基于“蘑菇书”的强化学习知识点(二):强化学习中基于策略(Policy-Based)和基于价值(Value-Based)方法的区别
强化学习中基于策略(Policy-Based)和基于价值(Value-Based)方法的区别
- 摘要
- 强化学习中基于策略(Policy-Based)和基于价值(Value-Based)方法的区别
- 1. 定义与核心思想
- (1) 基于策略的方法(Policy-Based Methods)
- (2) 基于价值的方法(Value-Based Methods)
- 2. 核心区别
- 3. 具体示例
- 场景:CartPole游戏
- (1) 基于价值的方法示例(如DQN)
- (2) 基于策略的方法示例(如REINFORCE或PPO)
- 4. 优缺点对比
- 5. 典型算法
- 6. 关键总结
- 示例总结
摘要
本系列知识点讲解基于蘑菇书EasyRL中的内容进行详细的疑难点分析!具体内容请阅读蘑菇书EasyRL!
对应蘑菇书EasyRL——1.4.4.1基于价值的智能体与基于策略的智能体
强化学习中基于策略(Policy-Based)和基于价值(Value-Based)方法的区别
在强化学习中,基于策略的方法和基于价值的方法是两类核心的算法设计思路。它们的核心差异在于优化目标和动作选择方式。以下是详细对比及具体示例:
1. 定义与核心思想
(1) 基于策略的方法(Policy-Based Methods)
- 定义:直接学习策略函数(即状态到动作的映射),通过优化策略参数来最大化长期累积奖励。
- 核心思想:
策略函数可以是确定性的(如 a = π ( s ) a = \pi(s) a=π(s))或概率性的(如 π ( a ∣ s ) = P ( a ∣ s ) \pi(a|s) = P(a|s) π(a∣s)=P(a∣s))。算法通过梯度上升调整策略参数,使高奖励的动作概率增加。 - 数学表示:
π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) 表示参数为 θ \theta θ 的策略函数,目标是最大化期望回报 J ( θ ) = E π θ [ G t ] J(\theta) = \mathbb{E}_{\pi_\theta}[G_t] J(θ)=Eπθ[Gt]。
(2) 基于价值的方法(Value-Based Methods)
- 定义:学习价值函数(如状态值函数 V ( s ) V(s) V(s) 或动作值函数 Q ( s , a ) Q(s,a) Q(s,a)),通过价值函数间接选择动作。
- 核心思想:
通过贝尔曼方程迭代更新价值函数,最终策略由价值函数导出(例如选择具有最高 Q ( s , a ) Q(s,a) Q(s,a) 的动作)。 - 数学表示:
贝尔曼方程: Q ( s , a ) = E [ R + γ max a ′ Q ( s ′ , a ′ ) ] Q(s,a) = \mathbb{E}[R + \gamma \max_{a'} Q(s',a')] Q(s,a)=E[R+γmaxa′Q(s′,a′)]。
2. 核心区别
| 特征 | 基于策略的方法 | 基于价值的方法 |
|---|---|---|
| 优化目标 | 直接优化策略参数 θ \theta θ | 优化价值函数(如 Q ( s , a ) Q(s,a) Q(s,a) 或 V ( s ) V(s) V(s)) |
| 策略表示 | 显式定义策略 π ( a ∣ s ) \pi(a | s) π(a∣s) | 隐式策略(如贪婪策略: a = arg max a Q ( s , a ) a = \arg\max_a Q(s,a) a=argmaxaQ(s,a)) |
| 动作空间适应性 | 天然支持连续动作空间(如机器人控制) | 通常需离散化动作空间(如DQN) |
| 探索能力 | 通过策略的随机性自然探索(如概率选择动作) | 需额外机制(如ε-greedy)促进探索 |
| 收敛性 | 更稳定但可能收敛到局部最优 | 可能存在震荡或不收敛(尤其是函数逼近时) |
| 策略更新频率 | 通常按回合(on-policy)更新 | 可在线更新(off-policy,如Q-learning) |
3. 具体示例
场景:CartPole游戏
- 目标:控制小车左右移动,保持杆子竖直不倒。
- 动作空间:离散(左/右)或连续(力的大小)。
(1) 基于价值的方法示例(如DQN)
- 步骤:
- 学习动作值函数 Q ( s , a ) Q(s,a) Q(s,a),预测每个动作的长期价值。
- 选择使 Q ( s , a ) Q(s,a) Q(s,a) 最大的动作(例如,向左或向右)。
- 局限性:
如果动作空间连续(如施加0.1N或0.5N的力),需离散化处理,导致维度灾难。 - 代码片段逻辑:
action = argmax(q_network(state)) # 选择Q值最大的动作
(2) 基于策略的方法示例(如REINFORCE或PPO)
- 步骤:
- 直接输出动作的概率分布(例如,向左概率70%,向右30%)。
- 通过策略梯度上升,增加高回报动作的概率。
- 优势:
可直接输出连续动作(如力的大小为0.3N),无需离散化。 - 代码片段逻辑:
mean, std = policy_network(state) # 输出高斯分布的均值和方差 action = sample(mean, std) # 从分布中采样连续动作
4. 优缺点对比
| 方法类型 | 优点 | 缺点 |
|---|---|---|
| 基于策略 | 1. 支持连续动作空间 2. 探索能力强 3. 策略表达灵活 | 1. 高方差 2. 样本效率低 3. 训练不稳定 |
| 基于价值 | 1. 样本效率高(可off-policy) 2. 训练稳定 | 1. 依赖价值函数估计精度 2. 难以处理连续动作 |
5. 典型算法
- 基于策略的方法:
- REINFORCE(蒙特卡洛策略梯度)
- PPO(Proximal Policy Optimization)
- TRPO(Trust Region Policy Optimization)
- 基于价值的方法:
- Q-learning
- DQN(Deep Q-Network)
- SARSA
6. 关键总结
- 基于策略的方法:
直接操作策略,适合复杂动作空间(如机器人控制、游戏AI),但训练可能不稳定。 - 基于价值的方法:
依赖价值函数,适合离散动作空间(如Atari游戏),但对函数逼近误差敏感。 - 混合方法(Actor-Critic):
结合两者优点,用价值函数辅助策略更新(如A3C、DDPG)。
示例总结
- 迷宫导航(基于价值):
学习每个位置的Q值,选择最大Q值的路径。 - 机械臂控制(基于策略):
直接输出关节扭矩的连续值,通过策略梯度优化扭矩参数。
两者在解决不同类型问题时各具优势,实际应用中常结合使用(如Actor-Critic架构)。
相关文章:
:强化学习中基于策略(Policy-Based)和基于价值(Value-Based)方法的区别)
基于“蘑菇书”的强化学习知识点(二):强化学习中基于策略(Policy-Based)和基于价值(Value-Based)方法的区别
强化学习中基于策略(Policy-Based)和基于价值(Value-Based)方法的区别 摘要强化学习中基于策略(Policy-Based)和基于价值(Value-Based)方法的区别1. 定义与核心思想(1) 基于策略的方…...

民法学学习笔记(个人向) Part.2
民法学学习笔记(个人向) Part.2 民法始终在解决两个生活中的核心问题: 私法自治;交易安全; 3. 自然人 3.4 个体工商户、农村承包经营户 都是特殊的个体经济单位; 3.4.1 个体工商户 是指在法律的允许范围内,依法经…...

物业管理系统源码驱动社区管理革新提升用户满意度与服务效率
内容概要 在当今社会,物业管理正面临着前所未有的挑战,尤其是在社区管理方面。人们对社区安全、环境卫生、设施维护等日常生活需求愈发重视,物业公司必须提升服务质量,以满足居民日益增长的期望。而物业管理系统源码的出现&#…...

租房管理系统助力数字化转型提升租赁服务质量与用户体验
内容概要 随着信息技术的快速发展,租房管理系统正逐渐成为租赁行业数字化转型的核心工具。通过全面集成资产管理、租赁管理和物业管理等功能,这种系统力求为用户提供高效便捷的服务体验。无论是工业园、产业园还是写字楼、公寓,租房管理系统…...

Ollama教程:轻松上手本地大语言模型部署
Ollama教程:轻松上手本地大语言模型部署 在大语言模型(LLM)飞速发展的今天,越来越多的开发者希望能够在本地部署和使用这些模型,以便更好地控制数据隐私和计算资源。Ollama作为一个开源工具,旨在简化大语言…...

Baklib推动数字化内容管理解决方案助力企业数字化转型
内容概要 在当今信息爆炸的时代,数字化内容管理成为企业提升效率和竞争力的关键。企业在面对大量数据时,如何高效地存储、分类与检索信息,直接关系到其经营的成败。数字化内容管理不仅限于简单的文档存储,更是整合了文档、图像、…...

DeepSeek-R1 论文. Reinforcement Learning 通过强化学习激励大型语言模型的推理能力
论文链接: [2501.12948] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning 实在太长,自行扔到 Model 里,去翻译去提问吧。 工作原理: 主要技术,就是训练出一些专有用途小模型&…...

DOM 操作入门:HTML 元素操作与页面事件处理
DOM 操作入门:HTML 元素操作与页面事件处理 DOM 操作入门:HTML 元素操作与页面事件处理什么是 DOM?1. 如何操作 HTML 元素?1.1 使用 `document.getElementById()` 获取单个元素1.2 使用 `document.querySelector()` 和 `document.querySelectorAll()` 获取多个元素1.3 创建…...

使用 HTTP::Server::Simple 实现轻量级 HTTP 服务器
在Perl中,HTTP::Server::Simple 模块提供了一种轻量级的方式来实现HTTP服务器。该模块简单易用,适合快速开发和测试HTTP服务。本文将详细介绍如何使用 HTTP::Server::Simple 模块创建和配置一个轻量级HTTP服务器。 安装 HTTP::Server::Simple 首先&…...

C++滑动窗口技术深度解析:核心原理、高效实现与高阶应用实践
目录 一、滑动窗口的核心原理 二、滑动窗口的两种类型 1. 固定大小的窗口 2. 可变大小的窗口 三、实现细节与关键点 1. 窗口的初始化 2. 窗口的移动策略 3. 结果的更新时机 四、经典问题与代码示例 示例 1:和 ≥ target 的最短子数组(可变窗口…...

基于构件的软件开发方法
摘要: 本人在2023年1月参与广东某公司委托我司开发的“虚拟电厂”项目,主要负责整体架构设计和中间件的选型,该项目为新型电力存储、电力调度、能源交易提供一整套的软件系统,包括设备接入、负载预测、邀约竞价、用户设备调控等功能。本项目以“虚拟电厂”项目为例,讨论基…...

网站快速收录:如何设置robots.txt文件?
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/34.html 为了网站快速收录而合理设置robots.txt文件,需要遵循一定的规则和最佳实践。robots.txt文件是一个纯文本文件,它告诉搜索引擎爬虫哪些页面可以访问ÿ…...
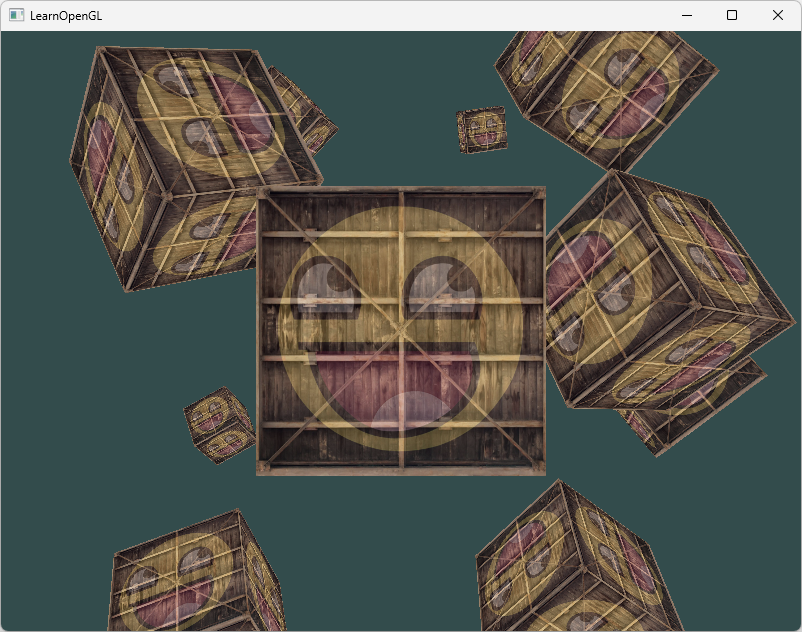
OpenGL学习笔记(六):Transformations 变换(变换矩阵、坐标系统、GLM库应用)
文章目录 向量变换使用GLM变换(缩放、旋转、位移)将变换矩阵传递给着色器坐标系统与MVP矩阵三维变换绘制3D立方体 & 深度测试(Z-buffer)练习1——更多立方体 现在我们已经知道了如何创建一个物体、着色、加入纹理。但它们都还…...

8.攻防世界Web_php_wrong_nginx_config
进入题目页面如下 尝试弱口令密码登录 一直显示网站建设中,尝试无果,查看源码也没有什么特别漏洞存在 用Kali中的dirsearch扫描根目录试试 命令: dirsearch -u http://61.147.171.105:53736/ -e* 登录文件便是刚才登录的界面打开robots.txt…...

【优先算法】专题——位运算
在讲解位运算之前我们来总结一下常见的位运算 一、常见的位运算 1.基础为运算 << &:有0就是0 >> |:有1就是1 ~ ^:相同为0,相异位1 /无进位相加 2.给一个数 n,确定它的二进制表示…...

qt.qpa.plugin: Could not find the Qt platform plugin “dxcb“ in ““
个人博客地址:qt.qpa.plugin: Could not find the Qt platform plugin "dxcb" in "" | 一张假钞的真实世界 我遇到的场景是,在Deepin系统终端中运行PySide应用时,没有错误提示,但在VS Code中运行时ÿ…...

1-刷力扣问题记录
25.1.19 1.size()和.length()有什么区别 2.result.push_back({nums[i], nums[left], nums[right]});为什么用大括号? 使用大括号 {} 是 C11 引入的 初始化列表 语法,它允许我们在构造或初始化对象时直接传入一组值。大括号的使用在许多情况下都能让代码…...

物联网 STM32【源代码形式-使用以太网】连接OneNet IOT从云产品开发到底层MQTT实现,APP控制 【保姆级零基础搭建】
物联网(IoT)是指通过各种信息传感器、射频识别技术、全球定位系统、红外感应器等装置与技术,实时采集并连接任何需要监控、连接、互动的物体或过程,实现对物品和过程的智能化感知、识别和管理。物联网的核心功能包括数据采集与监…...
)
【单层神经网络】基于MXNet的线性回归实现(底层实现)
写在前面 基于亚马逊的MXNet库本专栏是对李沐博士的《动手学深度学习》的笔记,仅用于分享个人学习思考以下是本专栏所需的环境(放进一个environment.yml,然后用conda虚拟环境统一配置即可)刚开始先从普通的寻优算法开始ÿ…...

unity中的动画混合树
为什么需要动画混合树,动画混合树有什么作用? 在Unity中,动画混合树(Animation Blend Tree)是一种用于管理和混合多个动画状态的工具,包括1D和2D两种类型,以下是其作用及使用必要性的介绍&…...

聊聊永磁同步电机里的那点“扰动“破事
两种负载扰动观测器设计思路,pmsm仿真 仿真基于离散模型,观测器设计基于m文件,方便移植到c验证 包含:(1)1.5延时补偿(2)扩张龙伯格扰动观测器(ESO)设计&#…...

告别显卡驱动残留困扰:Display Driver Uninstaller的深度清理全解析
告别显卡驱动残留困扰:Display Driver Uninstaller的深度清理全解析 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers…...
加个“车轮锁”:NHC/ODO约束原理通俗解读)
城市开车GPS总飘?试试给惯性导航(INS)加个“车轮锁”:NHC/ODO约束原理通俗解读
城市开车GPS总飘?试试给惯性导航(INS)加个“车轮锁”:NHC/ODO约束原理通俗解读 你是否遇到过这样的场景:开车穿过高楼林立的CBD时,车载导航突然开始"鬼畜漂移"?或是驶入隧道后&#x…...
)
GIL Free ≠ Thread Safe:从Linux futex源码到Python对象头重定义,解构无锁环境下的引用计数崩溃根因(含gdb逆向调试录屏脚本)
第一章:GIL Free ≠ Thread Safe:核心命题与崩溃现象全景Python 的全局解释器锁(GIL)长期被视为多线程性能的桎梏,而 PyPy、Jython 乃至最新 CPython 3.13 的实验性 GIL-free 构建,常被误读为“天然支持安全…...

从理论到实践:LFM2.5-1.2B-Thinking-GGUF解析卷积神经网络原理的可视化展示
从理论到实践:LFM2.5-1.2B-Thinking-GGUF解析卷积神经网络原理的可视化展示 1. 开篇:当AI开始教AI 想象一下,一个能看懂卷积神经网络工作原理的AI,正在用人类能理解的方式向你解释它自己是如何工作的。这听起来有点科幻…...

极简音乐工具:重新定义纯粹听歌体验
极简音乐工具:重新定义纯粹听歌体验 【免费下载链接】tonzhon-music 铜钟 (Tonzhon.com): 免费听歌; 没有直播, 社交, 广告, 干扰; 简洁纯粹, 资源丰富, 体验独特!(密码重置功能已回归) 项目地址: https://gitcode.com/GitHub_Trending/to/tonzhon-mus…...
)
别再手动汉化了!用Docker Compose持久化配置Greenbone GVM中文界面(附yml文件修改)
持久化配置Greenbone GVM中文界面的Docker Compose实战指南 对于安全工程师和运维人员来说,Greenbone Vulnerability Management(GVM)是进行漏洞扫描的利器。但每次重启容器后都需要重新配置中文界面,这无疑增加了维护成本。本文…...

网易云音乐无损解析:5大核心技术构建个人高品质音乐库
网易云音乐无损解析:5大核心技术构建个人高品质音乐库 【免费下载链接】Netease_url 网易云无损解析 项目地址: https://gitcode.com/gh_mirrors/ne/Netease_url 在数字音乐时代,如何突破平台限制,建立个人专属的高品质音乐库…...

LangChain4j向量化实战避坑:OpenAI、本地模型、Qdrant选哪个?我的踩坑记录
LangChain4j向量化实战避坑指南:OpenAI、本地模型与Qdrant的深度抉择 当Java开发者尝试构建基于大语言模型的应用时,LangChain4j框架中的向量化组件往往成为技术栈选型的第一个分水岭。我在三个实际项目中分别尝试了不同组合方案后,发现每个…...

Realistic Vision V5.1显存占用对比:启用offload前后VRAM峰值下降62%实测
Realistic Vision V5.1显存占用对比:启用offload前后VRAM峰值下降62%实测 1. 项目背景与技术特点 Realistic Vision V5.1是目前Stable Diffusion 1.5生态中最顶级的写实风格模型之一,能够生成媲美专业单反相机拍摄的人像作品。然而在实际使用中&#x…...