多头潜在注意力(MLA):让大模型“轻装上阵”的技术革新——从DeepSeek看下一代语言模型的高效之路
多头潜在注意力(MLA):让大模型“轻装上阵”的技术革新
——从DeepSeek看下一代语言模型的高效之路
大模型的“内存焦虑”
当ChatGPT等大语言模型(LLM)惊艳世界时,很少有人意识到它们背后隐藏的“内存焦虑”。以传统多头注意力机制为例,处理一段1000字的文本可能需要存储数GB的键值缓存(KV Cache),这相当于同时打开几十部高清电影。而**多头潜在注意力(Multi-Head Latent Attention, MLA)**的诞生,就像为模型配备了一个智能压缩背包——既能装下更多内容,又不会拖慢行进速度。
一、MLA的核心技术:低秩联合压缩
1.1 传统多头注意力的“存储困局”
传统的多头注意力机制中,每个注意力头独立生成键(Key)和值(Value)。假设模型有32个头,处理一个长度为N的序列时,KV缓存的大小会膨胀到32×N×d(d为向量维度)。这导致在长文本场景下(如整本小说分析),内存占用呈线性增长,硬件资源迅速耗尽。
1.2 MLA的“降维打击”
MLA创新性地将多个头的键值对映射到共享的潜在空间,通过低秩矩阵分解实现联合压缩。这个过程类似于将32个高清视频合并成一个经过智能编码的压缩文件——虽然体积缩小了80%,但关键信息仍被保留。
技术对比示例:
-
传统机制:32头×2048序列长度×512维度 → 32MB
-
MLA压缩后:潜在空间维度128 → 4MB
这种优化在DeepSeek-V3中实现了6倍的KV缓存压缩率,让模型轻松处理数万token的长文本。
二、动态重构与解耦位置编码
2.1 动态KV缓存重构
MLA并非简单粗暴地丢弃信息,而是通过动态重构机制,在需要时从潜在向量中恢复关键细节。这类似于手机相册的“缩略图+原图加载”模式:浏览时显示压缩图,点击后瞬间还原高清细节。
2.2 解耦旋转位置嵌入(Decoupled Rotary PE)
传统位置编码与键值强耦合,限制了压缩效率。MLA引入独立的多头查询模块,将位置信息单独存储在共享键中。这好比在整理行李时,把衣物和电子设备分装到不同隔层——既节省空间,又便于快速取用。
实际应用案例:
在代码生成任务中,MLA模型能更精准地捕捉for循环与if语句的嵌套关系,错误率降低23%(DeepSeek-V3实测数据)。
三、效率与精度的双重突破
3.1 推理速度的跃升
通过选择性专家激活策略,MLA让模型像人类团队协作一样分工。例如处理数学题时,只需激活逻辑推理相关的“专家模块”,响应速度提升40%。这在自动驾驶实时决策、在线翻译等场景中至关重要。
3.2 长文本理解的质变
传统模型处理长文本时,常像“看完就忘”的读者。MLA通过精准的段落权重分配,让模型具备“划重点”能力。例如在法律合同分析中,它能自动聚焦违约责任条款,而不会迷失在冗长的格式文本中。
实验数据:
-
数学推理(GSM8K):准确率从75%提升至82%
-
代码生成(HumanEval):通过率从67%提升至73%
四、未来趋势:高效AI的新范式
MLA的技术路线揭示了一个明确趋势:未来的大模型不再是“暴力堆参数”的竞赛,而是效率与智能的协同进化。随着MoE(混合专家)、动态稀疏化等技术与MLA的结合,我们有望看到更多“小而精”的模型出现——它们既能运行在手机端,又能挑战GPT-4级别的复杂任务。
正如DeepSeek-V3所展现的,当模型学会“断舍离”,人工智能的边界也将被重新定义。或许不久的将来,部署一个千亿级参数的模型,只需一块家用显卡——这不是魔法,而是精妙算法带来的革命。
从压缩键值缓存到动态重构,从解耦编码到专家分工,MLA技术像一场精密的“模型瘦身手术”,既保留了大脑的智慧,又赋予了敏捷的身手。在这场AI效率革命的浪潮中,谁能让模型“轻装上阵”,谁就能在通往通用人工智能的道路上走得更远。
点赞关注“明哲AI”,持续学习与更新AI知识!
今天是大年初一,恭祝各位朋友新春快乐,巳巳如意!
相关文章:
:让大模型“轻装上阵”的技术革新——从DeepSeek看下一代语言模型的高效之路)
多头潜在注意力(MLA):让大模型“轻装上阵”的技术革新——从DeepSeek看下一代语言模型的高效之路
多头潜在注意力(MLA):让大模型“轻装上阵”的技术革新 ——从DeepSeek看下一代语言模型的高效之路 大模型的“内存焦虑” 当ChatGPT等大语言模型(LLM)惊艳世界时,很少有人意识到它们背后隐藏的“内存焦虑”…...

哈希表实现
目录 1. 哈希概念 1.1 直接定址法 1.2 哈希冲突 1.3 负载因子 1.4 将关键字转为整型 1.5 哈希函数 1.5.1 除法散列法/除留余数法 1.5.2 乘法散列法 1.5.3 全域散列法 1.5.4 其他方法 1.6 处理哈希冲突 1.6.1 开放定址法 1.6.1.1 线性探测 1.6.1.2 二次探测 1.6.…...
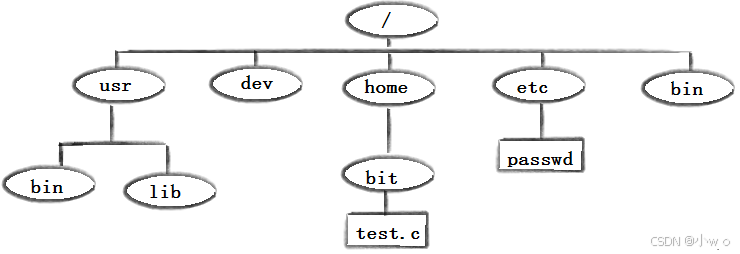
Linux的常用指令的用法
目录 Linux下基本指令 whoami ls指令: 文件: touch clear pwd cd mkdir rmdir指令 && rm 指令 man指令 cp mv cat more less head tail 管道和重定向 1. 重定向(Redirection) 2. 管道(Pipes&a…...

Ubuntu安装VMware17
安装 下载本文的附件,之后执行 sudo chmod x VMware-Workstation-Full-17.5.2-23775571.x86_64.bundle sudo ./VMware-Workstation-Full-17.5.2-23775571.x86_64.bundle安装注意事项: 跳过账户登录的办法:断开网络 可能出现的问题以及解决…...
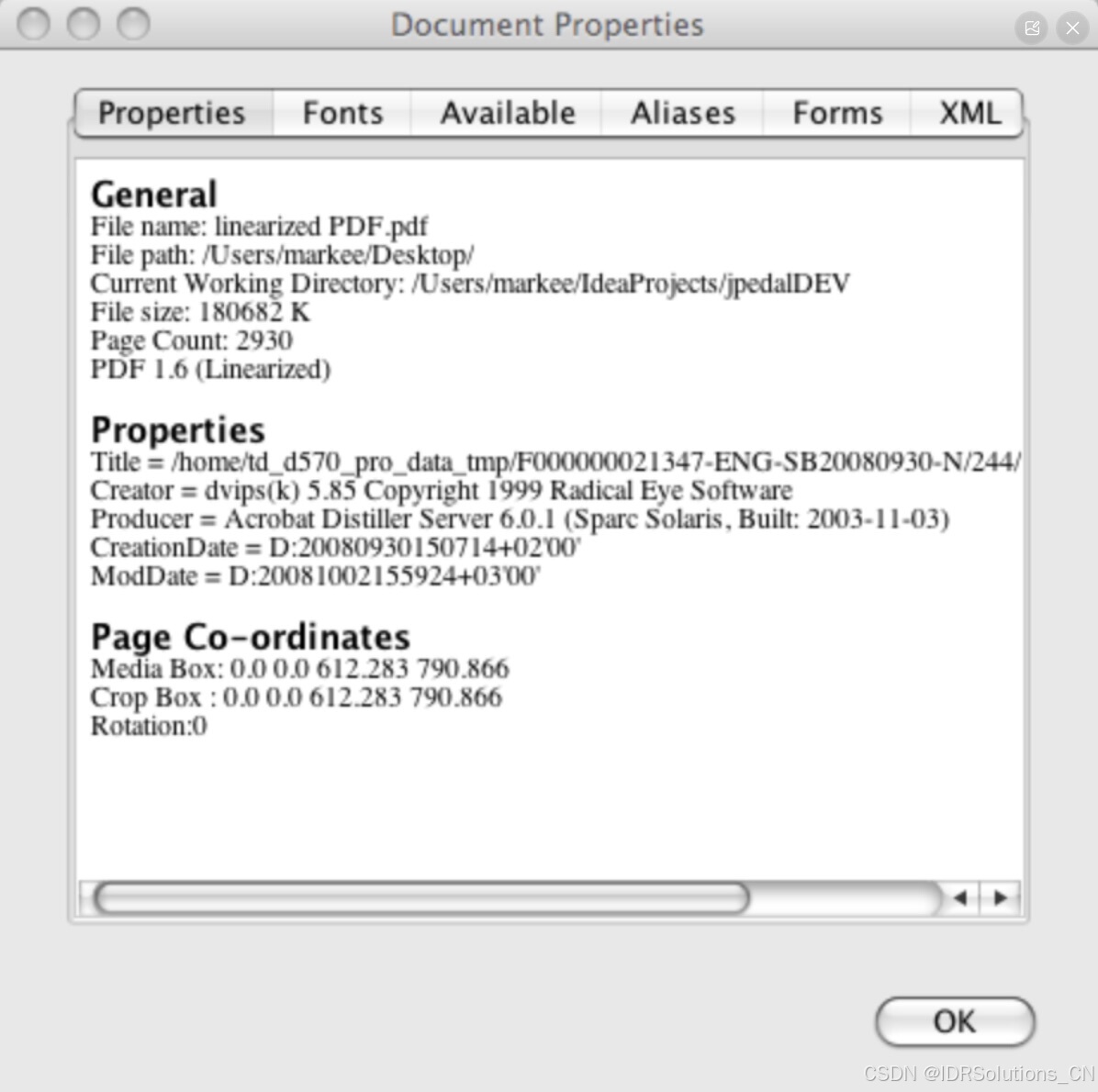
什么是线性化PDF?
线性化PDF是一种特殊的PDF文件组织方式。 总体而言,PDF是一种极为优雅且设计精良的格式。PDF由大量PDF对象构成,这些对象用于创建页面。相关信息存储在一棵二叉树中,该二叉树同时记录文件中每个对象的位置。因此,打开文件时只需加…...
每日一题——序列化二叉树
序列化二叉树 BM39 序列化二叉树题目描述序列化反序列化 示例示例1示例2 解题思路序列化过程反序列化过程 代码实现代码说明复杂度分析总结 BM39 序列化二叉树 题目描述 请实现两个函数,分别用来序列化和反序列化二叉树。二叉树的序列化是将二叉树按照某种遍历方式…...
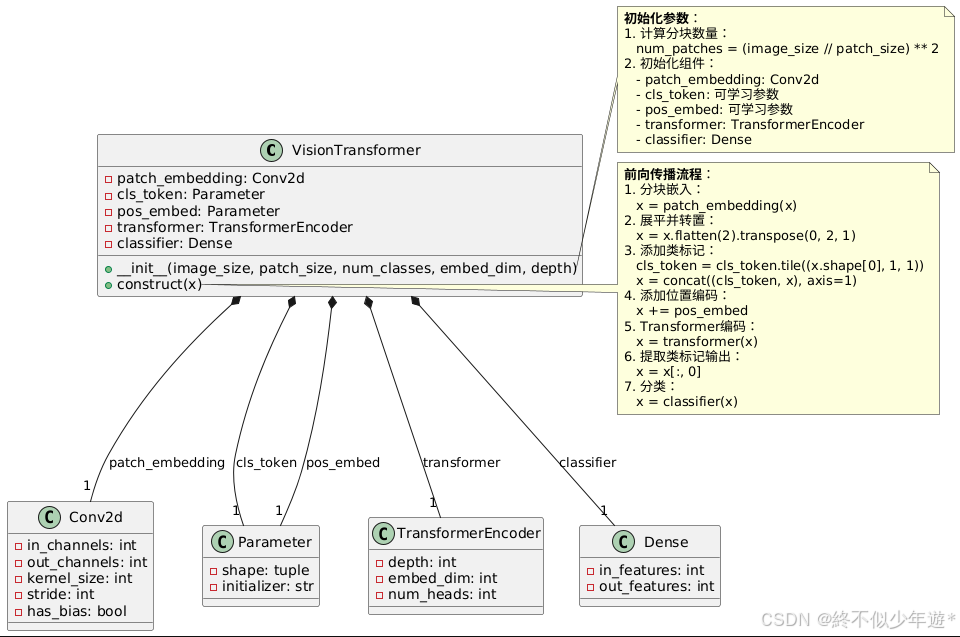
Transformer+vit原理分析
目录 一、Transformer的核心思想 1. 自注意力机制(Self-Attention) 2. 多头注意力(Multi-Head Attention) 二、Transformer的架构 1. 整体结构 2. 编码器层(Encoder Layer) 3. 解码器层(Decoder…...
「AI学习笔记」深度学习的起源与发展:从神经网络到大数据(二)
深度学习(DL)是现代人工智能(AI)的核心之一,但它并不是一夜之间出现的技术。从最初的理论提出到如今的广泛应用,深度学习经历了几乎一个世纪的不断探索与发展。今天,我们一起回顾深度学习的历史…...
【漫话机器学习系列】069.哈达马乘积(Hadamard Product)
哈达马乘积(Hadamard Product) 哈达马乘积(Hadamard Product)是两个矩阵之间的一种元素级操作,也称为逐元素乘积(Element-wise Product)。它以矩阵的对应元素相乘为规则,生成一个新…...

2025一区新风口:小波变换+KAN!速占!
今天给大家分享一个能让审稿人眼前一亮,好发一区的idea:小波变换KAN! 一方面:KAN刚中稿ICLR25,正是风口上,与小波变换的结合还处于起步阶段,正是红利期,创新空间广阔。 另一方面&a…...
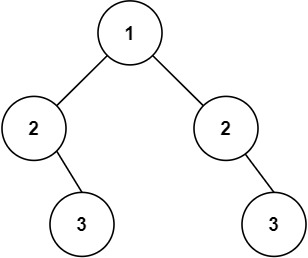
相同的树及延伸题型(C语言详解版)
从LeetCode 100和101看二叉树的比较与对称性判断 今天要讲的是leetcode100.相同的树,并且本文章还会讲到延伸题型leetcode101.对称二叉树。本文章编写用的是C语言,大家主要是学习思路,学习过后可以自己点击链接测试,并且做一些对…...

【Redis】 String 类型的介绍和常用命令
1. 介绍 Redis 中的 key 都是字符串类型Redis 中存储字符串是完全按照二进制流的形式保存的,所以 Redis 是不处理字符集编码的问题,客户端传入的命令中使用的是什么编码就采用什么编码,使得 Redis 能够处理各种类型的数据,包括文…...
 教程(5))
LLM - 大模型 ScallingLaws 的设计 100B 预训练方案(PLM) 教程(5)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/145356022 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 Scaling Laws (缩放法则) 是大模型领域中,用于描述 模型性能(Loss) 与…...
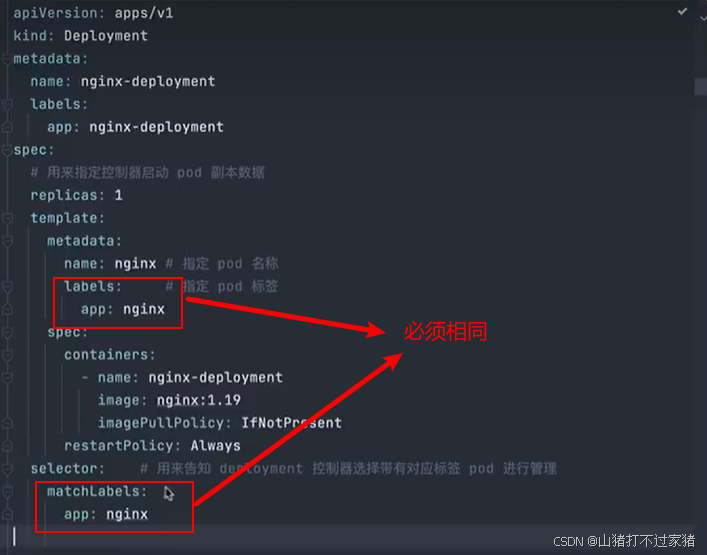
Docker/K8S
文章目录 项目地址一、Docker1.1 创建一个Node服务image1.2 volume1.3 网络1.4 docker compose 二、K8S2.1 集群组成2.2 Pod1. 如何使用Pod(1) 运行一个pod(2) 运行多个pod 2.3 pod的生命周期2.4 pod中的容器1. 容器的生命周期2. 生命周期的回调3. 容器重启策略4. 自定义容器启…...
32、【OS】【Nuttx】OSTest分析(1):stdio测试(二)
背景 接上篇wiki 31、【OS】【Nuttx】OSTest分析(1):stdio测试(一) 继续stdio测试的分析,上篇讲到标准IO端口初始化,单从测试内容来说其实很简单,没啥可分析的,但这几篇…...

git push到远程仓库时无法推送大文件
一、错误 remote: Error: Deny by project hooks setting ‘default’: size of the file ‘scientific_calculator’, is 164 MiB, which has exceeded the limited size (100 MiB) in commit ‘4c91b7e3a04b8034892414d649860bf12416b614’. 二、原因 本地提交过大文件&am…...

Vue.js路由管理与自定义指令深度剖析
Vue.js 是一个强大的前端框架,提供了丰富的功能来帮助开发者构建复杂的单页应用(SPA)。本文将详细介绍 Vue.js 中的自定义指令和路由管理及导航守卫。通过这些功能,你可以更好地控制视图行为和应用导航,从而提升用户体验和开发效率。 1 自定义指令详解 1.1 什么是自定义…...

NVIDIA GPU介绍:概念、序列、核心、A100、H100
概述 入职一家大模型领域创业公司,恶补相关知识。 概念 一些概念: HPC:High Performance Computing,高性能计算SoC:System on Chip,单片系统FLOPS:Floating Point Operations Per Second&am…...

【PyTorch】6.张量运算函数:一键开启!PyTorch 张量函数的宝藏工厂
目录 1. 常见运算函数 个人主页:Icomi 专栏地址:PyTorch入门 在深度学习蓬勃发展的当下,PyTorch 是不可或缺的工具。它作为强大的深度学习框架,为构建和训练神经网络提供了高效且灵活的平台。神经网络作为人工智能的核心技术&…...
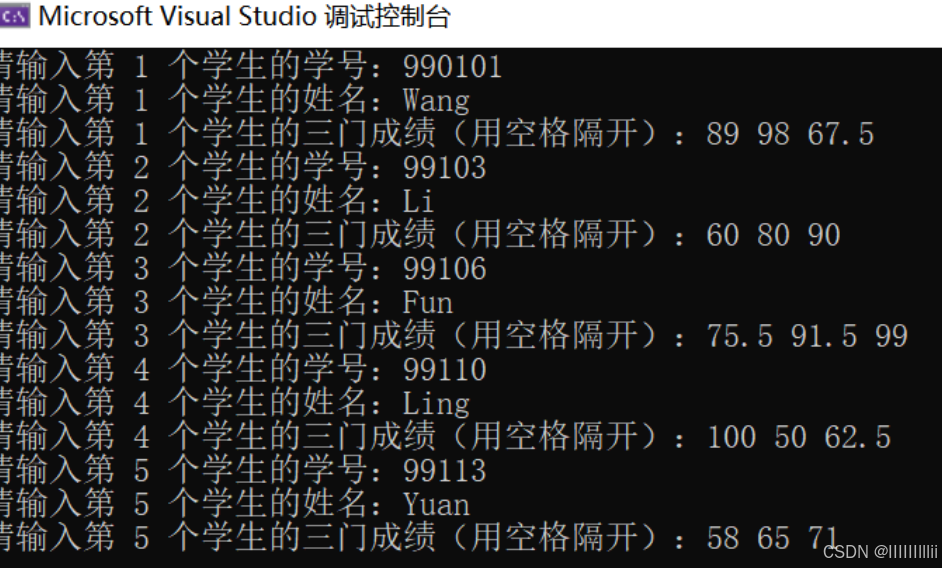
C语言练习(31)
有5个学生,每个学生有3门课程的成绩,从键盘输入以上数据(包括学号、姓名、3门课程成绩),计算出平均成绩,将原有数据和计算出的平均分数存放在磁盘文件stud中。 设5名学生的学号、姓名和3门课程成绩如下&am…...

如何三步轻松下载B站高清视频:BilibiliDown完整使用指南
如何三步轻松下载B站高清视频:BilibiliDown完整使用指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors…...

【最新 v2.7.1 版本】5 分钟搞定 OpenClaw Windows 环境部署配置
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟搭建专属数字员工【点击下载最新OpenClaw安装包】 前言 2026 年开源圈热门 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 …...
)
别再手动数脉冲了!用STM32定时器编码器模式搞定增量编码器(附CubeMX配置)
STM32硬件编码器模式实战:精准捕获增量编码器信号的工程指南 在电机控制、机器人关节定位和精密测量系统中,增量式编码器作为核心反馈元件,其信号处理质量直接影响整个系统的控制精度。传统的中断计数方式在高速脉冲场景下往往捉襟见肘&#…...

全球BGA锡球市场高速成长:2025年2.55亿美元筑基,2032年剑指4.43亿,8.3%CAGR锚定长期高增长逻辑
BGA锡球(BGA Solder Ball) 是用于替代IC元件封装结构中引脚的核心连接件,满足电性互连及机械连接的双重要求。简而言之,它是BGA封装工艺中不可或缺的焊接材料。QYResearch调研显示,2025年全球BGA锡球市场规模大约为2.5…...

PromethAI-Backend:构建标准化AI智能体后端框架的工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想搞一个能处理复杂工作流的智能体系统,发现了一个挺有意思的开源项目——PromethAI-Backend。这名字听着就有点“普罗米修斯”盗火种给人类的意思,挺形象的,它本质上就是一个为…...

那个号称能把安全厂商、操作系统厂商桌子都掀了的Anthropic Mythos到底是吹牛还是真牛
权力的杠杆与认知的泡沫:Anthropic Mythos 模型在网络安全领域的真实效能与战略叙事深度评估2026年4月7日,Anthropic 公司发布了名为 Claude Mythos Preview 的新型前沿模型,这一事件在人工智能与网络安全交叉领域引发了前所未有的剧烈震荡。…...

查重全红不用改!一招直接秒过知网
明明是自己一个字一个字敲的,怎么就红了半篇?更崩溃的是,导师说“后天必须交终稿”。 别急。查全红≠死定了。我花了整整一周实测了市面上十几款降重工具,发现一个真相:真正好用的就两款,而且搭配使用效果…...

DsHidMini技术深度解析:让经典PS3手柄在Windows上重获新生的开源方案
DsHidMini技术深度解析:让经典PS3手柄在Windows上重获新生的开源方案 【免费下载链接】DsHidMini Virtual HID Mini-user-mode-driver for Sony DualShock 3 Controllers 项目地址: https://gitcode.com/gh_mirrors/ds/DsHidMini 你是否有一台尘封已久的Play…...

Parabolic视频下载神器:一站式跨平台解决方案的终极指南
Parabolic视频下载神器:一站式跨平台解决方案的终极指南 【免费下载链接】Parabolic Download web video and audio 项目地址: https://gitcode.com/GitHub_Trending/pa/Parabolic Parabolic是一款基于yt-dlp引擎的专业级视频下载工具,为技术爱好…...

终极开源Spotify音乐下载指南:永久保存你的音乐收藏
终极开源Spotify音乐下载指南:永久保存你的音乐收藏 【免费下载链接】spotify-downloader Download your Spotify playlists and songs along with album art and metadata (from YouTube if a match is found). 项目地址: https://gitcode.com/gh_mirrors/spotif…...