【Elasticsearch】文本分类聚合Categorize Text Aggregation

响应参数讲解:
key (字符串)由 categorization_analyzer 提取的标记组成,这些标记是类别中所有输入字段值的共同部分。 doc_count (整数)与类别匹配的文档数量。 max_matching_length (整数)从较短消息中生成的类别也可能与从较长消息中生成的类别匹配。 max_matching_length 表示应被视为属于该类别的消息的最大长度。在搜索属于该类别的消息时,任何长度超过 max_matching_length 的消息都应被排除。使用此字段可以防止对短消息类别的搜索匹配到更长的消息。
regex (字符串)一个正则表达式,它将匹配类别中包含的所有输入字段值。在类别中包含的值的顺序不同时, regex 可能不会包含 key 中的每个术语。然而,在简单情况下, regex 将是按顺序连接的术语组成的正则表达式,允许在它们之间有任意部分。不建议将 regex 作为搜索原始被分类文档的主要机制,因为正则表达式搜索非常慢。相反,应该使用 key 字段中的术语来搜索匹配的文档,因为术语搜索可以利用倒排索引,因此速度要快得多。然而,在某些情况下,使用 regex 字段来测试未被索引的少量消息是否属于该类别,或者确认 key 中的术语在所有匹配文档中按正确顺序出现,可能是有用的。
总结:
重新分析大型结果集将需要大量的时间和内存。应将此聚合与异步搜索(Async search)结合使用。此外,你还可以考虑将该聚合作为采样器(sampler)或多样化采样器(diversified sampler)聚合的子聚合使用。这通常可以提高速度和内存使用效率。
POST log-messages/_search
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message"
}
}
}
}
输出
{
"aggregations": {
"categories": {
"buckets": [
{
"doc_count": 3,
"key": "Node shutting down",
"regex": ".*?Node.+?shutting.+?down.*?",
"max_matching_length": 49
},
{
"doc_count": 1,
"key": "Node starting up",
"regex": ".*?Node.+?starting.+?up.*?",
"max_matching_length": 47
}
]
}
}
}
使用 categorization_analyzer 的示例配置:
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"categorization_analyzer": {
"char_filter": ["html_strip"],
"tokenizer": "ml_standard",
"filter": ["lowercase", "stop"]
}
}
}
}
}
使用 categorization_filters 的示例配置:
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"categorization_filters": [
"\\w+\\_\\d{3}", // 过滤掉类似 "foo_123" 的模式
"ERROR:.*" // 过滤掉以 "ERROR:" 开头的日志
]
}
}
}
}
相关文章:
【Elasticsearch】文本分类聚合Categorize Text Aggregation
响应参数讲解: key (字符串)由 categorization_analyzer 提取的标记组成,这些标记是类别中所有输入字段值的共同部分。 doc_count (整数)与类别匹配的文档数量。 max_matching_length (整数)从…...

算法随笔_40: 爬楼梯
上一篇:算法随笔_39: 最多能完成排序的块_方法2-CSDN博客 题目描述如下: 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n 2 输出:2 解释&am…...

【Linux探索学习】第二十七弹——信号(一):Linux 信号基础详解
Linux学习笔记: https://blog.csdn.net/2301_80220607/category_12805278.html?spm1001.2014.3001.5482 前言: 前面我们已经将进程通信部分讲完了,现在我们来讲一个进程部分也非常重要的知识点——信号,信号也是进程间通信的一…...

【数学】矩阵、向量(内含矩阵乘法C++)
目录 一、前置知识:向量(一列或一行的矩阵)、矩阵1. 行向量2. 列向量3. 向量其余基本概念4. 矩阵基本概念5. 关于它们的细节 二、运算1. 转置(1)定义(2)性质 2. 矩阵(向量࿰…...

设置git区分大小写
设置git区分大小写 1.全局设置 (影响全部仓库): git config --global core.ignorecase false2.仓库级别设置 (影响当前仓库): git config core.ignorecase false3.已经提交了大小写不一致的文件处理: git mv -f OldName newName # 强制重命名 git commit -m "Fix cas…...

排序算法与查找算法
1.十大经典排序算法 我们希望数据以一种有序的形式组织起来,无序的数据我们要尽量将其变得有序 一般说来有10种比较经典的排序算法 简单记忆为Miss D----D小姐 时间复杂度 :红色<绿色<蓝色 空间复杂度:圆越大越占空间 稳定性&…...

Github 2025-01-31Java开源项目日报 Top10
根据Github Trendings的统计,今日(2025-01-31统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Java项目10C项目1Kotlin项目1Bazel:快速、可扩展的多语言构建系统 创建周期:3564 天开发语言:Java协议类型:Apache License 2.0Star数量:2…...

Java进阶笔记(中级)
-----接Java进阶笔记(初级)----- 目录 集合多线程 集合 ArrayList 可以通过List来接收ArrayList对象(因为ArrayList实现了List接口) 方法:接口名 柄名 new 实现了接口的类(); PS: List list new ArrayList();遍历…...

2025游戏行业的趋势预测
一、市场现状 从总产值的角度来看,游戏总产值的增长率已经放缓,由增量市场转化为存量市场,整体的竞争强度将会加大,技术水平不强(开发技术弱、产品品质低、开发效率低)的公司将会面临更大的生存的困难。 从…...

4-ET框架demo的运行
开始操作 开始运行报错 编译Unity项目 状态同步demo运行 1-设置构建参数 CodeMode:ClientServer EPlayMode:EditorSimulateMode 点击ReGeneratoePerojectFiles调整代码结构 2-编译 在Unity.sln下编译项目 3-运行 以帧同步模式运行 1-合端运行 1.1 修改帧同步标记 …...

kamailio源文件modules.lst的内容解释
在执行make cfg 后,在kamailio/src目录下有一个文件modules.lst,内容如下: # this file is autogenerated by make modules-cfg# the list of sub-directories with modules modules_dirs:modules# the list of module groups to compile cf…...

亚远景-从SPICE到ASPICE:汽车软件开发的标准化演进
一、SPICE标准的起源与背景 SPICE,全称“Software Process Improvement and Capability dEtermination”,即“软件流程改进和能力测定”,是由国际标准化组织ISO、国际电工委员会IEC、信息技术委员会JTC1联合发起制定的ISO 15504标准。该标准旨…...

vue3 + ElementPlus 封装列表表格组件包含分页
在前端开发中,封装组件是必不可少的。今天就来封装一个通用的列表表格组件,包含分页功能,可以提高代码的复用性和可维护性。 1. 组件设计 Props: tableData:表格数据。columns:表格列配置。totalÿ…...

挑战项目 --- 微服务编程测评系统(在线OJ系统)
一、前言 1.为什么要做项目 面试官要问项目,考察你到底是理论派还是实战派? 1.希望从你的项目中看到你的真实能力和对知识的灵活运用。 2.展示你在面对问题和需求时的思考方式及解决问题的能力。 3.面试官会就你项目提出一些问题,或扩展需求…...

Med-R2:基于循证医学的检索推理框架:提升大语言模型医疗问答能力的新方法
Med-R2 : Crafting Trustworthy LLM Physicians through Retrieval and Reasoning of Evidence-Based Medicine Med-R2框架Why - 这个研究要解决什么现实问题What - 核心发现或论点是什么How - 1. 前人研究的局限性How - 2. 你的创新方法/视角How - 3. 关键数据支持How - 4. 可…...
具体踩坑记录(一))
Oh3.2项目升级到Oh5.0(鸿蒙Next)具体踩坑记录(一)
目录 1.自动修复部分 Cause: The project structure and configuration require an upgrade. Solution: 1. Use Migrate Assistant to auto-upgrade the project structure and configuration. 2. Manually upgrade the project structure and configuration by following th…...
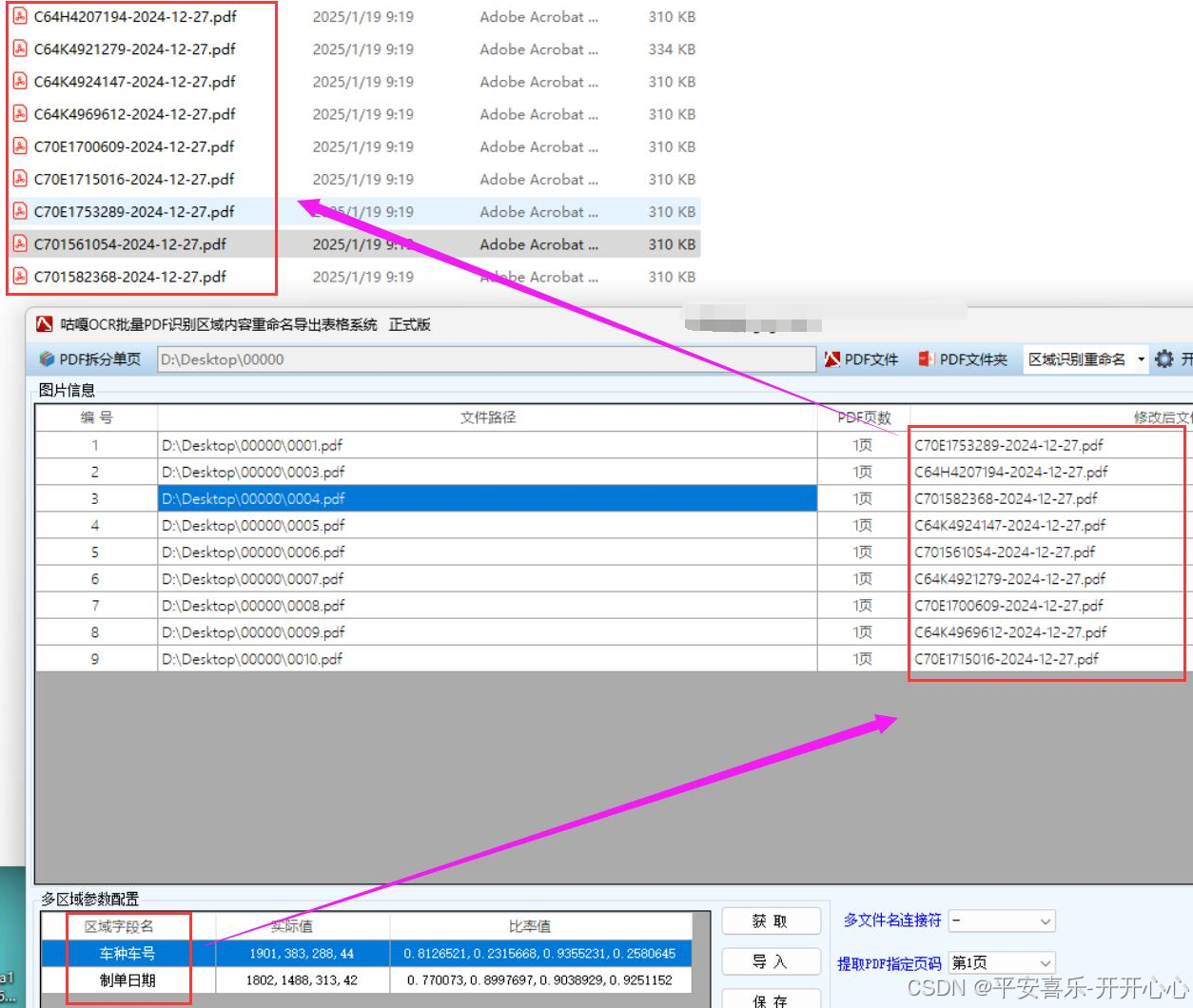
【自动化办公】批量图片PDF自定义指定多个区域识别重命名,批量识别铁路货物运单区域内容改名,基于WPF和飞桨ocr深度学习模型的解决方案
项目背景介绍 铁路货运企业需要对物流单进行长期存档,以便后续查询和审计。不同的物流单可能包含不同的关键信息,通过自定义指定多个区域进行识别重命名,可以使存档的图片文件名具有统一的规范和明确的含义。比如,将包含货物运单…...

Spring Boot篇
为什么要用Spring Boot Spring Boot 优点非常多,如: 独立运行 Spring Boot 而且内嵌了各种 servlet 容器,Tomcat、Jetty 等,现在不再需要打成 war 包部署到 容器 中,Spring Boot 只要打成一个可执行的 jar 包就能独…...
)
Unity3D学习笔记(二)
一、Unity编辑器相关 1、 Unity特殊的专属文件夹 1) Editor:编辑器相关资源可以放到此文件中,包括图片、脚本等文件。 2)Editor Default Resources:配合Editor使用不会打包到包中 3)Plugins:存放第三方SD…...

个人毕业设计--基于HarmonyOS的旅行助手APP的设计与实现(挖坑)
在行业混了短短几年,却总感觉越混越迷茫,趁着还有心情学习,把当初API9 的毕业设计项目改成API13的项目。先占个坑,把当初毕业设计的文案搬过来 摘要:HarmonyOS(鸿蒙系统)是华为公司推出的面向全…...
)
别再乱装CUDA了!用Anaconda为你的3060 Ti一键搞定PyTorch GPU环境(含CUDA 11.3实战)
3060 Ti显卡玩家的PyTorch环境配置指南:用Anaconda避开CUDA版本地狱 在深度学习领域,GPU加速已经成为提升模型训练效率的标配。然而,对于许多刚入门的开发者来说,配置PyTorch的GPU支持往往成为第一道门槛——尤其是当涉及到CUDA版…...

从零构建可定制对话系统:模块化架构与RAG实战指南
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“定制化聊天系统”。起因很简单,市面上现成的聊天机器人,无论是开源的还是商业的,总感觉差了那么点意思。要么是功能太臃肿&#x…...

Redis高效开发工具集:从SCAN迭代到数据迁移的Python实践
1. 项目概述:一个Redis开发者的“瑞士军刀”如果你和我一样,日常开发中重度依赖Redis,那你一定遇到过这些场景:想快速查看某个大Key的内存占用,得写脚本遍历;想分析某个Pattern下的所有键,得手动…...

嵌入式测试学习第 12天:串口基础概念:UART、波特率、数据位、校验位
串口基础概念:UART、波特率、数据位、校验位一、串口整体基础概念1、什么是UART串口2、串口实物真实图片① 主板/开发板排针串口② USB转TTL串口模块③ 老式DB9工业串口公头母头二、串口四大核心参数1、波特率概念常用标准固定值通俗理解测试场景2、数据位概念作用3…...

免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧
免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

AI智能体分类学:从原理到实践,构建高效Agent系统的设计指南
1. 项目概述与核心价值最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的现象:大家聊起Agent,要么是“它能帮我写代码”,要么是“它能自动处理客服”,但很少有人能系统地说清楚ÿ…...

Redis分布式锁进阶第二十二篇拆解
一、本篇前置衔接 第九十二篇我们完成Redisson源码拆解、手写复刻、底层内核穿透,彻底明白分布式锁代码层、脚本层、线程层原理。到此为止,代码、源码、坑点、运维、监控、面试全部讲透。但很多开发最大的困惑依旧存在:不同体量公司为什么锁架…...

ESP-SR深度解析:嵌入式语音识别系统的架构设计与性能优化实战指南
ESP-SR深度解析:嵌入式语音识别系统的架构设计与性能优化实战指南 【免费下载链接】esp-sr Speech recognition 项目地址: https://gitcode.com/gh_mirrors/es/esp-sr 在物联网设备智能化浪潮中,语音交互已成为人机交互的重要入口。ESP-SR作为乐鑫…...
)
模块六-数据合并与连接——32. merge 合并(上)
32. merge 合并(上) 1. 概述 merge 是 Pandas 中最强大的数据合并函数,类似于 SQL 中的 JOIN 操作。它可以根据一个或多个键将两个 DataFrame 的行连接起来。 import pandas as pd import numpy as np# 创建示例数据 # 员工表 employees pd.…...

雷达目标检测与成像算法实时实现【附代码】
✨ 长期致力于阵列雷达、多输入多输出、现场可编程门阵列、目标检测定位、高分辨成像研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)相控阵和差波束目…...