【大数据技术】用户行为日志分析(python+hadoop+mapreduce+yarn+hive)
用户行为日志分析(python+hadoop+mapreduce+yarn+hive)
-
搭建完全分布式高可用大数据集群(VMware+CentOS+FinalShell)
-
搭建完全分布式高可用大数据集群(Hadoop+MapReduce+Yarn)
-
本机PyCharm远程连接虚拟机Python
-
搭建完全分布式高可用大数据集群(MySQL+Hive)
-
本机DataGrip远程连接虚拟机MySQL/Hive
在阅读本文前,请确保已经阅读过以上5篇文章,成功搭建了Hadoop+MapReduce+Yarn+Python+Hive的大数据集群环境。
写在前面
本文主要介绍基于mapreduce+hive技术,自己编写python代码实现用户行为日志分析的详细步骤。
-
电脑系统:
Windows -
技术需求:
Hadoop、MapReduce、Yarn、Python3.12.8、Hive -
使用软件:
VMware、FinalShell、PyCharm、DataGrip
注:本文的所有操作均在虚拟机master中进行,不涉及另外两台虚拟机。(但是要开机)
启动Hadoop
-
使用finalshell连接并启动
master、slave01、slave02三台虚拟机。 -
在虚拟机
master的终端输入命令start-all.sh启动hadoop、mapreduce和yarn。 -
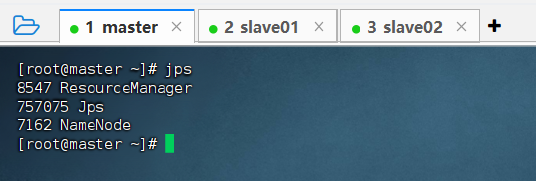
随后可以用命令
jps查看是否成功启动集群。
启动历史服务器
- 在
master的终端输入命令mr-jobhistory-daemon.sh start historyserver启动历史服务器。
- 历史服务器可以在mapreduce出错时查看报错原因。
- 如果不启动该历史服务器,则无法使用web页面(http://master:19888/jobhistory)查看mapreduce程序的运行状态。
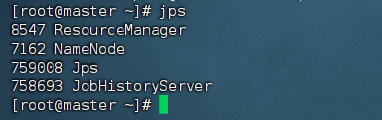
- 输入
jps查看历史服务器是否成功启动。
准备数据
- 创建文本数据
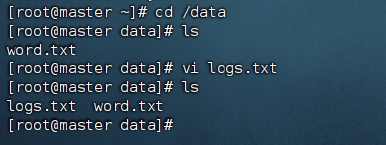
① 在虚拟机master的终端输入命令cd /data进入/data目录。
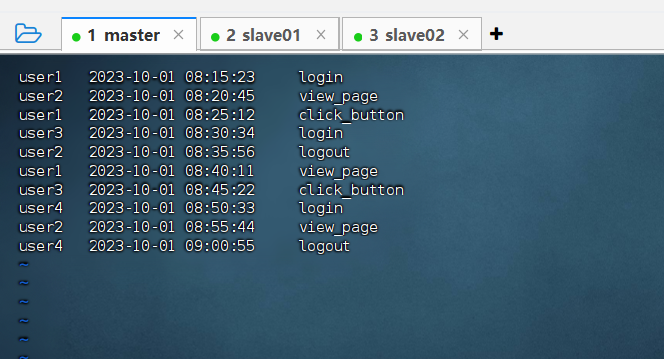
② 在虚拟机master的终端输入命令 vi logs.txt 创建并打开logs.txt文件,填入以下内容。
user1 2023-10-01 08:15:23 login
user2 2023-10-01 08:20:45 view_page
user1 2023-10-01 08:25:12 click_button
user3 2023-10-01 08:30:34 login
user2 2023-10-01 08:35:56 logout
user1 2023-10-01 08:40:11 view_page
user3 2023-10-01 08:45:22 click_button
user4 2023-10-01 08:50:33 login
user2 2023-10-01 08:55:44 view_page
user4 2023-10-01 09:00:55 logout
数据说明
user_id: 用户唯一标识。log_time: 日志时间,格式为YYYY-MM-DD HH:MM:SS。action: 用户执行的操作,例如login、logout、view_page、click_button等。
数据示例
user1在2023-10-01 08:15:23登录。user2在2023-10-01 08:20:45浏览页面。user1在2023-10-01 08:25:12点击按钮。user3在2023-10-01 08:30:34登录。user2在2023-10-01 08:35:56登出。user1在2023-10-01 08:40:11再次浏览页面。user3在2023-10-01 08:45:22点击按钮。user4在2023-10-01 08:50:33登录。user2在2023-10-01 08:55:44再次浏览页面。user4在2023-10-01 09:00:55登出。
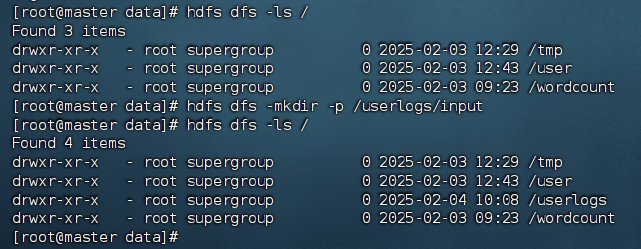
- 创建目录
① 在终端输入以下命令,可以在HDFS中创建/userlogs/input目录,用于存放文件logs.txt。
hdfs dfs -mkdir -p /userlogs/input
② 在终端输入以下命令验证是否创建/userlogs/input目录。
hdfs dfs -ls /
- 上传文件
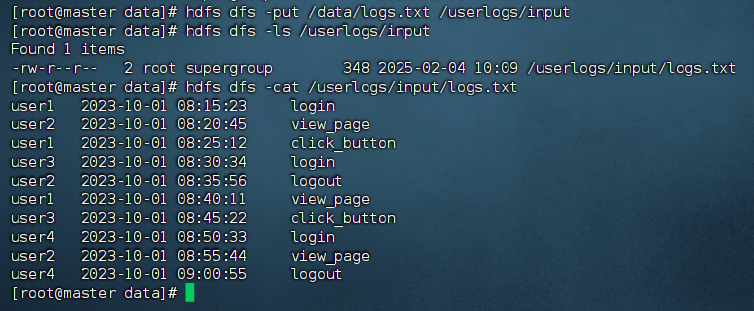
① 在终端执行以下命令将文件logs.txt上传到HDFS的/userlogs/input目录。
hdfs dfs -put /data/logs.txt /userlogs/input
② 在终端输入以下命令验证是否成功将文件logs.txt上传到HDFS的/userlogs/input目录。
hdfs dfs -ls /userlogs/input
③ 可以使用以下命令查看上传的logs.txt文件的内容。
hdfs dfs -cat /userlogs/input/logs.txt
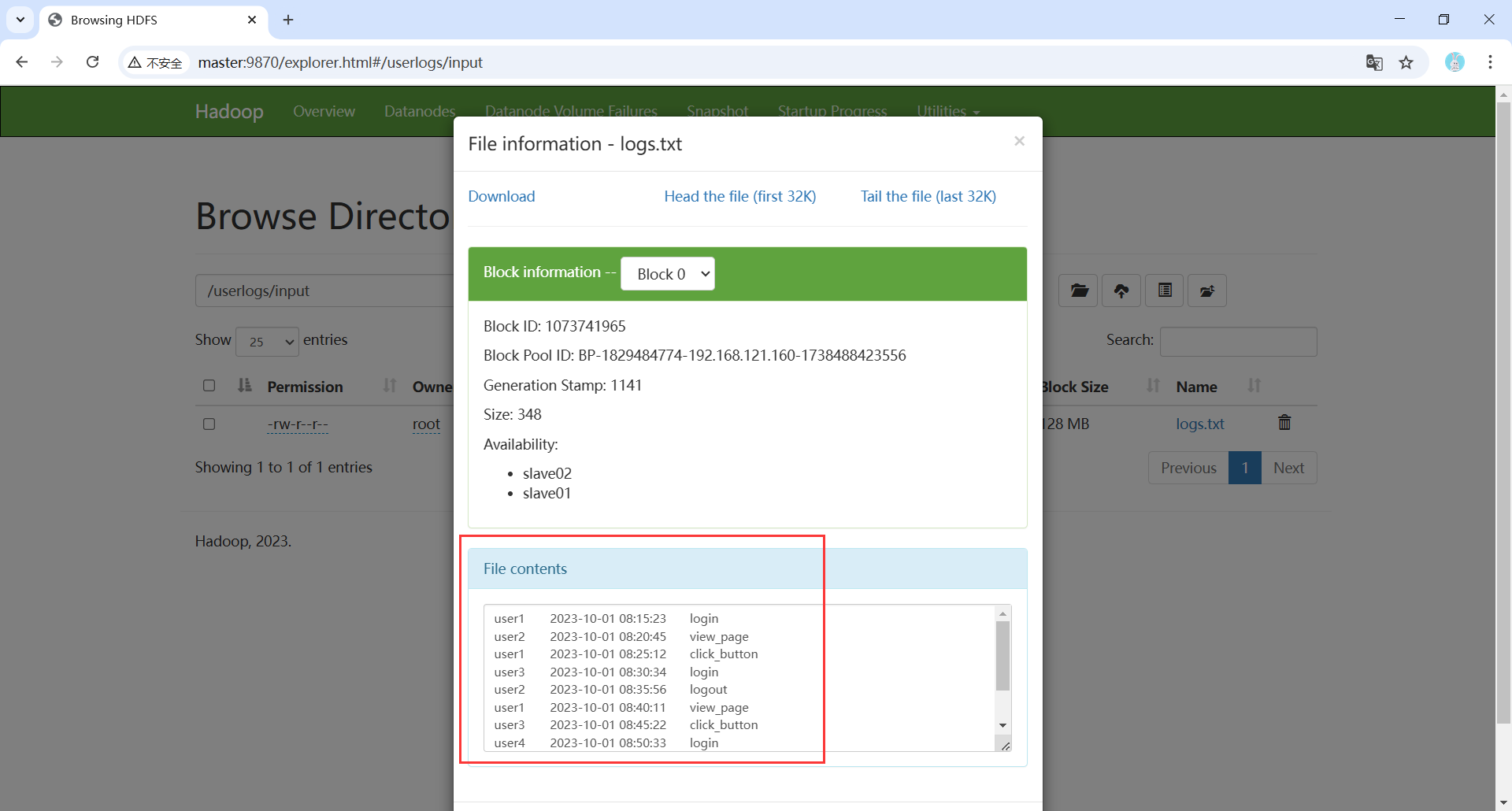
④ 也可以通过HDFS的Web UI(http://master:9870)查看文件logs.txt是否上传成功。
编写Python脚本
打开PyCharm专业版,远程连接虚拟机master,先创建一个文件夹userlogs,后在该文件夹中分别创建map.py和reduce.py两个脚本。
1. 编写mapper脚本map.py
在map.py脚本中填入以下代码。
import sysfor line in sys.stdin:# 假设输入的每一行是Hive表中的一行数据user_id, log_time, action = line.strip().split('\t')# 输出 user_id 和 actionprint(f"{user_id}\t{action}")
这段代码是一个典型的 MapReduce Mapper 脚本,用 Python 编写,用于处理从 Hive 表或 HDFS 文件中读取的日志数据。,以下是对代码的详细分析。
-
读取输入数据:
- 通过
sys.stdin逐行读取输入数据。输入数据通常来自 Hadoop Streaming 的输入文件(如 Hive 表导出文件或 HDFS 文件)。 - 每行数据的格式为
user_id\tlog_time\taction,例如:user1\t2023-10-01 08:15:23\tlogin。
- 通过
-
数据解析:
- 使用
line.strip().split('\t')对每行数据进行解析:strip():去除行首尾的空白字符(如换行符)。split('\t'):以制表符(\t)为分隔符,将行数据拆分为user_id、log_time和action三个字段。
- 使用
-
输出结果:
- 使用
print(f"{user_id}\t{action}")输出user_id和action,中间用制表符分隔。 - 输出格式为
user_id\taction,例如:user1\tlogin。
- 使用
总的来说,这段代码是一个简单但功能明确的 Mapper 脚本,适用于从结构化日志数据中提取关键字段并生成中间结果。通过优化异常处理和性能,可以使其更加健壮和高效。
2. 编写reducer脚本reduce.py
在reduce.py脚本中填入以下代码。
import sys
from collections import defaultdictaction_count = defaultdict(int)for line in sys.stdin:user_id, action = line.strip().split('\t')action_count[(user_id, action)] += 1for (user_id, action), count in action_count.items():print(f"{user_id}\t{action}\t{count}")
这段代码是一个典型的 MapReduce Reducer 脚本,用 Python 编写,用于对 Mapper 输出的中间结果进行聚合统计,以下是对代码的详细分析。
-
读取输入数据:
- 通过
sys.stdin逐行读取 Mapper 输出的中间结果,每行数据的格式为user_id\taction,例如:user1\tlogin。
- 通过
-
数据统计:
- 使用
defaultdict(int)创建一个字典action_count,用于统计每个(user_id, action)组合的出现次数。 - 对每行数据解析后,将
(user_id, action)作为键,累加其计数:action_count[(user_id, action)] += 1。
- 使用
-
输出结果:
- 遍历
action_count字典,输出每个(user_id, action)组合及其出现次数,格式为user_id\taction\tcount,例如:user1\tlogin\t3。
- 遍历
这段代码是一个简单但功能明确的 Reducer 脚本,适用于对 Mapper 输出的中间结果进行聚合统计。通过优化异常处理和性能,可以使其更加健壮和高效。
运行MapReduce程序
- 查看
mapreduce程序
进入虚拟机master的/opt/hadoop/share/hadoop/tools/lib目录,在该目录下执行ls命令,查看hadoop提供的mapreduce程序。
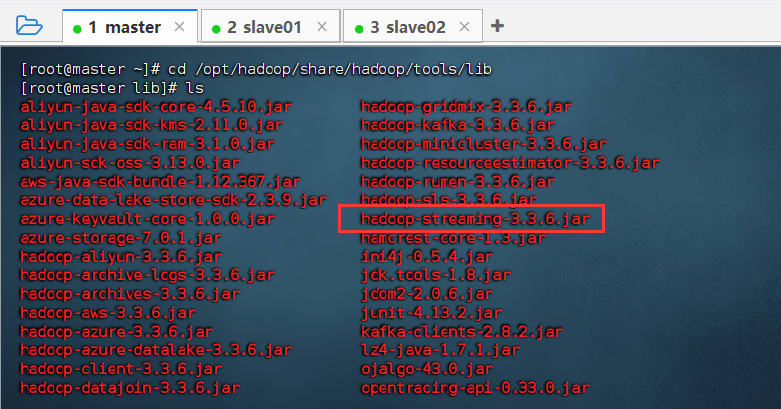
其中,hadoop-streaming-3.3.6.jar是执行mapreduce的程序。
- 执行
mapreduce程序
① 在终端输入命令cd /opt/python/code/userlogs进入存放map.py和reduce.py脚本的目录。

② 执行以下命令,统计logs.txt文件中的用户行为。
hadoop jar /opt/hadoop/share/hadoop/tools/lib/hadoop-streaming-3.3.6.jar -file map.py -file reduce.py -input /userlogs/input/logs.txt -output /userlogs/output -mapper "python map.py" -reducer "python reduce.py"
注意: 在每次执行这个命令前,请确保/userlogs/output的output文件夹不在HDFS中,如果在,请删除。
③ 出现以下信息说明程序执行成功。
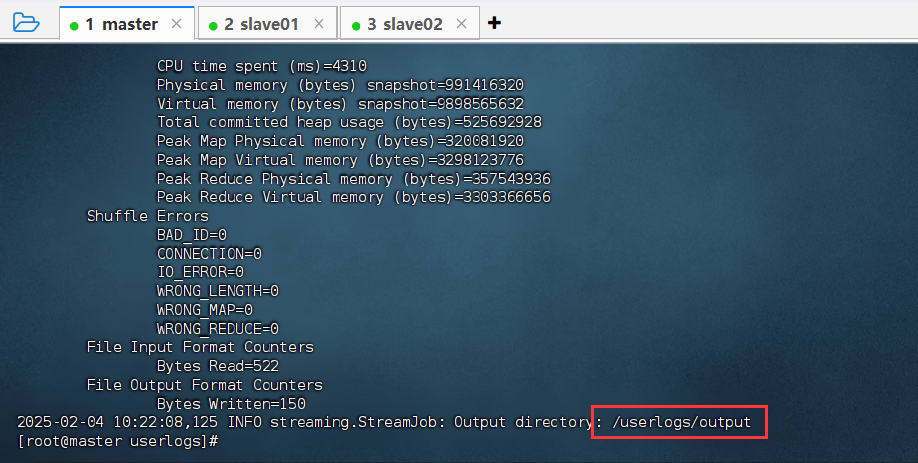
查看程序运行状态和结果
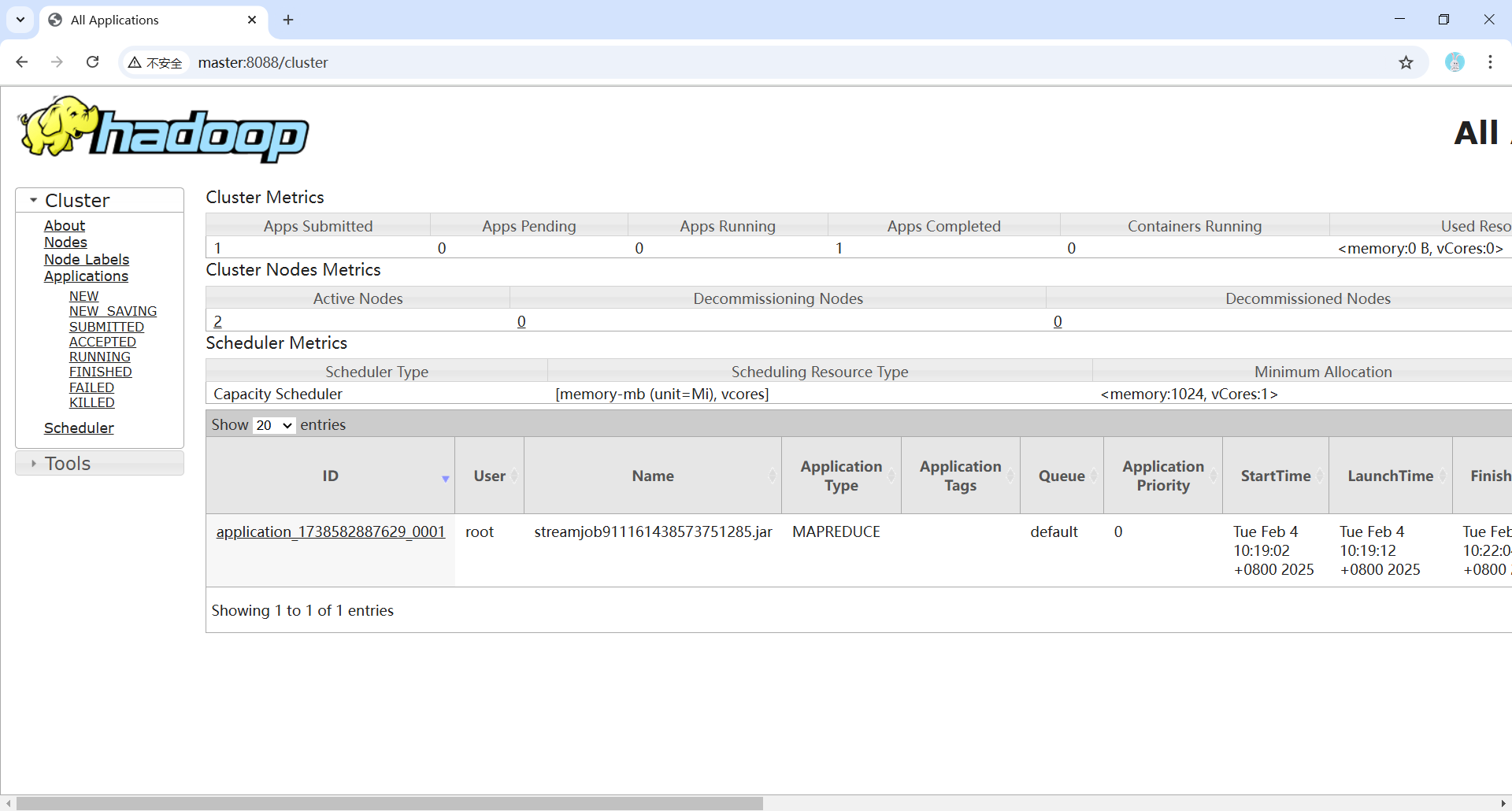
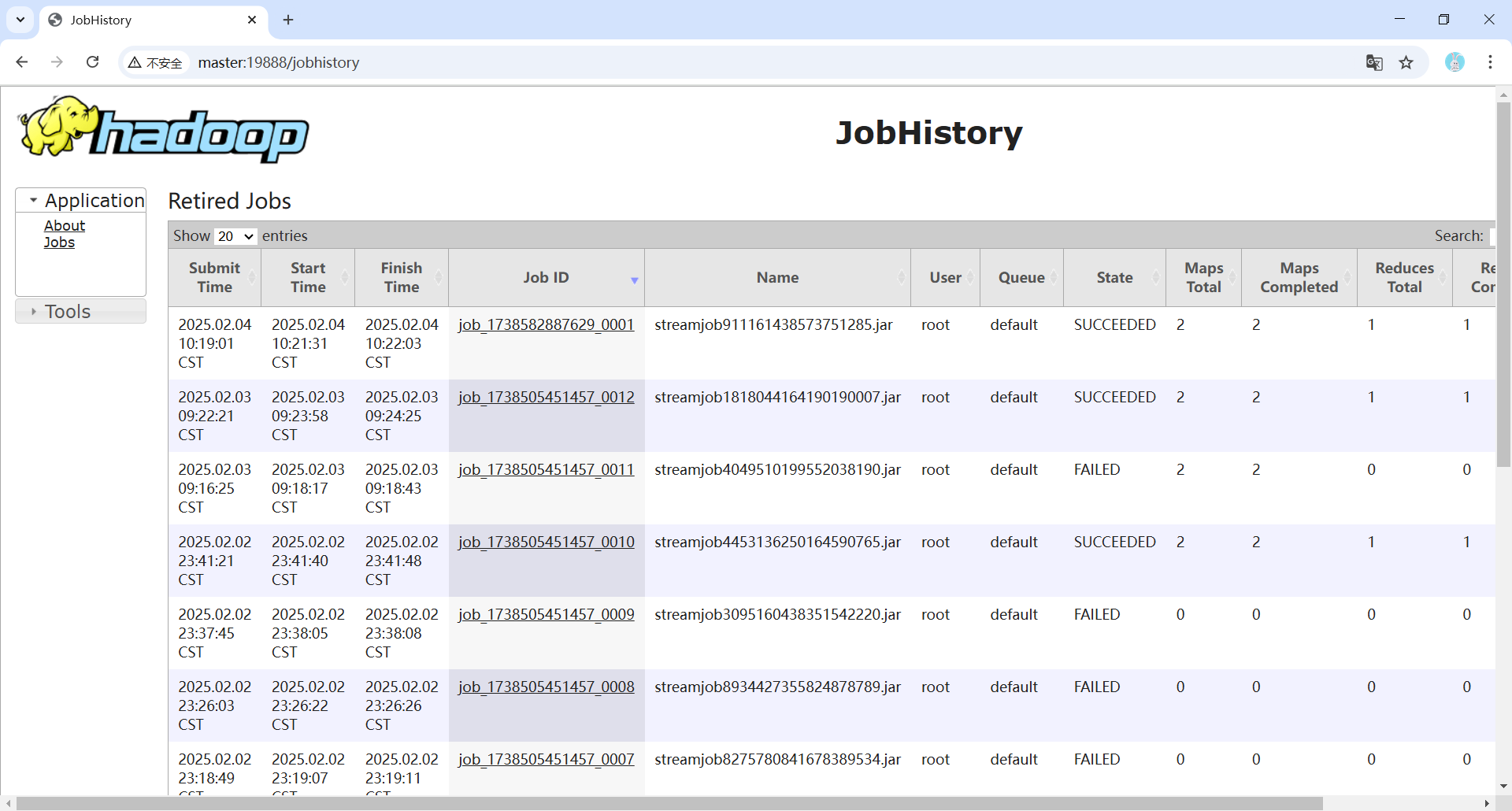
- MapReduce程序运行过程中,可以使用浏览器访问Web UI(http://master:8088)查看历史服务器。
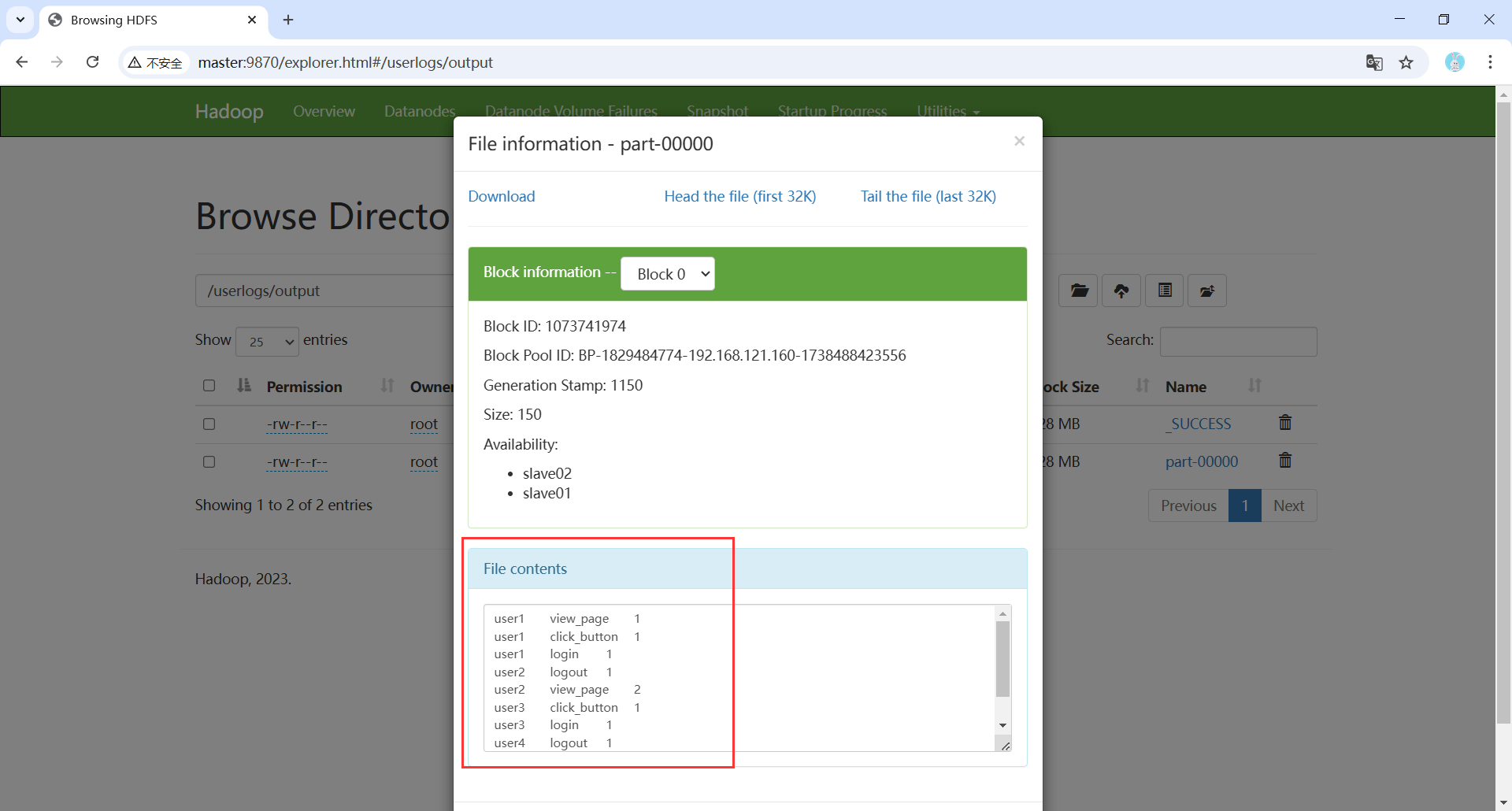
- MapReduce程序运行结束后,可以在HDFS的Web UI(http://master:9870)查看用户行为日志的统计的结果。
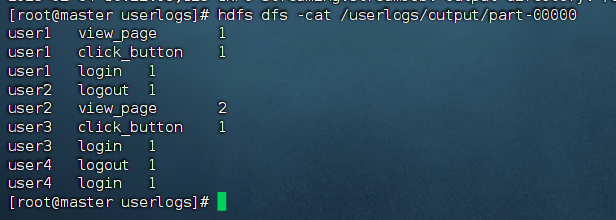
- 当然,也可以在
master的终端输入以下命令查看程序运行结果。
hdfs dfs -cat /userlogs/output/part-00000
注意: 如果在运行mapreduce程序时出现错误,可以使用浏览器访问Web UI(http://master:19888/jobhistory)查看历史服务器的logs文件。
将结果存入Hive
在虚拟机中启动Hive,打开DataGrip,远程连接虚拟机的hive。
① 启动hiveserver2服务:hive --service hiveserver2(第一个master终端)
② 启动beeline连接:beeline -u jdbc:hive2://master:10000 -n root(第三个master终端)
③ 使用DataGrip远程连接Hive
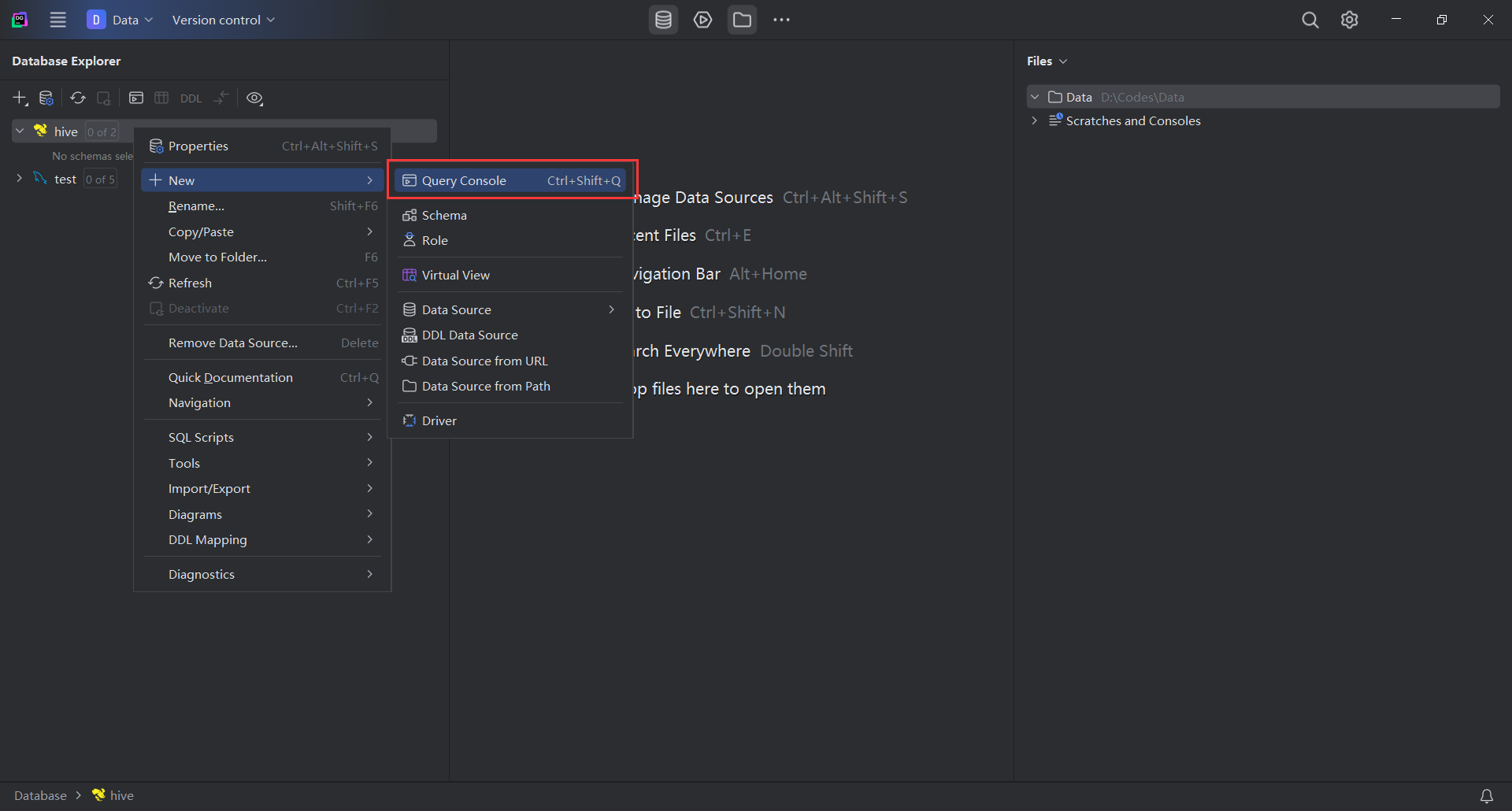
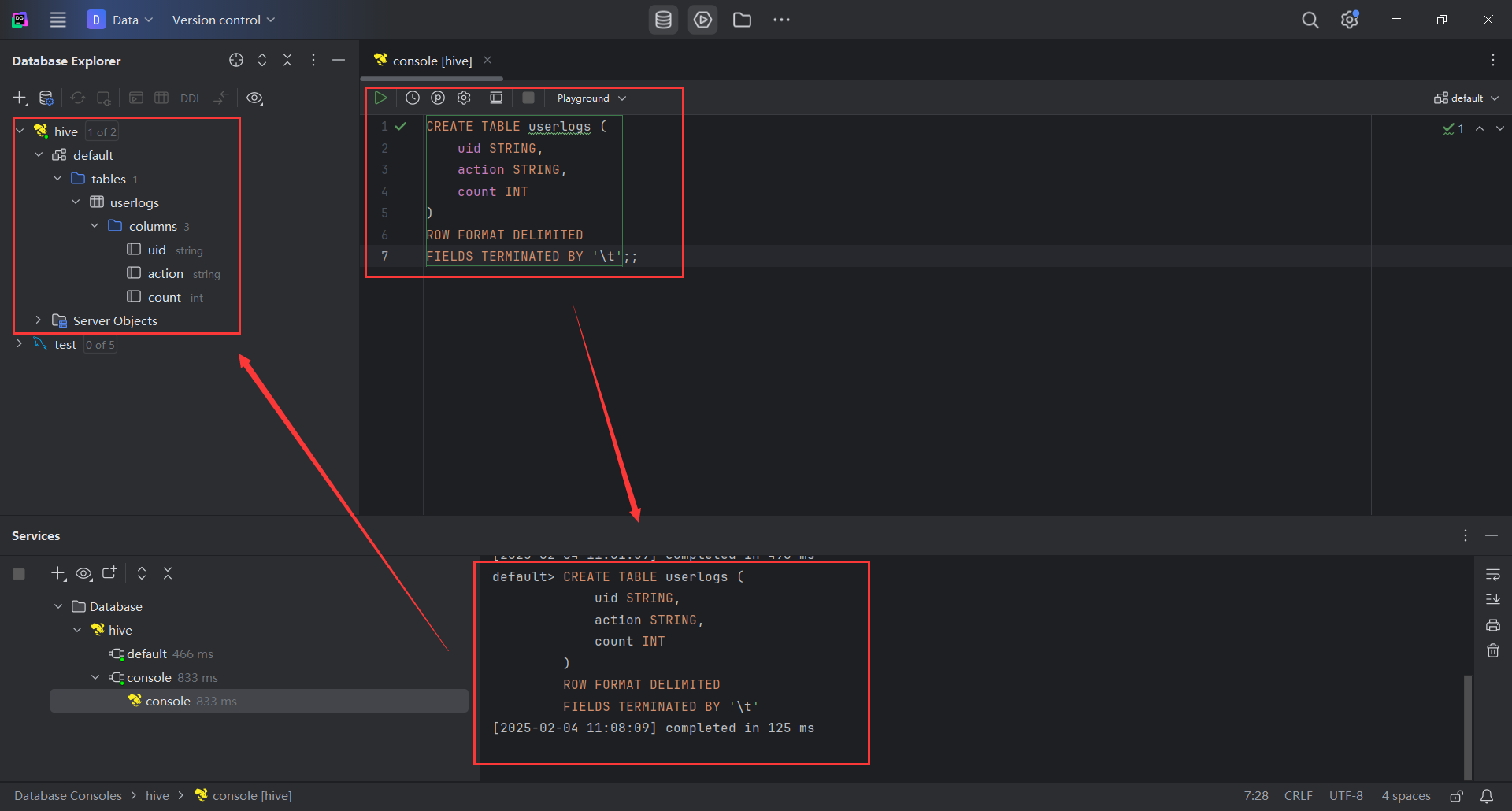
- 打开
DataGrip的Query Console,输入以下代码,创建一个名为userlogs的Hive表。
CREATE TABLE userlogs (uid STRING,action STRING,count INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
这段 SQL 语句用于在 Hive 中创建一个表 userlogs,让我们逐部分分析这段 SQL语句。
-
CREATE TABLE userlogs (...)-
CREATE TABLE userlogs: 这部分表示创建一个名为userlogs的表。 -
(...): 括号内定义了表的列名和数据类型。这里定义了 3 列。
-
-
列定义
-
uid STRING: 第一列是uid,数据类型是STRING。这里假设存储的是用户标识符(如user1、user2等)。STRING类型可以存储任意文本数据。 -
action STRING: 第二列是action,数据类型也是STRING。它表示用户的操作类型(如view_page、click_button、Login等)。 -
count INT: 第三列是count,数据类型是INT,表示操作的计数或频率(如1、2等)。
-
-
ROW FORMAT DELIMITED- 这部分表示数据的存储格式是 定界符分隔的 。在 Hive 中,
ROW FORMAT DELIMITED表示数据以某种字符(比如制表符、逗号等)分隔。
- 这部分表示数据的存储格式是 定界符分隔的 。在 Hive 中,
-
FIELDS TERMINATED BY '\t'FIELDS TERMINATED BY '\t': 这部分指定了字段之间使用制表符(\t)作为分隔符,也就是每列的值通过制表符分隔。这样,Hive 就知道如何解析存储在文件中的数据。
总的来说,这段 SQL 语句的功能是创建一个 userlogs 表,表中有三列:uid(用户标识符)、action(用户执行的操作)、count(操作次数)。每行数据的字段由制表符 \t 分隔,且表采用 定界符分隔 的存储格式。
这个表结构适用于存储类似于以下数据的记录:
user1 view_page 1
user1 click_button 1
user1 Login 1
user2 logout 1
user2 view_page 2
...
注意:该userlogs表默认创建在default数据库中。
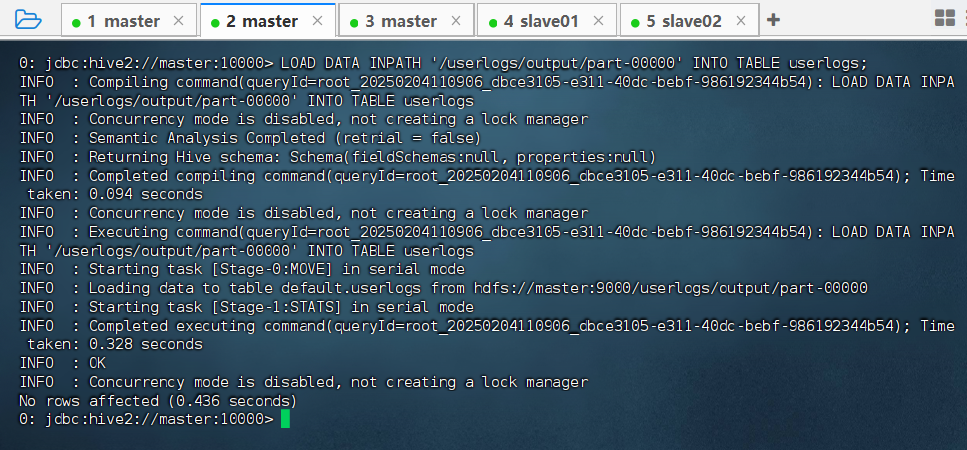
- 在
beeline命令行入以下命令,将mapreduce的输出加载到Hive的userlogs表中。
LOAD DATA INPATH '/userlogs/output/part-00000' INTO TABLE userlogs;
- 在DataGrip中查看
uselogs数据表中的数据。
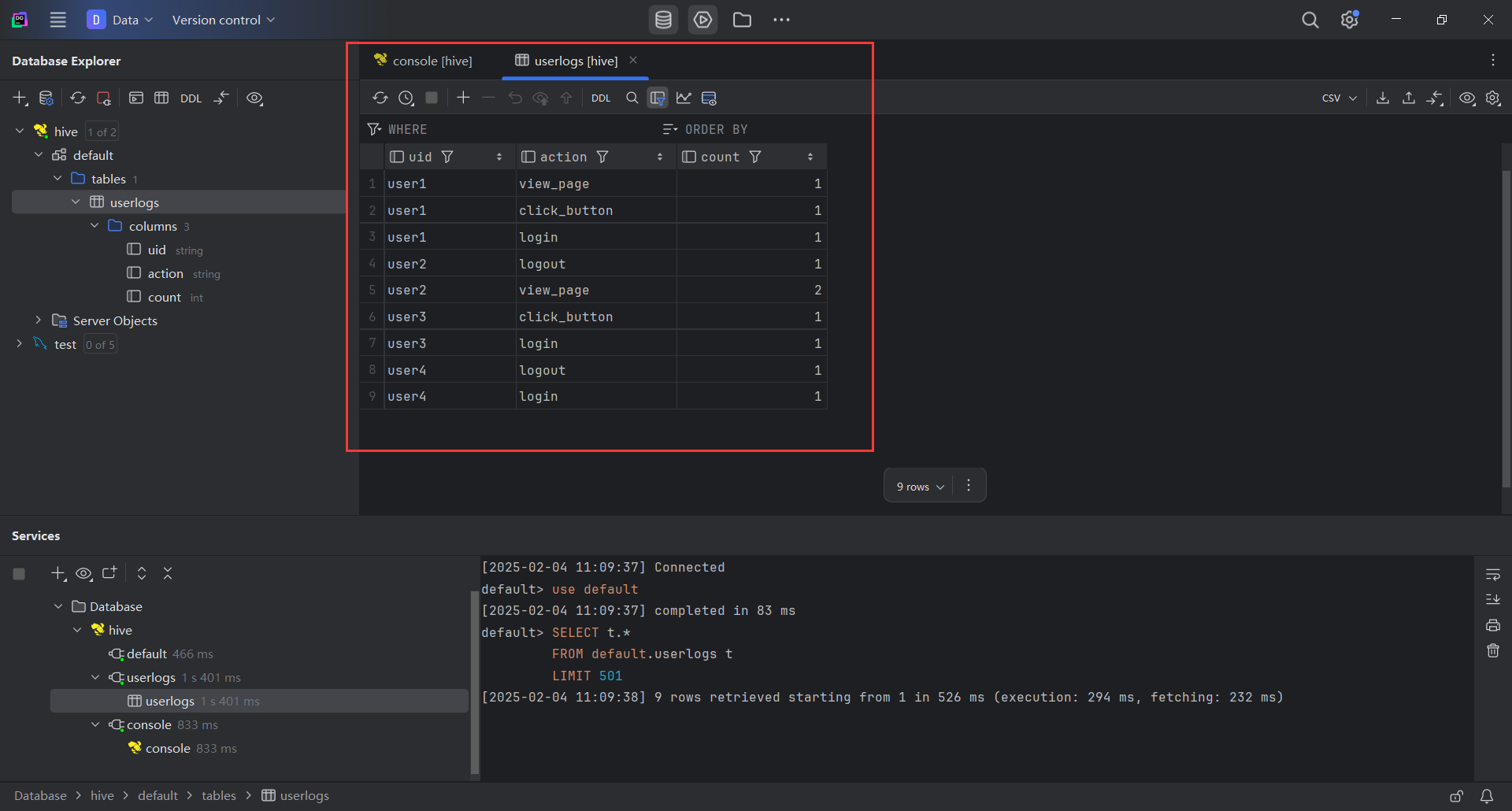
- 在
beeline使用SELECT * FROM userlogs LIMIT 10;命令查看数据信息。
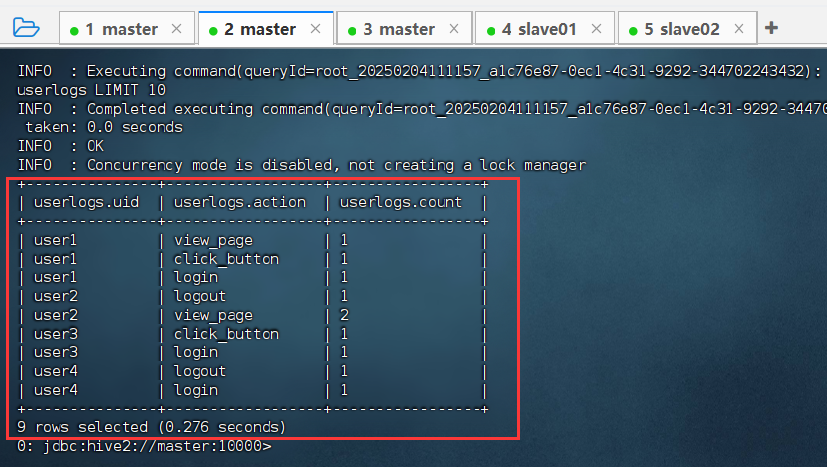
到此,成功将mapreduce的执行结果存入了hive的default数据库的userlogs数据表中。
注意事项
- 执行
LOAD DATA INPATH '/userlogs/output/part-00000' INTO TABLE userlogs;命令后,在HDFS中的part-00000文件将被移动至Hive中。
- 启动HiveServer2服务后,可以访问Web UI(http://master:10002/)查看Hive信息。

写在后面
本文仅供学习使用,原创文章,请勿转载,谢谢配合。
相关文章:
【大数据技术】用户行为日志分析(python+hadoop+mapreduce+yarn+hive)
用户行为日志分析(pythonhadoopmapreduceyarnhive) 搭建完全分布式高可用大数据集群(VMwareCentOSFinalShell) 搭建完全分布式高可用大数据集群(HadoopMapReduceYarn) 本机PyCharm远程连接虚拟机Python …...

[Day 16]螺旋遍历二维数组
今天我们看一下力扣上的这个题目:146.螺旋遍历二维数组 题目描述: 给定一个二维数组 array,请返回「螺旋遍历」该数组的结果。 螺旋遍历:从左上角开始,按照 向右、向下、向左、向上 的顺序 依次 提取元素,…...
大模型的底层逻辑及Transformer架构
一、大模型的底层逻辑 1.数据驱动 大模型依赖海量的数据进行训练,数据的质量和数量直接影响模型的性能。通过大量的数据,模型能够学习到丰富的模式和规律,从而更好地处理各种任务。 2.深度学习架构 大模型基于深度学习技术,通常采用多层神经网络进行特征学习与抽象。其中…...

数据结构-基础
1、概念: 程序 数据结构 算法 2、程序的好坏 可读性,稳定性,扩展性,时间复杂度,空间复杂度。 3、数据结构 是指存储、组织数据的方式,以便高效地进行访问和修改。通过选择适当的数据结构, 能…...

SystemUI中NavigationBar分析
需求 SystemUI是一个与系统组件显示紧密相关的应用,包含快捷中心、消息通知、状态栏、导航栏、任务中心等诸多模块,本文介绍NavigationBar模块。SystemUI源码位于/frameworks/base/packages/SystemUI,Android13平台。NavigationBar显示如下&…...

MySQL的底层原理与架构
前言 了解MySQL的架构和原理对于很多的后续很多的操作会有很大的帮助与理解。并且很多知识都与底层架构相关联。 了解MySQL架构 通过上面的架构图可以得知,Server层中主要由 连接器、查询缓存、解析器/分析器、优化器、执行器 几部分组成的,下面将主要…...

三极管的截止、放大、饱和区
三极管的几个区,都有什么用: 截止区:晶体管不导通,用于开关电路的“关”状态。 放大区:晶体管用于信号放大,集电极电流与基极电流成正比。 饱和区:晶体管完全导通,用于开关电路的“…...
 动态规划-习题1 300.最长递增子序列)
2025-2-7-算法学习(一) 动态规划-习题1 300.最长递增子序列
文章目录 算法学习(一) 动态规划-习题1 300.最长递增子序列(1)题目(2)举例:(3)提示(4)分析(5)动态规划代码:&a…...

学习日记-250207
一.论文 1.Prompt Learning for News Recommendation 任务不一致(LLM与实际任务)产生prompt提示。 Prompt Learning for News Recommendation 论文阅读 SIGIR2023-CSDN博客 2.GPT4Rec: A Generative Framework for Personalized Recommendation and…...

【Block总结】PSA,金字塔挤压注意力,解决传统注意力机制在捕获多尺度特征时的局限性
论文信息 标题: EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network论文链接: arXivGitHub链接: https://github.com/murufeng/EPSANet 创新点 EPSANet提出了一种新颖的金字塔挤压注意力(PSA)模块,旨…...

代码随想录算法训练营第三十一天| 回溯算法04
491. 递增子序列 题目: 代码随想录 视频讲解:回溯算法精讲,树层去重与树枝去重 | LeetCode:491.递增子序列_哔哩哔哩_bilibili 这题需要注意的点: 1. path长度在2以上才放入最终结果 2. 需要记录已经使用过的数字&am…...

pycharm集成通义灵码应用
在pycharm中安装通义灵码 1、打开files-settings 2、选中plugins-搜索”TONGYI Lingma“,点击安装 3.安装完成后在pycharm的右侧就有通义灵码的标签 4、登录账号 5、查看代码区域代码,每一个方法前面都多了通义灵码的标识,可以直接选择…...

赛博算命之 ”梅花易数“ 的 “JAVA“ 实现 ——从玄学到科学的探索
hello~朋友们!好久不见! 今天给大家带来赛博算命第三期——梅花易数的java实现 赛博算命系列文章: 周易六十四卦 掐指一算——小六壬 更多优质文章:个人主页 JAVA系列:JAVA 大佬们互三哦~互三必回!…...

【Leetcode刷题记录】54. 螺旋矩阵--模拟,以及循环条件处理的一些细节
54. 螺旋矩阵 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 示例 1: 输入:matrix [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5] 解题思路 顺时针螺旋顺序也就是“从左向…...

c++计算机教程
目的 做出-*/%计算机 要求 做出可以计算-*/%的计算机 实现 完整代码 #include<bits/stdc.h> int main() {std::cout<<"加 减- 乘* 除/ 取余% \没有了|(因为可以算三位)"<<"\n"<<"提示:每打完一个符号或打完一个数,\…...

蓝桥杯Java之输入输出练习题
题目 1:多组AB(基础版) 题目描述: 输入多组数据,每组数据包含两个整数 A 和 B,计算它们的和。输入以 文件结尾(EOF) 结束。 输入格式: 每行包含两个整数 A 和 B&#x…...

【R语言】环境空间
一、环境空间的特点 环境空间是一种特殊类型的变量,它可以像其它变量一样被分配和操作,还可以以参数的形式传递给函数。 R语言中环境空间具有如下3个特点: 1、对象名称唯一性 此特点指的是在不同的环境空间中可以有同名的变量出现&#x…...

【系统架构设计师】分布式数据库透明性
目录 1. 说明2. 分片透明3. 复制透明4. 位置透明5. 逻辑透明(局部数据模型透明)6.例题6.1 例题1 1. 说明 1.在分布式数据库系统中,分片透明、复制透明、位置透明和逻辑透明是几个重要的基本概念。2.分片透明、复制透明、位置透明和逻辑透明是…...

openpnp2.2 - 环境搭建 - 编译 + 调试 + 打包
文章目录 openpnp2.2 - 环境搭建 - 编译 调试 打包概述笔记前置任务克隆代码库切到最新的tag清理干净编译工程关掉旧工程打开已经克隆好的openpnp2.2工程将IDEA的SDK配置为openjdk23 切换中英文UI设置JAVA编译器 构建工程跑测试用例单步调试下断点导出工程的JAR包安装install…...

OpenCV:图像修复
目录 简述 1. 原理说明 1.1 Navier-Stokes方法(INPAINT_NS) 1.2 快速行进方法(INPAINT_TELEA) 2. 实现步骤 2.1 输入图像和掩膜(Mask) 2.2 调用cv2.inpaint()函数 2.3 完整代码示例 2.4 运行结果 …...

用Monster M4SK打造可穿戴互动眼睛:从硬件拆解到凯皮帽子制作
1. 项目概述:当马里奥的帽子“活”了过来如果你和我一样,既是任天堂游戏的粉丝,又对嵌入式硬件和可穿戴设备着迷,那么把游戏里的角色带到现实中来,绝对是一件充满乐趣的事。这次我们要“复活”的,是《超级马…...
CircuitPython实战:用传感器数据驱动NeoPixel灯光效果
1. 项目概述如果你刚拿到一块像Adafruit Circuit Playground Express这样的开发板,看着上面一圈彩色的NeoPixel LED和一堆传感器,可能会有点无从下手。别担心,这几乎是每个嵌入式开发者的必经之路。这块板子集成了光传感器、温度传感器、加速…...

架构设计实战指南:在约束中做取舍的工程智慧
架构设计实战指南:在约束中做取舍的工程智慧 版本:V1.0 适合人群:开发工程师、架构师、技术负责人、CTO、技术出身的创业者写在前面:你是不是也遇到过这些问题? 如果你是开发工程师: 刚写完的代码ÿ…...

C++内存可视化利器:silicondawn/memory-viewer库实战指南
1. 项目概述与核心价值最近在调试一个涉及复杂内存操作的C项目时,我又一次陷入了“内存黑盒”的困境。指针指向的数据结构到底对不对?序列化后的字节流里某个字段的值是不是我预期的?手动printf或者断点查看十六进制,效率低不说&a…...

ASCII艺术乱码修复:ascii-fix工具解决终端编码兼容性问题
1. 项目概述:当字符艺术遇上编码乱码如果你经常在终端里折腾,或者喜欢用命令行工具处理文本,那你肯定遇到过这种情况:一个精心设计的ASCII艺术Logo,或者一个结构清晰的表格,在某个终端或编辑器里打开时&…...

2026 最新 6 款漏洞扫描工具!一篇全覆盖
渗透测试收集信息完成后,就要根据所收集的信息,扫描目标站点可能存在的漏洞了,包括我们之前提到过的如:SQL注入漏洞、跨站脚本漏洞、文件上传漏洞、文件包含漏洞及命令执行漏洞等,通过这些已知的漏洞,来寻找…...

ARMv8 PMU架构与性能监控实战指南
1. ARMv8 PMU架构深度解析在ARMv8架构中,性能监控单元(Performance Monitor Unit, PMU)是处理器微架构层面的重要组件,它为开发者提供了硬件级别的性能数据采集能力。不同于传统的软件性能分析工具,PMU通过专用寄存器直接监控处理器内部事件&…...

DHCP 实验总结:类比“停车场取卡机”模式
企业导师换一个生活里更常见的场景:停车场入口的自动取卡机。你听完会发现,DHCP 就是网络世界的“自动取卡机”。一、生活比喻(停车场取卡全过程)想象你开车进入一个大型停车场:到达入口,按下取卡按钮&…...

当AI的键值记忆遇上大脑:原来我们和AI共享同一套记忆逻辑
导语在日常经验中,我们常把“遗忘”理解为信息的流失:时间久了,记忆就会慢慢消失;学习新知识,也可能覆盖旧内容。然而,从短视频推荐到大语言模型,再到人类被线索唤醒的记忆体验,这些…...

从Referrer Policy入手:剖析Chrome中strict-origin-when-cross-origin对POST请求的拦截与应对
1. 当POST请求突然"沉默":一个前端开发者的困惑 最近在调试一个前后端分离项目时,我遇到了一个诡异的现象:前端代码明明成功调用了后端接口,但响应数据却始终为空。打开Chrome开发者工具,控制台里赫然显示着…...