【Python】元组

个人主页:GUIQU.
归属专栏:Python

文章目录
- 1. 元组的本质与基础概念
- 1.1 不可变序列的意义
- 1.2 元组与数学概念的联系
- 2. 元组的创建方式详解
- 2.1 标准创建形式
- 2.2 单元素元组的特殊处理
- 2.3 使用 `tuple()` 函数进行转换
- 3. 元组的基本操作深入剖析
- 3.1 索引操作的边界与异常处理
- 3.2 切片操作的高级用法
- 3.3 拼接与重复操作的性能分析
- 4. 元组的内置方法深度探究
- 4.1 `count()` 方法的性能优化思路
- 4.2 `index()` 方法的异常处理与扩展应用
- 5. 元组在函数中的高级应用
- 5.1 函数参数的元组解包
- 5.2 函数返回多个值的应用场景与优化
- 6. 元组在数据处理与算法中的应用
- 6.1 元组在排序算法中的稳定性
- 6.2 元组在哈希算法中的应用
- 7. 元组与其他数据类型的交互与转换
- 7.1 元组与列表的相互转换及性能影响
- 7.2 元组与字典的结合使用
- 8. 元组的性能优化与最佳实践
- 8.1 减少不必要的元组创建
- 8.2 合理使用元组进行数据封装
正文
1. 元组的本质与基础概念
1.1 不可变序列的意义
在 Python 的数据类型体系中,元组属于不可变序列。这一特性有着深远的意义,它保证了数据的完整性和安全性。从内存管理的角度来看,不可变对象在创建后其内存地址和内容都不会改变,这使得 Python 解释器能够对其进行高效的缓存和复用。例如,当多个变量引用同一个元组时,它们实际上指向的是同一块内存区域,这有助于节省内存资源。
1.2 元组与数学概念的联系
从数学的角度来看,元组可以看作是一个有序的元素集合,类似于数学中的向量或点。在二维平面中,一个点可以用元组 (x, y) 来表示,这种表示方式简洁且直观,方便进行几何运算和数据处理。在三维空间中,点可以表示为 (x, y, z),这种对应关系使得元组在科学计算和图形处理等领域有着广泛的应用。
2. 元组的创建方式详解
2.1 标准创建形式
# 简单元素元组
basic_tuple = (1, 2, 3)
# 包含不同数据类型的元组
mixed_type_tuple = (1, 'apple', [4, 5], (6, 7))
print(basic_tuple)
print(mixed_type_tuple)
上述代码展示了元组可以包含不同类型的元素,甚至可以嵌套其他元组或列表。这种灵活性使得元组能够存储复杂的数据结构,满足多样化的编程需求。
2.2 单元素元组的特殊处理
single_element_tuple = (42,)
print(single_element_tuple)
需要特别注意的是,单元素元组必须在元素后面加上逗号,否则 Python 会将其视为普通的括号表达式。这是一个容易被忽略的细节,但在实际编程中非常重要。
2.3 使用 tuple() 函数进行转换
# 从列表转换
list_to_tuple = tuple([10, 20, 30])
# 从字符串转换
string_to_tuple = tuple('hello')
print(list_to_tuple)
print(string_to_tuple)
tuple() 函数可以将任何可迭代对象转换为元组。这为数据的转换和处理提供了便利,使得不同类型的数据可以方便地转换为元组形式进行操作。
3. 元组的基本操作深入剖析
3.1 索引操作的边界与异常处理
my_tuple = (100, 200, 300, 400, 500)
try:# 正常索引访问first_element = my_tuple[0]last_element = my_tuple[-1]print(first_element)print(last_element)# 越界访问,会引发 IndexErrorout_of_bounds = my_tuple[10]
except IndexError as e:print(f"IndexError: {e}")
在进行索引操作时,需要注意索引的范围。如果使用的索引超出了元组的长度,会引发 IndexError 异常。因此,在实际编程中,需要进行合理的边界检查和异常处理,以确保程序的健壮性。
3.2 切片操作的高级用法
my_tuple = (1, 2, 3, 4, 5, 6, 7, 8, 9)
# 提取偶数索引的元素
even_index_tuple = my_tuple[::2]
# 反转元组
reversed_tuple = my_tuple[::-1]
print(even_index_tuple)
print(reversed_tuple)
切片操作不仅可以提取元组的一部分,还可以通过设置步长来实现更复杂的操作。例如,使用步长为 2 可以提取偶数索引的元素,使用负步长可以反转元组。
3.3 拼接与重复操作的性能分析
tuple_a = (1, 2, 3)
tuple_b = (4, 5, 6)
# 拼接操作
concatenated_tuple = tuple_a + tuple_b
# 重复操作
repeated_tuple = tuple_a * 3
print(concatenated_tuple)
print(repeated_tuple)
虽然元组的拼接和重复操作很方便,但需要注意的是,每次进行这些操作都会创建一个新的元组对象,这可能会带来一定的性能开销。在处理大规模数据时,需要谨慎使用这些操作。
4. 元组的内置方法深度探究
4.1 count() 方法的性能优化思路
my_tuple = (1, 2, 2, 3, 2, 4)
count_2 = my_tuple.count(2)
print(count_2)
count() 方法用于统计指定元素在元组中出现的次数。在处理大规模元组时,可以考虑对元组进行预处理或使用其他数据结构来优化统计操作的性能,例如使用字典来记录元素的出现次数。
4.2 index() 方法的异常处理与扩展应用
my_tuple = (10, 20, 30, 40)
try:index_30 = my_tuple.index(30)print(index_30)# 查找不存在的元素,会引发 ValueErrorindex_50 = my_tuple.index(50)
except ValueError as e:print(f"ValueError: {e}")
index() 方法用于返回指定元素在元组中第一次出现的索引。如果元素不存在,会引发 ValueError 异常。在实际应用中,可以结合异常处理来处理这种情况,还可以扩展该方法的功能,例如查找元素的所有出现位置。
5. 元组在函数中的高级应用
5.1 函数参数的元组解包
def add_numbers(a, b):return a + bnumbers = (3, 5)
result = add_numbers(*numbers)
print(result)
在函数调用时,可以使用 * 运算符对元组进行解包,将元组中的元素依次传递给函数的参数。这种方式使得函数调用更加灵活,尤其是在处理可变数量的参数时非常有用。
5.2 函数返回多个值的应用场景与优化
def get_stats(data):min_val = min(data)max_val = max(data)avg_val = sum(data) / len(data)return min_val, max_val, avg_valdata = [1, 2, 3, 4, 5]
min_val, max_val, avg_val = get_stats(data)
print(f"Min: {min_val}, Max: {max_val}, Avg: {avg_val}")
元组可以方便地作为函数的返回值,一次性返回多个值。在实际应用中,可以根据需要对返回的元组进行解包操作,将不同的值赋给不同的变量。同时,还可以考虑对返回的元组进行命名元组的转换,以提高代码的可读性。
6. 元组在数据处理与算法中的应用
6.1 元组在排序算法中的稳定性
students = [('Alice', 20), ('Bob', 18), ('Charlie', 20)]
sorted_students = sorted(students, key=lambda x: x[1])
print(sorted_students)
在排序算法中,元组的元素顺序是稳定的。这意味着当多个元素的排序键相同时,它们在排序后的相对顺序不会改变。这种稳定性在处理复杂的数据排序时非常重要。
6.2 元组在哈希算法中的应用
hashable_tuple = (1, 2, 3)
hash_value = hash(hashable_tuple)
print(hash_value)
由于元组是不可变的,它可以作为哈希表的键。这使得元组在需要使用哈希算法的数据结构(如字典和集合)中有着重要的应用。
7. 元组与其他数据类型的交互与转换
7.1 元组与列表的相互转换及性能影响
my_list = [1, 2, 3]
tuple_from_list = tuple(my_list)
list_from_tuple = list(tuple_from_list)
print(tuple_from_list)
print(list_from_tuple)
元组和列表可以相互转换,但需要注意的是,每次转换都会创建一个新的对象,这可能会带来一定的性能开销。在实际应用中,需要根据具体情况选择合适的数据类型,避免不必要的转换。
7.2 元组与字典的结合使用
point_dict = {(1, 2): 'Point A', (3, 4): 'Point B'}
print(point_dict[(1, 2)])
元组可以作为字典的键,这使得可以使用元组来表示复杂的键值关系。例如,在地理信息系统中,可以使用元组 (经度, 纬度) 作为键来存储地理位置的相关信息。
8. 元组的性能优化与最佳实践
8.1 减少不必要的元组创建
在编写代码时,应尽量减少不必要的元组创建操作。例如,在循环中避免频繁地拼接元组,可以考虑先将元素存储在列表中,最后再将列表转换为元组。
8.2 合理使用元组进行数据封装
元组的不可变性使得它非常适合用于数据封装。在设计函数或类时,可以使用元组来封装相关的数据,提高代码的可读性和可维护性。
通过深入理解元组的各个方面,包括其本质、创建方式、操作方法、应用场景以及性能优化等,开发者可以更加灵活、高效地使用元组,编写出更加健壮和优质的 Python 代码。
结语
感谢您的阅读!期待您的一键三连!欢迎指正!

相关文章:
【Python】元组
个人主页:GUIQU. 归属专栏:Python 文章目录 1. 元组的本质与基础概念1.1 不可变序列的意义1.2 元组与数学概念的联系 2. 元组的创建方式详解2.1 标准创建形式2.2 单元素元组的特殊处理2.3 使用 tuple() 函数进行转换 3. 元组的基本操作深入剖析3.1 索引操…...

【AI实践】deepseek支持升级git
当前Windows 11 WSL的git是2.17,Android Studio提示需要升级到2.19版本 网上找到指导文章 安装git 2.19.2 cd /usr/src wget https://www.kernel.org/pub/software/scm/git/git-2.19.2.tar.gz tar xzf git-2.19.2.tar.gz cd git-2.19.2 make prefix/usr/l…...

【AI实践】Cursor上手-跑通Hello World和时间管理功能
背景 学习目的:熟悉Cursor使用环境,跑通基本开发链路。 本人背景:安卓开发不熟悉,了解科技软硬件常识 实践 基础操作 1,下载安装安卓Android Studio 创建一个empty project 工程,名称为helloworld 2&am…...

Redis数据库(二):Redis 常用的五种数据结构
Redis 能够做到高性能的原因主要有两个,一是它本身是内存型数据库,二是采用了多种适用于不同场景的底层数据结构。 Redis 常用的数据结构支持字符串、列表、哈希表、集合和有序集合。实现这些数据结构的底层数据结构有 6 种,分别是简单动态字…...

【计组】实验五 J型指令设计实验
目录 一、实验目的 二、实验环境 三、实验原理 四、实验任务 代码 一、实验目的 1. 理解MIPS处理器指令格式及功能。 2. 掌握lw, sw, beq, bne, lui, j, jal指令格式与功能。 3. 掌握ModelSim和ISE\Vivado工具软件。 4. 掌握基本的测试代码编写和FPGA开发板使用方法。 …...

ubuntu 本地部署deepseek r1 蒸馏模型
本文中的文件路径或网络代理需要根据自身环境自行删改 一、交互式chat页面 1.1 open-webui 交互窗口部署:基于docker安装,且支持联网搜索 Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 AI 平台,旨在完全离线操作。它支持各种 LLM…...

RestTemplate Https 证书访问错误
错误信息 resttemplate I/O error on GET request for “https://21.24.6.6:9443/authn-api/v5/oauth/token”: java.security.cert.CertificateException: No subject alternative names present; nested exception is javax.net.ssl.SSLHandshakeException: java.security.c…...
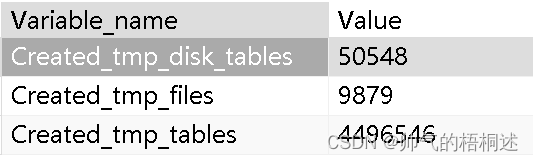
MySQL内存使用率高且不释放问题排查与总结
背景 生产环境mysql 5.7内存占用超过90%以上,且一直下不来。截图如下: 原因分析 1、确定mysql具体的占用内存大小,通过命令:cat /proc/Mysql进程ID/status查看 命令执行后的结果比较多(其他参数的含义想了解可参考这…...

mysql8 从C++源码角度看sql生成抽象语法树
在 MySQL 8 的 C 源码中,SQL 语句的解析过程涉及多个步骤,包括词法分析、语法分析和抽象语法树(AST)的生成。以下是详细的解析过程和相关组件的描述: 1. 词法分析器(Lexer) MySQL 使用一个称为…...

【DeepSeek】DeepSeek概述 | 本地部署deepseek
目录 1 -> 概述 1.1 -> 技术特点 1.2 -> 模型发布 1.3 -> 应用领域 1.4 -> 优势与影响 2 -> 本地部署 2.1 -> 安装ollama 2.2 -> 部署deepseek-r1模型 1 -> 概述 DeepSeek是由中国的深度求索公司开发的一系列人工智能模型,以其…...

【C++】多态原理剖析
目录 1.虚表指针与虚表 2.多态原理剖析 1.虚表指针与虚表 🍪类的大小计算规则 一个类的大小,实际就是该类中成员变量之和,需要注意内存对齐空类:编译器给空类一个字节来唯一标识这个类的对象 对于下面的Base类,它的…...

【Rust自学】20.4. 结语:Rust学习一阶段完成+附录
喜欢的话别忘了点赞、收藏加关注哦,对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 20.4.1. 总结 Rust初级学习之旅终于完成了!恭喜! 包括这篇文章,我们使用了110篇文章来学习Rust。 真…...

pytorch引用halcon写数据集
****加粗样式虽然啰嗦一点,但好歹halcon自己熟悉,不会忘记,用os 和 pil会导致脑子记得东西太多 import halcon as ha import torch from torch.utils.data import Datasetpath0 rE:\BaiduNetdiskDownload\cell class MyDataset(Dataset):de…...

让文物“活”起来,以3D数字化技术传承文物历史文化!
文物,作为不可再生的宝贵资源,其任何毁损都是无法逆转的损失。然而,当前文物保护与修复领域仍大量依赖传统技术,同时,文物管理机构和专业团队的力量相对薄弱,亟需引入数字化管理手段以应对挑战。 积木易搭…...

aarch64 Ubuntu20.04 安装docker
安装 docker 依赖项:sudo apt-get update sudo apt-get install apt-transport-https ca-certificates curl gnupg lsb-release添加 Docker GPG 密钥:curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyr…...

JAVA:CloseableHttpClient 进行 HTTP 请求的技术指南
1、简述 CloseableHttpClient 是 Apache HttpComponents 提供的一个强大 HTTP 客户端库。它允许 Java 程序与 HTTP/HTTPS 服务交互,可以发送 GET、POST 等各种请求类型,并处理响应。该库广泛用于 REST API 调用、文件上传和下载等场景。 2、特性 Close…...

Mac上搭建k8s环境——Minikube
1、在mac上安装Minikube可执行程序 brew cask install minikub 安装后使用minikube version命令查看版本 2、安装docker环境 brew install --cask --appdir/Applications docker #安装docker open -a Docker #启动docker 3、安装kubectl curl -LO https://storage.g…...

经典排序算法复习----C语言
经典排序算法复习 分类 交换类 冒泡快排 分配类 计数排序基数排序 选择类 选择排序 堆排序 归并类 归并排序 插入类 直接插入排序 希尔排序 折半插入排序 冒泡排序 基于交换。每一轮找最大值放到数组尾部 //冒泡排序 void bubSort(int* arr,int size){bool sorte…...

自动驾驶数据集三剑客:nuScenes、nuImages 与 nuPlan 的技术矩阵与生态协同
目录 1、引言 2、主要内容 2.1、定位对比:感知与规划的全维覆盖 2.2、数据与技术特性对比 2.3、技术协同:构建全栈研发生态 2.4、应用场景与评估体系 2.5、总结与展望 3、参考文献 1、引言 随着自动驾驶技术向全栈化迈进,Motional 团…...

[LUA ERROR] bad light userdata pointer
Cocos2d项目,targetSdkVersion30,在 android 13 设备运行报错: [LUA ERROR] bad light userdata pointer ,导致黑屏。 参考 cocos2dx 适配64位 arm64-v8a 30 lua 提示 bad light userdata pointer 黑屏-CSDN博客的方法 下载最新的Cocos2dx …...

内存占用3KB!极致瘦身释放MCU无限可能
极致小体积,给工业领域带来了无限的可能:更低硬件成本,更小芯片体积,更低功耗,更高可靠性,让每一颗小MCU都拥有大系统的完整能力。 https://www.bilibili.com/video/BV1eZLi6PEjc/?spm_id_from333.1387.ho…...

Burp Suite拦截与替换机制深度解析:从协议层到规则链
1. 这不是“点开就能用”的功能,而是你和目标系统之间的一道可编程闸门很多人第一次在Burp Suite里点开Proxy → Intercept,看到HTTP请求被拦下来,兴奋地改个User-Agent、删个Cookie就点Forward,以为自己已经掌握了“拦截与替换”…...

PCB的常规机械通孔与HDI工艺钻孔差异
结合常规 4 层通孔 PCB(非 HDI) 标准制程,分步骤讲清钻孔时机、先后顺序,区分机械通孔与板件结构,专业且贴合工厂实际流程。一、先明确 4 层通孔板基础结构4 层板结构:L1 → PP 半固化片 → L2/L3ÿ…...

Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题
Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘爆红、…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...

Unity塔防底层架构:ScriptableObject驱动的数据契约设计
1. 这不是“又一个塔防模板”,而是塔防开发的底层操作系统我第一次在Asset Store点开Tower Defense Toolkit 4(TDTK-4)的预览图时,下意识划走了——界面太“干净”了,没有炫酷的粒子特效演示,没有满屏飞舞的…...

基于晶体管逻辑的水箱自动控制器设计与实现
1. 项目概述:一个基于晶体管逻辑的自动水箱/湿度灌溉控制器 如果你也像我一样,曾经为家里的花园、阳台植物或者农村老家的储水塔手动开关水泵而烦恼,那么这个项目就是为你准备的。我设计并制作了一个完全自动化的水箱水位控制器,它…...
到底怎么设?附场景实测)
Unity新手避坑指南:NavMesh烘焙参数(Agent Radius/Height)到底怎么设?附场景实测
Unity导航系统深度解析:Agent参数设置与场景适配实战在Unity游戏开发中,导航系统(Navigation System)是实现角色智能移动的核心模块。对于刚接触Unity导航系统的开发者来说,Agent Radius(代理半径)和Agent Height(代理身高)这两个参数的设置往…...

解决claude code频繁封号与token不足的taotoken接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号与Token不足的Taotoken接入方案 1. 问题背景:Claude Code用户面临的挑战 对于依赖Claude Cod…...

SMUDebugTool:AMD Ryzen处理器深度调试与性能调优完全指南
SMUDebugTool:AMD Ryzen处理器深度调试与性能调优完全指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...