就可以根据检测到自己的D+为高还是D-为高,从而判断接入的设备是一个全速还是低速设备。
所以你可以看到STM32板子上的USB口D+有一个上拉电阻,而且是必须有的:

USB设备分类

看一个CDC虚拟串口的设备分类:

在看一个MSC的(模拟U盘):

不同的类有不同的用途;不同的应用场合对应不同的产品形态;不同的产品形态可能会有自己特殊的描述符,比如: HID类有报告描述符、CDC类有ACM、Union描述符等。
常用USB设备类:大容量存储类(Mass Storage Class - MSC),人机接口设备类(Human Interface Device - HID),音频设备类(Audio Device Class),视频设备类(Video Device Class),成像设备类(Imaging Device Class),打印机设备类(Printer Device Class)
描述符详解
以STM32里的MSC设备为例,MSC类所需要的描述符有:设备描述符+配置描述符+接口描述符(数量由配置描述符里的bNumInterfaces字段决定)+端点描述符(数量由配置描述符里的bNumEndpoints决定)
设备描述符
其中1个USB设备只能有一个设备描述符,但是其他描述符可以有多个。
一般实现USB复合设备的方法主要是:一个设备描述符、一个配置描述符、多个接口描述符、多个端点描述符......
每个USB设备都必须且只有一个设备描述符,摘取一下STM32的MSC设备里的实例代码:

每个字段的含义:
bLength:描述符大小.固定为0x12;
bDescriptorType:设备描述符类型.固定为0x01;
bcdUSB:USB 规范发布号.表示了本设备能适用于那种协议,如2.0=0200,1.1=0110;
bDeviceClass:类型代码(由USB指定)。当它的值是0时,表示所有接口在配置描述符里,并且所有接口是独立的。当它的值是1到FEH时,表示不同的接口关联的。当它的值是FFH时,它是厂商自己定义的;
bDeviceSubClass:子类型代码(由USB分配),如果 bDeviceClass值是0,一定要设置为0。其它情况就跟据USB-IF组织定义的编码;
bDeviceProtocol:协议代码(由USB分配),如果使用USB-IF组织定义的协议,就需要设置这里的值,否则直接设置为0。如果厂商自己定义的可以设置为FFH;
bMaxPacketSize0:端点0最大分组大小(只有8,16,32,64有效);
idVendor:供应商ID(由USB分配);
idProduct : 产品ID(由厂商分配),由供应商ID和产品ID,就可以让操作系统加载不同的驱动程序
bcdDevice :设备出产编码.由厂家自行设置;
iManufacturer :厂商描述符字符串索引.索引到对应的字符串描述符. 为0则表示没有;
iProduct :产品描述符字符串索引.同上;
iSerialNumber:设备序列号字符串索引.同上;
bNumConfigurations :可能的配置数.指配置字符串的个数。
bDeviceClass、bDeviceSubClass和bDeviceProtocol可在USB官网进行查询,idVendor是向USB机构申请的,需要支付一笔费用,如果针对开发者,可以选择芯片厂商的idVendor进行开发。


配置描述符
配置描述符定义了设备的配置信息,一个设备可以有多个配置描述符。摘一个STM32的MSC设备的配置描述符:

用C语言组合就是这样的一个结构:
typedef struct _USB_CONFIGURATION_DESCRIPTOR_
{BYTE bLength,BYTE bDescriptorType,uint16_t wTotalLength,BYTE bNumInterfaces,BYTE bConfigurationValue,BYTE iConfiguration,BYTE bmAttributes,BYTE MaxPower
}USB_CONFIGURATION_DESCRIPTOR;每个字段含义如下:
bLength:描述符大小,固定为0x09.
bDescriptorType:配置描述符类型,固定为0x02.
wTotalLength:返回整个数据的长度,指此配置返回的配置描述符,接口描述符以及端点描述符的全部大小
bNumInterfaces:配置所支持的接口数。指该配置配备的接口数量也表示该配置下接口描述符数量
bConfigurationValue:作为Set Configuration的一个参数选择配置值
iConfiguration:用于描述该配置字符串描述符的索引
bmAttributes:供电模式选择,Bit4-0保留,D7:总线供电,D6:自供电,D5:远程唤醒
MaxPower:总线供电的USB设备的最大消耗电流.以2mA为单位,0x32表示 100mA
接口描述符
接口描述符说明了接口所提供的配置,一个配置所拥有的接口数量通过配置描述符的bNumInterfaces决定,摘取STM32的MSC设备类的接口描述符:

用C语言组合就是这样的一个结构:
typedef struct _USB_INTERFACE_DESCRIPTOR_
{BYTE bLength,BYTE bDescriptorType,BYTE bInterfaceNumber,BYTE bAlternateSetting,BYTE bNumEndpoint,BYTE bInterfaceClass,BYTE bInterfaceSubClass,BYTE bInterfaceProtocol,BYTE iInterface
}USB_INTERFACE_DESCRIPTOR;每个字段含义如下:
bLength : 描述符大小.固定为0x09
bDescriptorType : 接口描述符类型.固定为0x04
bInterfaceNumber: 该接口的编号
bAlternateSetting : 用于为上一个字段选择可供替换的位置.即备用的接口描述符标号
bNumEndpoint : 使用的端点数目.端点0除外
bInterfaceClass : 类型代码(由USB分配)
bInterfaceSubClass : 子类型代码(由USB分配)
bInterfaceProtocol : 协议代码(由USB分配)
iInterface : 字符串描述符的索引
端点描述符
USB设备中的每个端点都有自己的端点描述符,由接口描述符中的bNumEndpoint决定其数量。摘取STM32的MSC设备类的端口描述符:

用C语言组合就是这样的一个结构:
typedef struct _USB_ENDPOINT_DESCRIPTOR_ {BYTE bLength,BYTE bDescriptorType,BYTE bEndpointAddress,BYTE bmAttributes,BYTE bInterval
}USB_ENDPOINT_DESCRIPTOR;
每个字段含义如下:
bLength : 描述符大小.固定为0x07
bDescriptorType : 接口描述符类型.固定为0x050
bEndpointType : USB设备的端点地址.Bit7决定方向,1为IN端点,0为OUT端点,对于控制端点可以忽略;Bit6-4,保留;BIt3-0:端点号
bmAttributes : 端点属性.Bit7-2,保留.BIt1-0:00控制,01同步,02批量,03中断
wMaxPacketSize : 本端点接收或发送的最大信息包大小
bInterval : 轮训数据传送端点的时间间隔.对于批量传送和控制传送的端点忽略.对于同步传送的端点,必须为1,对于中断传送的端点,范围为1-255
字符串描述符
字符串描述符是可选的,如果不支持字符串描述符,其设备描述符、配置描述符、接口描述符内的所有字符串描述符索引都必须为0。

字符串描述符结构如下:
typedef struct _USB_STRING_DESCRIPTION_BYTE bLength,BYTE bDescriptionType,BYTE bString[1];
}USB_STRING_DESCRIPTION;各个字段含义:
bLength : 描述符大小.由整个字符串的长度加上bLength和bDescriptorType的长度决定.
bDescriptorType : 接口描述符类型,固定为0x03.
bString[1] : Unicode编码字符串
IAD描述符
USB组合设备一般用Interface Association Descriptor(IAD)实现,就是在要合并的接口前加上IAD描述符。例如你想用一个硬件USB接口实现两个功能,又能到U盘又能当虚拟串口,那么在USB配置描述符中就需要加上IAD描述符来指明。
typedef struct _USBInterfaceAssociationDescriptor
{BYTE bLength: 0x08 //描述符大小,固定BYTE bDescriptorType: 0x0B //IAD描述符类型,固定BYTE bFirstInterface: 0x00 //起始接口编号BYTE bInterfaceCount: 0x02 //本个IAD下设备类的接口数量BYTE bFunctionClass: 0x0E //类型代码,本个IAD指示的是什么类型的设备,例如CDC是0X02,MSC是0X08BYTE bFunctionSubClass: 0x03 //子类型代码BYTE bFunctionProtocol: 0x00 //协议代码BYTE iFunction: 0x04 //描述字符串索引
}以MSC+CDC为例,他的配置描述符结构就是这样的:
配置描述符
{IAD描述符1(CDC){接口描述符1(通信接口){其他描述符(特殊描述符){/*Header Functional Descriptor*//*Call Management Functional Descriptor*//*ACM Functional Descriptor*//*Union Functional Descriptor*/}端点描述符(命令端点){}}接口描述符2(数据接口){端点描述符1(输出端口){}端点描述符2(输入端口){ }}}IAD描述符(MSC){接口描述符1{端点描述符1{}端点描述符2{}}}
}其它描述符

Packet的组成
Packet主要由下面四部分组成:
SOP:起始帧,从DILE状态(J状态)切换到K状态
SYNC:同步域,3个重复的KJ状态切换,后跟随2个位时间的K状态
Packet Connent:内容域,主要包括以下内容:
PID:包标识
地址:设备地址
帧号:11位帧号
数据:通信的数据
CRC:校验
EOP:结束帧,持续2个位时间的SE0信号,后跟随1个位时间的J状态
接下来重点讲解一下Packet Connent域里面的内容。

Packet的内容
Packet包的内容--PID域

PID:Packet Identifier,包标识,LSB在前,前4个字节为PID码,后四个字节是前四个字节的取反。
以下是PID的类型码。

Packet包的内容--地址域

地址由7位的设备地址和4位的端点地址组成。

Packet包的内容--帧号域

帧号域由以下特性:
11位
主机每发出一个帧,帧号都会自动加1(全速和低速设备1ms发出一帧, 高速设备0.125ms发出一帧)
当帧号达到0x7FFF的时候,将清零帧号重新计数
仅在每个帧的帧首才传输一次SOF包
Packet包的内容--数据域

根据传输类型的不同,数据域的数据长度从0-1024字节不等。
Packet包的内容--CRC域


Packet的类型
Packet包的类型--令牌包

令牌包的组成为:PID+地址+CRC
PID:IN、OUT、SETUP令牌
地址:7位的设备地址和4位的端点号组成
CRC:这里是对地址域计算

Packet包的类型--SOF包

SOF包的组成为:PID+帧号+CRC
PID:SOF令牌
帧号:LS/FS每1ms一个帧,HS每0.125ms一个帧
CRC:这里是对帧号域计算

Packet包的类型--数据包

数据包的组成为:PID+数据+CRC
PID:DATA0、DATA1、DATA2、MDATA令牌
数据:传输类型不同,数据包的最大长度有所不同
CRC:这里是对数据域计算

Packet包的类型--握手包

握手包的组成为:PID
PID:ACK、NAK、STALL、NYET令牌
ACK:表示正确接收数据,并且有足够的空间来容纳数据。主机和设备都可以用ACK来确认,而NAK、STALLA、NYET只能设备返回,主机不能使用这些握手包。
NAK:表示没有数据需要返回,或者数据正确接收但是没有足够的空间来容忍它们。 当主机收到NAK时,知道设备还未准备好,主机会在以后的合适的时机进行重新传输。
STALL:表示设备无法执行这个请求,或者端点已经被挂起,它表示一种错误的状态。 设备返回STALL后,需要主机进行干预才能解除这种STALL状态。
NYET:只在USB2.0的高速设备输出事物中使用,表示设备本次数据成功接收,但是没有 足够的空间来接收下一次数据。主机在下一次输出数据时,将先使用PING令牌包来试探 设备是否有空间接收数据,以避免不必要的带宽浪费。
注意:
1. 当收到SETUP包的时候,设备只能回复ACK;
2. 当同步传输的时候,没有握手包。

传输类型
USB的传输类型分为控制传输、中断传输、批量传输和同步传输,每种传输类型用在特定的场合。
控制传输
非周期性传输,用于命令和状态的传输。每个USB设备都必须有控制端点,支持控制传输来进行命令和状态的传输。USB主机驱动将通过控制传输与USB设备的控制端点通讯,完成USB设备的枚举和配置。
控制传输是双向的传输,必须有IN和OUT两个方向上的特定端点号的控制端点来完成两个方向上的控住传输。

中断传输
周期性,低频率传输,允许有限延迟的通信,中断传输用于那些频率不高,但对周期有一定要求的数据传输。具有保证的带宽,并能在下个周期对先前错误的传输进行重传;对于全速端点,中断传输的时间间隔在1ms到255ms之间,对于低速端点,时间间隔限制在10ms到255ms之间,对于高速端点, 时间间隔为2bInterval-1*125us,bInterval的值在1到16之间。
中断传输总算单向的,可以用单向的中断端点来实现某个方向上的中断传输。

批量传输
非周期性,大容量数据的通信,数据可以占用任意带宽。大容量数据传输适用于那些需要大数据量传输,但是对实时性,对延迟性和带宽没有严格要求的应用。大容量传输可以占用任意可用的数据带宽。
大容量传输是单向的,可以用单向的大容量传输端点来实现某个方向的大容量传输。

同步传输
周期性,持续的传输,用于传输与时效相关的信息,并且在数据中保存时间戳的信息。同步传输用于传输那些需要保证带宽,并且不能忍受延迟的信息。整个带宽都将用于保证同步传输的数据完整,并且不支持出错重传。
同步传输总是单向的,可以使用单向的同步端点来实现某个方向上的同步传输。

复位挂起和唤醒机制
USB使用的差分传输模式,两个数据线D+和D-(VOH:2.8V VOL:0.3V)
差分信号1:D+ > VOH and D- < VOL
差分信号0:D- > VOH and D+ < VOL
IDLE状态:J状态
复位信号:D+ and D- < VOL for >= 10ms
挂起信号:USB主机3m内不发送任何信号(3ms以上的IDLE状态)
唤醒信号:K状态持续20ms以上,并以低速EOP信号结尾。


USB的枚举过程
枚举就是从设备读取一些信息,知道设备是什么样的设备,如何进行通信,这样主机就可以根据这些信息来加载合适的驱动程序。调试USB设备,很重要的一点就是USB的枚举过程,只要枚举成功了,那么就已经成功大半了。
枚举通信过程具体如下:
step1:检测电压变化,报告主机
首先,USB设备上电后,一直监测USB设备接口电平变化HUB检测到有电压变化,将利用自己的中断端点将信息反馈给主控制器有设备连接。
Step2:主机了解连接设备
主机在知道有设备接入后会发送一个Get_Port_Status请求(request)给hub以了解此次状态改变的确切含义。
Step3:Hub检测所插入的设备是高速还是低速
hub通过检测USB总线空闲(Idle)时差分线的高低电压来判断所连接设备的速度类型,当host发来Get_Port_Status请求时,hub就可以将此设备的速度类型信息回复给host。USB 2.0规范要求速度检测要先于复位(Reset)操作。
Step4:hub复位设备
主机一旦得知新设备已连上以后,它至少等待100ms以使得插入操作的完成以及设备电源稳定工作。然后主机控制器就向hub发出一个 Set_Port_Feature请求让hub复位其管理的端口(刚才设备插上的端口)。hub通过驱动数据线到复位状态(D+和D-全为低电平 ),并持续至少10ms。当然,hub不会把这样的复位信号发送给其他已有设备连接的端口,所以其他连在该hub上的设备自然看不到复位信号,不受影响。
Step5: Host检测所连接的全速设备是否是支持高速模式
因为根据USB 2.0协议,高速(High Speed)设备在初始时是默认全速(Full Speed )状态运行,所以对于一个支持USB 2.0的高速hub,当它发现它的端口连接的是一个全速设备时,会进行高速检测,看看目前这个设备是否还支持高速传输,如果是,那就切到高速信号模式,否则就一直在全速状态下工作。
同样的,从设备的角度来看,如果是一个高速设备,在刚连接bub或上电时只能用全速信号模式运行(根据USB 2.0协议,高速设备必须向下兼容USB 1.1的全速模式)。随后hub会进行高速检测,之后这个设备才会切换到高速模式下工作。假如所连接的hub不支持USB 2.0,即不是高速hub,不能进行高速检测,设备将一直以全速工作。
Step6:Hub建立设备和主机之间的信息通道
主机不停地向hub发送Get_Port_Status请求,以查询设备是否复位成功。Hub返回的报告信息中有专门的一位用来标志设备的复位状态。
当hub撤销了复位信号,设备就处于默认/空闲状态(Default state),准备接收主机发来的请求。设备和主机之间的通信通过控制传输,默认地址0,端点号0进行。此时,设备能从总线上得到的最大电流是100mA。(所有的USB设备在总线复位后其地址都为0,这样主机就可以跟那些刚刚插入的设备通过地址0通信。)
Step7:主机发送Get_Descriptor请求获取默认管道的最大包长度
默认管道(Default Pipe)在设备一端来看就是端点0。主机此时发送的请求是默认地址0,端点0,虽然所有未分配地址的设备都是通过地址0来获取主机发来的请求,但由于枚举过程不是多个设备并行处理,而是一次枚举一个设备的方式进行,所以不会发生多个设备同时响应主机发来的请求。
设备描述符的第8字节代表设备端点0的最大包大小。虽然说设备所返回的设备描述符(Device Descriptor)长度只有18字节,但系统也不在乎,此时,描述符的长度信息对它来说是最重要的,其他的瞄一眼就过了。当完成第一次的控制传输后,也就是完成控制传输的状态阶段,系统会要求hub对设备进行再一次的复位操作(USB规范里面可没这要求)。再次复位的目的是使设备进入一个确定的状态。
Step8:主机给设备分配一个地址
主机控制器通过Set_Address请求向设备分配一个唯一的地址。在完成这次传输之后,设备进入地址状态(Address state),之后就启用新地址继续与主机通信。这个地址对于设备来说是终生制的,设备在,地址在;设备消失(被拔出,复位,系统重启),地址被收回。同一个设备当再次被枚举后得到的地址不一定是上次那个了。
Step9:主机获取设备的信息
主机发送 Get_Descriptor请求到新地址读取设备描述符,这次主机发送Get_Descriptor请求可算是诚心,它会认真解析设备描述符的内容。设备描述符内信息包括端点0的最大包长度,设备所支持的配置(Configuration)个数,设备类型,VID(Vendor ID,由USB-IF分配), PID(Product ID,由厂商自己定制)等信息。
之后主机发送Get_Descriptor请求,读取配置描述符(Configuration Descriptor),字符串等,逐一了解设备更详细的信息。事实上,对于配置描述符的标准请求中,有时wLength一项会大于实际配置描述符的长度(9字节),比如255。这样的效果便是:主机发送了一个Get_Descriptor_Configuration 的请求,设备会把接口描述符,端点描述符等后续描述符一并回给主机,主机则根据描述符头部的标志判断送上来的具体是何种描述符。
接下来,主机就会获取配置描述符。配置描述符总共为9字节。主机在获取到配置描述符后,根据里面的配置集合总长度,再获取配置集合。配置集合包括配置描述符,接口描述符,端点描符等等。
如果有字符串描述符的话,还要获取字符串描述符。另外HID设备还有HID描述符等。
Step10: 主机给设备挂载驱动(复合设备除外)
主机通过解析描述符后对设备有了足够的了解,会选择一个最合适的驱动给设备。 然后tell the world(announce_device)说明设备已经找到了,最后调用设备模型提供的接口device_add将设备添加到 usb 总线的设备列表里,然后 usb总线会遍历驱动列表里的每个驱动,调用自己的 match(usb_device_match) 函数看它们和你的设备或接口是否匹配,匹配的话调用device_bind_driver函数,现在就将控制权交到设备驱动了。
对于复合设备,通常应该是不同的接口(Interface)配置给不同的驱动,因此,需要等到当设备被配置并把接口使能后才可以把驱动挂载上去。
Step11:设备驱动选择一个配置
驱动(注意,这里是驱动,之后的事情都是有驱动来接管负责与设备的通信)根据前面设备回复的信息,发送Set_Configuration请求来正式确定选择设备的哪个配置(Configuration)作为工作配置(对于大多数设备来说,一般只有一个配置被定义)。至此,设备处于配置状态(Configured),当然,设备也应该使能它的各个接口(Interface)。
对于复合设备,主机会在这个时候根据设备接口信息,给它们挂载驱动。


以下是一个简单的枚举过程,帮助大家理解软件层面的协议。
Host [ 80 06 00 01 00 00 40 00 ] 主机:你是什么设备?
Device [ 12 01 00 02 0A 00 00 40 70 34 08 00 00 02 01 02 03 01 ] 设备:我是CDC设备
Host [ 00 05 21 00 00 00 00 00 ] 主机设置唯一设备地址(地址只能从0-127),以后使用此地址和设备通讯
Host [ 80 06 00 01 00 00 12 00 ] 主机:你是什么设备?
Device [ 12 01 00 02 02 02 02 40 70 34 08 00 00 02 01 02 03 01 ] 设备:我是CDC设备
Host [ 80 06 00 02 00 00 FF 00 ] 主机:你有几个接口?每个接口使用了哪几个端点?
Device [ 09 02 43 00 02 01 00 C0 32 09 04 00 00 01 02 02 01 00 05 24 00 10 01 05 24 01 00 01 04 24 02 02 05 24 06 00 01 07 05 82 03 08 00 FF 09 04 01 00 02 0A 00 00 00 07 05 03 02 40 00 00 07 05 81 02 ]
Device [ 40 00 00 ] 设备:我有2个接口,一个接口使用了输入端点2,一个接口使用了输入端点1和输出端点3
Host [ 80 06 00 03 00 00 FF 00 ] 主机:你的字符串使用的是什么编码格式?
Device [ 04 03 09 04 ] 设备:我使用的美国的编码格式
Host [ 80 06 02 03 09 04 FF 00 ] 主机:你的产品名称是什么?
Device [ 32 03 53 00 54 00 4D 00 33 00 32 00 20 00 56 00 69 00 72 00 74 00 75 00 61 00 6C 00 20 00 43 00 4F 00 4D 00 20 00 50 00 6F 00 72 00 74 00 20 00 20 00 ] 设备:我的产品名称是…
Host [ 80 06 03 03 09 04 FF 00 ] 主机:你的设备UID是什么?
Device [ 1A 03 35 00 43 00 44 00 45 00 35 00 38 00 34 00 30 00 33 00 32 00 33 00 30 00 ] 设备:我的UID是....
STM32相关讲解
STM32-USB详解

这个512字节SRAM叫做Packet Buffer Memory Area(简称PMA),这个很重要,后面会详细讲解。

根据描述可以,一共有8个端点,16个寄存器,一个端点关联两个寄存器,所以我们可以将他们规划为8个输入端点(0x80-0X87)+8个输出端点(0X00-0X07)。
STM32-PMA详解
先说一下USB的数据包大小,全速设备的最大包大小为64字节,高速最大为1024字节,STM32是USB全速设备,所以最大为64字节。
Packet Buffer Memory Area(简称PMA)
STM32F1/F3/L1系列都有且结构相同(其他系列暂未考证),译过来就是包数据缓存区,大小为512字节,按2字节进行寻址。
这个PMA的作用就是USB设备模块用来实现MCU与主机进行数据通信的一个专门的数据缓冲区,我们称之为USB硬件缓冲区。
说得具体点就是USB模块把来自主机的数据接收进来后先放到PMA,然后再被拷贝到用户数据缓存区;或者MCU要发送到主机的数据,先从用户数据缓存区拷贝进PMA,再通过USB模块负责发送给主机。
很多人利用ST官方的USB库修改自己的USB应用时候卡住,获取改完之后懵懵懂懂出现错误,估计大多数原因就在此处的修改!
摘取一下STM32F1参考手册里的PMA描述表:

名称含义:
ADDR0_TX:输出端点0发送缓冲区地址
COUNT0_TX:输出端点0发送缓冲区大小
ADDR0_RX:输入端点0发送缓冲区地址
COUNT0_RX:输入端点0发送缓冲区大小
可以看到一个完整的端点描述包括:缓冲区地址+缓冲区大小。
PMA的头部为端点的描述,每个端点占8个字节,实际使用了几个端点就有几个描述头,例如使用了0、1、2这三个连续端点(这里注意是连续端点),那么PMA头部的3x8=24(十六进制的0X18)字节就是描述,倘若你使用的是0、1、3这三个端点,其中编号为2的端点虽然没使用但是占用空间,那么PMA头部的端点描述就是4x8=32字节,编号为2的端点8字节的空间就浪费了(严格来说没浪费,就是不方便使用)。
头部的端点描述之后就是各个端点的缓冲区了,例如使用了0、1、2三个端点,占用了PMA头部3x8=24字节的空间,那么这三个端点的缓冲区地址就是从PMA偏移24字节开始的,当然只要是大于24就都可以,这里就是最关键的地方了,很多人修改ST官方库实现自己USB应用时候就是没改这里的地址,导致缓冲区的使用覆盖了PMA头部的端点描述从而出错!
下面摘取一个STM32官方MSC设备的实例进行分析:

可以看到一共用到了4个端点,分别是输入端点0X80和0X81,输出端点0X00和0X01,其中0X00端点和0X80端点是供USB使用必须有的,0X81和0X01端点则是MSC设备输入输出端点。
那么一共使用了4个端点,按理来说PMA头部的端点描述大小应该是4X8=32(十六进制的0X20)字节,0X20之后的才是各个端点缓冲区,但是ST这里的却是从0X18开始,也就是说使用了三个端点,这个地方我还没有搞明白为什么,欢迎各位补充!
至于为什么0X18之后是0X58,是因为USB全速设备的最大包是64字节(十进制的0X40),所以这里PMA的划分就是:
头部0X18字节为各个端点的描述
0X18地址开始的64字节为输出端点0的缓冲区
0X58地址开始的64字节为输入端点0的缓冲区
0X98地址开始的64字节为输入端点1的缓冲区
0XD8地址开始的64字节为输出端点1的缓冲区
这里注意一点,缓冲区分配好之后访问是不会溢出的,也就是说缓冲区之间完全隔离。
STM32F1-HAL库中 USB外设库的文件介绍
STM32_USB_Host_Library 中的文件介绍


STM32_USB_Device_Library 中的文件介绍


这篇内容很多,很难完全看完,对于像弄明白USB原理和过程的有一定意义,但是对于只想快速做出东西的可以直接看后面的文章。
相关文章:
(1)STM32 USB设备开发-基础知识
开篇感谢: 【经验分享】STM32 USB相关知识扫盲 - STM32团队 ST意法半导体中文论坛 单片机学习记录_桃成蹊2.0的博客-CSDN博客 USB_不吃鱼的猫丿的博客-CSDN博客 1、USB鼠标_哔哩哔哩_bilibili usb_冰糖葫的博客-CSDN博客 USB_lqonlylove的博客-CSDN博客 USB …...

Spring中如何动态的创建、监听MQ以及创建Exchange
文章目录 前言动态创建和管理Exchange、Queue动态消费Queue结论 前言 前面我们学习 RabbitMQ 的时候,都是在编译的时候就确定了Exchange、Queue,也就是说我们需要在程序启动之前就创建好需要的Exchange和Queue,但是实际使用的时候࿰…...

中国综合算力指数(2024年)报告汇总PDF洞察(附原数据表)
原文链接: https://tecdat.cn/?p39061 在全球算力因数字化技术发展而竞争加剧,我国积极推进算力发展并将综合算力作为数字经济核心驱动力的背景下,该报告对我国综合算力进行研究。 中国算力大会发布的《中国综合算力指数(2024年…...

【Python项目】小区监控图像拼接系统
【Python项目】小区监控图像拼接系统 技术简介:采用Python技术、B/S框架、MYSQL数据库等实现。 系统简介:小区监控拼接系统,就是为了能够让业主或者安保人员能够在同一时间将不同地方的图像进行拼接。这样一来,可以很大程度的方便…...

常用排序算法之插入排序
目录 前言 一、基本原理 1.算法步骤 2.动画演示 3.插入排序的实现代码 二、插入排序的时间复杂度 1. 时间复杂度 1.最优时间复杂度 2.最差时间复杂度 3.平均时间复杂度 2. 空间复杂度 三、插入排序的优缺点 1.优点 2.缺点 四、插入排序的改进与变种 五、插入排…...
基础查询语法的使用)
Elasticsearch(ES)基础查询语法的使用
1. Match Query (全文检索查询) 用于执行全文检索,适合搜索文本字段。 { “query”: { “match”: { “field”: “value” } } } match_phrase:精确匹配短语,适合用于短语搜索。 { “query”: { “match_phrase”: { “field”: “text” }…...

一篇文章学会Milvus【Docker 中运行 Milvus(Windows),Python实现对Milvus的操作,源代码案例,已经解决巨坑】【程序员猫爪】
一篇文章学会Milvus【Docker 中运行 Milvus(Windows),Python实现对Milvus的操作,源代码案例,已经解决巨坑】【程序员猫爪】 一、Milvus 是什么?【程序员猫爪】1、Milvus 是一种高性能、高扩展性的向量数据库…...

前端之移动端
视口 布局视口 layout viewport 视口(viewport)就是浏览器显示页面内容的屏幕区域。 视口可以分为布局视口、视觉视口和理想视口 一般移动设备的浏览器都默认设置了一个布局视口,用于解决早期的PC端页面在手机上显示的问题。 iOS, Androi…...
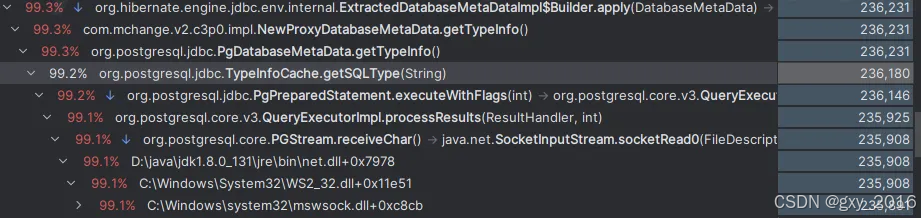
记一次 SpringBoot 启动慢的问题
记一次 SpringBoot 启动慢的问题 背景问题描述分析处理Flame Graph 火焰图Call Tree 调用树关键词检索尝试解决 为什么这样反向检索问题梳理 复盘处理流程为什么 Reference 背景 最近临时接了一个任务,就从一个旧 springboot 项目 copy 出来,临时写个服…...
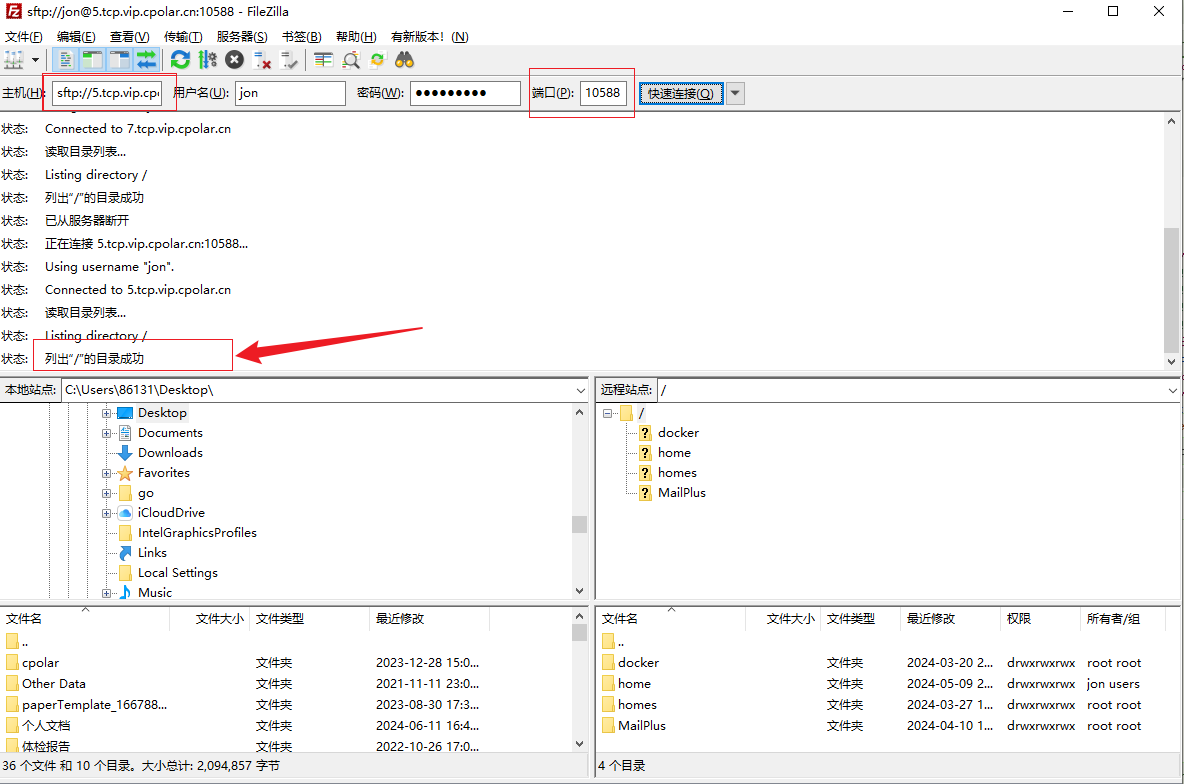
高效安全文件传输新选择!群晖NAS如何实现无公网IP下的SFTP远程连接
文章目录 前言1. 开启群晖SFTP连接2. 群晖安装Cpolar工具3. 创建SFTP公网地址4. 群晖SFTP远程连接5. 固定SFTP公网地址6. SFTP固定地址连接 前言 随着远程办公和数据共享成为新常态,如何高效且安全地管理和传输文件成为了许多人的痛点。如果你正在寻找一个解决方案…...

如何在Python中进行JSON数据的序列化和反序列化?
在Python中,JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。Python内置的json模块提供了简单易用的方法来实现数据的序列化和反序列化。下面将详细介绍如何…...

学习记录-统计记录场景下的Redis写请求合并优化实践
学习记录-使用Redis合并写请求来优化性能 1.业务背景 学习进度的统计功能:为了更精确的记录用户上一次播放的进度,采用的方案是:前端每隔15秒就发起一次请求,将播放记录写入数据库。但问题是,提交播放记录的业务太复杂了&#x…...

网站HTTP改成HTTPS
您不仅需要知道如何将HTTP转换为HTTPS,还必须在不妨碍您的网站自成立以来建立的任何搜索排名权限的情况下进行切换。 为什么应该从HTTP转换为HTTPS? 与非安全HTTP于不同,安全域使用SSL(安全套接字层)服务器上的加密代…...
上安装极狐GitLab?)
如何在龙蜥 OS(AliOS)上安装极狐GitLab?
本文分享如何在龙蜥操作系统(AliOS)(包括 RHCK 和 ANCK 两种,两种方式的安装流程一样)上安装极狐GitLab? 前提条件 一个安装了龙蜥操作系统的云服务器 可以查看 /etc/os-release中的信息,确认…...

unity插件Excel转换Proto插件-ExcelToProtobufferTool
unity插件Excel转换Proto插件-ExcelToProtobufferTool **ExcelToProtobufTool 插件文档****1. 插件概述****2. 默认配置类:DefaultIProtoPathConfig****属性说明** **3. 自定义配置类****定义规则****示例代码** **4. 使用方式****4.1 默认路径****4.2 自定义路径**…...

C#中的语句
C#提供了各式各样的语句,大多数是由C和C发展而来,当然,在C#中做了相应修改。语句和表达式一样,都是C#程序的基本组成部分,在本文我们来一起学习C#语句。 1.语句 语句是构造所有C#程序的过程构造块。在语句中可以声明…...

《罗宾逊-旅途VR》Build2108907官方学习版
《罗宾逊-旅途VR》官方版 https://pan.xunlei.com/s/VODiY5gn_fNxKREdVRdwVboCA1?pwdsh3f# 从第一人称的角度进行探索,玩家将遇到一系列恐龙和生物,这些恐龙和生物会对它们在泰森三世生态系统中的存在做出反应。强调与周围环境的互动,鼓励玩…...

常用的跨域方案有哪些?
在前端开发中,跨域(Cross-Origin)是一个常见问题,通常是由于浏览器的同源策略(Same-Origin Policy)限制导致的。为了解决跨域问题,前端开发者可以采用多种方案。 1. CORS(跨域资源共…...

JDBC实验测试
一、语言和环境 实现语言:Java。 环境要求:IDEA2023.3、JDK 17 、MySQL8.0、Navicat 16 for MySQL。 二、技术要求 该系统采用 SWING 技术配合 JDBC 使用 JAVA 编程语言完成桌面应用开发。 三、功能要求 某电商公司为了方便客服查看用户的订单信…...

ChatGPT 摘要,以 ESS 作为你的私有数据存储
作者:来自 Elastic Ryan_Earle 本教程介绍如何设置 Elasticsearch 网络爬虫,将网站索引到 Elasticsearch 中,然后利用 ChatGPT 使用我们的私人数据来总结对其提出的问题。 Python 脚本的 Github Repo:https://github.com/Gunner…...

Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 [特殊字符]
Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 😎 【免费下载链接】Ventoy A new bootable USB solution. 项目地址: https://gitcode.com/GitHub_Trending/ve/Ventoy 还在为每次安装系统都要重新制作启动盘而烦恼吗&#x…...

tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南
tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南 【免费下载链接】tools Assorted useful tools, almost entirely generated using LLMs 项目地址: https://gitcode.com/gh_mirrors/tools23/tools tools.simonwillison.net图像处理工具集是一…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

UE4动画蓝图实战:用双骨骼IK节点搞定手部穿模,附完整蓝图节点截图
UE4动画蓝图实战:双骨骼IK节点解决手部穿模的完整指南在角色动画开发中,手部穿模问题堪称"视觉杀手"。想象一下精心设计的角色挥拳时,拳头直接穿过墙壁或敌人身体——这种违和感足以毁掉整个场景的沉浸感。本文将彻底解决这个痛点&…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

避坑指南:Unity中AABB碰撞检测失效的5种常见原因及解决方法
Unity中AABB碰撞检测失效的深度排查与解决方案在Unity开发中,AABB(轴对齐包围盒)碰撞检测是基础但容易出问题的环节。许多开发者都遇到过这样的情况:明明逻辑正确,测试时却出现物体穿透、碰撞时有时无等诡异现象。本文…...

解决claude code频繁封号与token不足的taotoken接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号与Token不足的Taotoken接入方案 1. 问题背景:Claude Code用户面临的挑战 对于依赖Claude Cod…...

AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程
AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 想要让你的…...

公共卫生机器学习项目中的算法公平性实践:ACAR框架详解
1. 项目概述:当机器学习遇见公共卫生,公平性为何成为“必答题”?在公共卫生领域,机器学习(ML)正以前所未有的速度渗透到疾病监测、风险分层和资源分配等核心环节。想象一下,一个模型被用来预测某…...