支持向量机SVM的应用案例
支持向量机(Support Vector Machine,SVM)是一种强大的监督学习算法,广泛应用于分类和回归任务。
基本原理
SVM的主要目标是周到一个最优的超平面,该超平面能够将不同类别的数据点尽可能分开,并且使离该超平面最近的数据点(称为支持向量)到超平面的距离最大化。这个距离称为间隔(Margin)。
- 对于线性可分的数据,SVM试图周到一个线性超平面,通过求解一个凸二次规划问题实现。
- 对于线性不可分的数据,SVM将原始特征空间映射到一个更高维的特征空间,使得在高维空间中数据变得线性可分。
信用风险评估应用场景
金融机构在评估客户的信用风险时,会考虑众多因素,比如客户的收入水平、资产状况、信用历史、债务情况等。这些因素构成了高位的输入数据。SVM可以根据历史客户数据,建立信用风险分类模型。
数据收集与准备
- 数据收集
明确了客户信息的维度,ID(序号),Label(是否违约),AGE(年龄),GENDER(性别),MARITAL_STATUS(婚姻状况),MONTHLY_INCOME_WHITHOUT_TAX(税前月收入),LOANTYPE(贷款类型),GAGE_TOTLE_PRICE(抵押物总价),APPLY_AMOUNT(申请贷款金额),APPLY_TERM_TIME(贷适用期限),APPLY_INTEREST_RATE(申请利率),PAYMENT_TYPE(贷款还款方式) - 数据清洗
检查数据中缺失值、重复值和异常值。通过对原始数据的检查,未发现明显发现重复值和异常值。
-
检查缺失值
print(data.isna().sum())检查结果

税前收入(MONTHLY_INCOME_WITHOUT_TAX)存在缺失值的情况,因为整体样本较小,所以尽量不对存在缺失值的记录进行删除。在缺失值补充情况下,因为存在税前收入为0的同类情况,从业务角度来看,缺失的情况可以默认为0是比较合理的情况。所以对缺失值都赋值为0。此外,因为ID属性不包含任何有用信息,应予以移除。data=data.drop(columns=['ID']).fillna(0) -
检查重复值
print(data[data.duplicated(keep=False)])
结果:

未发现有重复数据
特征工程
- 特征选择
挑选对信贷分类有重要影响的特征,因为数据维度较少,通过业务经验分析,所有已有的属性都可能与信贷违约存在潜在关系,所以不进行筛选。 - 特征编码
对一些非数值型特征,进行编码处理,将其转换为数值型数据,以便 SVM 算法处理。
print(data['GENDER'].unique())print(data['MARITAL_STATUS'].unique())print(data['LOANTYPE'].unique())print(data['PAYMENT_TYPE'].unique())

性别、婚姻状况、贷款类型、还款方式这四个属性为非数值特征,需要进行编码处理。其中,性别、贷款类型以及还款方式都是二分类离散变量,婚姻状况是多分类离散变量。
① 对二分类离散变量处理
将性别、贷款类型以及还款方式映射为0和1。
data['GENDER'] = data['GENDER'].map({'Female': 1, 'Male': 0})
data['LOANTYPE'] = data['LOANTYPE'].map({'Frist-Hand': 1, 'Second-Hand': 0})
data['PAYMENT_TYPE'] = data['PAYMENT_TYPE'].map({'Average_Capital_Plus_Interest_Repayment': 1, 'Matching_The_Principal_Repayment': 0})
② 对多分类离散变量处理
多分类离散变量采用独热编码(one-hot)来处理,将单个特征转换为二进制的多个特征。
encoder = OneHotEncoder()
marital_status_encoded = encoder.fit_transform(data[['MARITAL_STATUS']]).toarray()
# 将单个marital_status 转换多个marital_status_i
marital_status_encoded_df = pd.DataFrame(marital_status_encoded, columns=[f'marital_status_{i}' for i in range(marital_status_encoded.shape[1])])
data = pd.concat([data.drop('MARITAL_STATUS', axis=1), marital_status_encoded_df], axis=1)
-
特征缩放
将数据特征进行归一化或标准化处理,将特征值映射到一定的范围内,如将数据归一化到 [0,1] 或使数据具有零均值和单位方差,以提升模型的训练效果和收敛速度。
将数据进行标准化处理,减少数据尺度的影响。基本原理为计算输入数据 X 的均值和标准差。对于每一个特征(列),计算其均值 μ 和标准差 σ。 x s c a l e d = x − μ σ x_{scaled}=\frac{x - \mu}{\sigma} xscaled=σx−μ其中:
- x s c a l e d x_{scaled} xscaled 是标准化后的特征值。
- x x x 是原始特征值。
- μ \mu μ 是特征的均值
X=data.drop('Label', axis=1).values
scaler=StandardScaler()
X_scaled=scaler.fit_transform(X)
建立模型
- 划分数据集
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
将准备好的数据划分为训练集和测试集,按照 8:2的比例划分。random_state 是一个可选参数,用于控制随机数生成器的状态。
当你设置 random_state 为一个特定的值42时,每次运行代码,数据集的划分结果都会相同。这是因为使用相同的 random_state 会导致随机数生成器产生相同的随机序列,从而使数据集的划分具有可重复性。
- 选择 SVM 类型和核函数
- SVM 类型:根据信贷数据的特点和分类需求,选择合适的 SVM 类型,如线性 SVM 或非线性 SVM。如果信贷数据的特征之间呈现明显的线性可分关系,可选择线性 SVM;若数据存在复杂的非线性关系,则考虑使用基于核函数的非线性 SVM。
- 核函数:常见的核函数有线性核、多项式核、径向基函数(RBF)核等。对于信贷数据,RBF 核函数通常能较好地处理数据中的非线性关系,是一种常用的选择。
- 设置参数:设置 SVM 模型的参数,主要包括惩罚参数 C 和核函数的参数。惩罚参数 C 用于平衡模型的训练误差和复杂度,C 值越大,模型对误分类的惩罚越重,可能会导致模型过拟合;C 值越小,模型可能会欠拟合。核函数参数根据所选核函数而定,如 RBF 核的 gamma 值,gamma 值越大,模型的拟合能力越强,但也越容易过拟合。
- 模型训练:使用训练集数据对 SVM 模型进行训练,通过优化算法求解 SVM 的目标函数,得到模型的参数,确定分类超平面或决策边界。
- 在无法明确数据分布的情况下,我们选择线性SVM和非线性SVM进行训练
# 使用线性核的 SVM 进行分类
svm_linear = SVC(kernel='linear',probability=True)
svm_linear.fit(X_train, y_train)
print(f"Linear SVM Accuracy : {svm_linear.score(X_test, y_test)}")
线性核的预测精度为0.95053(保留5位小数)
# 使用 RBF 核的 SVM 进行分类
svm_rbf = SVC(kernel='rbf')
svm_rbf.fit(X_train, y_train)
print(f"RBF SVM Accuracy : {svm_rbf.score(X_test, y_test)}")
非线性核RBF的预测精度为0.91519(保留5位小数)
- GridSearchCV 网格搜索最佳参数优化模型
# 定义参数网格
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000],'gamma': [0.001, 0.01, 0.1, 1, 10, 100, 1000],'kernel': ['rbf', 'poly', 'linear']
}# 使用 GridSearchCV 并设置 cv
svm = SVC()
grid_search = GridSearchCV(svm, param_grid,n_jobs=-1, cv=5) # cv = 5 表示使用 5 折交叉验证
grid_search.fit(X_train, y_train)# 输出最佳参数组合
print(f"Best parameters: {grid_search.best_params_}")# 使用最佳参数评估模型
best_svm = grid_search.best_estimator_
print(f"Best estimator: {best_svm}")# 输出最佳参数组合和准确率
y_pred = best_svm.predict(X_test)
print(f"Best accuracy: {accuracy_score(y_test, y_pred)}")
Best parameters: {‘C’: 100, ‘gamma’: 0.01, ‘kernel’: ‘rbf’}
Best estimator: SVC(C=100, gamma=0.01)
Best accuracy: 0.9717314487632509
在优化后,使用C为100,gamma为0.01以及核函数为RBF的SVC分类模型训练,预测精度提升至0.97173
评价模型
ROC评估
ROC(Receiver Operating Characteristic)曲线是种用于评估二分类模型性能的可视化工具。它通过绘制真正率(True Positive Rate,TPR)与假正例率(False Positive Rate, FPR)在不同分类阈值下的关系曲线来展示模型性能。
AUC(Area Under the Curve,AUC),AUC 是ROC曲线下的面积,取值范围在0到1之间,AUC越大表示模型性能越好。
# 对测试集进行预测,获取预测概率
y_pred_prob = best_svm.predict_proba(X_test)[:, 1]
# 计算 ROC 曲线
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
roc_auc = auc(fpr, tpr)# 绘制 ROC 曲线
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()

橙色曲线为优化后的SVC模型的ROC曲线,其AUC值为0.99,逼近于1,模型分类性能非常好。蓝色曲线为随机参照曲线,可以看到其AUC值为0.5。
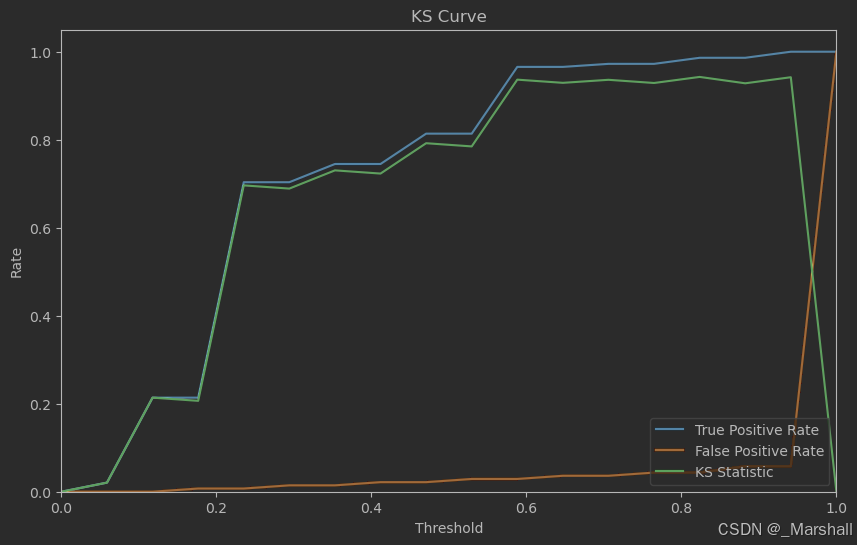
KS评估
KS(Kolmogorov-Simirnov)评估是一种用于评估二分类模型区分能力的统计指标,它基于累积分布函数(Cumulative Distribution Function, CDF)的概念。KS统计量衡量了正负样本的累积分布函数之间的最大差值。
0<KS<1,一般来说,KS值越大,模型的区分能力越强。通常,在信贷风险评估领域,KS值大于0.4被认为是一个 不错的模型。
# 计算 KS 统计量
ks_statistic = np.max(np.abs(tpr - fpr))
print(f"KS Statistic : {ks_statistic}")
KS Statistic : 0.9427286356821589
相关文章:
支持向量机SVM的应用案例
支持向量机(Support Vector Machine,SVM)是一种强大的监督学习算法,广泛应用于分类和回归任务。 基本原理 SVM的主要目标是周到一个最优的超平面,该超平面能够将不同类别的数据点尽可能分开,并且使离该超平面最近的数…...
Chrome 132 版本新特性
Chrome 132 版本新特性 一、Chrome 132 版本浏览器更新 1. 在 iOS 上使用 Google Lens 搜索 在 Chrome 132 版本中,开始在所有平台上推出这一功能。 1.1. 更新版本: Chrome 126 在 ChromeOS、Linux、Mac、Windows 上:在 1% 的稳定版用户…...
(5)STM32 USB设备开发-USB键盘
讲解视频:2、USB键盘-下_哔哩哔哩_bilibili 例程:STM32USBdevice: 基于STM32的USB设备例子程序 - Gitee.com 本篇为使用使用STM32模拟USB键盘的例程,没有知识,全是实操,按照步骤就能获得一个STM32的USB键盘。本例子是…...

Linux 系统服务开机自启动指导手册
一、引言 在 Linux 系统中,设置服务开机自启动是常见的系统配置任务。本文档详细介绍了多种实现服务开机自启动的方法,包括 systemctl 方式、通用脚本方式、crontab 方案等,并提供了生产环境下的方案建议和开机启动脚本示例。 二、systemct…...

分布式多卡训练(DDP)踩坑
多卡训练最近在跑yolov10版本的RT-DETR,用来进行目标检测。 单卡训练语句(正常运行): python main.py多卡训练语句: 需要通过torch.distributed.launch来启动,一般是单节点,其中CUDA_VISIBLE…...
-C题(树上两个节点不同边数最大值))
Codeforces Round 1000 (Div. 2)-C题(树上两个节点不同边数最大值)
https://codeforces.com/contest/2063/problem/C 牢记一棵树上两个节点如果相邻,它们有一条边会重叠,两个节点延伸出去的所有不同边是两个节点入度之和-1而不是入度之和,那么如果这棵树上有三个节点它们的入度都相同,那么优先选择非相邻的两个节点才能使所有不同边的数量最大!!…...

C++17 新特性解析:Lambda 捕获 this
C17 引入了许多改进和新特性,其中之一是对 lambda 表达式的增强。在这篇文章中,我们将深入探讨 lambda 表达式中的一个特别有用的新特性:通过 *this 捕获当前对象的副本。这个特性不仅提高了代码的安全性,还极大地简化了某些场景下…...

Spring Boot 使用 Micrometer 集成 Prometheus 监控 Java 应用性能
在Spring Boot中使用Micrometer集成Prometheus来监控Java应用性能是一种常见的做法。 一、Micrometer简介 Micrometer是一个开源的Java项目,主要用于为JVM应用程序提供监控和度量功能。以下是对Micrometer的详细介绍: 定义与功能 Micrometer是一个针…...

Spring Boot 事件驱动:构建灵活可扩展的应用
在 Spring Boot 应用中,事件发布和监听机制是一种强大的工具,它允许不同的组件之间以松耦合的方式进行通信。这种机制不仅可以提高代码的可维护性和可扩展性,还能帮助我们构建更加灵活、响应式的应用。本文将深入探讨 Spring Boot 的事件发布…...

IM系统设计
读多写少,一般采用写扩散成timeline来做 写扩散模式 利用last message id作为这个作为最后一个消息体 timeline和批量未读和ack 利用ZSET来维护连接的定时心跳,来续约运营商的连接不断开...

华为EC6110T-海思Hi3798MV310_安卓9.0_通刷-强刷固件包
华为EC6110T-海思Hi3798MV310_安卓9.0_通刷-强刷固件包 刷机教程说明: 适用机型:华为EC6110-T、华为EC6110-U、华为EC6110-M 破解总分为两个部分:拆机短接破解(保留IPTV)和OTT卡刷(不保留IPTV)…...

ASP.NET Blazor托管模型有哪些?
今天我们来说说Blazor的三种部署方式,如果大家还不了解Blazor,那么我先简单介绍下Blazor Blazor 是一种 .NET 前端 Web 框架,在单个编程模型中同时支持服务器端呈现和客户端交互性: ● 使用 C# 创建丰富的交互式 UI。 ● 共享使用…...
利用深度学习提升广告效果)
PyTorch广告点击率预测(CTR)利用深度学习提升广告效果
目录 广告点击率预测问题数据集结构广告点击率预测模型的构建1. 数据集准备2. 构建数据加载器3. 构建深度学习模型4. 训练与评估 总结 广告点击率预测(CTR,Click-Through Rate Prediction)是在线广告领域中的重要任务,它帮助广告平…...

PAT甲级-1017 Queueing at Bank
题目 题目大意 银行有k个窗口,每个窗口只能服务1个人。如果3个窗口已满,就需要等待。给出n个人到达银行的时间和服务时间,要求计算每个人的平均等待时间。如果某个人的到达时间超过17:00:00,则不被服务,等待时间也不计…...

OneData体系架构详解
阿里巴巴的 OneData 体系架构方法论,主要分为三个阶段:业务板块、规范定义 和 模型设计。每个阶段的核心目标是确保数据的高效管理、共享与分析能力。 一. 业务板块(Business Segment) 业务板块是OneData体系架构中的第一步&…...

Gin 框架入门实战系列教程
一,Gin介绍 Gin是一个 Go (Golang) 编写的轻量级 http web 框架,运行速度非常快,如果你是性能和高效的追求者,我们推荐你使用Gin框架。 Gin最擅长的就是Api接口的高并发,如果项目的规模不大,业务相对简单…...
)
鸿蒙harmony json转对象(2)
在ArkTS(Ark TypeScript)中,接口(interface)是用来定义一个对象的结构,它可以包含属性、方法签名,以及嵌套的类型(包括其他接口或对象类型)。因此,接口里面可…...

M-LAG与E-trunk
M-LAG和E-trunk都是用来实现跨设备链路聚合,解决单点故障的,其大部分特性相同,工作模式M-LAG更胜一筹,支持双活,而且其原理感觉像是vrrpmstp的升级版,是往增加网络可靠性去发展的;而E-trunk是基于LACP扩展实现…...

【面试常见问题】
如何自我介绍 自我介绍是面试关键部分,是面试官了解求职者的首要途径,清晰自信的介绍能提升面试官印象,对求职成功至关重要。 糟糕的自我介绍示例 求职者朱晓明虽表明自己善于交际、积极,23 年毕业且从事 java 开发,…...

Spring Boot Starter介绍
前言 大概10来年以前,当时springboot刚刚出现并没有流行,当时的Java开发者们开发Web应用主要是使用spring整合springmvc或者struts、iBatis、hibernate等开发框架来进行开发。项目里一般有许多xml文件配置,其中配置了很多项目中需要用到的Be…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...

量子计算中Loschmidt回声相位测量的创新方法
1. 量子计算中的Loschmidt回声相位测量方法概述Loschmidt回声是量子动力学中一个重要的概念,它描述了量子系统在时间反演演化后与初始状态的相似程度。在量子计算领域,精确测量Loschmidt回声的相位信息对于理解量子系统的非平衡态行为、计算能量本征值以…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

基于双T振荡器的正弦波LED调光电路设计与实践
1. 项目概述:用双T振荡器实现正弦波LED调光最近在捣鼓一些氛围灯项目,总感觉用单片机PWM做的呼吸灯效果有点“硬”,那种线性的明暗变化看久了难免审美疲劳。于是翻出以前模拟电路的老本行,琢磨着能不能用纯硬件的方式,…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...

03 - 变量与数据类型
03 - 变量与数据类型 变量是编程里最基础的概念,相当于你往电脑里存东西的"容器"。这章我们把变量的命名规则、Python 的几种基本数据类型都过一遍。 变量是什么 说白了,变量就是一个有名字的盒子。你往里面放个东西,以后想用这个…...

【DeepSeek漏洞扫描辅助实战指南】:20年安全专家亲授3大避坑法则与5步提效流程
更多请点击: https://intelliparadigm.com 第一章:DeepSeek漏洞扫描辅助的核心价值与适用边界 DeepSeek漏洞扫描辅助并非通用型渗透测试引擎,而是一个聚焦于大语言模型(LLM)应用层安全的轻量级分析工具。其核心价值在…...

Java网络编程基础分享
在学习 Java 的过程中,网络编程是非常重要的一环。无论是后端开发、分布式系统、即时通讯、文件传输,还是游戏服务、物联网设备,都离不开网络通信一、计算机网络基础1.1 什么是计算机网络把不同地理位置、具有独立功能的计算机,通…...