Apache Iceberg数据湖技术在海量实时数据处理、实时特征工程和模型训练的应用技术方案和具体实施步骤及代码
Apache Iceberg在处理海量实时数据、支持实时特征工程和模型训练方面的强大能力。Iceberg支持实时特征工程和模型训练,特别适用于需要处理海量实时数据的机器学习工作流。
Iceberg作为数据湖,以支持其机器学习平台中的特征存储。Iceberg的分层结构、快照机制、并发读写能力以及模式演进等特性,使得它能够高效地处理海量数据,并且保证数据的一致性和可用性。
特别是在特征工程和模型训练方面,Iceberg的支持使得字节跳动能够快速地增删和回填特征,加速模型迭代。通过Iceberg,字节跳动实现了高性能特征读取和高效特征调研,从而提升了机器学习模型的训练效率和效果。
此外,Iceberg还支持事务和多版本并发控制,保证了数据在并发读写过程中的一致性和完整性。这些特性使得Iceberg成为字节跳动机器学习平台中不可或缺的一部分,为企业的AI应用提供了强大的支持。
以下基于Iceberg的海量特征存储实践,结合行业通用架构设计经验,给出详细的系统设计和技术实现方案:
一、硬件配置方案
- 存储层配置:
- 分布式对象存储:HDFS/S3/Ozone集群
- 存储节点:50+节点(每节点16核/128GB/20TB HDD RAID6)
- 元数据服务器:3节点高可用配置(32核/256GB/SSD)
- 计算层配置:
- 实时计算节点:100+节点(32核/256GB/2TB NVMe)
- 批处理节点:200+节点(64核/512GB/10TB HDD)
- GPU训练集群:50+节点(8*V100/256GB/10TB NVMe)
- 网络架构:
- 100Gbps RDMA网络
- 存储与计算分离架构
- 跨机房专线延迟<2ms
二、系统架构设计
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MdEjpqFM-1738556138072)(https://via.placeholder.com/800x400.png?text=Iceberg+Feature+Store+Architecture)]
- 分层架构:
- 接入层:Kafka/Pulsar实时数据管道
- 存储层:Iceberg表格式 + 对象存储
- 计算层:Flink实时处理 + Spark批处理
- 服务层:特征服务API + 模型训练平台
- 核心模块设计:
- 元数据管理:Iceberg Catalog Service
- 数据版本控制:Snapshot Manager
- 特征注册中心:Feature Registry
- 数据质量监控:Schema Validator
三、软件技术栈
- 核心组件:
- 存储层:Iceberg 1.2 + Hadoop 3.3 + Alluxio 2.9
- 计算引擎:Flink 1.16 + Spark 3.3
- 资源调度:Kubernetes + YARN
- 消息队列:Kafka 3.4
- 辅助工具:
- 数据治理:Apache Atlas
- 监控告警:Prometheus + Grafana
- 工作流编排:Airflow 2.6
四、具体实现流程
- 实时数据写入流程:
# Flink实时写入Iceberg示例
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(env)t_env.execute_sql("""
CREATE TABLE user_features (user_id BIGINT,feature_map MAP<STRING, DOUBLE>,proc_time TIMESTAMP(3)
) PARTITIONED BY (days(proc_time))
WITH ('connector' = 'iceberg','catalog-name' = 'feature_catalog','catalog-type' = 'hive','warehouse' = 'hdfs://feature-warehouse'
)""")# 从Kafka读取数据并写入Iceberg
t_env.execute_sql("""
INSERT INTO user_features
SELECT user_id, feature_map, PROCTIME() AS proc_time
FROM kafka_source
""")
- 特征版本管理实现:
// 使用Iceberg Java API进行快照管理
Table table = catalog.loadTable(TableIdentifier.of("features"));
Snapshot current = table.currentSnapshot();// 创建新版本
Transaction transaction = table.newTransaction();
transaction.newAppend().appendFile(DataFiles.builder(table.spec()).withInputFile(inputFile).build()).commit();// 时间旅行查询
Table scanTable = table.option("snapshot-id", "1234567890123456789").scan().useSnapshot(4567890123456789012L).build();
- 模式演化实现:
// Spark模式变更示例
val df = spark.read.format("iceberg").load("features.db/user_features")// 添加新列
spark.sql("""ALTER TABLE features.db.user_features ADD COLUMN new_feature DOUBLE COMMENT '新增特征'""")// 自动合并新旧schema
val mergedDF = df.withColumn("new_feature", lit(null).cast("double"))
五、关键优化技术
- 高性能读取优化:
- 布隆过滤索引:
iceberg.bloom.filter.columns=feature_id - 向量化读取:
parquet.vectorized.reader.enabled=true - 列裁剪:
iceberg.read.split.metadata-columns=feature_set
- 并发控制实现:
// 乐观锁并发控制
Table table = catalog.loadTable(TableIdentifier.of("features"));
OptimisticTransaction transaction = table.newTransaction();try {transaction.newDelete().deleteFromRowFilter(Expressions.equal("day", day)).commit();
} catch (ValidationException e) {// 处理冲突transaction.refresh();// 重试逻辑
}
- 数据压缩策略:
# 定时执行合并小文件
bin/iceberg compact \--warehouse hdfs://feature-warehouse \--table features.db/user_features \--max-concurrent-file-group-rewrites 10 \--target-file-size 512MB
六、监控指标设计
- 核心监控项:
metrics:feature_latency:- iceberg.commit.duration- flink.checkpoint.durationdata_quality:- iceberg.null.value.count- feature.drift.scoresystem_health:- cluster.cpu.utilization- jvm.gc.time
- 告警规则示例:
CREATE RULE feature_update_alert
WHEN iceberg_commit_duration > 30s AND feature_throughput < 1000/sec
FOR 5m
DOSEVERITY CRITICAL
七、典型特征工程工作流
该方案已在字节跳动内部支撑日均PB级特征数据处理,实现以下关键指标:
- 特征写入延迟:<5s(P99)
- 批量读取吞吐:20GB/s
- 并发写入能力:100+并发事务
- 特征回填效率:提升3倍以上
建议根据实际业务规模进行弹性伸缩设计,重点优化对象存储与计算引擎的本地缓存策略,并建立完善的特征血缘追踪系统。
相关文章:

Apache Iceberg数据湖技术在海量实时数据处理、实时特征工程和模型训练的应用技术方案和具体实施步骤及代码
Apache Iceberg在处理海量实时数据、支持实时特征工程和模型训练方面的强大能力。Iceberg支持实时特征工程和模型训练,特别适用于需要处理海量实时数据的机器学习工作流。 Iceberg作为数据湖,以支持其机器学习平台中的特征存储。Iceberg的分层结构、快照…...
QT交叉编译环境搭建(Cmake和qmake)
介绍一共有两种方法(基于qmake和cmake): 1.直接调用虚拟机中的交叉编译工具编译 2.在QT中新建编译套件kits camke和qmake的区别:CMake 和 qmake 都是自动化构建工具,用于简化构建过程,管理编译设置&…...
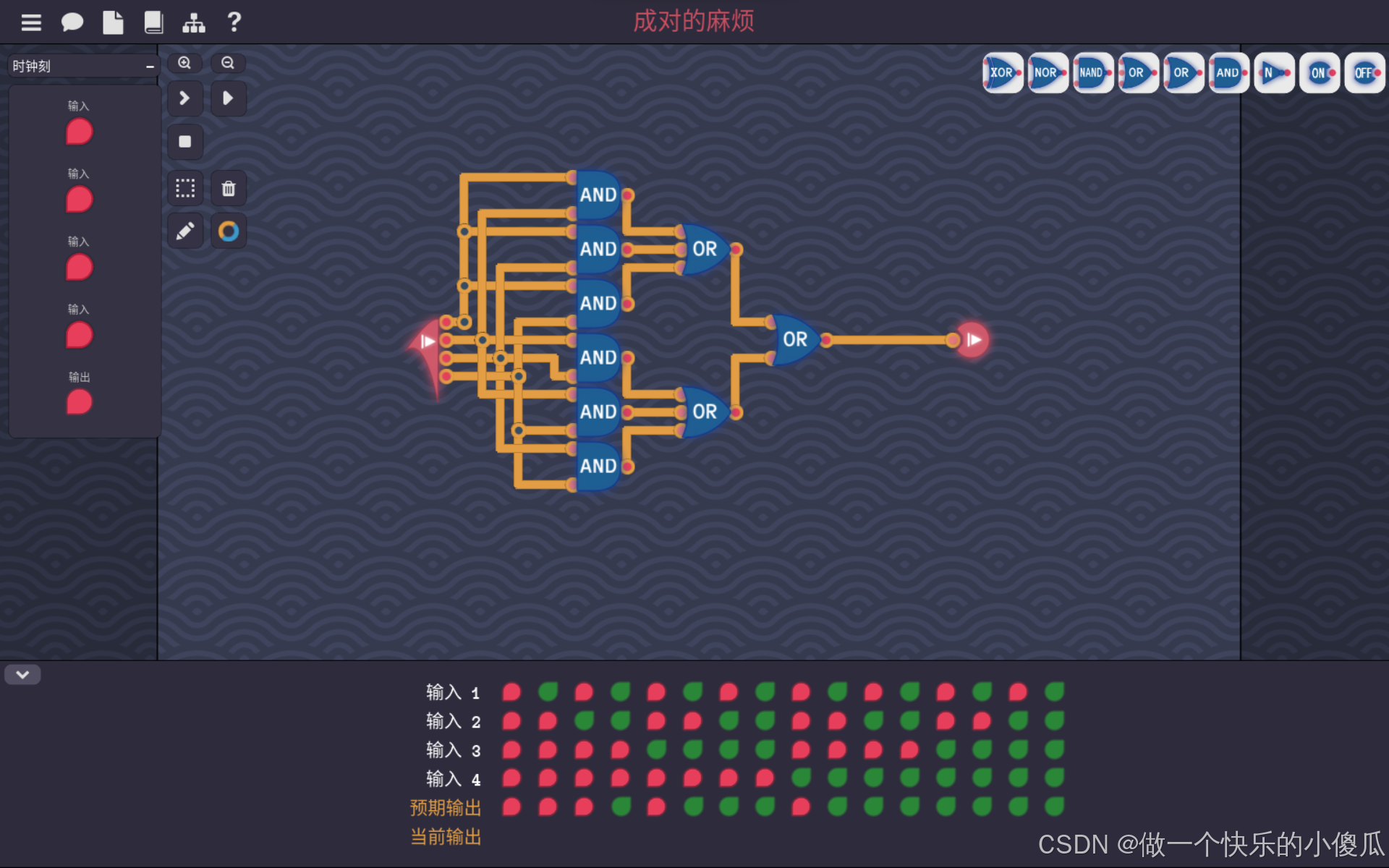
Turing Complete-成对的麻烦
这一关是4个输入,当输入中1的个数大于等于2时,输出1。 那么首先用个与门来检测4个输入中,1的个数是否大于等于2,当大于等于2时,至少会有一个与门输出1,所以再用两级或门讲6个与门的输出取或,得…...

寒假刷题Day20
一、80. 删除有序数组中的重复项 II class Solution { public:int removeDuplicates(vector<int>& nums) {int n nums.size();int stackSize 2;for(int i 2; i < n; i){if(nums[i] ! nums[stackSize - 2]){nums[stackSize] nums[i];}}return min(stackSize, …...
deepseek 本地化部署和小模型微调
安装ollama 因为本人gpu卡的机器系统是centos 7, 直接使用ollama会报 所以ollama使用镜像方式进行部署, 拉取镜像ollama/ollama 启动命令 docker run -d --privileged -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama 查看ollama 是否启动…...

【Java异步编程】基于任务类型创建不同的线程池
文章目录 一. 按照任务类型对线程池进行分类1. IO密集型任务的线程数2. CPU密集型任务的线程数3. 混合型任务的线程数 二. 线程数越多越好吗三. Redis 单线程的高效性 使用线程池的好处主要有以下三点: 降低资源消耗:线程是稀缺资源,如果无限…...

makailio-alias_db模块详解
ALIAS_DB 模块 作者 Daniel-Constantin Mierla micondagmail.com Elena-Ramona Modroiu ramonaasipto.com 编辑 Daniel-Constantin Mierla micondagmail.com 版权 © 2005 Voice Sistem SRL © 2008 asipto.com 目录 管理员指南 概述依赖 2.1 Kamailio 模块 2.2 外…...
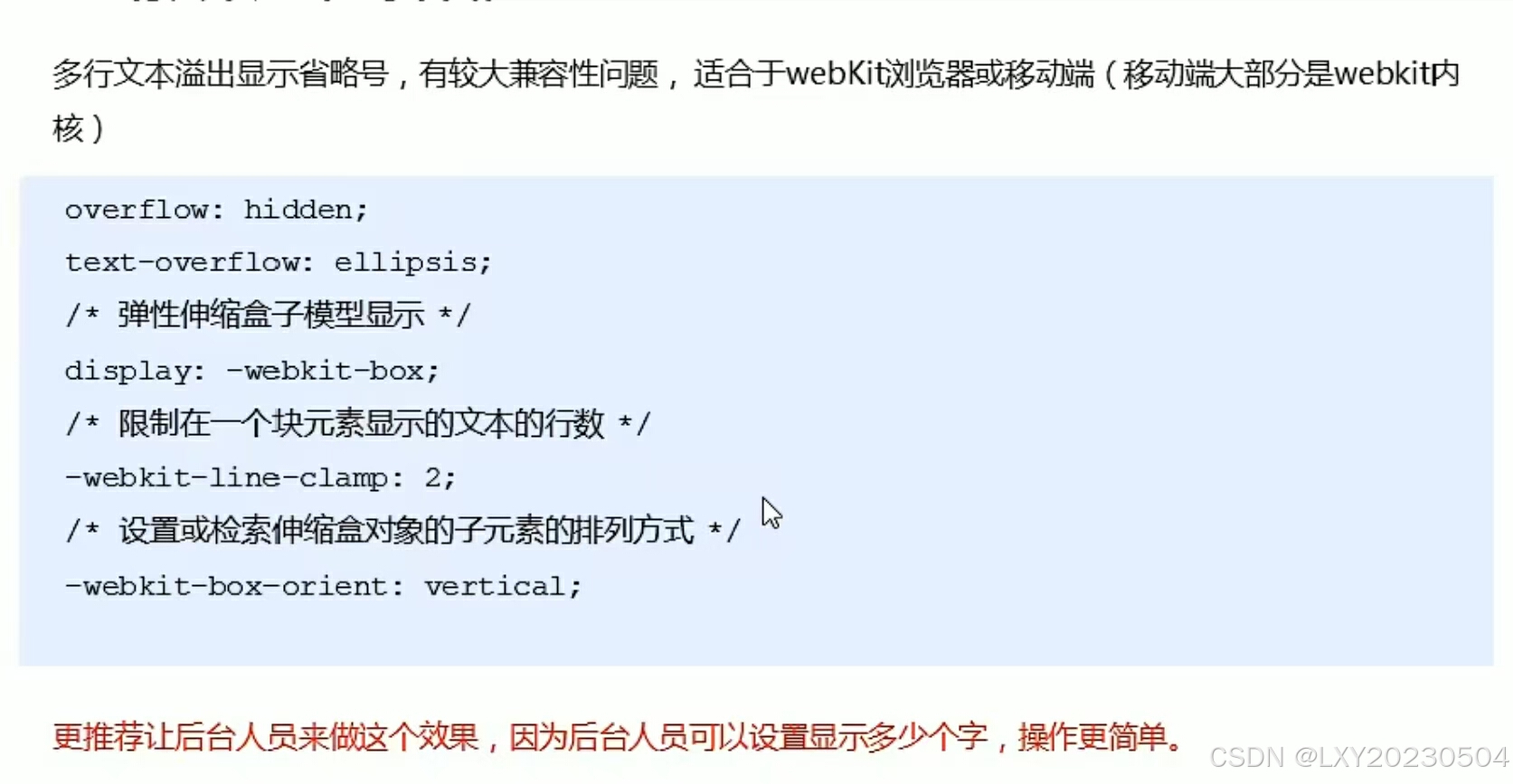
文字显示省略号
多行文本溢出显示省略号...

[LeetCode] 字符串完整版 — 双指针法 | KMP
字符串 基础知识双指针法344# 反转字符串541# 反转字符串II54K 替换数字151# 反转字符串中的单词55K 右旋字符串 KMP 字符串匹配算法28# 找出字符串中第一个匹配项的下标#459 重复的子字符串 基础知识 字符串的结尾:空终止字符00 char* name "hello"; …...

从零开始部署Dify:后端与前端服务完整指南
从零开始部署Dify:后端与前端服务完整指南 一、环境准备1. 系统要求2. 项目结构 二、后端服务部署1. 中间件启动(Docker Compose)2. 后端环境配置3. 依赖安装与数据库迁移4. 服务启动 三、前端界面搭建1. 环境配置2. 服务启动 四、常见问题排…...

springboot中路径默认配置与重定向/转发所存在的域对象
Spring Boot 是一种简化 Spring 应用开发的框架,它提供了多种默认配置和方便的开发特性。在 Web 开发中,路径配置和请求的重定向/转发是常见操作。本文将详细介绍 Spring Boot 中的路径默认配置,并解释重定向和转发过程中存在的域对象。 一、…...

二叉树——429,515,116
今天继续做关于二叉树层序遍历的相关题目,一共有三道题,思路都借鉴于最基础的二叉树的层序遍历。 LeetCode429.N叉树的层序遍历 这道题不再是二叉树了,变成了N叉树,也就是该树每一个节点的子节点数量不确定,可能为2&a…...

Leetcode 3444. Minimum Increments for Target Multiples in an Array
Leetcode 3444. Minimum Increments for Target Multiples in an Array 1. 解题思路2. 代码实现 题目链接:3444. Minimum Increments for Target Multiples in an Array 1. 解题思路 这一题我的思路上就是一个深度优先遍历,考察target数组当中的每一个…...
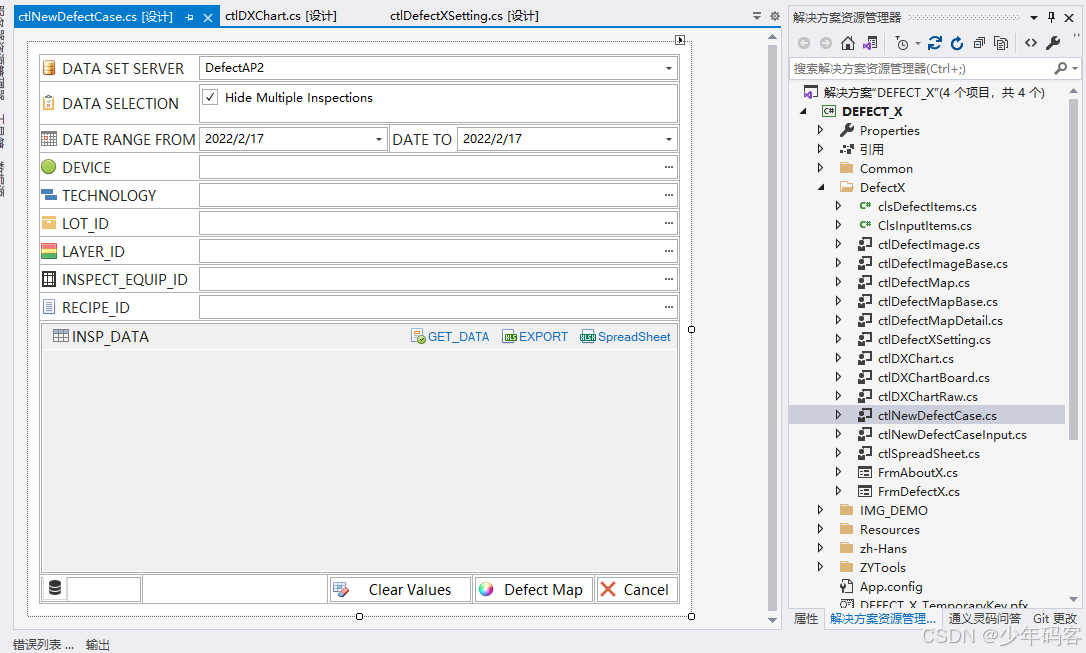
分享半导体Fab 缺陷查看系统,平替klarity defect系统
分享半导体Fab 缺陷查看系统,平替klarity defect系统;开发了半年有余。 查看Defect Map,Defect image,分析Defect size,defect count trend. 不用再采用klarity defect系统(license 太贵) 也可以…...
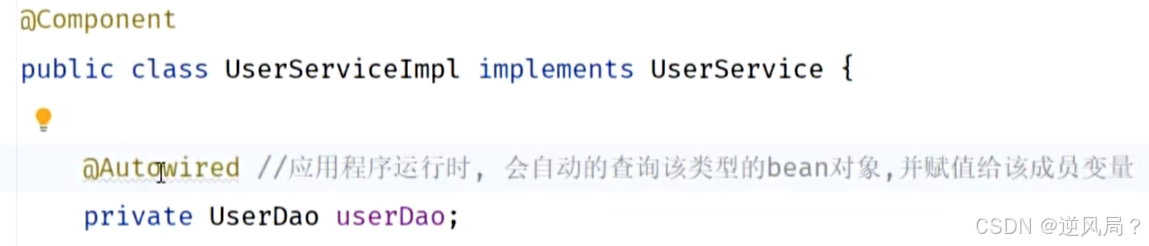
Java基础——分层解耦——IOC和DI入门
目录 三层架构 Controller Service Dao 编辑 调用过程 面向接口编程 分层解耦 耦合 内聚 软件设计原则 控制反转 依赖注入 Bean对象 如何将类产生的对象交给IOC容器管理? 容器怎样才能提供依赖的bean对象呢? 三层架构 Controller 控制…...
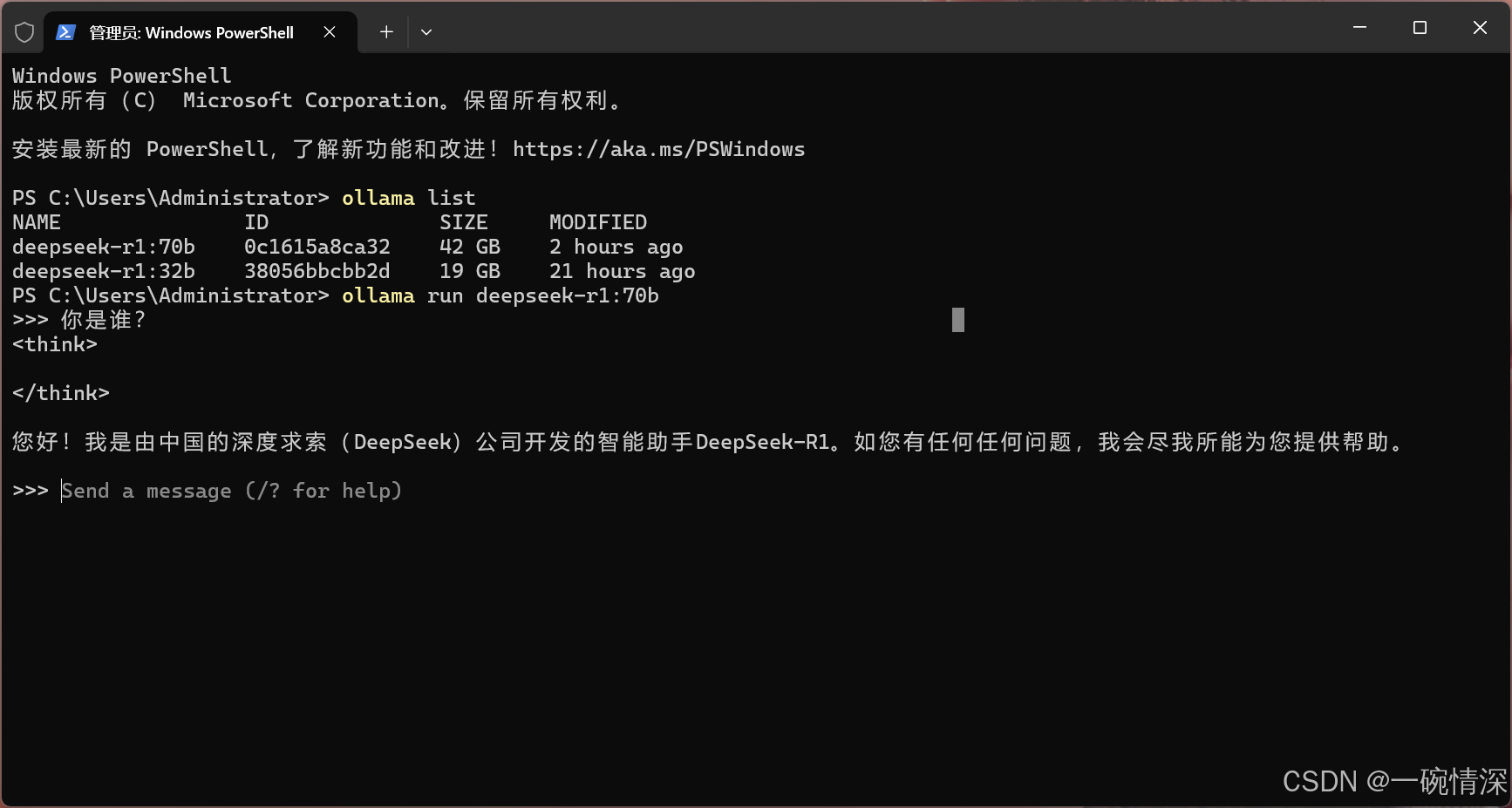
DeepSeek-R1 本地部署教程(超简版)
文章目录 一、DeepSeek相关网站二、DeepSeek-R1硬件要求三、本地部署DeepSeek-R11. 安装Ollama1.1 Windows1.2 Linux1.3 macOS 2. 下载和运行DeepSeek模型3. 列出本地已下载的模型 四、Ollama命令大全五、常见问题解决附:DeepSeek模型资源 一、DeepSeek相关网站 官…...
Vue3学习笔记-模板语法和属性绑定-2
一、文本插值 使用{ {val}}放入变量,在JS代码中可以设置变量的值 <template><p>{{msg}}</p> </template> <script> export default {data(){return {msg: 文本插值}} } </script> 文本值可以是字符串,可以是布尔…...

csapp笔记3.6节——控制(1)
本节解决了x86-64如何实现条件语句、循环语句和分支语句的问题 条件码 除了整数寄存器外,cpu还维护着一组单个位的条件码寄存器,用来描述最近的算数和逻辑运算的某些属性。可检测这些寄存器来执行条件分支指令。 CF(Carry Flag)…...

PYH与MAC的桥梁MII/MIIM
在学习车载互联网时,看到了一句话,Processor通过DMA直接存储访问与MAC之间进行数据的交互,MAC通过MII介质无关接口与PHY之间进行数据的交互。常见的以太网硬件结构是,将MAC集成进Processor芯片,将PHY留在Processor片外…...
)
国内flutter环境部署(记录篇)
设置系统环境变量 export PUB_HOSTED_URLhttps://pub.flutter-io.cn export FLUTTER_STORAGE_BASE_URLhttps://storage.flutter-io.cn使用以下命令下载flutter镜像 git clone -b stable https://mirror.ghproxy.com/https://github.com/<github仓库地址>#例如flutter仓…...

Sketchfab 3D模型本地化工具:Firefox浏览器专业解决方案
Sketchfab 3D模型本地化工具:Firefox浏览器专业解决方案 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 在数字创作领域,3D资源的离线获取与…...

AI写的论文如何降到20%以内?分场景教程+工具对比
AI写的论文如何降到20%以内?分场景教程工具对比 “我用DeepSeek写了大半篇论文,导师要求知网AI率必须低于20%,现在已经是52%,我该怎么办?” 这是毕业季最典型的求助问题之一。 不同的情况,处理方法不一样。…...

自编码器在异常检测中的实战应用:以金融交易数据为例
自编码器在金融异常检测中的实战指南:从数据清洗到模型部署 金融交易数据中的异常行为检测一直是风险控制的核心环节。传统基于规则的系统难以应对日益复杂的欺诈模式,而自编码器这类无监督学习模型正在改变游戏规则。本文将带您从零构建一个完整的异常检…...

Fish-Speech-1.5 API调用教程:Python脚本批量生成语音
Fish-Speech-1.5 API调用教程:Python脚本批量生成语音 1. 为什么选择Fish-Speech-1.5进行批量语音生成 在日常工作中,我们经常遇到需要将大量文本转换为语音的场景。无论是为视频内容生成旁白,还是为电子书制作有声版本,传统的人…...

终极指南:Windows免费倒计时神器Hourglass,5分钟从新手到高手
终极指南:Windows免费倒计时神器Hourglass,5分钟从新手到高手 【免费下载链接】hourglass The simple countdown timer for Windows. 项目地址: https://gitcode.com/gh_mirrors/ho/hourglass 还在为Windows系统找不到好用的倒计时工具而烦恼吗&a…...

科研写作效率提升300%:WPS-Zotero跨平台文献管理终极指南
科研写作效率提升300%:WPS-Zotero跨平台文献管理终极指南 【免费下载链接】WPS-Zotero An add-on for WPS Writer to integrate with Zotero. 项目地址: https://gitcode.com/gh_mirrors/wp/WPS-Zotero WPS-Zotero是一款革命性的WPS Office插件,专…...

5步攻克MZmine 3质谱数据分析:从问题解决到专业应用的实战指南
5步攻克MZmine 3质谱数据分析:从问题解决到专业应用的实战指南 【免费下载链接】mzmine3 MZmine 3 source code repository 项目地址: https://gitcode.com/gh_mirrors/mz/mzmine3 MZmine 3作为开源质谱数据分析领域的核心工具,在代谢组学、蛋白质…...

终极指南:如何在5分钟内完成你的第一个React Native动画模态框
终极指南:如何在5分钟内完成你的第一个React Native动画模态框 【免费下载链接】react-native-modal An enhanced, animated, customizable Modal for React Native. 项目地址: https://gitcode.com/gh_mirrors/re/react-native-modal React Native动画模态框…...

CBoard自研多维引擎揭秘:轻量级架构如何撬动大数据分析
CBoard自研多维引擎揭秘:轻量级架构如何撬动大数据分析 【免费下载链接】CBoard CBoard - 这是一个基于 Node.js 的开源面板,用于管理 Kubernetes 集群和应用程序。适用于 Kubernetes 集群管理、容器编排、持续集成等场景。 项目地址: https://gitcode…...

Youtu-VL-4B-Instruct步骤详解:Supervisor日志查看、错误定位与常见启动失败修复
Youtu-VL-4B-Instruct步骤详解:Supervisor日志查看、错误定位与常见启动失败修复 部署一个强大的多模态AI模型,最让人头疼的往往不是使用,而是启动。你满怀期待地拉取镜像、启动服务,结果浏览器里只显示一个冰冷的“无法访问此网…...