概率统计之概率篇
概率统计之概率篇
一 随机变量及其四种研究方法
为了更深入地研究随机现象,需要把随机试验的结果数量化,也就是要引进随机变量来描述随机试验的结果。
一般地,把表示随机现象的各种结果或描述随机事件的变量叫做随机变量。随机变量通常用大写英文字母 X, Y, Z 等表示。
随机变量具有以下两个特点:
(1) 在一次试验前,不能预言随机变量取什么值。即随机变量的取值具有偶然性,它的取值决定于随机试验的结果。
(2) 随机变量的所有可能取值是事先知道的,而且对应于随机变量取某一数值或某一范围的概率也是确定的。
引进随机变量以后,就可以把对随机事件的研究转化为对随机变量的研究,从而可以引用微积分等其他数学理论和方法来研究随机现象。
用来刻画随机变量在某一方面的特征的常数就统称为数字特征。
那概率论干嘛要引入数字特征呢? 概率论的核心是算概率,算概率之前必须确定随机现象的规律(即确定模型),所以要引入随机变量,再确定随机变量的分布,在此基础上才解决了概率的计算问题。 但在实际问题中,分布通常很难很难很难确定,只好退而求其次,了解一下随机变量的大概规律,即随机变量的平均值,波动范围等,这些就是数字特征。
1.1 频数(Frequencies)
频数(frequency)又称“次数”。一组数据中,某个值出现的次数。
频率(relative frequency),一组数据中,某个值出现的比例。
Relativefrequency=FrequencynRelative\;frequency = {{Frequency\;} \over {\rm{n}}} Relativefrequency=nFrequency
概率,又称或然率、机会率、机率(几率)或可能性,是概率论的基本概念。概率是对随机事件发生的可能性的度量,一般以一个在0到1之间的实数表示一个事件发生的可能性大小。
1.2 数据位置(Measures of location)
1.2.1 平均数/ 均值(Average/ Mean)
平均数,是表示一组数据集中趋势的量数,是指在一组数据中所有数据之和再除以这组数据的个数。它是反映数据集中趋势的一项指标。`
特点:
- 易受极端值影响
- 数学性质优良
- 数据对称分布或接近对称分布时应用
1)算数平均数(Arithmetic average)
在一组数据中所有数据之和再除以数据的个数,是反映数据集中趋势的一项指标:
Xˉ=X1+X2+…+XnN=∑i=1nXiN\bar X = {{{X_1} + {X_2} + \ldots + {X_{\rm{n}}}} \over N} = {{\sum\limits_{i = 1}^n {{X_i}} } \over N} Xˉ=NX1+X2+…+Xn=Ni=1∑nXi
2)加权平均数(Weighted average)
加权平均数是不同比重数据的平均数,加权平均数就是把原始数据按照合理的比例来计算:
Xˉ=X1f1+X2f2+…+Xmfmf1+f2+...+fm=∑i=1mXifi∑i=1mfi\bar X = {{{X_1}{f_1} + {X_2}{f_2} + \ldots + {X_{\rm{m}}}{f_m}} \over {{f_1} + {f_2} + ... + {f_m}}} = {{\sum\limits_{i = 1}^m {{X_i}} {f_i}} \over {\sum\limits_{i = 1}^m {{f_i}} }} Xˉ=f1+f2+...+fmX1f1+X2f2+…+Xmfm=i=1∑mfii=1∑mXifi
1.2.2 众数(Mode)
众数是指在统计分布上具有明显集中趋势点的数值,代表数据的一般水平。 也是一组数据中出现次数最多的数值,有时众数在一组数中有好几个。用M表示。其特点:
- 组数据中出现次数最多的变量值
- 适合于数据量较多时使用
- 不受极端值的影响
- 一组数据可能没有众数也可能有几个众数
1.2.3 中位数(Median)
中位数又称中值,统计学中的专有名词,是按顺序排列的一组数据中居于中间位置的数,代表一个样本、种群或概率分布中的一个数值,其可将数值集合划分为相等的上下两部分。对于有限的数集,可以通过把所有观察值高低排序后找出正中间的一个作为中位数。如果观察值有偶数个,通常取最中间的两个数值的平均数作为中位数。其特点:
- 不受极端值的影响。在有极端数值出现时,中位数作为分析现象中集中趋势的数值,比平均数更具有代表性
- 主要用于顺序数据,也可以用数值型数据,但不能用于分类数据
- 各变量值与中位数的离差绝对值之和最小
1.2.4 四分位数(Quartile)
四分位数也称四分位点,是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。多应用于统计学中的箱线图绘制。它是一组数据排序后处于25%和75%位置上的值。四分位数是通过3个点将全部数据等分为4部分,其中每部分包含25%的数据。很显然,中间的四分位数就是中位数,因此通常所说的四分位数是指处在25%位置上的数值(称为下四分位数)和处在75%位置上的数值(称为上四分位数)。与中位数的计算方法类似,根据未分组数据计算四分位数时,首先对数据进行排序,然后确定四分位数所在的位置,该位置上的数值就是四分位数。
比如有以下8个数:1、2、4、5、6、8、32、64
Q1在第(8+1)/4=2.25位,介于第二和第三位之间,但是更靠近第二位;所以第二位数权重占75%,第三位数权重占25%:Q1=(20.75+40.25)/(0.75+0.25)=2.5;
Q2在第(8+1)/2=4.5位,即第4和第5位的平均数,Q2=5.5;
同理,Q3在第(8+1)/43=6.75位,在第6位和第7位之间,更靠近第7位;所以,第7位权重75%,第6位权重25%:Q3=(320.75+8*0.25)/(0.75+0.25)=26;
1.3 数据散布(Measures of spread/dispersion )
1.3.1 数学期望(Mathematical expectations)
数学期望是对长期价值的数字化衡量。
数学期望值是理想状态下得到的实验结果的平均值,是试验中每次可能的结果概率乘以其结果的总和,是最基本的数学特征之一,它反映随机变量平均取值的大小。换句话说,期望值像是随机试验在同样的机会下重复多次,所有那些可能状态的平均结果。****
离散型随机变量数学期望严格的定义如下:
设离散型随机变量 X 的分布列为$P{ X = {x_i}} = {P_i},i = 1,2,… $
若级数
∑i=1+∞xipi\sum_{i=1}^{+\infty} x_i p_i i=1∑+∞xipi
绝对收敛,则称∑i=1+∞xipi\sum_{i=1}^{+\infty} x_i p_i∑i=1+∞xipi级数的和为随机变量 X 的数学期望(也称期望或均值),记为 EX 。即
EX=x1p1+x2p2+⋯+xipi+⋯=∑i=1+∞xipiE X=x_1 p_1+x_2 p_2+\cdots+x_i p_i+\cdots=\sum_{i=1}^{+\infty} x_i p_i EX=x1p1+x2p2+⋯+xipi+⋯=i=1∑+∞xipi
连续型随机变量数学期望严格的定义如下:
设连续型随机变量 X 的概率密度函数为f(x)f(x)f(x),积分$\int_{ - \infty }^{ + \infty } {xf(x)dx} $ 绝对收敛,则定义X 的数学期望EX为:
EX=∫−∞+∞xf(x)dxEX = \int_{ - \infty }^{ + \infty } {xf(x)dx} EX=∫−∞+∞xf(x)dx
一个随机变量的数学期望是一个常数,它表示随机变量取值的一个平均;这里用的不是算术平均,而是以概率为权重的加权平均;数学期望反映了随机变量的一大特征,即随机变量的取值将集中在其期望值附近;这类似于物理中质点组成的质心。
数学期望和平均数的联系:
平均数是一个统计学概念,期望是一个概率论概念。平均数是实验后根据统计得到样本的平均值,期望是实验前根据概率分布“预测”的样本的平均值。如果说概率是频率随样本趋于无穷的极限,那么期望就是平均数随样本趋于无穷的极限。
1.3.2 方差(Variance)
方差用来描述随机变量与数学期望的偏离程度。
如果把单个数据点称为“Xi,” 因此 “X1” 是第一个值,“X2” 是第二个值,以此类推,一共有 n 个值。均值称为“M”。初看上去Σ(Xi-M)就可以作为描述数据点散布情况的指标,也就是把每个Xi与M的偏差求和。换句话讲,是(单个数据点—数据点的平均)的总和。 看上去挺有逻辑性的,但却有一个致命的缺点: 高出均值的值和低于均值可以相互抵消,因此,上述定义的结果趋近于0。这个问题可以取差值的绝对值来解决(也就是说,忽略负值的符号),但是由于各种神秘兮兮的原因,统计学家不喜欢绝对值。另外一个剔除负号的方法是取平方,因为任何数的平方肯定是正的。所以,我们就有了方差的分子Σ(Xi-M)2。
但有一种情况:例如我们现在有25个样本,根据方差算出标准差是10,但如果把25个样本复制一下变成50个样本的话,直接上50个样本的数据点的分布情况是不会改变,但实际确是我们公式中的累加会产生更大的方差值,所以我们需要通过除以数据点数量N来弥补这个漏洞。因此,方差的定义如下所示:
DX=∑i=1n(xi−x‾)nDX = \sum\limits_{{\rm{i}} = 1}^n {{{({x_i} - \overline x )} \over {\rm{n}}}} DX=i=1∑nn(xi−x)
DX 越小,意味着X较集中在数学期望 EX附近。反之,DX越大,意味着 X 的取值越分散。因此,DX 是刻画 X取值分散程度的一个量,是衡量X取值分散程度的一个尺度。
1.3.3 标准差(standard deviation)
标准差是通过方差除以样本量在开根得到的,具体公式如下:
σ=∑i=1n(xi−xˉ)2n\sigma=\sqrt{\frac{\sum_{i=1}^n\left(x_i-\bar{x}\right)^2}{n}} σ=n∑i=1n(xi−xˉ)2
与方差的作用类似,标准差也能反映一个数据集的离散程度,它是各点与均值的平均距离。平均数相同的数据,标准差未必相同。
1.3.4 极差(Range)
极差,又称范围误差或全距(Range),用字母R表示,计算方法是其最大值与最小值之间的差距,即最大值减最小值只有所得的数据。
1.3.5 四分数范围(Interquartile Range )
四分位数,即把所有数值由小到大排列成四等份,处于三个分割点的数值就是四分位数。第三四分位数与第一四分位数的插值就称为四分位数间距(InterQuartile Range, IQR),简称四分位距。
四分位距(interquartile range, IQR)是描述统计学中的一种方法,但由于四分位距不受极大值或极小值的影响,常用语描述非正态分布资料的离散程度,其数值越大,数据的离散程度越大,反之,则离散程度越小。
1.4 图形表示(Graphical methods)
以图像的方式来表示随机变量的分布,根据随机变量的数量可以选择合适的图像表示方法。常用的图像表示方法如下:
-
箱型图(Box plot):易于观察数据的分布密度。
-
直方图(Histogram):统计不同数据范围的频数,无线细化后可拟合概率密度曲线。
-
条形图(Bar Chart):适应于统计分类型离散数据。
-
散点图(Scatter Plot):易于观察两个变量的相关性。

二 随机变量及其分布
2.1 随机变量的类型和概率分布
要理解概率分布,就需要先知道:
- 数据有哪些类型
- 什么是分布
离散型随机变量
在统计学里,随机变量的数据类型有两种。
第1种是离散数据。离散数据根据名称很好理解,就是数据的取值是不连续的。例如掷硬币就是一个典型的离散数据,因为抛硬币的就2种数值(也就是2种结果,要么是正面,要么是反面)。
连续性随机变量
离散型随机变量都是建立在随机变量的值可以一一列举出来的基础上,但生活中的大多数情况是不可以列举出来的,而是连续的充满某个实数区间。
概率分布
概率分布清楚而完整的表示了随机变量X所取值的概率分布情况。离散型随机变量的概率分布可以用表格来表示,称之为分布列。
| X | x1 | x2 | x… | x1 |
|---|---|---|---|---|
| P | p1 | p2 | p… | p1 |
离散型随机变量的概率分布列具有下列性质:
- pk>=0,k=1,2,…
- ∑k=1+∞pk=1\sum_{k=1}^{+\infty} p_k=1∑k=1+∞pk=1
连续性随机变量的概率分布可用函数来表示:

在我们知道概率分布之后,我会想:为什么要去统计概率分布呢?概率分布的作用是什么呢?学了对我们有什么用呢?
当统计学家们开始研究概率分布时,他们看到,有几种形状反复出现,于是就研究他们的规律,根据这些规律来解决特定条件下的问题。
举例:就那你自己在备战高考语文作文来举例,我们经常给自己准备一个“万能模板”,任何作为题目过来,我们都可以直接套用该模板,快速解决作文这个难题。同样的,在我们记住这些概率论里面的特殊分布的好处就是在下次在遇到这类问题的时候,就可以“套用模板”。
概率分布可以被分为理论概率分布 Theoretical probabilities (theory driven) 和 经验概率分布 Empirical probabilities (data driven)
- Theoretical probabilities: 科学家总结出来的常见分布,具体分为离散型概率分布,如二项分布,泊松分布等等;和连续性概率分布,如指数分布,正太分布等等
- Empirical probabilities: 经验分布函数是对产生样本点的累积分布函数的估计,简单说是根据样本估计出来的分布。
2.2 理论概率分布之常见的离散型分布
2.2.1 二点(Bernoulli)分布
如果随机变量X 的分布列如下:
P{X=1}=p(0<p<1)P{X=0}=q=1−p\begin{aligned} & P\{X=1\}=p \quad(0<p<1) \\ & P\{X=0\}=q=1-p \end{aligned} P{X=1}=p(0<p<1)P{X=0}=q=1−p
则称X服从二点分布。二点分布页脚贝努力分布(Bernoulli)或 0-1 分布。
二点分布虽简单但很有用。当随机试验只有 2 个可能结果,且都有正概率时,就确定一个服从二点分布的随机变量。例如检查产品质量是否合格;检查某车间的电力消耗是否超过负荷;某射手对目标的一次射击是否中靶等试验都可以用服从二点分布的随机变量来描述。
2.2.2 二项(binomial)分布
如果随机变量X的概率分布为:
P{X=k}=Cnkpkqn−k,k=0,1,2,⋯,n,0<p<1,q=1−pP\{X=k\}=C_n^k p^k q^{n-k}, \quad k=0,1,2, \cdots, n, \quad 0<p<1, q=1-p P{X=k}=Cnkpkqn−k,k=0,1,2,⋯,n,0<p<1,q=1−p
则称X服从参数为n,p的二项分布。其中二项定理的系数计算方法如下:
Cnk=n!k!(n−k)!C_n^k=\frac{n !}{k !(n-k) !} Cnk=k!(n−k)!n!
二项分布用记号XB˜(n,p)X\~B(n,p)XB˜(n,p)来表示。
二项分布有啥用呢?当你遇到一个事情,如果该事情发生次数固定,而你感兴趣的是成功的次数,那么就可以用二项分布的公式快速计算出概率来。
如何判断是不是二项分布? 故明思义,,为啥叫二项,不叫三项,或者二愣子呢?二项代表事件有2种可能的结果,把一种称为成功,另外一种称为失败。生活中有很多这样2种结果的二项情况,例如你表白是二项的,一种成功,一种是失败。你向老板提出加薪的要求,结果也有二项的。 二项分布要符合下面4个特点:
- 做某件事的次数(也叫试验次数)是固定的,用n表示。
- 每一次事件都有两个可能的结果(成功,或者失败)。
- 每一次成功的概率都是相等的,成功的概率用p表示
- 你感兴趣的是成功x次的概率是多少。
2.2.3 几何(geometric)分布
几何分布实际上与二项分布非常的像,我们先看看几何分布的4个特点:
- 做某件事的次数(也叫试验次数)是固定的,用n表示。
- 每一次事件都有两个可能的结果(成功,或者失败)。
- 每一次成功的概率都是相等的,成功的概率用p表示
- 你感兴趣的是进行x次尝试这个事情,取得第1次成功的概率是多大。
正如你上面看到的,几何分布和二项分布只有第4点,也就是解决问题目的不同。例如,你表白你的暗恋对象,你希望知道要表白3次,心仪对象答应和你手牵手的概率多大就是求解一个几何分布
几何分布的数学公式如下:
p(x)=(1−p)x−1pp(x)=(1-p)^{x-1} p p(x)=(1−p)x−1p
p为成功概率,即为了在第x次尝试取得第1次成功,首先你要失败(x-1)次。
最后,几何分布的期望是E(x)=1/p。假如你每次表白的成功概率是60%,同时你也符合几何分布的特点,所以期望E(x)=1/p=1/0.6=1.67。这意味着表白1.67次(约等于2次)会成功。这样的期望让你信心倍增,起码你不需要努力上100次才能成功,2次还是能做到的,有必要尝试下。
2.2.4 泊松(Poisson)分布
如果随机变量X的概率分布为:
P{X=k}=λke−λk!,k=0,1,2,⋯P\{X=k\}=\frac{\lambda^k \mathrm{e}^{-\lambda}}{k !}, \quad k=0,1,2, \cdots P{X=k}=k!λke−λ,k=0,1,2,⋯
其中常数λ>0,则称X服从参数为λ的泊松分布,记为X~P(λ)。k 代表事情发的次数,λ 代表给定时间范围内事情发生的平均次数。
那么泊松分布有啥用? 如果你想知道某个时间范围内,发生某件事情x次的概率是多大。这时候就可以用泊松分布轻松搞定。比如一天内中奖的次数,一个月内某机器损坏的次数等。
知道这些事情的概率有啥用呢? 当然是根据概率的大小来做出决策了。比如你搞了个抽奖活动,最后算出来一天内中奖10次的概率都超过了90%,然后你顺便算了下期望,再和你的活动成本比一下,发现要赔不少钱。那这个活动就别搞了。
泊松分布符合以下3个特点:
1)事件是独立事件。
2)在任意相同的时间范围内,事件发的概率相同。
3)你想知道某个时间范围内,发生某件事情x次的概率是多大。
例如你搞了个促销抽奖活动,只知道1天内中奖的平均个数为4个,你想知道1天内恰巧中奖次数为8的概率是多少?
P{X=8}=488!e−4=0.0298{\rm{P}}\{ X = 8\} = {{{4^8}} \over {8!}}{e^{ - 4}} = 0.0298P{X=8}=8!48e−4=0.0298
最后,泊松概率还有一个重要性质,它的数学期望和方差相等,都等于 λ 。
2.2.5 离散型数据分布小结
- 概率分布的作用?
下次遇到类似的问题,你就可以直接套用“模板”(这些特殊分布的规律)来求得概率了。 - 常见的离散概率分布有哪些?
- 二点分布(Bernoulli distribution):表示一次试验只有两种结果即随机变量X只有两个可能的取值。
- 二项分布(Binomial distribution):你感兴趣的是成功x次的概率是多少。
- 几何何分布(Geometric distribution):你感兴趣的是,进行x次尝试这个事情,取得第1次成功的概率是多大。
- 泊松分布(poisson distribution):你想知道某个时间范围内,发生某件事情x次的概率是多大。
- 二点分布和二项分布的区别?
两点分布:是试验次数为1的伯努利试验。二项分布:是试验次数为n次的伯努利试验。
2.3 理论概率分布之常见的连续型分布
-
概率密度函数PDF(Probability Density Function)
对于连续型随机变量,由于其取值不能一 一列举出来,因而不能用离散型随机变量的分布列来描述其取值的概率分布情况。但人们在大量的社会实践中发现连续型随机变量落在任一区间[a,b]上的概率,可用某一函数 f (x) 在[a,b]上的定积分来计算。于是有下列定义:
定义 对于随机变量 f(x)f(x)f(x),如果存在非负可积函数 f(x)(−∞<x<+∞)f{\rm{ }}\left( x \right){\rm{ }}\left( { - \infty {\rm{ }} < {\rm{ }}x{\rm{ }} < {\rm{ }} + \infty } \right)f(x)(−∞<x<+∞),使对任意a,b (a < b) 都有
P{a≤X≤b}=∫abf(x)dxP\{ a \le X \le b\} = \int_a^b {f(x)dx} P{a≤X≤b}=∫abf(x)dx
则称 X 为连续型随机变量;并称 f (x) 为连续型随机变量 X 的概率密度函数(probability density function, PDF),简称概率密度,或密度函数。 -
累积分布函数 CDF(Cumulative Distribution Function)
不管f(x)f(x)f(x)是什么类型(连续/离散/其他)的随机变量,都可以定义它的累积分布函数(cumulative distribution function ,CDF)Fx(x){F_x}(x)Fx(x),有时简称为分布函数。对于连续性随机变量,CDF就是PDF的积分,PDF就是CDF的导数:
FX(x)=Pr(X≤x)=∫−∞xfx(t)dt{F_X}(x) = {P_r}(X \le x) = \int_{ - \infty }^x {{f_x}(t)dt} FX(x)=Pr(X≤x)=∫−∞xfx(t)dt
2.3.1 均匀(uniform)分布
设连续型随机变量 X 在有限区间[a,b]上取值,且它的概率密度为
f(x)={0其他1b−aa≤x≤bf(x) = \{ _{0 其他}^{{1 \over {b - a}}a \le x \le b} f(x)={0其他b−a1a≤x≤b
则称 X 服从区间[a,b]上的均匀分布,可记成 X ~ U [a,b]。
2.3.2 指数(exponential)分布
指数分布可以用来表示独立随机事件发生的时间间隔,比如旅客进机场的时间间隔等。 许多电子产品的寿命分布一般服从指数分布。有的系统的寿命分布也可用指数分布来近似。它在可靠性研究中是最常用的一种分布形式。
设连续型随机变量 X 的概率密度为

其中常数λ>0,则称X 服从参数为λ的指数分布,可记成X~E(λ)。
2.3.3 正态(normal distribution)分布
正态分布(normal distribution)又名高斯分布(Gaussian distribution),是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。若连续型随机变量 X 的密度函数为
f(x)=12πσe−(x−μ)22σ2,−∞<x<+∞f(x) = {1 \over {\sqrt {2\pi \sigma } }}{{\rm{e}}^{ - {{{{(x - \mu )}^2}} \over {2{\sigma ^2}}}}}, - \infty < x < + \infty f(x)=2πσ1e−2σ2(x−μ)2,−∞<x<+∞
其中,μ 为均值、σ为标准差。 μ,σ (σ > 0) 都为常数,则称 X 服从参数为 μ,σ 的正态分布,简记为XN˜(μ,σ2)X\~N(\mu ,{\sigma ^2})XN˜(μ,σ2)。因其曲线呈钟形,因此人们又经常称之为钟形曲线.我们通常所说的标准正态分布是μ = 0,σ = 1的正态分布。
正态分布的参数中,μ 决定了其位置,标准差σ2决定了分布的幅度。具体来说,若固定σ 而改变 μ 的值,则正态分布密度曲线沿着 x 轴平行移动,而不改变其形状,可见曲线的位置完全由参数 μ 确定。若固定 μ 而改变σ 的值,则当σ 越小时图形变得越陡峭;反之,当σ 越大时图形变得越平缓,如图

正态分布中一些值得注意的量:
- 密度函数关于平均值对称
- 平均值与它的众数(statistical mode)以及中位数(median)同一数值。
- 68.268949%的面积在平均数左右的一个标准差范围内。
- 95.449974%的面积在平均数左右两个标准差的范围内。
- 99.730020%的面积在平均数左右三个标准差的范围内。
- 99.993666%的面积在平均数左右四个标准差的范围内。
- 函数曲线的拐点(inflection point)为离平均数一个标准差距离的位置。
相关文章:
概率统计之概率篇
概率统计之概率篇 一 随机变量及其四种研究方法 为了更深入地研究随机现象,需要把随机试验的结果数量化,也就是要引进随机变量来描述随机试验的结果。 一般地,把表示随机现象的各种结果或描述随机事件的变量叫做随机变量。随机变量通常用大…...
综合项目 旅游网 【5.旅游线路收藏功能】
分析判断当前登录用户是否收藏过该线路当页面加载完成后,发送ajax请求,获取用户是否收藏的标记根据标记,展示不同的按钮样式编写代码后台代码RouteServlet/*** 判断当前登录用户是否收藏过该路线*/ public void isFavorite(HttpServletReques…...
【ArcGIS Pro二次开发】(3):UI管理_显示隐藏Tab、Group、Control等控件
在ArcGIS Pro工作中,有时候会涉及到工具栏UI的管理,比如,打开模型构建器时,工具栏才会出现新的选项卡(Tab)【ModelBuilder】,工程未做更改,则【保存】按钮显示灰色不可用。 下面以一个小例子来学习一下。 一…...
Spring Boot开发实战——echarts图标填充数据
echarts模块的导入 先看看成品吧! 有的图标的数据用了一些计算框架不是直接查数据库所以有点慢。 ok!😃 上正文,接上节Spring boot项目开发实战——(LayUI实现前后端数据交换与定义方法渲染数据)讲解了一般…...

李达聪老师:互联网时代的B2B品牌如何塑造
李达聪老师:互联网时代的B2B品牌如何塑造互联网时代企业对企业的品牌如何塑造?互联网时代信息传播速度加快,并且各大新品牌就如春天的竹笋涌出,有的昙花一现,有的趁着时代的红利乘胜追击占领市场,建立品牌。有的成为一…...

javaEE 初阶 — 连接管理机制
文章目录连接管理机制1. 建立连接(三次握手)2. 断开连接(四次挥手)TCP 的工作机制确认应答机制 超时重传机制 连接管理机制 比如 主机A 的空间存储了 主机B 的 ip 和 端口,主机B 的空间存储了 主机A 的 ip 和 端口。…...

40个改变你编程技能的小技巧!
40个改变编程技能的小技巧 1、将大块代码分解成小函数 2、今日事今日毕,如果没毕,就留到明天。 如果下班之前还没有解决的问题,那么你需要做的,就是关闭电脑,把它留到明天。 中途不要再想着问题了! 3、…...

iTOP3588开发板直连电脑配置方法(无线上网)配置主机IP
首先使用网线连接好主机和开发板,在没有上电的情况下,可以看到以太网显示网络电缆 被拔出,如下图所示: 当开发板上电以后,开发板网卡与笔记本电脑的网卡会连接,如下图所示: 然后右键点击以太网…...
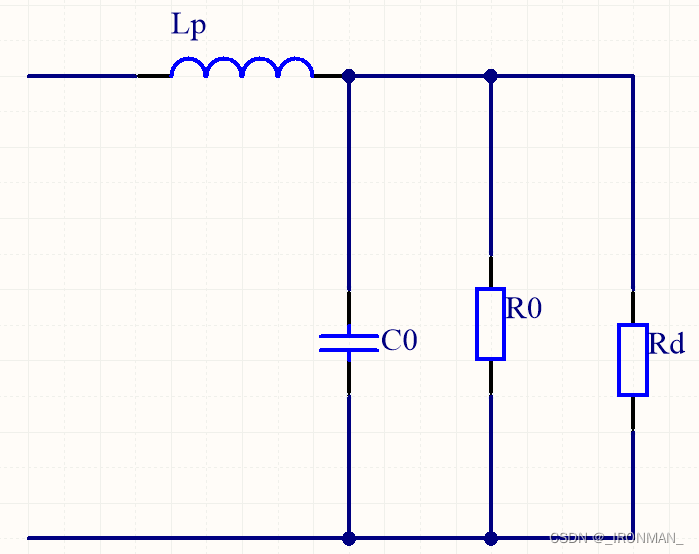
压电陶瓷换能器导纳圆图公式推导及匹配
压电陶瓷换能器的等效电路图如下图所示,分为左右两个部分左边的电容和电阻并联构成了电路的静态支路,被称为静态电容,可以由电表很方便的测量得到,这部分的参数是由换能器的电学参数决定的。右边的串联构成了动态支路,…...

设计模式C++实现11:观察者模式
参考大话设计模式; 详细内容参见大话设计模式一书第十四章,该书使用C#实现,本实验通过C语言实现。 观察者模式又叫做发布-订阅(Publish/Subscribe)模式。 观察者模式定义了一种一对多的依赖关系,让多个观察…...
l1和l2接口如何进行编写?一定要掌握这几个元素
在这个大数据时代,很多地方都需要用到l1和l2接口,l1和l2接口在应用程序与数据库之间起着桥梁的作用,是实现数据的整合与共享的重要帮手。 l1和l2接口适用于各行各业,应用场景的不断拓展,l1和l2接口的发展也兴起&#…...
GAMES101作业7及课程总结(重点实现多线程加速,微表面模型材质)
目录闲言碎语最终全部效果展示(均为10241024512ssp)课程总结与理解(Path Tracing)框架梳理任务一:迁移相关代码任务二:实现path tracing任务三:多线程加速(包括其他加速的小trick&am…...
面试题(二十四)数据结构与算法
9.1哈希 请谈一谈,hashCode() 和equals() 方法的重要性体现在什么地方? 考察点:JAVA哈希表 参考回答: Java中的HashMap使用hashCode()和equals()方法来确定键值对的索引,当根据键获取值的时候也会用到这两个方法。…...
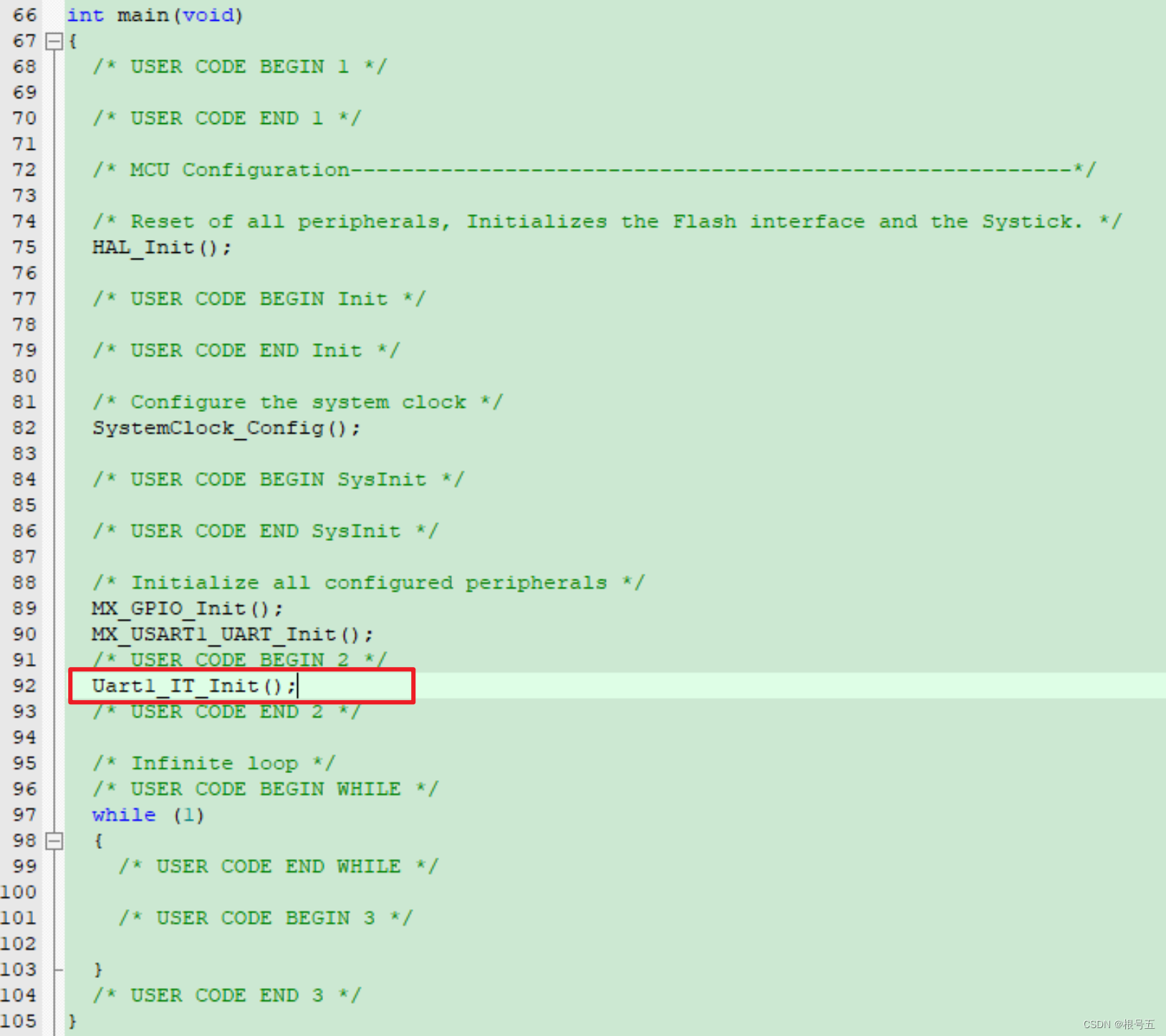
【HAL库】STM32CubeMX开发----STM32F407----Uart串口接收空闲中断
一、Uart串口接收空闲中断----详解 首先介绍串口通信的数据传输方式,这样后面的Uart串口空闲中断能更好的理解。 Uart串口通信----数据传输方式 串口通信的数据由发送设备通过自身的TXD接口传输到接收设备得RXD接口。 一个字符一个字符地传输,每个字符…...

Qt_文件操作
本文包含以下内容: 文件操作 基本介绍:ini文件:csv文件:代码功能文件读写:1.1 读取文件1.1.1按行读取1.1.2整体读取1.2 写入文件2. 文件信息读取3. 文件夹的创建4. 获取文件夹下所有的文件5. 获取文件夹及子文件夹下所有的文件用树的方式在界面显示文件夹目录基本介绍: …...

int和Integer有什么区别?
第7讲 | int和Integer有什么区别? Java 虽然号称是面向对象的语言,但是原始数据类型仍然是重要的组成元素,所以在面试中,经常考察原始数据类型和包装类等 Java 语言特性。 今天我要问你的问题是,int 和 Integer 有什么…...
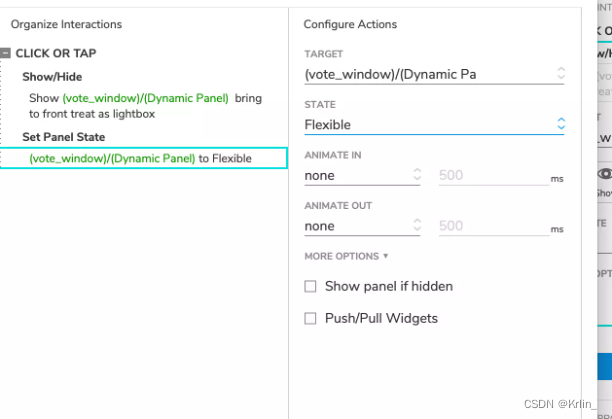
Axure 9 收录不同效果的制作过程
效果类别 一、默认选中实现单选效果 1、默认选中 点击组件,右键选择selected字样; 2、实现单选效果 点击所有组件,右键选择selected group,填好命名,并设置选中时的组件样式;选择其中一个组件…...

[Datawhale][CS224W]图神经网络(一)
目录一、导读1.1 当前图神经网络的难点1.2 图神经网络应用场景及对应的相关模型:1.3 图神经网络的应用方向及应用场景二、图机器学习、图神经网络编程工具参考文献一、导读 传统深度学习技术,如循环神经网络和卷积神经网络已经在图像等欧式数据和信号…...

【Android实现16位灰度图数据转RGB数据并以bitmap格式显示】
Android实现16位灰度图数据转RGB数据并以bitmap显示(单通道Gray数据转三通道RGB数据并显示) 需求发现问题解决方案需求 问题需求:项目上需要实现将深度相机传感器给出的数据实时显示出来的功能。经过了解得知,传感器给出的数据为16位灰度图数据,即16位数据表示一个像素的…...

uni-app②
文章目录二、微信小程序简介(一)文档相关开发者工具使用小程序代码构成小程序基本操作三、uniapp 开发规范uniapp 开发环境开发工具下载 HBuilderX工程搭建项目运行浏览器运行四、组件基础组件基础组件列表组件公共属性集合扩展组件自定义组件UNI-ICON五…...

数字永生:将意识上传云端的技术与伦理极限
——一个软件测试从业者的技术解构与风险分析各位同行,当你看到“数字永生”这四个字时,脑海里浮现的是什么?是马斯克口中2045年即将实现的意识上传,还是《黑镜》里那些被困在虚拟牢笼中的数字灵魂?作为一个每天与需求…...

先进制程重塑晶圆代工格局:从HPC需求到供应链博弈
1. 行业现状:先进制程如何重塑晶圆代工格局最近和几位在芯片设计公司负责流片的朋友聊天,大家讨论最激烈的,除了产能紧张,就是到底要不要、以及何时上更先进的工艺节点。一个普遍的共识是:7纳米和5纳米这类所谓“先进制…...

Windows10系统V-rep安装避坑指南:从百度网盘资源到环境配置
1. 为什么选择V-rep以及准备工作 如果你是机器人学或仿真技术的初学者,V-rep(现更名为CoppeliaSim)绝对是一个值得尝试的仿真平台。它轻量级、跨平台,而且对硬件要求不高,特别适合在个人电脑上进行算法验证和教学演示…...

2026毕业季必看!告别求职死循环,这两个高薪赛道让你稳上岸!
家人们谁都没想到,2026年毕业季求职难度直接拉满,堪称历年最难就业季!全国1270万高校毕业生扎堆涌入求职市场,岗位僧多粥少、竞争内卷到极致,无数应届生陷入一模一样的求职困境:精心打磨的简历海投出去&…...

CoverM如何革新宏基因组覆盖率分析:从短读长到PacBio HiFi的完整解决方案
CoverM如何革新宏基因组覆盖率分析:从短读长到PacBio HiFi的完整解决方案 【免费下载链接】CoverM Read alignment statistics for metagenomics 项目地址: https://gitcode.com/gh_mirrors/co/CoverM 宏基因组研究正经历着从短读长测序到长读长技术的深刻变…...

Taotoken如何助力AIGC内容创作团队平衡效果与成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何助力AIGC内容创作团队平衡效果与成本 对于专注于短视频脚本、营销文案等AIGC内容生产的团队而言,频繁调用…...

3步掌握SubtitleOCR:从视频到可编辑字幕的智能转换指南
3步掌握SubtitleOCR:从视频到可编辑字幕的智能转换指南 【免费下载链接】SubtitleOCR 快如闪电的硬字幕提取工具。仅需苹果M1芯片或英伟达3060显卡即可达到10倍速提取。A very fast tool for video hardcode subtitle extraction 项目地址: https://gitcode.com/g…...
 深度诊断与流量整形方案)
lsyncd rsyncssh同步中断:Broken pipe (32) 深度诊断与流量整形方案
1. 问题现象与初步诊断 最近在帮客户部署lsyncdrsyncssh方案时,遇到了一个典型问题:同步25GB目录时,总是在传输4GB左右中断。日志里反复出现"Broken pipe (32)"错误,就像下面这样: packet_write_wait: Conne…...

LibreHardwareMonitor:你的电脑健康管家,硬件监控从此无忧
LibreHardwareMonitor:你的电脑健康管家,硬件监控从此无忧 【免费下载链接】LibreHardwareMonitor Libre Hardware Monitor is free software that can monitor the temperature sensors, fan speeds, voltages, load and clock speeds of your computer…...

UniversalUnityDemosaics:Unity游戏马赛克去除全攻略
UniversalUnityDemosaics:Unity游戏马赛克去除全攻略 【免费下载链接】UniversalUnityDemosaics A collection of universal demosaic BepInEx plugins for games made in Unity3D engine 项目地址: https://gitcode.com/gh_mirrors/un/UniversalUnityDemosaics …...