华为数据之道-读书笔记
内容简介



关键字
数字化生产
已经成为普遍的商业模式,其本质是以数据为处理对象,以ICT平台为生产工具,以软件为载体,以服务为目的的生产过程。
信息与通信技术平台(Information and Communication Technology Platform,ICT)


数据孤岛
IT系统中的数据语言不统一,不同I系统之间的数据不贯通,同样的数据需要在不同TT系统中重复录入,甚至不同I系统中的同一个数据不一致等。这些问题限制了运营效率的提升和效益的改进,华为迫切需要数字化转型来改变这种状况。
数字化转型(怎么做)

ToB / ToC



数据入湖
数据入湖 是指将数据从各种数据源(如数据库、文件系统、实时流数据等)导入到 数据湖 中的过程。数据湖是一个存储系统,能够以原始格式保存海量结构化、半结构化和非结构化数据,为后续的数据分析、机器学习和数据驱动决策提供支持。



数据消费
数据消费 是指在数据生态系统中,用户或系统通过对数据的访问、分析和处理,从而获取有价值的信息,用于支持决策、优化业务流程或推动创新。它是数据生命周期的重要阶段,通常紧接在数据存储(如数据湖或数据仓库)之后。
数据消费的核心含义
- 数据消费的本质是将存储在数据平台中的原始数据转化为对业务有意义的洞察和价值。
- 数据消费的形式可以多种多样,比如生成报表、构建机器学习模型、驱动实时决策等。
数据消费的常见形式
-
报表与可视化:
- 数据被消费为可视化的报表和图表,用于业务监控和决策支持。
- 工具:Power BI、Tableau、FineBI 等。
- 例子:通过销售数据生成月度销售报表。
-
业务分析与洞察:
- 利用统计学或分析工具,对数据进行深度挖掘。
- 工具:Excel、Python(Pandas、Matplotlib)、R 等。
- 例子:分析用户行为数据,发现客户流失的原因。
-
实时数据处理:
- 消费实时流数据,支持快速响应和实时决策。
- 工具:Kafka、Spark Streaming、Flink 等。
- 例子:实时监控物流运输状态。
-
数据驱动的自动化:
- 数据直接被系统或服务消费,用于触发自动化流程。
- 例子:银行的风控系统根据用户交易数据自动判定风险。
-
机器学习与AI模型:
- 数据作为模型训练的输入,驱动机器学习或人工智能应用。
- 工具:TensorFlow、PyTorch、Scikit-learn 等。
- 例子:根据历史数据训练模型预测未来销售趋势。
-
API 数据消费:
- 数据通过 API 提供给应用程序消费。
- 例子:电商平台通过 API 查询库存数据并更新页面。
数据消费的技术架构
数据消费通常依赖于以下技术架构:
-
数据湖与数据仓库:
- 数据消费的基础是数据存储。数据湖存储原始数据,数据仓库存储加工后的结构化数据。
- 工具:Hadoop、Amazon S3、Snowflake 等。
-
数据集成与查询:
- 数据通过 ETL 或 ELT 流程集成,并通过查询工具消费。
- 工具:Presto、Hive、BigQuery 等。
-
数据可视化平台:
- 将复杂数据呈现为易于理解的图表或仪表板。
- 工具:Tableau、Power BI、Grafana 等。
-
实时流处理:
- 实时数据的消费需要强大的流处理能力。
- 工具:Kafka、Flink、Spark Streaming 等。
数据消费的挑战
- 数据质量:
- 如果数据不准确、不完整或不及时,会直接影响消费结果的可靠性。
- 访问性能:
- 当数据量过大时,如何高效查询和处理数据是一个难题。
- 安全与隐私:
- 数据消费涉及敏感数据时,如何确保合规性和安全性。
- 数据孤岛:
- 数据分散在多个系统中,导致消费过程中难以整合。
数据底座
数据底座 是一个支持企业数字化转型的核心技术平台,用来统一管理、存储和处理企业所有的数据资源。它是企业实现数据驱动决策、智能化应用的基础设施,类似于建筑物的地基,支撑着上层的各种数据应用。
数据底座的主要组成部分
-
数据存储:
- 数据底座需要存储结构化、半结构化和非结构化数据,通常包括以下系统:
- 数据湖:存储原始的、海量的多种数据类型。
- 数据仓库:存储经过处理和结构化的数据,用于高效分析。
- 云存储:灵活支持弹性存储(如 AWS S3、阿里云 OSS)。
- 数据底座需要存储结构化、半结构化和非结构化数据,通常包括以下系统:
-
数据集成:
- 将企业的多种数据源(如数据库、日志系统、实时流数据)统一整合到数据底座。
- 工具:ETL(提取、转换、加载)工具(如 Apache NiFi、Informatica)。
-
数据治理:
- 确保数据的质量、规范性和安全性。
- 包括数据清洗、数据标准化、元数据管理、数据权限控制。
-
数据分析与服务:
- 支持多种数据分析需求,包括统计分析、机器学习、实时处理等。
- 提供数据 API 和服务,支持上层应用调用数据。
-
数据安全:
- 实现数据加密、访问控制、日志记录,确保数据合规性和安全性。
-
开发与运维支持:
- 为数据科学家、分析师和开发者提供统一的平台工具(如 Jupyter Notebook、BI 工具)。
ETL(提取、转换、加载)
ETL 是指 提取(Extract)、转换(Transform)、加载(Load),是一种将数据从一个或多个来源提取出来,经过转换处理后加载到目标系统(如数据仓库、数据湖)的数据集成过程。ETL 是数据处理的重要环节,广泛用于数据仓库建设、数据分析和业务报表生成。
ETL 的三个主要步骤
-
提取(Extract):
- 从多个数据源中获取原始数据,包括结构化数据(如数据库表)、半结构化数据(如 JSON、XML)和非结构化数据(如文本、日志)。
- 数据源示例:
- 数据库(MySQL、Oracle、PostgreSQL)
- 文件系统(CSV、Excel)
- API 或实时流(如 Kafka)
- 目标是尽可能完整地提取数据,同时避免影响源系统性能。
-
转换(Transform):
- 对提取的原始数据进行清洗、规范化和处理,以满足目标系统的要求。通常包括以下操作:
- 数据清洗:处理空值、重复值、异常值。
- 格式转换:统一日期格式、单位等。
- 数据聚合:计算总数、平均值等。
- 维度处理:将数据映射到维度表或事实表。
- 业务规则应用:根据业务逻辑衍生新字段或分类数据。
- 对提取的原始数据进行清洗、规范化和处理,以满足目标系统的要求。通常包括以下操作:
-
加载(Load):
- 将转换后的数据加载到目标系统中,如数据仓库(如 Snowflake、Redshift)或数据湖(如 Hadoop、S3)。
- 加载方式:
- 全量加载:每次将所有数据重新加载到目标系统。
- 增量加载:只加载新增或更新的数据。
- 确保数据加载的完整性和准确性。
IoT数据
IoT数据(Internet of Things 数据)是指由物联网设备生成、收集和传输的数据。这些设备通过网络互联,可以实时感知、监测和传输信息,从而为数据分析和智能化应用提供支持。
IoT 数据的来源
IoT 数据主要来源于各种连接到互联网的设备和传感器,这些设备可以分为以下几类:
-
工业设备:
- 工厂中的机器、机器人、设备传感器。
- 例如:温度、压力、振动传感器。
-
智能家居设备:
- 智能音箱、智能门锁、智能灯泡、智能电表。
- 例如:记录室内温湿度、用电量、用户行为等。
-
可穿戴设备:
- 智能手表、健身追踪器。
- 例如:记录心率、步数、睡眠数据。
-
交通工具:
- 车辆中的 GPS、车载诊断系统(OBD)。
- 例如:车辆位置、速度、燃油使用情况。
-
环境监测设备:
- 气象站、空气质量监测仪。
- 例如:二氧化碳浓度、噪声水平、降雨量。
-
物流与零售:
- 包括物流追踪器、智能货架、RFID 标签。
- 例如:商品库存、运输位置、存储条件。
IoT 数据的特点
-
实时性:
- IoT 数据通常以流数据的形式实时产生,适合用于实时监控和快速响应。
- 例如:传感器每秒传输一次温度数据。
-
多样性:
- IoT 数据可以是结构化、半结构化或非结构化的,包含数值、文本、图片、视频等。
- 例如:结构化的电量数据,非结构化的设备日志。
-
海量性:
- 由于设备数量庞大,数据生成频率高,IoT 数据通常呈现出“数据爆炸”的特点。
- 例如:一台传感器每天产生上 GB 的数据。
-
分布式来源:
- 数据来自分布在不同地点的设备,具有高度分散性。
- 例如:不同城市的环境监测设备生成的数据。
-
时序性:
- 数据通常是以时间序列形式产生,带有时间戳,用于分析变化趋势。
- 例如:每天记录温度变化曲线。
IoT 数据的存储与处理
由于 IoT 数据量大、种类多且实时性强,对数据存储和处理系统的要求较高。
存储方式
-
云存储:
- 使用云平台(如 AWS、Azure、阿里云)存储数据,具有弹性扩展性。
- 例如:将 IoT 数据存储在 AWS IoT Core。
-
边缘计算:
- 在设备附近(边缘)处理和存储部分数据,降低传输延迟。
- 例如:工业设备实时分析振动数据,异常时才上传到云。
-
数据湖与数据仓库:
- 数据湖(如 Hadoop、AWS S3):存储原始数据。
- 数据仓库(如 Snowflake、Redshift):存储结构化数据用于分析。
处理方式
-
实时数据处理:
- 使用流处理框架(如 Apache Kafka、Flink)分析实时数据。
- 例如:监控车辆速度,超速时发出警报。
-
批量数据分析:
- 将 IoT 数据定期导入数据仓库,使用大数据工具(如 Spark)进行批处理。
- 例如:分析一周内设备的运行状态。
-
机器学习与AI:
- 使用 AI 模型对 IoT 数据进行预测和异常检测。
- 例如:预测工业设备的故障。
Mapping
Mapping 在开发中通常指的是数据或信息之间的映射关系,即将一种数据结构、字段或实体转换成另一种对应的数据结构或字段,以便在不同系统或模块之间进行数据的传递或处理。Mapping 是软件开发中常见的概念,广泛应用于数据传输、转换、模型映射等场景。
Mapping的常见场景





Mapping 的作用
-
数据转换:
- 将数据从一种格式或结构转换为另一种,以满足不同模块或系统的需求。
-
系统集成:
- 在多个系统之间共享数据时,通过映射来解决字段或数据结构不一致的问题。
-
降低耦合性:
- 使用映射层可以隔离不同系统或模块的实现细节,降低代码的耦合性。
-
提升代码可维护性:
- 通过统一的映射规则或工具,简化数据转换的逻辑,方便后续维护。
常见的 Mapping 技术与工具
-
编程语言中的工具:
- Java:
ModelMapper、MapStruct。 - Python:
pydantic、Marshmallow。 - JavaScript:手动映射(如使用
map()方法)。
- Java:
-
数据库工具:
- Hibernate、JPA(ORM 工具)。
- 数据库视图用于映射复杂字段。
-
ETL 工具:
- Apache Nifi、Talend、Informatica,用于跨系统的大规模数据映射和转换。
-
配置文件与规则:
- JSON、YAML 配置文件中定义的映射规则。
- 自定义映射规则文件。
逻辑实体

物理表

虚拟表

视图

数据模型
数据模型 是一种对现实世界数据及其相互关系的抽象表达,用来描述数据的结构、操作和约束。它是数据库设计、数据处理和数据管理的基础工具,帮助我们理解和组织复杂的数据。



Data Lab
Data Lab 是指企业数据管理和分析中的一个核心功能模块或场景,通常代表了一个集中的数据实验室(Data Laboratory)或分析平台。它的主要目标是为用户提供灵活的探索、分析和试验数据的环境,帮助实现业务洞察和智能决策。

数据治理
对企业的数据管理和利用进行评估、指导和监督,通过提供不断创新的数据服务,为企业创造价值
数据源
指业务上首次正式发布某项数据的应用系统,并经过数据管理专业组织认证,作为企业范围内唯一数据源头被周边系统调用。
数据Owner
公司数据 Owner 是公司数据战略的制定者、数据文化的营造者、数据资产的所有者和数据
争议的裁决者,拥有公司数据日常管理的最高决策权。
数据 Owner 的职责包括:
① 负责数据管理体系建设。
② 负责信息架构建设。
③ 负责数据质量管理。
④ 负责数据底座和数据服务建设。
⑤ 负责数据争议裁决。
数据Owner要负责所辖领域的信息架构建设和维护,负责保障所辖领域的数据质量,承接公司各个部门对本领域数据的需求,并有责任建立数据问题回溯和奖惩机制,对所辖领域的数据问题及争议进行裁决,公司有权对不遵从信息架构或存在严重数据质量问题的责任人进行问责。
主数据
参与业务事件的主体或资源,是具有高业务价值的、跨流程和跨系统重复使用的数据。主数据与基础数据有一定的相似性, 都是在业务事件发生之前预先定义;但又与基础数据不同,主数据的取值不受限于预先定义的数据范围,而且主数据的记录的增加和减少一般不会影响流程和IT系统的变化
元数据
定义数据的数据,是有关一个企业所使用的物理数据、技术和业务流程、数据规则和约束以及数据的物理与逻辑结构的信息
元数据是描述数据的数据,用于打破业务和IT之间的语言障碍,帮助业务更好地理解数据。
元数据通常分为业务、技术和操作三类。
其中:
业务元数据:用户访问数据时了解业务含义的途径,包括资产目录、Owner、数据密级
等。
技术元数据:实施人员开发系统时使用的数据,包括物理模型的表与字段、ETL 规则、
集成关系等。
操作元数据:数据处理日志及运营情况数据,包括调度频度、访问记录等。
数据导航/数据地图DMAP


汇聚/钻取/切片


数据粒度

SLA

第一部分

第一章


数字化转型目标

数字化转型蓝图

数据工作框架

数据体系建设的整体框架

第二章

数据治理体系框架

数据管理总纲




第三章


数据分类管理框架

数据分类


基础数据治理
基础数据是用于分类或目录整编的数据,通常有一个有限的允许、可选值范围。也就是常见的基础码值。如性别、币种、业务单类型等。
基础数据治理无论对优化业务流程还是数据分析都有较高的价值。一方面是增强与外部系统、提高业务敏捷度;另一方面,减少mapping的开发,支持业务端到端分析,增加业务确定性。码值管理最好通过系统来管控,目前的工作里也遇到这类问题,因为老系统之前较为混乱,新建系统建了一套全新的,但当时相关标准管理系统不完善,且在新老mapping上并不完善,导致数据部门很难开展工作。

基础数据治理的价值

基础数据治理的收益

基础数据治理的框架

主数据治理
主数据具有高业务价值的、可以在企业内跨流程跨系统被重复使用的数据,具有唯一、准确、权威的数据源。通常是业务事件的参与方,参与方在业务中是一个很重要的概念。常见的主数据有机构主数据、员工主数据、产品主数据、财务主数据等。
华为的主数据范围包含客户、产品、供应商、组织和人员。每个主数据都有相应的架构、流程及管控组织来负责管理。目前的工作里也各自新建域来管理相应的主数据,但缺少良好的流程和管控,产品功能存在但实际转起来时没有那么顺畅,需要不断打磨。最后的目的是保证数出一孔,提高数据质量、支持交易流打通等。


主数据管理策略

主数据管理框架

客户主数据
客户数据是企业最重要的主数据之一,几乎贯穿所有业务经营活动。客户数据在全流程中的及时性、准确性、完整性、一致性、有效性、唯一性是业务高效运作、经营可控的重要保障。随着业务发展,华为客户数量迅速增长,客户数据种类复杂多样,因此要构建客户数据管理和服务化能力,以满足经营分析、交易打通、内外部遵从、客户价值挖掘等核心要求,支撑面向多BG的战略转变。
这里的“多BG”指的是“多业务群”(Business Groups)的意思。华为作为一个全球化的大型企业,通常会根据不同的产品线、市场需求、技术方向等,划分为多个业务群(BGs)。这些业务群可能包括消费业务、企业业务、运营商业务等。每个BG都有其独立的目标、运作模式和管理需求。因此,“支撑面向多BG的战略转变”意味着要建立一个能够支持多个业务群战略需求的系统或平台,以确保客户数据能够在各个业务群之间高效流通和利用。
事务数据治理
事务数据用于记录企业经营过程中产生的业务事件,其实质是主数据之间活动产生的数据。如一条xx订单数据。

事务数据会调用主数据和基础数据,当然也有自身的数据。如一张订单上,一般有客户、产品、机构主数据,币种、订单类型等基础数据,也有订单金额、订单号等事务数据。因此,事务数据治理的重点是管理好事务数据对主数据和基础数据的调用,以及事务数据之间的关联关系,确保上下游传递顺畅,数仓中间层建模时就是事实表表来源。

报告数据治理
报告数据是对数据进行处理加工后,用作业务决策依据的数据。主要是指维度、指标。

观测数据治理
观测数据是观测者通过观测工具获取观测对象行为/过程的记录数据。如系统日志、物联网数据、GPS数据等。
观测对象主要是人、事、物和环境,观测对象要定义成业务对象进行管理。观测方式分为软感知(使用软件或各种技术进行数据收集,比如某log日志)和硬感知(收集对象为物理世界中物理实体,如IOT数据)。

规则数据治理
规则数据是结构化描述业务规则变量(一般为决策表、关联关系表、评分卡等形式)的数据,是实现业务规则的核心数据。无法实例化,只能以逻辑实体存在。如某下单流程中的定价规则,风控规则等。业务规则/规则变量->规则数据,一个业务规则可以包含0-N个规则数据。




非结构化数据

外部数据
外部数据是指华为公司引入的外部组织或者个人拥有处置权利的数据,如供应商资质证明、消费者洞察报告等。外部数据治理的出发点是合规遵从优先,与内部数据治理的目的不同。

元数据
元数据是定义数据的数据,是有关一个企业所使用的物理数据、技术和业务流程、数据规则和约束以及数据的物理与逻辑结构的信息。属于描述性标签,描述了数据、相关概念以及他们之间的关系,如业务术语、指标定义、表/字段描述等。



元数据设计原则




数据资产编码
数据资产编码(DAN,Data Asset Numbering) 是一种对数据资产进行唯一标识的编码体系,用于帮助企业对其数据资产进行统一管理、标识和追踪。


Schema (skiːmə,s给m)是数据库的设计图,定义了数据的结构、类型和关系,为数据存储、管理和使用提供规范。

元数据注册
元数据注册 是指将元数据(Metadata)按照一定的规范和标准,登记到一个元数据管理平台或元数据仓库中,以便统一管理和使用。这个过程确保企业或组织中的数据资源可以被清晰地描述、分类和追踪,从而实现对数据的全面理解、利用和管控。

元数据注册有4种模式,一对一模式(逻辑实体和物理表一对一)、主从模式(一对多,逻辑实体对应多张物理表)、主扩模式(一对多主物理表为核心表,少数属性存在其他物理表中)和父子模式(多个逻辑实体业务属性完全相同,按照不同场景区分逻辑实体,但落在同一物理表中)。






第二部分

第四章

企业级信息架构



信息架构原则
第五章


数据底座总体架构

数据湖
数据湖(入湖方法)





这里区分下物理入湖和虚拟入湖:
(1)物理入湖是指将原始数据复制到数据湖中,主要有批量集成、数据复制同步(实时,CDC)、消息集成(实时,API提取数据,MQ工具)和流集成(实时,Pipline工具)。
(2)虚拟入湖是指原始数据不在数据湖中进行物理存储,而是通过建立虚拟表的集成方式实现入湖,实时性强,一般面向小数据量应用,数据量过大可能影响源系统。主要是面向需要低数据低时延、高灵活性和临时模式(不断消费下的模式)的消费场景。如Denodo中的逻辑数据架构,支持数据虚拟化。

批量集成


数据复制同步


消息集成


流集成


数据虚拟化



结构化数据入湖
结构化数据是指由二维表结构来逻辑表达和实现的数据,严格遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。
触发结构化数据入湖的场景有两种:
第一,企业数据管理组织基于业务需求主动规划和统筹;
第二,响应数据消费方的需求。
结构化数据入湖过程包括:数据入湖需求分析及管理、检查数据入湖条件和评估入湖标准、实施数据入湖、注册元数据。

非结构化数据入湖


数据主题联结


第六章

数据服务

数据地图



服务+自助

数字化运营过程

第三部分

相关文章:
华为数据之道-读书笔记
内容简介 关键字 数字化生产 已经成为普遍的商业模式,其本质是以数据为处理对象,以ICT平台为生产工具,以软件为载体,以服务为目的的生产过程。 信息与通信技术平台(Information and Communication Technology Platf…...
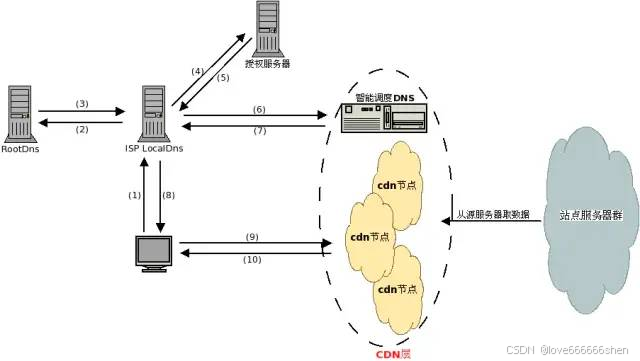
CDN、源站与边缘网络
什么是“源站” 源服务器 源服务器的目的是处理和响应来自互联网客户端的传入请求。源服务器的概念通常与边缘服务器或缓存服务器的概念结合使用。源服务器的核心是一台运行一个或多个程序的计算机,这些程序旨在侦听和处理传入的客户端请求。源服务器可以承担为网…...
工业相机 SDK 二次开发-Sherlock插件
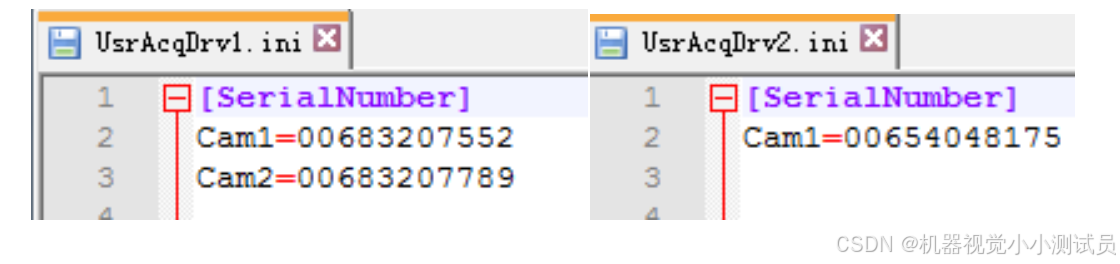
本文介绍了 sherlock 连接相机时的插件使用。通过本套插件可连接海康的工业相机。 一.环境配置 1. 拷贝动态库 在用户安装 MVS 目录下按照如下路径 Development\ThirdPartyPlatformAdapter 找到目 录为 DalsaSherlock 的文件夹,根据 Sherlock 版本找到…...
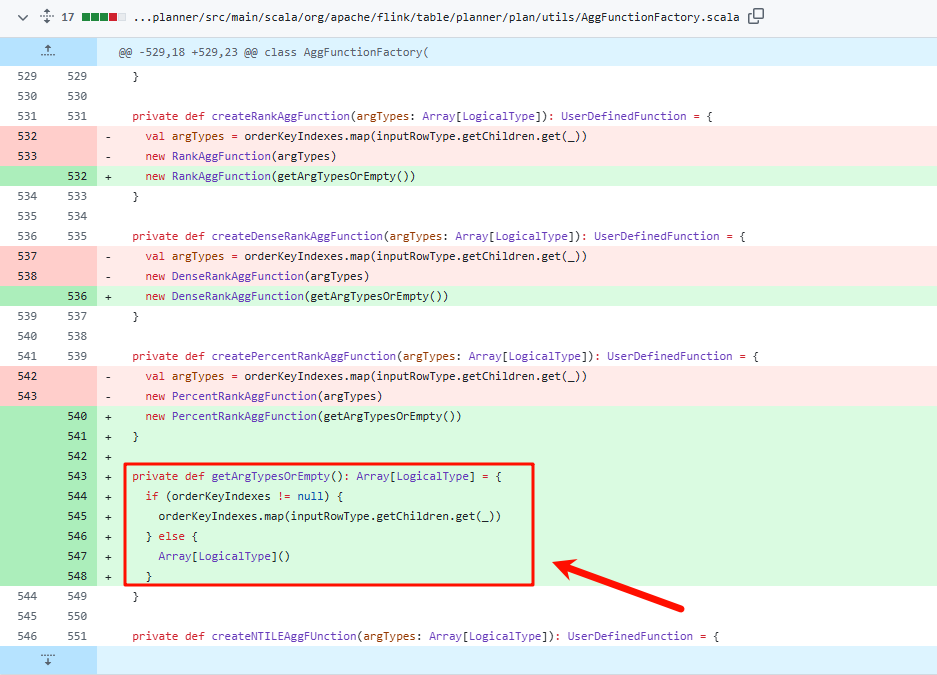
FlinkSql使用中rank/dense_rank函数报错空指针
问题描述 在flink1.16(甚至以前的版本)中,使用rank()或者dense_rank()进行排序时,某些场景会导致报错空指针NPE(NullPointerError) 报错内容如下 该报错没有行号/错误位置,无法排查 现状 目前已经确认为bug,根据github上的PR日…...
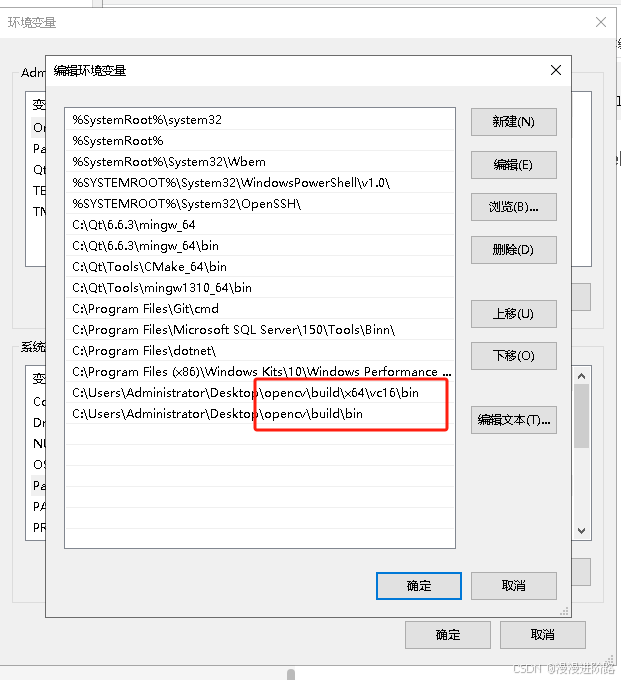
VS C++ 配置OPENCV环境
VS C 配置OPENCV环境 1.下载opencv2.安装环境3.opencv环境4.VS配置opencv环境5.EXE执行文件路径的环境lib和dll需要根据是debug还是release环境来区分使用哪个 6.Windows环境 1.下载opencv 链接: link 2.安装环境 双击运行即可 3.opencv环境 include文件路径:opencv\build\…...
【SpringSecurity】基本开发流程
文章目录 概要整体架构流程实现流程1、编写各种Handler2 、AccessToken处理器3、定义AuthenticationFilter 继承 OncePerRequestFilter (OncePerRequestFilter是Spring提供的一个过滤器基类,它确保了在一次完整的HTTP请求中,无论请求经过多少…...
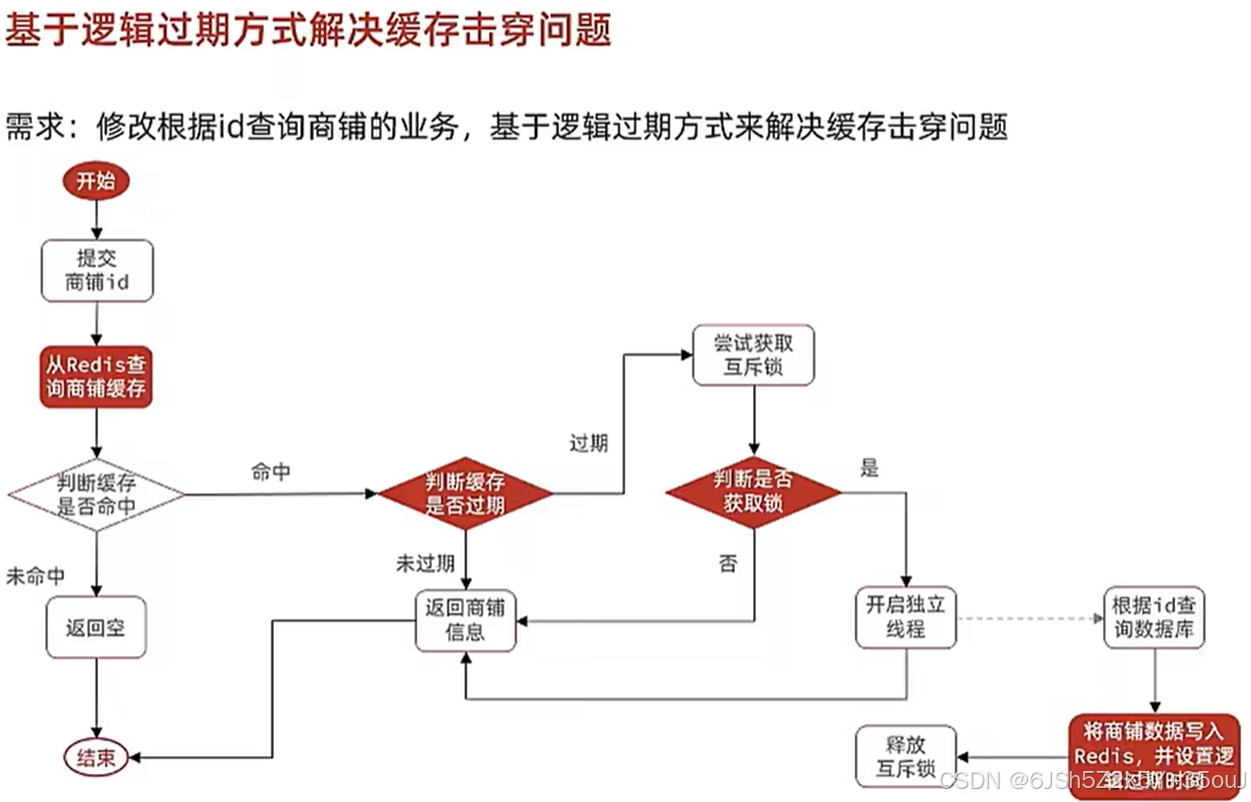
Redis实战(黑马点评)——关于缓存(缓存更新策略、缓存穿透、缓存雪崩、缓存击穿、Redis工具)
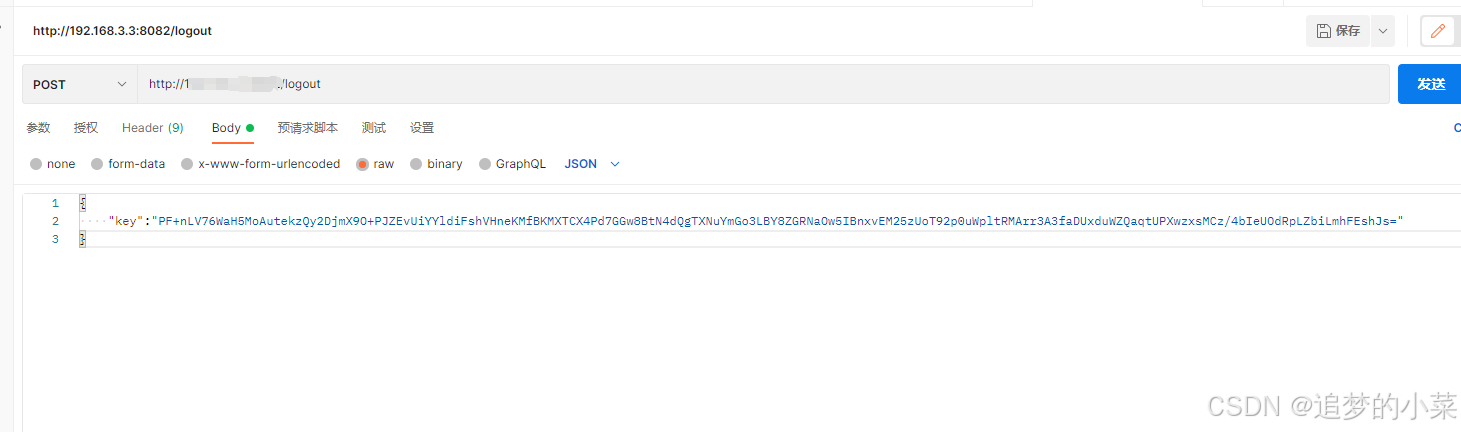
redis实现查询缓存的业务逻辑 service层实现 Overridepublic Result queryById(Long id) {String key CACHE_SHOP_KEY id;// 现查询redis内有没有数据String shopJson (String) redisTemplate.opsForValue().get(key);if(StrUtil.isNotBlank(shopJson)){ // 如果redis的数…...

ChatGPT从数据分析到内容写作建议相关的46个提示词分享!
在当今快节奏的学术环境中,研究人员面临着海量的信息和复杂的研究任务。幸运的是,随着人工智能技术的发展,像ChatGPT这样的先进工具为科研人员提供了强大的支持。今天就让我们一起探索如何利用ChatGPT提升研究效率进一步优化研究流程。 ChatG…...

在 Windows 11 中设置 WSL2 Ubuntu 的 `networkingMode=mirrored` 详细教程
在 Windows 11 中设置 WSL2 Ubuntu 的 networkingModemirrored 详细教程 引言环境要求配置 .wslconfig 文件重启 WSL2验证镜像网络模式解决常见问题其他注意事项结论 引言 在 Windows 11 中使用 WSL2(Windows Subsystem for Linux 2)时,默认…...
万字长文总结前端开发知识---JavaScriptVue3Axios
JavaScript学习目录 一、JavaScript1. 引入方式1.1 内部脚本 (Inline Script)1.2 外部脚本 (External Script) 2. 基础语法2.1 声明变量2.2 声明常量2.3 输出信息 3. 数据类型3.1 基本数据类型3.2 模板字符串 4. 函数4.1 具名函数 (Named Function)4.2 匿名函数 (Anonymous Fun…...

怎么样把pdf转成图片模式(不能复制文字)
贵但好用的wps, 转换——转为图片型pdf —————————————————————————————————————————— 转换前: 转换后: 肉眼可见,模糊了,且不能复制。 其他免费办法,参考&…...
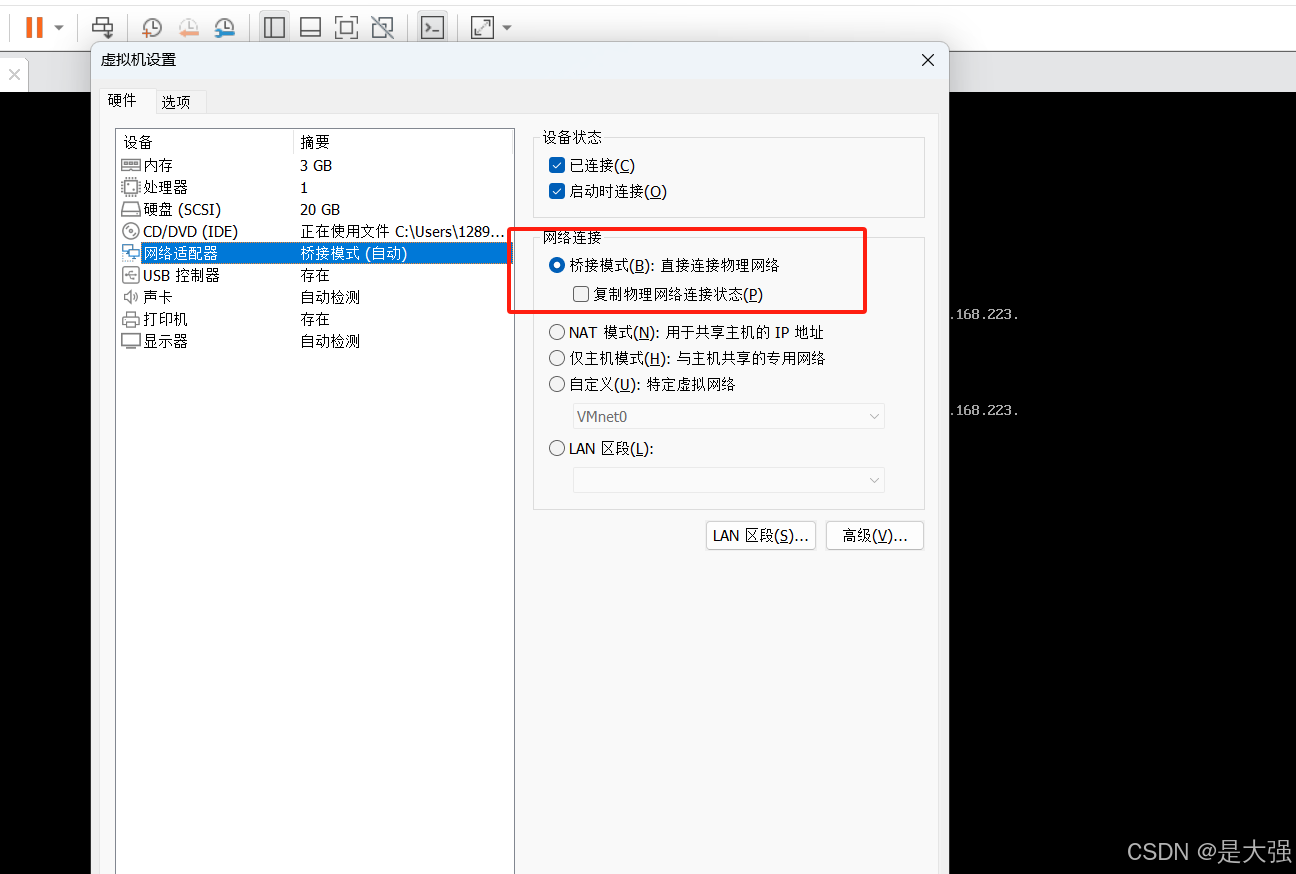
本地centos网络配置
1、路径 2、配置 另外还需要...

kotlin内联函数——runCatching
1.runCatching作用 代替try{}catch{}异常处理,用于捕获异常。 2.runCatching函数介绍 参数:上下文引用对象为参数返回值:lamda表达式结果 调用runCatching函数,如果调用成功则返回其封装的结果,并可回调onSuccess函…...

Python3 正则表达式:文本处理的魔法工具
Python3 正则表达式:文本处理的魔法工具 内容简介 本系列文章是为 Python3 学习者精心设计的一套全面、实用的学习指南,旨在帮助读者从基础入门到项目实战,全面提升编程能力。文章结构由 5 个版块组成,内容层层递进,逻…...
《DiffIR:用于图像修复的高效扩散模型》学习笔记
paper:2303.09472 GitHub:GitHub - Zj-BinXia/DiffIR: This project is the official implementation of Diffir: Efficient diffusion model for image restoration, ICCV2023 目录 摘要 1、介绍 2、相关工作 2.1 图像恢复(Image Rest…...
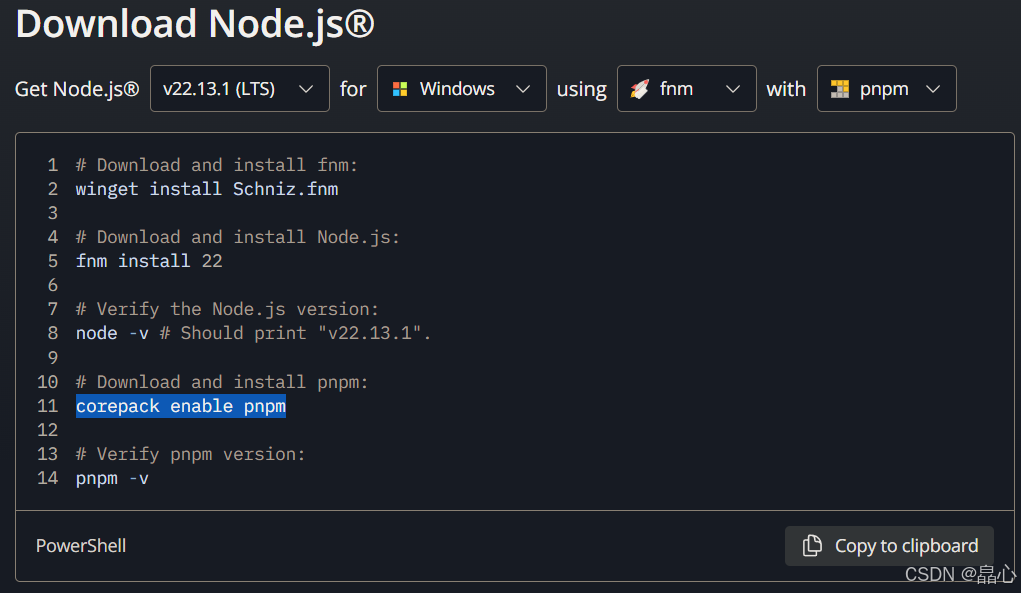
windows平台通过命令行安装前端开发环境
访问node.js官网 访问node.js官网https://nodejs.org/en/download/,可以看到类似画面: 可以获取以下命令 # Download and install fnm: winget install Schniz.fnm # Download and install Node.js: fnm install 22 # Verify the Node.js version: no…...
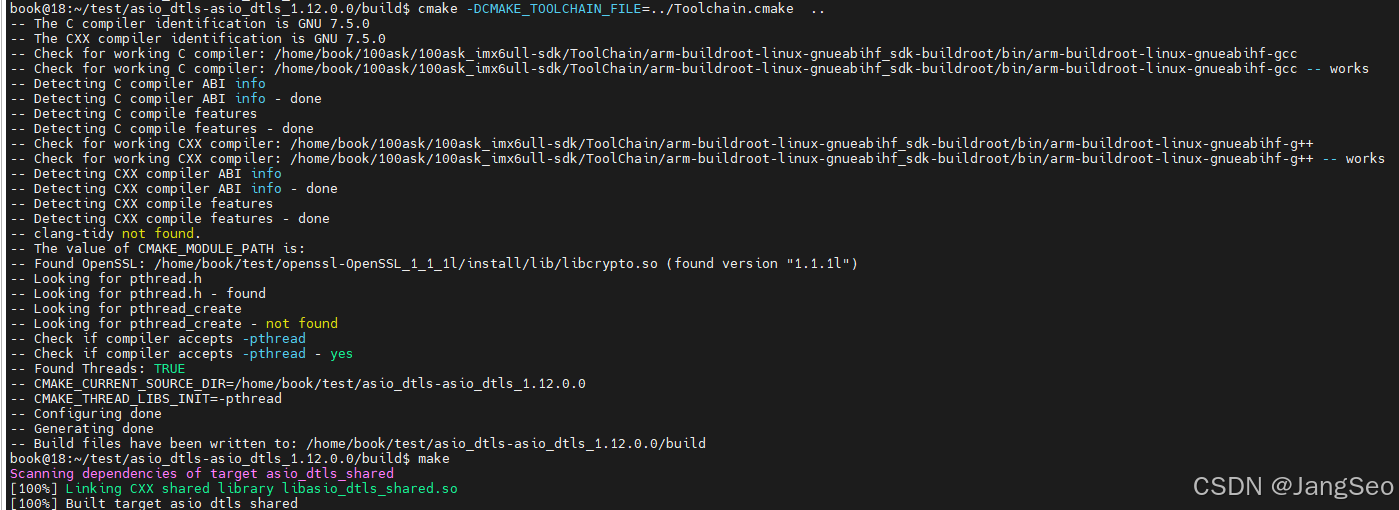
记交叉编译asio_dtls过程
虽然编译成功了,但是还是有一些不妥的地方,参考一下就行了。 比如库的版本选择就有待商榷,我这里不是按照项目作者的要求严格用对应的版本编译的,这里也可以注意一下。 编译依赖库asio 下载地址, 更正一下,我其实用…...
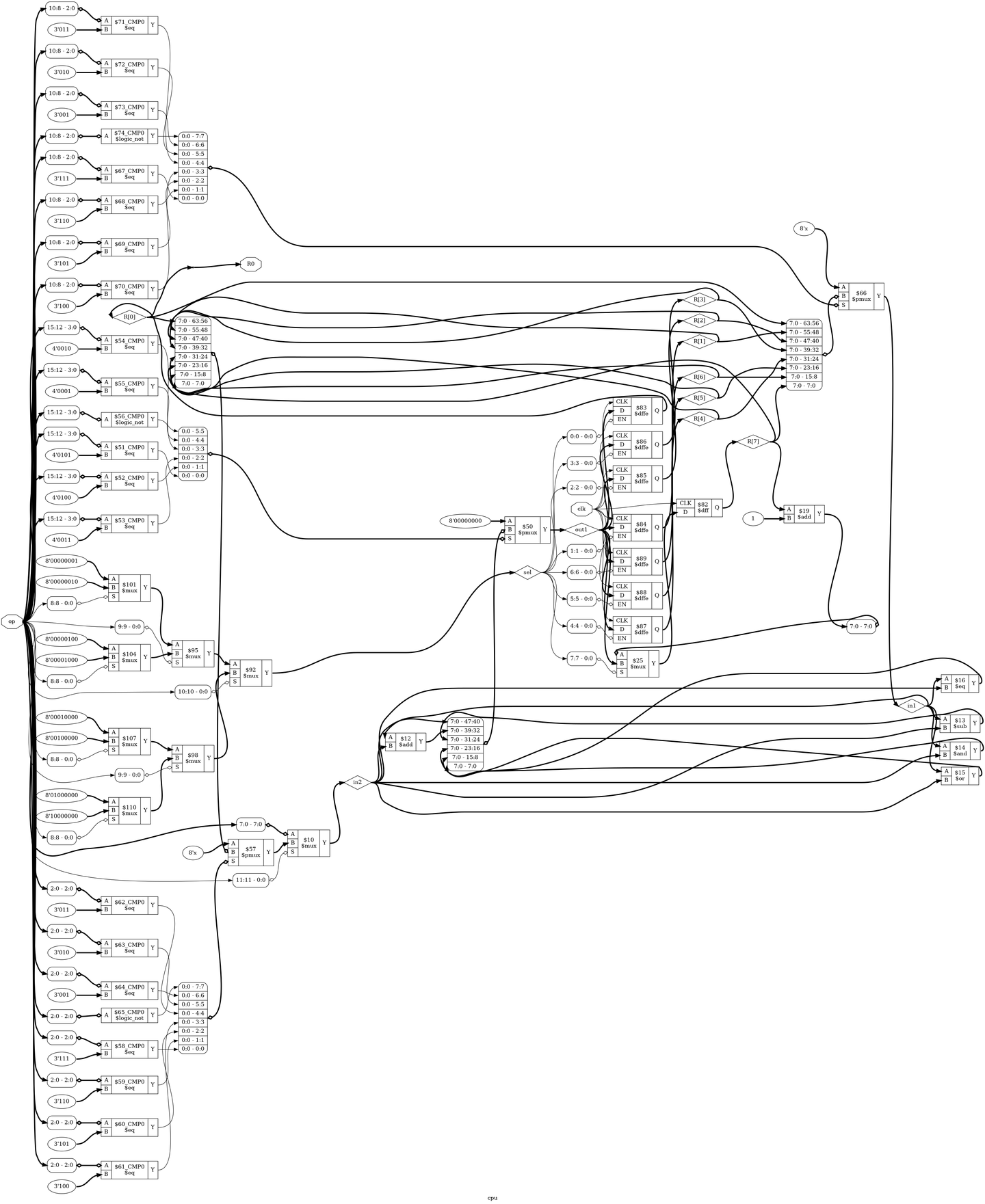
学习yosys(一款开源综合器)
安装 sudo apt-get install yosys #ubuntu22.04仓库里面是yosys-0.9 sudo install xdot 创建脚本show_rtl.ys read_verilog cpu.v hierarchy -top cpu proc; opt; fsm; opt; memory; opt; show -prefix cpu 调用脚本 yosys show_rtl.ys verilog代码 module cpu(input c…...

自定义数据集 使用tensorflow框架实现逻辑回归并保存模型,然后保存模型后再加载模型进行预测
一、使用tensorflow框架实现逻辑回归 1. 数据部分: 首先自定义了一个简单的数据集,特征 X 是 100 个随机样本,每个样本一个特征,目标值 y 基于线性关系并添加了噪声。tensorflow框架不需要numpy 数组转换为相应的张量࿰…...

对于Docker的初步了解
简介与概述 1.不需要安装环境,工具包包含了环境(jdk等) 2.打包好,“一次封装,到处运行” 3.跨平台,docker容器在任何操作系统上都是一致的,这就是实现跨平台跨服务器。只需要一次配置好环境&…...
结合贝塞尔曲线拟合(Bezier)进行无人机三维路径规划的详细项目实例(含模型描述及部分示例代码) 还请多多点一下关注 加)
项目介绍 MATLAB实现基于RRT-Bezier快速搜索随机树算法(RRT)结合贝塞尔曲线拟合(Bezier)进行无人机三维路径规划的详细项目实例(含模型描述及部分示例代码) 还请多多点一下关注 加
MATLAB实现基于RRT-Bezier快速搜索随机树算法(RRT)结合贝塞尔曲线拟合(Bezier)进行无人机三维路径规划的详细项目实例 更多详细内容可直接联系博主本人 或者访问对应标题的完整博客或者文档下载页面(含完整的程序&a…...

如何让键盘听懂你的设备语言?设备条件判断打造智能多设备键盘映射方案
如何让键盘听懂你的设备语言?设备条件判断打造智能多设备键盘映射方案 【免费下载链接】Karabiner-Elements Karabiner-Elements is a powerful utility for keyboard customization on macOS Sierra (10.12) or later. 项目地址: https://gitcode.com/gh_mirrors…...

终极指南:如何利用Reor AI智能笔记应用的本地化语义搜索与智能推荐功能
终极指南:如何利用Reor AI智能笔记应用的本地化语义搜索与智能推荐功能 【免费下载链接】reor Self-organizing AI note-taking app that runs models locally. 项目地址: https://gitcode.com/GitHub_Trending/re/reor Reor是一款革命性的AI智能笔记应用&am…...

Fluent Bit源码解析:KISS原则如何打造轻量级日志处理神器
Fluent Bit源码解析:KISS原则如何打造轻量级日志处理神器 【免费下载链接】fluent-bit Fast and Lightweight Logs and Metrics processor for Linux, BSD, OSX and Windows 项目地址: https://gitcode.com/GitHub_Trending/fl/fluent-bit 在当今云原生时代&…...

技术赋能B端拓客:号码核验行业的破局与价值深耕,氪迹科技法人股东核验筛选系统,阶梯式价格
2026年,B端市场进入存量竞争的深水区,“精准获客、降本增效”不再是企业的加分项,而是生存发展的必选项。号码核验作为B端拓客流程的前置筛选环节,直接决定了线索质量、人力效能与投入回报比,成为影响企业拓客竞争力的…...

GIS小白也能搞定!用QGIS加载2023版全国自然保护区SHP数据的保姆级教程
GIS小白也能搞定!用QGIS加载2023版全国自然保护区SHP数据的保姆级教程 第一次接触GIS软件时,看着满屏的专业术语和复杂界面,很多人都会感到无从下手。但别担心,今天我们就用最通俗易懂的方式,带你一步步完成全国自然保…...

nli-distilroberta-base效果展示:Entailment/Contradiction/Neutral三类判别置信度热力图
nli-distilroberta-base效果展示:Entailment/Contradiction/Neutral三类判别置信度热力图 1. 项目概述 nli-distilroberta-base是基于DistilRoBERTa模型的自然语言推理(NLI)Web服务,专门用于分析两个句子之间的逻辑关系。这个轻量级模型能够快速准确地…...

AI手势识别从入门到应用:彩虹骨骼版MediaPipe Hands全流程解析
AI手势识别从入门到应用:彩虹骨骼版MediaPipe Hands全流程解析 1. 手势识别技术概述 手势识别作为人机交互的重要分支,正在改变我们与数字世界的互动方式。想象一下,无需触碰任何设备,仅凭手势就能控制音乐播放、浏览照片或操作…...

RAG实战解析:如何通过检索增强生成提升知识密集型NLP任务性能
1. RAG技术为什么能改变知识密集型NLP任务格局 第一次听说RAG(Retrieval-Augmented Generation)这个概念时,我正被一个开放域问答项目折磨得焦头烂额。当时我们用纯BART模型生成的答案总是出现事实性错误,比如把"特斯拉创始人…...
)
零基础如何选择PMP和软考?2025年考证避坑指南(含最新政策解读)
零基础如何选择PMP和软考?2025年考证避坑指南(含最新政策解读) 项目管理领域的证书选择一直是职场人士关注的焦点。PMP和软考作为两大主流认证,各自拥有独特的价值定位和适用场景。对于零基础考生而言,如何在2025年这…...