Python 爬虫 - Selenium 框架
Python 爬虫 - Selenium 框架
- 安装
- 安装 Selenium
- 安装 WebDriver
- 操作浏览器
- 打开浏览器
- 普通方式
- 加载配置方式
- Headless 方式
- 设置浏览器窗口
- 最大化显示
- 最小化显示
- 自定义大小
- 前进后退
- 前进
- 后退
- 元素定位
- 根据 id 定位
- 根据 name 定位
- 根据 class 定位
- 根据标签名定位
- 使用 CSS 定位
- 使用链接文本定位超链接
- 使用 xpath 定位
- 等待事件
- 显示等待
- 隐式等待
- 登录 163 邮箱
- 方式一
- 方式二
Selenium 是一个用于测试 Web 应用程序的框架,该框架测试直接在浏览器中运行,就像真实用户操作一样。它支持多种平台:
Windows、Linux、Mac,支持多种语言:
Python、Perl、PHP、C# 等,支持多种浏览器:
Chrome、IE、Firefox、Safari 等。
安装
安装 Selenium
pip install selenium
安装 WebDriver
主要浏览器 WebDriver 地址如下:
- Chrome: http://chromedriver.storage.googleapis.com/index.html
- Firefox: https://github.com/mozilla/geckodriver/releases
- IE: http://selenium-release.storage.googleapis.com/index.html
本文以Chrome 为例,本机为 Windows 系统,WebDriver 使用版本 78.0.3904.11,Chrome 浏览器版本为 78.0.3880.4 驱动程序下载好后解压,将 chromedriver.exe 放到 Python 安装目录下即可。
操作浏览器
打开浏览器
普通方式
以打开去 163 邮箱为例,使用 Chrome 浏览器
from selenium import webdriverbrowser = webdriver.Chrome()
browser.get('https://mail.163.com/')
使用Firefox 浏览器
from selenium import webdriverbrowser = webdriver.Firefox()
browser.get('https://mail.163.com/')
使用IE 浏览器
from selenium import webdriverbrowser = webdriver.Ie()
browser.get('https://mail.163.com/')
加载配置方式
以Chrome 为例,在 Chrome 浏览器地址栏输入 chrome://version/ 打开,如图所示:
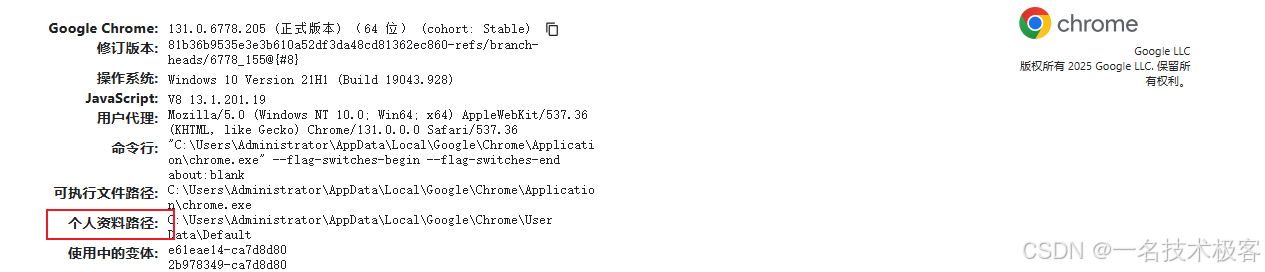
我们可以看到个人资料路径这一项,取到路径:C:\Users\Administrator\AppData\Local\Google\Chrome\User Data,取到 User Data 使用自己设置的配置,取到 Default 使用默认配置。看下示例:
from selenium import webdriveroption = webdriver.ChromeOptions()
# 自己的数据目录(需要将复制的路径中的 \ 替换成 / 或进行转义 \\)
# option.add_argument('--user-data-dir=C:/Users/admin/AppData/Local/Google/Chrome/User Data')
option.add_argument('--user-data-dir=C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\User Data')
browser = webdriver.Chrome(chrome_options=option)
browser.get('https://mail.163.com/')
# 关闭
browser.quit()
如果执行时报错没有打开指定页面,可先将浏览器关闭再执行。
Headless 方式
前两种方式都是有浏览器界面的方式,Headless 模式是 Chrome 浏览器的无界面形态,可以在不打开浏览器的前提下,使用所有 Chrome 支持的特性运行我们的程序。这种方式更加方便测试 Web 应用、获得网站的截图、做爬虫抓取信息等。看下示例:
from selenium import webdriverchrome_options = webdriver.ChromeOptions()
# 使用 headless 无界面浏览器模式
chrome_options.add_argument('--headless')
# 禁用 gpu 加速
chrome_options.add_argument('--disable-gpu')# 启动浏览器,获取网页源代码
browser = webdriver.Chrome(chrome_options=chrome_options)
url = 'https://mail.163.com/'
browser.get(url)
print('browser text = ',browser.page_source)
browser.quit()
设置浏览器窗口
最大化显示
browser.maximize_window()
最小化显示
browser.minimize_window()
自定义大小
# 宽 500,高 800
browser.set_window_size(500,800)
前进后退
前进
browser.forward()
后退
browser.back()
元素定位
当我们想要操作一个元素时,首先需要找到它,Selenium 提供了多种元素定位方式,我们以 Chrome 浏览器 Headless 方式为例。看下示例:
from selenium import webdriverchrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options)
url = 'https://xxx.xxx.com/'
browser.get(url)
data = browser.page_source
假设访问地址 https://xxx.xxx.com/,返回 data 为如下内容。
<html><body><form><input id="fid" name="fid" type="text" /><input id="firstName" name="fname" class="fname" type="text" /><input id="lastName" name="fname" class="fname" type="text" /><a href="index.html">index</a></form></body>
<html>
根据 id 定位
browser.find_element_by_id('fid')
根据 name 定位
# 返回第一个元素
browser.find_element_by_name('fname')
# 返回所有元素
browser.find_elements_by_name('fname')
根据 class 定位
# 返回第一个元素
browser.find_element_by_class_name('fname')
# 返回所有元素
browser.find_elements_by_class_name('fname')
根据标签名定位
# 返回第一个元素
browser.find_element_by_tag_name('input')
# 返回所有元素
browser.find_elements_by_tag_name('input')
使用 CSS 定位
# 返回第一个元素
browser.find_element_by_css_selector('.fname')
# 返回所有元素
browser.find_elements_by_css_selector('.fname')
使用链接文本定位超链接
# 返回第一个元素
browser.find_element_by_link_text('index')
# 返回所有元素
browser.find_elements_by_link_text('index')# 返回第一个元素
browser.find_element_by_partial_link_text('index')
# 返回所有元素
browser.find_elements_by_partial_link_text('index')
使用 xpath 定位
# 返回第一个元素
browser.find_elements_by_xpath("//input[@id='fid']")
# 返回所有元素
browser.find_elements_by_xpath("//input[@name='fname']")
等待事件
Web应用大多都使用 AJAX 技术进行加载,浏览器载入一个页面时,页面内的元素可能会在不同的时间载入,这会加大定位元素的困难程度,因为元素不在 DOM 里,会抛出 ElementNotVisibleException 异常,使用 Waits,我们就可以解决这个问题。
Selenium WebDriver 提供了显式和隐式两种Waits方式,显式的 Waits 会让 WebDriver 在更深一步的执行前等待一个确定的条件触发,隐式的 Waits 则会让 WebDriver 试图定位元素的时候对 DOM 进行指定次数的轮询。
显示等待
WebDriverWait 配合该类的 until() 和 until_not() 方法,就能够根据判断条件而进行灵活地等待了。它主要流程是:程序每隔 x 秒检查一下,如果条件成立了,则执行下一步操作,否则继续等待,直到超过设置的最长时间,然后抛出 TimeoutException 异常。先看一下方法:
__init__(driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None)
- driver: 传入
WebDriver实例; - timeout: 超时时间,单位为秒;
- poll_frequency: 调用
until 或 until_not中方法的间隔时间,默认是 0.5 秒; - ignored_exceptions: 忽略的异常,如果在调用
until 或 until_not的过程中抛出这个元组中的异常,则不中断代码,继续等待,如果抛出的是这个元组外的异常,则中断代码,抛出异常。默认只有NoSuchElementException。
until(method, message='')
- method: 在等待期间,每隔一段时间(
init中的poll_frequency)调用这个方法,直到返回值不是False; - message: 如果超时,抛出
TimeoutException,将message传入异常。
until_not(method, message='')
until 方法是当某条件成立则继续执行,until_not 方法与之相反,它是当某条件不成立则继续执行,参数与 until 方法相同。
以去163 邮箱为例,看一下示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://mail.163.com/')
try:超时时间为 5 秒data = WebDriverWait(browser,5).until(EC.presence_of_element_located((By.ID,'lbNormal')))print(data)
finally:browser.quit()
示例中代码会等待 5 秒,如果 5 秒内找到元素则立即返回,否则会抛出 TimeoutException 异常,WebDriverWait 默认每 0.5 秒调用一下 ExpectedCondition 直到它返回成功为止。
隐式等待
当我们要找一个或者一些不能立即可用的元素的时候,隐式 Waits 会告诉 WebDriver 轮询 DOM 指定的次数,默认设置是 0 次,一旦设定,WebDriver 对象实例的整个生命周期的隐式调用也就设定好了。看一下方法:
implicitly_wait(time_to_wait)
隐式等待是设置了一个最长等待时间 time_to_wait,该时间是针对全局设置的,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后执行下一步。看到了这里,我们会感觉有点像 time.sleep(),它们的区别是:time.sleep() 必须等待指定时间后才能继续执行, time_to_wait 是在指定的时间范围加载完成即执行,time_to_wait 比 time.sleep() 更灵活一些。
看下示例:
from selenium import webdriverbrowser = webdriver.Chrome()
browser.implicitly_wait(5)
browser.get('https://mail.163.com/')
data = browser.find_element_by_id('lbNormal')
print(data)
browser.quit()
登录 163 邮箱
最后,我们用Selenium来做个登录 163 邮箱的实战例子。
方式一
我们通过地址 https://email2.163.com/ 登录,如图所示:
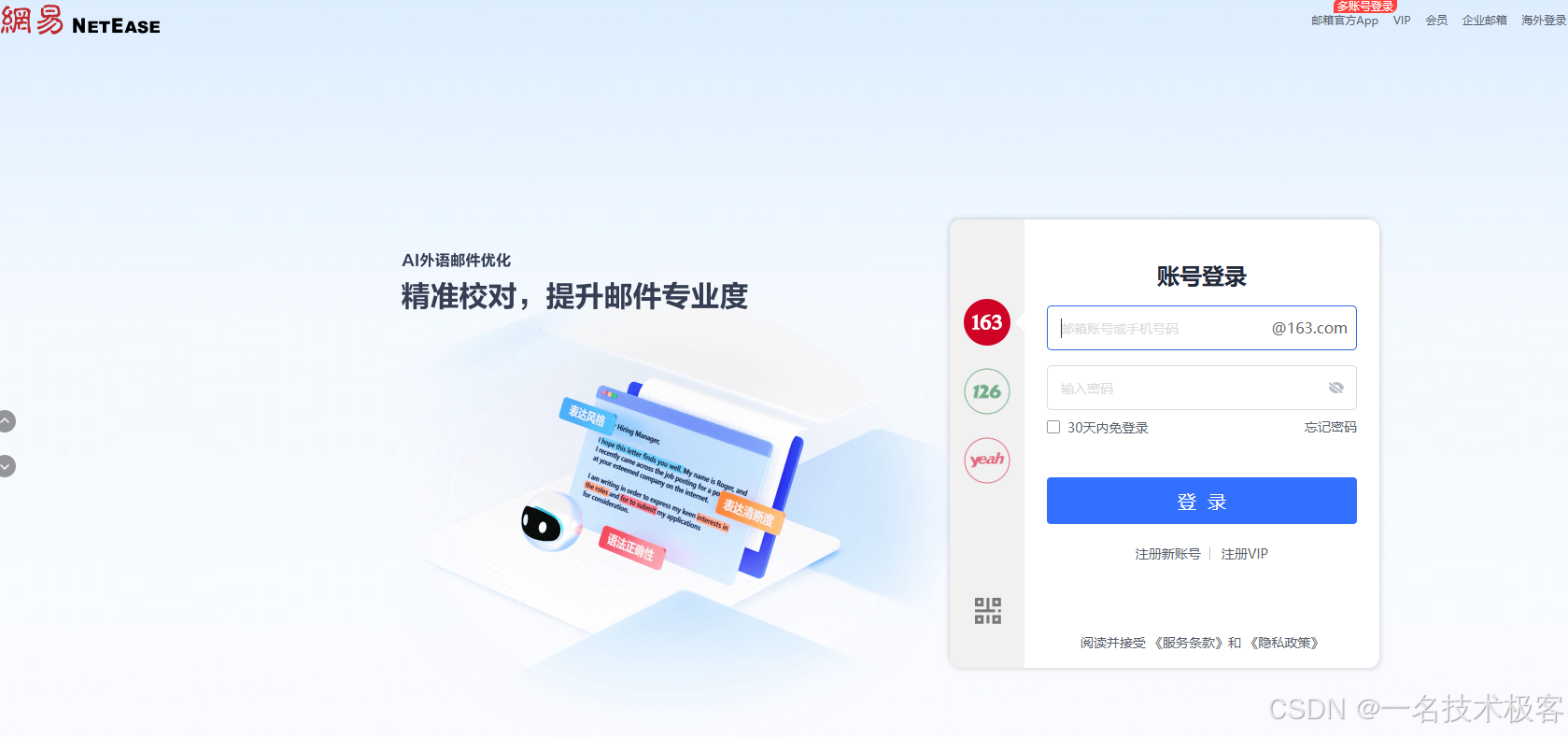
从图中我们发现直接进了 163 邮箱用户名、密码登录页,我们直接输入用户名、密码,点击登录按钮即可。示例如下:
from selenium import webdriverbrowser = webdriver.Chrome()
browser.implicitly_wait(2)
browser.get('https://email2.163.com/')
browser.switch_to.frame(browser.find_element_by_xpath('//iframe[starts-with(@id,"x-URS")]'))
# 自己的用户名
browser.find_element_by_xpath('//input[@name="email"]').send_keys('xxx')
# 自己的密码
browser.find_element_by_xpath('//input[@name="password"]').send_keys('xxx')
browser.find_element_by_xpath('//*[@id="dologin"]').click()
print(browser.page_source)
# 关闭
browser.quit()
方式二
第二种方式我们使用地址 https://mail.163.com/,先手动打开看一下:

从图中我们会发现,登录页面首先展示的是二维码登录方式,因此我们需要先点击上图红框圈住的位置切换到用户名、密码的登录方式,如图所示:
此时,我们先输入用户名、密码,然后点击登录按钮即可。详细代码见如下 GitHub 仓库。
使用Selenium 登录 163 邮箱示例代码
相关文章:
Python 爬虫 - Selenium 框架
Python 爬虫 - Selenium 框架 安装安装 Selenium安装 WebDriver 操作浏览器打开浏览器普通方式加载配置方式Headless 方式 设置浏览器窗口最大化显示最小化显示自定义大小 前进后退前进后退 元素定位根据 id 定位根据 name 定位根据 class 定位根据标签名定位使用 CSS 定位使用…...

mysql的having语句
MySQL的HAVING语句用于在GROUP BY子句对数据进行分组后,过滤满足特定条件的组。与WHERE子句不同,HAVING子句可以在过滤条件中使用聚合函数,而WHERE子句则不能。通常,HAVING子句与GROUP BY子句一起使用,以实现对分组数据…...

华为数据之道-读书笔记
内容简介 关键字 数字化生产 已经成为普遍的商业模式,其本质是以数据为处理对象,以ICT平台为生产工具,以软件为载体,以服务为目的的生产过程。 信息与通信技术平台(Information and Communication Technology Platf…...
CDN、源站与边缘网络
什么是“源站” 源服务器 源服务器的目的是处理和响应来自互联网客户端的传入请求。源服务器的概念通常与边缘服务器或缓存服务器的概念结合使用。源服务器的核心是一台运行一个或多个程序的计算机,这些程序旨在侦听和处理传入的客户端请求。源服务器可以承担为网…...
工业相机 SDK 二次开发-Sherlock插件
本文介绍了 sherlock 连接相机时的插件使用。通过本套插件可连接海康的工业相机。 一.环境配置 1. 拷贝动态库 在用户安装 MVS 目录下按照如下路径 Development\ThirdPartyPlatformAdapter 找到目 录为 DalsaSherlock 的文件夹,根据 Sherlock 版本找到…...
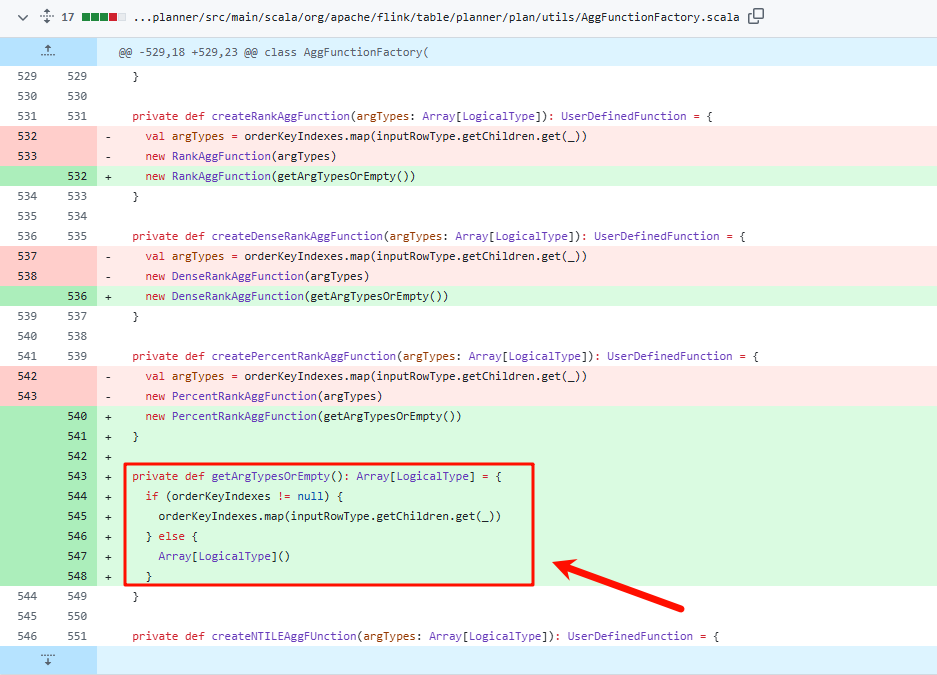
FlinkSql使用中rank/dense_rank函数报错空指针
问题描述 在flink1.16(甚至以前的版本)中,使用rank()或者dense_rank()进行排序时,某些场景会导致报错空指针NPE(NullPointerError) 报错内容如下 该报错没有行号/错误位置,无法排查 现状 目前已经确认为bug,根据github上的PR日…...
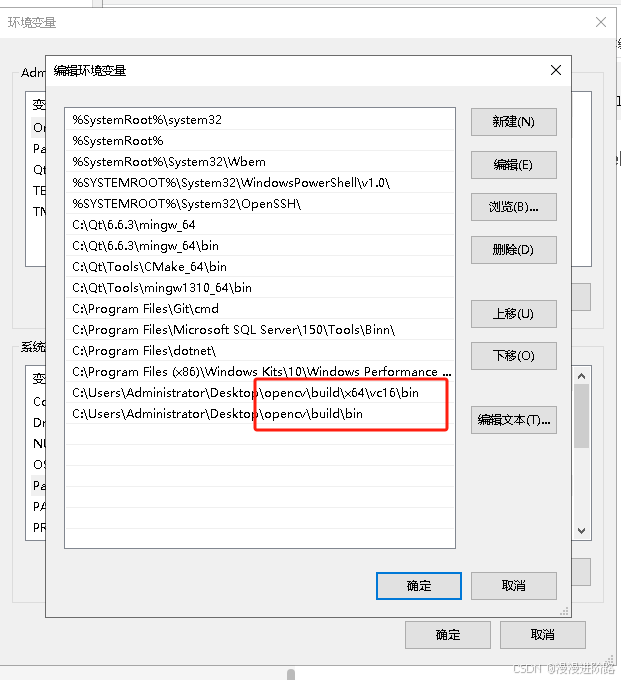
VS C++ 配置OPENCV环境
VS C 配置OPENCV环境 1.下载opencv2.安装环境3.opencv环境4.VS配置opencv环境5.EXE执行文件路径的环境lib和dll需要根据是debug还是release环境来区分使用哪个 6.Windows环境 1.下载opencv 链接: link 2.安装环境 双击运行即可 3.opencv环境 include文件路径:opencv\build\…...
【SpringSecurity】基本开发流程
文章目录 概要整体架构流程实现流程1、编写各种Handler2 、AccessToken处理器3、定义AuthenticationFilter 继承 OncePerRequestFilter (OncePerRequestFilter是Spring提供的一个过滤器基类,它确保了在一次完整的HTTP请求中,无论请求经过多少…...
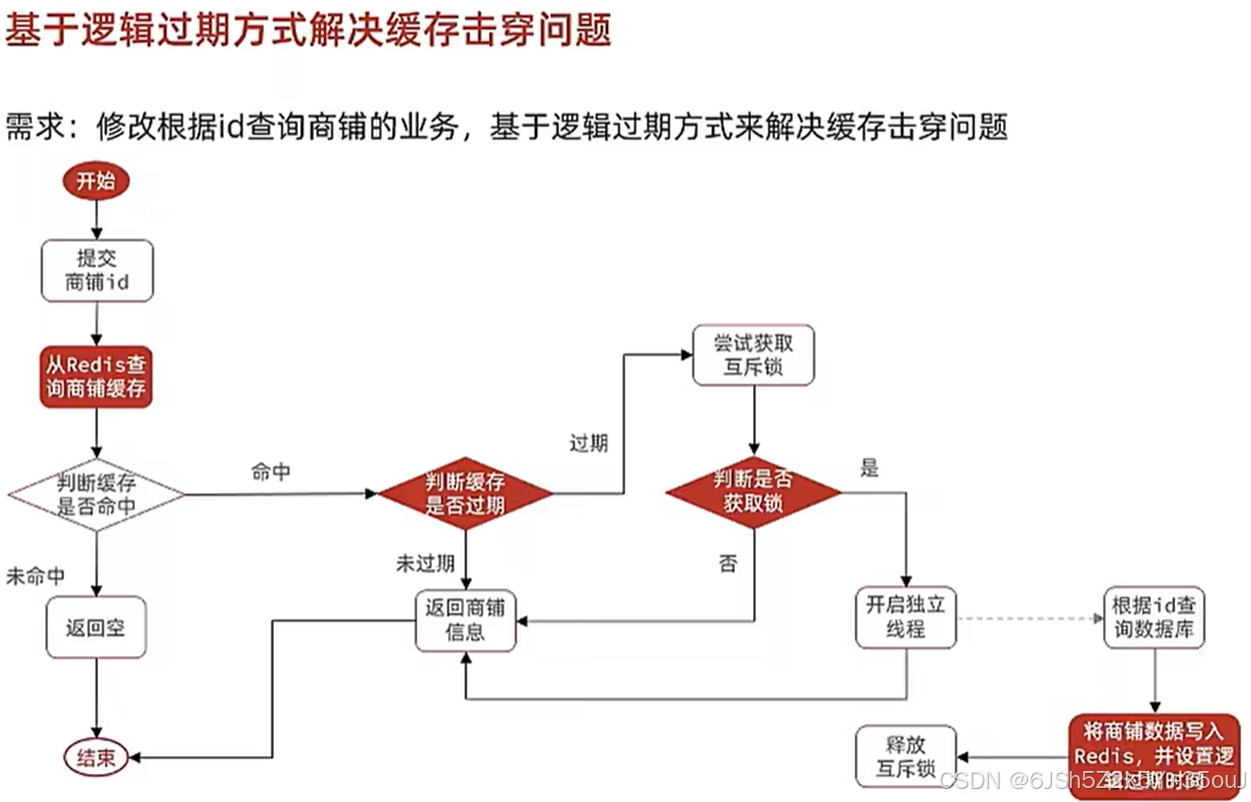
Redis实战(黑马点评)——关于缓存(缓存更新策略、缓存穿透、缓存雪崩、缓存击穿、Redis工具)
redis实现查询缓存的业务逻辑 service层实现 Overridepublic Result queryById(Long id) {String key CACHE_SHOP_KEY id;// 现查询redis内有没有数据String shopJson (String) redisTemplate.opsForValue().get(key);if(StrUtil.isNotBlank(shopJson)){ // 如果redis的数…...

ChatGPT从数据分析到内容写作建议相关的46个提示词分享!
在当今快节奏的学术环境中,研究人员面临着海量的信息和复杂的研究任务。幸运的是,随着人工智能技术的发展,像ChatGPT这样的先进工具为科研人员提供了强大的支持。今天就让我们一起探索如何利用ChatGPT提升研究效率进一步优化研究流程。 ChatG…...

在 Windows 11 中设置 WSL2 Ubuntu 的 `networkingMode=mirrored` 详细教程
在 Windows 11 中设置 WSL2 Ubuntu 的 networkingModemirrored 详细教程 引言环境要求配置 .wslconfig 文件重启 WSL2验证镜像网络模式解决常见问题其他注意事项结论 引言 在 Windows 11 中使用 WSL2(Windows Subsystem for Linux 2)时,默认…...
万字长文总结前端开发知识---JavaScriptVue3Axios
JavaScript学习目录 一、JavaScript1. 引入方式1.1 内部脚本 (Inline Script)1.2 外部脚本 (External Script) 2. 基础语法2.1 声明变量2.2 声明常量2.3 输出信息 3. 数据类型3.1 基本数据类型3.2 模板字符串 4. 函数4.1 具名函数 (Named Function)4.2 匿名函数 (Anonymous Fun…...

怎么样把pdf转成图片模式(不能复制文字)
贵但好用的wps, 转换——转为图片型pdf —————————————————————————————————————————— 转换前: 转换后: 肉眼可见,模糊了,且不能复制。 其他免费办法,参考&…...
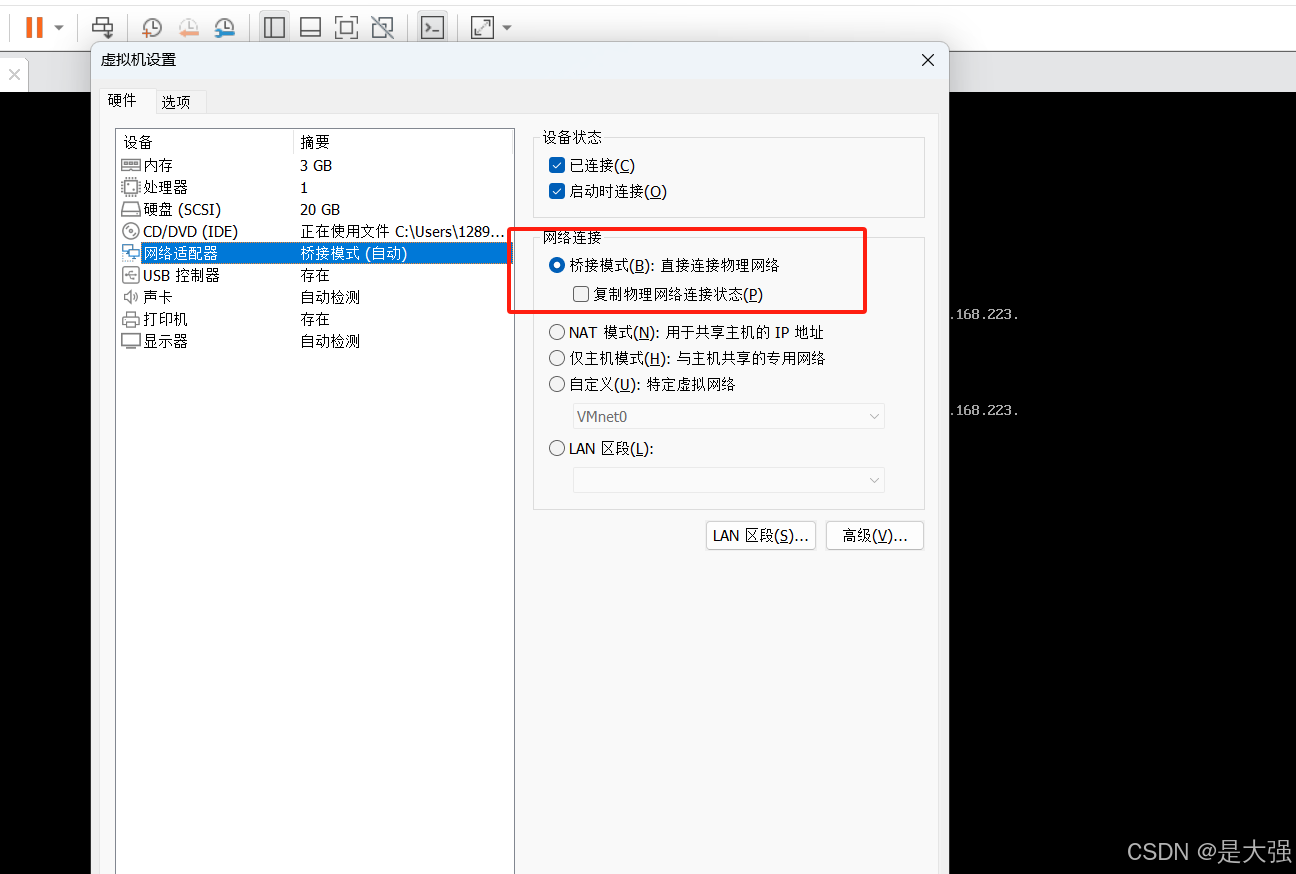
本地centos网络配置
1、路径 2、配置 另外还需要...

kotlin内联函数——runCatching
1.runCatching作用 代替try{}catch{}异常处理,用于捕获异常。 2.runCatching函数介绍 参数:上下文引用对象为参数返回值:lamda表达式结果 调用runCatching函数,如果调用成功则返回其封装的结果,并可回调onSuccess函…...

Python3 正则表达式:文本处理的魔法工具
Python3 正则表达式:文本处理的魔法工具 内容简介 本系列文章是为 Python3 学习者精心设计的一套全面、实用的学习指南,旨在帮助读者从基础入门到项目实战,全面提升编程能力。文章结构由 5 个版块组成,内容层层递进,逻…...
《DiffIR:用于图像修复的高效扩散模型》学习笔记
paper:2303.09472 GitHub:GitHub - Zj-BinXia/DiffIR: This project is the official implementation of Diffir: Efficient diffusion model for image restoration, ICCV2023 目录 摘要 1、介绍 2、相关工作 2.1 图像恢复(Image Rest…...
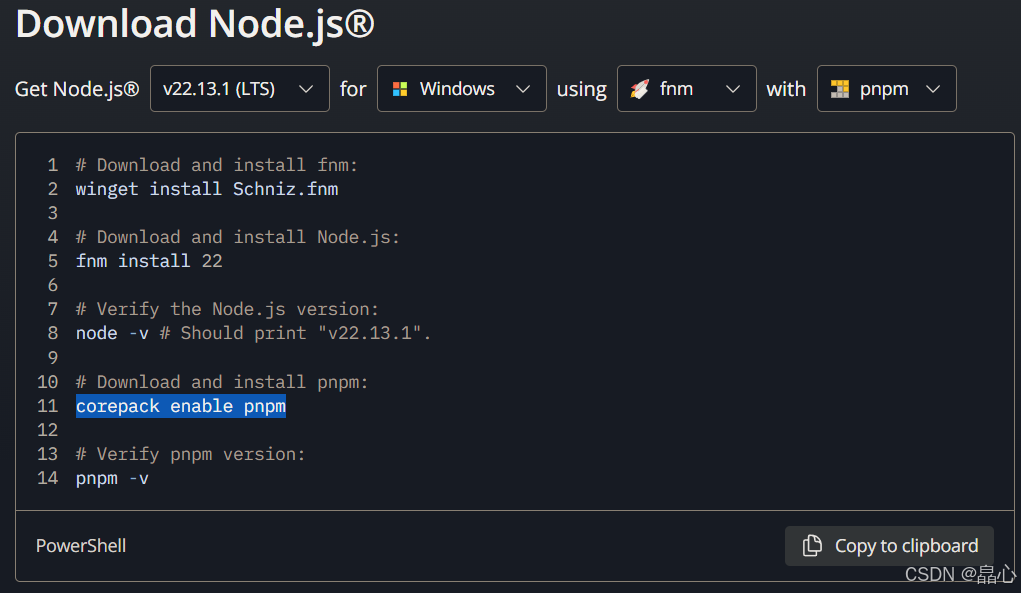
windows平台通过命令行安装前端开发环境
访问node.js官网 访问node.js官网https://nodejs.org/en/download/,可以看到类似画面: 可以获取以下命令 # Download and install fnm: winget install Schniz.fnm # Download and install Node.js: fnm install 22 # Verify the Node.js version: no…...
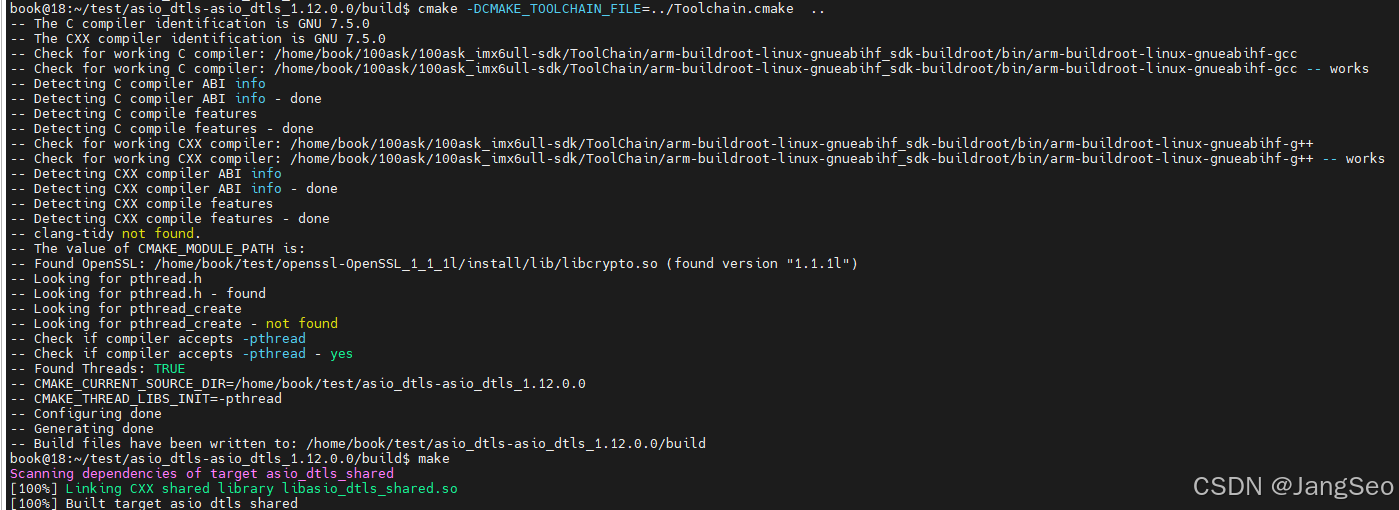
记交叉编译asio_dtls过程
虽然编译成功了,但是还是有一些不妥的地方,参考一下就行了。 比如库的版本选择就有待商榷,我这里不是按照项目作者的要求严格用对应的版本编译的,这里也可以注意一下。 编译依赖库asio 下载地址, 更正一下,我其实用…...
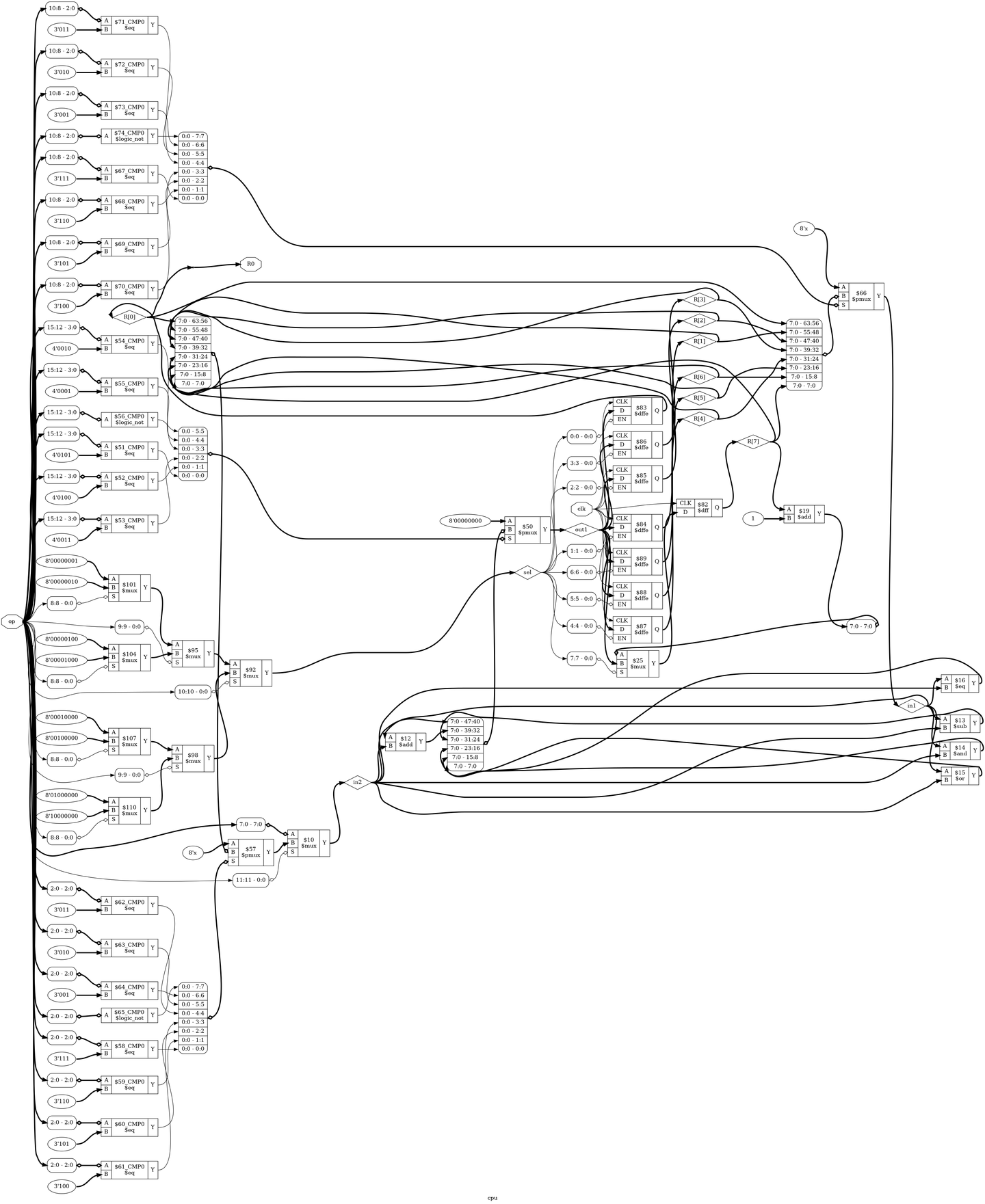
学习yosys(一款开源综合器)
安装 sudo apt-get install yosys #ubuntu22.04仓库里面是yosys-0.9 sudo install xdot 创建脚本show_rtl.ys read_verilog cpu.v hierarchy -top cpu proc; opt; fsm; opt; memory; opt; show -prefix cpu 调用脚本 yosys show_rtl.ys verilog代码 module cpu(input c…...

AppleRa1n开源工具:iOS 15-16激活锁绕过完整解决方案
AppleRa1n开源工具:iOS 15-16激活锁绕过完整解决方案 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 激活锁(Activation Lock)作为iOS设备的重要安全机制࿰…...
前置环境)
Shell脚本一键部署Kubenetes(k8s)前置环境
1. 服务器环境[rootlocalhost~]# cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core)2. 脚本内容#!/bin/bash#本文针对CentOS7系统#1)关闭交换分区swap disable_swap(){echo -e "\e[32m1)开始关闭swap\e[0m"#备份fstabsudo cp /e…...

OpenClaw配置备份指南:Qwen3-32B镜像环境迁移无忧方案
OpenClaw配置备份指南:Qwen3-32B镜像环境迁移无忧方案 1. 为什么需要备份OpenClaw环境 上周我的主力开发机RTX4090D突然显卡故障送修,导致所有OpenClaw自动化流程中断。最痛苦的不是硬件问题,而是重新配置Qwen3-32B镜像环境时,发…...

memory-lancedb-pro混合检索揭秘:向量搜索+BM25如何提升AI记忆准确率300%
memory-lancedb-pro混合检索揭秘:向量搜索BM25如何提升AI记忆准确率300% 【免费下载链接】memory-lancedb-pro Enhanced LanceDB memory plugin for OpenClaw — Hybrid Retrieval (Vector BM25), Cross-Encoder Rerank, Multi-Scope Isolation, Management CLI …...

AI 培训报名:主流机构专业度对比分析
引言 随着人工智能技术的快速发展,AI 培训市场也日益火爆。无论是企业还是个人,都希望通过专业的培训来提升对 AI 技术的应用能力。然而,当前 AI 培训市场鱼龙混杂,机构众多,质量参差不齐。企业和个人在选择 AI 培训机…...

Java八股文实战:从cv_resnet101模型服务理解RPC与序列化
Java八股文实战:从cv_resnet101模型服务理解RPC与序列化 你是不是也遇到过这种情况?面试时被问到“RPC和HTTP有什么区别?”、“序列化协议怎么选?”,脑子里全是书本上的概念,什么“远程过程调用”、“轻量…...

从RS232到112G SerDes:高速串行接口的‘逆袭’简史与FPGA工程师的生存指南
从RS232到112G SerDes:高速串行接口的技术革命与工程师转型指南 在数字通信领域,接口技术的演进犹如一场静默的革命。二十年前,工程师们还在为并行总线的布线复杂度和时钟偏移问题头疼不已;而今天,单通道112G PAM4 Ser…...

Qwen-Image-2512-SDNQ使用心得:如何写出更有效的中文Prompt获得理想图片
Qwen-Image-2512-SDNQ使用心得:如何写出更有效的中文Prompt获得理想图片 1. 为什么中文Prompt需要特别优化? 在AI绘画领域,Prompt(提示词)的质量直接影响生成结果。对于中文用户而言,使用母语描述想象中的…...
)
Google Test进阶玩法:用测试夹具重构你的C++项目(CLion实战篇)
Google Test进阶实战:用测试夹具重构复杂C项目的工程化实践 当你的C项目从几百行扩展到几万行代码时,那些曾经简单的单元测试开始变得力不从心。测试用例之间出现隐蔽的状态依赖,setup代码重复率飙升,而每次运行测试套件的时间越来…...

FastAPI分块上传存储:对象存储集成完整指南
FastAPI分块上传存储:对象存储集成完整指南 【免费下载链接】fastapi FastAPI framework, high performance, easy to learn, fast to code, ready for production 项目地址: https://gitcode.com/GitHub_Trending/fa/fastapi 想要在FastAPI应用中实现大文件…...