将 OneLake 数据索引到 Elasticsearch - 第二部分
作者:来自 Elastic Gustavo Llermaly 及 Jeffrey Rengifo

本文分为两部分,第二部分介绍如何使用自定义连接器将 OneLake 数据索引并搜索到 Elastic 中。
在本文中,我们将利用第 1 部分中学到的知识来创建 OneLake 自定义 Elasticsearch 连接器。
我们已经上传了一些 OneLake 文档并将其索引到 Elasticsearch 中以供搜索。但是,这仅适用于一次性上传。如果我们想要同步数据,那么我们需要开发一个更复杂的系统。
幸运的是,Elastic 有一个连接器框架可用于开发满足我们需求的自定义连接器:
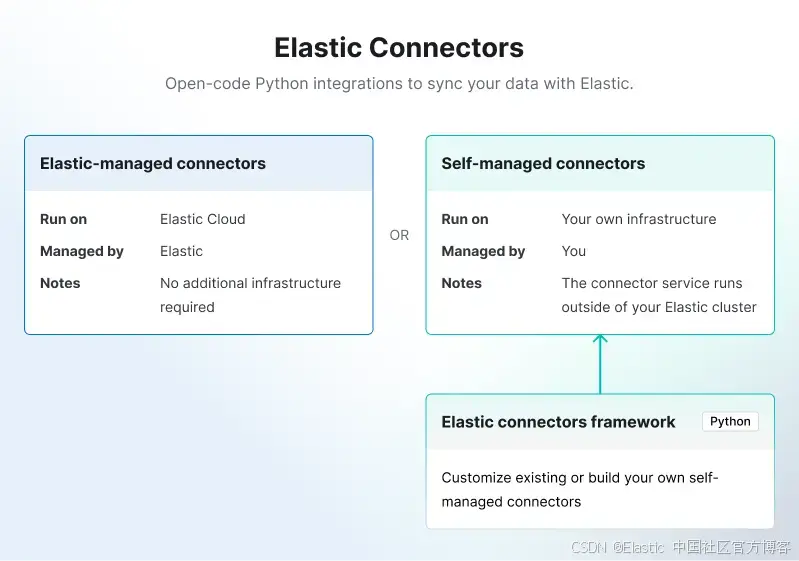
我们现在将根据本文制作一个 OneLake 连接器:如何为 Elasticsearch 创建自定义连接器。
步骤
- 连接器引导
- 实现 BaseDataSource 类
- 身份验证
- 运行连接器
- 配置计划
连接器引导
背景信息:Elastic 连接器分为两种类型:
- Elastic 托管连接器:完全由 Elastic Cloud 托管和运行。
- 自托管连接器:由用户自行托管,必须部署在你的基础设施中。
自定义连接器属于 “连接器客户端” 类别,因此我们需要下载并部署连接器框架。
首先,克隆连接器的代码库:
git clone https://github.com/elastic/connectors现在在 requirements/framework.txt 文件末尾添加你将使用的依赖项。在本例中:
azure-identity==1.19.0
azure-storage-file-datalake==12.17.0这样,存储库就完成了,我们可以开始编码了。
实现 BaseDataSource 类
你可以在此存储库中找到完整的工作代码。
我们将介绍 onelake.py 文件中的核心部分。
在导入和类声明之后,我们必须定义将捕获配置参数的 __init__ 方法。
"""OneLake connector to retrieve data from datalakes"""from functools import partialfrom azure.identity import ClientSecretCredential
from azure.storage.filedatalake import DataLakeServiceClientfrom connectors.source import BaseDataSourceACCOUNT_NAME = "onelake"class OneLakeDataSource(BaseDataSource):"""OneLake"""name = "OneLake"service_type = "onelake"incremental_sync_enabled = True# Here we can enter the data that we'll later need to connect our connector to OneLake.def __init__(self, configuration):"""Set up the connection to the azure base clientArgs:configuration (DataSourceConfiguration): Object of DataSourceConfiguration class."""super().__init__(configuration=configuration)self.tenant_id = self.configuration["tenant_id"]self.client_id = self.configuration["client_id"]self.client_secret = self.configuration["client_secret"]self.workspace_name = self.configuration["workspace_name"]self.data_path = self.configuration["data_path"]然后,你可以配置 UI 将显示的表单,使用返回配置字典的 get_default_configuration 方法填充这些参数。
# Method to generate the Enterprise Search UI fields for the variables we need to connect to OneLake.@classmethoddef get_default_configuration(cls):"""Get the default configuration for OneLakeReturns:dictionary: Default configuration"""return {"tenant_id": {"label": "OneLake tenant id","order": 1,"type": "str",},"client_id": {"label": "OneLake client id","order": 2,"type": "str",},"client_secret": {"label": "OneLake client secret","order": 3,"type": "str","sensitive": True, # To hide sensitive data like passwords or secrets},"workspace_name": {"label": "OneLake workspace name","order": 4,"type": "str",},"data_path": {"label": "OneLake data path","tooltip": "Path in format <DataLake>.Lakehouse/files/<Folder path>","order": 5,"type": "str",},"account_name": {"tooltip": "In the most cases is 'onelake'","default_value": ACCOUNT_NAME,"label": "Account name","order": 6,"type": "str",},}然后我们配置下载方法,并从 OneLake 文档中提取内容。
async def download_file(self, file_client):"""Download file from OneLakeArgs:file_client (obj): File clientReturns:generator: File stream"""try:download = file_client.download_file()stream = download.chunks()for chunk in stream:yield chunkexcept Exception as e:self._logger.error(f"Error while downloading file: {e}")raiseasync def get_content(self, file_name, doit=None, timestamp=None):"""Obtains the file content for the specified file in `file_name`.Args:file_name (obj): The file name to process to obtain the content.timestamp (timestamp, optional): Timestamp of blob last modified. Defaults to None.doit (boolean, optional): Boolean value for whether to get content or not. Defaults to None.Returns:str: Content of the file or None if not applicable."""if not doit:returnfile_client = await self._get_file_client(file_name)file_properties = file_client.get_file_properties()file_extension = self.get_file_extension(file_name)doc = {"_id": f"{file_client.file_system_name}_{file_properties.name}", # workspacename_data_path"name": file_properties.name.split("/")[-1],"_timestamp": file_properties.last_modified,"created_at": file_properties.creation_time,}can_be_downloaded = self.can_file_be_downloaded(file_extension=file_extension,filename=file_properties.name,file_size=file_properties.size,)if not can_be_downloaded:return docextracted_doc = await self.download_and_extract_file(doc=doc,source_filename=file_properties.name.split("/")[-1],file_extension=file_extension,download_func=partial(self.download_file, file_client),)return extracted_doc if extracted_doc is not None else doc为了让我们的连接器对框架可见,我们需要在 connectors/config.py 文件中声明它。为此,我们将以下代码添加到源中:
"sources": {..."onelake": "connectors.sources.onelake:OneLakeDataSource",...}身份验证
在测试连接器之前,我们需要获取 client_id, tenant_id 和 client_secret,我们将使用它们从连接器访问工作区。
我们将使用 service principals 作为身份验证方法。
Azure service principal 是为与应用程序、托管服务和自动化工具一起使用以访问 Azure 资源而创建的身份。
步骤如下:
- 创建应用程序并收集 client_id、tenant_id 和 client_secret
- 在工作区中启用 service principal
- 将 service principal 添加到工作区
你可以逐步遵循本教程。
准备好了吗?现在是测试连接器的时候了!
运行连接器
连接器准备好后,我们现在可以连接到我们的 Elasticsearch 实例。
转到: Search > Content > Connectors > New connector 并选择 Customized Connector
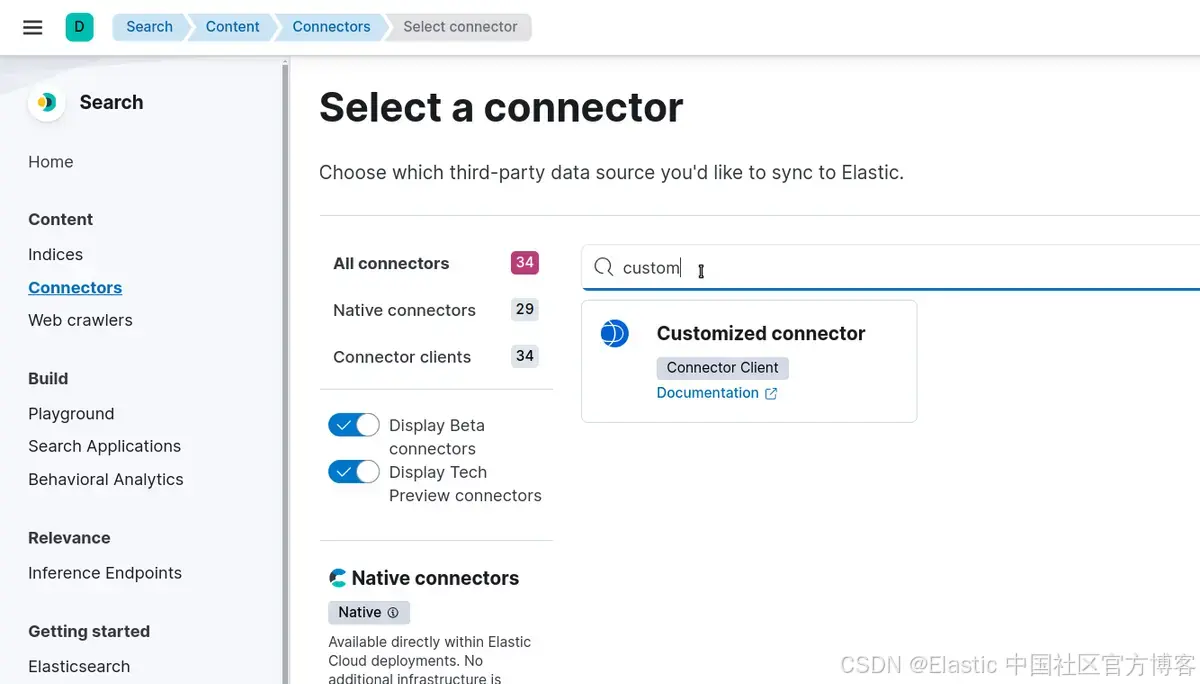
选择要创建的名称,然后选择 “Create and attach an index” 以创建与连接器同名的新索引。
你现在可以使用 Docker 运行它或从源代码运行它。在此示例中,我们将使用 “Run from source”。
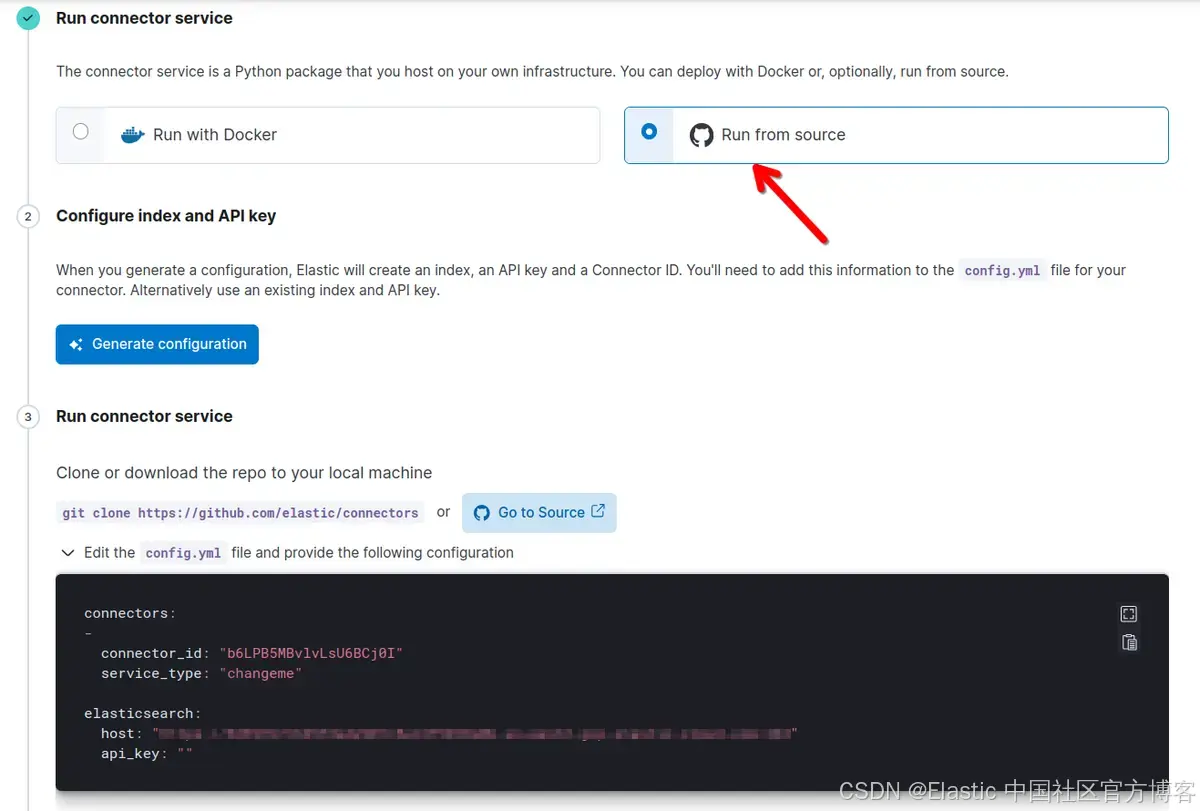
单击 “Generate Configuration”,然后将框中的内容粘贴到项目根目录中的 config.yml 文件中。在字段 service_type 上,你必须匹配 Connectors/config.py 中的连接器名称。在本例中,将 changeme 替换为 onelake。
现在,你可以使用以下命令运行连接器:
make install
make run如果连接器正确初始化,你应该在控制台中看到如下消息:

注意:如果出现兼容性错误,请检查你的连接器/版本文件并与你的 Elasticsearch 集群版本进行比较:与 Elasticsearch 的版本兼容性。我们建议保持连接器版本和 Elasticsearch 版本同步。在本文中,我们使用 Elasticsearch 和连接器版本 8.15。
如果一切顺利,我们的本地连接器将与我们的 Elasticsearch 集群通信,我们将能够使用我们的 OneLake 凭据对其进行配置:
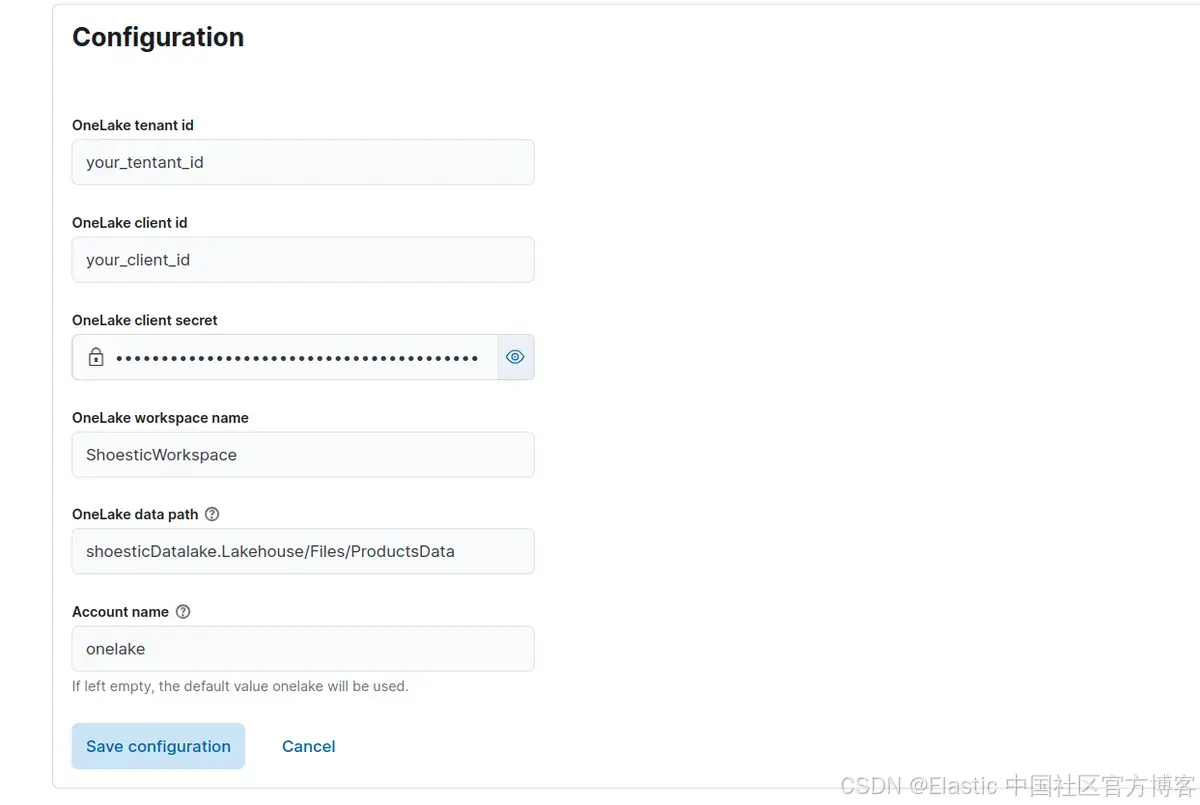
我们现在将索引来自 OneLake 的文档。为此,请单击 Sync > Full Content,运行完整内容同步:
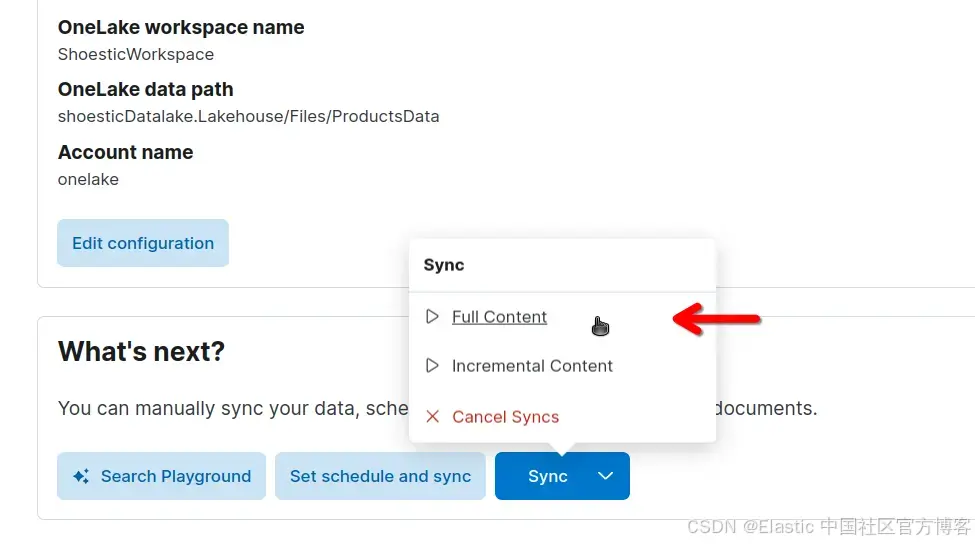
同步完成后,你应该在控制台中看到以下内容:

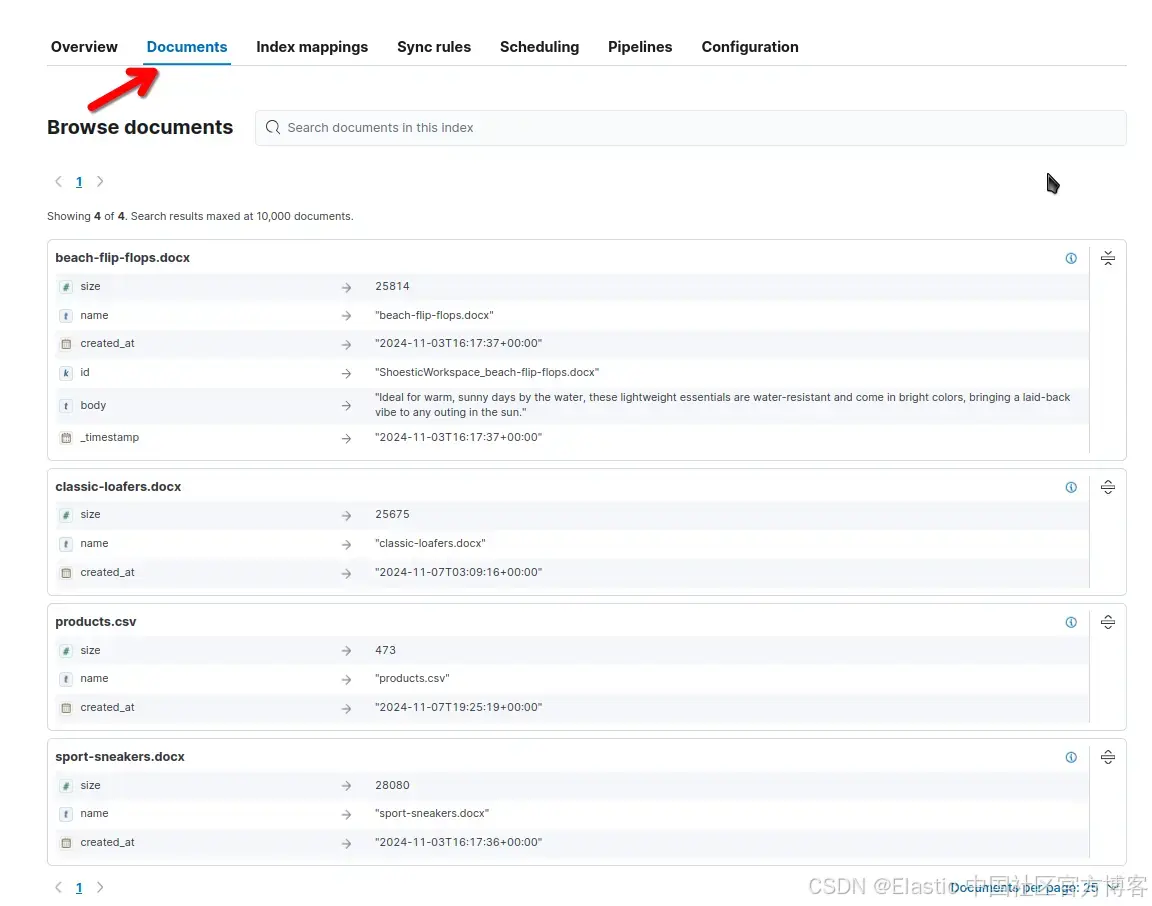
在企业搜索 UI 中,你可以单击 “Documents” 来查看已索引的文档:
配置计划
你可以根据需要使用 UI 安排定期内容同步,以使索引保持更新并与 OneLake 同步。
要配置计划同步,请转到 “Search > Content > Connectors,然后选择你的连接器。然后单击 “scheduling”:
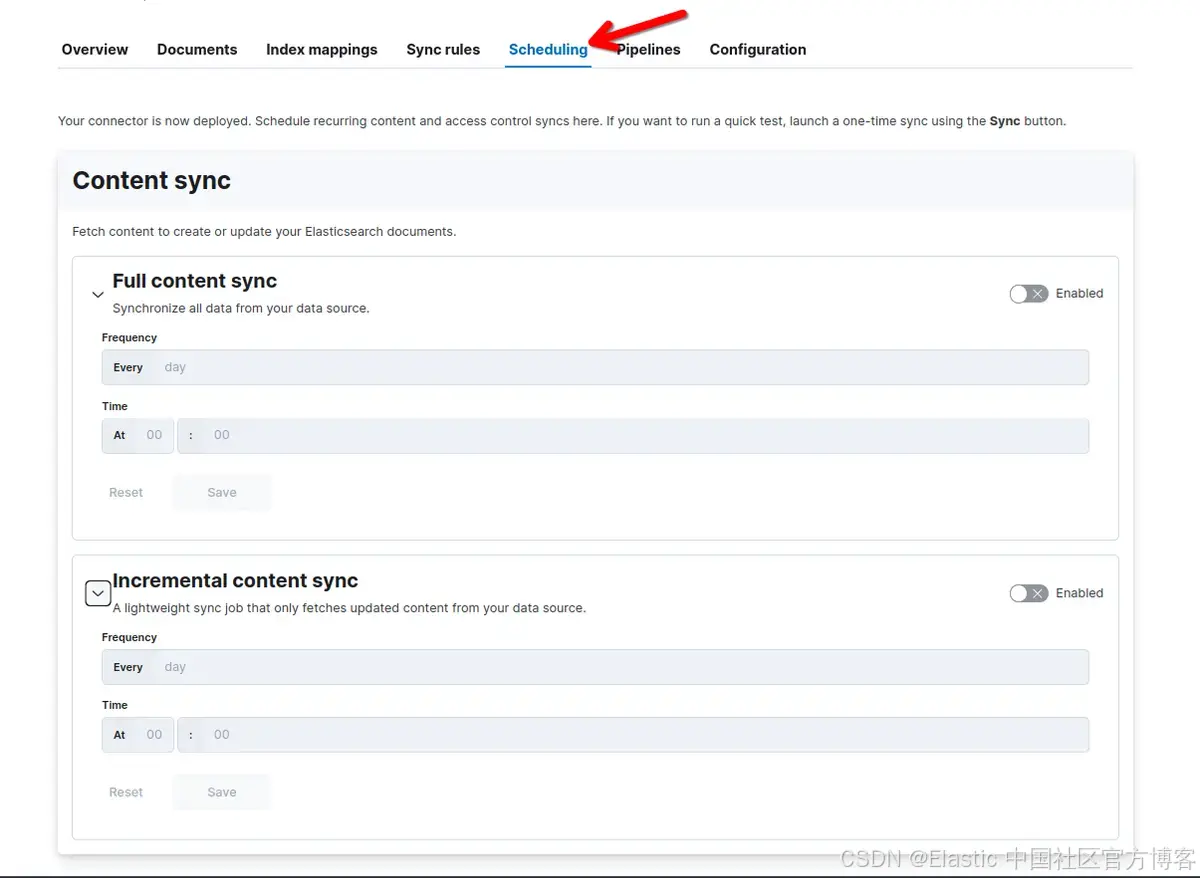
或者,你可以使用允许 CRON 表达式的更新连接器调度 API。
结论
在第二部分中,我们通过使用 Elastic 连接器框架并开发我们自己的 OneLake 连接器来轻松与我们的 Elastic Cloud 实例通信,将我们的配置更进一步。
想要获得 Elastic 认证?了解下一次 Elasticsearch 工程师培训何时开始!
Elasticsearch 包含新功能,可帮助你为你的用例构建最佳搜索解决方案。深入了解我们的示例笔记本以了解更多信息,开始免费云试用,或立即在你的本地机器上试用 Elastic。
原文:Indexing OneLake data into Elasticsearch - Part II - Elasticsearch Labs
相关文章:
将 OneLake 数据索引到 Elasticsearch - 第二部分
作者:来自 Elastic Gustavo Llermaly 及 Jeffrey Rengifo 本文分为两部分,第二部分介绍如何使用自定义连接器将 OneLake 数据索引并搜索到 Elastic 中。 在本文中,我们将利用第 1 部分中学到的知识来创建 OneLake 自定义 Elasticsearch 连接器…...

Linux——冯 • 诺依曼体系结构
目录 一、冯•诺依曼体系结构原理二、内存提高冯•诺依曼体系结构效率的方法三、当用QQ和朋友聊天时数据的流动过程四、关于冯诺依曼五、总结 我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系 流程&#…...

Java进阶(一)
目录 一.Java注解 什么是注解? 内置注解 元注解 二.对象克隆 什么是对象克隆? 为什么用到对象克隆 三.浅克隆深克隆 一.Java注解 什么是注解? java中注解(Annotation)又称java标注,是一种特殊的注释。 可以添加在包,类&…...

appium自动化环境搭建
一、appium介绍 appium介绍 appium是一个开源工具、支持跨平台、用于自动化ios、安卓手机和windows桌面平台上面的原生、移动web和混合应用,支持多种编程语言(python,java,Ruby,Javascript、PHP等) 原生应用和混合应用…...

Qt 5.14.2 学习记录 —— 이십 QFile和多线程
文章目录 1、QFile1、打开2、读写3、关闭4、程序5、其它功能 2、多线程1、演示2、锁 3、条件变量和信号量 1、QFile Qt有自己的一套文件体系,不过Qt也可以使用C,C,Linux的文件操作。使用Qt的文件体系和Qt自己的一些类型更好配合。 管理写入读…...
積分方程與簡單的泛函分析7.希爾伯特-施密特定理
1)def函數叫作"由核生成的(有源的)" 定义: 设 是定义在区域上的核函数。 对于函数,若存在函数使得, 则称函数是“由核生成的(有源的)”。 这里的直观理解是: 函数的“来源”可以通过核函数 与另一个函数的积分运算得到。 在积分方程理论中,这种表述常…...

使用vitepress搭建自己的博客项目
一、介绍can-vitepress-blog 什么是CAN BLOG CAN BLOG是基于vitepress二开的个人博客系统,他能够方便使用者快速构建自己的博客文章,无需繁琐的配置和复杂的代码编写。 CAN BLOG以antdv为UI设计基础,简洁大方,界面友好…...

开始步入达梦中级dba
分析内存使用需要的方法之一 disql /nolog conn sysdba/sysdbaselect value from v$parameter where nameMEMORY_LEAK_CHECK; SP_SET_PARA_VALUE(0,MEMORY_LEAK_CHECK,1); select * from V$MEM_REGINFO; select * from V$MEM_HEAP;...

如何在docker中的mysql容器内执行命令与执行SQL文件
通过 docker ps -a 查询当前运行的容器,找到想执行命令的容器名称。 docker ps -a若想执行sql文件,则将sql文件放入当前文件夹下后将项目内的 SQL 文件拷贝到 mysql 容器内部的 root下。 sudo docker cp /root/enterprise.sql mysql:/root/然后进入 my…...

S4 HANA更改Tax base Amount的字段控制
本文主要介绍在S4 HANA OP中Tax base Amount的字段控制相关设置。具体请参照如下内容: 1. 更改Tax base Amount的字段控制 以上配置用于控制FB60/FB65/FB70/FB75/MIRO的页签“Tax”界面是否可以修改“Tax base Amount”, 如果勾选Change 表示可以修改T…...

Linux权限有关
文章目录 一、添加普通用户二、Xshell下命令行的知识三、 Linux和Windows操作系统四、再探指令和Linux权限五、用户相关用户切换: 今天我们学习与Linux有关的权限等内容,以及一些零碎知识帮助我们理解Linux的系统和Xshell的原理。 本篇是在Xshell环境下执行的。 一…...

【github 使用相关】提交pr和commit message Conventional Commits 规范 代码提交的描述该写什么?
目录 Git 提交信息格式格式描述Subject(标题)Body(正文) 规范的标签(Tag)示例 CG Git 提交信息格式 格式描述 一般开源项目代码库根目录都会有一个 CONTRIBUTING.md 或者其他类似名字的文档来介绍如何开始…...

Docker—搭建Harbor和阿里云私有仓库
Harbor概述 Harbor是一个开源的企业级Docker Registry管理项目,由VMware公司开发。它的主要用途是帮助用户迅速搭建一个企业级的Docker Registry服务,提供比Docker官方公共镜像仓库更为丰富和安全的功能,特别适合企业环境使用。12 Harb…...

Maven的下载安装配置
maven的下载安装配置 maven是什么 Maven 是一个用于 Java 平台的 自动化构建工具,由 Apache 组织提供。它不仅可以用作包管理,还支持项目的开发、打包、测试及部署等一系列行为 Maven的核心功能 项目构建生命周期管理:Maven定义了项目构建…...

Rust:高性能与安全并行的编程语言
引言 在现代编程世界里,开发者面临的最大挑战之一就是如何平衡性能与安全性。在许多情况下,C/C这样的系统级编程语言虽然性能强大,但其内存管理的复杂性导致了各种安全漏洞。为了解决这些问题,Rust 作为一种新的系统级编程语言进入…...
函数详解(OK))
matlab的cat()函数详解(OK)
cat函数的功能是 连接数组 功能: 按指定的维度连接多个向量 结构: C cat(dim, A, B) 按dim指定的维度连接向量A和BC cat(dim, A1, A2, A3,A4, …) 按dim指定的维度连接多个向量A1, A2,A3,A4…C cat(dim, A{:}) 将包含向量的cell或结构数组联合为一…...

将个人微信中的时间改成标准的日期时间格式
list1["10:05","上午 10:07","下午 2:07","晚上 8:07","昨天 16:07","星期天 19:27","星期二 19:27","星期四 14:27","2025年1月10日 17:43"]from datetime import datetime, time…...

centos9编译安装opensips 二【进阶篇-定制目录+模块】推荐
环境:centos9 last opensips -V version: opensips 3.6.0-dev (x86_64/linux) flags: STATS: On, DISABLE_NAGLE, USE_MCAST, SHM_MMAP, PKG_MALLOC, Q_MALLOC, F_MALLOC, HP_MALLOC, DBG_MALLOC, CC_O0, FAST_LOCK-ADAPTIVE_WAIT ADAPTIVE_WAIT_LOOPS1024, MAX_RE…...

初步搭建并使用Scrapy框架
目录 目标 版本 实战 搭建框架 获取图片链接、书名、价格 通过管道下载数据 通过多条管道下载数据 下载多页数据 目标 掌握Scrapy框架的搭建及使用,本文以爬取当当网魔幻小说为案例做演示。 版本 Scrapy 2.12.0 实战 搭建框架 第一步:在D:\pyt…...

基于SpringBoot的软件产品展示销售系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

3分钟掌握HashCalculator:你的文件完整性守护专家
3分钟掌握HashCalculator:你的文件完整性守护专家 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/ha/HashCalculator …...

phpMyAdmin CVE-2018-12613:从文件读取到RCE的伪协议利用链
1. 这个漏洞不是“能读文件”那么简单,而是后台权限的彻底失守phpMyAdmin 4.8.1里那个CVE-2018-12613,很多人扫到就报个“存在文件包含”,顺手贴个?targetphp://filter/convert.base64-encode/resource/etc/passwd截图完事。我去年在给一家教…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南
如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南 【免费下载链接】CrewAI-Studio A user-friendly, multi-platform GUI for managing and running CrewAI agents and tasks. Supports Conda and virtual environments, no coding need…...

Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式 对于技术管理者或项目负责人而言,清晰了解团队的AI…...

Claude Agent SDK 从 0 到 1 快速上手教程
Claude Agent SDK 从 0 到 1 快速上手教程 什么是 Claude Agent SDK? Claude Agent SDK 是 Anthropic 官方推出的用于构建 AI 智能体的开发工具包。它基于 Claude Code 构建,让开发者能够以编程方式创建、扩展和定制由 Claude 驱动的应用程序。与简单的聊天机器人不同,基于…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...

NPU跑LLM实战指南:KV Cache动态性如何突破硬件限制
NPU跑LLM实战指南:KV Cache动态性如何突破硬件限制 副标题: 从预分配+Attention Mask到三层软件栈,完整解析NPU推理架构 痛点:为什么NPU跑LLM这么难? LLM的生成机制和NPU的硬件特性存在根本冲突: LLM特性 NPU特性 冲突点 逐token生成 固定shape执行 KV Cache动态增长 动…...