论文阅读:Realistic Noise Synthesis with Diffusion Models
这篇文章是 2025 AAAI 的一篇工作,主要介绍的是用扩散模型实现对真实噪声的仿真模拟
Abstract
深度去噪模型需要大量来自现实世界的训练数据,而获取这些数据颇具挑战性。当前的噪声合成技术难以准确模拟复杂的噪声分布。我们提出一种新颖的逼真噪声合成扩散器(Realistic Noise Synthesis Diffusor,RNSD)方法,利用扩散模型来应对这些挑战。通过将相机设置编码到一种时间感知的相机条件仿射调制(time - aware camera - conditioned affine modulation,TCCAM)中,RNSD 能够在各种相机条件下生成更逼真的噪声分布。此外,RNSD 集成了一个多尺度内容感知模块(multi - scale content - aware module,MCAM),使得能够生成在多个频率上具有空间相关性的结构化噪声。我们还引入了深度图像先验采样(Deep Image Prior Sampling,DIPS),这是一种基于深度图像先验的可学习采样序列,它在显著加速采样过程的同时,还能保持合成噪声的高质量。大量实验表明,我们的 RNSD 方法在多个指标下合成逼真噪声以及提升图像去噪性能方面,显著优于现有技术。
Introduction
在深度学习中,图像去噪是一个不适定问题,通常需要使用大量的数据对进行有监督训练。在 RGB 色彩空间中,一幅含噪图像 y \mathbf{y} y 可以通过以下公式建模为其无噪版本 s \mathbf{s} s 加上经过图像信号处理(ISP)后的噪声 n \mathbf{n} n:
y = I S P ( s + n ) (1) \mathbf{y} = \mathbf{ISP}(\mathbf{s} + \mathbf{n}) \tag{1} y=ISP(s+n)(1)
与 RAW 格式图像中可线性建模且空间独立的噪声不同,RGB 色彩空间中的噪声呈现出以下特点:
不规则且多样的噪声分布:图像信号处理(ISP)的后处理参数,如自动白平衡(AWB)、色彩校正矩阵(CCM)和伽马校正(GAMMA),由于其依赖于传感器、感光度(ISO)、场景和曝光设置,会导致噪声在不同场景、通道、ISO 等级以及像素间呈现出非均匀的变化。
噪声的结构与空间相关性:与空间相关的 ISP 操作,包括去马赛克、降噪和锐化等,会给噪声引入局部结构模式,从而增强了噪声与信噪比之间的相关性。
大多数数据集依赖多帧平均法,这不仅获取难度大,而且无法提供多样的噪声类型,也不能解决结构性噪声问题。一些方法将噪声建模为高斯白噪声,忽略了真实噪声中存在的空间相关性。基于生成对抗网络(GAN)的方法试图对真实噪声分布进行建模,但由于缺乏严格的似然函数,常常面临不稳定性和模式崩溃问题,导致生成的噪声分布与真实噪声分布不匹配。相比之下,扩散模型因其严格的似然推导,在图像生成方面表现得更为稳定且多样。然而,它们尚未成功应用于合成噪声生成,这可能是由于针对具有空间相关性的复杂噪声分布,其条件设计不够完善。
在本文中,我们引入了逼真噪声合成扩散器(Realistic Noise Synthesize Diffusor, RNSD),这是一种基于扩散模型来合成逼真 RGB 噪声数据的新方法。RNSD 能够借助来自各种公开数据集的干净图像,生成大量与真实世界噪声分布极为相似的噪声图像。RNSD 生成的增强数据,在降噪和图像保真度方面,都显著提升了现有去噪模型的性能。
具体而言,RNSD 使用真实的含噪图像 y \mathbf{y} y 作为初始状态 x 0 \mathbf{x}_0 x0 来构建用于噪声生成的扩散模型。为了有效适应多样的噪声分布,我们提出了一种时间感知相机条件仿射调制(time - aware camera - conditioned affine modulation),称为 TCCAM。该模块对不同的相机设置进行编码,并在采样过程中采用时间自适应条件仿射变换,使得 RNSD 能够合成多样化且逼真的噪声。
此外,我们构建了一个多尺度内容感知模块(multi - scale content - aware module,简称 MCAM),它将干净图像的多尺度引导信息整合到扩散网络中。该模块能有效地引导生成与信号相关且具有空间相关性的噪声。
基于深度图像先验理论,即网络先学习低频成分,然后学习高频成分,我们开发了深度图像先验采样(Deep Image Prior Sampling,DIPS)方法。与去噪扩散隐式模型(DDIM)不同,DIPS 采用基于蒸馏的单步模型和衰减采样,将原本 1000 步的模型缩减至仅 5 步,而准确率仅损失 4%,显著提高了采样效率。
综上所述,我们的主要贡献如下:
- 我们首次提出了一种基于扩散模型的真实噪声数据合成方法 RNSD。
- 我们设计了时间感知相机条件仿射调制(TCCAM),它能够更好地控制生成噪声的分布和强度。
- 通过构建多尺度内容感知模块(MCAM),引入了多频信息的耦合,使得能够生成更逼真的、具有空间相关性的噪声。
- 深度图像先验采样(DIPS):利用网络先学习低频成分再学习高频成分的深度图像先验特性,与 DDIM 相比,DIPS 将 1000 步的模型缩减至仅 5 步,而准确率仅损失 4%,从而提高了采样效率。
- 我们的方法在多个基准测试和指标上取得了领先的成果,显著提升了去噪模型的性能。
Methodology

-
图 2:(a) 通过扩散产生噪声的流程。(b) 我们的时空交叉注意力记忆模块(TCCAM)的流程。
© 我们设计的带有多尺度交叉注意力模块(MCAM)的 UNet 架构 -
我们提出了一种新颖的基于扩散的方法来合成逼真的噪声数据,称为 “基于扩散的真实噪声合成”(RNSD,见图 2(a))。
-
我们的方法以真实含噪图像作为初始条件,并融入了时间感知相机条件仿射调制(TCCAM,见图 2(b))来控制结果。
-
此外,我们引入了一个多尺度内容感知模块(MCAM,见图 2(c)),以引导生成与信号相关的噪声。
-
最后,我们基于深度图像先验(DIPS,Ulyanov、Vedaldi 和 Lempitsky,2018 年)设计了一种可学习的加速采样方法,如算法 2 所示。
Noise Generation via Diffusion
传统的扩散模型通常在无噪声的风格数据上进行训练,这种模型能够从任意高斯噪声分布中采样出目标域图像。相比之下,我们将具有真实噪声分布的图像视为目标域图像。如图 2(a)所示,通过用具有真实噪声分布的数据 y \mathbf{y} y 替换 x 0 \mathbf{x}_0 x0,并经过简单设置,扩散模型就能从任意高斯噪声分布中采样出真实噪声。
具体而言,我们采用去噪扩散概率模型(DDPM,Ho、Jain 和 Abbeel,2020)的概率模型。在正向过程中,使用一个 T T T 步的马尔可夫链来最小化先验概率 q ( x T ∣ x 0 ) q(\mathbf{x}_T|\mathbf{x}_0) q(xT∣x0),也就是将 x 0 \mathbf{x}_0 x0 扩散为具有方差噪声强度 β t \beta_t βt 的纯高斯分布 x T \mathbf{x}_T xT
q ( x T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) (2) \begin{aligned} q(\mathbf{x}_T|\mathbf{x}_0)&=\prod_{t = 1}^{T}q(\mathbf{x}_t|\mathbf{x}_{t - 1})\\ q(\mathbf{x}_t|\mathbf{x}_{t - 1})&=\mathcal{N}(\mathbf{x}_t;\sqrt{1-\beta_t}\mathbf{x}_{t - 1},\beta_t\mathbf{I}) \end{aligned} \tag{2} q(xT∣x0)q(xt∣xt−1)=t=1∏Tq(xt∣xt−1)=N(xt;1−βtxt−1,βtI)(2)
其中, I \mathbf{I} I 是单位协方差矩阵,对于相邻的两个步骤,借助重参数化, x t \mathbf{x}_t xt 可以看作是从先验分布 $q(\mathbf{x}t | \mathbf{x}{t-1}) $ 中采样得到的,该分布被视为由 x t − 1 \mathbf{x}_{t-1} xt−1 和 β t \beta_t βt 形成的高斯分布。
一般的采样过程是通过反向求解高斯马尔可夫链过程得到的,将其视为联合概率分布 p θ ( x 0 : T ) p_{\theta}(\mathbf{x}_{0:T}) pθ(x0:T) ,这可以理解为从上述高斯分布 x T \mathbf{x}_T xT 逐步去噪以获得采样结果 x 0 \mathbf{x}_0 x0。
p θ ( x 0 : T ) = p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ t ) (3) \begin{aligned} p_{\theta}(\mathbf{x}_{0:T})&=p(\mathbf{x}_T)\prod_{t = 1}^{T}p_{\theta}(\mathbf{x}_{t - 1}|\mathbf{x}_t)\\ p_{\theta}(\mathbf{x}_{t - 1}|\mathbf{x}_t)&=\mathcal{N}(\mathbf{x}_{t - 1};\mu_{\theta}(\mathbf{x}_t,t),\Sigma_t) \end{aligned} \tag{3} pθ(x0:T)pθ(xt−1∣xt)=p(xT)t=1∏Tpθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σt)(3)
其中 μ θ \mu_{\theta} μθ 是由网络估计的后验分布的均值, Σ t \Sigma_{t} Σt 是通过 β t \beta_t βt 正向计算得到的方差。我们引入了额外的信息,即干净图像 s \mathbf{s} s 和相机设置信息 c s \mathbf{cs} cs,以使整个过程更具可控性。从数学角度来看,该过程为:
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ t , Σ t ) μ t = μ θ ( x t , s , c s , t ) (4) \begin{aligned} p_{\theta}(\mathbf{x}_{t - 1}|\mathbf{x}_t)&=\mathcal{N}(\mathbf{x}_{t - 1};\mu_{\mathbf{t}},\Sigma_t)\\ \mu_{\mathbf{t}}&=\mu_{\theta}(\mathbf{x}_t, s, \mathbf{cs}, t) \end{aligned} \tag{4} pθ(xt−1∣xt)μt=N(xt−1;μt,Σt)=μθ(xt,s,cs,t)(4)
考虑到相机设置( c s \mathbf{cs} cs)信息在不同采样步骤中的影响变化以及 RGB 域中噪声的空间相关性,我们制定了增强的条件机制 —— 时间感知相机条件仿射调制(TCCAM)和多尺度内容感知模块(MCAM),以实现噪声生成模块与基于扩散的图像采样框架之间更紧密的耦合。
TCCAM: Time-aware Camera Conditioned Affine Modulation
- 算法 1:

如算法 1 所示,常规的扩散模型学习网络参数 ϵ θ \epsilon_{\theta} ϵθ,以便在正向过程中从 x 0 \mathbf{x}_0 x0 到 x t \mathbf{x}_t xt 预测添加的噪声分量 ϵ t \epsilon_{t} ϵt。然而,真实的噪声分布由多种因素决定,包括 ISO 增益、快门速度、色温、亮度等。在不区分不同条件下的噪声分布的情况下,基于空间光度变化、ISO 变化和传感器变化,从复杂噪声中学习一种通用分布是具有挑战性的。
根本问题在于,噪声分布在不同条件下差异很大。例如,不同传感器的噪声可能呈现出完全不同的分布。在学习过程中,网络倾向于收敛到数据集的总体期望,从而导致固定模式的噪声模式,这使得生成的噪声与目标噪声之间存在差异。为了解决这个问题,我们引入了算法 1 中所示的五个因素。
c s = ϕ ( i s o , s s , s t , c t , b m ) (5) \mathbf{cs} = \phi (iso, ss, st, ct, bm) \tag{5} cs=ϕ(iso,ss,st,ct,bm)(5)
其中,iso 是感光度(ISO),ss 是快门速度,st 是传感器类型,ct 是色温,bm 是亮度模式。这些因素通过一种编码方法( ϕ \phi ϕ)被嵌入,作为相机设置 c s \mathbf{cs} cs 的特征向量,以控制噪声生成。这种显式先验缩小了网络的学习范围,使其能够逼近更复杂多变的噪声分布。相机设置的影响应该随采样步骤而变化。例如,与图像信号处理器(ISP)高度相关的传感器类型(st)决定了噪声的基本形式,其影响通常与图像内容中的高频信息相关联。当 t t t 从 T T T 到 0 0 0 进行采样,从低频到高频恢复图像内容时,相机设置的影响逐渐增大。为了解决这个问题,我们提出了一种具有动态设置机制的时间感知相机条件仿射调制(TCCAM),其中不同因素的权重随采样步骤而变化。如图 2(b)所示,该过程如下:
γ , β = M L P 3 ( M L P 1 ( s i n u _ p o s ( t ) ) + M L P 2 ( c s ) ) F o u t p u t = γ ∗ F i n p u t + β (6) \begin{aligned} \gamma, \beta&=MLP_3(MLP_1(sinu\_pos(t)) + MLP_2(\mathbf{c}_s))\\ \mathbf{F}_{output}&=\gamma * \mathbf{F}_{input}+\beta \end{aligned} \tag{6} γ,βFoutput=MLP3(MLP1(sinu_pos(t))+MLP2(cs))=γ∗Finput+β(6)
其中,使用多层感知器(MLP)将相机设置与采用正弦位置编码(sinu_pos)的采样步骤一起进行编码,以便在 UNet 的每一层生成仿射参数 β \beta β 和 γ \gamma γ。这种方法通过对 UNet 中每一层的特征 F i n p u t \mathbf{F}_{input} Finput 应用仿射变换,实现了一种动态设置影响机制。
MCAM: Multi-scale Content-aware Module
真实的噪声分布与图像内容有着内在的联系,由于光子捕获和图像信号处理器(ISP)的处理,它在不同亮度区域会有所不同。受周等人(Zhou 等人,2020 年)关于噪声空间频率特性见解的启发,我们提出了一个多尺度内容感知模块(MCAM,见图 2(c)),用于对不同频率下噪声 - 图像的耦合进行建模。从数学角度来看,我们的方法如下:
F x t i = e n c o d e r i ( x t ) F s i = e n c o d e r i ( s ) , i = 1 , 2 , 3 F o i = d e c o d e r i ( C o n c a t ( F i , F s i , F x t i ) ) (7) \begin{aligned} \mathbf{F}_{\mathbf{x}_{t_i}}&=encoder_i(\mathbf{x}_t)\\ \mathbf{F}_{\mathbf{s}_i}&=encoder_i(\mathbf{s}),i = 1,2,3\\ \mathbf{F}_{\mathbf{o}_i}&=decoder_i(Concat(\mathbf{F}_i,\mathbf{F}_{\mathbf{s}_i},\mathbf{F}_{\mathbf{x}_{t_i}})) \end{aligned} \tag{7} FxtiFsiFoi=encoderi(xt)=encoderi(s),i=1,2,3=decoderi(Concat(Fi,Fsi,Fxti))(7)
其中,在编码器的三个下采样阶段,使用对称但不共享权重的编码器从 x t \mathbf{x}_t xt 和干净图像 s \mathbf{s} s 中提取特征。除了在 F i \mathbf{F}_i Fi 和 F x t i \mathbf{F}_{\mathbf{x}_{t_i}} Fxti 之间的标准跳跃连接外,我们在三个上采样阶段融入了 F s i \mathbf{F}_{\mathbf{s}_i} Fsi 的多尺度特征。
Deep Image Prior Sampling(DIPS)
基于深度图像先验论文中的观察,即网络在学习高频噪声之前首先学习干净的低频成分,我们在去噪扩散概率模型(DDPM)采样过程中注意到了类似的模式。反向库尔贝克 - 莱布尼茨散度(AKLD)的下降随着采样从 1000 步推进而显示出越来越大的梯度,这表明基于扩散的真实噪声合成(RNSD)从低频内容过渡到高频噪声,如图 3 所示。由于去噪扩散隐式模型(DDIM)使用均匀的采样步骤,它与我们的噪声估计任务不太契合。因此,正如我们的实验所示,减少采样步骤的数量会导致性能大幅下降。
为了解决这个问题,我们提出了一种新的采样方式:
t = t l a s t + ( T − t l a s t ) e r ( i − 1 S − 1 ) − 1 e r − 1 , i = S : 1 (8) t = t_{last}+(T - t_{last})\frac{e^{r(\frac{i - 1}{S - 1})}-1}{e^{r}-1}, \quad i = S:1 \tag{8} t=tlast+(T−tlast)er−1er(S−1i−1)−1,i=S:1(8)
其中, T T T 是去噪扩散概率模型(DDPM)的采样步骤数, S S S 是基于深度图像先验(DIPS)的采样步骤数。 t l a s t t_{last} tlast 是第 0 步之前的最后一个采样步骤。由于边界效应,最后几步的生成效果较弱,所以当总采样步骤数减少时,将其置于重要步骤中。 r r r 控制采样密度的梯度。对于 T = 1000 T=1000 T=1000 和 S = 10 S=10 S=10,得到采样序列 [ 1000 , 572 , 327 , 186 , 106 , 59 , 33 , 18 , 9 , 4 , 0 ] [1000, 572, 327, 186, 106, 59, 33, 18, 9, 4, 0] [1000,572,327,186,106,59,33,18,9,4,0]。
我们的基础版本,即基本的基于深度图像先验(DIPS - Basic),在保持质量的同时将采样步骤数减少到。此外,我们发现从步到步的低频学习可以有效地由一个单步模型替代,从而能够从更接近的截断步骤而不是进行采样。
我们的基础版本,即基本的基于深度图像先验(DIPS - Basic),在保持质量的同时将采样步骤数 S S S 减少到 30。此外,我们发现从 1000 步到 200 步的低频学习可以有效地由一个单步模型替代,从而能够从更接近的截断步骤 N = 200 N=200 N=200 而不是 T = 1000 T=1000 T=1000 进行采样。其具体公式如下:
∇ θ ∥ ψ θ ( x T , t N ) − ϵ θ ( x N , t N ) ∥ (9) \nabla_{\theta} \left\lVert \psi_{\theta}(x_T, t_N) - \epsilon_{\theta}(x_N, t_N) \right\rVert \tag{9} ∇θ∥ψθ(xT,tN)−ϵθ(xN,tN)∥(9)
其中,单步模型 ψ θ \psi_{\theta} ψθ 是从预训练模型 ϵ θ \epsilon_{\theta} ϵθ 中提炼出来的,这使我们能够降低初始采样位置,并构建确定性映射,从而在保持质量的同时实现 5 步采样。如算法 2 所示,这种方法被称为高级版基于深度图像先验(DIPS - Advanced)。
- 算法 2

相关文章:
论文阅读:Realistic Noise Synthesis with Diffusion Models
这篇文章是 2025 AAAI 的一篇工作,主要介绍的是用扩散模型实现对真实噪声的仿真模拟 Abstract 深度去噪模型需要大量来自现实世界的训练数据,而获取这些数据颇具挑战性。当前的噪声合成技术难以准确模拟复杂的噪声分布。我们提出一种新颖的逼真噪声合成…...

复杂场景使用xpath定位元素
在复杂场景下使用XPath定位元素时,可以通过以下高级技巧提高定位准确性和稳定性: 动态属性处理 模糊匹配: //div[contains(id, dynamic-part)] //button[starts-with(name, btn-)] //input[ends-with(class, -input)] (需XPath 2.0)多属性…...

算法基础——存储
引入 基础理论的进步,是推动技术实现重大突破,促使相关领域的技术达成跨越式发展的核心。 在发展日新月异的大数据领域,基础理论的核心无疑是算法。不管是技术设计,还是工程实践,都必须仰仗相关算法的支持࿰…...
)
动态规划 (环形)
在一个圆形操场的四周摆放着n堆石子,现要将石子有次序地合并成一堆。规定每次只能选相邻2堆石子合并成新的一堆,并将新的一堆石子数记为该次合并的得分。试设计一个算法,计算出将n堆石子合并成一堆的最小得分和最大得分。 输入格式: n表示n…...

信号模块--simulink操作
位置simulink/sourses 常用的模块 功能:常数模块,提供一个常数 数据设置可以是一维或多维 一维数据设置 多维数据设置(例三维数据设置) 方波脉冲模块 模块用于按固定间隔生成方波脉冲信号 振幅就是方波的幅度,0到…...

Streamlit入门
1、Streamlit是什么 Streamlit 是一个用于快速构建数据应用的开源 Python 库,由 Streamlit 公司开发并维护。它极大地简化了从数据脚本到交互式 Web 应用的转化过程,让开发者无需具备前端开发的专业知识,就能轻松创建出美观、实用的交互式应…...
)
列表(列表是什么)
你将学习列表是什么以及如何使用列表元素。列表让你能够在一个地方存储成组的信息,其中可以只包含几个元素,也可以包含数百万个元素。 列表是新手可直接使用的最强大的Python功能之一,它融合了众多重要的编程概念。 列表是什么 列表 由一系列…...

笔记本搭配显示器
笔记本:2022款拯救者Y9000P,显卡RTX3060,分辨率2560*1600,刷新率:165Hz,无DP1.4口 显示器:2024款R27Q,27存,分辨率2560*1600,刷新率:165Hz &…...

基于排队理论的物联网发布/订阅通信系统建模与优化
论文标题 英文标题:Queuing Theory-Based Modeling and Optimization of a Publish/Subscribe IoT Communication System 中文标题:基于排队理论的物联网发布/订阅通信系统建模与优化 作者信息 Franc Pouhela Anthony Kiggundu Hans D. Schotten …...

指针(C语言)从0到1掌握指针,为后续学习c++打下基础
目录 一,指针 二,内存地址和指针 1,什么是内存地址 2,指针在不同系统下所占内存 三,指针的声明和初始化以及类型 1,指针的声明 2,指针 的初始化 1, 初始化方式优点及适用场景 4,指针的声明初始化类型…...

实验八 JSP访问数据库
实验八 JSP访问数据库 目的: 1、熟悉JDBC的数据库访问模式。 2、掌握使用My SQL数据库的使用 实验要求: 1、通过JDBC访问mysql数据,实现增删改查功能的实现 2、要求提交实验报告,将代码和实验结果页面截图放入报告中 实验过程&a…...

Day31-【AI思考】-关键支点识别与战略聚焦框架
文章目录 关键支点识别与战略聚焦框架**第一步:支点目标四维定位法****第二步:支点验证里程碑设计****第三步:目标网络重构方案****第四步:动态监控仪表盘** 执行工具箱核心心法 关键支点识别与战略聚焦框架 让思想碎片重焕生机的…...

DeepSeek与其他大模型相比
DeepSeek与其他大模型相比 与GPT-4对比 性能方面 推理速度:DeepSeek在解决复杂的数学、物理和逻辑推理问题方面速度惊人,是ChatGPT的两倍。“幻觉”现象:在处理需要网络信息检索的任务时,DeepSeek的“幻觉”现象似乎比ChatGPT更少。创意任务:ChatGPT在创意性任务,如创作…...
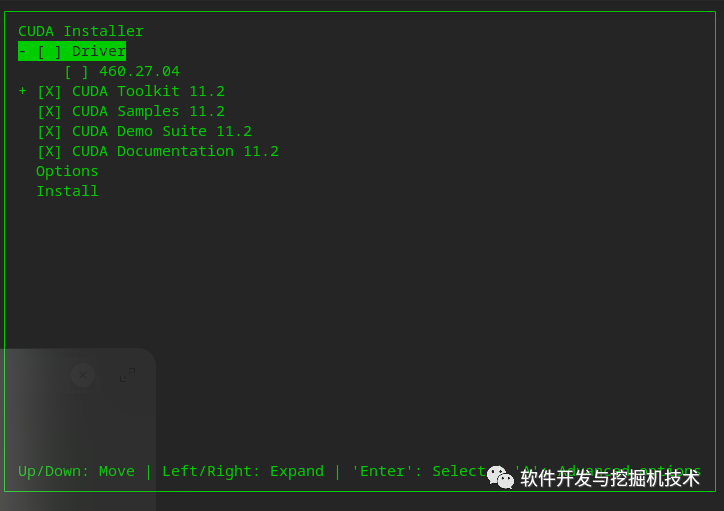
在深度Linux (Deepin) 20中安装Nvidia驱动
文章创作不易,麻烦大家点赞关注收藏一键三连。 在Deepin上面跑Tensorflow, pytorch等人工智能框架不是一件容易的事情。特别是如果你要使用GPU,就得有nvidia的驱动。默认情况下Deepin系统自带的是nouveau开源驱动。这是没办法用tensorflow的。下面内容是…...

“LoRA技术中参数初始化策略:为何A参数采用正态分布而B参数初始化为0”
在LoRA(Low-Rank Adaptation)中,参数A和B的初始化策略是经过精心设计的,以确保模型训练的稳定性和有效性。具体来说,参数A通常被初始化为正态分布,而参数B则初始化为0。这样的设计有以下几个优点࿱…...

C语言初阶力扣刷题——349. 两个数组的交集【难度:简单】
1. 题目描述 力扣在线OJ题目 给定两个数组,编写一个函数来计算它们的交集。 示例: 输入:nums1 [1,2,2,1], nums2 [2,2] 输出:[2] 输入:nums1 [4,9,5], nums2 [9,4,9,8,4] 输出:[9,4] 2. 思路 直接暴力…...

理解动手学深度学习的自编包d2l
跟着李沐的《动手学深度学习-PyTorch版》入门Python编程和Pytorch框架,以前是重度Matlab用户,对于Python里的各种包很不习惯。特别是,本书还自己做了一个名为d2l包,有几个问题很是困惑。今天终于弄明白了,写在这里&…...
)
RK3568使用opencv(使用摄像头捕获图像数据显示)
文章目录 一、opencv相关的类1. **cv::VideoCapture**2. **cv::Mat**3. **cv::cvtColor**4. **QImage**5. **QPixmap**总结 二、代码实现 一、opencv相关的类 1. cv::VideoCapture cv::VideoCapture 是 OpenCV 中用于视频捕捉的类,常用于从摄像头、视频文件、或者…...

OpenEuler学习笔记(十六):搭建postgresql高可用数据库环境
以下是在OpenEuler系统上搭建PostgreSQL高可用数据环境的一般步骤,通常可以使用流复制(Streaming Replication)或基于Patroni等工具来实现高可用,以下以流复制为例: 安装PostgreSQL 配置软件源:可以使用O…...

数学平均数应用
给定一个长度为 n 的数组 a。在一次操作中,你可以从索引 2 到 n−1中选择一个索引i,然后执行以下两个操作之一: 将 a[i−1] 减少 1,同时将 a[i1] 增加 1。 将 a[i1] 减少 1,同时将 a[i−1] 增加 1。 在每次操作后&…...

阿里云服务器上Certbot更新Let‘s Encrypt证书总超时?一个更换公网IP的实战解决记录
阿里云服务器Certbot更新Lets Encrypt证书超时问题深度解析与实战解决 最近在阿里云北京区域的服务器上更新Lets Encrypt证书时,遇到了一个看似简单却令人困扰的问题:Certbot在续签证书时频繁报错,提示acme-v02.api.letsencrypt.org连接超时。…...

Meta Manus vs OpenClaw:2026年AI Agent之战,谁才是你的最佳选择?
## 引言2026年AI Agent市场迎来爆发式增长,预计到2034年将达到1400亿美元规模。在这个赛道上,Meta的Manus和开源项目OpenClaw成为最受关注的两大竞争者。本文将深入分析两者的差异,帮助你做出最佳选择。## Meta Manus:巨头的入场#…...

Tesla Dashcam:3步搞定特斯拉行车记录视频合并的专业工具
Tesla Dashcam:3步搞定特斯拉行车记录视频合并的专业工具 【免费下载链接】tesla_dashcam Convert Tesla dash cam movie files into one movie 项目地址: https://gitcode.com/gh_mirrors/te/tesla_dashcam 还在为特斯拉行车记录仪生成的零散视频文件而烦恼…...

革命性超分辨率突破:OptiScaler让任何显卡实现4K级画质与帧率双提升
革命性超分辨率突破:OptiScaler让任何显卡实现4K级画质与帧率双提升 【免费下载链接】OptiScaler DLSS replacement for AMD/Intel/Nvidia cards with multiple upscalers (XeSS/FSR2/DLSS) 项目地址: https://gitcode.com/GitHub_Trending/op/OptiScaler 在…...

【PyO3/Rust-Python测试权威框架】:Rust生态下Python扩展的零信任CI流水线设计
第一章:Python 扩展模块测试Python 扩展模块(如用 C/C、Rust 或 Cython 编写的模块)在提升性能的同时,也引入了跨语言交互的复杂性。对其开展系统性测试,是保障功能正确性、内存安全性和 ABI 兼容性的关键环节。测试环…...

超越跑分:Gemini 3.1 Pro 2026年多维度能力评估体系深度拆解
对于追求精准选型的开发者和研究者而言,评估Gemini 3.1 Pro的真正实力需超越简单问答,而应建立一套涵盖推理、代码、长文本、安全性的多维度评估体系。目前,通过RskAi(www.rsk.cn)等聚合镜像站是国内用户以零成本、直接…...
)
别再让蜂鸣器只会‘哔哔’叫了!用STM32F103的PWM和电容,DIY你的家电提示音库(附超级玛丽彩蛋)
用STM32F103打造专业级家电提示音库:从单调蜂鸣到沉浸式音效的进阶指南 1. 为什么传统蜂鸣器音效总让人皱眉? 每次听到微波炉完成加热时刺耳的"嘀——"声,或是洗衣机结束运转时机械的"哔哔"提示,总让人有种想…...

React 转 Vue3 避坑指南:10个思维误区和正确写法
从 React 转来的开发者学 Vue3 最容易踩这10个坑,每个坑都附上错误写法和正确解法。前言React 和 Vue3 都是现代前端框架,但思维模型差异不小。很多 React 开发者转 Vue3 时,习惯性地用 React 思维写 Vue,导致各种奇怪的 bug。本文…...

AI皮衣设计新体验:The Leather Archive时尚杂志风界面实测
AI皮衣设计新体验:The Leather Archive时尚杂志风界面实测 1. 引言:当AI遇见时尚杂志 走进任何一家高端时尚杂志的编辑部,你会看到精心设计的版面、充满艺术感的排版和令人惊艳的视觉呈现。现在,这种专业级的时尚杂志体验被带入…...

零基础玩转RetinaFace:一键部署人脸检测,合影/监控都能精准识别
零基础玩转RetinaFace:一键部署人脸检测,合影/监控都能精准识别 1. 为什么选择RetinaFace人脸检测 在当今数字时代,人脸检测技术已经成为众多应用的基础功能。无论是社交媒体上的自动标记、安防监控系统的人脸识别,还是手机相册…...