NVIDIA GPU介绍:概念、序列、核心、A100、H100
概述
入职一家大模型领域创业公司,恶补相关知识。
概念
一些概念:
- HPC:High Performance Computing,高性能计算
- SoC:System on Chip,单片系统
- FLOPS:Floating Point Operations Per Second,每秒浮点运算次数,用于衡量硬件性能
- SM:Streaming Multiprocessor,流多处理器
- QoS:Quality of Service,服务质量
- MIG:Multi-Instance GPU,多实例GPU
- CUDA:Compute Unified Device Architecture,计算统一设备架构。描述GPU的并行计算能力,以及访问CUDA核心指令集的API
- MMA:Matrix Multiplication and Accumulation,矩阵乘法和累加计算
- TEE:Trusted Execution Environment,可信执行环境
- CC:Confidential Computing,机密计算
- TMA:Tensor Memory Accelerator,张量内存加速器
- VDI:Virtual Desktop Infrastructure,虚拟桌面基础设施
产品
- GeForce:面向游戏玩家,提供强大的图形处理能力、先进的游戏技术。
- Quadro:面向专业市场,如设计师、工程师、科学家和内容创作者。如Quadro P 系列。
- Tesla:面向数据中心和HPC市场,提供强大算力,适用于科学研究、深度学习。如V100、A100等。
- Titan:高端显卡系列,介于消费者和专业市场之间,兼具游戏和计算能力。
- RTX:包含实时光线追踪技术的显卡,适用于游戏和高性能计算。
- GTX:面向主流和高性能游戏市场。
- Clara:面向医疗成像和生命科学领域,提供 AI 和加速计算能力,用于医学影像处理和生命数据分析。
- Jetson:面向边缘计算和机器人市场,提供小型化、低功耗的AI计算模块,适合嵌入式系统和机器人应用。
- Orin:面向自动驾驶和边缘AI市场,高能效SoC,集成CPU、GPU和深度学习加速器。
系列
在NVIDIA GPU的命名体系中,首字母通常代表该GPU采用的微架构。微架构是GPU芯片设计的核心,决定其基本的运算方式、指令集以及内部结构。每隔几年,NVIDIA都会针对其消费级和数据中心产品线推出全新的微架构,以实现性能和能效比的显著提升。

架构序列号:
- F:Fermi,2008推出。首次采用 GPU-Direct 技术,拥有32个SM和 16 个 PolyMorph Engine 阵列,每个 SM 都拥有 1 个 PolyMorph Engine 和 64 个 CUDA 核心。该架构采用 4 颗芯片的模块化设计,拥有 32 个光栅化处理单元和 16 个纹理单元,搭配 GDDR5 显存。
- K:Kepler,2011。采用 28nm 制程,首度支持超级计算和双精度计算。Kepler GK110 具有 2880 个流处理器和高达 288GB/s 的带宽,计算能力比 Fermi 架构提高 3-4 倍。Kepler 架构的出现使 GPU 开始成为HPC的关注点。
- M:Maxwell,2014
- P:Pascal,2016
- V:Volta,2017
- T:Turing,2018
- A:Ampere,2020
- H:Hopper,2022.03
- L:Ada Lovelace,2022.09
- B:Blackwell,2024.03
性能等级(Tier):通常用数字表示,数字越大通常代表性能越强,价格越高,功耗更高。
- 4系列:入门级或低功耗级
通常是同代产品中体积最小、功耗最低的型号,设计目标是在有限的功耗预算下提供足够的计算性能。适合对性能要求不高、注重成本效益的应用场景,例如:- 轻量级的模型推理任务,例如图像分类、NLP等;
- 边缘计算设备或低功耗服务器;
- 对成本敏感的应用部署。
- 10系列:中端推理优化级
通常是针对AI推理应用进行优化的中端产品。在性能、功耗和成本之间取得较好的平衡,适合需要较高推理吞吐量和较低延迟的应用场景,例如:- 大规模的在线推理服务;
- 视频分析和图像处理;
- 实时语音识别和翻译。
- 40系列:高端图形和虚拟工作站级
通常是面向专业图形应用和虚拟工作站的高端产品。拥有强大的图形渲染能力和计算性能,适合对图形处理和计算性能要求较高的应用场景,例如:- 专业级图形设计和渲染;
- HPC可视化;
- VDI。
- 100系列:旗舰级HPC和AI级
是同代产品中性能最强、价格最高的旗舰级产品。拥有最多的内核数量、最大的显存容量和最高的内存带宽,专为处理要求最严格的计算负载而设计,例如:- 大规模的模型训练和微调;
- 高性能科学计算和模拟;
- 超大规模数据中心部署。
Core
Core,译为核心,有三类:
- CUDA Core:最常见的核心,计算核心单元,用于执行通用的并行计算任务。NVIDIA通常用最小的运算单元表示自己的运算能力,CUDA Core指的是一个执行基础运算的处理元件,CUDA Core数量,通常对应的是FP32计算单元的数量。
- Tensor Core:Volta架构及其后续架构中引入的一种特殊计算单元。专门用于深度学习任务中的张量计算,如矩阵乘法和卷积运算。核心特别大,通常与深度学习框架相结合使用,它可以把整个矩阵都载入寄存器中批量运算,实现十几倍的效率提升。
- Ray Tracing Core:下文统一简称RT Core,专用硬件单元,定位是用于加速光线追踪计算的消费级显卡。主要用于游戏开发、电影制作和虚拟现实等需要实时渲染的领域。
CUDA Core
最基础的处理单元,专门用于执行并行计算任务。其主要职责包括处理大规模的浮点运算和整数运算,尤其适合需要高吞吐量的计算场景。
GPU内部的处理单元被称为CUDA核心。是 NVIDIA GPU 的基石,自 2006 年首次推出以来,已成为HPC领域不可或缺的重要组成部分。
CUDA 核心的设计特点是多线程并行执行,能够一次性运行数千甚至数百万个线程。在以下任务中表现卓越:
- 图像和视频处理:通过对像素和帧进行并行处理,显著提升渲染效率。
- 科学计算:例如粒子模拟、气象预测等需要密集计算的领域。
- 实时物理计算:如游戏中的碰撞检测、流体模拟等。
核心优势:
- 大规模并行性:通常以成千上万的数量存在,其核心数显著高于传统 CPU 核心。
- 高计算效率:通过简化指令流水线,提高并行任务的执行速度。
- 广泛的开发工具支持:NVIDIA 提供完整的 CUDA 开发工具链,帮助开发者编写高效的并行代码。
典型应用:
- 视频转码:如 NVIDIA NVENC,加速高分辨率视频的编码和解码。
- 3D 渲染:在 Blender 或 Maya 等软件中显著提升渲染速度。
- 深度学习基础运算:为复杂矩阵运算提供底层计算支持。
Tensor Core
Tensor cores为深度学习模型训练和推理任务专门设计的计算单元,首次引入于 Volta 架构(如 Tesla V100)。其核心特性是能够在张量运算(Tensor Operations)如MMA中表现出色。
相比CUDA cores,Tensor cores 能够以混合精度(FP16/FP32或更高精度)处理大规模矩阵运算,这显著提升深度学习任务的性能和效率。通常而言,Tensor cores 的性能优势在于其专用性。例如,在矩阵计算任务中,其性能往往是 CUDA cores 的数倍,尤其是在处理 FP16 或 INT8 类型的高效计算时。
核心优势:
- 混合精度计算:通过在性能与精度之间找到平衡,可实现 10 倍甚至更高的运算速度。
- 针对 AI 优化:专为神经网络的训练和推理任务设计。
- 低延迟高吞吐量:加速深度学习中占主导地位的线性代数运算。
典型应用:
- DL训练:如神经网络的前向传播和反向传播计算。
- 推理优化:在实时语音识别或图像分类任务中显著提升推理速度。
- 生成式AI:支持GPT-4、DALL-E 这样的生成模型加速计算。
- 大规模 AI 框架支持:TensorFlow、PyTorch 和 JAX 等DL框架已深度集成对 Tensor cores 的优化。
RT Core
RT Core是针对光线追踪渲染技术专门设计的核心单元,首次引入于 Turing 架构(如 RTX 20 系列)。其主要任务是加速光线追踪计算,即模拟光线在 3D 场景中的传播和交互,以实现逼真的光影效果。
光线追踪的关键任务
- 光线与场景交互检测(Ray-Object Intersection Detection):快速判断光线是否与场景中的几何体相交。
- 路径追踪(Path Tracing):模拟光线的多次反射和折射路径,生成真实感光影效果。
- 动态光影渲染:支持实时生成动态场景中的光影变化。
核心优势:
- 硬件加速:相较于传统的软件光线追踪,RT Core能够以更高效率完成复杂光线计算;
- 实时性能:在高分辨率游戏和虚拟现实场景中实现实时光线追踪效果;
- 兼容性与扩展性:支持 NVIDIA RTX 技术(如 DLSS)进一步优化性能。
典型应用:
- 高端游戏:提供真实的光影和反射效果。
- 电影特效:提升 CG 动画渲染效率和视觉效果。
- 虚拟现实:增强 VR 场景中的沉浸感。
协作
三者在功能上分工明确,但并非孤立运行,而是以互补和协同的方式共同完成任务。
从硬件架构和应用场景两方面,剖析三者之间的关系:
- 硬件架构中的关系
- 共享基础资源:三种核心都集成在 GPU 的SM模块中,SM通过共享缓存、寄存器和内存接口,使得三者能够高效协同工作。
- 多任务调度:CUDA cores 负责通用计算任务,而当涉及特定的深度学习推理或训练时,任务会由 Tensor cores 加速执行。对于需要实时光线追踪的场景,RT Core会接管相关计算。
- 统一编程模型:提供统一的编程框架,使开发者能够灵活调配三种核心的资源。例如,开发者可通过 CUDA 代码调用 Tensor cores 的矩阵加速功能,或在光线追踪算法中结合 CUDA cores 进行辅助计算。
- 应用场景中的关系
三种核心的协同作用在实际应用中尤为明显,通过分工合作提升计算效率:- 深度学习中的协同作用
Tensor cores 提供高效的矩阵计算,用于深度神经网络训练和推理。
CUDA cores 处理预处理、数据加载和其他非矩阵计算任务,为 Tensor cores 减轻负担。
在某些生成式模型(如 GAN 和 Stable Diffusion)中,RT Core可用于生成更真实的图像效果。 - 游戏与图形渲染中的协同作用
RT Core处理复杂的光线追踪运算,如反射、折射和全局光照。
CUDA cores 辅助执行像素着色、几何计算和纹理映射等传统渲染任务。
Tensor cores 加速 AI 驱动的渲染技术(如 NVIDIA DLSS),通过深度学习优化渲染质量和性能。 - 科学计算中的协同作用
CUDA cores 负责通用的数值计算和模拟任务。
Tensor cores 加速涉及矩阵运算的HPC任务,如气候模拟和分子动力学仿真。
RT Core可用于科学可视化中的光线追踪渲染,生成高质量的三维图像。
- 深度学习中的协同作用
此外,三种核心的协同工作使得GPU 能够在多种应用场景中展现出卓越性能,其主要优势包括:
- 性能最大化:不同核心各司其职,分担不同计算任务,提高整体吞吐量。例如,在 AI 模型训练中,Tensor cores 执行矩阵运算,CUDA cores 执行辅助任务,从而实现更快的训练速度。
- 多功能性:三种核心的结合使得 GPU 不仅能够胜任通用计算任务,还能处理 AI 推理和实时渲染等高度专业化任务,扩展GPU 的应用范围。
- 节能与效率:通过为不同类型的任务分配最合适的硬件资源,GPU 的功耗得以优化。例如,Tensor cores 的设计使其能够在较低的功耗下完成高效矩阵计算。
CUDA cores 提供通用计算能力,Tensor cores 专注于 AI 加速,而RT Core为光线追踪渲染提供支持。三者在硬件架构、任务协作和应用场景中形成高效的协同关系,为深度学习、科学计算、图形渲染等领域带来革命性突破。
A100
2020 年发布的 A100 是首款基于 Ampere 架构的 GPU。与V100 相比,A100能效提升3 倍,性能提升20 倍,带宽提升近 2 倍,被誉为V100直接替代品。
主要特性
如下:
- MIG技术
MIG允许将一块物理 A100 GPU 划分成多个独立的虚拟 GPU 实例,每个实例在硬件层面实现完全隔离,拥有独立的资源配额,包括显存、计算核心和缓存。这种硬件级别的隔离确保不同实例之间的互不干扰,提高资源利用率和安全性。MIG 技术使得企业能够更灵活地管理 GPU 资源,根据不同的工作负载需求动态调整实例的配置,例如为小规模的推理任务分配较小的实例,为大规模的训练任务分配较大的实例,从而最大限度地利用数据中心的资源。
MIG 技术显著提升 GPU 硬件的性能,同时在多个客户端(例如虚拟机、进程和容器)之间提供指定的QoS和隔离性。
借助 MIG,开发人员可以为其所有应用程序获得突破性的加速性能,而 IT 管理员则可以为每项任务提供适当的 GPU 加速,从而最大限度地提高利用率,并扩展每个用户和应用程序的访问权限。
例如,用户可以根据工作负载的大小创建两个各 30 GB 显存的 MIG 实例,三个各 20 GB 的实例,甚至五个各 10 GB 的实例。 - 第三代 Tensor Cores
A100 配备第三代 Tensor Cores,与 Volta 架构的 GPU 相比,A100 在训练和推理方面都提供20 倍的 Tensor 浮点运算/秒 (FLOPS)及 Tensor tera 运算/秒 (TOPS),从而使得用户能够更快地训练更大的模型,并以更高的效率进行推理。 - NVLink 和 NVSwitch
作为一种高速的 GPU 互连技术,NVLink 主要用于连接多个GPU,实现高速的 GPU 间通信。A100 采用第三代 NVLink 技术,其吞吐量比上一代产品提升2 倍,显著提高多 GPU 协同工作的效率。
NVSwitch 作为一种片上交换机设计,可连接多个GPU,并提供高带宽、低延迟的通信通道。通过 NVLink 和 NVSwitch 的结合使用,可构建大规模的 GPU 集群,加速分布式训练和HPC任务。 - 结构稀疏性
结构稀疏性指的是在神经网络中,并非所有神经元之间的连接都是必要的。通过将不重要的连接或权重设置为零,可创建稀疏模型。减少模型的计算量和存储空间,并提高推理速度。
对于稀疏模型,A100 的 Tensor Cores 可提供高达两倍的性能提升,能够更有效地处理稀疏矩阵运算。虽然稀疏性对训练也有一定的加速作用,但其对推理性能的提升更为显著,尤其是在资源受限的边缘设备上。 - 高带宽内存拓展
A100 提供高达 2 TB/s 的内存带宽,可以极高的速度访问内存中的数据,避免因数据传输瓶颈而导致的性能下降。 - 更为强大的算力支撑
A100 采用当时最先进的 7 纳米制程工艺。结合高速的 PCI Express 接口,A100 能够提供前所未有的计算性能,显著缩短模型训练时间,将原本可能需要数周的训练任务压缩到数小时内完成。
上述特性对于需要处理海量数据集和进行实时数据处理的应用至关重要,例如LLM推理、推荐系统、HPC等。高带宽内存使得 A100 能够快速加载和处理数据,为用户提供流畅、高效的使用体验。
应用场景
作为 NVIDIA 生态全面深度学习解决方案中的核心组件,A100 解决方案包含硬件、网络、软件、库和应用程序等构建模块,以及优化的 AI 模型。
基于其牛逼特性,使研究人员能够取得切实可行的成果,并将解决方案的部署扩展到生产环境,使其成为数据中心最强大的端到端 AI 和HPC解决方案。
-
AI 模型开发与推理
针对特定领域的任务,无论是模型开发还是推理,通常都具有高度的复杂性,而利用 GPU 加速技术可显著优化这些任务的效率。在此过程中,A100 被广泛视为高效加速的理想选择,可同时满足模型开发和推理的需求。
与此前的 GPU 产品相比,A100 在模型开发和推理性能上实现显著提升,其计算速度加快 3 倍到 7 倍。这一提升不仅得益于第三代 Tensor Core 技术的引入,还包括对大规模并行计算、稀疏矩阵运算以及多精度计算(如 FP32、TF32、FP16 和 INT8)的优化支持,从而极大地提升 AI 工作负载的整体效率。
因此,通过结合具体业务需求选择A100,用户不仅能够获得开发与推理任务的显著性能提升,还能够优化资源使用效率,降低整体计算成本。这使得 A100 成为各行业在 AI 模型开发和推理场景中的首选解决方案。
-
HPC新里程碑
研究人员得益于 A100 的双精度 Tensor Core,可将传统需要V100 十小时完成的双精度仿真任务缩短至 四小时。这一改进为科学计算、工程仿真以及气候建模等高度依赖计算密集型任务的领域,提供强有力的支持。
A100 的 Tensor Core 针对单精度稠密矩阵乘法引入 TF32 精度,使单精度计算性能提升 多达十倍。这使得 A100 成为HPC和 AI 工作负载的理想选择,无论是训练深度学习模型,还是执行复杂科学任务,都能显著加速计算速度。 -
视频/图像解码性能的全面提升
在深度学习平台上,要实现与开发和推理性能匹配的视频解码性能,维持高端到端吞吐量是一个关键问题。
A100针对这一挑战做出重大改进,配备 五个 NVDEC 单元,相比前代 GPU 显著增强解码能力。无论是在视频分析、流媒体处理,还是在复杂的计算机视觉任务中,A100 的多解码单元设计都能确保高吞吐量,同时显著降低延迟,从而满足现代 AI 应用对于视频/图像处理的苛刻需求。
-
增强的故障与错误检测能力
基于 Ampere 架构的最新一代 A100 GPU,在故障检测和识别能力上实现前所未有的突破。其新增的错误与故障识别功能,能够更快速、可靠、高效地发现系统问题,并采取隔离和解决措施。
A100 Tensor Core GPU 的架构专为功能性、安全性及故障容错而设计,确保应用程序在运行期间,数据对象始终得到正确初始化,并能在故障发生时快速隔离问题。
除上述的场景及解决方案外,得益于其架构内置的扩展功能使得可以在合理的时间内训练参数规模达到 一万亿 的大型模型。与上一代 GPU 相比,A100 不仅在性能上大幅提升,还在处理效率上远超 CPU。
H100
相较于A100,H100的提升和差异:
- Transformer Engine优化:H100 配备专为深度学习模型优化的 Transformer Engine,训练速度提高多达六倍,尤其是在需要处理大量并行计算和数据交换的任务中,表现尤为突出。
- FP8 任务的性能提升六倍,能够达到 4 PetaFLOPS 的峰值性能。
- 内存容量增加50%,采用 HBM3 高带宽内存,速度高达 3 Tbps,通过外部连接甚至接近 5 Tbps,极大地提升数据吞吐能力。
- CC:静态数据加密和传输中数据加密是常见的安全措施,但 CC 将这种保护扩展到使用中的数据。对于处理敏感信息的行业(如医疗保健和金融)尤其具有吸引力。机密计算通过在硬件层面创建一个TEE,确保即使在云环境中,数据在处理过程中也能得到保护,免受恶意软件或未经授权的访问。
- TMA:将内存管理任务从 GPU 线程中卸载,从而显著提升性能。与简单地增加核心数量不同,TMA 代表着一次根本性的架构转变,通过专用硬件加速内存访问,减少CPU 和 GPU 之间的通信瓶颈,从而提高整体计算效率。此外,随着对训练数据需求的增长,TMA 在不增加计算线程负担的情况下无缝处理大型数据集的能力变得越来越有价值。此外,随着训练软件不断发展以充分利用此功能,H100 可能会成为大规模AI模型训练的首选,提供增强的未来适用性。这意味着企业在未来部署更大规模、更复杂的AI模型时,H100仍然能够提供强大的支持。
NVLink
NVSwitch
4090
参考
- 一文读懂NVIDIA GPU产品线
- NVIDIA GPU核心与架构演进史
相关文章:
NVIDIA GPU介绍:概念、序列、核心、A100、H100
概述 入职一家大模型领域创业公司,恶补相关知识。 概念 一些概念: HPC:High Performance Computing,高性能计算SoC:System on Chip,单片系统FLOPS:Floating Point Operations Per Second&am…...

【PyTorch】6.张量运算函数:一键开启!PyTorch 张量函数的宝藏工厂
目录 1. 常见运算函数 个人主页:Icomi 专栏地址:PyTorch入门 在深度学习蓬勃发展的当下,PyTorch 是不可或缺的工具。它作为强大的深度学习框架,为构建和训练神经网络提供了高效且灵活的平台。神经网络作为人工智能的核心技术&…...
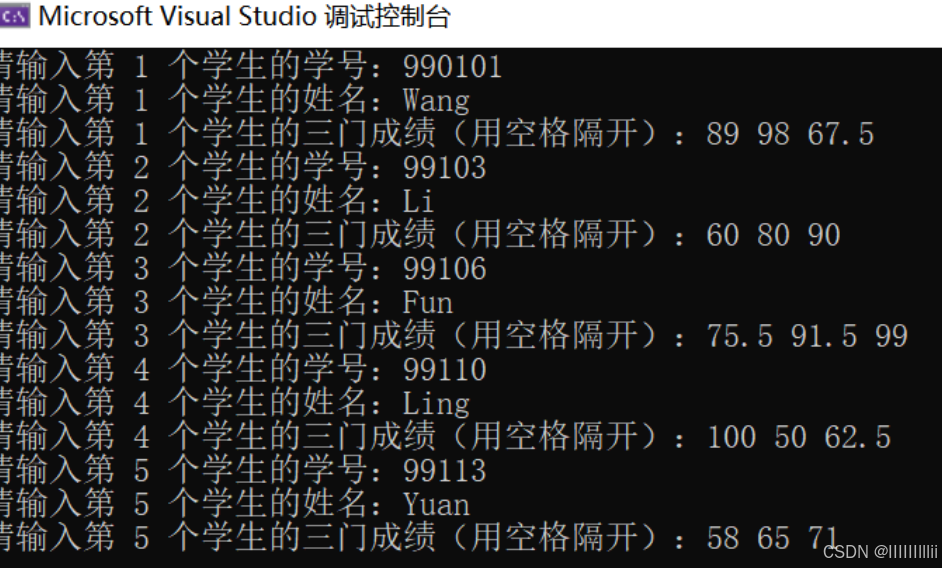
C语言练习(31)
有5个学生,每个学生有3门课程的成绩,从键盘输入以上数据(包括学号、姓名、3门课程成绩),计算出平均成绩,将原有数据和计算出的平均分数存放在磁盘文件stud中。 设5名学生的学号、姓名和3门课程成绩如下&am…...

什么是长短期记忆网络?
一、概念 长短期记忆网络(Long Short-Term Memory, LSTM)是一种特殊的循环神经网络(RNN),旨在解决标准RNN在处理长序列时的梯度消失和梯度爆炸问题。LSTM通过引入三个门(输入门、遗忘门和输出门)…...

git中有关old mode 100644、new mode 10075的问题解决小结
在 Git 版本控制系统中,文件权限变更是一种常见情况。当你看到类似 old mode 100644 和 new mode 100755 的信息时,这通常表示文件的权限发生了变化。本文将详细解析这种情况,并提供解决方法和注意事项。 问题背景 在 Git 中,文…...

Jenkins上生成的allure report打不开怎么处理
目录 问题背景: 原因: 解决方案: Jenkins上修改配置 通过Groovy脚本在Script Console中设置和修改系统属性 步骤 验证是否清空成功 进一步的定制 也可以使用Nginx去解决 使用逆向代理服务器Nginx: 通过合理调整CSP配置&a…...

JSR303校验教学
1、什么是JSR303校验 JSR是Java Specification Requests的缩写,意思是Java 规范提案。是指向JCP(Java Community Process)提出新增一个标准化技术规范的正式请求。任何人都可以提交JSR,以向Java平台增添新的API和服务。JSR已成为Java界的一个重要标准。…...

使用DeepSeek技巧:提升内容创作效率与质量
一、引言 在当今快节奏的数字时代,内容创作的需求不断增加,无论是企业营销、个人博客还是学术研究,高效且高质量的内容生成变得至关重要。DeepSeek作为一款先进的人工智能写作助手,凭借其强大的语言生成能力,为创作者…...
)
【第六天】零基础入门刷题Python-算法篇-数据结构与算法的介绍-一种常见的贪心算法(持续更新)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、Python数据结构与算法的详细介绍1.Python中的常用的贪心算法2.贪心算法3.详细的贪心代码1)一种常见的贪心算法 总结 前言 提示:这里…...
C# Winform制作一个登录系统
using System; using System.Collections; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Forms;namespace 登录 {p…...

算法总结-哈希表
文章目录 1.赎金信1.答案2.思路 2.字母异位词分组1.答案2.思路 3.两数之和1.答案2.思路 4.快乐数1.答案2.思路 5.最长连续序列1.答案2.思路 1.赎金信 1.答案 package com.sunxiansheng.arithmetic.day14;/*** Description: 383. 赎金信** Author sun* Create 2025/1/22 11:10…...

向下调整算法(详解)c++
算法流程: 与⽗结点的权值作⽐较,如果⽐它⼤,就与⽗亲交换; 交换完之后,重复 1 操作,直到⽐⽗亲⼩,或者换到根节点的位置 大家可能会有点疑惑,这个是大根堆,22是怎么跑到…...

蓝桥杯之c++入门(一)【C++入门】
目录 前言5. 算术操作符5.1 算术操作符5.2 浮点数的除法5.3 负数取模5.4 数值溢出5.5 练习练习1:计算 ( a b ) ⋆ c (ab)^{\star}c (ab)⋆c练习2:带余除法练习3:整数个位练习4:整数十位练习5:时间转换练习6ÿ…...
的实战指南)
使用Python爬虫获取1688商品拍立淘API接口(item_search_img)的实战指南
在电商领域,通过图片搜索商品(拍立淘)已经成为一种重要的商品检索方式。1688平台的item_search_img接口允许用户通过上传图片来搜索相似商品,这为商品信息采集和市场分析提供了极大的便利。本文将详细介绍如何使用Python爬虫技术调…...

ElasticSearch-文档元数据乐观并发控制
文章目录 什么是文档?文档元数据文档的部分更新Update 乐观并发控制 最近日常工作开发过程中使用到了 ES,最近在检索资料的时候翻阅到了 ES 的官方文档,里面对 ES 的基础与案例进行了通俗易懂的解释,读下来也有不少收获࿰…...

使用Navicat Premium管理数据库时,如何关闭事务默认自动提交功能?
使用Navicat Premium管理数据库时,最糟心的事情莫过于事务默认自动提交,也就是你写完语句运行时,它自动执行commit提交至数据库,此时你就无法进行回滚操作。 建议您尝试取消勾选“选项”中的“自动开始事务”,点击“工…...

【单细胞-第三节 多样本数据分析】
文件在单细胞\5_GC_py\1_single_cell\1.GSE183904.Rmd GSE183904 数据原文 1.获取临床信息 筛选样本可以参考临床信息 rm(list ls()) library(tinyarray) a geo_download("GSE183904")$pd head(a) table(a$Characteristics_ch1) #统计各样本有多少2.批量读取 学…...
 IO流)
(java) IO流
学习IO流之前,我们需要先认识file对象,帮助我们更好的使用IO流 1.1 file 作用:关联硬盘上的文件 写法: File(String path); (推荐)File(String parent, String child); //由父级路径,再子级路径拼接而成File(File p…...

2025年1月个人工作生活总结
本文为 2025年1月工作生活总结。 研发编码 使用sqlite3命令行查询表数据 可以直接使用sqlite3查询数据表,不需进入命令行模式。示例如下: sqlite3 database_name.db "SELECT * FROM table_name;"linux shell使用read超时一例 先前有个编译…...

线性调整器——耗能型调整器
线性调整器又称线性电压调节器,以下是关于它的介绍: 基本工作原理 线性调整器的基本电路如图1.1(a)所示,晶体管Q1(工作于线性状态,或非开关状态)构成一个连接直流源V和输出端V。的可调电气电阻,直流源V由60Hz隔离变压器(电气隔离和整流&#…...

为啥大模型都要用 Token 调用,不能直接扒网页端接口?
1. 网页端接口是「给人用的」,随时会改 网页版(比如官网聊天页)的接口: 参数、请求头、加密算法、签名天天变 前端一改版,接口地址、加密方式直接作废 你好不容易扒完,过两天就挂,还要重新抓包、逆向 而官方开放的 API + Token 是稳定商用接口,几年都不换格式,专门给…...

CircuitPython开发实战:从环境搭建到内存优化与硬件选型
1. CircuitPython开发环境搭建与核心概念 如果你是从Arduino或者传统的嵌入式C开发转向微控制器编程,第一次接触CircuitPython的感觉,就像是突然有人给你递了一把万能钥匙。过去,点个灯、读个传感器,你得跟寄存器、数据手册、还有…...

OpenRGB终极指南:一站式免费控制所有RGB设备的完整解决方案
OpenRGB终极指南:一站式免费控制所有RGB设备的完整解决方案 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcProgrammer1/OpenRGB. R…...

弹球打砖块
<!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0, user-scalableno"><title>弹球打砖块</title><…...

高效构建面试题库系统:React+Node全栈技术实战指南
高效构建面试题库系统:ReactNode全栈技术实战指南 【免费下载链接】mianshiya-public 持续维护的企业面试题库网站,帮你拿到满意 offer!⭐️ 2026年最新Java面试题、前端面试题、AI大模型面试题、AI Agent面试题、RAG面试题、C面试题、Go面试…...

Postman数据迁移实战:如何用导入导出功能,在团队间高效同步你的接口集合和环境变量
Postman团队协作指南:接口资产迁移与标准化管理实践 在分布式团队和敏捷开发成为主流的今天,API开发工具的高效使用直接影响着协作效率。作为被全球超过2000万开发者使用的API工具,Postman的集合与环境变量功能已经成为团队间接口定义传递的事…...

使用taotaokencli工具一键配置多开发环境下的ai代理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 TaoToken CLI 工具一键配置多开发环境下的 AI 代理 基础教程类,介绍如何通过 npx 或全局安装 TaoToken 提供的命令…...

在微服务架构中统一接入Taotoken管理所有AI调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在微服务架构中统一接入Taotoken管理所有AI调用 当企业采用微服务架构时,AI能力的调用往往分散在各个独立的服务中。每…...

如何用RPG Maker多层级视差地图插件创建专业级游戏场景?
如何用RPG Maker多层级视差地图插件创建专业级游戏场景? 【免费下载链接】RPGMakerMV RPGツクールMV、MZで動作するプラグインです。 项目地址: https://gitcode.com/gh_mirrors/rp/RPGMakerMV RPG Maker多层级视差地图插件是一个功能强大的开源工具…...

别熬大夜改 PPT 了!Paperxie AI PPT,一键搞定毕业论文答辩
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 论文终稿刚定稿,答辩 PPT 的空白页面就开始让人焦虑。打开 PowerPoint,对着 “新建幻灯片” 发愣&am…...