智能风控 数据分析 groupby、apply、reset_index组合拳
目录
groupby——分组
本例
apply——对每个分组应用一个函数
等价用法
reset_index——重置索引
使用前编辑
注意事项
groupby必须配合聚合函数、
关于agglist
一些groupby试验
1. groupby对象之后。sum(一个列名)
2. groupby对象之后。sum(2个列名)
3. groupby对象之后。sum(空)编辑
sum添加一个列明
一样,只有数字上榜编辑
sum添加俩列名编辑
书上官方:apply后自己定义列名
是否有列表框住很重要
其他用法
np。nansum
例axis=0 未指定列名,把他们放到了一个列表编辑
axis=0,指定列名,只有这个咧
编辑axis=1报错1啊编辑
df_g = df.groupby('uid') # 按照uid进行分组
gn = pd.DataFrame() # 创建一个空的DataFrame用于存储结果
for i in agg_list: # 遍历agg_list列表if isinstance(i, str): # 如果i是字符串类型tp = pd.DataFrame(df_g.groupby('uid').apply(lambda df: len(df[i])).reset_index()) # 对每个组应用lambda函数计算长度,并将索引重置tp.columns = ['uid', i + '_cnt'] # 设置列名if gn.empty == True: # 如果gn为空gn = tp # 将tp赋值给gnelse:gn = pd.merge(gn, tp, on='uid', how='left') # 合并gn和tpelif isinstance(i, int): # 如果i是整数类型tp = pd.DataFrame(df_g.groupby('uid').apply(lambda df: np.where(df[i] > 0, 1, 0).sum()).reset_index()) # 对每个组应用lambda函数计算满足条件的元素的和,并将索引重置tp.columns = ['uid', i + '_num']if gn.empty == True:gn = tpelse:gn = pd.merge(gn, tp, on='uid', how='left')elif isinstance(i, float): # 如果i是浮点数类型tp = pd.DataFrame(df_g.groupby('uid').apply(lambda df: np.nansum(df[i])).reset_index()) # 对每个组应用lambda函数计算非NaN值的和,并将索引重置tp.columns = ['uid', i + '_tot']if gn.empty == True:gn = tpelse:gn = pd.merge(gn, tp, on='uid', how='left')elif isinstance(i, list): # 如果i是列表类型tp = pd.DataFrame(df_g.groupby('uid').apply(lambda df: np.nanmean(df[i])).reset_index()) # 对每个组应用lambda函数计算平均值,并将索引重置tp.columns = ['uid', i + '_avg']if gn.empty == True:gn = tpelse:gn = pd.merge(gn, tp, on='uid', how='left')else: # 其他情况tp = pd.DataFrame(df_g.groupby('uid').apply(lambda df: np.nanmax(df[i])).reset_index()) # 对每个组应用lambda函数计算最大值,并将索引重置tp.columns = ['uid', i + '_max']if gn.empty == True:gn = tpelse:gn = pd.merge(gn, tp, on='uid', how='left')
groupby——分组
groupby 是 pandas 库中一个非常重要的功能,它用于将数据分组并对每个组应用函数。groupby 的基本用法是将 DataFrame 分成多个组,每个组由一个或多个唯一值定义。
语法:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False, **kwargs)
关键参数:
by: 用于分组的键,可以是列名、列名的列表或一个返回分组键的函数。axis: 指定分组是在哪个轴上进行的,默认为 0(行)。as_index: 默认为 True,表示返回的 DataFrame 中的分组键作为索引。如果设置为 False,则分组键将作为列返回。
本例
df.groupby('uid')
这会按照 ‘uid’ 列的值对 DataFrame 进行分组。
apply——对每个分组应用一个函数
apply 函数用于对 DataFrame 中的每个组应用一个函数。这个函数可以是自定义的,也可以是 pandas 中的内置函数。
语法:
DataFrameGroupBy.apply(func, *args, **kwargs)
关键参数:
func: 应用于每个组的函数。
例子:
df_g.apply(lambda df: np.sum(df['value']))
这会对每个组应用一个 lambda 函数,计算 ‘value’ 列的总和。
返回这个函数的结果dataframe
等价用法
其中,.df_g.apply(lambda df: np.sum(df['value']))等价于groupby对象.sum(列名即“value”)
例pd.DataFrame(customers_df.groupby(["Time"]).sum('CustomerID'))
reset_index——重置索引
reset_index 用于重置 DataFrame 的索引,或者将索引的级别转换为列。这在 groupby 操作后特别有用,因为 groupby 默认会将分组键作为索引。
语法:
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
关键参数:
level: 如果是多级索引,可以指定要重置的级别。drop: 如果为 True,则重置索引后,原始索引将不会作为列添加到 DataFrame 中。inplace: 如果为 True,则直接在原始 DataFrame 上修改,不返回新的 DataFrame。
例子:
df_g.reset_index()
这会将分组后的 DataFrame 的索引重置,并将原来的索引作为 DataFrame 的一列。
返回重置后的dataframe
使用前
使用后
结合以上三个功能,代码中的例子可以这样解释:
df_g = df.groupby('uid') # 按照列 'uid' 对 DataFrame 进行分组
gn = pd.DataFrame() # 创建一个空的 DataFrame 用于存储结果
for i in agg_list: # 遍历一个聚合操作的列表# ... 对每个分组应用不同的聚合函数 ...tp = pd.DataFrame(df_g[i].apply(lambda df: np.sum(df)).reset_index()) # 应用聚合函数并重置索引# ... 合并结果到 gn DataFrame ...
在这个例子中,groupby 用于创建分组,apply 用于对每个分组执行聚合操作,而 reset_index 用于将聚合后的结果转换为 DataFrame,并保留原始的分组键作为一列。
注意事项
groupby必须配合聚合函数、
聚合函数可以是groupby对象后面。后缀
、也可以是。apply自定义
当你使用 pd.DataFrame(customers_df.groupby(['Time', "CustomerID"])) 时,你实际上是将 groupby 对象转换成了一个 DataFrame。groupby 对象本身是一个中间对象,用于表示分组操作,它包含了原始 DataFrame 的分组信息,但并不包含聚合后的结果。
import pandas as pd# 客户信息 DataFrame
customers_df = pd.DataFrame({'CustomerID': [1, 2, 3, 4],'CustomerName': ['Alice', 'Bob', 'Charlie', 'David'],'Time': [10, 20, 10, 40]
})# 将 groupby 对象转换为 DataFrame
grouped_df = pd.DataFrame(customers_df.groupby(['Time', "CustomerID"]))print(grouped_df)
输出将是一个包含两个列的 DataFrame,这两个列是 'Time' 和 'CustomerID',它们表示分组键。这个 DataFrame 的每一行代表一个唯一的分组。但是,由于没有应用任何聚合函数,这个 DataFrame 不会包含任何关于分组内容的聚合信息。
输出看起来像这样:
Time CustomerID
0 10 1 1
1 20 2 2
2 10 3 3
3 40 4 4
解释:
groupby(['Time', "CustomerID"])创建了一个分组对象,这个对象根据 ‘Time’ 和 ‘CustomerID’ 的每个唯一组合对数据进行分组。- 由于没有指定聚合函数,转换成 DataFrame 后,它只是显示了分组键的组合,并没有显示每个组中的数据。
- 在这个特定的例子中,由于 ‘CustomerID’ 是唯一的,所以每个 ‘Time’ 和 ‘CustomerID’ 的组合都是唯一的,因此这个操作并没有实际上的分组效果,它只是简单地展示了每一行数据的 ‘Time’ 和 ‘CustomerID’。
如果你想要查看每个组中的数据,你应该在 groupby 后面应用聚合函数,例如 .size()、.sum()、.mean() 等,然后可能需要使用 .reset_index() 来将结果转换成一个 DataFrame。例如:
grouped_df = customers_df.groupby(['Time', "CustomerID"]).size().reset_index(name='Count')
print(grouped_df)
这将输出每个分组中的元素数量。
关于agglist
在Python中,当你在循环中使用for i in agg_list:时,agg_list通常是包含要处理的项或值的列表。在这个上下文中,agg_list可能包含一些聚合函数的名字或者是其他与数据处理相关的参数。具体来说,这取决于你正在进行的任务和你如何定义和使用agg_list。
例如,如果你的程序涉及到数据分析,并且你想对不同列的数据进行某种形式的聚合(如求和、平均值等),那么agg_list可能会包含字符串形式的函数名称,如['sum', 'mean'],然后在循环内部对这些函数进行处理。
再举一个具体的例子,假设你有如下代码片段:
python
复制
agg_list = ['sum', 'mean']
dataframe = pd.DataFrame(...) # 假设这是一个已经存在的DataFramefor func_name in agg_list:if func_name == 'sum':result = dataframe.sum()elif func_name == 'mean':result = dataframe.mean()# ... 其他可能的聚合函数处理 ...print(f"The {func_name} of the data is: {result}")
在这个例子中,agg_list就是一个包含字符串的列表,其中每个字符串代表一种聚合函数的名称。通过遍历这个列表,我们可以依次调用相应的聚合函数来处理数据。
总结一下,agg_list通常是一个列表,其中包含你要执行的某些操作的相关信息,如函数名称、参数等。具体的内容取决于你的编程需求和上下文。
书上:agg_list='oil_amount','discount_amount','sale_amount','amount',,'pay_amount','coupon_amount'等等。并不是前面所说的sum average之流
一些groupby试验
1. groupby对象之后。sum(一个列名)

仅显示为数字的列,name这列没写,并且另一列也作用了这个sum函数,即使没有写这一列的名字
2. groupby对象之后。sum(2个列名)

比1多了name一列,三列统统使用了sum操作,name是字符串的相加
3. groupby对象之后。sum(空)
与1相同的结果,name又没了
sum添加一个列明
一样,只有数字上榜
sum添加俩列名
 2or3结果一样,name上榜
2or3结果一样,name上榜
这个用法似乎不太正规
书上官方:apply后自己定义列名
这个结合apply及lambda自定义函数的方法会丢失列名且仅有此列
是否有列表框住很重要
无
name赫然在列
有

name消失 。且保留有其他数字的列
哪怕是只有一个列名的列表
其他用法
np。nansum

只能给他一列,多了会报错。
np.nanmin 是 NumPy 库中的一个函数,
——忽略nan的某函数们,具体有nanmin nanmax nanvar nansum nanmean
他们通常作用在一维nparray上
如果用到多维,需要指定axis
例axis=0 未指定列名,把他们放到了一个列表
axis=0,指定列名,只有这个咧
 axis=1报错1啊
axis=1报错1啊
用于计算数组中非 NaN (Not a Number) 值的最小值。当数组中包含 NaN 值时,标准的 min 函数会返回 NaN,而 np.nanmin 会忽略这些 NaN 值并返回剩余非 NaN 值中的最小值。
以下是 np.nanmin 的基本用法:
import numpy as np# 创建一个包含 NaN 值的数组
arr = np.array([1, 2, np.nan, 4, np.nan, 6])# 使用 np.nanmin 计算非 NaN 值的最小值
min_value = np.nanmin(arr)print(min_value) # 输出: 1
以下是 np.nanmin 的一些其他特性:
- 它可以接受一个
axis参数,用于计算指定轴上的最小值。 - 它可以接受一个
out参数,用于指定输出数组。
例子:
# 创建一个二维数组
arr_2d = np.array([[1, 2, np.nan], [np.nan, 4, 6], [7, np.nan, 9]])# 计算每一列的非 NaN 最小值
min_values_per_column = np.nanmin(arr_2d, axis=0)print(min_values_per_column) # 输出: [1 2 6]# 计算每一行的非 NaN 最小值
min_values_per_row = np.nanmin(arr_2d, axis=1)print(min_values_per_row) # 输出: [1 4 7]
在这个例子中,axis=0 表示沿着列的方向计算最小值,而 axis=1 表示沿着行的方向计算最小值。np.nanmin 会自动忽略每列或每行中的 NaN 值。
相关文章:
智能风控 数据分析 groupby、apply、reset_index组合拳
目录 groupby——分组 本例 apply——对每个分组应用一个函数 等价用法 reset_index——重置索引 使用前编辑 注意事项 groupby必须配合聚合函数、 关于agglist 一些groupby试验 1. groupby对象之后。sum(一个列名) 2. groupby对象…...

Python网络自动化运维---用户交互模块
文章目录 目录 文章目录 前言 实验环境准备 一.input函数 代码分段解析 二.getpass模块 前言 在前面的SSH模块章节中,我们都是将提供SSH服务的设备的账户/密码直接写入到python代码中,这样很容易导致账户/密码泄露,而使用Python中的用户交…...

【JVM】调优
目的: 减少minor gc、full gc的次数,也就是减少STW的时间,因为java虚拟机在做后台垃圾收集线程的时候,会停掉其他线程,专门做垃圾收集,这样会影响网站的性能,以及用户的体验。 调优位置&#x…...
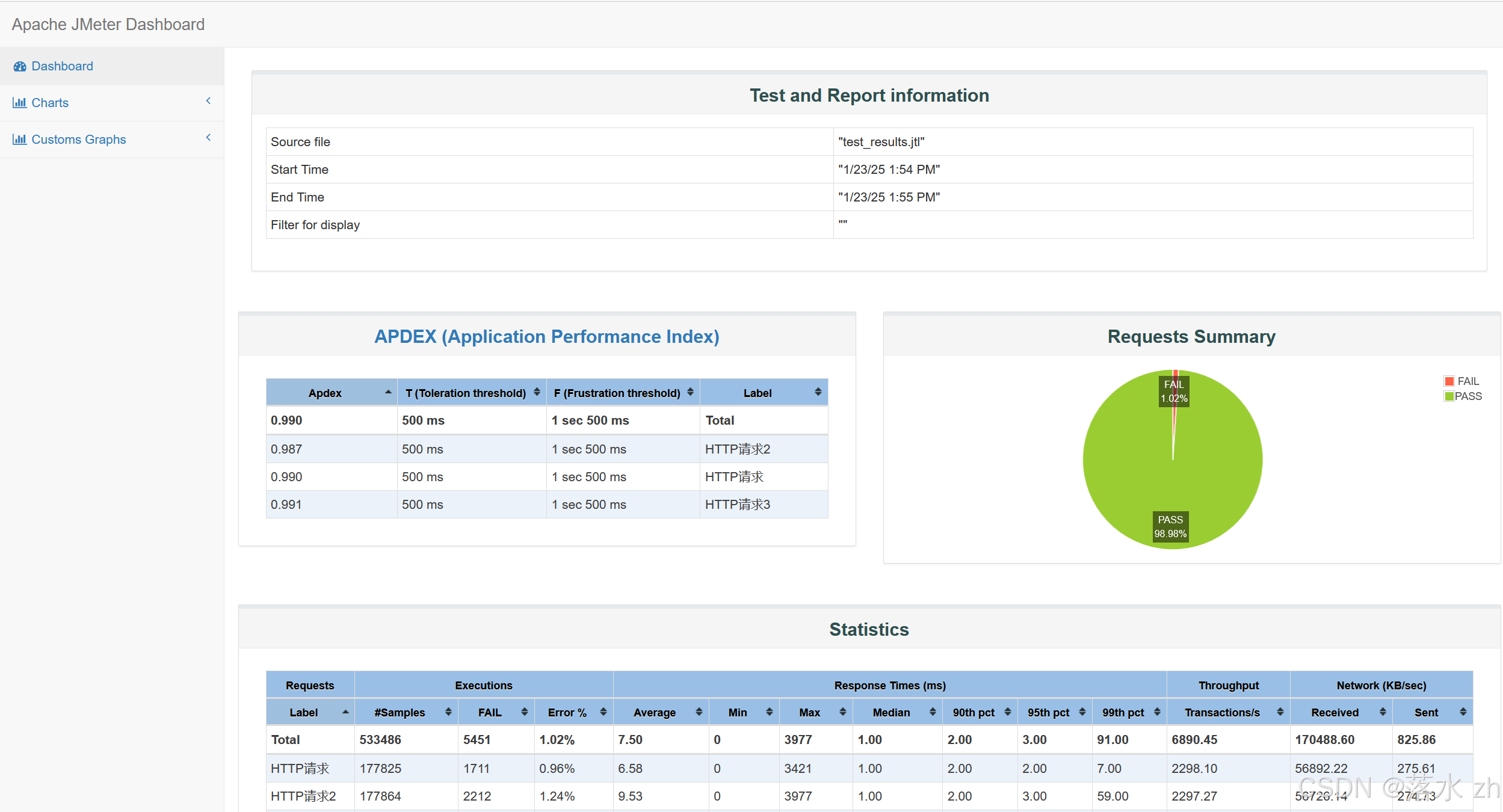
软件测试 —— jmeter(2)
软件测试 —— jmeter(2) HTTP默认请求头(元件)元件作用域和取样器作用域HTTP Cookie管理器同步定时器jmeter插件梯度压测线程组(Stepping Thread Group)参数解析总结 Response Times over TimeActive Thre…...
为什么LabVIEW适合软硬件结合的项目?
LabVIEW是一种基于图形化编程的开发平台,广泛应用于软硬件结合的项目中。其强大的硬件接口支持、实时数据采集能力、并行处理能力和直观的用户界面,使得它成为工业控制、仪器仪表、自动化测试等领域中软硬件系统集成的理想选择。LabVIEW的设计哲学强调模…...

【机器学习】自定义数据集 使用tensorflow框架实现逻辑回归并保存模型,然后保存模型后再加载模型进行预测
一、使用tensorflow框架实现逻辑回归 1. 数据部分: 首先自定义了一个简单的数据集,特征 X 是 100 个随机样本,每个样本一个特征,目标值 y 基于线性关系并添加了噪声。tensorflow框架不需要numpy 数组转换为相应的张量࿰…...

.NET Core缓存
目录 缓存的概念 客户端响应缓存 cache-control 服务器端响应缓存 内存缓存(In-memory cache) 用法 GetOrCreateAsync 缓存过期时间策略 缓存的过期时间 解决方法: 两种过期时间策略: 绝对过期时间 滑动过期时间 两…...
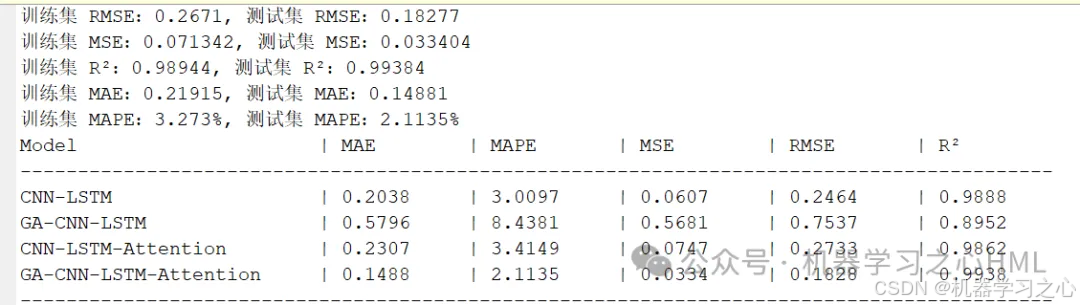
GA-CNN-LSTM-Attention、CNN-LSTM-Attention、GA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比
GA-CNN-LSTM-Attention、CNN-LSTM-Attention、GA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比 目录 GA-CNN-LSTM-Attention、CNN-LSTM-Attention、GA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比预测效果基本介绍程序设计参考资料 预测效果 基本介绍 基于GA-CNN-LST…...
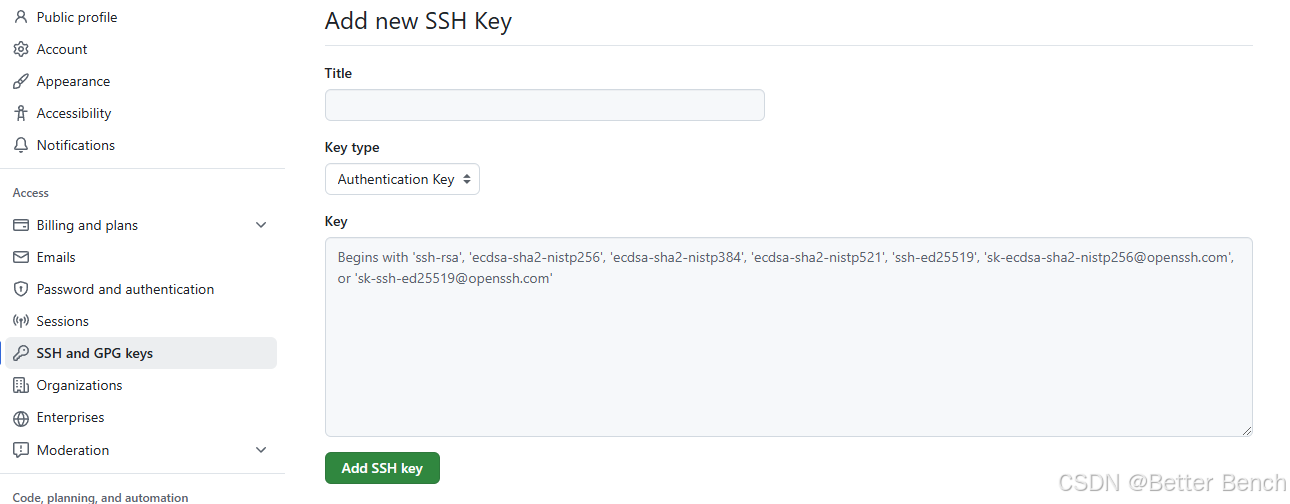
git Bash通过SSH key 登录github的详细步骤
1 问题 通过在windows 终端中的通过git登录github 不再是通过密码登录了,需要本地生成一个密钥,配置到gihub中才能使用 2 步骤 (1)首先配置用户名和邮箱 git config --global user.name "用户名"git config --global…...
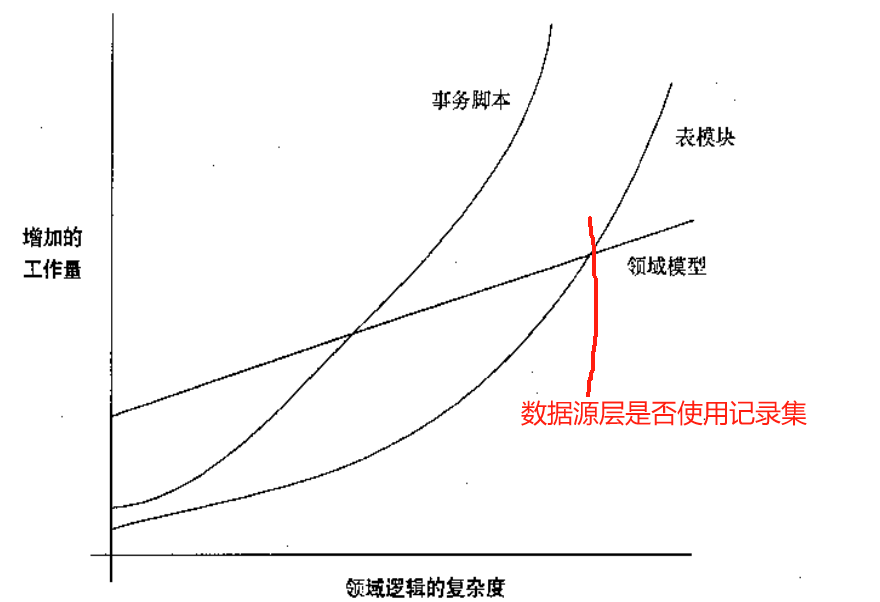
《企业应用架构模式》笔记
领域逻辑 表模块和数据集一起工作-> 先查询出一个记录集,再根据数据集生成一个(如合同)对象,然后调用合同对象的方法。 这看起来很想service查询出一个对象,但调用的是对象的方法,这看起来像是充血模型…...
 (void *)) _IO_funlockfile)
深入理解 C 语言函数指针的高级用法:(void (*) (void *)) _IO_funlockfile
深入理解 C 语言函数指针的高级用法 函数指针是 C 语言中极具威力的特性,广泛用于实现回调、动态函数调用以及灵活的程序设计。然而,复杂的函数指针声明常常让即使是有经验的开发者也感到困惑。本文将从函数指针的基本概念出发,逐步解析复杂…...

【JavaSE】图书管理系统
前言:为了巩固之前学习的java知识点,我们用之前学习的java知识点(方法,数组,类和对象,封装,继承,多态,抽象类,接口)来实现一个简单的图书管理系统…...

【C++数论】880. 索引处的解码字符串|2010
本文涉及知识点 数论:质数、最大公约数、菲蜀定理 LeetCode880. 索引处的解码字符串 给定一个编码字符串 s 。请你找出 解码字符串 并将其写入磁带。解码时,从编码字符串中 每次读取一个字符 ,并采取以下步骤: 如果所读的字符是…...

C++/stack_queue
目录 1.stack 1.1stack的介绍 1.2stack的使用 练习题: 1.3stack的模拟实现 2.queue的介绍和使用 2.1queue的介绍 2.2queue的使用 2.3queue的模拟实现 3.priority_queue的介绍和使用 3.1priority_queue的介绍 3.2priority_queue的使用 欢迎 1.stack 1.1stack…...

浅谈APP之历史股票通过echarts绘图
浅谈APP之历史股票通过echarts绘图 需求描述 今天我们需要做一个简单的历史股票收盘价格通过echarts进行绘图,效果如下: 业务实现 代码框架 代码框架如下: . 依赖包下载 我们通过网站下载自己需要的涉及的图标,勾选之后进…...

Ubuntu 20.04 x64下 编译安装ffmpeg
试验的ffmpeg版本 4.1.3 本文使用的config命令 ./configure --prefixhost --enable-shared --disable-static --disable-doc --enable-postproc --enable-gpl --enable-swscale --enable-nonfree --enable-libfdk-aac --enable-decoderh264 --enable-libx265 --enable-libx…...

【橘子Kibana】Kibana的分析能力Analytics简易分析
一、kibana是啥,能干嘛 我们经常会用es来实现一些关于检索,关于分析的业务。但是es本身并没有UI,我们只能通过调用api来完成一些能力。而kibana就是他的一个外置UI,你完全可以这么理解。 当我们进入kibana的主页的时候你可以看到这样的布局。…...

【STM32】-TTP223B触摸开关
前言 本文章旨在记录博主STM32的学习经验,我自身也在不断的学习当中,如果文章有写的不对的地方,欢迎各位大佬批评指正。 准备工作 今天这篇文章介绍的是触摸开关这一外围硬件。 ST-link调试器STM32最小系统板单路TTP223B触摸传感器模块LE…...

三星手机人脸识别解锁需要点击一下电源键,能够不用点击直接解锁吗
三星手机的人脸识别解锁功能默认需要滑动或点击屏幕来解锁。这是为了增强安全性,防止误解锁的情况。如果希望在检测到人脸后直接进入主界面,可以通过以下设置调整: 打开设置: 进入三星手机的【设置】应用。 进入生物识别和安全&a…...

Frida使用指南(三)- Frida-Native-Hook
1.Process、Module、Memory基础 1.Process Process 对象代表当前被Hook的进程,能获取进程的信息,枚举模块,枚举范围等 2.Module Module 对象代表一个加载到进程的模块(例如,在 Windows 上的 DLL,或在 Linux/Android 上的 .so 文件), 能查询模块的信息,如模块的基址、名…...

免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧
免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

CFD工程师必看:TVD格式选型指南——从SUPERBEE到UMIST,哪个才是你的菜?
CFD工程师必看:TVD格式选型实战指南——从工程场景到最优解 在计算流体力学(CFD)的世界里,TVD格式就像赛车手的轮胎选择——没有绝对的好坏,只有场景的适配。当你在汽车外气动分析中遇到激波振荡,或在燃烧模拟中面临虚假扩散时&am…...

韩国市场合规语音交付迫在眉睫!ElevenLabs韩文生成必须配置的4项GDPR+KCC隐私开关
更多请点击: https://intelliparadigm.com 第一章:韩国市场语音AI合规落地的紧迫性与战略意义 韩国《个人信息保护法》(PIPA)于2023年修订后,明确将语音生物特征数据列为“敏感信息”,要求语音AI系统在采集…...

Solon框架:微内核驱动的Java全栈云原生应用开发实践
1. 项目概述:从“微内核”到“全栈”的Java框架演进如果你在Java生态里摸爬滚打有些年头,肯定经历过从SSH(StrutsSpringHibernate)到SSM(Spring MVCSpringMyBatis)的架构变迁,也一定对Spring Bo…...

树莓派GPIO扩展实战:基于MCP23017芯片与Adafruit Bonnet
1. 项目概述:为什么你的树莓派需要GPIO扩展?玩树莓派的朋友,尤其是那些热衷于物联网、智能家居或者自动化项目的,肯定都经历过一个共同的烦恼:GPIO引脚不够用。树莓派引以为傲的40针GPIO排针,在连接了几个传…...

用Circuit Playground Express制作可穿戴互动闪光T恤:零焊接图形化编程入门
1. 项目概述:一件会“跳舞”的闪光T恤几年前,当我第一次把微控制器缝进衣服里时,那感觉既兴奋又麻烦——满桌子的电线、烙铁,还有对洗衣机深深的恐惧。但现在,像Adafruit的Circuit Playground Express(后面…...

Visual Paradigm 17.0 新特性解析:团队协作与项目管理效率跃升
1. Visual Paradigm 17.0 团队协作功能全面升级 Visual Paradigm 17.0 版本带来了多项针对团队协作的实用改进,让分布式团队的建模工作变得更加高效。作为一个长期使用该工具的老用户,我发现这次更新特别注重解决实际协作中的痛点问题。 首先说说模型搜索…...

工业智能化落地实践:从边缘AI到预测性维护的ST方案整合
1. 项目概述:一场工业智能化的深度对话最近刚参加完ST(意法半导体)的工业峰会回来,感触颇深。这场活动与其说是一场展会,不如说是一场关于“工业智能化如何落地”的深度行业对话。作为一家长期深耕工业通讯、物联网与嵌…...

深度学习篇---向量空间
向量空间(或称线性空间)是一个很美妙的数学结构。它不仅是线性代数的核心,更是我们理解很多高级概念(比如深度学习中的词向量、特征空间)的基础。简单说,向量空间就是一个定义了向量加法和数乘运算…...

ModelScope架构深度解析:大规模AI模型服务化实战指南
ModelScope架构深度解析:大规模AI模型服务化实战指南 【免费下载链接】modelscope ModelScope: bring the notion of Model-as-a-Service to life. 项目地址: https://gitcode.com/GitHub_Trending/mo/modelscope ModelScope作为阿里巴巴开源的模型即服务平台…...