windows下本地部署安装hadoop+scala+spark-【不需要虚拟机】
注意版本依赖【本实验版本如下】
Hadoop 3.1.1
spark 2.3.2
scala 2.111.依赖环境
1.1 java
安装java并配置环境变量【如果未安装搜索其他教程】
环境验证如下:
C:\Users\wangning>java -version
java version "1.8.0_261"
Java(TM) SE Runtime Environment (build 1.8.0_261-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.261-b12, mixed mode)
1.2 hadoop安装
下载地址:https://hadoop.apache.org/releases.html
本案例下载:hadoop-3.1.1.tar.gz 或者直接访问:
https://hadoop.apache.org/release/3.1.1.html1.2.1 hadoop安装

环境变量新增:HADOOP_HOME 值,本地安装目录(根据实际更改)D:\apps\hadoop-3.3.6
path增加%HADOOP_HOME%\bin 和 %HADOOP_HOME%\sbin
验证hadoop是否安装好:
C:\Users\wangning>hadoop version
Hadoop 3.1.1
Source code repository https://github.com/apache/hadoop -r 2b9a8c1d3a2caf1e733d57f346af3ff0d5ba529c
Compiled by leftnoteasy on 2018-08-02T04:26Z
Compiled with protoc 2.5.0
From source with checksum f76ac55e5b5ff0382a9f7df36a3ca5a0
This command was run using /D:/apps/hadoop-3.1.1/share/hadoop/common/hadoop-common-3.1.1.jar
1.2.2 修改hadoop配置文件
修改hadoop的配置文件,这些配置文件决定了hadoop是否能正常启动
配置文件的位置:在%HADOOP_HOME%\etc\hadoop\
core-site.xml, -- 是全局配置
hdfs-site.xml, --hdfs的局部配置。
mapred-site.xml -- mapred的局部配置。
a:在coresite.xml下的配置:
添加
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>b: hdfs文件都可以建立在本地监听的这个服务下
在hdfs-site.xml下的配置:
添加
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>/D:/apps/hadoop-3.1.1/data/namenode</value> </property><property><name>dfs.datanode.data.dir</name><value>/D:/apps/hadoop-3.1.1/data/datanode</value> </property></configuration>在Hadoop3.1.1的安装目录下新建data文件夹,再data下,新建namenode和datanode 文件夹,

yarn-site.xml下的配置:
<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
mapred-site.xml文件下的配置:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
1.2.3 配置文件下载
下载的hadoop安装包默认是在linux环境下运行的,如果需要在windows中启动,需要额外增加两个步骤
a、下载对应版本的bin文件包,替换本机hadoop安装目录下的bin包
https://github.com/cdarlint/winutilsb、将对应版本bin包中的hadoop.dll这个文件放在本机的C:\Windows\System32下

step4: 启动hadoop
进入sbin目录中,用 管理员模式启动cmd:
先初始化NameNode:hdfs namenode -format

再运行start-dfs.cmd,
再运行start-yarn.cmd
运行完上述命令,会出现2*2个窗口,如果没有报错继续,如果报错根据错误定位原因。
在cmd中输入jps,如果返回如下几个进程,就说明启动成功了

1.2.4 访问验证
http://localhost:8088 ——查看应用管理界面ResourceManager

http://localhost:9870 ——NameNode界面

1.3 Spark安装
spark下载路径:[根据自己的版本进行下载]
https://archive.apache.org/dist/spark/spark-2.3.2/
下载对应的预编译文件:[spark-2.3.2-bin-hadoop2.7.tgz]下载后解压到路径,配置环境变量:
SPARK_HOME 变量值:Spark 的解压目录,例如 C:\Spark
编辑 Path,添加:%SPARK_HOME%\bin验证 Spark:[cmd下执行:spark-shell]
C:\Users\wangning>spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://DESKTOP-8B1BDRS.mshome.net:4040
Spark context available as 'sc' (master = local[*], app id = local-1737362793261).
Spark session available as 'spark'.
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 2.3.2/_/Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_261)
Type in expressions to have them evaluated.
Type :help for more informationui页面验证:http://localhost:4040
1.4 Scala安装
下载scala
https://www.scala-lang.org/download/2.11.0.html
下载后执行安装,比如安装目录为:D:\apps\scala-2.11.0

配置环境变量:
SCALA_HOME
配置完执行验证
C:\Users\wangning>scala -version
Scala code runner version 2.11.0 -- Copyright 2002-2013, LAMP/EPFLC:\Users\wangning>scala
Welcome to Scala version 2.11.0 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_261).
Type in expressions to have them evaluated.
Type :help for more information.scala> print("hello scala")
hello scala
scala>2. 创建scala项目
增加scala插件

2.1 项目初始化
对应的pom.xml文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>untitled</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><spark.version>2.3.2</spark.version><scala.version>2.11</scala.version></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.11.0</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-compiler</artifactId><version>2.11.0</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.4</version><scope>test</scope></dependency><dependency><groupId>org.specs</groupId><artifactId>specs</artifactId><version>1.2.5</version><scope>test</scope></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_${scala.version}</artifactId><version>${spark.version}</version></dependency></dependencies></project>2.2 coding
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._object WordCount_local {def main(args: Array[String]) {// if (args.length < 1) {// System.err.println("Usage: <file>")// System.exit(1)// }val conf = new SparkConf().setMaster("local").setAppName("HuiTest") //本地调试需要// val conf = new SparkConf() //onlineval sc = new SparkContext(conf)// val line = sc.textFile(args(0)) //online
// val line = sc.textFile("hdfs://localhost:9000/user/words.txt") //本地调试val line = sc.textFile("file:///D:/file/words.txt")line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect().foreach(println)sc.stop()}
}
2.3 打包
1. File->Project Structure



注意接下来删除除了jar包和compile output之外的所有jar,否则执行阶段会报错
执行相关操作:
C:\Windows\system32>hdfs dfs -ls hdfs://localhost:9000/C:\Windows\system32>hdfs dfs -mkdir hdfs://localhost:9000/user/C:\Windows\system32>hdfs dfs -ls hdfs://localhost:9000/
Found 1 items
drwxr-xr-x - wangning supergroup 0 2025-01-22 18:09 hdfs://localhost:9000/userC:\Windows\system32>hdfs dfs -put D:/file/words.txt hdfs://localhost:9000/user/words.txt
put: `/file/words.txt': No such file or directoryC:\Windows\system32>hdfs dfs -put file:///D:/file/words.txt hdfs://localhost:9000/user/words.txtC:\Windows\system32>
C:\Windows\system32>hdfs dfs -cat hdfs://localhost:9000/user/words.txt
hello
hello spark
hello redis
hello flink
hello doris
C:\Windows\system32>2.4 执行验证
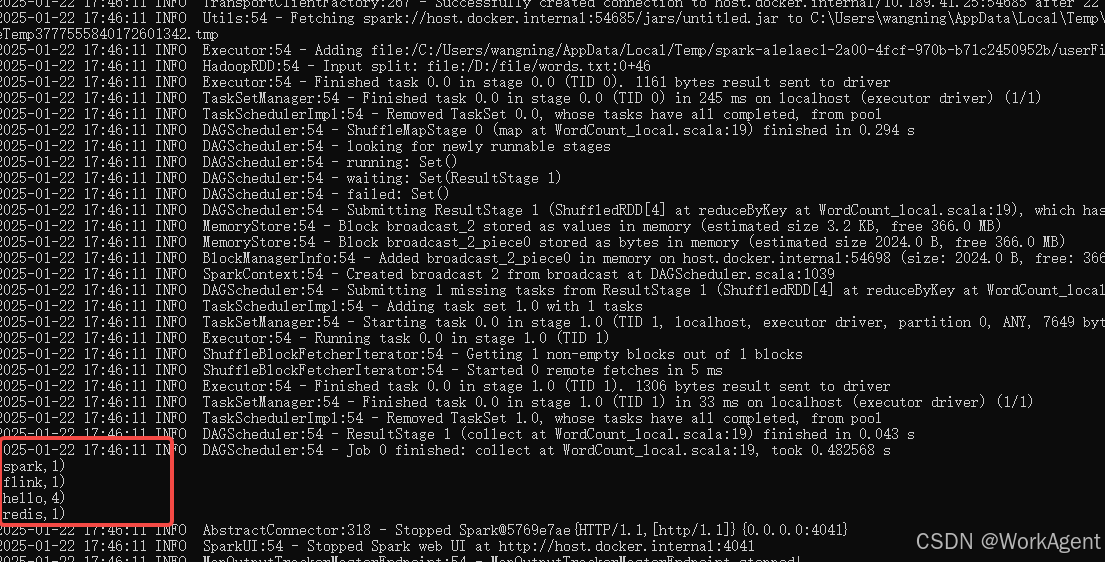
cmd下执行:
# 查看编译是否成功jar tf D:\code\testcode\t6\out\artifacts\untitled_jar\untitled.jar | findstr "WordCount_local"# 运行代码
spark-submit --master local --name huihui --class WordCount_local D:\code\testcode\t6\out\artifacts\untitled_jar\untitled.jar查看运行结果如下:
相关文章:
windows下本地部署安装hadoop+scala+spark-【不需要虚拟机】
注意版本依赖【本实验版本如下】 Hadoop 3.1.1 spark 2.3.2 scala 2.11 1.依赖环境 1.1 java 安装java并配置环境变量【如果未安装搜索其他教程】 环境验证如下: C:\Users\wangning>java -version java version "1.8.0_261" Java(TM) SE Runti…...

倍频增量式编码器--角度插值法输出A,B(Aangular Interpolation)
问题是: 最大速度,周期刻度,最小细分刻度,可以计算得到: 结论: 按照最高速度采样;数字A,B输出间隔时间:按照计算角度 插入细分角度运算算时间(最快速度)&a…...

LSM对于特殊数据的优化手段
好的,我现在需要帮助用户理解如何针对不同的特殊工作负载优化LSM树结构。用户提到了四种情况:时态数据、小数据、半排序数据和追加为主的数据。我需要分别解释每种情况下的优化方法,并参考用户提供的LHAM的例子,可能还有其他例子。…...

83,【7】BUUCTF WEB [MRCTF2020]你传你[特殊字符]呢
进入靶场 图片上这个人和另一道题上的人长得好像 54,【4】BUUCTF WEB GYCTF2020Ezsqli-CSDN博客 让我们上传文件 桌面有啥传啥 /var/www/html/upload/344434f245b7ac3a4fae0a6342d1f94a/123.php.jpg 成功后我就去用蚁剑连了,连不上 看了别的wp知需要…...
: 数据类型)
Go语言入门指南(二): 数据类型
文章创作不易,麻烦大家点赞关注转发一键三连。 在上一篇文章,我们已经完成了开发环境的搭建,成功创建了第一个“Hello, World”程序,并且对变量的声明和初始化有了初步的认识。在这篇文章中,我们将主要介绍Go语言的数据…...

2025.1.26机器学习笔记:C-RNN-GAN文献阅读
2025.1.26周报 文献阅读题目信息摘要Abstract创新点网络架构实验结论缺点以及后续展望 总结 文献阅读 题目信息 题目: C-RNN-GAN: Continuous recurrent neural networks with adversarial training会议期刊: NIPS作者: Olof Mogren发表时间…...

FAST-DDS and ROS2 RQT connect
reference: FAST-DDS与ROS2通信_ros2 收fastdds的数据-CSDN博客 software version: repositories: foonathan_memory_vendor: type: git url: https://github.com/eProsima/foonathan_memory_vendor.git version: v1.1.0 fastcdr: …...

GESP2024年3月认证C++六级( 第三部分编程题(2)好斗的牛)
参考程序(暴力枚举) #include <iostream> #include <vector> #include <algorithm> using namespace std; int N; vector<int> a, b; int ans 1e9; int main() {cin >> N;a.resize(N);b.resize(N);for (int i 0; i &l…...

记一次STM32编译生成BIN文件过大的问题(基于STM32CubeIDE)
文章目录 问题描述解决方法更多拓展 问题描述 最近在一个项目中使用了 STM32H743 单片机(基于 STM32CubeIDE GCC 开发),它的内存分为了 DTCMRAM RAM_D1 RAM_D2 …等很多部分。其中 DTCM 的速度是比通常的内存要快的,缺点是不支持…...

【暴力洗盘】的实战技术解读-北玻股份和三变科技
龙头的上攻与回调动作都是十分惊人的。不惊人不足以吸引投资者的关注,不惊人也就不能成为龙头了。 1.建筑节能概念--北玻股份 建筑节能,是指在建筑材料生产、房屋建筑和构筑物施工及使用过程中,满足同等需要或达到相同目的的条件下…...

Day42:列表的组合
在Python 中,列表的组合是指将两个或多个列表合并成一个新的列表。Python 提供了多种方法来实现这一操作,每种方法都有其特定的应用场景。今天我们将学习如何通过不同的方式组合列表。 1. 使用 运算符进行列表合并 最直接的方式是使用 运算符&#x…...

mantisbt添加修改用户密码
文章目录 问题当前版本安装流程创建用户修改密码老的方式探索阶段 问题 不太好改密码啊。貌似必须要域名要发邮件。公司太穷,看不见的东西不关心,只能改源码了。 当前版本 当前mantisbt版本 2.27 php版本 7.4.3 安装流程 (下面流程不是…...

DroneXtract:一款针对无人机的网络安全数字取证工具
关于DroneXtract DroneXtract是一款使用 Golang 开发的适用于DJI无人机的综合数字取证套件,该工具可用于分析无人机传感器值和遥测数据、可视化无人机飞行地图、审计威胁活动以及提取多种文件格式中的相关数据。 功能介绍 DroneXtract 具有四个用于无人机取证和审…...

简单树形菜单
引言 在网页开发中,树形菜单是一种非常实用的,它可以清晰地展示具有层级关系的数据,并且能够方便用户进行导航和操作。 整体思路 整个项目主要分为三个部分:HTML 结构搭建、CSS 样式设计和 JavaScript 交互逻辑实现。通过 XMLHt…...

Windows 靶机常见服务、端口及枚举工具与方法全解析:SMB、LDAP、NFS、RDP、WinRM、DNS
在渗透测试中,Windows 靶机通常会运行多种服务,每种服务都有其默认端口和常见的枚举工具及方法。以下是 Windows 靶机常见的服务、端口、枚举工具和方法的详细说明: 1. SMB(Server Message Block) 端口 445/TCP&…...

RNN实现阿尔茨海默症的诊断识别
本文为为🔗365天深度学习训练营内部文章 原作者:K同学啊 一 导入数据 import torch.nn as nn import torch.nn.functional as F import torchvision,torch from sklearn.preprocessing import StandardScaler from torch.utils.data import TensorDatase…...

14-6-1C++STL的list
(一)list容器的基本概念 list容器简介: 1.list是一个双向链表容器,可高效地进行插入删除元素 2.list不可以随机存取元素,所以不支持at.(pos)函数与[ ]操作符 (二)list容器头部和尾部的操作 list对象的默…...

Redis事务机制详解与Springboot项目中的使用
Redis 的事务机制允许将多个命令打包在一起,作为一个原子操作来执行。虽然 Redis 的事务与关系型数据库的事务有所不同,但它仍然提供了一种确保多个命令顺序执行的方式。以下是 Redis 事务机制的详细解析: 1. Redis 事务的基本概念 Redis 事…...

DeepSeek-R1,用Ollama跑起来
# DeepSeek-R1横空出世,超越OpenAI-o1,教你用Ollama跑起来 使用Ollama在本地运行DeepSeek-R1的操作指南。 DeepSeek-R1作为第一代推理模型,在数学、代码和推理任务上表现优异,与OpenAI-o1模型不相上下。 将此类模型部署到本地&am…...

Leecode刷题C语言之组合总和②
执行结果:通过 执行用时和内存消耗如下: int** ans; int* ansColumnSizes; int ansSize;int* sequence; int sequenceSize;int** freq; int freqSize;void dfs(int pos, int rest) {if (rest 0) {int* tmp malloc(sizeof(int) * sequenceSize);memcpy(tmp, seque…...

2026年4月OpenClaw部署教程:阿里云快速部署OpenClaw、配置百炼APIKey、集成Skill详细方法
2026年4月OpenClaw部署教程:阿里云快速部署OpenClaw、配置百炼APIKey、集成Skill详细方法。OpenClaw(原Clawdbot)作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉&#x…...

关于整数和浮点数在内存中的存储
了解整数和浮点数在内存中的存储可以更有助于我们深入理解知识,在解一些题时也能起到重要的作用,是我们在学C中不可或缺的重要组成部分,接下来我简要介绍一下:首先,整数就是用二进制码存储。在内存中以补码的形式进行存…...

如何统计不同电话号码的个数?—位图法
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

JetBrains Runtime实战配置指南:解决IDE性能瓶颈的5个核心技巧
JetBrains Runtime实战配置指南:解决IDE性能瓶颈的5个核心技巧 【免费下载链接】JetBrainsRuntime Runtime environment based on OpenJDK for running IntelliJ Platform-based products on Windows, macOS, and Linux 项目地址: https://gitcode.com/gh_mirrors…...
告别Elsevier投稿焦虑:Elsevier Tracker的智能监控方案
告别Elsevier投稿焦虑:Elsevier Tracker的智能监控方案 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 作为科研工作者,你是否也曾经历过这样的困境:每天多次登录Elsevier投稿系统…...
)
PyTorch 3.0静态图分布式训练全链路解析(含NCCL拓扑感知、Graph Partitioning与梯度同步优化)
第一章:PyTorch 3.0静态图分布式训练概览与演进脉络PyTorch 3.0标志着框架在可扩展性与编译优化方向的重大跃迁——其核心变化之一是将TorchDynamo Inductor后端深度整合为默认的静态图编译通道,并原生支持跨设备、跨节点的分布式静态图训练。这一演进并…...

暗黑破坏神2存档编辑器终极指南:5分钟解放你的游戏体验
暗黑破坏神2存档编辑器终极指南:5分钟解放你的游戏体验 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为暗黑破坏神2中反复刷装备而烦恼吗?想快速体验不同职业build却不想从头练级?d2s-e…...

如何用Notepad--打造跨平台开发环境:国产编辑器的逆袭之路
如何用Notepad--打造跨平台开发环境:国产编辑器的逆袭之路 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- …...
)
4月3日(Claude Code深度解读)
Claude Code源码解读从雇佣一个程序员角度看实际上的他用户输入→ 动态组装 7 层系统提示词→ 注入 Git 状态、项目约定、历史记忆→ 42 个工具各自附带使用手册→ LLM 决定使用哪个工具→ 9 层安全审查(AST 解析、ML 分类器、沙箱检查...)→ 权限竞争解…...

如何解决OpenHTMLtoPDF在容器化环境中的字体加载NullPointerException问题
如何解决OpenHTMLtoPDF在容器化环境中的字体加载NullPointerException问题 【免费下载链接】openhtmltopdf An HTML to PDF library for the JVM. Based on Flying Saucer and Apache PDF-BOX 2. With SVG image support. Now also with accessible PDF support (WCAG, Section…...