Gurobi基础语法之addVar 和 addVars
addVar 和 addVars作为 Gurobi模型对象中的方法,常常用来生成变量,本文介绍了Python中的这两个接口的使用
addVar
addVar(lb=0.0, ub=float('inf'), obj=0.0, vtype=GRB.CONTINUOUS, name='', column=None)
lb 和 ub让变量在生成的时候就有下界和上届,
obj 确定了生成的变量在 目标函数的系数的取值
vtype 确定了变量取值的类型 (GRB.CONTINUOUS, GRB.BINARY, GRB.INTEGER, GRB.SEMICONT, or GRB.SEMIINT)
name 确定了这个参数的名字
column这个参数可以用来确定在已经存在的约束条件中这个变量的系数,但是由于在新版本中可以直接在生成约束条件(即调用addConstr)的时候就直接指定具体的约束条件,所以column参数并不经常使用,但是下面的代码还是给出这个参数的使用方法:
max 3x + 2y
x + y <= 10
2x + y <= 15
x >= 0, y >= 0
m = gp.Model("example")
m.setParam('OutputFlag', 0) # 优化完成后不打印许可和/或计算服务器信息
# 添加约束
c1 = m.addConstr(0, GRB.LESS_EQUAL, 10, name="c1")
c2 = m.addConstr(0, GRB.LESS_EQUAL, 15, name="c2")# 使用column参数添加变量
x = m.addVar(lb=0, ub=GRB.INFINITY, obj=3, vtype=GRB.CONTINUOUS, name="x", column=gp.Column([1, 2], [c1, c2]))
y = m.addVar(lb=0, ub=GRB.INFINITY, obj=2, vtype=GRB.CONTINUOUS, name="y", column=gp.Column([1, 1], [c1, c2]))# 设置目标函数:最大化 3x + 2y,由于所有的决策变量和约束条件都以已经确定,
# 而且gurobi中是默认最大化目标函数,所以下面这句话可以选择不打
# m.setObjective(3 * x + 2 * y, GRB.MAXIMIZE)# 优化模型
m.optimize()if m.status == GRB.OPTIMAL:# 打印结果
else:# 无解有了新版的设计,可以直接写成如下形式
m = gp.Model("example")
m.setParam('OutputFlag', 0)
x = m.addVar(lb=0, ub=GRB.INFINITY, vtype=GRB.CONTINUOUS, obj=3, name='x')
y = m.addVar(lb=0, ub=GRB.INFINITY, vtype=GRB.CONTINUOUS, obj=2, name='y')m.addConstr(x + y <= 10, name="c1")
m.addConstr(2 * x + y <= 15, name="c2")m.optimize()if m.Status == GRB.OPTIMAL:print(f'Optimal solution is {x.x}, {y.x}')print(f'Optimal value is {m.objVal}')
else:print("No solution!")值得注意的是:
1. 调用addVar变量之后,返回值是与addVar中传入的参数不同的,比如 写下 x = m.addVar() 这句代码之后,这个变量名 x 是你在Python代码中用来操作和引用这个变量的标识符。
而调用y = model.addVar(vtype=GRB.INTEGER, obj=1.0, name="y"),其中name = "y"的参数就是在Gurobi模型内部使用,用于在模型的输出、日志文件或错误消息中标识该变量
2.调用 addVar接口,其返回值的类型是 gurobipy.Var,返回的这个变量可以直接和整数进行加减乘除运算,运算的结果可以作为目标函数或者约束条件,但是不能直接与浮点数进行非线性运算,如 x = m.addVar(); x ** 0.5; 但是可以使用其他方法实现非线性约束的效果,具体可以看我其他的博客
addVars
addVars ( *indices , lb=0.0 , ub=float('inf') , obj=0.0 , vtype=GRB.CONTINUOUS , name='' )
与addVar不同的是,addVars的第一个参数是一个参数包,对这个参数包,可以传入多种形式的参数,包括:
1. 数字序列: x = m.addVars(2, 3, 2),x 是一个包含 2 * 3 * 2 个键值对的 tupledict
2. 单个list: x = m.addVars( [1, 2, 3, 4] ),x 是以 1, 2, 3, 4 为key 的 tupledict
3. 多个list: x = m.addVars( [1, 2], ['a', 'b'] ),x 是以(1, 'a') 和 (2, 'b')为 key 的tupledict
4. tuplelist: x = m.addVars( [ (3, 'a'), (7, 'b') ] ),x 是分别以这两个元组为 key 的 tupledict
可以看到addVars在调用的过程中会生成很多变量,这些变量应该怎么配合lb, ub, obj, vtype, name 这些参数,实现不同的变量设置不同的属性?
使用列表即可,比如如下代码
z = m.addVars(3, obj=[1.0, 2.0, 1.2], name=["a", "b", "c"])将会生成以0, 1, 2为key的三个键值对为tupledict对象的内容,其中z1的系数是1.0,在 gurobi 内部的名称是“a”, 以此类推,这样一下生成3个变量的同时,还可以规定这三个变量的系数和名称
addVar 和 addVars的返回值
addVar 的返回值类型是 <class 'gurobipy.Var'>
addVars 的返回值类型是 <class 'gurobipy.tupledict'>
所以想要使用这两种方法的返回值构建一个表达式,需要将 addVars 的返回值转成其他形式
可以使用 sum() 方法,代码示例如下
y = m.addVar(vtype=GRB.CONTINUOUS, name="y1")
z = m.addVars(3, obj=[1.0, 2.0, 1.2], name=["z1", "z2", "z3"])
m.update()
print(y + z.sum())代码将打印 y1 + z1 + z2 + z3
添加变量到底是在干什么?
我们知道,Gurobi 作为一个优化问题的求解器,构建模型的过程实际上就是在声明和定义变量,调用 addVar(s) 方法实际上就是将这些声明和定义后的变量进行暂存,
暂存过程包括对变量的暂存和对约束条件的暂存,
在调用addVar(s) 和 addConstr系列方法之后
1. 变量会被暂存到模型的内部变量列表中。这些变量在暂存状态下不会被完全初始化,但Gurobi会记录它们的基本信息,如变量类型、上下界、目标函数系数等,
2. 约束条件会被暂存到模型的内部约束列表中。这些约束在暂存状态下不会被完全初始化,但Gurobi会记录它们的基本信息,如约束类型、左侧表达式、右侧常数等
然后这些变量 / 表达式将 处于暂存状态
暂存状态的可视化
添加变量,并直接打印这个变量
z = m.addVars(3, obj=[1.0, 2.0, 1.2])
print(z)打印结果
{0: <gurobi.Var *Awaiting Model Update*>, 1: <gurobi.Var *Awaiting Model Update*>, 2: <gurobi.Var *Awaiting Model Update*>}
暂存的意义
-
性能优化
Gurobi在内部进行了优化,避免在每次添加变量或约束时立即进行更新,因为这可能会导致不必要的性能开销。通过将这些操作暂存起来,Gurobi可以在适当的时候一次性进行更新,提高效率。
-
批量处理
在添加大量变量和约束时,批量更新可以显著提高性能。例如,当你在循环中添加大量变量和约束时,调用一次 model.update() 比每次添加一个变量或约束后都调用 model.update() 要高效得多。
Gurobi 模型的 update() 方法
Gurobi 会遍历这些暂存的变量和约束,将它们完全初始化并添加到模型的内部数据结构中,所谓的添加到内部数据结构,就是给变量 / 约束分配一个唯一的索引
在调用 update() 方法之后,这些变量 / 表达式将 处于完全初始化状态
完全初始化状态的可视化
添加变量,更新之后再打印这个变量
z = m.addVars(3, obj=[1.0, 2.0, 1.2], name=["z1", "z2", "z3"])
m.update()
print(z)打印结果
{0: <gurobi.Var z1>, 1: <gurobi.Var z2>, 2: <gurobi.Var z3>}
相关文章:

Gurobi基础语法之addVar 和 addVars
addVar 和 addVars作为 Gurobi模型对象中的方法,常常用来生成变量,本文介绍了Python中的这两个接口的使用 addVar addVar(lb0.0, ubfloat(inf), obj0.0, vtypeGRB.CONTINUOUS, name, columnNone) lb 和 ub让变量在生成的时候就有下界和上届,…...
---函数)
C语言学习阶段性总结(五)---函数
函数构成五要素: 1、返回值类型 2、函数名 3、参数列表(输入) 4、函数体 (算法) 5、返回值 (输出) 返回值类型 函数名 (参数列表) { 函数体; return 返回值; } void 类型…...

K8S 快速实战
K8S 核心架构原理: 我们已经知道了 K8S 的核心功能:自动化运维管理多个容器化程序。那么 K8S 怎么做到的呢?这里,我们从宏观架构上来学习 K8S 的设计思想。首先看下图: K8S 是属于主从设备模型(Master-Slave 架构),即有 Master 节点负责核心的调度、管理和运维,Slave…...

java后端之事务管理
Transactional注解:作用于业务层的方法、类、接口上,将当前方法交给spring进行事务管理,执行前开启事务,成功执行则提交事务,执行异常回滚事务 spring事务管理日志: 默认情况下,只有出现Runti…...

【Redis】缓存+分布式锁
目录 缓存 Redis最主要的使用场景就是作为缓存 缓存的更新策略: 1.定期生成 2.实时生成 面试重点: 缓存预热(Cache preheating): 缓存穿透(Cache penetration) 缓存雪崩 (Cache avalan…...

二分查找题目:寻找两个正序数组的中位数
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法一思路和算法代码复杂度分析 解法二思路和算法代码复杂度分析 题目 标题和出处 标题:寻找两个正序数组的中位数 出处:4. 寻找两个正序数组的中位数 难度 8 级 题目描述 要求 给定两个大…...
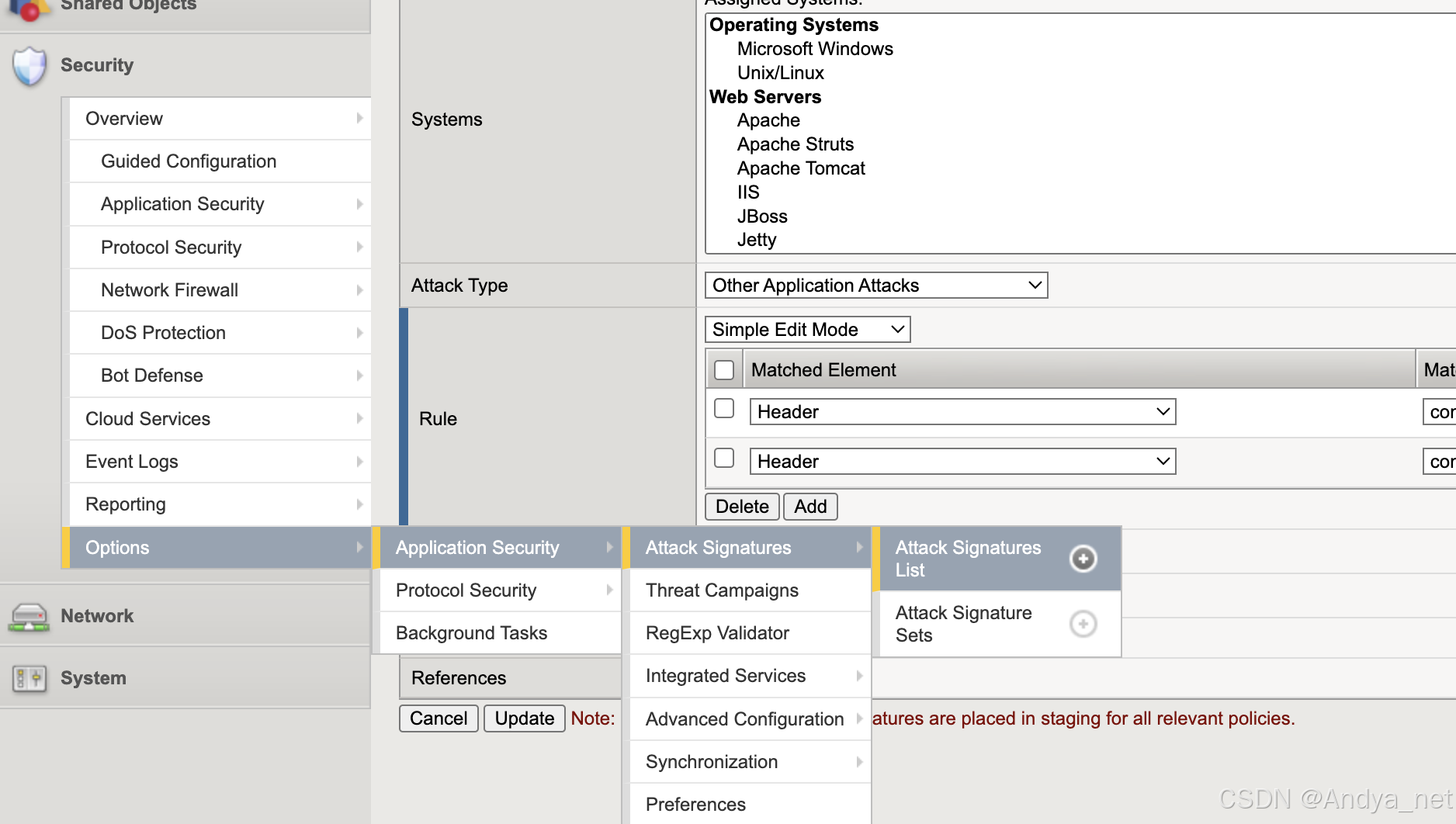
网络安全 | F5-Attack Signatures详解
关注:CodingTechWork 关于攻击签名 攻击签名是用于识别 Web 应用程序及其组件上攻击或攻击类型的规则或模式。安全策略将攻击签名中的模式与请求和响应的内容进行比较,以查找潜在的攻击。有些签名旨在保护特定的操作系统、Web 服务器、数据库、框架或应…...
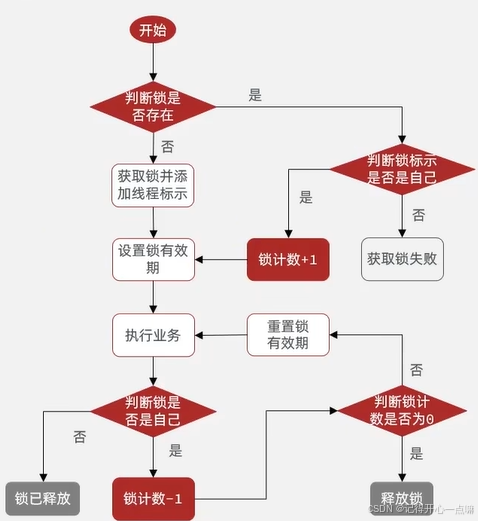
Redis --- 分布式锁的使用
我们在上篇博客高并发处理 --- 超卖问题一人一单解决方案讲述了两种锁解决业务的使用方法,但是这样不能让锁跨JVM也就是跨进程去使用,只能适用在单体项目中如下图: 为了解决这种场景,我们就需要用一个锁监视器对全部集群进行监视…...
--Java)
LeetCode100之全排列(46)--Java
1.问题描述 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案 示例1 输入:nums [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]] 示例2 输入:nums [0,1] 输出…...

goframe 博客分类文章模型文档 主要解决关联
goframe 博客文章模型文档 模型结构 (BlogArticleInfoRes) BlogArticleInfoRes 结构体代表系统中的一篇博客文章,包含完整的元数据和内容管理功能。 type BlogArticleInfoRes struct {Id uint orm:"id,primary" json:"id" …...

【JavaWeb06】Tomcat基础入门:架构理解与基本配置指南
文章目录 🌍一. WEB 开发❄️1. 介绍 ❄️2. BS 与 CS 开发介绍 ❄️3. JavaWeb 服务软件 🌍二. Tomcat❄️1. Tomcat 下载和安装 ❄️2. Tomcat 启动 ❄️3. Tomcat 启动故障排除 ❄️4. Tomcat 服务中部署 WEB 应用 ❄️5. 浏览器访问 Web 服务过程详…...

安卓日常问题杂谈(一)
背景 关于安卓开发中,有很多奇奇怪怪的问题,有时候这个控件闪一下,有时候这个页面移动一下,这些对于快速开发中,去查询,都是很耗费时间的,因此,本系列文章,旨在记录安卓…...

Kitchen Racks 2
Kitchen Racks 2 吸盘置物架 Kitchen Racks-CSDN博客...

嵌入式学习笔记-杂七杂八
文章目录 连续波光纤耦合激光器工作原理主要特点应用领域设计考虑因素 数值孔径(Numerical Aperture,简称NA)数值孔径的定义数值孔径的意义数值孔径的计算示例数值孔径与光纤 四象限探测器检测目标方法四象限划分检测目标的步骤1. 数据采集2.…...
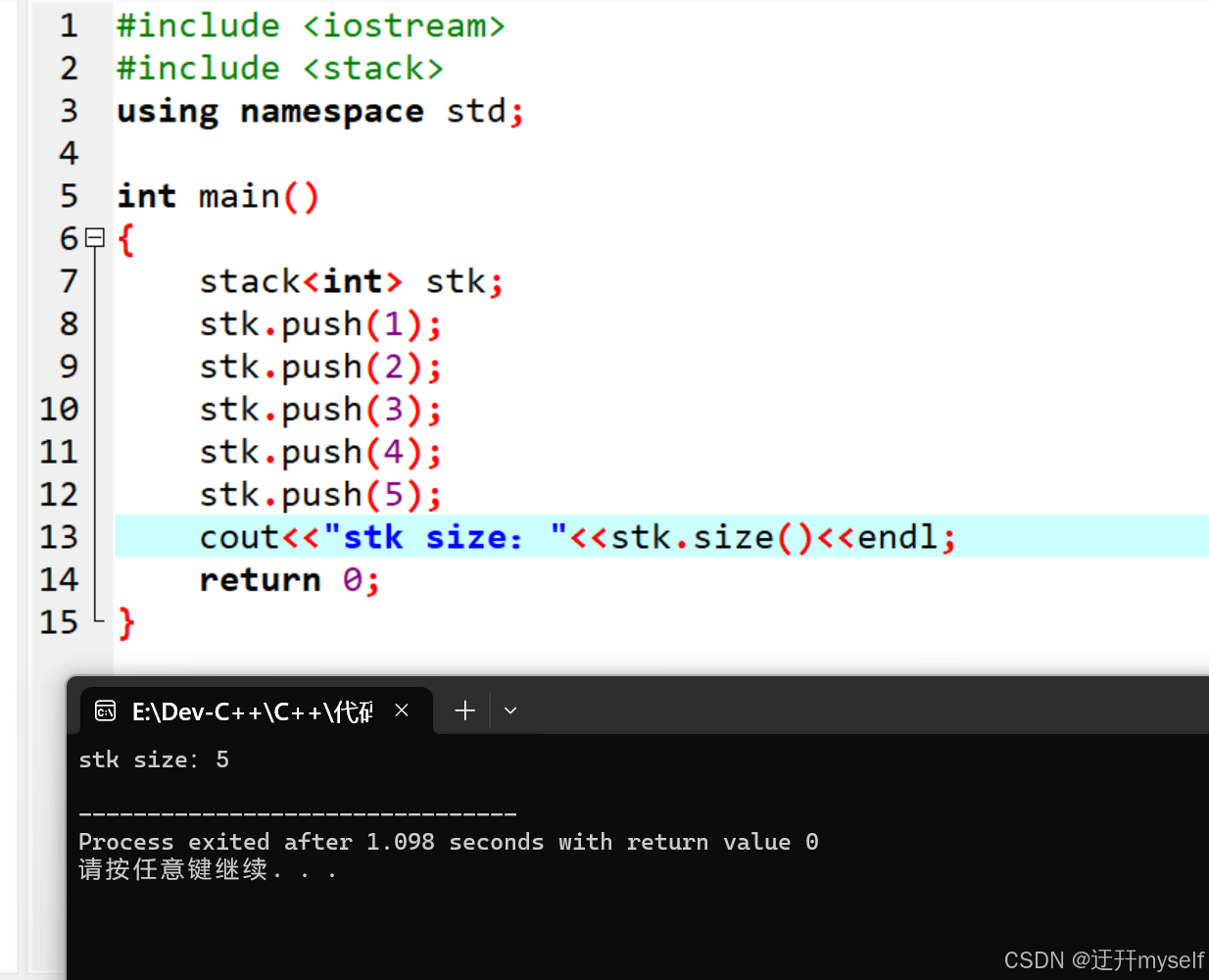
14-7C++STL的stack容器
(一)stack容器的入栈与出栈 (1)stack容器的简介 stack堆栈容器,“先进后出”的容器,且stack没有迭代器 (2)stack对象的默认构造 stack采用模板类实现,stack对象的默认…...

Vue 3 中的响应式系统:ref 与 reactive 的对比与应用
Vue 3 的响应式系统是其核心特性之一,它允许开发者以声明式的方式构建用户界面。Vue 3 引入了两种主要的响应式 API:ref 和 reactive。本文将详细介绍这两种 API 的用法、区别以及在修改对象属性和修改整个对象时的不同表现,并提供完整的代码…...

物业巡更系统助推社区管理智能化与服务模式创新的研究与应用
内容概要 在现代社区管理中,物业巡更系统扮演着至关重要的角色。首先,我们先来了解一下这个系统的概念与发展背景。物业巡更系统,顾名思义,是一个用来提升物业管理效率与服务质量的智能化工具。随着科技的发展,传统的…...
)
windows蓝牙驱动开发-生成和发送蓝牙请求块 (BRB)
以下过程概述了配置文件驱动程序生成和发送蓝牙请求块 (BRB) 应遵循的一般流程。 BRB 是描述要执行的蓝牙操作的数据块。 生成和发送 BRB 分配 IRP。 分配BRB,请调用蓝牙驱动程序堆栈导出以供配置文件驱动程序使用的 BthAllocateBrb 函数。;初始化 BRB…...
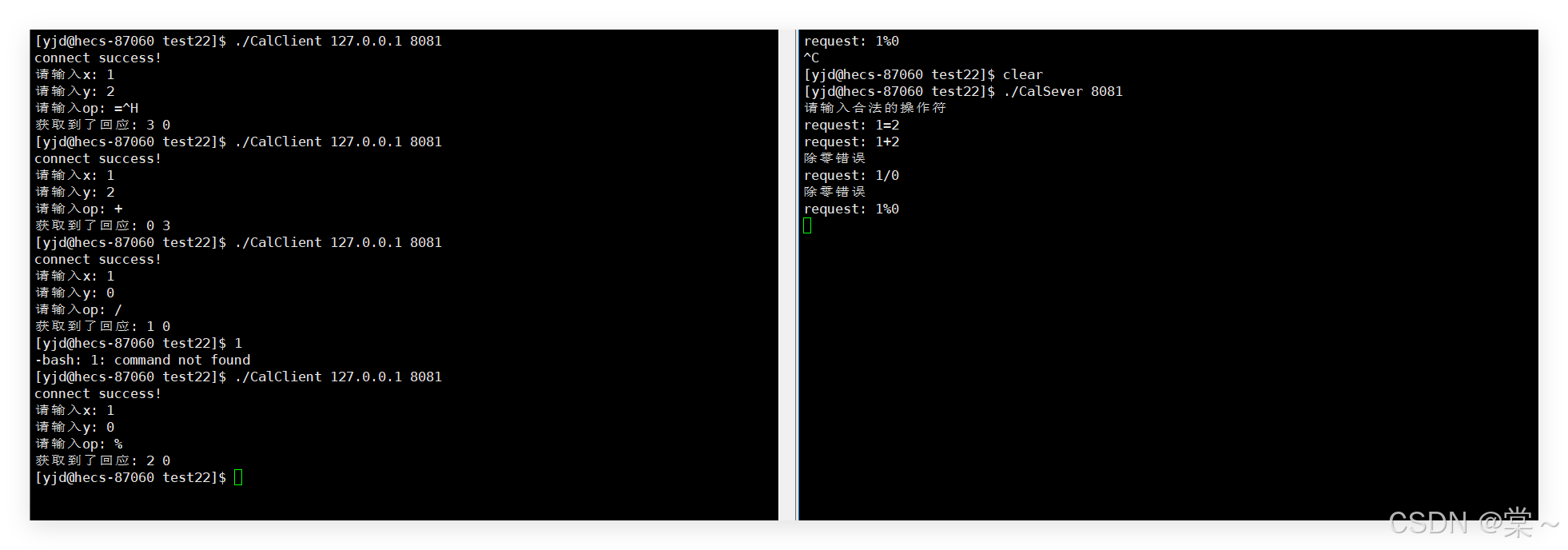
Linux网络之序列化和反序列化
目录 序列化和反序列化 上期我们学习了基于TCP的socket套接字编程接口,并实现了一个TCP网络小程序,本期我们将在此基础上进一步延伸学习,实现一个网络版简单计算器。 序列化和反序列化 在生活中肯定有这样一个情景。 上图大家肯定不陌生&a…...
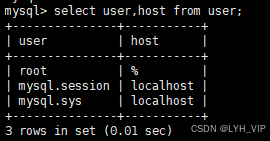
linux设置mysql远程连接
首先保证服务器开放了mysql的端口 然后输入 mysql -u root -p 输入密码后即可进入mysql 然后再 use mysql; select user,host from user; update user set host"%" where user"root"; flush privileges; 再执行 select user,host from user; 即可看到变…...

告别B站缓存碎片化:3步智能合并视频的终极解决方案
告别B站缓存碎片化:3步智能合并视频的终极解决方案 【免费下载链接】BilibiliCacheVideoMerge 项目地址: https://gitcode.com/gh_mirrors/bi/BilibiliCacheVideoMerge 你是否曾在高铁上打开B站缓存视频准备消遣时光,却发现播放器卡在开头几秒后…...

设备独立滚动控制:让macOS输入设备各得其所的开源解决方案
设备独立滚动控制:让macOS输入设备各得其所的开源解决方案 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 问题溯源:当滚动方向成为效率隐形杀手 在数字…...

Meshroom终极指南:从照片到3D模型的免费开源解决方案
Meshroom终极指南:从照片到3D模型的免费开源解决方案 【免费下载链接】Meshroom Node-based Visual Programming Toolbox 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom Meshroom是一款革命性的开源3D重建软件,能够将普通照片自动转换为…...

Qwen3-ForcedAligner-0.6B与LaTeX的学术工作流整合
Qwen3-ForcedAligner-0.6B与LaTeX的学术工作流整合 1. 引言 学术研究过程中,我们经常需要处理大量的访谈录音、讲座内容或实验讨论。传统的手工转录不仅耗时耗力,更让人头疼的是如何在最终论文中精准引用特定时间点的对话内容。想象一下,你…...

破局Windows Defender:重构系统防护管理的黑科技方案
破局Windows Defender:重构系统防护管理的黑科技方案 【免费下载链接】defender-control An open-source windows defender manager. Now you can disable windows defender permanently. 项目地址: https://gitcode.com/gh_mirrors/de/defender-control 当…...

YOLO X Layout部署教程:CentOS 7离线环境安装ONNX Runtime 1.16兼容包
YOLO X Layout部署教程:CentOS 7离线环境安装ONNX Runtime 1.16兼容包 1. 引言 如果你正在CentOS 7服务器上部署YOLO X Layout文档理解模型,可能会遇到一个常见问题:系统自带的ONNX Runtime版本太旧,而YOLO X Layout需要1.16或更…...

ComfyUI-Manager:一站式AI绘画插件智能管理平台
ComfyUI-Manager:一站式AI绘画插件智能管理平台 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various custom node…...

旧Mac焕新:使用OpenCore Legacy Patcher让2008-2017年设备支持最新macOS系统
旧Mac焕新:使用OpenCore Legacy Patcher让2008-2017年设备支持最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 老旧设备升级正成为越…...

CosyVoice语音克隆3步上手:5分钟搭建个人语音合成服务
CosyVoice语音克隆3步上手:5分钟搭建个人语音合成服务 1. 快速了解CosyVoice语音克隆 CosyVoice是由阿里巴巴通义实验室开发的多语言语音生成模型,它最吸引人的功能就是零样本声音克隆——只需要3-10秒的参考音频,就能克隆出相似度极高的合…...

IQuest-Coder-V1功能实测:一键生成高质量SQL查询脚本
IQuest-Coder-V1功能实测:一键生成高质量SQL查询脚本 在数据驱动的时代,SQL查询脚本的编写是每个数据分析师、后端工程师乃至产品经理的日常。面对复杂的业务逻辑和多表关联,手动编写SQL不仅耗时,还容易出错。有没有一种工具&…...