基于深度学习的人工智能量化衰老模型构建与全流程应用研究
 一、引言
一、引言
1.1 研究背景与意义
1.1.1 人口老龄化现状与挑战
人口老龄化是当今全球面临的重要社会趋势之一,其发展态势迅猛且影响深远。根据联合国的相关数据,1980 年,全球 65 岁及以上人口数量仅为 2.6 亿,到 2021 年,这一数字已翻番,达到 7.61 亿,而预计到 2050 年,该群体将急剧增加到 16 亿 。在全球范围内,老龄化程度不断加深,2021 年,每 10 人中就有 1 人属于 65 岁及以上群体,而到 2050 年,这一比例将变为每 6 人中就有 1 人属于该群体。日本作为老龄化较为严重的国家,其 65 岁及以上人口占比在 2021 年接近 30%,而韩国预计在 2050 年 65 岁人口比例将突破 40%,到 2060 年将达到 43.9%,人口中位数年龄也将在 2060 年高达 61.3 岁。从区域来看,发展中国家的老年人人数增长最多且最为迅速,亚洲将成为老年人口最多的区域,北非、西亚和撒哈拉以南非洲地区在未来 30 年也将经历快速的老年人数量增长。
人口老龄化带来了诸多严峻的挑战,在健康领域,老年群体的健康问题日益复杂和多样化。随着年龄的增长,老年人身体机能逐渐衰退,慢性病的发病率大幅上升。据中国老年学会发布的数据显示,70% 以上的老年人患有一种或多种慢性病,如高血压、糖尿病、骨关节疾病等,这些慢性病不仅严重影响老年人的生活质量,还需要长期的医疗护理和治疗,给医疗资源带来了沉重的负担。同时,老年人的身体免疫力较低,急性病和突发疾病的发生率也较高,对医疗服务的需求急剧增加,使得医疗系统面临巨大的压力。
在经济层面,老龄化对劳动力市场和经济增长产生了显著的负面影响。劳动力是经济发展的重要支撑,而老龄化导致劳动年龄人口减少,劳动力供给不足,进而影响经济的发展速度。以日本为例,自 1990 年其劳动人口比例开始下滑,年均 GDP 增长率也随之不足 1%,随后的 20 年经济一直处于通缩阶段。在通缩环境下,资产价格持续下跌,企业和家庭背负的负债过重,消费需求不足,经济增长乏力,投资回报率降低,给整个经济体系带来了极大的困境。此外,随着老年人口的增加,养老金和医疗费用等社会保障支出不断攀升,给政府财政带来了沉重的压力。在发达国家,老年群体的资金来源主要依赖养老金、医保在内的公共财政转移支付,而在公共财政转移支付能力欠发达的国家,老年人的养老和医疗保障面临更大的挑战。
1.1.2 人工智能在生物医学领域的应用潜力
近年来,人工智能在生物医学领域展现出了巨大的应用潜力,成为推动该领域发展的重要力量。人工智能是一门研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的新技术科学,它具有强大的信息处理能力、自主学习能力、推理能力和自我适应能力,能够模拟人类的意识和思维过程。自 20 世纪 50 年代起,人工智能开始被应用于生物医学领域,最初主要用于医学影像分析,随着技术的不断进步,其应用范围逐渐拓展到疾病诊断、治疗、药物研发等多个关键领域。
在疾病诊断方面,人工智能通过深度学习和图像识别等技术,能够对医学影像资料进行快速、准确的分析,辅助医生进行疾病诊断,大大提高了诊断的准确性和效率。例如,在医学影像识别中,人工智能算法可以自动识别医学影像中的异常区域,帮助医生更及时地发现疾病,减少误诊和漏诊的发生。在药物研发领域,人工智能可以通过大数据分析和机器学习等方法,快速筛选和设计新的药物分子,缩短药物研发周期,降低研发成本。传统的药物研发需要耗费大量的时间和资金,通常开发一款新药需要 10 年时间,投入 10 亿美元,而借助人工智能技术,需要筛选的化合物种类大幅减少,新药前期开发的效率得到了显著提升。此外,人工智能还可以对患者的基因组、生活习惯等多维度信息进行分析,为患者提供个性化的治疗方案,实现精准医疗,提高治疗效果。
将人工智能应用于衰老研究,对于衰老的预测和预防具有极其重要的意义。衰老过程涉及到复杂的生理和病理变化,传统的研究方法难以全面、深入地揭示衰老的机制和规律。而人工智能凭借其强大的数据处理和分析能力,能够整合多源数据,挖掘其中隐藏的信息,从而更准确地预测个体的衰老进程。通过构建衰老预测模型,能够提前识别出衰老风险较高的个体,为制定个性化的预防措施提供科学依据。在预防方面,人工智能可以根据个体的健康状况和生活习惯,制定个性化的抗衰老方案,包括饮食、运动、药物干预等,帮助人们延缓衰老进程,提高老年生活质量。例如,通过分析个体的基因数据、生活方式数据和健康监测数据,人工智能可以为其量身定制适合的饮食和运动计划,以维持身体的健康状态,延缓衰老的发生。
二、Python 与人工智能基础概述
2.1 Python 语言特性及其在量化分析中的优势
2.1.1 人工智能核心技术在衰老研究中的适用性
2.2.2 深度学习技术架构
深度学习作为人工智能的重要分支,其神经网络架构在衰老研究中展现出独特的优势和广泛的应用前景。深度学习通过构建具有多个层次的神经网络模型,能够自动从大量数据中学习复杂的模式和特征,无需人工手动提取特征,大大提高了数据分析的效率和准确性。
卷积神经网络(Convolutional Neural Network,CNN)是一种专门为处理具有网格结构数据(如图像、音频)而设计的深度学习架构。在衰老研究中,CNN 在医学图像分析领域发挥着重要作用。在心血管衰老研究中,CNN 可以对心电图(ECG)数据进行分析。传统的心电图分析主要依赖医生的人工判读,存在主观性和局限性。而利用 CNN 强大的特征提取能力,能够自动学习心电图中的特征模式,构建 “心电图年龄” 模型。通过对大量心电图数据的学习,CNN 可以识别出与心血管衰老相关的特征,如心率变异性、ST 段变化等,从而预测个体的心血管年龄。巴西的研究团队使用 156 万名患者的心电图等数据,通过多层卷积神经网络预测出对应的 “心电图年龄”,并发现心电图年龄大于时序年龄超过 8 岁的个体,其全因死亡率是正常人群的 1.79 倍 ,为心血管疾病的早期风险评估提供了新的方法。
在视网膜图像分析中,CNN 也可用于开发基于深度学习的生物衰老标记物(RetiPhenoAge)。清华大学医学院黄天荫教授团队联合新加坡国立大学等团队,利用具有多层卷积神经网络的架构,对英国生物库数据集的视网膜图片进行训练,识别与肾脏、免疫、肝功能、炎症和能量代谢以及与实际年龄相关的血液生物标记物变化相关的视网膜模式和特征,从而预测 PhenoAge 的综合得分。研究结果表明,RetiPhenoAge 与发病率和死亡率的关联性比手握力、端粒长度和身体活动更强,为人体衰老和疾病风险评估提供了新的视角。
循环神经网络(Recurrent Neural Network,RNN)及其变体长短期记忆网络(Long Short-Term Memory,LSTM)和门控循环单元(Gated Recurrent Unit,GRU),适用于处理序列数据,能够捕捉数据中的时间依赖关系。在衰老研究中,这些模型可用于分析时间序列的生理数据,如血压、血糖、心率等随时间的变化趋势,从而预测衰老相关疾病的发生发展。通过对患者长期的血压数据进行分析,LSTM 模型可以学习到血压的变化规律,预测高血压等心血管疾病的发病风险。LSTM 模型还可以对老年人的认知能力随时间的变化进行建模,通过分析认知测试得分等时间序列数据,预测老年痴呆等神经退行性疾病的发生。由于老年人的认知能力下降是一个渐进的过程,LSTM 模型能够捕捉到这种时间上的变化趋势,提前发现认知能力下降的迹象,为早期干预提供依据。
生成对抗网络(Generative Adversarial Network,GAN)由生成器和判别器组成,通过两者的对抗训练,能够生成逼真的数据。在衰老研究中,GAN 可用于数据增强,解决衰老相关数据样本不足的问题。在医学图像分析中,由于获取大量的衰老相关医学图像数据较为困难,使用 GAN 可以生成虚拟的医学图像,扩充数据集,提高模型的训练效果。GAN 还可以用于生成虚拟的衰老细胞模型,帮助研究人员更好地理解衰老细胞的特性和机制,为抗衰老药物的研发提供支持。通过生成不同状态下的衰老细胞模型,研究人员可以模拟药物对衰老细胞的作用,筛选出具有潜在抗衰老效果的药物分子。

三、衰老量化数据获取与预处理
3.1 衰老相关数据类型及来源
3.1.1 生物标志物数据
生物标志物数据在衰老研究中占据着核心地位,为深入探究衰老机制和评估衰老进程提供了关键线索。DNA 甲基化数据作为一种重要的表观遗传修饰,在衰老研究中具有极高的价值。DNA 甲基化是指在 DNA 甲基转移酶的作用下,将甲基基团添加到 DNA 特定区域的过程,这一过程能够在不改变 DNA 序列的前提下,对基因表达进行调控。随着年龄的增长,DNA 甲基化模式会发生显著变化,这些变化与衰老相关的生理和病理过程密切相关。大量研究表明,某些基因的甲基化水平会随着年龄的增加而升高或降低,从而影响基因的表达活性,进而影响细胞的功能和衰老进程。在一些衰老相关的疾病中,如心血管疾病、神经退行性疾病等,DNA 甲基化模式也会出现异常改变。通过分析 DNA 甲基化数据,可以构建出高精度的表观遗传时钟,用于准确预测个体的生物学年龄。Steve Horvath 教授联合 100 多个实验室,对 200 多种哺乳动物的血液和组织样本、36000 个胞嘧啶甲基化情况进行深入整理分析,成功设计出了 “表观遗传时钟”,该时钟能够通过 DNA 甲基化情况精准追踪人类和其他哺乳动物的生物学年龄 ,为衰老研究提供了重要的工具。
基因表达数据则从转录水平揭示了衰老过程中基因的活性变化。基因表达是指基因转录成 RNA,再进一步翻译成蛋白质的过程,这一过程受到严格的调控,而在衰老过程中,基因表达的调控网络会发生紊乱。随着年龄的增长,许多与细胞代谢、免疫功能、氧化应激等相关的基因表达会发生显著改变。研究发现,在衰老的细胞中,参与能量代谢的基因表达水平下降,导致细胞能量供应不足;而与炎症反应相关的基因表达则会上调,引发慢性炎症状态,进一步加速细胞和机体的衰老。通过对基因表达数据的分析,可以筛选出与衰老密切相关的关键基因和信号通路,深入了解衰老的分子机制。利用微阵列技术和 RNA 测序技术,可以全面、准确地检测基因表达水平,为衰老研究提供丰富的数据支持。
蛋白质组学数据从蛋白质层面反映了衰老过程中蛋白质的表达、修饰和相互作用的变化。蛋白质是生命活动的主要执行者,其表达和功能的改变直接影响细胞和机体的生理状态。在衰老过程中,蛋白质的合成、折叠、降解等过程都会出现异常,导致蛋白质组的组成和功能发生变化。一些与衰老相关的蛋白质,如衰老相关分泌表型(SASP)中的蛋白质,会随着年龄的增长而大量分泌,这些蛋白质包括细胞因子、趋化因子、蛋白酶等,它们会对周围细胞和组织产生影响,促进炎症反应和组织损伤,加速衰老进程。通过蛋白质组学技术,如质谱分析、蛋白质芯片等,可以对蛋白质组进行全面的分析,鉴定出与衰老相关的蛋白质标志物,为衰老的诊断和治疗提供新的靶点。美国梅奥医学中心的 Jennifer L. St. Sauver 教授团队通过对 1923 名 65 岁及以上老人的研究,评估了 28 种 SASP 蛋白的血浆水平与死亡风险之间的关系,发现与死亡风险增加最密切相关的五种衰老生物标志物是 GDF15、RAGE、VEGFA、PARC 和 MMP2 ,这些发现为预测老年人的临床健康状况提供了重要的依据。
3.1.2 临床数据与生活方式数据
临床数据在衰老研究中具有不可或缺的价值,它为全面了解衰老个体的健康状况提供了直接的信息。临床检查指标,如血压、血糖、血脂、肾功能指标、肝功能指标等,能够直观地反映出老年人身体各个系统的功能状态。血压的升高往往与心血管疾病的发生密切相关,而随着年龄的增长,血管弹性下降,血压升高的风险也会增加。血糖和血脂的异常则与糖尿病、动脉粥样硬化等衰老相关疾病密切相关。通过对这些临床检查指标的监测和分析,可以及时发现老年人身体的潜在问题,评估衰老对身体健康的影响程度。肾功能指标中的肌酐、尿素氮等可以反映肾脏的排泄功能,随着年龄的增长,肾脏功能逐渐衰退,这些指标会发生相应的变化,通过检测这些指标,可以了解肾脏的衰老进程。
疾病史也是临床数据的重要组成部分,它记录了个体曾经患过的疾病以及疾病的治疗情况。许多慢性疾病,如高血压、糖尿病、心脏病等,在老年人群中的发病率较高,且这些疾病的发生与衰老密切相关。了解个体的疾病史,可以分析疾病与衰老之间的因果关系,为预防和治疗衰老相关疾病提供参考。对于有糖尿病病史的老年人,研究其疾病的发展过程和治疗效果,可以深入了解糖尿病对衰老进程的影响,以及如何通过有效的治疗措施延缓衰老。家族病史也能为衰老研究提供重要线索,某些遗传因素可能会增加个体患衰老相关疾病的风险,通过分析家族病史,可以发现潜在的遗传风险因素,为个性化的衰老预防和治疗提供依据。
生活方式数据对衰老研究也具有重要意义,它反映了个体的生活习惯和行为方式对衰老的影响。生活习惯,如饮食、运动、睡眠、吸烟、饮酒等,与衰老进程密切相关。合理的饮食结构能够为身体提供充足的营养,维持细胞和组织的正常功能。富含抗氧化物质的食物,如蔬菜、水果、坚果等,可以帮助清除体内的自由基,减少氧化应激对细胞的损伤,从而延缓衰老。适量的运动可以增强身体的代谢能力,提高心血管功能,促进血液循环,增强肌肉力量,改善身体的柔韧性和平衡能力,有助于延缓衰老。睡眠质量对身体的恢复和修复至关重要,良好的睡眠可以促进细胞的再生和修复,调节免疫系统功能,减少炎症反应,对延缓衰老具有积极作用。而吸烟和过量饮酒则会对身体造成损害,加速衰老进程。吸烟会导致血管收缩,减少氧气供应,增加氧化应激,损伤细胞和组织;过量饮酒会损害肝脏、心脏等器官的功能,影响身体的代谢和免疫功能。
通过对大量个体的生活方式数据进行分析,可以建立起生活方式与衰老之间的关联模型,为制定个性化的抗衰老方案提供科学依据。美国功能医学研究院、加州大学洛杉矶分校等机构的研究人员开展的一项随机对照临床试验,在 40 多名 50 - 72 岁之间的健康男性志愿者中进行实验,他们在 8 周时间里接受饮食、睡眠、运动和放松指导,并补充益生菌和植物营养素。具体指导方案包括间歇性禁食、限制热量摄入、以植物性饮食为主、每周至少 5 天每天进行 30 分钟以上运动、每晚至少平均睡眠 7 小时、每天进行两次放松方法等。实验结束后,发现与对照组相比,8 周的饮食、运动、睡眠和放松治疗让他们的 DNA 甲基化年龄减少了 3.23 年 ,这充分证明了生活方式干预对延缓衰老的重要作用。
3.2 使用 Python 进行数据预处理
3.2.1 数据清洗与去噪
在衰老量化研究中,获取到的原始数据往往存在各种问题,如缺失值、重复值、异常值以及噪声数据等,这些问题会严重影响后续分析和模型构建的准确性与可靠性,因此数据清洗与去噪是数据预处理的关键环节。Python 作为强大的数据处理工具,其丰富的库函数为数据清洗提供了高效的解决方案。
Pandas 库是 Python 进行数据处理的核心库之一,在处理缺失值方面表现出色。在处理 DNA 甲基化数据时,若数据集中存在缺失值,可利用 Pandas 的isnull()函数来检测数据中的缺失值,该函数会返回一个与原数据结构相同的布尔型数据,其中缺失值对应的位置为True,非缺失值对应的位置为False。通过sum()函数对isnull()的返回结果进行求和,能够统计出每列缺失值的数量,从而直观地了解数据缺失的情况。对于存在缺失值的样本或特征,可根据实际情况选择合适的处理方法。若缺失值较少,可采用删除含有缺失值的行或列的方式,使用dropna()函数即可轻松实现,该函数可根据指定的轴(axis=0表示行,axis=1表示列)删除含有缺失值的部分。若缺失值较多,删除会导致大量数据丢失,此时可考虑使用填充的方法。Pandas 提供了fillna()函数,可使用指定的值(如均值、中位数、众数等)对缺失值进行填充。对于数值型数据,可计算其均值或中位数,然后使用fillna()函数将缺失值替换为均值或中位数;对于分类数据,可使用众数进行填充。
在处理重复值时,Pandas 同样提供了便捷的方法。通过duplicated()函数可以检测数据中的重复行,该函数返回一个布尔型的 Series,其中重复行对应的位置为True,唯一行对应的位置为False。使用drop_duplicates()函数则可直接删除重复行,保留唯一的行数据,确保数据的唯一性,避免重复数据对分析结果的干扰。
异常值的检测与处理对于保证数据质量也至关重要。在衰老相关的临床数据中,如血压、血糖等指标,可能会出现异常值。利用 Python 的 Numpy 库和 Pandas 库结合,可以采用多种方法检测异常值。常用的方法之一是基于统计学的 3σ 原则,即数据应分布在均值加减 3 倍标准差的范围内,超出这个范围的数据点可被视为异常值。首先,使用 Numpy 的mean()和std()函数计算数据的均值和标准差,然后根据 3σ 原则确定异常值的范围,通过比较数据与异常值范围,标记出异常值。在 Python 中,可通过布尔索引的方式筛选出异常值,进而对其进行处理。处理异常值的方法有多种,可根据具体情况选择删除异常值、将异常值替换为合理的值(如均值、中位数等)或者对异常值进行修正。
噪声数据是指那些对数据分析和模型训练产生干扰的无关或错误的数据。在基因表达数据中,可能会存在因实验误差或测量噪声导致的异常波动。为了去除噪声数据,可以使用平滑滤波的方法,如移动平均法。在 Python 中,利用 Pandas 的rolling()函数结合mean()函数可以实现移动平均操作。通过设置合适的窗口大小,对基因表达数据进行移动平均计算,能够平滑数据曲线,减少噪声的影响,使数据更能反映真实的基因表达趋势。
3.2.2 数据标准化与归一化
数据标准化与归一化是数据预处理中不可或缺的步骤,它能够使不同特征的数据具有相同的尺度和分布,从而提高模型的训练效果和性能。在衰老量化研究中,涉及到多种类型的数据,如生物标志物数据、临床数据等,这些数据的量纲和取值范围往往差异较大,若不进行标准化和归一化处理,可能会导致模型训练不稳定、收敛速度慢以及预测准确性降低等问题。Python 提供了丰富的工具和方法来实现数据的标准化与归一化。
Z-score 标准化是一种常用的数据标准化方法,它基于原始数据的均值和标准差进行转换,将数据转换为均值为 0、标准差为 1 的标准正态分布。在 Python 中,使用 Scikit-learn 库的preprocessing.StandardScaler类可以方便地实现 Z-score 标准化。以基因表达数据为例,首先导入相关库:
| from sklearn import preprocessing import numpy as np import pandas as pd |
然后读取基因表达数据,假设数据存储在一个 CSV 文件中,文件名为gene_expression.csv,可以使用 Pandas 的read_csv()函数读取数据,并将其转换为二维数组:
| data = pd.read_csv('gene_expression.csv') X = data.iloc[:, 1:].values # 假设第一列是样本ID,其余列为基因表达数据 |
接下来创建StandardScaler对象,并对数据进行拟合和转换:
| scaler = preprocessing.StandardScaler() scaled_X = scaler.fit_transform(X) |
经过上述操作,scaled_X即为标准化后的基因表达数据,其均值为 0,标准差为 1。Z-score 标准化适用于特征的最大值和最小值未知,或存在离群数据的情况,它能够有效地消除数据的量纲影响,使不同特征的数据具有可比性。
Min-Max 归一化是另一种常见的方法,它将数据线性变换到指定的区间,通常是。其公式为:
,其中x为原始数据,
和
分别为数据的最小值和最大值,x^{'}为归一化后的数据。在 Python 中,使用 Scikit-learn 库的preprocessing.MinMaxScaler类可以实现 Min-Max 归一化。仍以上述基因表达数据为例,创建MinMaxScaler对象并进行拟合和转换:
| min_max_scaler = preprocessing.MinMaxScaler() min_max_scaled_X = min_max_scaler.fit_transform(X) |
此时,min_max_scaled_X就是归一化到区间的基因表达数据。Min-Max 归一化能够保留数据的原始分布特征,并且在数据没有极端值的情况下,
相关文章:
基于深度学习的人工智能量化衰老模型构建与全流程应用研究
一、引言 1.1 研究背景与意义 1.1.1 人口老龄化现状与挑战 人口老龄化是当今全球面临的重要社会趋势之一,其发展态势迅猛且影响深远。根据联合国的相关数据,1980 年,全球 65 岁及以上人口数量仅为 2.6 亿,到 2021 年,这一数字已翻番,达到 7.61 亿,而预计到 2050 年,…...

【医院运营统计专题】2.运营统计:医院管理的“智慧大脑”
医院成本核算、绩效管理、运营统计、内部控制、管理会计专题索引 引言 在当今医疗行业快速发展的背景下,医院运营管理的科学性和有效性成为了决定医院竞争力和可持续发展能力的关键因素。运营统计作为医院管理的重要工具,通过对医院各类数据的收集、整理、分析和解读,为医…...

Spring Boot Actuator使用
说明:本文介绍Spring Boot Actuator的使用,关于Spring Boot Actuator介绍,下面这篇博客写得很好,珠玉在前,我就不多介绍了。 Spring Boot Actuator 简单使用 项目里引入下面这个依赖 <!--Spring Boot Actuator依…...

【AI应用】免费的文本转语音工具:微软 Edge TTS 和 开源版 ChatTTS 对比
【AI论文解读】【AI知识点】【AI小项目】【AI战略思考】【AI日记】【读书与思考】【AI应用】 我试用了下Edge TTS,感觉还不错,不过它不支持克隆声音(比如自己的声音) 微软 Edge TTS 和 开源版 ChatTTS 都是免费的 文本转语音&…...
如何在 Qt 中添加和使用系统托盘图标
在 Qt 中实现系统托盘图标是一个常见的需求,尤其是在桌面应用程序中。系统托盘图标可以让应用程序在后台运行时仍然具有可见性,同时避免占用过多的桌面空间。本文将详细介绍如何在 Qt 项目中添加托盘图标,并通过资源系统(.qrc 文件…...
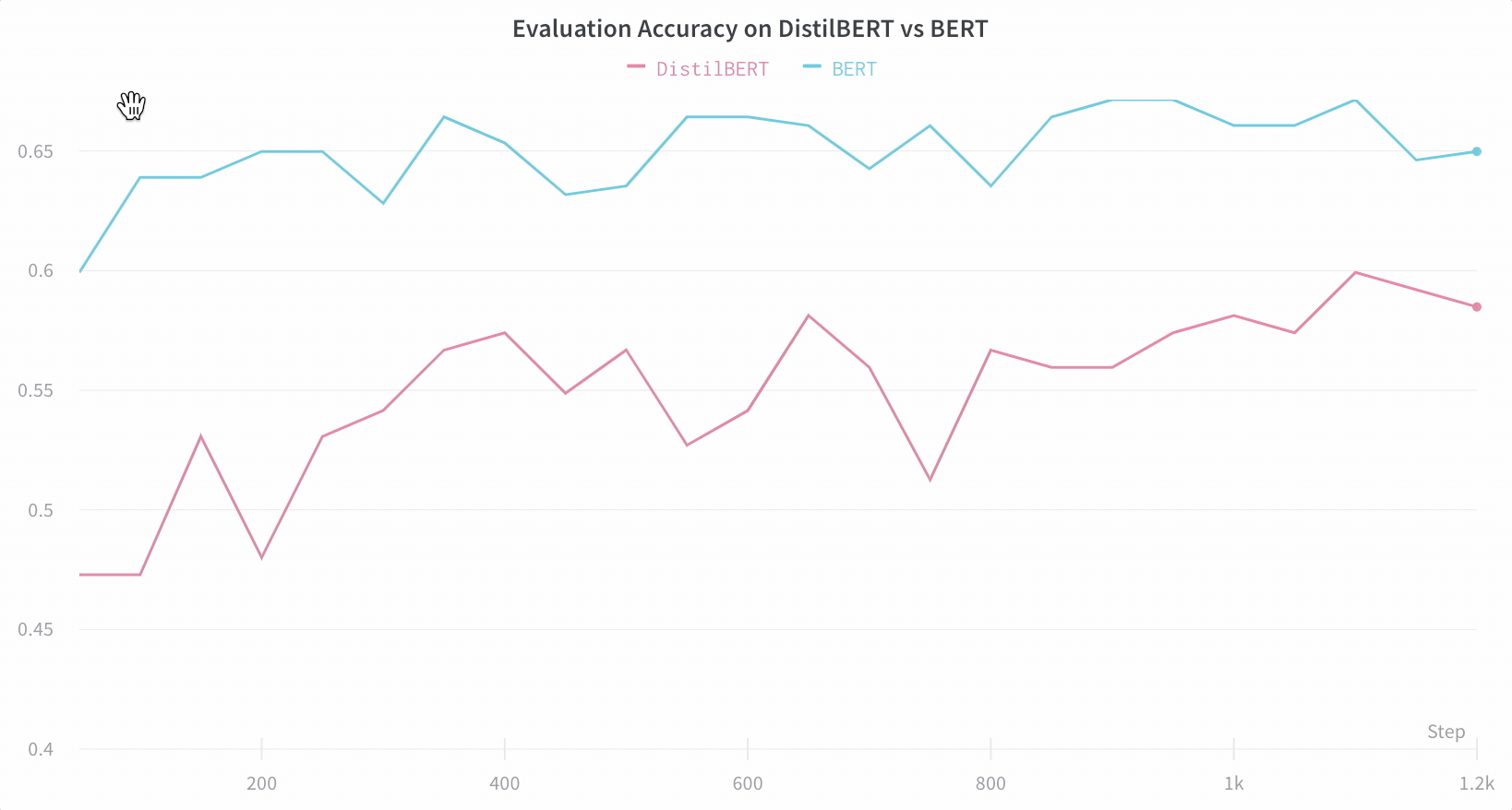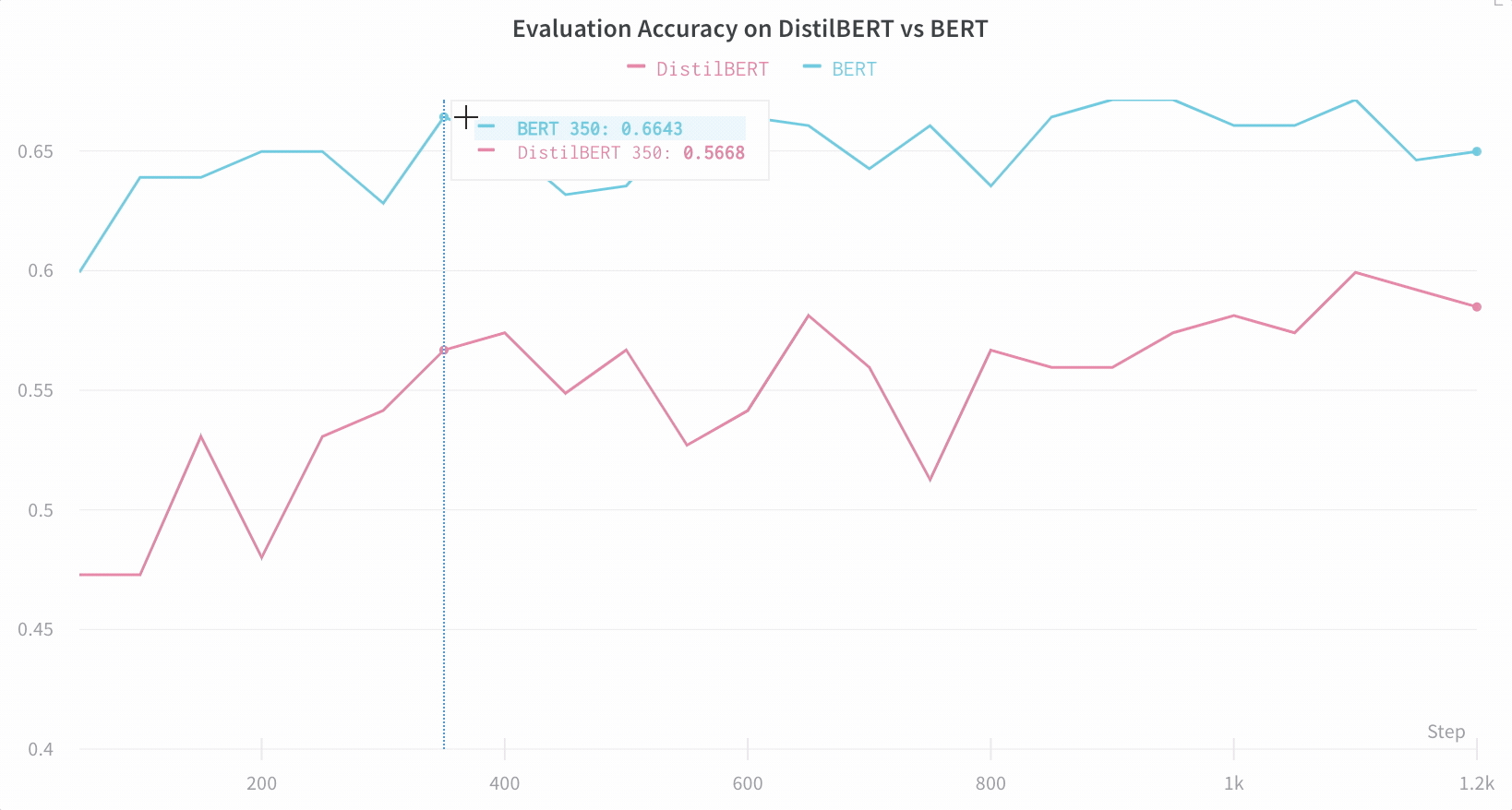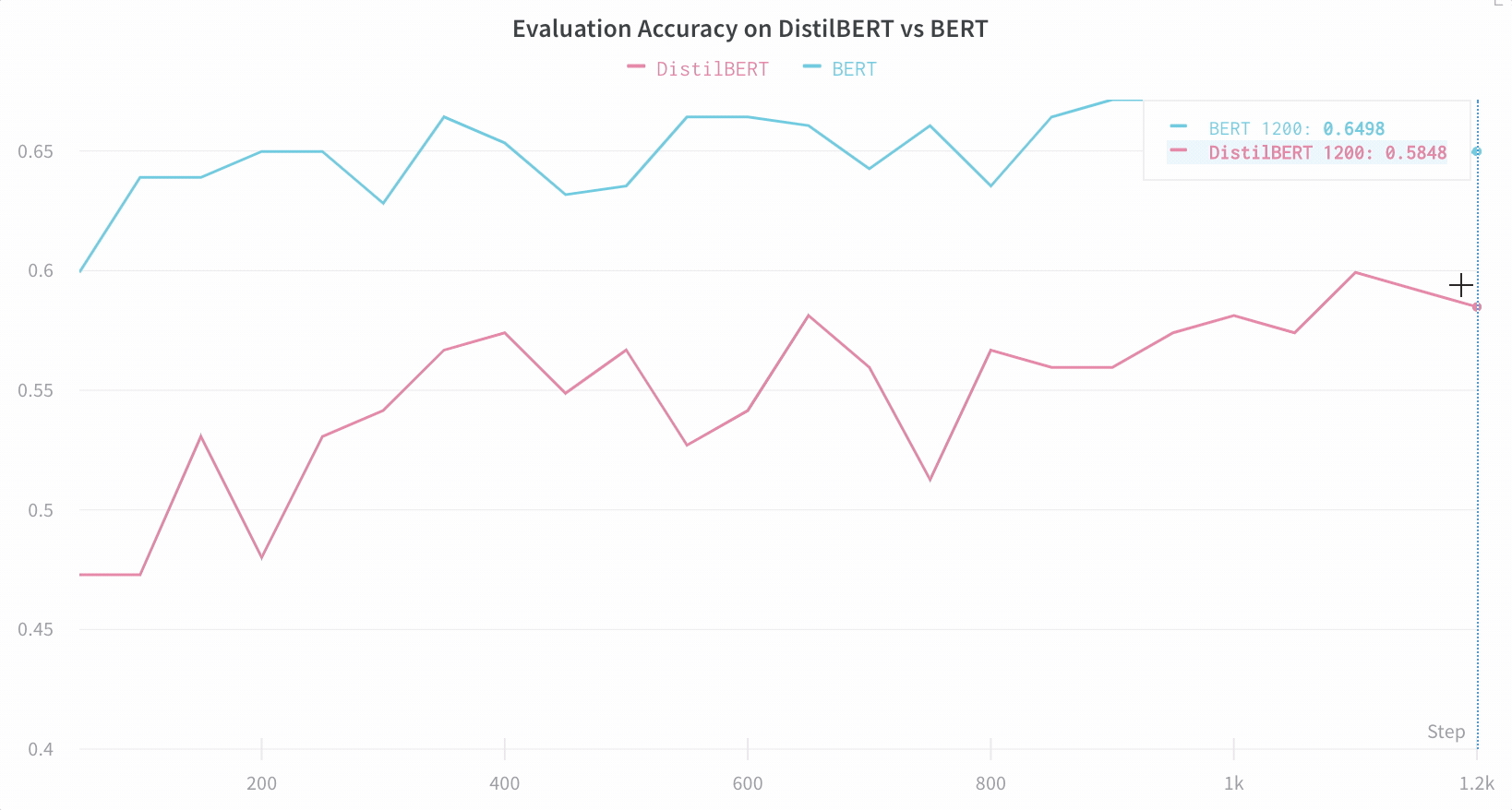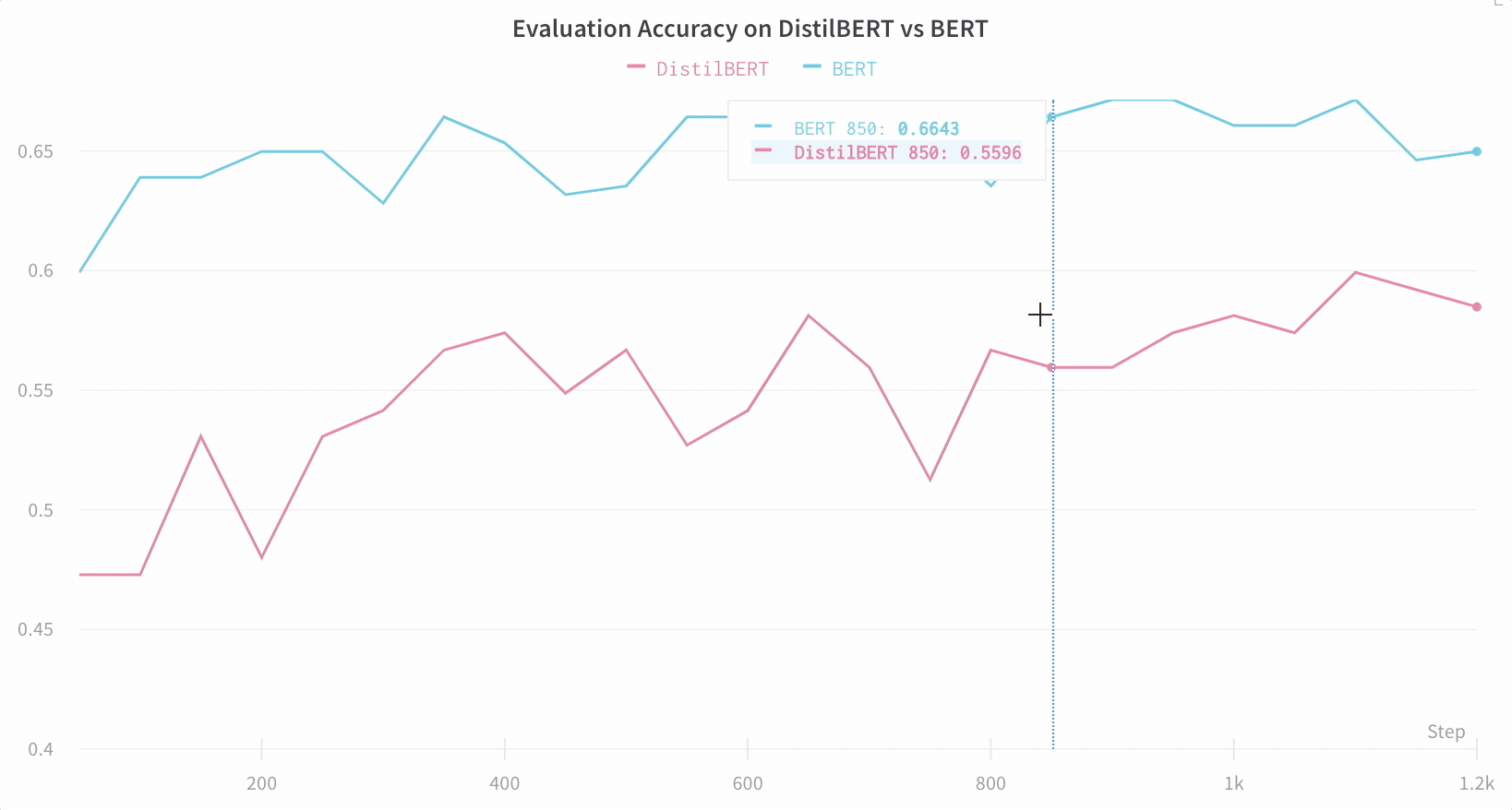
【WB 深度学习实验管理】利用 Hugging Face 实现高效的自然语言处理实验跟踪与可视化
本文使用到的 Jupyter Notebook 可在GitHub仓库002文件夹找到,别忘了给仓库点个小心心~~~ https://github.com/LFF8888/FF-Studio-Resources 在自然语言处理领域,使用Hugging Face的Transformers库进行模型训练已经成为主流。然而,随着模型复…...
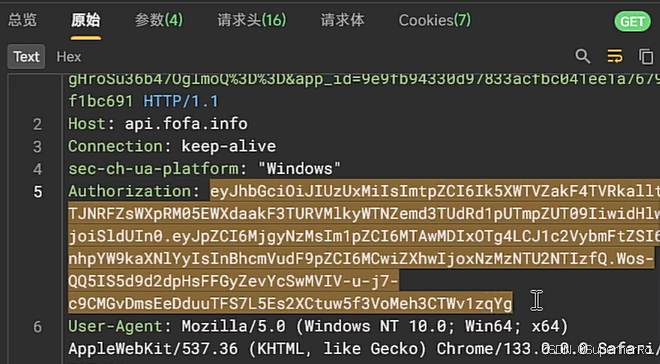
基础入门-网站协议身份鉴权OAuth2安全Token令牌JWT值Authirization标头
知识点: 1、网站协议-http/https安全差异(抓包) 2、身份鉴权-HTTP头&OAuth2&JWT&Token 一、演示案例-网站协议-http&https-安全测试差异性 1、加密方式 HTTP:使用明文传输,数据在传输过程中可以被…...
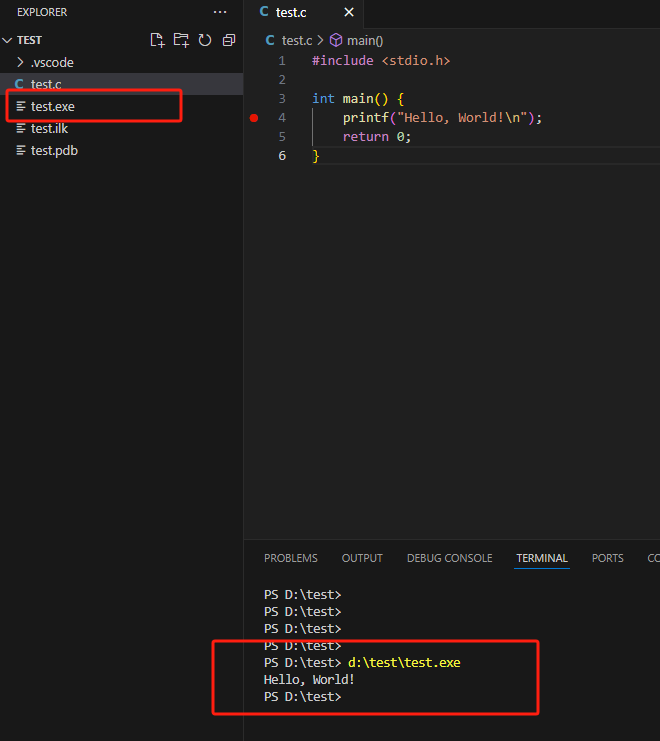
C语言基础系列【3】VSCode使用
前面我们提到过VSCode有多么的好用,本文主要介绍如何使用VSCode编译运行C语言代码。 安装 首先去官网(https://code.visualstudio.com/)下载安装包,点击Download for Windows 获取安装包后,一路点击Next就可以。 配…...

MySQL-5.7.44安装(CentOS7)
目录 1、下载安装包并解压 2、创建数据目录与日志目录 3、设置环境变量 4、刷新环境变量 5、执行初始化 6、创建配置文件目录 7、新建配置文件 8、为安装目录赋予可执行权限 9、创建服务启动脚本 10、启动服务并将启动脚本加入开机自启动 11、查看服务状态 12、创建…...

服务端与多客户端照片的传输,recv,send
一、照片传输 server.c /* * 文件名称:server.c * 创 建 者: * 创建日期:2025年02月07日 * 描 述: */ #include <stdio.h> #include <sys/types.h> /* See NOTES */ #include <sys/socket.h…...

JS实现灯光闪烁效果
在 JS中,我们可以实现灯光闪烁效果,这里主要用 setInterval 和 clearInterval 两个重要方法。 效果图 源代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>灯闪烁效果<…...

SpringCloud面试题----Nacos和Eureka的区别
功能特性 服务发现 Nacos:支持基于 DNS 和 RPC 的服务发现,提供了更为灵活的服务发现机制,能满足不同场景下的服务发现需求。Eureka:主要基于 HTTP 的 RESTful 接口进行服务发现,客户端通过向 Eureka Server 发送 HT…...

verilog练习:i2c slave 模块设计
文章目录 前言1. 结构2.代码2.1 iic_slave.v2.2 sync.v2.3 wr_fsm.v2.3.1 状态机状态解释 2.4 ram.v 3. 波形展示4. 建议5. 资料总结 前言 首先就不啰嗦iic协议了,网上有不少资料都是叙述此协议的。 下面将是我本次设计的一些局部设计汇总,如果对读者有…...
)
3.5 Go(特殊函数)
目录 一、匿名函数 1、匿名函数的特点: 2、匿名函数代码示例 2、匿名函数的类型 二、递归函数 1. 递推公式版本 2. 循环改递归 三、嵌套函数 1、嵌套函数用途 2、代码示例 3、作用域 & 变量生存周期 四、闭包 1、闭包使用场景 2、代码示例 五、De…...

Android的MQTT客户端实现
在 Android 平台上实现 MQTT 客户端的完整技术方案,涵盖基础实现、安全连接、性能优化和最佳实践: 一、技术选型与依赖配置 推荐库 Eclipse Paho Android Service(官方维护,支持后台运行) gradle 复制 // build.gradl…...

国产编辑器EverEdit - 编辑辅助功能介绍
1 编辑辅助功能 1.1 各编辑辅助选项说明 1.1.1 行号 打开该选项时,在编辑器主窗口左侧显示行号,如下图所示: 1.1.2 文档地图 打开该选项时,在编辑器主窗口右侧靠近垂直滚动条的地方显示代码的缩略图,如下图所示&…...

WPF 在后台使TextBox失去焦点的方法
在软件设计开发的时候,偶尔会遇到在后台xaml.cs后台中,要将TextBox控件的焦点取消或者使TextBox控件获取焦点,下面介绍讲述一种简单的“只让特定的 TextBox 失去焦点”方法: 前端xaml代码示例: <StackPanel Orientation"…...
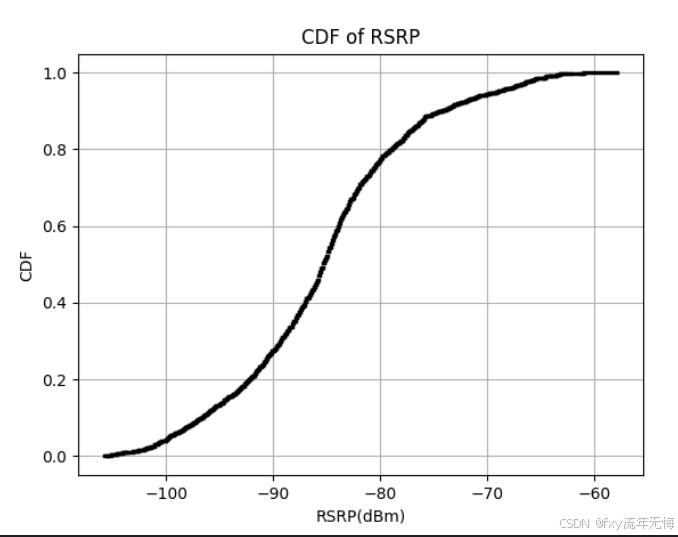
工作案例 - python绘制excell表中RSRP列的CDF图
什么是CDF图 CDF(Cumulative Distribution Function)就是累积分布函数,是概率密度函数的积分。CDF函数是一个在0到1之间的函数,描述了随机变量小于或等于一个特定值的概率。在可视化方面,CDF图表明了一个随机变量X小于…...
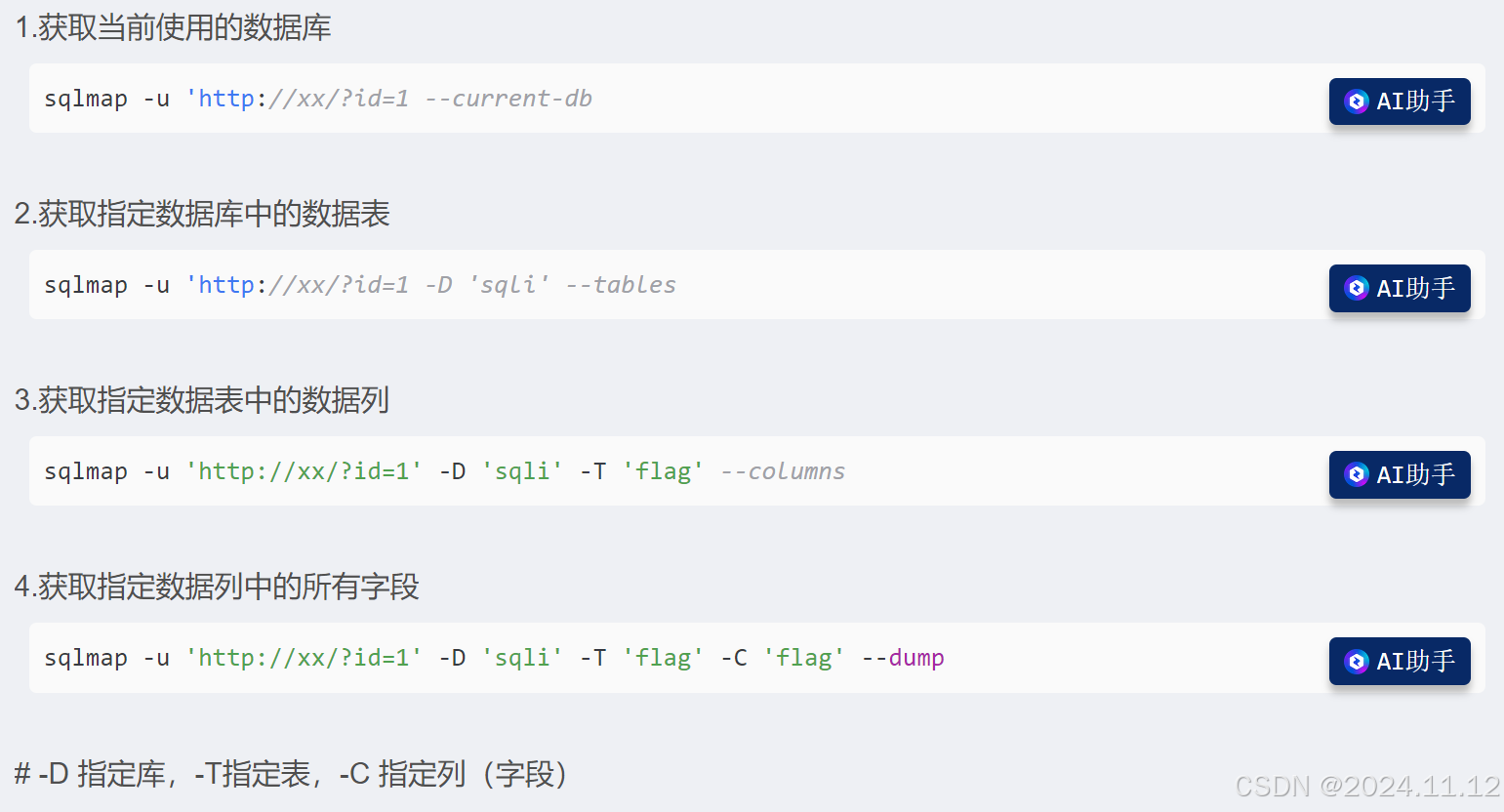
CTF SQL注入学习笔记
部分内容来自于SQL注入由简入精_哔哩哔哩_bilibili SQL语句 1.mysqli_error():返回最近调用函数的最后一个错误描述 语法:mysqli_error(connection) 规定要使用的Mysql连接; 返回一个带有错误描述的字符串。如果没有错误发生则返回 "" 2…...

element-plus el-tree-select 修改 value 字段
element-plus el-tree-select 修改 value 字段 ,不显示label 需要注意两个地方: <el-tree-select v-model"value" :data"data" multiple :render-after-expand"false" show-checkbox style"width: 240px" …...

开源技能库构建指南:Git+Markdown+Docsify打造个人技术知识体系
1. 项目概述:一个开源技能库的诞生与价值在技术领域,尤其是软件开发、运维和数据分析等方向,我们每天都在与海量的工具、框架和命令打交道。时间一长,一个很现实的问题就摆在了面前:那些曾经花了好几个小时才调通的复杂…...

JetBrains IDE 30天试用重置:一键解决方案的完整实践指南
JetBrains IDE 30天试用重置:一键解决方案的完整实践指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 当您正专注于代码调试时,IDE突然弹出"评估期已结束"的红色警告…...

OpenClaw 小龙虾智能体联动 DeepSeek 大模型部署实操攻略
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常启动OpenClaw,右上角 Gateway 状态显示在线设备网络通畅,可正常访问 DeepSeek 开放平台拥有可接收验证码的手机号 / 微信,用于平…...

基于IMAP的邮件自动化处理工具mymailclaw配置与实战指南
1. 项目概述:一个轻量级的邮件抓取与处理工具最近在折腾一个需要自动化处理邮件通知的小项目,发现市面上的方案要么太重,要么不够灵活。直到我遇到了psandis/mymailclaw这个项目,它就像一把小巧而锋利的瑞士军刀,专门用…...

ESP32-S2 Reverse TFT Feather开发板深度解析:从核心硬件到物联网项目实战
1. 项目概述:为什么选择ESP32-S2 Reverse TFT Feather?如果你正在寻找一款能让你快速搭建物联网设备原型,尤其是那些需要一块漂亮屏幕来交互或显示信息的项目,那么ESP32-S2 Reverse TFT Feather绝对是一个值得你花时间研究的开发板…...

如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南
如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经历过手机丢失、微信重装后珍贵聊天…...

番茄小说下载器终极指南:3分钟打造你的私人数字图书馆
番茄小说下载器终极指南:3分钟打造你的私人数字图书馆 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在深夜追更小说时,突然发现网络连接中断?…...

如何在Chrome浏览器中快速生成与解析二维码:Chrome QRCode插件终极指南
如何在Chrome浏览器中快速生成与解析二维码:Chrome QRCode插件终极指南 【免费下载链接】chrome-qrcode :zap: A Chrome plugin to Genrate QRCode of URL / Text, or Decode the QRcode in website. 一个Chrome浏览器插件,用于生成当前URL或者选中内容的…...

Golioth Firmware SDK:物联网设备连接与管理的开源解决方案
1. 项目概述:Golioth Firmware SDK 是什么?如果你正在开发物联网设备,尤其是那些需要稳定连接到云端、进行远程管理、固件更新和数据同步的设备,那么你一定对“设备管理”和“连接复杂性”这两个词深有体会。自己从头搭建一套稳定…...

桌面CNC木质游戏手柄外壳制作:从Fusion 360设计到实战加工全流程
1. 项目概述:从数字模型到木质手柄的旅程如果你和我一样,既痴迷于复古游戏的怀旧情怀,又享受亲手将数字设计变为实体物件的成就感,那么这个项目绝对能点燃你的热情。我们这次要做的,不是一个简单的3D打印外壳ÿ…...