【机器学习】自定义数据集 使用pytorch框架实现逻辑回归并保存模型,然后保存模型后再加载模型进行预测,对预测结果计算精确度和召回率及F1分数
一、使用pytorch框架实现逻辑回归
1. 数据部分:
- 首先自定义了一个简单的数据集,特征
X是 100 个随机样本,每个样本一个特征,目标值y基于线性关系并添加了噪声。 - 将
numpy数组转换为 PyTorch 张量,方便后续在模型中使用。
2. 模型定义部分:
方案 1:使用 nn.Sequential 直接按顺序定义了一个线性层,简洁直观。
import torch
import torch.nn as nn
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score# 自定义数据集
X = np.random.rand(100, 1).astype(np.float32)
y = 2 * X + 1 + 0.3 * np.random.randn(100, 1).astype(np.float32)# 转换为 PyTorch 张量
X_tensor = torch.from_numpy(X)
y_tensor = torch.from_numpy(y)# 定义线性回归模型
model = nn.Sequential(nn.Linear(1, 1)
)# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):# 前向传播outputs = model(X_tensor)loss = criterion(outputs, y_tensor)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 模型评估
with torch.no_grad():y_pred = model(X_tensor).numpy()mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")# 输出模型的系数和截距
print("模型系数:", model[0].weight.item())
print("模型截距:", model[0].bias.item())方案 2:使用 nn.ModuleList 存储线性层,在 forward 方法中依次调用层进行前向传播,适合动态构建层序列。
import torch
import torch.nn as nn
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score# 自定义数据集
X = np.random.rand(100, 1).astype(np.float32)
y = 2 * X + 1 + 0.3 * np.random.randn(100, 1).astype(np.float32)# 转换为 PyTorch 张量
X_tensor = torch.from_numpy(X)
y_tensor = torch.from_numpy(y)# 定义线性回归模型
class LinearRegression(nn.Module):def __init__(self):super(LinearRegression, self).__init__()self.layers = nn.ModuleList([nn.Linear(1, 1)])def forward(self, x):for layer in self.layers:x = layer(x)return xmodel = LinearRegression()# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):# 前向传播outputs = model(X_tensor)loss = criterion(outputs, y_tensor)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 模型评估
with torch.no_grad():y_pred = model(X_tensor).numpy()mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")# 输出模型的系数和截距
print("模型系数:", model.layers[0].weight.item())
print("模型截距:", model.layers[0].bias.item())方案 3:使用 nn.ModuleDict 以字典形式存储层,通过键名调用层,适合需要对层进行命名和灵活访问的场景。
import torch
import torch.nn as nn
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score# 自定义数据集
X = np.random.rand(100, 1).astype(np.float32)
y = 2 * X + 1 + 0.3 * np.random.randn(100, 1).astype(np.float32)# 转换为 PyTorch 张量
X_tensor = torch.from_numpy(X)
y_tensor = torch.from_numpy(y)# 定义线性回归模型
class LinearRegression(nn.Module):def __init__(self):super(LinearRegression, self).__init__()self.layers = nn.ModuleDict({'linear': nn.Linear(1, 1)})def forward(self, x):x = self.layers['linear'](x)return xmodel = LinearRegression()# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):# 前向传播outputs = model(X_tensor)loss = criterion(outputs, y_tensor)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 模型评估
with torch.no_grad():y_pred = model(X_tensor).numpy()mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")# 输出模型的系数和截距
print("模型系数:", model.layers['linear'].weight.item())
print("模型截距:", model.layers['linear'].bias.item())方案 4:直接继承 nn.Module,在 __init__ 方法中定义线性层,在 forward 方法中实现前向传播逻辑,是最常见和基础的定义模型方式。
import torch
import torch.nn as nn
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score# 自定义数据集
X = np.random.rand(100, 1).astype(np.float32)
y = 2 * X + 1 + 0.3 * np.random.randn(100, 1).astype(np.float32)# 转换为 PyTorch 张量
X_tensor = torch.from_numpy(X)
y_tensor = torch.from_numpy(y)# 定义线性回归模型
class LinearRegression(nn.Module):def __init__(self):super(LinearRegression, self).__init__()self.linear = nn.Linear(1, 1)def forward(self, x):return self.linear(x)model = LinearRegression()# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):# 前向传播outputs = model(X_tensor)loss = criterion(outputs, y_tensor)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 模型评估
with torch.no_grad():y_pred = model(X_tensor).numpy()mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")# 输出模型的系数和截距
print("模型系数:", model.linear.weight.item())
print("模型截距:", model.linear.bias.item())3. 训练和评估部分:
- 定义了均方误差损失函数
nn.MSELoss和随机梯度下降优化器torch.optim.SGD。 - 通过多个 epoch 进行训练,每个 epoch 包含前向传播、损失计算、反向传播和参数更新。
- 训练结束后,在无梯度计算模式下进行预测,并使用
scikit-learn的指标计算均方误差和决定系数评估模型性能,最后输出模型的系数和截距。
二、保存pytorch框架逻辑回归模型
在 PyTorch 中,有两种常见的保存模型的方式:保存模型的权重和其他参数,以及保存整个模型。下面将结合一个简单的逻辑回归模型示例,详细介绍这两种保存方式及对应的加载方法。
方式 1:保存模型的权重和其他参数
这种方式只保存模型的状态字典(state_dict),它包含了模型的所有可学习参数(如权重和偏置)。这种方法的优点是文件体积小,便于共享和迁移,缺点是加载时需要先定义模型结构。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 自定义数据集
X = np.random.randn(100, 2).astype(np.float32)
y = (2 * X[:, 0] + 3 * X[:, 1] > 0).astype(np.float32).reshape(-1, 1)X_tensor = torch.from_numpy(X)
y_tensor = torch.from_numpy(y)# 定义逻辑回归模型
class LogisticRegression(nn.Module):def __init__(self, input_size):super(LogisticRegression, self).__init__()self.linear = nn.Linear(input_size, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):out = self.linear(x)out = self.sigmoid(out)return out# 初始化模型
input_size = 2
model = LogisticRegression(input_size)# 定义损失函数和优化器
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):outputs = model(X_tensor)loss = criterion(outputs, y_tensor)optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 保存模型的权重和其他参数
torch.save(model.state_dict(), 'model_weights.pth')# 加载模型的权重和其他参数
loaded_model = LogisticRegression(input_size)
loaded_model.load_state_dict(torch.load('model_weights.pth'))
loaded_model.eval()# 生成新数据进行预测
new_X = np.random.randn(10, 2).astype(np.float32)
new_X_tensor = torch.from_numpy(new_X)with torch.no_grad():predictions = loaded_model(new_X_tensor)predicted_labels = (predictions >= 0.5).float()print("预测概率:")
print(predictions.numpy())
print("预测标签:")
print(predicted_labels.numpy())
代码解释
- 模型训练:首先定义并训练一个逻辑回归模型。
- 保存模型:使用
torch.save(model.state_dict(), 'model_weights.pth')保存模型的状态字典到文件model_weights.pth。 - 加载模型:先创建一个新的模型实例
loaded_model,然后使用loaded_model.load_state_dict(torch.load('model_weights.pth'))加载保存的状态字典。 - 预测:将模型设置为评估模式,生成新数据进行预测。
方式 2:保存整个模型
这种方式会保存整个模型对象,包括模型的结构和状态字典。优点是加载时不需要重新定义模型结构,缺点是文件体积较大,并且可能会受到 Python 版本和库版本的限制。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 自定义数据集
X = np.random.randn(100, 2).astype(np.float32)
y = (2 * X[:, 0] + 3 * X[:, 1] > 0).astype(np.float32).reshape(-1, 1)X_tensor = torch.from_numpy(X)
y_tensor = torch.from_numpy(y)# 定义逻辑回归模型
class LogisticRegression(nn.Module):def __init__(self, input_size):super(LogisticRegression, self).__init__()self.linear = nn.Linear(input_size, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):out = self.linear(x)out = self.sigmoid(out)return out# 初始化模型
input_size = 2
model = LogisticRegression(input_size)# 定义损失函数和优化器
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):outputs = model(X_tensor)loss = criterion(outputs, y_tensor)optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 保存整个模型
torch.save(model, 'whole_model.pth')# 加载整个模型
loaded_model = torch.load('whole_model.pth')
loaded_model.eval()# 生成新数据进行预测
new_X = np.random.randn(10, 2).astype(np.float32)
new_X_tensor = torch.from_numpy(new_X)with torch.no_grad():predictions = loaded_model(new_X_tensor)predicted_labels = (predictions >= 0.5).float()print("预测概率:")
print(predictions.numpy())
print("预测标签:")
print(predicted_labels.numpy())
代码解释
- 模型训练:同样先定义并训练逻辑回归模型。
- 保存模型:使用
torch.save(model, 'whole_model.pth')保存整个模型对象到文件whole_model.pth。 - 加载模型:使用
torch.load('whole_model.pth')直接加载整个模型。 - 预测:将模型设置为评估模式,生成新数据进行预测。
通过以上两种方式,可以根据实际需求选择合适的模型保存和加载方法。
三、加载pytorch框架逻辑回归模型
以下将分别详细介绍在 PyTorch 中针对只保存模型参数和保存结构与参数这两种不同保存方式对应的模型加载方法,同时给出完整的代码示例。
方式 1:只保存模型参数的加载方式
当用户只保存了模型的参数(即 state_dict)时,在加载模型时需要先定义好与原模型相同结构的模型,再将保存的参数加载到该模型中。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 自定义数据集
X = np.random.randn(100, 2).astype(np.float32)
y = (2 * X[:, 0] + 3 * X[:, 1] > 0).astype(np.float32).reshape(-1, 1)X_tensor = torch.from_numpy(X)
y_tensor = torch.from_numpy(y)# 定义逻辑回归模型
class LogisticRegression(nn.Module):def __init__(self, input_size):super(LogisticRegression, self).__init__()self.linear = nn.Linear(input_size, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):out = self.linear(x)out = self.sigmoid(out)return out# 初始化模型
input_size = 2
model = LogisticRegression(input_size)# 定义损失函数和优化器
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):outputs = model(X_tensor)loss = criterion(outputs, y_tensor)optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 保存模型的参数
torch.save(model.state_dict(), 'model_params.pth')# 加载模型的参数
# 重新定义模型结构
loaded_model = LogisticRegression(input_size)
# 加载保存的参数
loaded_model.load_state_dict(torch.load('model_params.pth'))
# 将模型设置为评估模式
loaded_model.eval()# 生成新数据进行预测
new_X = np.random.randn(10, 2).astype(np.float32)
new_X_tensor = torch.from_numpy(new_X)# 进行预测
with torch.no_grad():predictions = loaded_model(new_X_tensor)predicted_labels = (predictions >= 0.5).float()print("预测概率:")
print(predictions.numpy())
print("预测标签:")
print(predicted_labels.numpy())
代码解释
- 模型定义与训练:定义了一个简单的逻辑回归模型,并使用自定义数据集进行训练。
- 保存参数:使用
torch.save(model.state_dict(), 'model_params.pth')保存模型的参数。 - 加载参数:
- 重新定义与原模型相同结构的
loaded_model。 - 使用
loaded_model.load_state_dict(torch.load('model_params.pth'))加载保存的参数。
- 重新定义与原模型相同结构的
- 预测:将模型设置为评估模式,生成新数据进行预测。
方式 2:保存结构和参数的模型加载方式
当保存了模型的结构和参数时,加载模型就相对简单,直接使用 torch.load 函数即可加载整个模型。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 自定义数据集
X = np.random.randn(100, 2).astype(np.float32)
y = (2 * X[:, 0] + 3 * X[:, 1] > 0).astype(np.float32).reshape(-1, 1)X_tensor = torch.from_numpy(X)
y_tensor = torch.from_numpy(y)# 定义逻辑回归模型
class LogisticRegression(nn.Module):def __init__(self, input_size):super(LogisticRegression, self).__init__()self.linear = nn.Linear(input_size, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):out = self.linear(x)out = self.sigmoid(out)return out# 初始化模型
input_size = 2
model = LogisticRegression(input_size)# 定义损失函数和优化器
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):outputs = model(X_tensor)loss = criterion(outputs, y_tensor)optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 保存整个模型(结构和参数)
torch.save(model, 'whole_model.pth')# 加载整个模型
loaded_model = torch.load('whole_model.pth')
# 将模型设置为评估模式
loaded_model.eval()# 生成新数据进行预测
new_X = np.random.randn(10, 2).astype(np.float32)
new_X_tensor = torch.from_numpy(new_X)# 进行预测
with torch.no_grad():predictions = loaded_model(new_X_tensor)predicted_labels = (predictions >= 0.5).float()print("预测概率:")
print(predictions.numpy())
print("预测标签:")
print(predicted_labels.numpy())
代码解释
- 模型定义与训练:同样定义并训练逻辑回归模型。
- 保存整个模型:使用
torch.save(model, 'whole_model.pth')保存模型的结构和参数。 - 加载整个模型:使用
torch.load('whole_model.pth')直接加载整个模型。 - 预测:将模型设置为评估模式,生成新数据进行预测。
通过以上两种方式,可以根据不同的保存情况正确加载 PyTorch 模型。
五、计算pytorch模型预测结果的精确度
在机器学习任务中,计算预测结果的精确度(Accuracy)是评估模型性能的重要指标。对于回归任务,通常使用均方误差(MSE)、平均绝对误差(MAE)或R² 分数 来评估模型的性能;而对于分类任务,则使用准确率(Accuracy)、精确率(Precision)、召回率(Recall) 等指标。
以下是如何在 PyTorch 中计算预测结果的精确度(以回归任务为例):
1. 分类任务的精确度计算
对于分类任务,常用的评估指标是准确率(Accuracy),即预测正确的样本数占总样本数的比例。
代码实现
import torch# 假设有真实标签和预测标签
y_true = torch.tensor([0, 1, 1, 0, 1, 0, 0, 1]) # 真实标签
y_pred = torch.tensor([0, 1, 0, 0, 1, 0, 1, 1]) # 预测标签# 计算准确率
accuracy = (y_true == y_pred).float().mean()
print(f"准确率: {accuracy.item():.4f}")2. 回归任务的精确度计算
对于回归任务,常用的评估指标包括:
-
均方误差(MSE):预测值与真实值之间差异的平方的平均值。
-
平均绝对误差(MAE):预测值与真实值之间差异的绝对值的平均值。
-
R² 分数:表示模型对数据的拟合程度,取值范围为 [0, 1],越接近 1 表示模型越好。
代码实现
import torch
import torch.nn as nn# 假设有真实值和预测值
y_true = torch.tensor([3.0, 5.0, 7.0, 9.0], dtype=torch.float32)
y_pred = torch.tensor([2.8, 5.1, 7.2, 8.9], dtype=torch.float32)# 计算均方误差 (MSE)
mse = nn.MSELoss()(y_pred, y_true)
print(f"Mean Squared Error (MSE): {mse.item():.4f}")# 计算平均绝对误差 (MAE)
mae = nn.L1Loss()(y_pred, y_true)
print(f"Mean Absolute Error (MAE): {mae.item():.4f}")# 计算 R² 分数
def r2_score(y_true, y_pred):ss_total = torch.sum((y_true - torch.mean(y_true)) ** 2)ss_residual = torch.sum((y_true - y_pred) ** 2)r2 = 1 - (ss_residual / ss_total)return r2r2 = r2_score(y_true, y_pred)
print(f"R²分数: {r2.item():.4f}")六、计算pytorch模型预测结果的召回率
1. 召回率的定义
在分类任务中,召回率(Recall) 是一个重要的评估指标,用于衡量模型对正类样本的识别能力。召回率的定义是:
其中:
-
True Positives (TP):模型正确预测为正类的样本数。
-
False Negatives (FN):模型错误预测为负类的正类样本数。
2. 计算召回率的步骤
-
获取真实标签和预测标签:
- 真实标签(
y_true):数据集中样本的真实类别。 - 预测标签(
y_pred):模型对样本的预测类别。
-
计算混淆矩阵:
- 通过比较
y_true和y_pred,计算混淆矩阵中的 TP 和 FN。
-
计算召回率:
使用公式 计算召回率。
3. 二分类任务召回率代码
-
对于二分类任务,召回率衡量模型对正类样本的识别能力。
import torch# 假设有真实标签和预测标签
y_true = torch.tensor([0, 1, 1, 0, 1, 0, 0, 1]) # 真实标签
y_pred = torch.tensor([0, 1, 0, 0, 1, 0, 1, 1]) # 预测标签# 计算混淆矩阵
def confusion_matrix(y_true, y_pred):TP = ((y_true == 1) & (y_pred == 1)).sum().item() # 模型正确预测为正类的样本数FN = ((y_true == 1) & (y_pred == 0)).sum().item() # 模型错误预测为负类的正类样本数FP = ((y_true == 0) & (y_pred == 1)).sum().item() # 模型错误预测为正类的正类样本数TN = ((y_true == 0) & (y_pred == 0)).sum().item() # 模型正确预测为负类的样本数return TP, FN, FP, TN# 计算召回率
def recall_score(y_true, y_pred):TP, FN, _, _ = confusion_matrix(y_true, y_pred)if TP + FN == 0:return 0.0 # 避免除以零return TP / (TP + FN)# 计算召回率
recall = recall_score(y_true, y_pred)
print(f"召回率: {recall:.4f}")4. 多分类任务召回率代码
-
对于多分类任务,可以分别计算每个类别的召回率,然后取平均值。
import torch# 假设有真实标签和预测标签(多分类任务)
y_true = torch.tensor([0, 1, 2, 0, 1, 2]) # 真实标签
y_pred = torch.tensor([0, 1, 0, 0, 1, 2]) # 预测标签# 计算每个类别的召回率
def recall_score_multiclass(y_true, y_pred, num_classes):recall_scores = []for cls in range(num_classes):TP = ((y_true == cls) & (y_pred == cls)).sum().item() # 模型正确预测为正类的样本数FN = ((y_true == cls) & (y_pred != cls)).sum().item() # 模型错误预测为负类的正类样本数if TP + FN == 0:recall_scores.append(0.0) # 避免除以零else:recall_scores.append(TP / (TP + FN))return recall_scores# 计算召回率
num_classes = 3
recall_scores = recall_score_multiclass(y_true, y_pred, num_classes)
for cls, recall in enumerate(recall_scores):print(f"每个类别的召回率 {cls}: {recall:.4f}")# 计算宏平均召回率
macro_recall = sum(recall_scores) / num_classes
print(f"宏平均召回率: {macro_recall:.4f}")七、计算pytorch模型预测结果的F1分数
1. F1分数的定义
F1 分数(F1 Score) 是分类任务中常用的评估指标,结合了 精确率(Precision) 和 召回率(Recall) 的信息。F1 分数的定义是:
其中:
-
精确率(Precision):预测为正类的样本中,实际为正类的比例。
-
召回率(Recall):实际为正类的样本中,预测为正类的比例。
F1 分数的取值范围为 [0, 1],越接近 1 表示模型性能越好。
2. 计算 F1 分数的步骤
-
获取真实标签和预测标签:
- 真实标签(
y_true):数据集中样本的真实类别。 - 预测标签(
y_pred):模型对样本的预测类别。
-
计算混淆矩阵:
- 通过比较
y_true和y_pred,计算混淆矩阵中的 TP、FP 和 FN。
-
计算精确率和召回率:
- 精确率:
- 召回率:
-
计算 F1 分数:
- 使用公式:
3. 二分类任务F1分数代码
-
对于二分类任务,F1 分数结合了精确率和召回率,是评估模型性能的重要指标。
import torch# 假设有真实标签和预测标签
y_true = torch.tensor([0, 1, 1, 0, 1, 0, 0, 1]) # 真实标签
y_pred = torch.tensor([0, 1, 0, 0, 1, 0, 1, 1]) # 预测标签# 计算混淆矩阵
def confusion_matrix(y_true, y_pred):TP = ((y_true == 1) & (y_pred == 1)).sum().item() # 模型正确预测为正类的样本数FN = ((y_true == 1) & (y_pred == 0)).sum().item() # 模型错误预测为负类的正类样本数FP = ((y_true == 0) & (y_pred == 1)).sum().item() # 模型错误预测为正类的正类样本数TN = ((y_true == 0) & (y_pred == 0)).sum().item() # 模型正确预测为负类的样本数return TP, FN, FP, TN# 计算 F1 分数
def f1_score(y_true, y_pred):TP, FN, FP, _ = confusion_matrix(y_true, y_pred)# 计算精确率和召回率precision = TP / (TP + FP) if (TP + FP) > 0 else 0.0recall = TP / (TP + FN) if (TP + FN) > 0 else 0.0# 计算 F1 分数if precision + recall == 0:return 0.0 # 避免除以零f1 = 2 * (precision * recall) / (precision + recall)return f1# 计算 F1 分数
f1 = f1_score(y_true, y_pred)
print(f"F1分数: {f1:.4f}")4. 多分类任务F1分数代码
-
对于多分类任务,可以分别计算每个类别的 F1 分数,然后取平均值。
import torch# 假设有真实标签和预测标签(多分类任务)
y_true = torch.tensor([0, 1, 2, 0, 1, 2]) # 真实标签
y_pred = torch.tensor([0, 1, 0, 0, 1, 2]) # 预测标签# 计算每个类别的 F1 分数
def f1_score_multiclass(y_true, y_pred, num_classes):f1_scores = []for cls in range(num_classes):TP = ((y_true == cls) & (y_pred == cls)).sum().item() # 模型正确预测为正类的样本数FN = ((y_true == cls) & (y_pred != cls)).sum().item() # 模型错误预测为负类的正类样本数FP = ((y_true != cls) & (y_pred == cls)).sum().item() # 模型错误预测为正类的正类样本数# 计算精确率和召回率precision = TP / (TP + FP) if (TP + FP) > 0 else 0.0recall = TP / (TP + FN) if (TP + FN) > 0 else 0.0# 计算 F1 分数if precision + recall == 0:f1_scores.append(0.0) # 避免除以零else:f1_scores.append(2 * (precision * recall) / (precision + recall))return f1_scores# 计算 F1 分数
num_classes = 3
f1_scores = f1_score_multiclass(y_true, y_pred, num_classes)
for cls, f1 in enumerate(f1_scores):print(f"每个类别的F1分数 {cls}: {f1:.4f}")# 计算宏平均 F1 分数
macro_f1 = sum(f1_scores) / num_classes
print(f"宏平均 F1 分数: {macro_f1:.4f}")八、完整流程(使用直接继承 nn.Module逻辑回归,且仅保存模型的权重和其他参数,计算了二分类任务的精确度、召回率及F1分数)
1. 实现思路
① 自定义数据集:
生成 100 个样本,每个样本有 2 个特征。
根据特征生成标签,使用简单的线性组合和阈值判断。
② 定义逻辑回归模型:
使用 nn.Linear 定义一个线性层,并通过 实现逻辑回归。
③ 训练模型:
使用二元交叉熵损失 (nn.BCELoss) 和随机梯度下降优化器 (optim.SGD) 训练模型。
④ 保存模型:
使用 torch.save 保存模型参数。
⑤ 加载模型:
使用 torch.load 加载模型参数。
⑥ 预测:
加载模型后,使用新数据进行预测,并将概率转换为类别(0 或 1)。
⑦ 评估模型:
计算模型的精确度、召回率和 F1 分数。
2. 代码示例
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 自定义数据集
# 生成 100 个样本,每个样本有 2 个特征
X = np.random.randn(100, 2).astype(np.float32)
# 根据特征生成标签,使用简单的线性组合和阈值判断
y = (2 * X[:, 0] + 3 * X[:, 1] > 0).astype(np.float32).reshape(-1, 1)# 将 numpy 数组转换为 PyTorch 张量
X_tensor = torch.from_numpy(X)
y_tensor = torch.from_numpy(y)# 定义逻辑回归模型
class LogisticRegression(nn.Module):def __init__(self, input_size):super(LogisticRegression, self).__init__()self.linear = nn.Linear(input_size, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):out = self.linear(x)out = self.sigmoid(out)return out# 初始化模型
input_size = 2
model = LogisticRegression(input_size)# 定义损失函数和优化器
criterion = nn.BCELoss() # 二元交叉熵损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):# 前向传播outputs = model(X_tensor)loss = criterion(outputs, y_tensor)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 保存模型
torch.save(model.state_dict(), 'logistic_regression_model.pth')# 加载模型
loaded_model = LogisticRegression(input_size)
loaded_model.load_state_dict(torch.load('logistic_regression_model.pth'))
loaded_model.eval()# 生成新数据进行预测
new_X = np.random.randn(10, 2).astype(np.float32)
new_X_tensor = torch.from_numpy(new_X)# 使用加载的模型进行预测
with torch.no_grad():predictions = loaded_model(new_X_tensor)predicted_labels = (predictions >= 0.5).float()print("预测概率:")
print(predictions.numpy())
print("预测标签:")
print(predicted_labels.numpy())# 计算精确度、召回率和 F1 分数
def evaluate_model(y_true, y_pred):# 计算混淆矩阵TP = ((y_true == 1) & (y_pred == 1)).sum().item() # 模型正确预测为正类的样本数FN = ((y_true == 1) & (y_pred == 0)).sum().item() # 模型错误预测为负类的正类样本数FP = ((y_true == 0) & (y_pred == 1)).sum().item() # 模型错误预测为正类的正类样本数TN = ((y_true == 0) & (y_pred == 0)).sum().item() # 模型正确预测为负类的样本数# 计算精确度、召回率和 F1 分数accuracy = (TP + TN) / (TP + TN + FP + FN) if (TP + TN + FP + FN) > 0 else 0.0precision = TP / (TP + FP) if (TP + FP) > 0 else 0.0recall = TP / (TP + FN) if (TP + FN) > 0 else 0.0f1 = 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0 else 0.0return accuracy, precision, recall, f1# 对训练集进行预测,计算评估指标
with torch.no_grad():train_predictions = loaded_model(X_tensor)train_predicted_labels = (train_predictions >= 0.5).float()# 计算评估指标
accuracy, precision, recall, f1 = evaluate_model(y_tensor, train_predicted_labels)# 输出结果
print("\n模型评估结果:")
print(f"精确度: {accuracy:.4f}")
print(f"精确率: {precision:.4f}")
print(f"召回率: {recall:.4f}")
print(f"F1分数: {f1:.4f}")3. 代码解释
① 数据集生成:
X = np.random.randn(100, 2).astype(np.float32):生成 100 个样本,每个样本有 2 个特征。y = (2 * X[:, 0] + 3 * X[:, 1] > 0).astype(np.float32).reshape(-1, 1):根据特征的线性组合生成标签,大于 0 标记为 1,否则标记为 0。X_tensor = torch.from_numpy(X)和y_tensor = torch.from_numpy(y):将numpy数组转换为 PyTorch 张量。
② 模型定义:
LogisticRegression类继承自nn.Module,包含一个线性层nn.Linear和一个 Sigmoid 激活函数nn.Sigmoid。forward方法定义了前向传播的逻辑。
③ 损失函数和优化器:
criterion = nn.BCELoss():使用二元交叉熵损失函数,适用于二分类问题。optimizer = optim.SGD(model.parameters(), lr=0.01):使用随机梯度下降优化器,学习率为 0.01。
④ 模型训练:
- 通过多次迭代进行前向传播、损失计算、反向传播和参数更新。
- 每 100 个 epoch 打印一次损失值。
⑤ 模型保存:
torch.save(model.state_dict(), 'logistic_regression_model.pth'):保存模型的参数到本地文件logistic_regression_model.pth。
⑥ 模型加载和预测:
loaded_model = LogisticRegression(input_size):创建一个新的模型实例。loaded_model.load_state_dict(torch.load('logistic_regression_model.pth')):加载保存的模型参数。loaded_model.eval():将模型设置为评估模式。- 生成新数据
new_X并转换为张量new_X_tensor。 - 使用
loaded_model进行预测,通过(predictions >= 0.5).float()将预测概率转换为标签。
⑦ 模型评估:
-
定义
evaluate_model函数:
计算混淆矩阵(TP、FN、FP、TN)。
计算精确度、精确率、召回率和 F1 分数。
-
对训练集进行预测并计算评估指标:
train_predictions = loaded_model(X_tensor):计算训练集的预测概率。
train_predicted_labels = (train_predictions >= 0.5).float():将预测概率转换为标签。
-
输出评估结果:
精确度(Accuracy):模型预测正确的样本比例。
精确率(Precision):预测为正类的样本中,实际为正类的比例。
召回率(Recall):实际为正类的样本中,预测为正类的比例。
F1 分数(F1 Score):精确率和召回率的调和平均值。
相关文章:
【机器学习】自定义数据集 使用pytorch框架实现逻辑回归并保存模型,然后保存模型后再加载模型进行预测,对预测结果计算精确度和召回率及F1分数
一、使用pytorch框架实现逻辑回归 1. 数据部分: 首先自定义了一个简单的数据集,特征 X 是 100 个随机样本,每个样本一个特征,目标值 y 基于线性关系并添加了噪声。将 numpy 数组转换为 PyTorch 张量,方便后续在模型中…...
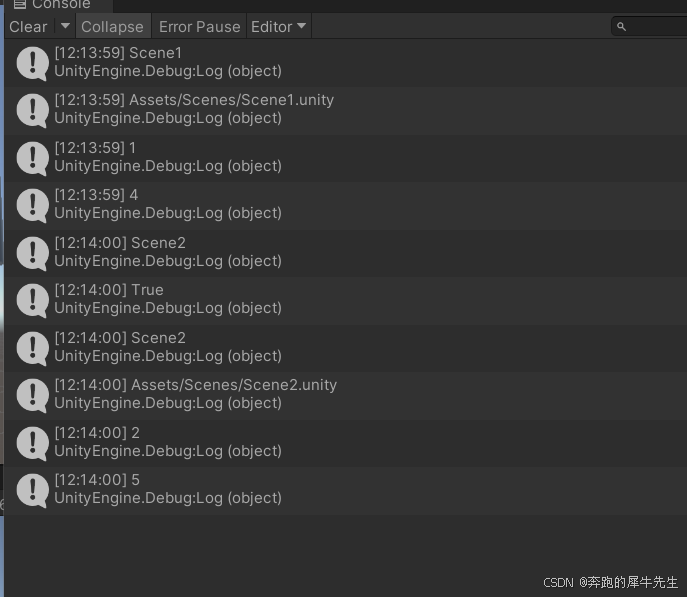
unity学习23:场景scene相关,场景信息,场景跳转
目录 1 默认场景和Assets里的场景 1.1 scene的作用 1.2 scene作为project的入口 1.3 默认场景 2 场景scene相关 2.1 创建scene 2.2 切换场景 2.3 build中的场景,在构建中包含的场景 (否则会认为是失效的Scene) 2.4 Scenes in Bui…...
自学路线)
AI(计算机视觉)自学路线
本文仅用来记录一下自学路线方便日后复习,如果对你自学有帮助的话也很开心o(* ̄▽ ̄*)ブ B站吴恩达机器学习->B站小土堆pytorch基础学习->opencv相关知识(Halcon或者opencv库)->四类神经网络(这里跟…...

Linux第104步_基于AP3216C之I2C实验
Linux之I2C实验是在AP3216C的基础上实现的,进一步熟悉修改设备树和编译设备树,以及学习如何编写I2C驱动和APP测试程序。 1、AP3216C的原理图 AP3216C集成了一个光强传感器ALS,一个接近传感器PS和一个红外LED,为三合一的环境传感…...
 - 20250131)
常用Android模拟器(雷电 MuMu 夜神 Genymotion 蓝叠) - 20250131
常用Android模拟器(雷电 MuMu 夜神 Genymotion 蓝叠) - 20250131 Android模拟器概述 Android 模拟器是一种软件工具,允许用户在 Windows、Linux 或 macOS 电脑上运行 Android 操作系统,以模拟 Android 设备的行为。它广泛用于 开发测试、应用运行、游戏…...

算法题(53):对称二叉树
审题: 需要我们判断二叉树是否满足对称结构,并返回判断结果 思路: 方法一:递归 其实是否对称分成两部分判断 第一部分:根节点是否相等 第二部分:根节点一的左子树和根节点二的右子树是否相等,根…...

Golang 并发机制-2:Golang Goroutine 和竞争条件
在今天的软件开发中,我们正在使用并发的概念,它允许一次执行多个任务。在Go编程中,理解Go例程是至关重要的。本文试图详细解释什么是例程,它们有多轻,通过简单地使用“go”关键字创建它们,以及可能出现的竞…...

深入剖析 CSRF 漏洞:原理、危害案例与防护
目录 前言 漏洞介绍 漏洞原理 产生条件 产生的危害 靶场练习 post 请求csrf案例 防御措施 验证请求来源 设置 SameSite 属性 双重提交 Cookie 结语 前言 在网络安全领域,各类漏洞层出不穷,时刻威胁着用户的隐私与数据安全。跨站请求伪造&…...

C++和Python实现SQL Server数据库导出数据到S3并导入Redshift数据仓库
用C实现高性能数据处理,Python实现操作Redshift导入数据文件。 在Visual Studio 2022中用C和ODBC API导出SQL Server数据库中张表中的所有表的数据为CSV文件格式的数据流,用逗号作为分隔符,用双引号包裹每个数据,字符串类型的数据…...

AI大模型开发原理篇-5:循环神经网络RNN
神经概率语言模型NPLM也存在一些明显的不足之处:模型结构简单,窗口大小固定,缺乏长距离依赖捕捉,训练效率低,词汇表固定等。为了解决这些问题,研究人员提出了一些更先进的神经网络语言模型,如循环神经网络、…...

4-图像梯度计算
文章目录 4.图像梯度计算(1)Sobel算子(2)梯度计算方法(3)Scharr与Laplacian算子4.图像梯度计算 (1)Sobel算子 图像梯度-Sobel算子 Sobel算子是一种经典的图像边缘检测算子,广泛应用于图像处理和计算机视觉领域。以下是关于Sobel算子的详细介绍: 基本原理 Sobel算子…...

数据结构与算法 —— 常用算法模版
数据结构与算法 —— 常用算法模版 二分查找素数筛最大公约数与最小公倍数 二分查找 人间若有天堂,大马士革必在其中;天堂若在天空,大马士革必与之齐名。 —— 阿拉伯谚语 算法若有排序,二分查找必在其中;排序若要使用…...

DDD - 领域事件_解耦微服务的关键
文章目录 Pre领域事件的核心概念领域事件的作用领域事件的识别领域事件的技术实现领域事件的运行机制案例领域事件驱动的优势 Pre DDD - 微服务设计与领域驱动设计实战(中)_ 解决微服务拆分难题 EDA - Spring Boot构建基于事件驱动的消息系统 领域事件的核心概念 领域事件&a…...

芯片AI深度实战:实战篇之vim chat
利用vim-ollama这个vim插件,可以在vim内和本地大模型聊天。 系列文章: 芯片AI深度实战:基础篇之Ollama-CSDN博客 芯片AI深度实战:基础篇之langchain-CSDN博客 芯片AI深度实战:实战篇之vim chat-CSDN博客 芯片AI深度…...

【产品经理学习案例——AI翻译棒出海业务】
前言: 本文主要讲述了硬件产品在出海过程中,翻译质量、翻译速度和本地化落地策略是硬件产品规划需要考虑的核心因素。针对不同国家,需要优化翻译质量和算法,关注市场需求和文化差异,以便更好地满足当地用户的需求。同…...

解决运行npm时报错
在运行一个Vue项目时报错,产生下面问题 D:\node\npm.cmd run dev npm WARN logfile could not be created: Error: EPERM: operation not permitted, open D:\node\node_cache\_logs\2025-01-31T01_01_58_076Z-debug-0.log npm WARN logfile could not be created:…...

【07-编译工程与导入网表】
这里写自定义目录标题 一丶编译原理图编译默认属性一丶编译项目二丶输出BOM材料报告优化EXCEL-BOM清单 三丶输出PDF原理图给维修人员看 四丶导入网格表查看是否有错误常见错误 其他问题什么是位号(C1)?EXCEL添加序号列和居中显示?位号(序号)与单位(型号)EXCEL设置自动换行 编…...

FireFox | Google Chrome | Microsoft Edge 禁用更新 final版
之前的方式要么失效,要么对设备有要求,这次梳理一下对设备、环境几乎没有要求的通用方式,universal & final 版。 1.Firefox 方式 FireFox火狐浏览器企业策略禁止更新_火狐浏览器禁止更新-CSDN博客 这应该是目前最好用的方式。火狐也…...

conda配置channel
你收到 CondaKeyError: channels: value https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main not present in config 错误是因为该镜像源(https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main)可能没有被正确添加到 Conda 的配置文件中&…...

【MQ】探索 Kafka
基本概念 主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。 分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。消息位移:Offset。表示分区中每条消息的位置信息,是一个…...

新手避坑指南:给UR机械臂选配RealSense D435相机,这5个参数千万别看错
新手避坑指南:给UR机械臂选配RealSense D435相机,这5个参数千万别看错 第一次为UR机械臂选配深度相机时,我盯着RealSense D435的参数表发呆了半小时——那些专业术语像天书一样。直到项目因选型错误延误两周后,我才明白参数表里藏…...

FPGA做信号处理,你的浮点加减法拖后腿了吗?聊聊Vivado Floating-point IP核的性能调优
FPGA信号处理中浮点加减法的性能瓶颈与Vivado Floating-point IP核深度调优 在雷达脉冲压缩、波束成形等实时信号处理系统中,浮点运算单元往往是制约整体性能的关键瓶颈。许多工程师在完成基础功能验证后,常发现系统吞吐量不达标或时序无法收敛ÿ…...

OpenClaw多通道管理:百川2-13B-4bits量化模型同时接入飞书与钉钉
OpenClaw多通道管理:百川2-13B-4bits量化模型同时接入飞书与钉钉 1. 为什么需要多通道管理? 上个月我遇到一个尴尬场景:团队部分成员用飞书沟通,另一部分用钉钉。当我尝试用OpenClaw搭建自动化助手时,不得不在两个平…...

零知识证明终极指南:Awesome ZKP项目快速入门教程
零知识证明终极指南:Awesome ZKP项目快速入门教程 【免费下载链接】awesome-zero-knowledge-proofs A curated list of awesome things related to learning Zero-Knowledge Proofs (ZKP). 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-zero-knowledge-p…...

构建智能体协作网络:从 MCP 资源连接到 A2A 通信的 Agentic AI 工程实践
1. 智能体协作网络的基础架构 想象一下,你正在指挥一支由不同专家组成的团队完成市场报告。数据分析师负责整理数据,文案专员负责撰写内容,而行政助理则负责最终分发。在AI领域,这样的分工协作正是通过MCP协议和A2A协议实现的。前…...

深入解析DHT11单总线通信:如何通过时序控制实现稳定数据传输?
1. DHT11单总线通信的基本原理 第一次用DHT11传感器时,我被它只用一根线就能传数据惊到了。这就像两个人打电话,不需要复杂的线路,只要一根电话线就能聊天气温湿度。DHT11采用的单总线协议(1-Wire Protocol)就是这样一…...

【Unity实战】利用Preserve特性解决代码裁剪导致的反射调用失效问题
1. 代码裁剪与反射调用的相爱相杀 第一次遇到这个问题是在去年做手游项目的时候。那天测试同事急匆匆跑过来说:"哥,安卓包加载存档直接闪退!"我心想编辑器里明明好好的,怎么打包就出问题?打开日志一看&#…...

Ubuntu 20.04 虚拟机环境快速克隆与迁移实战指南
1. 为什么需要虚拟机环境克隆与迁移? 作为常年和虚拟机打交道的开发者,我深刻理解重复搭建环境的痛苦。每次新项目启动都要从头配置Ubuntu环境,安装依赖库,调试网络,这个过程至少要浪费半天时间。更可怕的是当团队需要…...
验证服务**在Web3.0时代,用户不再依赖中心化的身份提供商()
**发散创新:用Rust构建Web3.0去中心化身份(DID)验证服务**在Web3.0时代,用户不再依赖中心化的身份提供商(
发散创新:用Rust构建Web3.0去中心化身份(DID)验证服务 在Web3.0时代,用户不再依赖中心化的身份提供商(如Google、微信登录),而是通过去中心化身份(Decentralized Identity, DID&…...
—— 数码管动态扫描原理与实现)
51单片机(九)—— 数码管动态扫描原理与实现
1. 数码管动态扫描原理揭秘 第一次接触多位数码管显示时,我盯着电路板百思不得其解:明明只有8个数据引脚,怎么能同时控制8位数码管显示不同内容?直到理解了动态扫描原理,才恍然大悟这背后的精妙设计。动态扫描本质上是…...