【MQ】探索 Kafka
基本概念
主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
副本:Replica。Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
生产者:Producer。向主题发布新消息的应用程序。
消费者:Consumer。从主题订阅新消息的应用程序。
消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
Kafka 的三层消息架构
第一层是主题层,每个主题可以配置 M 个分区,而每个分区又可以配置 N 个副本。
第二层是分区层,每个分区的 N 个副本中只能有一个充当领导者角色,对外提供服务;其他 N-1 个副本是追随者副本,只是提供数据冗余之用。
第三层是消息层,分区中包含若干条消息,每条消息的位移从 0 开始,依次递增。最后,客户端程序只能与分区的领导者副本进行交互。

Broker 是如何持久化数据
总的来说,Kafka 使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。因为只能追加写入,故避免了缓慢的随机 I/O 操作,改为性能较好的顺序 I/O 写操作,这也是实现 Kafka 高吞吐量特性的一个重要手段。不过如果你不停地向一个日志写入消息,最终也会耗尽所有的磁盘空间,因此 Kafka 必然要定期地删除消息以回收磁盘。怎么删除呢?简单来说就是通过日志段(Log Segment)机制。在 Kafka 底层,一个日志又进一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka 会自动切分出一个新的日志段,并将老的日志段封存起来。Kafka 在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的。
高性能
-
消息的顺序性、顺序写磁盘
-
零拷贝
-
RocketMQ内部主要是使用基于mmap实现的零拷贝,用来读写文件
-
减少cpu的拷贝次数和上下文切换次数,实现文件的高效读写操作
-
- Kafka
零拷贝
- Kafka 使用到了 mmap 和 sendfile 的方式来实现零拷贝。分别对应 Java 的 MappedByteBuffer 和 FileChannel.transferTo
顺序写磁盘
- Kafka 采用顺序写文件的方式来提高磁盘写入性能。顺序写文件,基本减少了磁盘寻道和旋转的次数
- 完成一次磁盘 IO,需要经过寻道、旋转和数据传输三个步骤,如果在写磁盘的时候省去寻道、旋转可以极大地提高磁盘读写的性能。
- Kafka 中每个分区是一个有序的,不可变的消息序列,新的消息不断追加到 Partition 的末尾,在 Kafka 中 Partition 只是一个逻辑概念,Kafka 将 Partition 划分为多个 Segment,每个 Segment 对应一个物理文件,Kafka 对 segment 文件追加写,这就是顺序写文件
页缓存技术
- 应当使用本地磁盘作为存储介质。Page Cache 的存在就可以提升消息的读取速度,
批量传输与压缩消息
- 生产端有两个重要的参数:batch.size和linger.ms。这两个参数就和 Producer 的批量发送消息有关。
网络模型
- Kafka 自己实现了网络模型做 RPC。底层基于 Java NIO,采用和 Netty 一样的 Reactor 线程模型。
- Kafka 即基于 Reactor 模型实现了多路复用和处理线程池。
- Reactor 模型基于池化思想,避免为每个连接创建线程,连接完成后将业务处理交给线程池处理;基于 IO 复用模型,多个连接共用同一个阻塞对象,不用等待所有的连接。遍历到有新数据可以处理时,操作系统会通知程序,线程跳出阻塞状态,进行业务逻辑处理
分区并发
- Kafka 的 Topic 可以分成多个 Partition,每个 Paritition 类似于一个队列,保证数据有序。同一个 Group 下的不同 Consumer 并发消费 Paritition,分区实际上是调优 Kafka 并行度的最小单元,因此,可以说,每增加一个 Paritition 就增加了一个消费并发。
高效的文件数据结构
- 每个 Topic 又可以分为一个或多个分区。每个分区各自存在一个记录消息数据的日志文件。Kafka 每个分区日志在物理上实际按大小被分成多个 Segment。
- segment file 组成:由 2 大部分组成,分别为 index file 和 data file,此 2 个文件一一对应,成对出现,
- index 采用稀疏索引,这样每个 index 文件大小有限,Kafka 采用mmap的方式,直接将 index 文件映射到内存,这样对 index 的操作就不需要操作磁盘 IO
- 分段和索引的策略:利用偏移量和时间索引文件实现快速消息查找
高可用
-
Kafka
- Kafka 从 0.8 版本开始提供了高可用机制,可保障一个或多个 Broker 宕机后,其他 Broker 能继续提供服务
分区副本、备份机制

同一个 Partition 存在多个消息副本,每个 Partition 的副本通常由 1 个 Leader 及 0 个以上的 Follower 组成,
- Kafka 会尽量将所有的 Partition 以及各 Partition 的副本均匀地分配到整个集群的各个 Broker 上
- 多副本机制
- 分区(Partition)引入了多副本(Replica)机制。
- 多分区、多副本机制好处呢?
- 1. Kafka 通过给特定 Topic 指定多个 Partition分区, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力(负载均衡)。
- 2. Partition 可以指定对应的 Replica 数, 这也极大地提高了消息存储的安全性, 提高了容灾能力,不过也相应的增加了所需要的存储空间。
ACK 机制
-
-
-
- 生产者发送消息中包含 acks 字段,该字段代表 Leader 应答生产者前 Leader 收到的应答数
- 「acks=0」
- 生产者无需等待服务端的任何确认,因此 acks=0 不能保证服务端已收到消息
- 「acks=1」默认值
- 只要 Partition Leader 接收到消息而且写入本地磁盘了,就认为成功了,不管其他的 Follower 有没有同步
- 「acks=all or -1」
- 服务端会等所有的 follower 的副本受到数据后才会收到 leader 发出的 ack,这样数据不会丢失
- Broker 有个配置项min.insync.replicas(默认值为 1)代表了正常写入生产者数据所需要的最少 ISR 个数
- 发送的 acks=1 和 0 消息会出现丢失情况,为了不丢失消息可配置生产者acks=all & min.insync.replicas >= 2
-
-
ISR 机制
-
-
-
- ISR 中的副本都是与 Leader 同步的副本,不在 ISR 中的Follower副本就被认为是没有资格的
- Follower 周期性地向 Leader 发送 FetchRequest 请求,发送时间间隔配置在replica.fetch.wait.max.ms中,默认值为 500
- 每个分区的 Leader 负责维护 ISR 列表并将 ISR 的变更同步至 ZooKeeper,被移出 ISR 的 Follower 会继续向 Leader 发 FetchRequest 请求,试图再次跟上 Leader 重新进入 ISR
- ISR 中所有副本都跟上了 Leader,通常只有 ISR 里的成员才可能被选为 Leader
-
-
主从同步
-
-
-
- 1、Follower副本通过发送Fetch请求来同步Leader副本上的数据。
- LEO(Log End Offset)
- 对于Leader副本和每个Follower副本来说,它们都有各自的LEO
- LEO是下一个要写入的消息的偏移量
- HW(High Watermark)
- HW是分区中所有副本的已提交消息的最大偏移量。是分区中所有ISR(In-Sync Replicas)副本的LEO中的最小值
- 只要分区的Leader副本和至少一个Follower副本保持同步,消费者就能看到所有已提交的消息,即使Leader副本发生故障
- 确保了Kafka在分区的Leader副本发生故障时,可以从ISR中选举出一个Follower副本作为新的Leader,
- Unclean 领导者选举
- 当 Kafka 中unclean.leader.election.enable配置为 true(默认值为 false)且 ISR 中所有副本均宕机的情况下,
- 开启 Unclean 领导者选举可能会造成数据丢失,但好处是,它使得分区 Leader 副本一直存在,不至于停止对外提供服务,因此提升了高可用性,
-
-
Leader 选举 & 故障恢复机制
-
-
-
- 「Kafka 从 0.8 版本开始引入了一套 Leader 选举及失败恢复机制」
- 在集群所有 Broker 中选出一个 Controller,负责各 Partition 的 Leader 选举以及 Replica 的重新分配
- Controller
- 集群中的 Controller 也会出现故障,因此 Kafka 让所有 Broker 都在 ZooKeeper 的 Controller 节点上注册一个 Watcher。
- 当出现 Leader 故障后,Controller 会将 Leader/Follower 的变动通知到需要为此作出响应的 Broker。
- Kafka 使用 ZooKeeper 存储 Broker、Topic 等状态数据,Kafka 集群中的 Controller 和 Broker 会在 ZooKeeper 指定节点上注册 Watcher(事件监听器),以便在特定事件触发时,由 ZooKeeper 将事件通知到对应 Broker
- 当 Broker 发生故障后,由 Controller 负责选举受影响 Partition 的新 Leader 并通知到相关 Broker
-
-
相关文章:
【MQ】探索 Kafka
基本概念 主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。 分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。消息位移:Offset。表示分区中每条消息的位置信息,是一个…...

Workbench 中的热源仿真
探索使用自定义工具对移动热源进行建模及其在不同行业中的应用。 了解热源动力学 对移动热源进行建模为各种工业过程和应用提供了有价值的见解。激光加热和材料加工使用许多激光束来加热、焊接或切割材料。尽管在某些情况下,热源 (q) 不是通…...

计算机网络 笔记 网络层 3
IPv6 IPv6 是互联网协议第 6 版(Internet Protocol Version 6)的缩写,它是下一代互联网协议,旨在解决 IPv4 面临的一些问题,以下是关于 IPv6 的详细介绍: 产生背景: 随着互联网的迅速发展&…...

翼星求生服务器搭建【Icarus Dedicated Server For Linux】
一、前言 本次搭建的服务器为Steam平台一款名为Icarus的沙盒、生存、建造游戏,由于官方只提供了Windows版本服务器导致很多热爱Linux的小伙伴无法释怀,众所周知Linux才是专业服务器的唯一准则。虽然Github上已经有大佬制作了容器版本但是容终究不够完美,毕竟容器无法与原生L…...

ZZNUOJ(C/C++)基础练习1011——1020(详解版)
目录 1011 : 圆柱体表面积 C语言版 C版 1012 : 求绝对值 C语言版 C版 1013 : 求两点间距离 C语言版 C版 1014 : 求三角形的面积 C语言版 C版 1015 : 二次方程的实根 C语言版 C版 1016 : 银行利率 C语言版 C版 1017 : 表面积和体积 C语言版 C版 代码逻辑…...

论文阅读:Realistic Noise Synthesis with Diffusion Models
这篇文章是 2025 AAAI 的一篇工作,主要介绍的是用扩散模型实现对真实噪声的仿真模拟 Abstract 深度去噪模型需要大量来自现实世界的训练数据,而获取这些数据颇具挑战性。当前的噪声合成技术难以准确模拟复杂的噪声分布。我们提出一种新颖的逼真噪声合成…...

复杂场景使用xpath定位元素
在复杂场景下使用XPath定位元素时,可以通过以下高级技巧提高定位准确性和稳定性: 动态属性处理 模糊匹配: //div[contains(id, dynamic-part)] //button[starts-with(name, btn-)] //input[ends-with(class, -input)] (需XPath 2.0)多属性…...

算法基础——存储
引入 基础理论的进步,是推动技术实现重大突破,促使相关领域的技术达成跨越式发展的核心。 在发展日新月异的大数据领域,基础理论的核心无疑是算法。不管是技术设计,还是工程实践,都必须仰仗相关算法的支持࿰…...
)
动态规划 (环形)
在一个圆形操场的四周摆放着n堆石子,现要将石子有次序地合并成一堆。规定每次只能选相邻2堆石子合并成新的一堆,并将新的一堆石子数记为该次合并的得分。试设计一个算法,计算出将n堆石子合并成一堆的最小得分和最大得分。 输入格式: n表示n…...

信号模块--simulink操作
位置simulink/sourses 常用的模块 功能:常数模块,提供一个常数 数据设置可以是一维或多维 一维数据设置 多维数据设置(例三维数据设置) 方波脉冲模块 模块用于按固定间隔生成方波脉冲信号 振幅就是方波的幅度,0到…...

Streamlit入门
1、Streamlit是什么 Streamlit 是一个用于快速构建数据应用的开源 Python 库,由 Streamlit 公司开发并维护。它极大地简化了从数据脚本到交互式 Web 应用的转化过程,让开发者无需具备前端开发的专业知识,就能轻松创建出美观、实用的交互式应…...
)
列表(列表是什么)
你将学习列表是什么以及如何使用列表元素。列表让你能够在一个地方存储成组的信息,其中可以只包含几个元素,也可以包含数百万个元素。 列表是新手可直接使用的最强大的Python功能之一,它融合了众多重要的编程概念。 列表是什么 列表 由一系列…...

笔记本搭配显示器
笔记本:2022款拯救者Y9000P,显卡RTX3060,分辨率2560*1600,刷新率:165Hz,无DP1.4口 显示器:2024款R27Q,27存,分辨率2560*1600,刷新率:165Hz &…...

基于排队理论的物联网发布/订阅通信系统建模与优化
论文标题 英文标题:Queuing Theory-Based Modeling and Optimization of a Publish/Subscribe IoT Communication System 中文标题:基于排队理论的物联网发布/订阅通信系统建模与优化 作者信息 Franc Pouhela Anthony Kiggundu Hans D. Schotten …...

指针(C语言)从0到1掌握指针,为后续学习c++打下基础
目录 一,指针 二,内存地址和指针 1,什么是内存地址 2,指针在不同系统下所占内存 三,指针的声明和初始化以及类型 1,指针的声明 2,指针 的初始化 1, 初始化方式优点及适用场景 4,指针的声明初始化类型…...

实验八 JSP访问数据库
实验八 JSP访问数据库 目的: 1、熟悉JDBC的数据库访问模式。 2、掌握使用My SQL数据库的使用 实验要求: 1、通过JDBC访问mysql数据,实现增删改查功能的实现 2、要求提交实验报告,将代码和实验结果页面截图放入报告中 实验过程&a…...

Day31-【AI思考】-关键支点识别与战略聚焦框架
文章目录 关键支点识别与战略聚焦框架**第一步:支点目标四维定位法****第二步:支点验证里程碑设计****第三步:目标网络重构方案****第四步:动态监控仪表盘** 执行工具箱核心心法 关键支点识别与战略聚焦框架 让思想碎片重焕生机的…...

DeepSeek与其他大模型相比
DeepSeek与其他大模型相比 与GPT-4对比 性能方面 推理速度:DeepSeek在解决复杂的数学、物理和逻辑推理问题方面速度惊人,是ChatGPT的两倍。“幻觉”现象:在处理需要网络信息检索的任务时,DeepSeek的“幻觉”现象似乎比ChatGPT更少。创意任务:ChatGPT在创意性任务,如创作…...
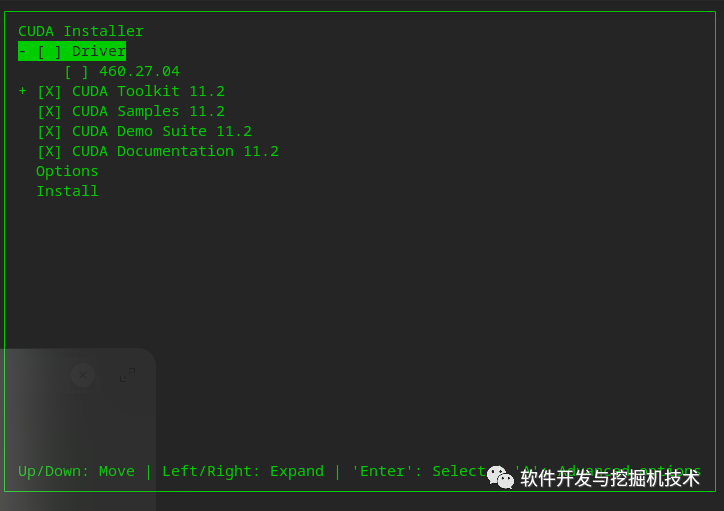
在深度Linux (Deepin) 20中安装Nvidia驱动
文章创作不易,麻烦大家点赞关注收藏一键三连。 在Deepin上面跑Tensorflow, pytorch等人工智能框架不是一件容易的事情。特别是如果你要使用GPU,就得有nvidia的驱动。默认情况下Deepin系统自带的是nouveau开源驱动。这是没办法用tensorflow的。下面内容是…...

“LoRA技术中参数初始化策略:为何A参数采用正态分布而B参数初始化为0”
在LoRA(Low-Rank Adaptation)中,参数A和B的初始化策略是经过精心设计的,以确保模型训练的稳定性和有效性。具体来说,参数A通常被初始化为正态分布,而参数B则初始化为0。这样的设计有以下几个优点࿱…...

乙巳马年·皇城大门春联生成终端W安全部署实践:网络配置与访问控制
乙巳马年皇城大门春联生成终端W安全部署实践:网络配置与访问控制 最近在星图GPU平台上部署了一个挺有意思的AI应用,叫“皇城大门春联生成终端W”。说白了,就是一个能根据你的要求,自动生成各种风格春联的AI模型。部署过程本身不难…...

使用Chandra构建数学建模助手:美赛备战全攻略
使用Chandra构建数学建模助手:美赛备战全攻略 1. 引言 数学建模竞赛就像一场智力马拉松,需要在有限时间内解决复杂问题。每年美赛期间,无数团队熬夜奋战,只为找到最优解决方案。但现实往往是:选题纠结、算法选择困难…...

超轻量级OpenClaw与LaTeX结合:学术文档自动化处理
超轻量级OpenClaw与LaTeX结合:学术文档自动化处理 科研工作者每天需要处理大量的文献整理、公式编辑和文档排版工作,传统手动方式耗时且容易出错。本文将展示如何用超轻量级OpenClaw实现学术文档的自动化处理,让LaTeX文档编写变得轻松高效。 …...

Qwen3-Reranker-0.6B一文详解:轻量0.6B参数如何实现SOTA级重排序性能
Qwen3-Reranker-0.6B一文详解:轻量0.6B参数如何实现SOTA级重排序性能 1. 引言:为什么你需要关注这个0.6B的小模型? 如果你用过搜索引擎,肯定有过这样的体验:输入一个问题,搜出来一堆结果,但真…...
)
手把手教你用Cline插件5分钟搞定DeepSeek-R1模型接入(附硅基流动平台2000万Token福利)
5分钟极速上手:用Cline插件无缝对接DeepSeek-R1大模型实战指南 当你第一次听说只需要5分钟就能让一个强大的AI模型为你工作时,可能会觉得这像是某种夸张的营销话术。但作为一个曾经花了整整三天时间才搞定第一个模型接入的开发者,我可以负责任…...

影墨·今颜模型API接口开发与调用全指南
影墨今颜模型API接口开发与调用全指南 你是不是已经成功部署了影墨今颜模型,看着它能在本地生成惊艳的图片,心里正盘算着怎么把它变成一个能对外服务的“产品”?比如,让公司的设计团队直接调用,或者集成到自己的应用里…...

s2-proGPU部署方案:多模型共存时s2-pro显存隔离与QoS保障策略
s2-proGPU部署方案:多模型共存时s2-pro显存隔离与QoS保障策略 1. 引言 在GPU服务器上同时运行多个AI模型已成为常态,但这也带来了显存资源竞争和性能波动的问题。本文将详细介绍如何在多模型共存环境下,为s2-pro语音合成模型实现显存隔离与…...

FireRedASR Pro在微信小程序开发中的应用:实时语音输入与转写
FireRedASR Pro在微信小程序开发中的应用:实时语音输入与转写 不知道你有没有这样的经历:用手机打字回复长消息时,手指按得发酸;或者在线听课时,想快速记下老师的重点,手速却跟不上语速。在移动优先的今天…...

开源字体实用指南:Poppins字体家族的全方位应用策略
开源字体实用指南:Poppins字体家族的全方位应用策略 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 价值定位:如何让开源字体成为项目的视觉资产&#x…...

基于Xinference-v1.17.1的嵌入式Linux开发指南
基于Xinference-v1.17.1的嵌入式Linux开发指南 1. 引言 嵌入式设备上的AI推理一直是个技术挑战,特别是在资源受限的环境中部署大模型。Xinference-v1.17.1作为一个开源推理框架,为嵌入式Linux系统提供了轻量级的AI模型部署方案。无论你是想在树莓派上运…...