Java 中 LinkedList 的底层源码
在 Java 的集合框架中,LinkedList是一个独特且常用的成员。它基于双向链表实现,与数组结构的集合类如ArrayList有着显著差异。深入探究LinkedList的底层源码,有助于我们更好地理解其工作原理和性能特点,以便在实际开发中做出更合适的选择。
这里如何具体在idea里查看底层源码的教程在我ArrayList那篇文章有,基本大差不差,具体步骤我就不再演示了,我直接把所有底层源码总结下来供大家参考。

咱们可以根据这个代码逻辑自己推一下,捋清楚了思路就好理解多了。

一、基本结构与成员变量
LinkedList的底层核心是一个双向链表,其内部通过节点来存储数据。以下是LinkedList源码中关键的成员变量定义:
// 头节点
transient Node<E> first;
// 尾节点
transient Node<E> last;
// 元素数量
transient int size = 0;
// 底层双向链表节点的内部类
private static class Node<E> {// 当前节点的元素值E item;// 指向下一个节点的引用Node<E> next;// 指向前一个节点的引用Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}
}
first和last分别指向双向链表的头节点和尾节点,通过它们可以方便地对链表进行遍历和操作。size变量用于记录链表中元素的个数。Node内部类则定义了链表节点的结构,每个节点不仅存储了元素值item,还持有指向前驱节点prev和后继节点next的引用,这使得双向链表能够灵活地在两个方向上进行遍历和元素的插入、删除等操作。
二、构造函数剖析
无参构造函数
public LinkedList() {
}
无参构造函数非常简洁,它只是创建了一个空的LinkedList对象。此时,first和last都为null,size为 0,链表中没有任何元素。
带集合参数的构造函数
public LinkedList(Collection<? extends E> c) {this();addAll(c);
}
该构造函数先调用无参构造函数创建一个空链表,然后通过addAll方法将传入集合中的所有元素添加到新创建的LinkedList中。这为我们在初始化LinkedList时提供了一种便捷的方式,可以直接将其他集合中的元素导入进来。
三、元素添加操作
在链表尾部添加元素
add(E e)方法用于在链表尾部添加一个元素,它是LinkedList中最常用的添加元素的方式之一。
public boolean add(E e) {linkLast(e);return true;
}
void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)first = newNode;elsel.next = newNode;size++;modCount++;
}
add(E e)方法内部调用了linkLast方法。linkLast方法首先记录原链表的尾节点l,然后创建一个新的节点newNode,使其前驱指向原尾节点l,后继为null。接着更新last指向新节点,如果原尾节点为空,说明链表之前是空的,此时first也指向新节点;否则将原尾节点的后继指向新节点。最后,更新元素数量size和修改次数modCount。这个过程使得在链表尾部添加元素的操作非常高效,时间复杂度为 O (1)。
在指定位置插入元素
add(int index, E element)方法可以在链表的指定位置插入一个元素。
public void add(int index, E element) {checkPositionIndex(index);if (index == size)linkLast(element);elselinkBefore(element, node(index));
}
该方法首先调用checkPositionIndex方法检查索引是否越界(要求0 <= index <= size)。如果索引等于size,说明要在链表尾部插入元素,直接调用linkLast方法即可;否则,调用linkBefore方法在指定节点前插入元素。这里的node(index)方法用于获取指定索引位置的节点:
Node<E> node(int index) {if (index < (size >> 1)) {Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}
}
node(index)方法通过判断索引与链表长度一半的大小关系,决定从链表头部还是尾部开始遍历查找指定索引位置的节点。如果索引小于链表长度的一半,从链表头部开始遍历;否则从链表尾部开始遍历。这种优化策略可以减少遍历的节点数量,提高查找效率。
四、元素删除操作
移除指定位置的元素
remove(int index)方法用于移除链表中指定位置的元素。
public E remove(int index) {checkElementIndex(index);return unlink(node(index));
}
该方法先调用checkElementIndex方法检查索引是否越界(要求0 <= index < size),然后通过node(index)方法获取指定索引位置的节点,最后调用unlink方法移除该节点并返回其存储的元素。
E unlink(Node<E> x) {final E element = x.item;final Node<E> next = x.next;final Node<E> prev = x.prev;if (prev == null) {first = next;} else {prev.next = next;x.prev = null;}if (next == null) {last = prev;} else {next.prev = prev;x.next = null;}x.item = null;size--;modCount++;return element;
}
unlink方法通过调整节点之间的引用关系,将指定节点从链表中移除。它先保存要移除节点的元素值、后继节点和前驱节点,然后根据前驱和后继节点的情况更新链表的头节点first或尾节点last,以及相关节点的前驱和后继引用。最后将被移除节点的元素值置为null,更新元素数量size和修改次数modCount,并返回被移除的元素。
移除指定元素的第一个匹配项
remove(Object o)方法用于移除链表中指定元素的第一个匹配项。
public boolean remove(Object o) {if (o == null) {for (Node<E> x = first; x != null; x = x.next) {if (x.item == null) {unlink(x);return true;}}} else {for (Node<E> x = first; x != null; x = x.next) {if (o.equals(x.item)) {unlink(x);return true;}}}return false;
}
该方法通过遍历链表,分别处理要移除的元素为null和不为null的情况。找到匹配的元素后,调用unlink方法将其移除并返回true;如果遍历完链表都没有找到匹配元素,则返回false。
五、元素查找操作
查找指定元素首次出现的索引
indexOf(Object o)方法用于返回指定元素在链表中首次出现的索引,如果不存在则返回 -1。
public int indexOf(Object o) {int index = 0;if (o == null) {for (Node<E> x = first; x != null; x = x.next) {if (x.item == null)return index;index++;}} else {for (Node<E> x = first; x != null; x = x.next) {if (o.equals(x.item))return index;index++;}}return -1;
}
该方法从链表头部开始遍历,分别处理查找元素为null和不为null的情况,找到匹配元素时返回其索引,遍历完链表都未找到则返回 -1。
查找指定元素最后一次出现的索引
lastIndexOf(Object o)方法用于返回指定元素在链表中最后一次出现的索引,如果不存在则返回 -1。
public int lastIndexOf(Object o) {int index = size;if (o == null) {for (Node<E> x = last; x != null; x = x.prev) {index--;if (x.item == null)return index;}} else {for (Node<E> x = last; x != null; x = x.prev) {index--;if (o.equals(x.item))return index;}}return -1;
}
该方法从链表尾部开始遍历,分别处理查找元素为null和不为null的情况,找到匹配元素时返回其索引,遍历完链表都未找到则返回 -1。
通过对LinkedList底层源码的剖析,我们清楚地了解了它的结构和各种操作的实现原理。LinkedList在插入和删除元素时具有高效性,尤其是在链表中间位置进行操作时,不需要像ArrayList那样进行大量元素的移动。然而,由于其基于链表结构,随机访问元素的时间复杂度较高,需要遍历链表来查找指定位置的元素。因此,在实际开发中,我们应根据具体的需求和操作场景,合理选择使用LinkedList或其他集合类,以达到最佳的性能和功能实现。
相关文章:
Java 中 LinkedList 的底层源码
在 Java 的集合框架中,LinkedList是一个独特且常用的成员。它基于双向链表实现,与数组结构的集合类如ArrayList有着显著差异。深入探究LinkedList的底层源码,有助于我们更好地理解其工作原理和性能特点,以便在实际开发中做出更合适…...

使用服务器部署DeepSeek-R1模型【详细版】
文章目录 引言deepseek-r1IDE或者终端工具算力平台体验deepseek-r1模型总结 引言 在现代的机器学习和深度学习应用中,模型部署和服务化是每个开发者面临的重要任务。无论是用于智能推荐、自然语言处理还是图像识别,如何高效、稳定地将深度学习模型部署到…...

k8s,1.修改容器内主机名和/etc/hosts 文件,2.root特权容器,3.pod安全策略(基于名称空间
1.修改容器内主机名和/etc/hosts 文件,让持久生效,通过修改资源清单方式---kind: PodapiVersion: v1metadata:name: rootspec:hostname: myhost # 修改主机名hostAliases: # 修改 /etc/hosts- ip: 192.168.88.240 # IP 地址hostnames: # 名…...

MSPFN 代码复现
1、环境配置 conda create -n MSPFN python3.9 conda activate MSPFN pip install opencv-python pip install tensorflow pip install tqdm pip install matplotlib2、train 2.1 创建数据集 2.1.1 数据集格式 |--rainysamples |--file1: |--file2:|--fi…...

除了console.error,还有什么更好的错误处理方式?
除了 console.error,在 Vue 应用中进行更好的错误处理可以采用以下几种方式: 一、使用全局错误处理 Vue 的错误捕获在 Vue 2 中,可以使用 errorHandler 来捕获全局的错误: Vue.config.errorHandler = (err, vm, info) => {// 处理错误,例如记录日志logError(err, info…...

力扣.270. 最接近的二叉搜索树值(中序遍历思想)
文章目录 题目描述思路复杂度Code 题目描述 思路 遍历思想(利用二叉树的中序遍历) 本题的难点在于可能存在多个答案,并且要返回最小的那一个,为了解决这个问题,我门则要利用上二叉搜索树中序遍历为有序序列的特性,具体到代码中&a…...

Yageo国巨的RC系列0402封装1%电阻库来了
工作使用Cadence多年,很多时候麻烦的就是整理BOM,因为设计原理图的时候图省事,可能只修改value值和封装。 但是厂家,规格型号,物料描述等属性需要在最后的时候一行一行的修改,繁琐又容易出错,过…...

wait/notify/join/设计模式
JUC wait obj.wait() 让进入 object 监视器的线程到 waitSet 等待wait()方法会释放对象的锁,进入 WaitSet 等待区,从而让其他线程就机会获取对象的锁。无限制等待,直到 notify 为止wait(long n)有时限的等…...

Windows Docker笔记-Docker拉取镜像
通过在前面的章节《安装docker》中,了解并安装成功了Docker,本章讲述如何使用Docker拉取镜像。 使用Docker,主要是想要创建并运行Docker容器,而容器又要根据Docker镜像来创建,那么首当其冲,必须要先有一个…...

七大排序思想
目录 七大排序的时间复杂度和稳定性 排序 插入排序 简单插入排序 希尔排序 选择排序 简单选择排序 堆排序 交换排序 冒泡排序 快速排序 快排的递归实现 hoare版本的快排 挖坑法的快排 双指针法的快排 快排的非递归 归并排序 归并的递归实现 归并的非递归实现…...

intra-mart实现简易登录页面笔记
一、前言 最近在学习intra-mart框架,在此总结下笔记。 intra-mart是一个前后端不分离的框架,开发时主要用的就是xml、html、js这几个文件; xml文件当做配置文件,html当做前端页面文件,js当做后端文件(js里…...

SpringBoot整合RocketMQ
前言 在当今快速发展的软件开发领域,构建高效、稳定的应用系统是每个开发者的追求。Spring Boot 作为一款极具影响力的开发框架,凭借其强大的自动化配置和便捷的开发特性,极大地简化了项目搭建过程。使用 Spring Boot,我们无需再…...

深入理解 YUV Planar 和色度二次采样 —— 视频处理的核心技术
深入理解 YUV Planar 和色度二次采样 —— 视频处理的核心技术 在现代视频处理和编码中,YUV 颜色空间和**色度二次采样(Chroma Subsampling)**是两个非常重要的概念。它们的结合不仅能够显著减少视频数据量,还能在保持较高视觉质量的同时优化存储和传输效率。而 YUV Plana…...

项目顺利交付,几个关键阶段
年前离放假还有10天的时候,来了一个应急项目, 需要在放假前一天完成一个演示版本的项目,过年期间给甲方领导看。 本想的最后几天摸摸鱼,这么一来,非但摸鱼不了,还得加班。 还在虽然累,但也是…...

第七天 开始学习ArkTS基础,理解声明式UI编程思想
学习 ArkTS 的声明式 UI 编程思想是掌握 HarmonyOS 应用开发的核心基础。以下是一份简洁高效的学习指南,帮助你快速入门: 一、ArkTS 声明式 UI 核心思想 数据驱动 UI f(state):UI 是应用状态的函数,状态变化自动触发 UI 更新。单…...
)
windows C++ Fiber (协程)
协程,也叫微线程,多个协程在逻辑上是并发的,实际并发由用户控件。 在windows上引入了纤程(fiber)。 WinBase.h 中函数原型 #if(_WIN32_WINNT > 0x0400)// // Fiber begin //#pragma region Application Family or OneCore Family or Game…...

游戏引擎学习第89天
回顾 由于一直没有渲染器,终于决定开始动手做一个渲染器,虽然开始时并不确定该如何进行,但一旦开始做,发现这其实是正确的决定。因此,接下来可能会花一到两周的时间来编写渲染器,甚至可能更长时间…...

2025新鲜出炉--前端面试题(一)
文章目录 1. vue3有用过吗, 和vue2之间有哪些区别2. vue-router有几种路由, 分别怎么实现3. webpack和rollup这两个什么区别, 你会怎么选择4. 你能简单介绍一下webpack项目的构建流程吗5. webpack平时有手写过loader和plugin吗6. webpack这块你平时做过哪些优化吗?7…...

教程 | i.MX RT1180 ECAT_digital_io DEMO 搭建(一)
本文介绍 i.MX RT1180 EtherCAT digital io DEMO 搭建,Master 使用 TwinCAT ,由于步骤较多,分为上下两篇,本文为第一篇,主要介绍使用 TwinCAT 控制前的一些准备。 原厂 SDK 提供了 evkmimxrt1180_ecat_examples_digit…...
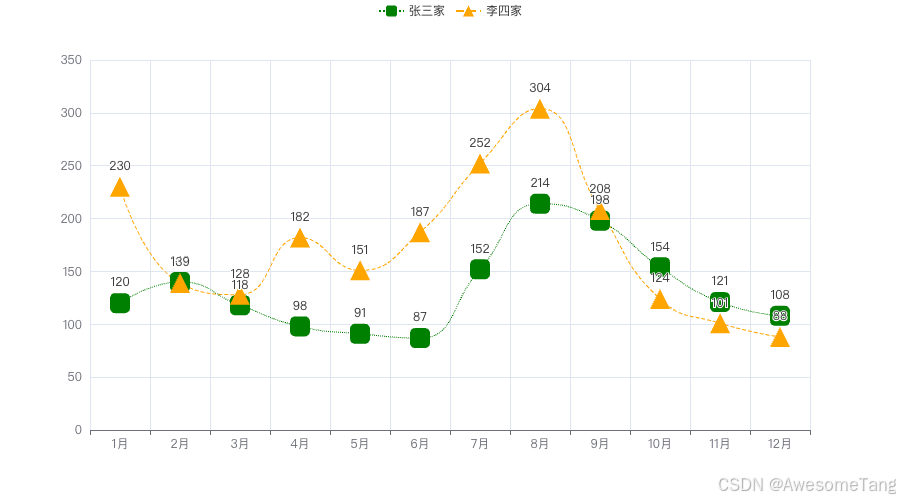
Pyecharts系列课程04——折线图/面积图(Line)
本章我们学习在Pyecharts中折线图(Line)的使用。折线图通用应用于数据的趋势分析。 折线图 我们现在有两组数据,x_data是2024年的月份,y_data为对应张三甲每个月的用电量。 # 家庭每月用电量趋势 x_data ["1月", &q…...

基于React的记忆管理UI组件库:openclaw-memory-ui实战指南
1. 项目概述:一个为记忆管理而生的开源UI组件库最近在折腾一个需要处理大量结构化记忆数据的项目,比如知识库、笔记应用或者智能助手的历史对话管理。这类应用的核心痛点在于,数据本身是复杂的、多维的,但传统的列表或表格展示方式…...

AI赋能安全分析:hexstrike-ai项目实战与提示词工程详解
1. 项目概述:一个为安全研究而生的AI助手如果你是一名安全研究员、逆向工程师或者渗透测试人员,那么你肯定对“工具链”这个词深有体会。我们的工作台就像是一个复杂的车间,摆满了IDA Pro、Ghidra、x64dbg、Burp Suite、Wireshark……这些工具…...

AI攻防时间差:当漏洞发现速度碾压修复速度— 聚焦技术核心
AI攻防时间差:当漏洞发现速度碾压修复速度 — 聚焦技术核心 引言:当两个世界碰撞 2026年5月,对于网络安全领域而言,是一个具有分水岭意义的月份。 一边是360人工智能安全研究院在5月12日发布的重磅报告,首次提出**“AI…...

RTX 5090功耗传闻解析:600W显卡对PC生态的挑战与应对
1. 项目概述:从一则功耗新闻到显卡生态的深度思考最近,英伟达下一代旗舰显卡RTX 5090的功耗传闻在硬件圈里炸开了锅。消息称其TGP(总图形功耗)可能高达600W,相比RTX 4090的450W,直接激增了150W。这不仅仅是…...

FanControl终极指南:如何突破NVIDIA显卡风扇30%限制实现0 RPM静音控制
FanControl终极指南:如何突破NVIDIA显卡风扇30%限制实现0 RPM静音控制 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/Git…...

基于LLM与RAG构建智能问答系统:架构、实现与优化指南
1. 项目概述:当RAG遇上LLM,构建你的智能知识问答引擎最近在GitHub上看到一个挺有意思的项目,叫“Jenqyang/LLM-Powered-RAG-System”。光看名字,圈内人大概就能猜到个七七八八:这是一个基于大语言模型(LLM&…...

神经网络建筑负荷预测与供暖优化【附程序】
✨ 长期致力于BP神经网络、负荷预测、空气源热泵、优化控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于BP神经网络的公共建筑热负荷预测模型&…...

从零制作LED智能面具:三种方案详解与避坑指南
1. 项目概述:三种不同段位的LED化妆面具制作如果你对闪烁的灯光和可穿戴电子设备着迷,一直想亲手做一个能在派对或演出中吸引眼球的智能面具,但又觉得无从下手,那这个项目就是为你准备的。我花了几个周末的时间,从最简…...
)
FPGA驱动ADS1256的ADC精度优化实战(三)
1. 硬件连接优化:从杜邦线到PCB布局的精度跃升 第一次用杜邦线连接FPGA和ADS1256时,我测得的电压误差居然有30mV,这让我差点怀疑人生。后来把万用表直接怼到ADC引脚上,才发现杜邦线本身就有5-8mV的压降波动。这种看似微不足道的干…...
)
Win10/Win11网络适配器出问题?试试这个重置TCP/IP和Winsock的终极命令(netsh winsock reset)
彻底解决Windows网络协议栈故障:netsh命令深度指南 当你的Windows 10或11设备突然无法联网,甚至连网络适配器都显示异常时,大多数人会本能地尝试重启电脑或切换飞行模式。但如果你发现这些常规操作毫无效果,甚至Windows自带的网络…...