【论文翻译】DeepSeek-V3论文翻译——DeepSeek-V3 Technical Report——第一部分:引言与模型架构
论文原文链接:DeepSeek-V3/DeepSeek_V3.pdf at main · deepseek-ai/DeepSeek-V3 · GitHub
特别声明,本文不做任何商业用途,仅作为个人学习相关论文的翻译记录。本文对原文内容直译,一切以论文原文内容为准,对原文作者表示最大的敬意。如有任何侵权请联系我下架相关文章。
目录
DeepSeek-V3 技术报告
摘要
1. 引言
2. 架构
2.1. 基本架构
2.1.1. 多头潜在注意力
2.1.2. 无辅助损失负载均衡的 DeepSeekMoE
2.2 多标记预测
DeepSeek-V3 技术报告
摘要
我们提出了 DeepSeek-V3,这是一种强大的专家混合(MoE)语言模型,总参数量为 6710 亿,其中每个 token 仅激活 370 亿参数。为了实现高效推理和成本效益高的训练,DeepSeek-V3 采用了多头潜在注意力(MLA)和 DeepSeekMoE 结构,这些结构在 DeepSeek-V2 中已得到充分验证。此外,DeepSeek-V3 首次引入了一种无辅助损失的负载均衡策略,并设定了多 token 预测训练目标,以实现更强的性能。我们在 14.8 万亿个多样化且高质量的 token 上对 DeepSeek-V3 进行了预训练,随后通过监督微调和强化学习阶段充分发挥其能力。全面评估表明,DeepSeek-V3 的性能优于其他开源模型,并达到了与领先的闭源模型相当的水平。尽管性能卓越,DeepSeek-V3 的完整训练仅需 278.8 万 H800 GPU 小时。此外,其训练过程异常稳定。在整个训练过程中,我们未曾遇到不可恢复的损失峰值,也未进行任何回滚。模型检查点可在以下地址获取:GitHub - deepseek-ai/DeepSeek-V3

图 1 | DeepSeek-V3 及其对比模型的基准测试性能。
1. 引言
近年来,大型语言模型(LLMs)正经历快速迭代和演进(Anthropic, 2024; Google, 2024; OpenAI, 2024a),逐步缩小与人工通用智能(AGI)之间的差距。除了闭源模型之外,开源模型(包括 DeepSeek 系列(DeepSeek-AI, 2024a,b,c; Guo et al., 2024)、LLaMA 系列(AI@Meta, 2024a,b; Touvron et al., 2023a,b)、Qwen 系列(Qwen, 2023, 2024a,b)以及 Mistral 系列(Jiang et al., 2023; Mistral, 2024))也在不断取得重大进展,努力缩小与闭源模型的性能差距。为了进一步推动开源模型能力的边界,我们扩大了模型规模,并推出 DeepSeek-V3——一个拥有 6710 亿参数的专家混合(MoE)模型,其中每个 token 仅激活 370 亿参数。
从前瞻性角度出发,我们始终追求强大的模型性能和经济可控的计算成本。因此,在架构方面,DeepSeek-V3 仍采用多头潜在注意力(MLA)(DeepSeek-AI, 2024c)以实现高效推理,并采用 DeepSeekMoE(Dai et al., 2024)以优化训练成本。这两种架构在 DeepSeek-V2(DeepSeek-AI, 2024c)中已被验证,能够在保证稳健模型性能的同时,实现高效训练和推理。除了基础架构之外,我们还引入了两种额外策略以进一步提升模型能力。首先,DeepSeek-V3 首次提出了一种无辅助损失(auxiliary-loss-free)策略(Wang et al., 2024a)来实现负载均衡,旨在减少负载均衡对模型性能的负面影响。其次,DeepSeek-V3 采用了多 token 预测训练目标,我们观察到这一方法能够在多个评测基准上提升整体性能。
为了实现高效训练,我们支持 FP8 混合精度训练,并对训练框架进行了全面优化。低精度训练已成为高效训练的一个重要解决方案(Dettmers et al., 2022; Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b),其发展与硬件能力的进步密切相关(Luo et al., 2024; Micikevicius et al., 2022; Rouhani et al., 2023a)。在本研究中,我们引入了一种 FP8 混合精度训练框架,并首次在超大规模模型上验证了其有效性。通过支持 FP8 计算与存储,我们在加速训练的同时减少了 GPU 内存使用。此外,在训练框架方面,我们设计了 DualPipe 算法,以实现高效的流水线并行(pipeline parallelism)。该算法减少了流水线气泡(pipeline bubbles),并通过计算-通信重叠(computation-communication overlap)隐藏了大部分训练过程中的通信开销。该重叠机制确保在模型规模进一步扩大的情况下,只要保持计算与通信比率恒定,我们仍能在多个节点上部署细粒度专家,并实现接近零的 all-to-all 通信开销。此外,我们还开发了高效的跨节点 all-to-all 通信内核,以充分利用 InfiniBand(IB)和 NVLink 带宽。此外,我们精心优化了内存占用,使得 DeepSeek-V3 的训练无需依赖昂贵的张量并行(tensor parallelism)。综合以上优化,我们成功实现了高效的训练流程。
在预训练过程中,我们在 14.8 万亿高质量且多样化的 token 上训练 DeepSeek-V3。整个预训练过程异常稳定。在整个训练过程中,我们未曾遇到不可恢复的损失峰值,也未进行任何回滚操作。接下来,我们为 DeepSeek-V3 进行两阶段的上下文长度扩展。在第一阶段,我们将最大上下文长度扩展至 32K;在第二阶段,进一步扩展至 128K。随后,我们对 DeepSeek-V3 的基础模型进行后训练,包括监督微调(SFT) 和 强化学习(RL),以使其对齐人类偏好,并进一步释放其潜力。在后训练阶段,我们从 DeepSeek-R1 系列模型中蒸馏推理能力,同时精心维护模型的准确性与生成长度之间的平衡。
我们在一系列全面的基准测试上对 DeepSeek-V3 进行了评估。尽管其训练成本经济,综合评估结果表明 DeepSeek-V3-Base 是当前最强的开源基础模型,特别是在代码和数学方面表现突出。其聊天版本(chat version)同样优于其他开源模型,并在一系列标准化和开放式基准测试上 达到了与领先闭源模型(如 GPT-4o 和 Claude-3.5-Sonnet)相当的性能。
最后,我们再次强调 DeepSeek-V3 的经济训练成本,其训练成本已在表 1 中总结,并通过我们优化的算法、框架和硬件的协同设计得以实现。在预训练阶段,DeepSeek-V3 每训练 1 万亿个 token 仅需 18 万 H800 GPU 小时,即在我们拥有 2048 张 H800 GPU 的集群上,仅需 3.7 天。因此,我们在不到两个月内完成了整个预训练,总计耗费 266.4 万 GPU 小时。加上11.9 万 GPU 小时的上下文长度扩展训练和 5000 GPU 小时的后训练,DeepSeek-V3 完整训练总共仅耗费 278.8 万 GPU 小时。假设 H800 GPU 的租赁价格为每小时 2 美元,则我们的总训练成本仅为 557.6 万美元。需要注意的是,上述成本仅包括 DeepSeek-V3 的正式训练成本,并不包括先前关于架构、算法或数据的研究和消融实验的相关费用。

表 1 | DeepSeek-V3 的训练成本(假设 H800 GPU 的租赁价格为每 GPU 小时 2 美元)。
我们的主要贡献包括:
架构:创新的负载均衡策略与训练目标
-
在 DeepSeek-V2 高效架构的基础上,我们首创了一种无辅助损失(auxiliary-loss-free)的负载均衡策略,最大程度地减少了负载均衡对模型性能的负面影响。
-
我们研究了多 token 预测(MTP)目标,并证明其有助于提升模型性能。此外,该目标还能用于推测解码(speculative decoding),以加速推理过程。
预训练:迈向极致的训练效率
-
我们设计了 FP8 混合精度训练框架,并首次在超大规模模型上验证了 FP8 训练的可行性和有效性。
-
通过算法、框架和硬件的协同设计,我们克服了跨节点 MoE 训练中的通信瓶颈,实现了近乎完整的计算-通信重叠,大幅提升训练效率并降低训练成本,使得我们能够在不增加额外开销的情况下进一步扩展模型规模。
-
仅耗费 266.4 万 H800 GPU 小时,我们在 14.8 万亿 token 上完成了 DeepSeek-V3 的预训练,产出了当前最强的开源基础模型。此外,预训练后的后续训练阶段仅需 10 万 GPU 小时。
后训练:从 DeepSeek-R1 进行知识蒸馏
-
我们提出了一种创新方法,将长链式思维(Long Chain-of-Thought, CoT)模型(特别是 DeepSeek-R1 系列的一款模型)的推理能力蒸馏到标准 LLM(尤其是 DeepSeek-V3)中。
-
在此过程中,我们巧妙地将 R1 的验证(verification)和反思(reflection)模式融入 DeepSeek-V3,显著提升其推理能力。同时,我们也精准控制了 DeepSeek-V3 的输出风格和生成长度。
核心评估结果总结
-
知识能力:(1)在 MMLU、MMLU-Pro 和 GPQA 等教育类基准测试上,DeepSeek-V3 超越所有其他开源模型,分别获得 88.5(MMLU)、75.9(MMLU-Pro)和 59.1(GPQA) 的成绩。其表现可媲美领先的闭源模型(如 GPT-4o 和 Claude-Sonnet-3.5),缩小了开源模型与闭源模型在该领域的差距。(2)在事实性知识(factuality)基准测试中,DeepSeek-V3 在 SimpleQA 和 Chinese SimpleQA 上表现优越,在开源模型中排名第一。尽管在英文事实知识(SimpleQA)上仍略逊于 GPT-4o 和 Claude-Sonnet-3.5,但在中文事实知识(Chinese SimpleQA)上超越了这些模型,展现了其在中文事实性知识上的优势。
-
代码、数学与推理能力:(1)在所有非长链 CoT(non-long-CoT)的开源和闭源模型中,DeepSeek-V3 在数学相关基准测试上达到了当前最佳水平。值得注意的是,在 MATH-500 这样的特定基准上,它甚至超越了 o1-preview,展现出强大的数学推理能力。(2)在编程相关任务中,DeepSeek-V3 在 LiveCodeBench 等编程竞赛基准测试中表现最佳,巩固了其在该领域的领先地位。在工程相关任务上,虽然 DeepSeek-V3 略逊于 Claude-Sonnet-3.5,但仍远超所有其他模型,在各种技术基准上展现出强劲的竞争力。
在本文的其余部分,我们将详细介绍 DeepSeek-V3 的架构(第 2 节)。接着,我们介绍计算集群、训练框架、FP8 训练支持、推理部署策略,以及对未来硬件设计的建议。随后,我们描述预训练过程,包括训练数据构建、超参数设置、长上下文扩展技术、相关评测及讨论(第 4 节)。接下来,我们讨论后训练阶段,包括监督微调(SFT)、强化学习(RL)、对应评测及讨论(第 5 节)。最后,我们总结本文内容,讨论 DeepSeek-V3 现存的局限性,并提出未来研究的潜在方向(第 6 节)。
2. 架构
我们首先介绍 DeepSeek-V3 的基本架构,该架构采用多头潜在注意力 MLA 以提高推理效率,并使用 DeepSeekMoE 以优化训练成本。随后,我们提出多token预测 MTP 训练目标,该目标在多个评测基准上表现出对整体性能的提升。对于其他未明确提及的细节,DeepSeek-V3仍遵循DeepSeek-V2的设置。
2.1. 基本架构
DeepSeek-V3的基本架构仍然基于Transformer框架。为了提高推理效率和优化训练成本,DeepSeek-V3采用MLA和DeepSeekMoE,这两种架构在DeepSeek-V2中已被充分验证。与DeepSeek-V2相比,DeepSeek-V3额外引入了一种无辅助损失负载均衡策略,用于缓解在确保负载均衡过程中对模型性能造成的影响。

图2 | DeepSeek-V3基本架构示意图。继承DeepSeek-V2的设计,我们采用MLA和DeepSeekMoE以实现高效推理和经济训练
图2展示了DeepSeek-V3的基本架构,我们将在本节简要回顾MLA和DeepSeekMoE的细节。
2.1.1. 多头潜在注意力
在注意力机制中,DeepSeek-V3采用 MLA 架构。设 𝑑 表示嵌入维度, 表示注意力头的数量,
表示每个头的维度,
∈
表示在某个注意力层中第𝑡个token的注意力输入。MLA 的核心是对注意力键(Key)和值(Value)进行低秩联合压缩,以减少推理时的键值 KV 缓存:

其中, ∈
是键(Key)和值(Value)的压缩潜在向量;
(≪
) 表示KV压缩维度;
∈
是下投影矩阵;
和
∈
分别是键和值的上投影矩阵;
∈
是用于生成解耦键(decoupled key)的矩阵,该键携带旋转位置编码RoPE(Su et al., 2024);RoPE(·) 表示应用RoPE矩阵的运算;[·; ·] 表示向量拼接。需要注意的是,在MLA中,仅需缓存蓝框标记的向量,即
和
,这大大减少了KV缓存需求,同时仍能保持与标准多头注意力MHA(Vaswani et al., 2017)相当的性能。
对于注意力查询(queries),我们同样执行低秩压缩,这可以减少训练期间的激活内存占用:

其中, ∈
是查询(query)的压缩潜在向量;
(≪
) 表示查询压缩维度;
∈
和
∈
分别是查询的下投影矩阵和上投影矩阵;
∈
是用于生成解耦查询(decoupled queries)的矩阵,该查询携带旋转位置编码RoPE。
最终,注意力查询 、键
和值
结合后生成最终的注意力输出
:

其中, ∈
表示输出投影矩阵。
2.1.2. 无辅助损失负载均衡的 DeepSeekMoE
DeepSeekMoE 的基本架构。对于前馈网络(FFNs),DeepSeek-V3 采用 DeepSeekMoE 架构(Dai et al., 2024)。与 GShard(Lepikhin et al., 2021)等传统 MoE 架构相比,DeepSeekMoE 使用更细粒度的专家(experts),并将部分专家隔离为共享专家。设 为第 𝑡 个 token 的 FFN 输入,我们计算其 FFN 输出
如下:
 其中,𝑁𝑠 和 𝑁𝑟 分别表示共享专家和路由专家的数量;
其中,𝑁𝑠 和 𝑁𝑟 分别表示共享专家和路由专家的数量; 和
分别表示第 𝑖 个共享专家和第 𝑖 个路由专家;𝐾𝑟 表示激活的路由专家数量;
是第 𝑖 个专家的门控值(gating value);
是 token 对专家的亲和度(token-to-expert affinity);
是第 𝑖 个路由专家的中心向量(centroid vector);Topk(·, 𝐾) 表示从所有路由专家计算出的亲和度分数中选取最高的 𝐾 个分数的集合。与 DeepSeek-V2 略有不同,DeepSeek-V3 采用 sigmoid 函数计算亲和度分数,并在所有被选中的亲和度分数之间进行归一化,以生成最终的门控值。
无辅助损失负载均衡。对于 MoE 模型,专家负载不均衡会导致路由崩溃(Shazeer et al., 2017),并在专家并行的场景中降低计算效率。传统的解决方案通常依赖于辅助损失(Fedus et al., 2021;Lepikhin et al., 2021)来避免负载不均衡。然而,过大的辅助损失会损害模型的性能(Wang et al., 2024a)。为了在负载均衡和模型性能之间实现更好的平衡,我们开创了一种无辅助损失的负载均衡策略(Wang et al., 2024a),以确保负载均衡。具体来说,我们为每个专家引入一个偏置项 ,并将其添加到对应的亲和度分数
中,以确定 top-K 路由:

注意,偏置项仅用于路由。门控值(gating value),即将与 FFN 输出相乘的值,仍然来自于原始的亲和度分数 。 在训练过程中,我们会持续监控每个训练步骤中整个批次的专家负载。在每个步骤结束时,如果对应的专家超载,我们将偏置项减少 𝛾;如果对应的专家负载不足,我们将其增加 𝛾,其中 𝛾 是一个超参数,称为偏置更新速度(bias update speed)。通过这种动态调整,DeepSeek-V3 在训练过程中保持专家负载平衡,并且相比于仅通过纯辅助损失来鼓励负载平衡的模型,能够实现更好的性能。
互补的序列级辅助损失。尽管 DeepSeek-V3 主要依赖于无辅助损失策略来实现负载平衡,但为了防止单个序列内部出现极端的不平衡,我们还使用了一个互补的序列级平衡损失:

其中,平衡因子 𝛼 是一个超参数,对于 DeepSeek-V3 来说将赋予一个极小的值;1(·) 表示指示函数;𝑇 表示序列中的标记数。序列级平衡损失鼓励每个序列的专家负载保持平衡。
节点限制路由。与 DeepSeek-V2 使用的设备限制路由类似,DeepSeek-V3 也使用了一种受限路由机制,以限制训练过程中的通信成本。简而言之,我们确保每个标记最多只会发送到 𝑀 个节点,这些节点是根据分布在每个节点上的专家的前 个亲和度分数的总和来选择的。在这个约束下,我们的 MoE 训练框架几乎可以实现完全的计算-通信重叠。
无Token丢弃。由于有效的负载平衡策略,DeepSeek-V3 在整个训练过程中保持良好的负载平衡。因此,DeepSeek-V3 在训练期间不会丢弃任何Token。此外,我们还实施了特定的部署策略,以确保推理过程中的负载平衡,因此 DeepSeek-V3 在推理过程中也不会丢弃Token。
2.2 多标记预测
受到 Gloeckle 等人(2024)的启发,我们为 DeepSeek-V3 设定了一个多标记预测(MTP)目标,将预测范围扩展到每个位置的多个未来标记。一方面,MTP 目标可以密集化训练信号,可能提高数据效率。另一方面,MTP 可以使模型预先规划其表示,以便更好地预测未来的标记。图 3 展示了我们的 MTP 实现。与 Gloeckle 等人(2024)通过独立输出头并行预测 𝐷 个额外标记不同,我们依次预测额外的标记,并在每个预测深度保持完整的因果链条。在本节中,我们介绍了 MTP 实现的细节。
MTP 模块。具体而言,我们的 MTP 实现使用 𝐷 个顺序模块来预测 𝐷 个额外的标记。第 𝑘 个 MTP 模块由一个共享嵌入层 Emb(·)、一个共享输出头 OutHead(·)、一个 Transformer 块 TRM𝑘 (·) 和一个投影矩阵 𝑀𝑘 ∈ 组成。对于第 𝑖 个输入标记
,在第 𝑘 个预测深度,我们首先将第 𝑖 个标记在第 (𝑘−1) 深度的表示
∈
与第 (𝑖+𝑘) 个标记的嵌入 𝐸𝑚𝑏(
) ∈
结合,并进行线性投影:

其中,[·; ·] 表示拼接操作。特别地,当 𝑘 = 1 时,指的是由主模型给出的表示。需要注意的是,对于每个 MTP 模块,它的嵌入层与主模型共享。组合后的
作为 Transformer 块第 𝑘 深度的输入,以生成当前深度的输出表示
:

其中,𝑇 表示输入序列的长度,𝑖:𝑗 表示切片操作(包括左右边界)。最后,以 作为输入,共享的输出头将计算第 𝑘 个附加预测 token 的概率分布
∈
,其中 𝑉 是词汇表的大小:
![]()
输出头 OutHead(·) 将表示映射到 logits,并随后应用 Softmax(·) 函数来计算第 𝑘 个附加 token 的预测概率。同时,对于每个 MTP 模块,它的输出头与主模型共享。我们保持预测的因果链的原则与 EAGLE (Li et al., 2024b) 类似,但它的主要目标是推测解码 (Leviathan et al., 2023; Xia et al., 2023),而我们利用 MTP 来改进训练。
MTP 训练目标。在每个预测深度,我们计算交叉熵损失 :

其中,𝑇 表示输入序列的长度, 表示第 𝑖 个位置的真实标记,
表示给定 𝑘-th MTP 模块的预测概率。最后,我们计算所有深度的 MTP 损失的平均值,并将其乘以一个权重因子 𝜆,得到最终的 MTP 损失 LMTP,该损失作为 DeepSeek-V3 的附加训练目标:

MTP 在推理中的应用。我们的 MTP 策略主要旨在提升主模型的性能,因此,在推理过程中,我们可以直接丢弃 MTP 模块,主模型可以独立且正常地运行。此外,我们还可以将这些 MTP 模块重新用于推测解码,以进一步提升生成的延迟表现。
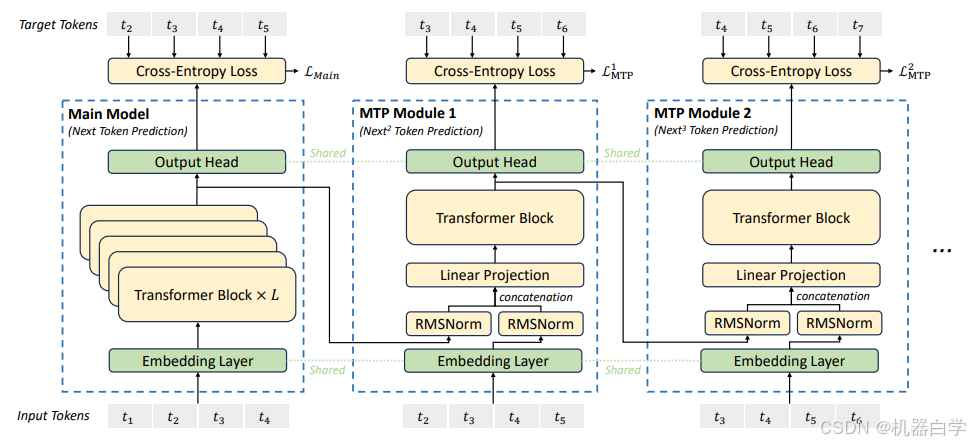
图3 | 我们的多Token预测(MTP)实现示意图。我们在每一层保留完整的因果链,以预测每个标记。
引言和架构部分翻译至此结束,下一部分将继续翻译后续内容。
相关文章:
【论文翻译】DeepSeek-V3论文翻译——DeepSeek-V3 Technical Report——第一部分:引言与模型架构
论文原文链接:DeepSeek-V3/DeepSeek_V3.pdf at main deepseek-ai/DeepSeek-V3 GitHub 特别声明,本文不做任何商业用途,仅作为个人学习相关论文的翻译记录。本文对原文内容直译,一切以论文原文内容为准,对原文作者表示…...

【docker】Failed to allocate manager object, freezing:兼容兼容 cgroup v1 和 v2
参考大神让系统同时兼容 cgroup v1 和 v2 要解决你系统中只挂载了 cgroup v2 但需要兼容 cgroup v1 的问题,可以通过以下几步来使系统同时兼容 cgroup v1 和 cgroup v2。这样 Docker 和其他服务就可以正常工作了。步骤 1:更新 Grub 配置,启用兼容模式 编辑 GRUB 配置来启用同…...

我使用deepseek高效学习-分析外文网站Cron定时执行任务
最近在spring框架中 设置定时任务,有的末尾是星号有的是问号,有的是6位,有的是7位。就这个机会总结下cron表达式的使用,综合源代码中的crontab地址翻译分析,结合最近超爆的deepseek 提高学习效率,归纳总结出…...
Android13-系统服务大管家-ServiceManager进程-启动篇
文章目录 关注 ServiceMager 原因ServerManager需要掌握的知识资料参考ServiceManager 进程启动启动脚本涉及到的相关源码文件源码跟踪ServiceManager脚本启动位置ServiceManager关联脚本 Native层源码分析main.cpp流程打开驱动 initWithDriverinitmakeProcessState 构造方法op…...
论文笔记:Rethinking Graph Neural Networks for Anomaly Detection
目录 摘要 “右移”现象 beta分布及其小波 实验 《Rethinking Graph Neural Networks for Anomaly Detection》,这是一篇关于图(graph)上异常节点诊断的论文。 论文出处:ICML 2022 论文地址:Rethinking Graph Ne…...

vue知识补充
1.列的样式 第一种:一列一列的写 <div class"house-detail"><div class"static-container"><form-item-static label"业主姓名">{{ baseData.mainOwnerName }}</form-item-static><form-item-static la…...

pushgateway指标聚合问题
一 问题现象 一个job有多个实例推送指标,但是从pushgateway上看这个job的instance字段,只显示一个实例的ip,而不是多个实例。导致在grafana上无法正常根据ip查看监控。 应用的prometheus的配置 management:metrics:tags:application: ${spr…...

使用docker搭建FastDFS文件服务
1.拉取镜像 docker pull registry.cn-hangzhou.aliyuncs.com/qiluo-images/fastdfs:latest2.使用docker镜像构建tracker容器(跟踪服务器,起到调度的作用) docker run -dti --networkhost --name tracker -v /data/fdfs/tracker:/var/fdfs -…...

【R语言】数据分析
一、描述性统计量 借助R语言内置的airquality数据集进行简单地演示: 1、集中趋势:均值和中位数 head(airquality) # 求集中趋势 mean(airquality$Ozone, na.rmT) # 求均值 median(airquality$Ozone, na.rmT) # 求中位数 2、众数 众数(mod…...

蓝桥杯C语言组:图论问题
蓝桥杯C语言组图论问题研究 摘要 图论是计算机科学中的一个重要分支,在蓝桥杯C语言组竞赛中,图论问题频繁出现,对参赛选手的算法设计和编程能力提出了较高要求。本文系统地介绍了图论的基本概念、常见算法及其在蓝桥杯C语言组中的应用&#…...

jmeter 性能测试Linux 常用的安装
把软件安装包全部都放在/data/soft目录下 一、 Java 环境安装 1. 把JDK的安装包上传到/data/soft/目录下 2. 解压jdk安装包,重命名jdk 3. 配置环境变量 JAVA_HOME [root@MiWiFi-RA72-srv soft]# vim /etc/profile export JAVA_HOME=/data/soft/jdk1.8 export PATH=…...
)
19 角度操作模块(angle.rs)
angle.rs代码定义了一个泛型结构体 Angle,用于表示一个角度,其中角度以弧度为单位存储。这个结构体提供了许多特性,包括复制、克隆、默认实现、调试输出、部分相等性比较、哈希等。此外,它还根据编译时的特性(features…...

前端高级面试题及其答案
以下是一些前端高级面试题及其答案: 一、JavaScript相关 事件循环(Event Loop)机制 答案: JavaScript的事件循环负责执行代码、收集和处理事件以及执行队列中的子任务。它包含宏任务(macrotask)队列&…...

【ORACLE】这个‘‘和null不等价的场景,deepseek你怎么看?
【ORACLE】一处’和null不等价的场景–to_char(number,varchar2) 背景 最近在做一个国产数据库替代项目,要求将ORACLE迁移到一个openGauss系数据库,迁移后,执行一个存储过程时,发现国产库的执行结果和ORACLE不一致, …...

使用Python实现PDF与SVG相互转换
目录 使用工具 使用Python将SVG转换为PDF 使用Python将SVG添加到现有PDF中 使用Python将PDF转换为SVG 使用Python将PDF的特定页面转换为SVG SVG(可缩放矢量图形)和PDF(便携式文档格式)是两种常见且广泛使用的文件格式。SVG是…...

ComfyUI 安装教程:macOS 和 Linux 统一步骤
本教程将详细介绍如何在 macOS 和 Linux 上安装 ComfyUI。我们将从 安装 Anaconda 开始,到安装 PyTorch 和 ComfyUI,最后提供一些常见问题的解决方法。 macOS和linux安装步骤很相似 可以按照1️⃣安装anaconda2️⃣安装python3️⃣torch4️⃣comfyui Co…...

360手机刷机 360手机解Bootloader 360手机ROOT
360手机刷机 360手机解Bootloader 360手机ROOT 问:360手机已停产,现在和以后,能刷机吗? 答:360手机,是肯定能刷机的 360手机资源下载网站 360手机-360手机刷机RootTwrp 360os.top 360rom.github.io 一、…...

t113-qt
修改QT配置: # # qmake configuration for building with arm-linux-gnueabi-g ## MAKEFILE_GENERATOR UNIX # CONFIG incremental # QMAKE_INCREMENTAL_STYLE sublib# include(../common/linux.conf) # include(../common/gcc-base-unix.conf) # inc…...

【真一键部署脚本】——一键部署deepseek
目录 deepseek一键部署脚本说明 0 必要前提 1 使用方法 1.1 使用默认安装配置 1.1 .1 使用其它ds模型 1.2 使用自定义安装 2 附录:deepseek模型手动下载 3 脚本下载地址 deepseek一键部署脚本说明 0 必要前提 linux环境 python>3.10 1 使用方法 1.1 …...

【AI 语音】实时语音交互优化全解析:从 RTC 技术到双讲处理
网罗开发 (小红书、快手、视频号同名) 大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等…...

Harbor:统一管理MCP服务器的配置中心与团队协作平台
1. 项目概述:一个统一管理MCP服务器的“港口” 如果你和我一样,每天都在Claude Code、Cursor、VS Code这几个编辑器之间来回切换,同时还要折腾一堆MCP服务器,那你肯定也经历过这种痛苦:在 ~/.claude.json 里加一个配…...

CSS 视图过渡完全指南
CSS 视图过渡完全指南 引言 CSS 视图过渡(View Transitions)是一个强大的新特性,它允许开发者创建平滑的页面过渡动画。本文将深入探讨视图过渡的各种用法和高级技巧。 基础概念回顾 什么是视图过渡 视图过渡 API 允许你在 DOM 状态变化时创建…...

初创公司如何借助Taotoken控制大模型API试用与正式成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何借助Taotoken控制大模型API试用与正式成本 对于初创公司而言,在产品从原型验证到正式上线的过程中&#x…...

淘宝要接入AI购物助手:以后买东西,可能不是搜索,而是“让AI帮你挑”
最近AI圈有一个很值得关注的新热点。据路透社5月10日报道,阿里巴巴正准备把通义千问Qwen接入淘宝,让用户可以通过和AI聊天的方式浏览、比较和购买商品,而不是像以前那样自己一个个翻商品列表。报道还提到,Qwen应用将接入淘宝和天猫…...

慕尼黑电子展:洞察汽车电子、工业物联网与功率半导体技术趋势
1. 从慕尼黑看全球电子产业:一场技术与商业的“双向奔赴”又到了双数年的十一月,全球电子工程师和产业领袖的目光,不约而同地再次聚焦于德国慕尼黑。没错,Electronica——这个被誉为全球电子元器件行业“晴雨表”的顶级盛会&#…...

南京彩钢瓦屋面防水供应商
在南京,彩钢瓦屋面广泛应用于各类建筑,然而其防水问题一直是困扰众多业主的难题。选择一家靠谱的彩钢瓦屋面防水供应商至关重要。今天就为大家详细介绍雨中行修缮工程有限公司,同时也对比其他一些大厂,看看雨中行修缮为何能在市场…...

osModa:基于NixOS与AI智能体的下一代服务器操作系统
1. 项目概述:为AI智能体而生的操作系统如果你和我一样,长期在服务器运维和AI应用部署的一线摸爬滚打,那你一定对这样的场景深有体会:凌晨三点,手机突然响起刺耳的告警,你睡眼惺忪地爬起来,SSH连…...

AI驱动游戏开发:Godogen自动化流水线全解析
1. 项目概述:当AI成为你的游戏开发合伙人 如果你是一名独立游戏开发者,或者对用Godot引擎做点小玩意儿感兴趣,那你肯定体会过那种感觉:一个绝妙的点子在你脑海里盘旋,但一想到要从零开始搭场景、写脚本、画素材&#x…...

基于物理信息神经网络与降阶模型的文物数字孪生保护框架
1. 项目概述:当文化遗产保护遇上科学计算与人工智能最近几年,我一直在关注一个交叉领域:如何用前沿的计算科学和人工智能技术,去解决那些看似传统、实则充满挑战的文物保护难题。这次分享的“基于SciML与数字孪生的文化遗产保护框…...

【信息科学与工程学】【通信工程】第五十九篇 面向SDN城域网网络的算法工程02
条目:SDN-Metro-0065 (IPoE入L3VPN业务) 字段 内容 1. 编号 SDN-Metro-0065 2. 类别 业务领域 / 接入与VPN 3. 领域 基于动态策略的IPoE用户接入L3VPN业务 4. 模型配方 IPoE(IP over Ethernet)用户通过以太网接入,并直接进入运营商的L3VPN网络,访问企业内…...