MySQL三大版本的演进
三大版本的演进
文章目录
- 三大版本的演进
- 一:5.6版本(大跃进时期)
- 1:支持只读事务
- 2:innodb存储引擎增强
- 2.1:缓冲池刷盘策略优化
- 2.2:BufferPool缓冲池预热
- 3:新增Performance_Schema库监控全局资源
- 4:索引下推(减少回表)
- 5:MRR机制(减少回表)
- 6:主从同步的复制改进
- 7:其他特性
- 二:5.7版本
- 1:引入共享排它锁(SX锁)
- 1.1:SMO【悲观写入操作】问题
- 2.2:SX工作原理
- 1:读操作的执行流程
- 2:乐观写入的执行流程
- 3:悲观写入的执行流程
- 2.3:并发事务冲突分析
- 2:json格式的支持
- 3:其他特性
- 三:8.0版本
- 1:移除查询缓存(Query Cache)
- 2:锁机制优化
- 3:在线修改的系统参数支持持久化
- 4:增强多表连接查询
- 4.1:哈希连接(Hash Join)
- 4.2:反连接(Anti Join)
- 5:增强索引机制
- 5.1:索引跳跃式扫描机制(Index Skip Scan)
- 6:CTE通用表达式
- 7:窗口函数(难点,特色)
- 8:其他特性
一:5.6版本(大跃进时期)
增加了很多重要的功能但是都没有完美实现
1:支持只读事务
在此之前的版本中,MySQL默认会为每个事务都分配事务ID,所有事务都一视同仁
但在5.6版本中开始支持只读事务,MySQL内部会有两个事务链表,一个是只读事务链表,一个是正常事务链表。
当一个事务中只有读操作时,MySQL并不会为这些事务分配ID,默认全部为0(但是会分配查询ID),然后将其标记为一个只读事务,并加入只读事务链表中,直到当这个事务中出现变更数据的操作时,才会正式为其分配事务ID,以及将其挪动到正常事务链表中。
这样做的好处在于:其他事务利用MVCC机制读取数据时,生成的ReadView读视图中的活跃事务链表会小很多很多,因此遍历的速度更快
同时也无需为其分配回滚段,从而进一步提升了MySQL整体的查询性能。
2:innodb存储引擎增强
2.1:缓冲池刷盘策略优化
在之前的版本的InnoDB-BufferPool缓冲池中,变更过的数据页会共用MySQL后台的刷盘线程,也就是redo-log、undo-log、bin-log…一系列内存到磁盘的刷盘工作,都是采用同一批线程来完成。
在MySQL5.6版本中,BufferPool引入了独立的刷盘线程,也就意味着缓冲池中变更过的数据页会由专门的线程来负责刷盘,这样能够提升缓冲池的刷盘效率,无需排队等待刷写。
同时BufferPool的刷盘线程,还支持开启多线程并发刷盘操作,这样在缓冲池较大的情况下,能够进一步提升刷盘的效率,从而让数据落盘的效率更快,从一定程度上也提升了数据的安全性
2.2:BufferPool缓冲池预热
缓冲池预热是一种特别好的机制,在之前版本的内存缓冲池中,当MySQL关闭时,原本内存中的热点数据都会被清空,重启后所有的热点数据又需要经过时间的沉淀,然后才能留在内存中。
但MySQL5.6版本中,每次关闭MySQL时都会将内存中的热点数据页保存到磁盘中,当重启时会直接从磁盘中载入之前的热点数据,避免了热点数据的重新“选拔”!
3:新增Performance_Schema库监控全局资源
这里面会记录:数据库整体的监控信息,比如事务监控信息、最近执行的SQL信息、最近连接的客户端信息、数据库各空间的使用信息…
基于这个库可以在线上构建出一个完善的MySQL监控系统:
- Statements/execution stages:MySQL统计的一些消耗资源较高的SQL语句。
- Table and Index I/O:MySQL统计的那些表和索引会导致I/O负载过高。
- Table Locks:MySQL统计的表中数据的锁资源竞争信息。
- Users/Hosts/Accounts:消耗资源最多的客户端、IP机器、用户。
- Network I/O:MySQL统计的一些网络相关的资源情况。
4:索引下推(减少回表)
Index Condition Pushdown索引下推简称ICP,索引下推是MySQL5.6版本以后引入的一种优化机制
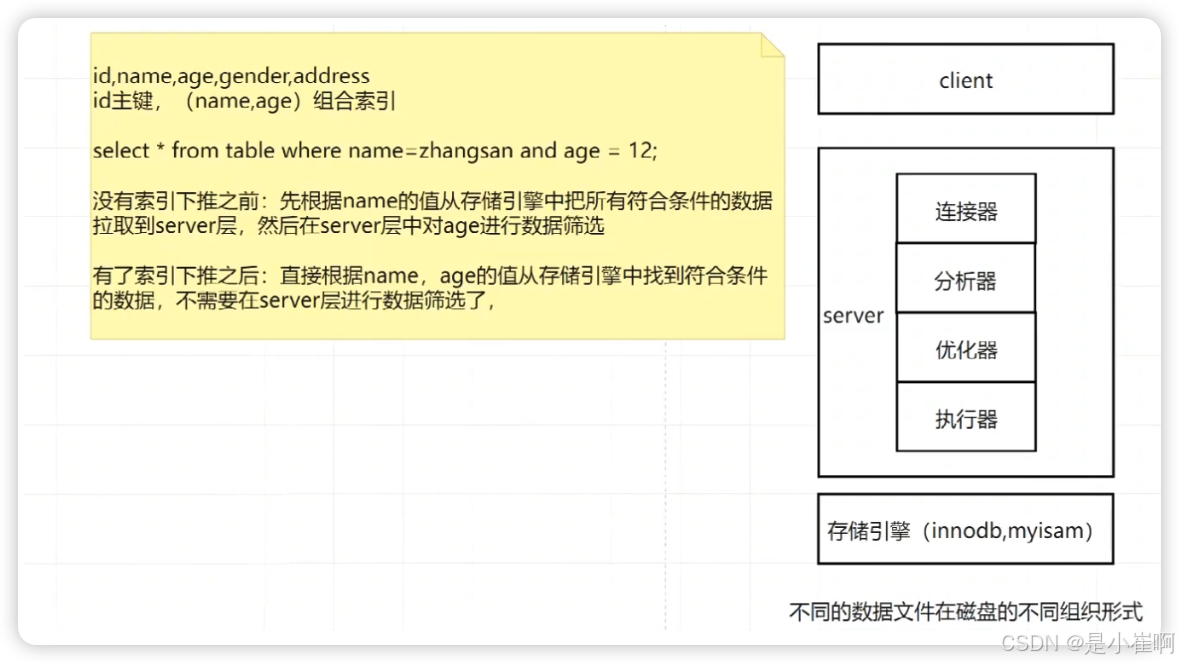
可以通过命令set optimizer_switch=‘index_condition_pushdown=off|on’;命令来手动管理。
set optimizer_switch='index_condition_pushdown=on';
set optimizer_switch='index_condition_pushdown=off';
5:MRR机制(减少回表)
Multi-Range Read简称为MRR机制,这也是和索引下推一同在MySQL5.6版本中引入的性能优化措施
一般来说,在实际业务中我们应当尽量通过索引覆盖的特性,减少回表操作以降低IO次数,但在很多时候往往又不得不做回表才能查询到数据
回表显然会导致产生大量磁盘IO,同时更严重的一点是:还会产生大量的离散IO
select * from student where score between 0 and 59; # 找到所有的不及格的学生
假设成绩字段上存在一个普通索引,那思考一下,这条SQL的执行流程是什么样的呢?
- 先在成绩字段的索引上找到0分的节点,然后拿着ID去回表得到成绩零分的学生信息。
- 再次回到成绩索引,继续找到所有1分的节点,继续回表得到1分的学生信息。
- 再次回到成绩索引,继续找到所有2分的节点…
- 周而复始,不断重复这个过程,直到将0~59分的所有学生信息全部拿到为止。
假设此时成绩05分的表数据,位于磁盘空间的page_01页上,而成绩为510分的数据,位于磁盘空间的page_02页上,成绩为10~15分的数据,又位于磁盘空间的page_01页上。
此时回表查询时就会导致在page_01、page_02两页空间上来回切换,但05、1015分的数据完全可以合并,然后读一次page_01就可以了,既能减少IO次数,同时还避免了离散IO。
而MRR机制就主要是解决这个问题的,针对于辅助索引的回表查询,减少离散IO,并且将随机IO转换为顺序IO,从而提高查询效率。
MRR实现原理
MRR机制中,对于辅助索引中查询出的ID,会将其放到缓冲区的read_rnd_buffer中
然后等全部的索引检索工作完成后,或者缓冲区中的数据达到read_rnd_buffer_size大小时,此时MySQL会对缓冲区中的数据排序
从而得到一个有序的ID集合:rest_sort,最终再根据顺序IO去聚簇/主键索引中回表查询数据。
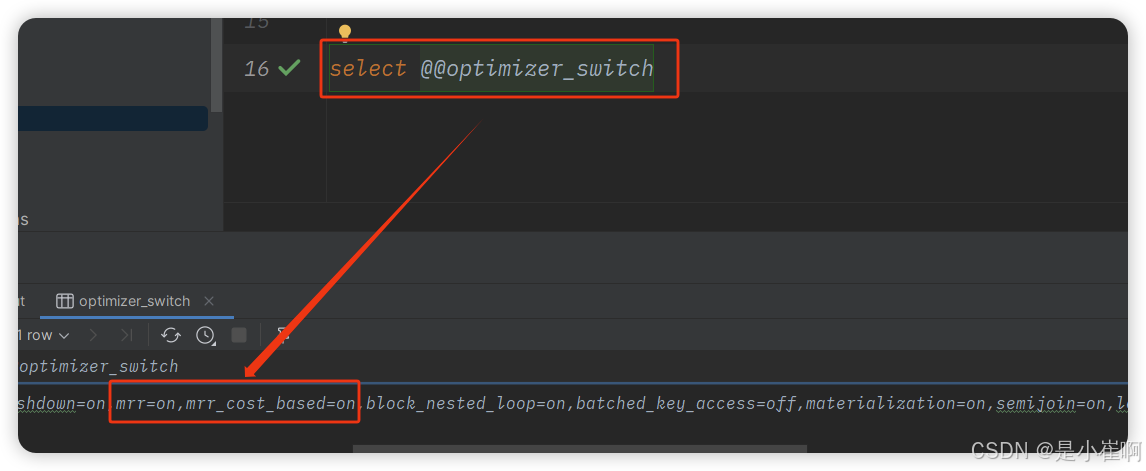
如何开启和关闭呢?
set @@optimizer_switch='mrr=on|off, mrr_cost_based=on|off';
可以通过上述这条命令开启或关闭MRR机制,MySQL5.6及以后的版本是默认开启的。
6:主从同步的复制改进
针对于主从数据同步的问题,主要引入了GTID复制、无损复制(增强半同步复制)、延时复制、并行复制这四种技术,这个后续详细说
7:其他特性
- 索引增强:全文索引支持InnoDB与亚洲语种分词、支持空间索引等。
- 表分区增强:单表分区数量最大可创建8192个、分区锁性能提升、支持cloumns分区类型。
- 增强日期类型:time、datetime、timestamp精度提升到微秒级,datetime容量缩减到5字节。
- 日志增强:Redo-log文件大小限制由4G→512G、Undo-log文件可独立指定位置存储。
- 支持在线DDL(Online DDL)、对limit语句做了优化…

二:5.7版本
5.6版本中步子迈的太大,很多方面的技术都需要根据市场反馈做细微调整,因此成功的为MySQL5.7做好了铺垫
一般的项目如果不选用MySQL8.0,基本上都会选择MySQL5.7而不是5.6。
1:引入共享排它锁(SX锁)
在MySQL5.7之前的版本中,数据库中仅存在两种类型的锁,即共享锁与排他锁
但是在MySQL5.7.2版本中引入了一种新的锁,被称之为(SX)共享排他锁,这种锁是共享锁与排他锁的杂交类型
SX锁不会阻塞S锁,但是会阻塞X、SX锁
1.1:SMO【悲观写入操作】问题
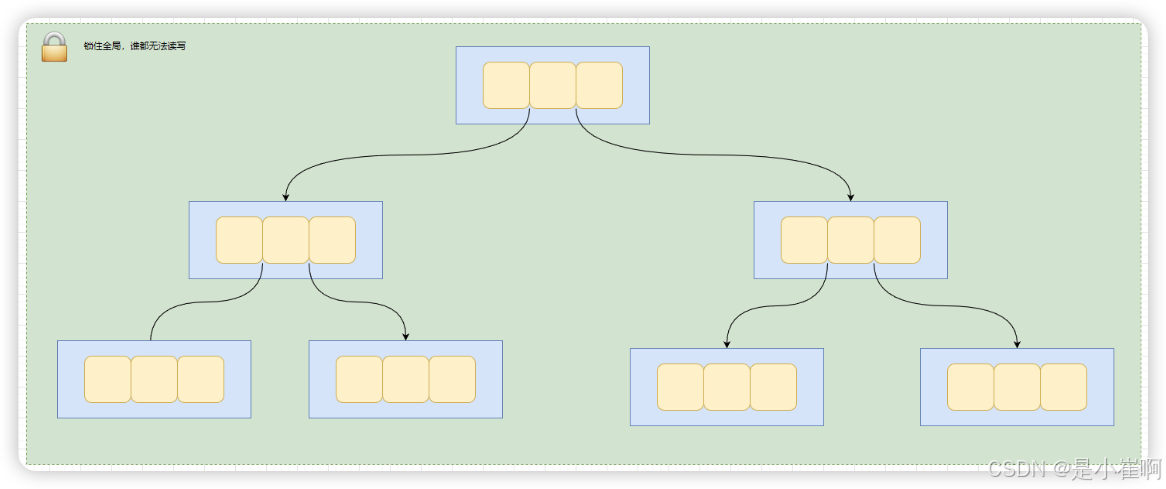
在SQL执行期间一旦更新操作触发B+Tree叶子节点分裂,那么就会对整棵B+Tree加排它锁
这不但阻塞了后续这张表上的所有的更新操作,同时也阻止了所有试图在B+Tree上的读操作,也就是会导致所有的读写操作都被阻塞,其影响巨大。
因此,这种大粒度的排它锁成为了InnoDB支持高并发访问的主要瓶颈,而这也是MySQL 5.7版本中引入SX锁要解决的问题。
2.2:SX工作原理
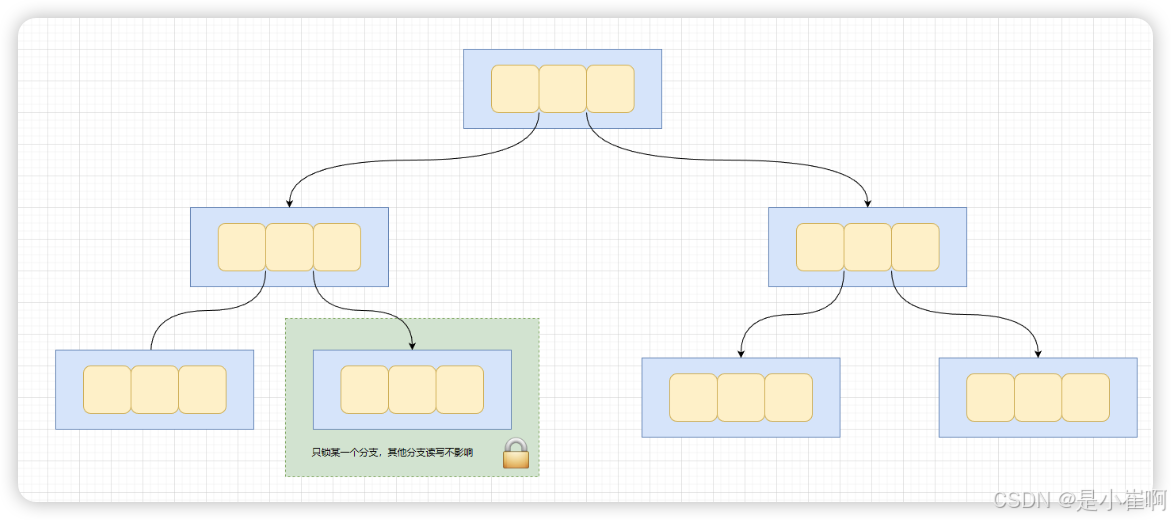
针对上述问题最简单的方式就是减小SMO问题发生时,锁定的B+Tree粒度
当发生SMO问题时,就只锁定B+Tree的某个分支,而并不是锁定整颗B+树,从而做到不影响其他分支上的读写操作。
1:读操作的执行流程
- 读取数据之前首先会对B+Tree加一个共享锁。
- 在基于树检索数据的过程中,对于所有走过的叶节点会加一个共享锁。
- 找到需要读取的目标叶子节点后,先加一个共享锁,释放步骤②上加的所有共享锁。
- 读取最终的目标叶子节点中的数据,读取完成后释放对应叶子节点上的共享锁。
2:乐观写入的执行流程
- 乐观写入之前首先会对B+Tree加一个共享锁。
- 在基于树检索修改位置的过程中,对于所有走过的叶节点会加一个共享锁。
- 找到需要写入数据的目标叶子节点后,先加一个排他锁,释放步骤②上加的所有共享锁。
- 修改目标叶子节点中的数据后,释放对应叶子节点上的排他锁。
3:悲观写入的执行流程
- 悲观更新之前首先会对B+Tree加一个共享排他锁(SX锁)。
- 由于①上已经加了SX锁,因此当前事务执行过程中会阻塞其他尝试更改树结构的事务。
- 遍历查找需要写入数据的目标叶子节点,找到后对其分支加上排他锁,释放①中加的SX锁。
- 执行SMO操作,也就是执行悲观写入操作,完成后释放步骤③中在分支上加的排他锁。
2.3:并发事务冲突分析
对于读操作、乐观写入操作而言,并不会加SX锁,共享排他锁仅针对于悲观写入操作会加
由于读操作、乐观写入执行前对整颗树加的是S锁,因此悲观写入时加的SX锁并不会阻塞乐观写入和读操作
但当另一个事务尝试执行SMO操作变更树结构时,也需要先对树加上一个SX锁,这时两个悲观写入的并发事务就会出现冲突,新来的事务会被阻塞。
⚠️ 当第一个事务寻找到要修改的节点后,会对其分支加上X锁,紧接着会释放B+Tree上的SX锁,这时另外一个执行SMO操作的事务就能获取SX锁啦!
因此:MySQL5.7版本引入SX锁之后,解决了5.6版本发生SMO操作时阻塞一切读写操作的问题,这样能够在一定程度上提升了InnoDB表的并发性能。
⚠️ 虽然一个执行悲观写入的事务,找到了要更新/插入数据的节点后会释放SX锁,但是会对其上级的叶节点(叶分支)加上排他锁,因此正在发生SMO操作的叶分支,依旧是会阻塞所有的读写行为!也就是当一个要读取的数据,位于正在执行SMO操作的叶分支中时,依旧会被阻塞。
2:json格式的支持
随着非结构化数据的存储需求持续增长,各类非关系型数据库应运而生,例如MongoDB
在MySQL5.7.8版本中也支持了json数据类型,并且为其提供了一系列操作的API。
虽然说MySQL也支持了json格式存储,但显然是太晚了,自然无法抢过MongoDB的市场占用率
从性能和存储容量来说,MySQL也无法竞争过MongoDB,但相较于其他非结构化数据库,MySQL存储json数据有两大优势:
- 对于json数据的API操作支持事务
- 支持为一个表字段设置json格式,也就意味着MySQL中可以将结构化数据和非结构化数据共同存储。
3:其他特性
- 临时表优化,临时表的写操作不记录redo-log、不为其生成缓冲数据页,减小资源占用。
- 多接点部署时,数据同步复制再次优化,支持多主/源复制、以及真正意义上的并行复制等。
- 引入了虚拟列的实现,类似于Oracle数据库中的函数索引。
- 移除了默认的test数据库,以及默认不会创建匿名用户,引入密码过期策略。
- 触发器增强,表上同一种事件、同一时机的触发器可创建多个,之前则只能允许创建一个。
- 推出了新的mysqlpump工具,用于数据的逻辑备份、引入了新的客户端工具mysqlsh等。
- 支持通过max_execution_time限制一条SQL的执行超时时间、支持innodb_deadlock_detect死锁检测。
- GIS空间数据类型增强,使用Boost.Geometry代替原有的GIS算法,InnoDB支持空间索引。
- …
具体看这个:https://dev.mysql.com/doc/refman/5.7/en/
三:8.0版本
1:移除查询缓存(Query Cache)
Query Cahce查询缓存的设计初衷很好,也就是利用热点探测技术,对于一些频繁执行的查询SQL,直接将结果缓存在内存中
之后再次来查询相同数据时,就无需走磁盘,而是直接从查询缓存中获取数据并返回。
听起来似乎还不错呀,好像确实能带来不小的性能提升呢?但实则很鸡肋
select * from table where user_id=1;
select * from table where user_id = 1;
看似一模一样的语句因为user_id后面有没有空格就会导致sql计算出来的hash值不同,从而导致无法命中查询缓存,所以查询缓存十分的鸡肋
不仅如此,被移除还有如下的原因:
- 缓存命中率低:几乎大部分SQL都无法从查询缓存中获得数据。
- 占用内存高:将大量查询结果放入到内存中,会占用至少几百MB的内存。
- 增加查询步骤:查询表之前会先查一次缓存,查询后会将结果放入缓存,额外多几步开销。
- 缓存维护成本不小,需要LRU算法淘汰缓存,同时每次更新、插入、删除数据时,都要清空缓存中对应的数据。
- 查询缓存是专门为MyISAM引擎设计的,而InnoDB构建的缓冲区完全具备查询缓存的作用。
- redis yyds
2:锁机制优化
一方面对获取共享锁的写法进行了优化,如下:
-- MySQL8.0之前的版本
select ... lock in share mode;-- MySQL8.0及后续的版本
select ... for share;
第二方面则支持非阻塞式获取锁机制,可以在获取锁的写法上加上NOWAIT、SKIP LOCKED关键字,这样在未获取到锁时不会阻塞等待
- 使用SKIP LOCKED未获取到锁时会直接返回空
- 使用NOWAIT会直接返回并向客户端返回异常。
-- 非阻塞式获取锁机制,拿不到锁时不用等待
select * for update nowait; -- 返回异常
select * for update skip locked -- 返回null
3:在线修改的系统参数支持持久化
在之前的版本中,通过set、set global的形式修改某个系统变量时,这种方式设置的参数值都是一次性的
也就是修改过的参数并不会被同步到本地,当MySQL重启时,这些调整过的参数又会回归默认值
如果想要让调整过的参数生效,就必须要手动停止MySQL,然后去修改my.ini/my.conf文件,修改完成后再重启数据库服务,这时才能让参数永久生效。
而在MySQL8.0中则彻底优化了这个问题,推出了在线修改参数后,支持持久化到本地文件的机制,也就是通过SET PERSIST命令来完成,如下:
-- 调整事务的隔离级别(针对于当前连接有效)
set transaction isolation level read uncommitted;-- 调整事务的隔离级别(针对于全局有效,重启后会丢失)
set global tx_isolation = "read-committed";-- 调整事务的隔离级别(针对于全局有效,并且会持久化到本地,重启后不会丢失)
set persist global.tx_isolation = "repeatable-read";
通过set persist命令持久化的参数,可以通过下述命令来查看:
select * from performance_schema.persisted_variables;
这条命令的本质其实是:基于MySQL自带的performance_schema监控库查询持久化过的参数。
参数持久化的原理也非常简单,当执行set persist命令时,会将改变过的参数写入到本地的mysqld-auto.cnf文件中
MySQL每次启动时都会读取这个文件中的值,如果该文件中存在参数,则会直接将其加载,从而实现了一次修改,永久有效。
移除永久设置
如果想要参数不再持久化到本地时,可以选择删除安装目录下的mysqld-auto.cnf文件,或执行reset persist命令来清除
但这两种方式都只对下次重启时生效,毕竟本次参数已经被载入内存了,所以只能通过再次手动修改的方式复原。
4:增强多表连接查询
在之前的MySQL版本中,仅支持交叉连接、内连接、左外连接、右外连接四种连接类型,这四种连接都会采用默认的连接算法
在8.0版本中提供了哈希连接、反连接两种连接优化的支持。
4.1:哈希连接(Hash Join)
对于哈希连接算法,MySQL是默认开启的,咱们可通过set optimizer_switch=“hash_join=off”;的形式来手动控制开关。
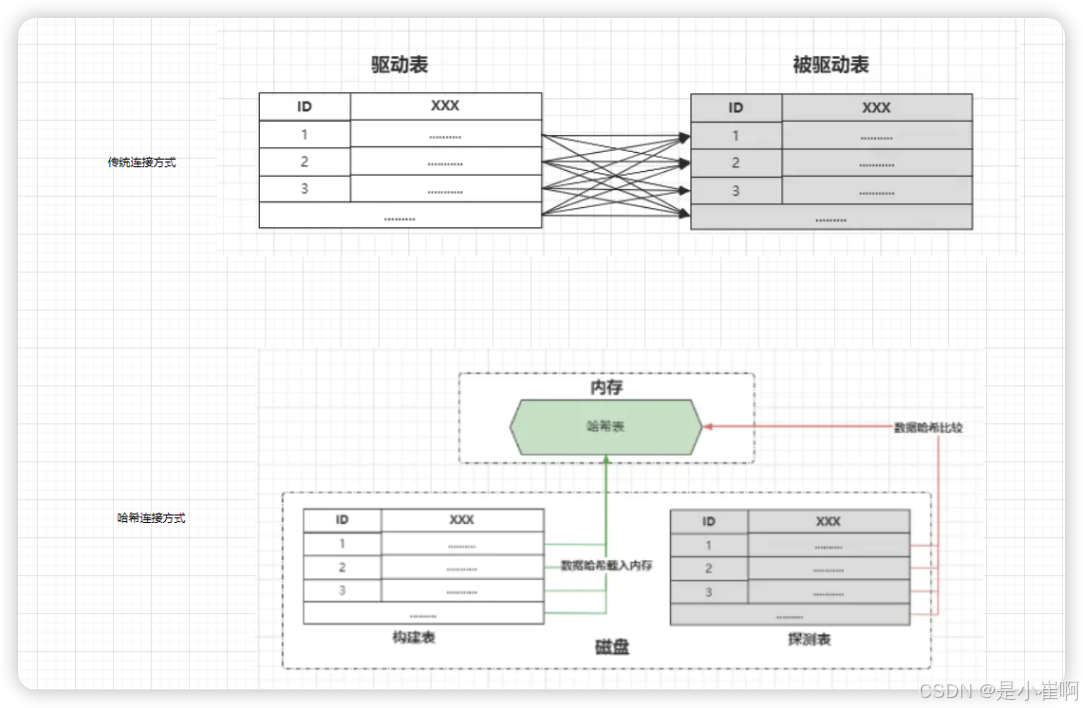
在哈希连接算法中会分为两个阶段:
- 构建阶段:选择一张小表作为构建表,接着会基于连接字段做哈希处理,生成哈希值放入内存中构建出一张哈希表。
- 探测阶段:遍历大表的每一行数据,然后对连接字段做哈希处理,通过生成的哈希值与内存哈希表做比较,符合条件则放入结果集中。
哈希连接的问题和解决方案
哈希连接存在一个致命问题,就是内存中join_buffer_size的容量无法完全载入构建表的哈希数据时怎么办呢?这里就有两种解决方案:
- 分批处理,将构建表的数据拆分为几部分,每次载入一部分到内存,但这样会导致大表的遍历次数,随着分批次数变大而增多。
- 利用磁盘完成,也就是首先将构建表的所有数据做哈希处理,放不下时将一部分处理好的哈希数据放入磁盘,在探测阶段遍历大表时,每次对大表数据生成哈希值后,做判断时从磁盘依次读取处理好的哈希值做判断。
而MySQL中选择的是第二种,也就是当内存无法完全放下构建表的哈希数据时,会采用磁盘+内存混合的模式执行哈希连接。
MySQL什么情况下会选用哈希连接?
该算法有几个硬性限制:
- 目前哈希连接算法仅支持内连接的多表连查方式。
- 哈希连接算法必须要求存在等值连接条件,即a.id=b.id才行,a.id>b.id是不行的。
- 如果连接字段可以走索引查询的情况下,默认依旧会采用循环连接算法。
第二点的原因在于:哈希连接算法生成的哈希值是无序的,所以必须要用等值连接才行。
第三点的原因在于:连接查询时走索引的效率并不低,哈希连接需要生成哈希表,因此需要时间,因此在能够走索引连表的情况下,哈希连接算法的效率反而比不上循环连接。
4.2:反连接(Anti Join)
反连接是MySQL8.0对于一些反范围查询操作的优化,主要针对于下述几种情况会做优化:
not in (select ... from ...);
not exists (select ... from ...);in (select ... from) is not true
exists (select .. from ...) is not truein (select ... from ..) is false
exists (select ... from ...) is false
在MySQL早些版本中,使用NOT EXISTS、NOT IN、IS NOT…这类操作时有可能会导致索引失效,而且也会让查询效率变低
因此MySQL8.0版本中会对上述几类语句进行优化,当你的SQL语句使用了上述语法检索数据时,在MySQL内部会将其转变为反连接类型的查询语句。
也就是会将右边的子查询结果集,变为一张物理临时表,然后基于条件字段做连接查询,官方号称在某些场景下,能够让上述几类语句的查询性能提升20%
5:增强索引机制
首先对联合索引提供了一种跳跃扫描机制的支持,也就意味着使用联合索引时,就算未遵循最左前缀匹配原则,也可以使用联合索引来检索数据。
除此之外,还有另外三种新的索引特性:隐藏索引、降序索引以及函数索引
5.1:索引跳跃式扫描机制(Index Skip Scan)
比如此时通过(A、B、C)三个列建立了一个联合索引,此时有如下一条SQL:
select * from table where B = 'xxx' and C = 'xxx';
按理来说,这条SQL既不符合最左前缀原则,也不具备使用索引覆盖的条件,因此绝对是不会走联合索引查询的
但跳跃扫描机制使得优化器为你重构了SQL,比如上述这条SQL则会重构成如下情况:
SELECT * FROM tb_xx WHERE B = xxx AND C = xxx AND A = 'xxx'
UNION ALL
SELECT * FROM tb_xx WHERE B = xxx AND C = xxx AND A = "yyy"
......
SELECT * FROM tb_xx WHERE B = xxx AND C = xxx AND A = "zzz";
“虽然你没用第一个字段,但我给你加上去,今天这个联合索引你就得用,不用也得给我用”
⚠️ 跳跃式扫描机制有很多条件限制,很多情况下无法触发:https://dev.mysql.com/doc/refman/8.0/en/range-optimization.html
6:CTE通用表达式
CTE是一个具备变量名的临时结果集,也就是可以将一条查询语句的结果保存到一个变量里面
后续在其他语句中允许直接通过变量名来使用该结果集,语法如下:
with CTE名称 as (查询语句/子查询语句) select 语句;
-- MySQL8.0版本之前的子查询语句
select * from t1 where xx in (select xx from t2 where yy = "zzz");-- MySQL8.0中使用CTE表达式来代替
with cte_query as(select xx from t2 where yy = "zzz")
select * from t1 join cte_query on t1.xx = cte_query.xx;
7:窗口函数(难点,特色)
窗口函数是一种分析型的OLAP函数,因此也被称之为分析函数,它可以理解成是数据的集合,类似于group by分组的功能
之前的MySQL版本基于某个字段分组后,会将数据压缩到一行显示
窗口函数的实际语法如下:
窗口函数 over([partition by 字段名 order by 字段名 asc|desc])窗口函数 over 窗口名 ... window 窗口名
as ([partition by 字段名 order by 字段名 asc|desc])
- 序号函数:
- row_number():按序排列,相同的值序号会往后推,如88、88、89排序为1、2、3。
- rank():并列排序,相同的值序号会跳过,如88、88、89排序为1、1、3。
- dense_rank():并列排序,相同的值序号不会跳过,如88、88、89排序为1、1、2。
- 分布函数:
- percent_rank():计算当前行数据的某个字段值占窗口内某个字段所有值的百分比。
- cume_dist(): 小于等于当前字段值的行数与整个分组内所有行数据的占比。
- 前后函数:
- lag(expr,n):返回分组中的前n条符合expr条件的数据。
- lead(expr,n):返回分组中的后n条符合expr条件的数据。
- 首尾函数:
- first_value(expr):返回分组中的第一条符合expr条件的数据。
- last_value(expr):返回分组中的最后一条符合expr条件的数据。
- 其它函数:
- nth_value(expr,n):返回分组中的第n条符合expr条件的数据。
- ntile(n):将一个分组中的数据再分成n个小组,并记录每个小组编号。
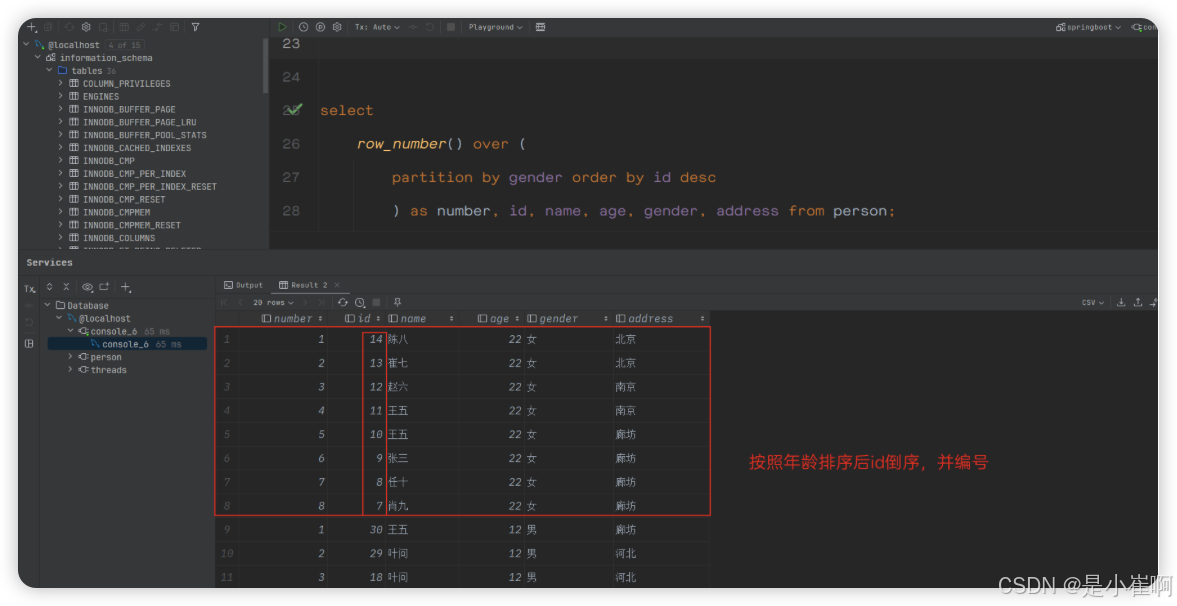
-- 按性别分组,并按照ID值从大到小对各分组中的数据进行排序,最后输出。select -- 使用 row_number() 序号窗口函数row_number() over(-- 基于性别做分组partition by user_sex -- 然后基于 ID 做倒序order by user_id desc) as serial_num,user_id, user_name, user_sex, password, register_time
fromzz_users;+------------+---------+-----------+----------+----------+---------------------+
| serial_num | user_id | user_name | user_sex | password | register_time |
+------------+---------+-----------+----------+----------+---------------------+
| 1 | 4 | 张三 | 女 | 8888 | 2022-09-17 23:48:29 |
| 2 | 1 | 李四 | 女 | 6666 | 2022-08-14 15:22:01 |
| 1 | 3 | 王五 | 男 | 4321 | 2022-09-16 07:42:21 |
| 2 | 2 | 赵六 | 男 | 1234 | 2022-09-14 16:17:44 |
+------------+---------+-----------+----------+----------+---------------------+
8:其他特性
-
将默认的UTF-8编码格式从latin替换成了utf8mb4,后者包含了所有emoji表情包字符。
-
增强NoSQL存储功能,优化了5.6版本引入的NoSQL技术,并完善了对JSON的支持性。
-
InnoDB引擎再次增强,对自增、索引、加密、死锁、共享锁等方面做了大量改进与优化。
-
支持定义原子DDL语句,即当需要对库表结构发生变更时,变更操作可定义为原子性操作。
-
支持正则检索,新增REGEXP_LIKE()、EGEXP_INSTR()、REGEXP_REPLACE()、REGEXP_SUBSTR()等函数提供支持。
-
优化临时表,临时表默认引擎从Memory替换为TempTable引擎,资源开销少,性能更强。
-
锁机制增强,除开前面聊到的锁特性变更外,新引入了一种备份锁,获取/释放锁语法如下:
-- 获取锁: lock instance for backup -- 释放锁: unlock instance -
Bin-log日志增强,过期时间精确到秒,利用zstd算法增强了日志事务的压缩功能。
-
安全性提高,认证加密插件更新、密码策略改进、新增角色功能、日志文件支持加密等。
-
引入资源组的概念,支持按业务优先级来控制工作线程的CPU资源抢占几率。
-
更多详细:https://dev.mysql.com/doc/refman/8.0/en/
相关文章:
MySQL三大版本的演进
三大版本的演进 文章目录 三大版本的演进一:5.6版本(大跃进时期)1:支持只读事务2:innodb存储引擎增强2.1:缓冲池刷盘策略优化2.2:BufferPool缓冲池预热 3:新增Performance_Schema库监…...

利用 IMU 估计人体关节轴向和位置 —— 论文推导
Title: 利用 IMU 估计人体关节轴向和位置 —— “Joint axis and position estimation from inertial measurement data by exploiting kinematic constraints” —— 论文推导 文章目录 I. 论文回顾II. 铰接关节的约束1. 铰接关节约束的原理2. 铰接关节约束的梯度3. 铰接关节约…...

脚本一键生成管理下游k8s集群的kubeconfig
一、场景 1.1 需要管理下游k8s集群的场景。 1.2 不希望使用默认的cluster-admin权限的config. 二、脚本 **重点参数: 2.1 配置变量。 1、有单独namespace的权限和集群只读权限。 2、自签名的CA证书位置要正确。 2.2 如果配置错误,需要重新…...

数据库系统概念第六版记录 三
外码约束(Foreign Key Constraint) 外码(Foreign Key, FK)是关系数据库中的一个约束,它用于保证表之间的引用完整性。外码的值必须: 要么存在于被引用表的主键列中,要么为空(NULL&…...

YOLOv11-ultralytics-8.3.67部分代码阅读笔记-files.py
files.py ultralytics\utils\files.py 目录 files.py 1.所需的库和模块 2.class WorkingDirectory(contextlib.ContextDecorator): 3.def spaces_in_path(path): 4.def increment_path(path, exist_okFalse, sep"", mkdirFalse): 5.def file_age(path__fi…...

微信小程序案例1——制作猫眼电影底部标签导航栏
文章目录 一、项目步骤1 新建一个无AppID的movie项目2将准备好的底部标签导航图标拷贝到movie项目下面(将图标文件夹image放到项目文件夹里)3 打开App.json配置文件,在pages数组里添加4个页面路径:电影“pages/movie/movie”、影院“pages/cinema/cinema…...

【大数据技术】搭建完全分布式高可用大数据集群(Kafka)
搭建完全分布式高可用大数据集群(Kafka) kafka_2.13-3.9.0.tgz注:请在阅读本篇文章前,将以上资源下载下来。 写在前面 本文主要介绍搭建完全分布式高可用集群 Kafka 的详细步骤。 注意: 统一约定将软件安装包存放于虚拟机的/software目录下,软件安装至/opt目录下。 安…...

【服务器知识】如何在linux系统上搭建一个nfs
文章目录 NFS网络系统搭建**1. 准备工作****2. 服务器端配置****(1) 安装 NFS 服务****(2) 创建共享目录****(3) 配置共享规则****(4) 生效配置并启动服务****(5) 防火墙配置** **3. 客户端配置****(1) 安装 NFS 客户端工具****(2) 创建本地挂载点****(3) 挂载 NFS 共享目录***…...
图片画质增强:轻松提升画质
前言: 今天给大家推荐一款非常实用的图片画质增强软件,它无需联网即可使用,完全离线操作,这款软件基于先进的深度学习技术,能够对模糊图片进行强大的高清处理,效果令人惊艳。 图片画质增强:一…...

vscode快速接入deepseek 实践操作
背景说明 在deepseek快速火爆的情况下,也想自己体验一把。看看在vscode中集成进来,方便平时的脚本开发。对于年纪大的人还是非常方便的。 操作过程 安装continue 打开vscode进入扩展市场,搜索安装 安装完成就是上面的样子,会…...

mapbox进阶,添加绘图扩展插件,绘制圆形
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀前言1.1 ☘️mapboxgl.Map 地图对象1.2 ☘️mapboxgl.Map style属性1.3 ☘️MapboxDraw 绘图控件二、🍀添加绘图扩…...

Cursor 与多语言开发:全栈开发的利器
引言 全栈开发要求开发者跨越前端、后端、数据库甚至数据科学等多个技术领域,而不同技术栈往往需要切换工具和思维方式。Cursor 作为一款 AI 驱动的智能编程助手,凭借其对 20 编程语言 和主流框架的深度支持,正在成为全栈开发的“瑞士军刀”…...

2025 CCF BDCI|“基于TPU平台的OCR模型性能优化”一等奖作品
2024年12月,中国计算机学会在海南博鳌成功举办了第十二届CCF大数据与计算智能大赛(简称2024 CCF BDCI)。本届比赛的算能赛道吸引了1748名选手报名,经过激烈角逐,北京航空航天大学的“常务副SOTA”团队脱颖而出…...

FPGA的IP核接口引脚含义-快解
疑问 手册繁琐,怎样快速了解IP核各输入输出接口引脚的含义。 答疑 不慌不慌,手册确实比较详细但繁琐,如何快速知晓该部分信息,涛tao道长给你们说,简单得很,一般新入门的道友有所不知,往往后面…...

数据库高安全—审计追踪:传统审计统一审计
书接上文数据库高安全—角色权限:权限管理&权限检查,从权限管理和权限检查方面解读了高斯数据库的角色权限,本篇将从传统审计和统一审计两方面对高斯数据库的审计追踪技术进行解读。 4 审计追踪 4.1 传统审计 审计内容的记录方式通…...

机器学习 - 需要了解的条件概率、高斯分布、似然函数
似然函数是连接数据与参数的桥梁,通过“数据反推参数”的逆向思维,成为统计推断的核心工具。理解它的关键在于区分“参数固定时数据的概率”与“数据固定时参数的合理性”,这种视角转换是掌握现代统计学和机器学习的基础。 一、在学习似然函…...

Spring Boot Web 入门
目录 Spring Boot Web 是 Spring Boot 框架的一个重要模块,它简化了基于 Spring 的 Web 应用程序的开发过程。以下是一个 Spring Boot Web 项目的入门指南,涵盖了项目创建、代码编写、运行等关键步骤。 1. 项目创建 使用 Spring Initializr 使用 IDE …...

神经网络|(八)概率论基础知识-二项分布及python仿真
【1】引言 前序已经学习了古典概型、条件概率、全概率公式和贝叶斯公式,它们作为基础,解释了事件发生及其概率的对应关系,相关文章链接为: 神经网络|(四)概率论基础知识-古典概型-CSDN博客 神经网络|(五)概率论基础知识-条件概…...

【面试场景】MySQL分布式主键选取
文章目录 一. MySQL的自增主键二. UUID三. 雪花ID(推荐) 我的博客地址 一. MySQL的自增主键 适合单表的情况, 在分布式分库分表下可能会有一些问题 主键冲突问题 在分布式系统中,多个数据库节点独立生成自增主键,很容易出现重复的主键值。例如ÿ…...

执行git stash drop stash@{x} 时出现error: unknown switch `e‘ 的解决方式
原因: 在 PowerShell 或某些 Shell 中,{} 是特殊符号,stash{0} 会被解析成 stash 0,而 后的字符可能被误认为选项(如 -e),使 Git 收到意外的 -e 参数,导致报错 unknown switch ‘e’。 解决方…...

AgentGym:构建标准化AI智能体训练与评估平台的实践指南
1. 项目概述:当AI智能体走进“健身房”最近在开源社区里,一个名为“AgentGym”的项目引起了我的注意。它来自开发者WooooDyy,名字起得很有意思——“智能体健身房”。这可不是让AI去举铁跑步,而是为那些基于大语言模型的智能体提供…...

041二叉树的层序遍历
二叉树的层序遍历 题目链接:https://leetcode.cn/problems/binary-tree-level-order-traversal/description/?envTypestudy-plan-v2&envIdtop-100-liked 我的解答: public List<List<Integer>> levelOrder(TreeNode root) {List<Lis…...

微信网页版访问终极指南:wechat-need-web插件完整教程
微信网页版访问终极指南:wechat-need-web插件完整教程 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为无法在浏览器中使用微信网页版…...

信号净化实战:从基础平滑到智能去噪
1. 信号净化入门:为什么我们需要处理噪声? 第一次接触传感器数据时,我被现实狠狠上了一课——实验室里漂亮的平滑曲线在真实场景中根本不存在。记得去年处理工厂振动传感器数据时,原始信号看起来就像心电图叠加了摇滚乐节奏。这种…...

自动驾驶-数据解析01:四元数04【nuPlan 数据集中的 ego2global_rotation 四元数是采集时生成的,还是后期处理得到的?】
标题:nuPlan 数据集中的 ego2global_rotation 四元数是采集时生成的,还是后期处理得到的? 1. 先给结论 在讨论 nuPlan 数据集中的自车姿态四元数时,不能简单地说: 它一定是车辆采集瞬间直接生成的原始四元数。也不能简单地说: 它是后期人工标注生成的四元数。更准确的…...

3分钟看懂无人机飞行日志:免费在线工具让数据说话
3分钟看懂无人机飞行日志:免费在线工具让数据说话 【免费下载链接】UAVLogViewer An online viewer for UAV log files 项目地址: https://gitcode.com/gh_mirrors/ua/UAVLogViewer 还在为看不懂无人机飞行日志而烦恼吗?那些密密麻麻的数据、复杂…...

开源、有文档、能上线的 .NET + Vue 通用权限系统
前言在日常项目开发中,权限管理几乎是每个系统都绕不开的基础模块。从用户登录、菜单控制到数据隔离,一套稳定、灵活、可扩展的权限体系,往往决定了整个项目的成败。然而,从零开始搭建这样的平台,不仅耗时耗力…...

基于Council框架的多智能体协作:构建专家委员会式AI决策系统
1. 项目概述:一个智能化的团队决策引擎最近在开源社区里看到一个挺有意思的项目,叫“Cat-tj/council-tj”。这个名字乍一看有点抽象,但拆开来看,“Council”在英文里是“议会”或“委员会”的意思,而“tj”通常是“Tav…...

Rust服务脚手架:快速构建生产级微服务的标准化起点
1. 项目概述:为什么我们需要一个Rust服务脚手架?在当今的微服务与云原生架构浪潮中,快速启动一个健壮、可维护的后端服务是每个开发团队的核心诉求。如果你和我一样,厌倦了每次开启新项目时,都要重复搭建项目结构、配置…...

Java笔记——Java 初识_java 版本历史
Java笔记——Java 初识_java 版本历史 Java 的发展历程 Sun 公司:Stanford University Network,斯坦福大学网络公司。 Oracle 公司。2004 年发布 Java 5.0,2014 年发布 Java 8,从 Java 9 开始每 6 个月发布一次 Java。 其实&#…...