基于 NodeJs 一个后端接口的创建过程及其规范 -- 【elpis全栈项目】
基于 NodeJs 一个后端接口的创建过程及其规范
一个接口的诞生:
流程简述:
- 首先通过
router-schema定义接口入参规则; - 然后在
router中定义接口; - 调用接口, 会经过一个
controller中间层处理业务逻辑,业务逻辑中的数据则是通过调用service来获取所需的数据; service则负责对数据的处理,中会封装一些对数据库增删改查的方法。
一、 router-schema: 请求规则
router-schema 中配置了每个接口所需的字段、类型、是否必填等信息。可以有效的规避掉客户端的一些无效请求,比如,下面这个接口中入参没有 ‘proj_key’ 的话,就无法通过校验会直接返回参数不合法的提示,节省了服务器资源。
'/api/project': {get: {query: {type: 'object',properties: { proj_key: { type: 'string' }, ...},required: ['proj_key']....}}}
他的配置需要遵循JSON schama 的规范;
而校验的是否符合规范的过程是由中间件去实现,本项目中通过 elpis-core 去实现,大概的思路就是:
- router-schema 中的配置会被挂载到全局的 app 实例上,可以通过
app.routerSchema['/api/project']去访问到每个接口的 schema 规则对象; - 然后借助一个中间件去实现校验:(如下是主要思路)
const Ajv = require('ajv'); // 需要安转ajv检验器const ajv = new Ajv();const $schema = "http://json-schema.org/draft-07/schema#" // 告知校验器(ajv),用什么规则去校验 const schema = app.routerSchema[path]schema.headers.$schema = $schema;let validate = ajv.compile(schema.query) // 读取path接口的schema,及其query的配置let valid = validate(query) // 校验数据
schema 配置文件示例:
--| router-schema--| project.js// 遵循 JSON schema 规范
module.exports = {'/api/project': {get: {query: {type: 'object',properties: {proj_key: {type: 'string'}},required: ['proj_key']}}},'/api/project/model_list': {get: {}}
}
JSON Schema 中文文档
二、 定义路由
使用koa-router 定义接口名称, 并传入一个 controller 中间件处理业务逻辑。
module.exports = (app, router) => {const { project: projectController } = app.controllerrouter.get('/api/project/list', projectController.getList.bind(projectController))router.get('/api/project/model_list', projectController.getModelList.bind(projectController))
}
三、 处理业务逻辑
对数据处理无非就是增删改查,而对数据库增删改查的方法是不变,而且是会被反复用到的。每个接口只是对增删改查的不同组合,所以为了保留这些方法的原子性。特地从接口和数据之间抽出一个中间层,用来处理不同接口的业务逻辑。由此 controller 中间层应孕而生。
可以在其中处理入参,构造响应数据等操作:
module.exports = (app) => {const BaseController = require('./base')(app)return class ProjectController extends BaseController {/*** 获取当前 projectKey 对应模型下的项目列表 (如果无 projectKey, 全量获取)*/async getList(ctx) {const { proj_key: projKey } = ctx.request.query;const { project: projectService } = app.service;const projectList = projectService.getList({ projKey })// 构造关键数据 listconst dtoProjectList = projectList.map(item => {// console.log('item', item)const { modelKey, key, name, desc, homePage } = item;return { modelKey, key, name, desc, homePage }});this.success(ctx, dtoProjectList)}}
}
四、 处理数据
目前还没有接入数据库,暂时引入本地 js文件模拟。
module.exports = (app) => {const BaseService = require('./base')(app)const modelList = require('../../model/index.js')(app)return class ProjectService extends BaseService {/*** 获取统一模型下的项目列表 (如果无 projkey, 取全量 )*/getList({ projKey }) {return modelList.reduce((preList, modelItem) => {const { project } = modelItem;// 如果存在 projectList 则只去当前同模型下的项目, 不传的情况下则取全量.if (projKey && !project[projKey]) {return preList};for (const pKey in project) {preList.push(project[pKey])}return preList;}, [])}async getModelList() {return modelList}}
}
全文特别鸣谢: 抖音“哲玄前端”,《全栈实践课》
相关文章:

基于 NodeJs 一个后端接口的创建过程及其规范 -- 【elpis全栈项目】
基于 NodeJs 一个后端接口的创建过程及其规范 一个接口的诞生: #mermaid-svg-46HXZKI3fdnO0rKV {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-46HXZKI3fdnO0rKV .error-icon{fill:#552222;}#mermaid-sv…...

企业知识库提升企业核心竞争力促进团队协作和知识分享
内容概要 在快速发展的数字化时代,企业知识库的构建与运用变得愈发重要。其重要性不仅体现在信息的集中管理上,更在于推动企业整体竞争力的提升。一个高效的知识库可以作为团队合作的重要平台,促进不同部门之间的信息交流与协作,…...

C++ unordered_map和unordered_set的使用,哈希表的实现
文章目录 unordered_map,unorder_set和map ,set的差异哈希表的实现概念直接定址法哈希冲突哈希冲突举个例子 负载因子将关键字转为整数哈希函数除法散列法/除留余数法 哈希冲突的解决方法开放定址法线性探测二次探测 开放定址法代码实现 哈希表的代码 un…...

games101-作业3
由于此次试验需要加载模型,涉及到本地环节,如果是windows系统,需要对main函数中的路径稍作改变: 这么写需要: #include "windows.h" 该段代码: #include "windows.h" int main(int ar…...

【Block总结】高效多尺度注意力EMA,超越SE、CBAM、SA、CA等注意力|即插即用
论文信息 标题: Efficient Multi-Scale Attention Module with Cross-Spatial Learning 作者: Daliang Ouyang, Su He, Guozhong Zhang, Mingzhu Luo, Huaiyong Guo, Jian Zhan, Zhijie Huang 论文链接: https://arxiv.org/pdf/2305.13563v2 GitHub链接: https://github.co…...

Pwn 入门核心工具和命令大全
一、调试工具(GDB 及其插件) GDB 启动调试:gdb ./binary 运行程序:run 或 r 设置断点:break *0x地址 或 b 函数名 查看寄存器:info registers 查看内存:x/10wx 0x地址 (查看 10 个 …...

探索AI(chatgpt、文心一言、kimi等)提示词的奥秘
大家好,我是老六哥,我正在共享使用AI提高工作效率的技巧。欢迎关注我,共同提高使用AI的技能,让AI成功你的个人助理。 "AI提示词究竟是什么?" 这是许多初学者在接触AI时的共同疑问。 "我阅读了大量关于…...

利用飞书机器人进行 - ArXiv自动化检索推荐
相关作者的Github仓库 ArXivToday-Lark 使用教程 Step1 新建机器人 根据飞书官方机器人使用手册,新建自定义机器人,并记录好webhook地址,后续将在配置文件中更新该地址。 可以先完成到后续步骤之前,后续的步骤与安全相关&…...
)
小白爬虫冒险之反“反爬”:无限debugger、禁用开发者工具、干扰控制台...(持续更新)
背景浅谈 小白踏足JS逆向领域也有一年了,对于逆向这个需求呢主要要求就是让我们去破解**“反爬机制”**,即反“反爬”,脚本处理层面一般都是decipher网站对request设置的cipher,比如破解一个DES/AES加密拿到key。这篇文章先不去谈…...

Ubuntu中MySQL安装-02
服务器端安装 安装服务器端:在终端中输入如下命令,回车后,然后按照提示输入 sudo apt-get install mysql-server 当前使用的ubuntu镜像中已经安装好了mysql服务器端,无需再安装,并且设置成了开机自启动服务器用于接…...

大数据相关职位介绍之一(数据分析,数据开发,数据产品经理,数据运营)
大数据相关职位介绍之一 随着大数据、人工智能(AI)和机器学习的快速发展,数据分析与管理已经成为各行各业的重要组成部分。从互联网公司到传统行业的数字转型,数据相关职位在中国日益成为推动企业创新和提升竞争力的关键力量。以…...

使用DeepSeek API生成Markdown文件
DeepSeek技术应用与代码实现 一、DeepSeek简介 DeepSeek是一款强大的人工智能写作助手,能够根据用户输入的提示(Prompt)快速生成高质量的文章。它不仅支持批量生成文章,还能通过智能分段、Markdown转HTML等功能优化内容。此外&…...

java多线程学习笔记
文章目录 关键词1.什么是多线程以及使用场景?2.并发与并行3.多线程实现3.1继承 Thread 类实现3.2Runnable 接口方式实现3.3Callable接口/Future接口实现3.4三种方式总结 4.常见的成员方法(重点记忆)94.1setName/currentThread/sleep要点4.2线程的优先级…...

Manticore Search,新一代搜索引擎之王
吊打ES,新一代搜索引擎之王 概述 Manticore Search 是一个开源的分布式搜索引擎,专注于高性能和低延迟的搜索场景。 它基于 Sphinx 搜索引擎开发,继承了 Sphinx 的高效索引和查询能力,并在分布式架构、实时搜索、易用性等方面进…...

【MySQL】数据类型与表约束
目录 数据类型分类 数值类型 tinyint类型 bit类型 小数类型 字符串类型 日期和时间类型 enum和set 表的约束 空属性 默认值 列描述 zerofill 主键 自增长 唯一键 外键 数据类型分类 数值类型 tinyint类型 MySQL中,整形可以是有符号和无符号的&…...

CAG技术:提升LLM响应速度与质量
标题:CAG技术:提升LLM响应速度与质量 文章信息摘要: CAG(Cache-Augmented Generation)通过预加载相关知识到LLM的扩展上下文中,显著减少了检索延迟和错误,从而提升了响应速度和质量。与传统的R…...

上位机知识篇---Linux源码编译安装链接命令
文章目录 前言第一部分:Linux源码编译安装1. 安装编译工具2. 下载源代码3. 解压源代码4. 配置5. 编译6. 测试(可选)7. 安装8. 清理(可选)9.注意事项 第二部分:链接命令硬链接(Hard Link…...
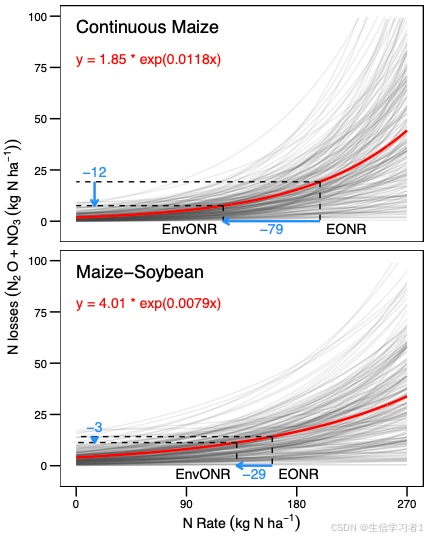
科研绘图系列:R语言绘制线性回归连线图(line chart)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍加载R包数据下载导入数据数据预处理画图保存图片系统信息参考介绍 科研绘图系列:R语言绘制线性回归连线图(line chart) 加载R包 library(tidyverse) library(ggthemes) libra…...

将ollama迁移到其他盘(eg:F盘)
文章目录 1.迁移ollama的安装目录2.修改环境变量3.验证 背景:在windows操作系统中进行操作 相关阅读 :本地部署deepseek模型步骤 1.迁移ollama的安装目录 因为ollama默认安装在C盘,所以只能安装好之后再进行手动迁移位置。 # 1.迁移Ollama可…...

Oracle 创建用户和表空间
Oracle 创建用户和表空间 使用sys 账户登录 建立临时表空间 --建立临时表空间 CREATE TEMPORARY TABLESPACE TEMP_POS --创建名为TEMP_POS的临时表空间 TEMPFILE /oracle/oradata/POS/TEMP_POS.DBF -- 临时文件 SIZE 50M -- 其初始大小为50M AUTOEXTEND ON -- 支持…...
)
Codex入门10-Goal自主任务(进阶必学:设定目标就不管了,AI自己干活到完成)
🎯 本文目标 掌握 /goal 持久化任务系统,让 Codex 自主完成复杂的大型工作。 🤔 /goal 和普通对话有什么区别? 对比 普通对话 /goal 任务 交互方式 一问一答 设定目标后AI自主工作 持久性 关终端就中断 关终端也能继续 适合任务 小任务、即时反馈 大任务、长期执行 计划…...

詹姆斯·韦伯望远镜:344个单点故障背后的航天工程极限挑战
1. 韦伯望远镜的“生死十日”:一场价值百亿美元的太空芭蕾作为一名在航天与深空探测领域摸爬滚打了十几年的工程师,我经历过无数次地面测试的紧张,也见证过发射倒计时的屏息瞬间。但像詹姆斯韦伯空间望远镜(JWST)这样&…...

复杂技术决策如何避免“竞选广告”陷阱?工程师必备的4项流程变革
1. 从一场“选举广告”引发的思考:工程师如何审视复杂系统设计午餐时看新闻,每个广告时段都被政治竞选广告塞满,内容无一例外都在攻击对手,却对自身主张闭口不谈。这场景让我这个在电子设计自动化(EDA)和半…...

怎样3步掌握桌面自动化:智能鼠标键盘录制工具完整攻略
怎样3步掌握桌面自动化:智能鼠标键盘录制工具完整攻略 【免费下载链接】KeymouseGo 类似按键精灵的鼠标键盘录制和自动化操作 模拟点击和键入 | automate mouse clicks and keyboard input 项目地址: https://gitcode.com/gh_mirrors/ke/KeymouseGo Keymouse…...

限流不是加个计数器就行:用 Lua 脚本实现多维度原子限流
限流不是加个计数器就行:用 Lua 脚本实现多维度原子限流 项目地址:interview-agent 技术栈:Java 21 / Spring Boot 4.0 / Redis 7 (Redisson) / PostgreSQL 问题:单维度限流挡不住真实场景 简历上传接口,你加了一个&q…...

抖音下载器:三步实现无水印高清素材批量获取
抖音下载器:三步实现无水印高清素材批量获取 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批…...

三维扫描平民化实战:从手机APP到高精度重建全流程指南
1. 项目概述:当三维扫描走下神坛几年前,如果你想获取一个真实物体的三维数字模型,那通常意味着你需要联系一家专业的三维扫描服务公司,支付一笔不菲的费用,然后等待专业人士用一台价格堪比一辆豪华轿车的设备ÿ…...

开源物联网平台SiteWhere:微服务架构下的设备管理与数据流实战
1. 项目概述:一个开源的物联网应用平台如果你正在寻找一个能帮你快速搭建、管理和扩展物联网应用的核心平台,而不是从零开始造轮子,那么SiteWhere这个开源项目绝对值得你花时间深入了解。它不是一个简单的设备连接网关,而是一个功…...

基于双链笔记构建个人消费知识系统:从记录到生活策展
1. 项目概述与核心价值看到“SimonsTang/xiaofei-liberal-arts”这个项目标题,我的第一反应是,这应该是一个关于“消费”与“文科”交叉领域的知识库或工具集。作为一名长期关注效率工具和知识管理的从业者,我深知在信息爆炸的时代࿰…...

Hermes Agent 可视化监控与文档生成工具 hermes-dashboard 详解
1. 项目概述与核心价值如果你正在使用 Hermes Agent 进行 AI 智能体开发,或者对 Agent 的内部运行状态感到好奇,那么你很可能需要一个“上帝视角”。hermes-dashboard正是这样一个工具,它为你提供了一个实时的监控仪表盘和一个自动生成的、可…...